
模式分工型混合生成式对抗网络
2019-04-08 00:46侍海峰何良华卢剑
现代计算机 2019年6期
侍海峰,何良华,卢剑
(1.同济大学计算机系,上海201804;2.北京大学第三医院,北京100083)
0 引言
生成式对抗网络(Generative Adversarial Nets,GAN)[1]是一类基于对抗训练和深度神经网络的无监督生成式模型,由一个生成器网络和一个判别器网络构成,可以生成服从训练集分布的无限多的样本。自2014年被提出后,迅速成为深度学习、人工智能领域的研究热点之一,在图像生成、图像风格变换、图像超分辨率、视频生成等领域应用广泛。
然而GAN存在训练不稳定,容易对抗崩溃的问题。此外,生成分布还存在“模式丢失(mode dropping)”问题[2],只能生成训练集分布的一个子集,多样性不足。WGAN-GP[3]改进了原始GAN的目标函数,解决了训练不稳定的问题。混合生成式对抗网络(Mixture GAN,MGAN)[4]是一种集成模型,通过混合多个生成器的分布来改善模式丢失问题,增加生成样本的多样性。然而,MGAN的多个生成器的混合权重被设置为均等值,不适合类别不平衡且比例未知的数据集。
基于WGAN-GP和MGAN,本文提出模式分工型混合生成式对抗网络(Mode-Splitting MGAN,MSMGAN),向MGAN的训练算法中加入了生成器混合权重学习环节,提高了MGAN在类别不平衡数据集上的生成效果,能促使多个生成器分别学习训练集中不同的模式,即“模式分工”。此外,替换MGAN的原始GAN目标函数为WGAN-GP的目标函数,使训练更稳定。在由UTKFace[5]和Toronto Face Dataset[6]混合而成的多模态不平衡人脸图像数据集上的实验表明,MSMGAN生成分布具有更低的Frechet Inception Distance(FID)[7],且支持按类别生成图片。
1 生成式对抗网络
原始生成式对抗网络[1]结构如图1所示,由生成器和判别器两个神经网络构成。生成器将输入的噪声向量z映射为生成样本xF(又称假样本);判别器接收生成的假样本和来自训练集的真实样本x,输出样本为真实样本的概率。
噪声向量z的各分量通常是相互独立的高斯噪声。生成器的训练目标是优化自身参数,尽可能使判别器误把假样本判别成真样本;判别器的训练目标则是优化自身参数,尽可能准确地区分真实样本和假样本。生成器和判别器训练的目标函数(损失函数)分别为:
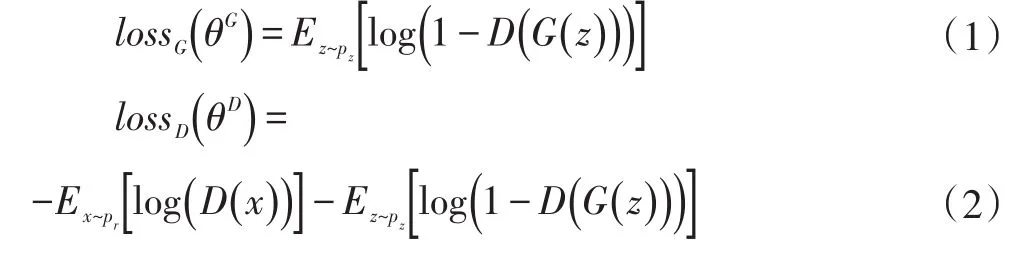

图1 生成式对抗网络结构图
文献[1]证明了在理想的条件下,对抗训练将达到纳什均衡,生成器生成的样本xF的分布Pg将和训练集真实分布Pr相同,判别器将无法区分其输入样本的来源,输出恒定为0.5。此时的生成器即可用于生成能以假乱真的样本。
原始GAN存在训练不稳定,容易崩溃的问题。针对该问题,文献[3]提出WGAN-GP模型,模型的判别器损失函数为:
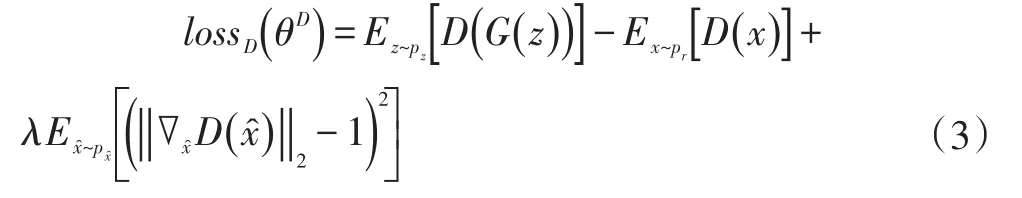
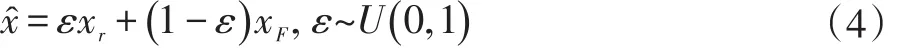
