
融合翻译知识的机器翻译质量估计算法
2019-05-16 01:40朱聪慧赵铁军
智能计算机与应用 2019年2期
孙 潇,朱聪慧,赵铁军
(哈尔滨工业大学计算机科学与技术学院,哈尔滨150001)
0 引 言
随着经济的发展,国际交流合作日益频繁,对机器翻译的需求逐渐增大。而机器翻译译文质量的自动评价,对机器翻译的研究非常重要。其中,广泛使用的BLEU评价指标就推动了机器翻译的进步与发展。
目前常用的BLEU评价指标存在2个主要问题。首先是指标的计算要求有参考译文作为输入,其次指标在句子级别上对译文的评分效果比较差。而句子级别的机器翻译质量估计(Sentence-Level Translation Quality Estimation,Sentence-Level QE)则可显著改善这类现象。Sentence-Level QE是指在没有参考译文的情况下,只根据源语句,来对机器翻译译文的质量进行估计。定义中的质量可以指:adequate(和源语句的意思相近程度)、fluency(翻译的流畅程度)、HTER(Human-targeted Translation Edit Rate)等等。其中,HTER最为常用。HTER是机器翻译的译文和人工修改的参考译文(Humantargeted Translation)之间的编辑距离除以所有参考译文的平均长度。
以往的基于特征工程的翻译质量估计方法的研究中,一些用神经网络提取特征的方法并没有考虑引入翻译知识。
本文中,研究提出一种原创的用神经网络机器翻译模型来为QE任务提取特征的方法,该方法利用了NMT模型,比以往的用神经网络提取的QE特征包含了更多的语义信息。
1 相关工作
对句子级别的机器翻译质量估计的研究,一般是将其归作为一个有监督的回归问题,此前的研究主要是应用传统的统计模型,比如SVR、线性回归模型等等,研究均重点致力于特征提取(feature extraction)和特征选择(feature selection)方面。其中,特征提取指的是从源语句和对应的机器翻译的译文以及一些外部的资源或工具中提取构造和译文质量相关的特征,也就是针对这个机器学习任务做特征工程(feature engineering)。而特征选择是指,从已经提取的特征集合中选择预测效果最好的特征子集,这可以看作是一个搜索寻优问题,并被证明是一个NP问题,无法在多项式的时间复杂度内得到准确解。因此机器译文质量估计的特征选择一般包括产生候选子集和对特征子集进行评价这2个要素,机器译文质量估计领域常用的特征选择算法包括高斯过程[1]、启发式[2]。 在之前句子级别机器译文质量估计的研究中,至关重要的即是特征提取,也就是人工设计合适的特征[3-6]。常见的人工提取的特征包括源语句长度、目标语句长度、特殊字符匹配率等等。这些人工提取的特征,大多数是一些语法特征,很少涉及到语句的深层次语义信息。
随着深度学习的发展,有些研究者将神经网络用于特征提取的过程中,然后将提取到的特征单独或者和其它传统特征一同输入到机器学习模型中;常见的神经网络提取的特征包括源语句和目标语句在神经网络语言模型中的分数、在神经网络机器翻译下的分数、语句的所有单词对应的词向量的平均值等等[7-10]。这些特征和之前传统的特征相比,包含了较多的语义信息。
除了用神经网络提取特征,然后应用传统的统计模型外,有的研究更进一步提出了基于多层神经网络的端到端的机器译文质量估计模型[11-14]。而且,研究中QE任务的数据集比较小,因此直接训练端到端的模型,将存在过拟合的风险。目前,效果较好的此类方法,一般都是直接或间接地利用了大量的平行语料来提高模型的泛化能力。
2 模型详述