WGAN-GP训练稳定性和生成分布的多样性均优于原始GAN,本文提出的MS-MGAN模型亦采用该损失函数和训练方式。
2 混合生成对抗网络
为了解决GAN存在的“模式丢失”问题,增加生成样本的多样性,一些基于集成模型思路的集成类GAN模型被提出,Mixture GAN(MGAN)便是其中的典型。MGAN由K个生成器网络、一个判别器网络D和一个分类器C构成。分类器预测生成样本来源于哪一个生成器,判别器预测生成样本来源于真实分布还是生成分布。MGAN的生成器、判别器和分类器进行如下的最小-最大博弈:
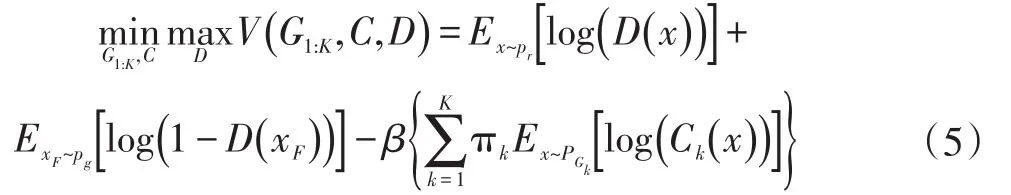
可见生成器的目标有两部分,既含有原始GAN目标函数中对抗判别器的项,又包含迎合分类器分类的项。后者含有超参数β,用于平衡目标函数中二者的比例。MGAN中各生成器G1,G2,…,Gk的混合权重被π1,π2,…,πK设定为1/K,即K个生成器的分布均匀混合。MGAN的目标函数能直接迫使多个生成器生成不同模式的样本,以便于分类器区分,适合学习由若干个良好分离的分布等概率混合而成的分布。
3 模式分工混合生成对抗网络
基于WGAN-GP和MGAN模型,本文提出模式分工混合生成对抗网络(MS-MGAN),以更好地学习和生成类别不均衡的数据分布。原始GAN和WGAN-GP模型都只具有一个生成器,让单个生成器网络学习复杂的多模态图像数据分布是比较困难的,易导致生成的图像质量欠佳。MGAN采用多个生成器分工学习复杂的数据分布,其实验表明[4],算法提高了生成样本的质量和多样性,但是其超参数β对数据集比较敏感,需要精心调节,增加了算法的调参难度。此外,MGAN的多个生成器的混合权重π1,π2,…,πK被设定为均匀分布,但现实中的数据集往往各类别(模式)的占比不均匀,导致MGAN的各生成器会出现不合理的分工,影响生成质量。
本文提出的MS-MGAN舍弃了MGAN中的分类器,从而从模型中去除了敏感的超参数 β。采用WGAN-GP的训练目标代替了MGAN中使用的原始GAN目标函数,提高了模型的训练稳定性。此外,增加了多个生成器混合权重的学习环节,能根据训练分布中不同模式样本数量的占比分配各生成器对应得权重,使得各生成器合理分工学习训练集中不同得模式,即使没有额外分类器的促使作用。MS-MGAN的判别器损失函数同WGAN-GP的判别器损失函数,即式(3)。而生成器损失函数则被修改为判别器对多个生成器样本评价的加权值:
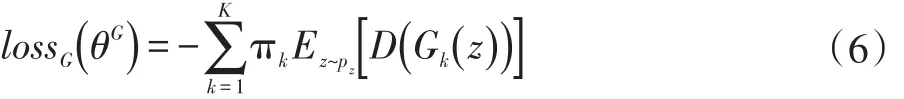
MS-MGAN的训练算法在WGAN-GP的基础上增加了对π1,π2,…,πk的梯度下降法更新过程。在一次GAN训练迭代中,除了原有的①固定生成器网络,训练判别器;②固定判别器网络,训练生成器;这两个步骤以外,加入混合权重学习环节③固定判别器网络和各生成器网络,并从每一个生成器各采样一个mini-batch的生成样本,计算判别器对各生成器分布的期望评价并作为常数带入(6)式,再将生成器的损失函数对π1,π2,…,πK,求梯度,更新混合权重。每一个迭代中进行上述3个步骤的计算,可以使多个生成器按训练集中不同模式的比重合理分工。
4 实验
4.1 数据集与实验环境
为了测试MS-MGAN在类别不均衡数据集上的表现,将UTKFace和Toronto Face Dataset(TFD)数据集中的人脸图像混合成一个训练集。UTKFace数据集提供了23708张分辨率为200×200的剪裁并对齐了的彩色人脸图像,TFD包含102236张分辨率96×96的灰度人脸图像。由于UTKFace中的图像数量较少,将每一张人脸图像都水平翻转,以将数据集图像数量倍增至47416。TFD数据集中的图像的灰度通道则被复制为3通道彩色图像。所有人脸图像均缩放至64×64分辨率。因此可知不平衡混合人脸数据集中UTKFace和TFD这两种模式的比例为47416:102236=0.3168:0.6832。
本文MS-MGAN实验程序基于WGAN-GP的官方开源代码修改而成,生成器网络和判别器网络均选用广泛使用的类DCGAN[8]的网络结构。实验使用NVIDIA GTX 1080Ti GPU和TensorFlow 1.12进行训练,操作系统为Ubuntu 18.04。
4.2 生成分布评价指标
实验评价除了采用直接观察生成图像的定性方法外,还采用广泛使用的定量指标Frechet Inception Distance(FID)。FID使用Inception[9]模型的中间编码层的特征向量,对训练集真实图像和生成器合成的图像的Inception编码层特征分别回归成多元高斯分布,然后计算这两个多元高斯分布之间的Frechet距离,计算公式如下:
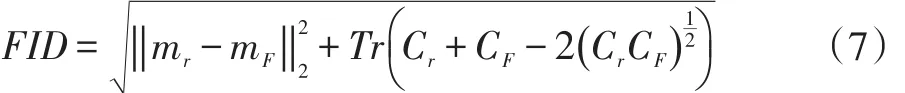
其中mr,mF分别是真实图像和生成图像输入Inception模型得到的编码层向量的均值,Cr和CF分别是协方差。FID值越低,生成分布就更接近真实分布。
4.3 实验结果与分析
实验考察了单生成器的WGAN-GP模型、具有2个生成器的MGAN模型和具有2个生成器的MSMGAN模型。为了公平比较,单生成器的WGAN-GP模型的生成器规模等比例放大到MGAN和MS-MGAN生成器的2倍。三个模型的实验的批大小均为64,训练迭代200000次(每次迭代中生成器被训练一次,判别器被训练5次)。每个WGAN-GP模型和MGAN模型训练一次花费GPU约26小时,MS-MGAN由于增加了混合权重学习环节,训练一次花费27小时左右。为了避免神经网络类方法固有的随机误差,每个模型均随机初始化训练了4次。训练过程中,每10000次迭代,采样50000个生成样本,计算FID值。每个模型在一次训练过程中达到的最小FID值的平均值、标准差如表1所示。表中生成器参数量是指模型包含的所有生成器网络参数的总和。所有模型都只有一个相同结构的判别器,判别器参数量均为4.317M。

表1 不同模型生成质量(FID)对比表
从表1可以看出,WGAN-GP、MGAN和MSMGAN的FID值依次降低,表明后二者生成分布质量均优于WGAN-GP,即使单生成器模型的生成器尺寸已经翻倍。支持生成器混合权重学习的MS-MGAN取得了最低的FID值,表明MS-MGAN更能适应现实中更为普遍的类别不均衡数据集。