2.1 基本模型简述
本文利用神经网络机器翻译模型来为机器翻译译文质量估计问题(QE)提取特征,是对直接将语句的单词词向量的平均作为特征的方法的有效改进。在本文第一节中提到,QE领域的研究中,对特征的提取非常关键;在特征提取方面,之前的研究主要是对源语句和机器翻译的译文提取语法相关的特征,也有一些研究探讨了语义问题。随着近些年深度学习的兴起,一些研究使用神经网络来提取和句子的语义相关的特征。其中一个方法是,用词袋模型对句子建立模型,也就是将句子看成是单词的集合,不考虑词语间的先后顺序,用该语句的所有单词对应的词向量的平均值作为对该语句的编码。对源语句和译文用上述方法编码之后,得到2个向量,对这2个向量进行拼接,作为QE模型的输入特征。
这种直接对句子中的单词的词向量求平均的方法,没有考虑词语间的先后顺序和联系,很难提取到语句深层次的语义信息。因此可以考虑用循环神经网络(Recurrent Neural Network,RNN)对句子进行编码,本文采用的是 GRU(Gated Recurrent Unit)。GRU是循环神经网络的一种,不仅可以适用于如自然语言语句这种变长的序列研究,同时也可以如长短期记忆网络(Long Short-Term Memory,LSTM)一样处理较长距离的依赖关系,但与LSTM相比结构更加简单,因此本文在循环神经网络的变体中选用GRU作为编码器(和解码器)。同时,针对已有研究的分析表明,GRU每一步的隐状态包含了输入序列中当前输入以及之前所有输入的信息,因此本文采用GRU最后一步输出的隐状态作为对整个语句的编码向量。
此外,因为QE任务的数据集一般比较小,比如本文实验选用的训练集只有2万个标注数据;而机器翻译领域的常见语言对的数据集一般比较大,因此本文考虑通过引入2个简单的神经网络机器翻译(Neural Machine Translation,NMT) 模型,来充分利用大量的平行语料。引入的2个NMT模型翻译方向相反,一个是源端到目标端语言,另一个是目标端语言到源端语言。这2个NMT模型的编码器分别对源语句和目标语句进行编码得到编码向量,然后2个NMT模型的解码器再分别对编码向量解码得到目标语句和源语句;其中,2个NMT模型对源语句和目标端语句编码得到的编码向量理论上就分别包含了源语句和目标语句的信息。本文利用2个NMT模型的编码器分别对源语句和机器翻译的译文进行编码,得到的向量就作为QE模型的输入特征。
整个模型由2部分构成。第一部分是2个翻译方向相反的NMT模型,第二部分是QE模型,输出最终的质量HTER。输入的是从源语句和目标语句提取得到的特征向量,在这里是2个NMT模型编码得到的编码向量,特征向量中除此之外也可以包含通过其它途径提取到的特征。整体的模型结构如图1所示。
2.1.1 NMT 子模型
整个算法中一共包括2个翻译方向相反的NMT模型,分别是源端到目标端和目标端到源端。2个NMT模型结构完全相同,共享词向量参数。下面即以源端到目标端的NMT模型为例展开论述。源端的语句X={x1,x2, …,xS},xi(1≤i≤S) 是源语句中的单词的one-hot编码,S为源端语句的长度;目标端语句Y={y1,y2, …,yT},yj(1 ≤j≤T)是目标语句中的单词的one-hot编码,T为目标端语句的长度。源端和目标端的词向量矩阵为ES和ET,其中词向量矩阵的每一列代表一个单词的词向量。选用的NMT模型由编码器和解码器2部分组成,编码器和解码器使用的神经网络模型都是GRU。编码器的功能是将源端语句X编码为固定向量C。然后解码器对C进行解码得到目标端语句Y。 整个NMT模型可以表示为P(Y|X;θ),该条件概率可以用概率的乘法法则分解,数学公式可见如下:
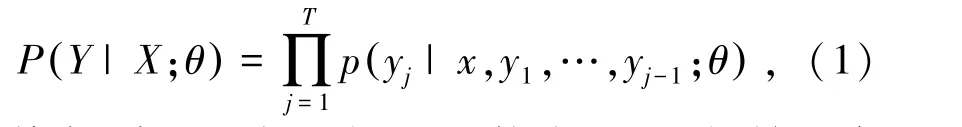
其中,编码器主要由GRU构成,GRU初始的隐状态为零向量。在每一步的实际计算中,需先将该步的单词的one-hot表示xi用词向量矩阵ES映射为词向量ES×xi,然后和上一步的隐状态一起作为输入,进行GRU当前步的计算。并且将最后一步输出的隐状态hS作为对整个源语句的编码向量C。第t步的计算公式可表示为:

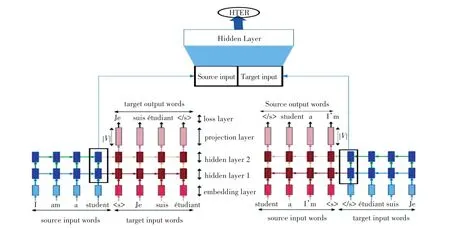
图1 模型整体结构Fig.1 The structure of the model
解码器对源语句的编码向量C进行解码。采用的神经网络模型是GRU,初始的隐状态是C,C包含了源语句的信息。每一步最终的输出是对这一步的词表中所有单词的概率分布,而输入却是上一步的预测的单词的词向量,训练过程中的输入则是上一步中目标语句对应的单词的词向量。第t步的隐状态ht的计算公式和编码器部分相似。这里采用的是一个单隐层的前向神经网络,第t步的目标词概率分布的计算公式具体如下:
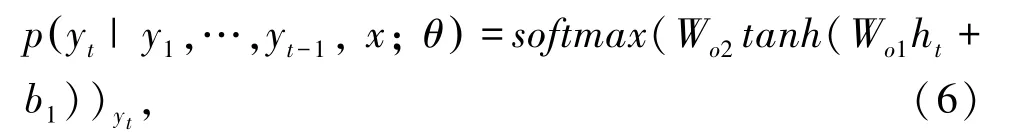
2.1.2 QE 模型
QE模型的输入是特征向量V,在基本模型中特征向量是源端句子编码向量CS和目标端句子编码向量CT的拼接 [CS:CT]。 模型采用的是单隐层的前向神经网络,权重分别是W1和W2,偏置向量分别是b1和b2。隐层的激活函数采用relu,输出层因为要输出0~1的分数,因此采用sigmoid作为激活函数。公式表述如下:

2.2 加入其他特征
对源语句和机器翻译译文的编码向量分别包含了源语句和译文的语义语法信息,但是向量的每个维度都具有不可解释性。因此本文将其它一些人工提取的特征和这2个用神经网络提取的特征进行连接,作为QE模型的输入特征。这些特征都具有高度直观、且容易理解的含义。添加的特征有 17个[15],对其含义可阐释解析如下。
(1)源语句中的单词数量。
(2)机器翻译语句中的单词数量。
(3)源语句长度。
(4)源语句的语言模型概率。
(5)机器翻译语句的语言模型概率。
(6)机器翻译语句内单词出现次数的平均值。
(7)源语句中每个单词对应的翻译数量的平均值(使用 IBM 模型 1, 阈值设置为prob(t|s)>0.2)。
(8)源语句中每个单词对应的翻译数量(使用IBM 模型 1, 阈值设置为prob(t|s)>0.01) 的加权平均值,权重为源语言语料库中每个词的逆频率。
(9)源语句中的单词占源语言语料库(SMT训练平行语料库)中频率四分位数1(频率较低的单词)的百分比。
(10)源语句中的单词占源语言语料库中频率四分位数4(频率较高的单词)的百分比。
(11)源语句中的bigrams占源语言语料库中频率四分位数1的百分比。
(12)源语句中的bigrams占源语言语料库中频率四分位数4的百分比。
(13)源语句中的trigrams占源语言语料库中频率四分位数1的百分比。
(14)源语句中的trigrams占源语言语料库中频率四分位数4的百分比。
(15)在语料库(SMT训练平行语料库)中可以看到的源语句中的单词所占的百分比。
(16)源句子中标点符号的数量。
(17)目标语句中标点符号的数量。
3 实验
3.1 实验设置
本文为了对用NMT模型提取的特征的效果进行验证,在2个不同的数据集上分别进行了4组实验,每组实验的不同点主要在于输入的特征。这4组实验采用的特征,分别是:17个人工提取的特征、词向量特征、NMT模型提取的特征、NMT提取的特征加上17个人工提取的特征。其中,第一组实验采用SVR作为模型,其它组的模型采用前向神经网络。这里,关于本次实验中的数值指标设计,对其可概述如下。