图2为MS-MGAN模型在200000次GAN训练迭代中,两个生成器的混合权重的变化趋势。横轴为迭代次数,为展现训练早期的曲线变化,采用对数坐标。可见训练初期两个生成器的混合权重波动较为剧烈,因为此时模型刚初始化,见到的训练集样本不多,生成分布和判别器判别都不太准确。但是迭代次数超过10000次后,混合权重已经基本稳定在真实值附近小幅波动了。因此,本文提出的MS-MGAN可以快速学习出合理的生成器混合权重,其实可以在后95%的训练迭代中的固定混合权重不再学习,以加快训练速度。
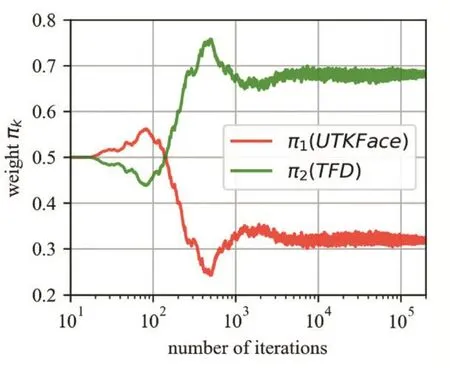
图2 MS-MGAN生成器混合权重变化图
表2为MS-MGAN在4次随机初始化实验中学习到的两个生成器的混合权重。由于两个生成器符号具有轮换对称性,我们约定训练结束后混合权重较小的生成器为G1,对应权重为π1。混合权重较大的则为G2,对应权重为π2。可见4次实验中MS-GAN均基本准确地向两个生成器分配了符合训练集两种模式占比(0.3168:0.6832)的混合权重。因此,本文提出的混合权重学习算法是稳定而精确的。
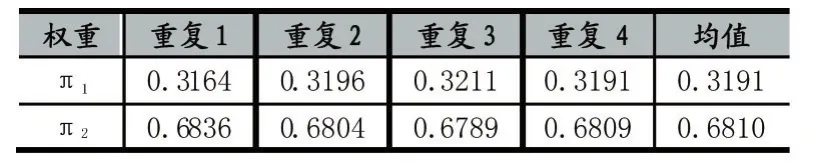
表2 MS-MGAN混合权重学习结果表
从MS-MGAN和MGAN的两个生成器随机采样的一部分样本如图3所示,前2行(红线上方)分别是MS-MGAN的两个生成器生成的样本,后两行(红线下方)分别是MGAN的两个生成器生成的样本。通过比较可以发现,MS-MGAN的两个生成器G1,G2分别学习生成了混合人脸数据集中UTKFace(彩色)和TFD(灰度)这两种模式的样本,而MGAN的生成器G2负责生成TFD的人脸,G1既负责生成一部分UTKFace的彩色人脸,又负责生成一部分TFD人脸。这是因为MGAN的两个生成器的混合权重被固定为0.5,而训练集中两种模式的比例分别为0.3168:0.6832,导致必须有一个生成器负责两种模式样本的生成,才能使生成分布服从真实分布。MS-GAN由于具有混合权重学习环节,两个生成器的混合权重能快速收敛至训练集中两种模式的混合比例,使生成器更合理的分工,从而可以生成比MGAN具有更少瑕疵、失真的人脸样本,并可以通过选择不同的生成器以实现按类别采样,增加了采样的可操控性。

图3 MS-MGAN和MGAN随机生成样本图
5 结语
本文提出了模式分工型混合生成式对抗网络(MS-MGAN),向MGAN训练算法中加入混合比例学习环节,在类别分布不平衡数据集上的生成质量优于MGAN,且各生成器能分工学习训练集中不同的模式,从而支持按类别采样生成。
猜你喜欢
现代装饰(2022年5期)2022-10-13
心理学报(2022年5期)2022-05-16
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
当代陕西(2020年17期)2020-10-28
小学生学习指导(低年级)(2019年6期)2019-07-22
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
小学生学习指导(低年级)(2018年3期)2018-01-31