(1)模型和训练的参数设置。SVR的核函数采用径向基,其他超参数使用交叉验证确定。源端和目标端词表大小为74 000,词向量的维度设置为512,神经网络(包括GRU、全连接神经网络)的隐层神经元个数为1 024。神经网络的优化算法采用adam,batch的大小为64,训练NMT模型的学习率为3e-4,训练QE模型的学习率为5e-5。
(2)实验所使用的数据集描述。用于训练NMT的数据集来自于WMT 2017 shared task的en-de翻译任务,语料包括 Europarl v7、Common Crawl corpus、News Commentary v12、Rapid corpus of EU press releases等,总共3 M个句对。研究采用的NMT模型结构比较简单,因此从所有3 M个句对中随机抽取90 w个句对。再加上对应的QE数据集(源语句加上被人工post edit后的译文)中的2 w个句对,组成训练本文所需的NMT模型的平行语料。
用于训练QE的数据集来自于WMT17 Shared Task:Quality Estimation任务一,包括德语到英语和英语到德语2个方向的数据集,并且分别属于2个不同的领域。数据集信息详见表1。
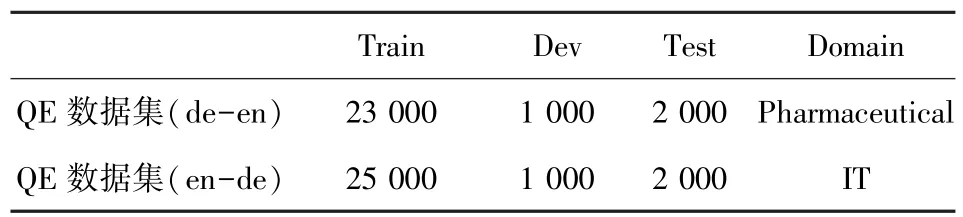
表1 QE数据集Tab.1 QE data set
3.2 实验结果
实验运行结果参见表2、表3。
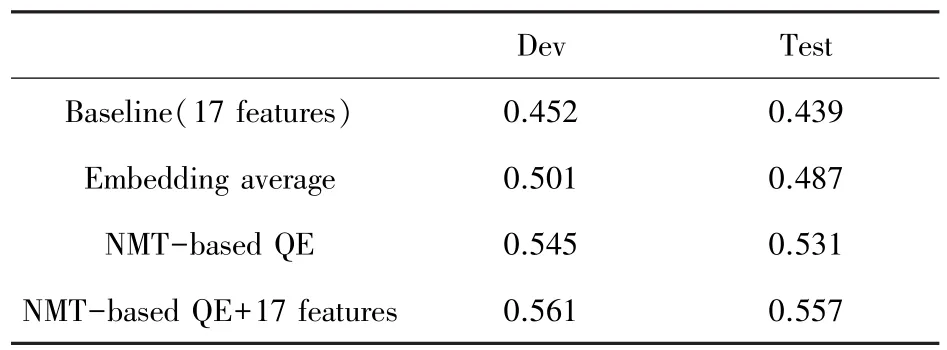
表2 de-en数据集Pearson相关系数Tab.2 The Pearson of de-en

表3 en-de数据集Pearson相关系数Tab.3 The Pearson of en-de
综上结果分析可知,在2个方向上,可以看到相比于人工提取的17个特征,即使使用词向量直接相加提取的特征,效果也会更好。这说明词向量包含的单词带有大量的语义信息,即使不考虑单词之间的顺序和关系,也可以对最终译文的质量的预测有所帮助。然后本文使用了NMT模型中的编码器对句子的单词序列进行了非线性变换,最终的实验结果表明,这种非线性变换和直接求平均相比,对机器翻译译文质量的预测能力更强。最后,编码器得到的编码向量虽然包含了语义信息,但是每个维度都具有不可解释性,将其和人工提取的17个具有直观含义的特征拼接起来作为输入特征,效果有所提升,说明编码向量特征和这17个特征在一定程度上实现了互补。
4 结束语
针对机器翻译译文质量估计问题,本文提出了一个融合了翻译知识的特征提取算法,该算法首先训练2个翻译方向相反的NMT模型,然后利用2个编码器编码得到向量作为特征。实验表明,利用NMT编码器提取的特征比直接对语句中单词词向量平均的特征预测效果更好。并且,该特征和本文提到的17个手工提取的特征一定程度上具有互补性,2类特征的结合可以进一步提升QE模型的效果。
猜你喜欢
传感器世界(2022年4期)2022-08-05
锻压装备与制造技术(2021年5期)2021-11-13
外语学刊(2021年1期)2021-11-04
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
师道·教研(2017年11期)2017-12-10
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年1期)2014-06-15
小雪花·初中高分作文(2009年8期)2009-11-16
