
基于Ad-Sim算法的代码克隆检测方法
2019-06-11 08:18
浙江工业大学学报 2019年4期
(浙江工业大学 计算机科学与技术学院, 浙江 杭州 310023)
随着互联网高速发展及软件需求的不断增加,代码克隆和代码复用频繁地出现在软件快速开发和重构过程中。研究数据表明:一般的软件开发过程中包含5%~20%的重复代码,在很多知名的软件系统中也包含大量的代码复用,如Linux核心代码中就存在15%~25%的复用代码,而在开源项目中更是有超过50%的代码被复用[1]。随着开源项目的不断发展、代码复用不断扩大,代码复用的广泛程度可以作为代码质量的评判标准和选择所复用的代码模块的参考依据[2]。代码复用也存在两面性:一方面,重用高质量的代码不仅可以提高开发效率,而且能规避编写新代码带来的风险;另一方面,恶意或滥用低质量的代码则会导致系统出现大量Bug、软件运行效率低下以及影响系统安全[3]等问题,且克隆代码给软件维护带来影响,当克隆代码出现Bug时,其他相似代码则存在相同Bug。通过代码克隆检测可以判断应用系统中是否存在克隆代码,若存在克隆代码则对其进行重构,从而提高代码质量。因此,对于软件开发项目的代码克隆检测就显得十分必要。代码克隆检测有很多不同种类的检测技术及应用场景,主要分为5 类:基于Text(文本)方法[4]、基于Token(词法)方法[5]、基于AST(抽象语法树)方法[6]、基于PDG(程序依赖图)方法[7]和基于Metrics(度量值)方法[8]。基于Text检测方法通常是对源代码之间的字符串进行比较,对代码文本布局、注释进行规范化处理外不进行其他形式转换。基于Token方法首先使用词法或语法分析工具把源代码的每一行都转换成token序列,并将所有序列连接成token串;接着扫描这个token串并找到相似的token子序列即为克隆代码。基于AST方法使用语法分析器将检测代码转化为抽象语法树,再使用子树匹配算法检测。基于PDG方法是将检测代码转换为程序依赖图,再使用检测子图同构方法进行检测。基于Metrics方法是通过提取检测代码的度量值间接对代码中可能存在的类似代码进行检测[9]。
经过对以上克隆检测方法的研究:一方面,基于AST,PDG等方法有较高的准确率及召回率,但算法复杂,实现较为困难,消耗过多的计算资源,并且可扩展性有限,不适用于大量代码的克隆检测;另一方面,基于Text,Token,Metrics等方法有较快的检测速度,但检测准确率和召回率较低。因此,提出了基于Simhash[10]算法的代码克隆检测方法,并在Simhash指纹签名的计算过程中使用TF-IDF[11]及马尔科夫模型优化关键词权重分配,计算出L位二进制01串代码指纹签名。文档相似度计算存在很多不同的方法和应用[12],笔者采用汉明距离[13]来计算待检测代码的相似度。
1 Simhash算法
Simhash算法由Google公司的Charikar等在2007年第一次提出,是一种降低维度的算法,其核心是将一篇文档离散化转换成高维的特征向量再映射成唯一的L位二进制指纹签名,进而比较所产生的指纹签名,得出各文档之间的相似度。指纹越接近,则表明文档越相似。Simhash算法计算步骤描述如下:
步骤1初始化:待检测代码作为输入,输出为L位的二进制指纹签名S,初始化为0;定义L维向量V,初始化为0。
步骤2预处理:对代码文件进行分词处理,将文档转化为一组特征。
步骤3指纹计算:对于每一项特征,使用Hash算法得出L位的签名b,在Hash值得基础上,给所有特征向量进行加权,即w=Hash×Weight,如果b的第i(1≤i≤f)位为1,则向量V的第i个元素加上该特征的权重;否则V的第i个元素减去该特征的权重。
步骤4输出签名:如果向量V的第i个元素大于0,则签名S的第i位为1,否则为0,输出指纹签名S。
具体计算步骤如图1所示。
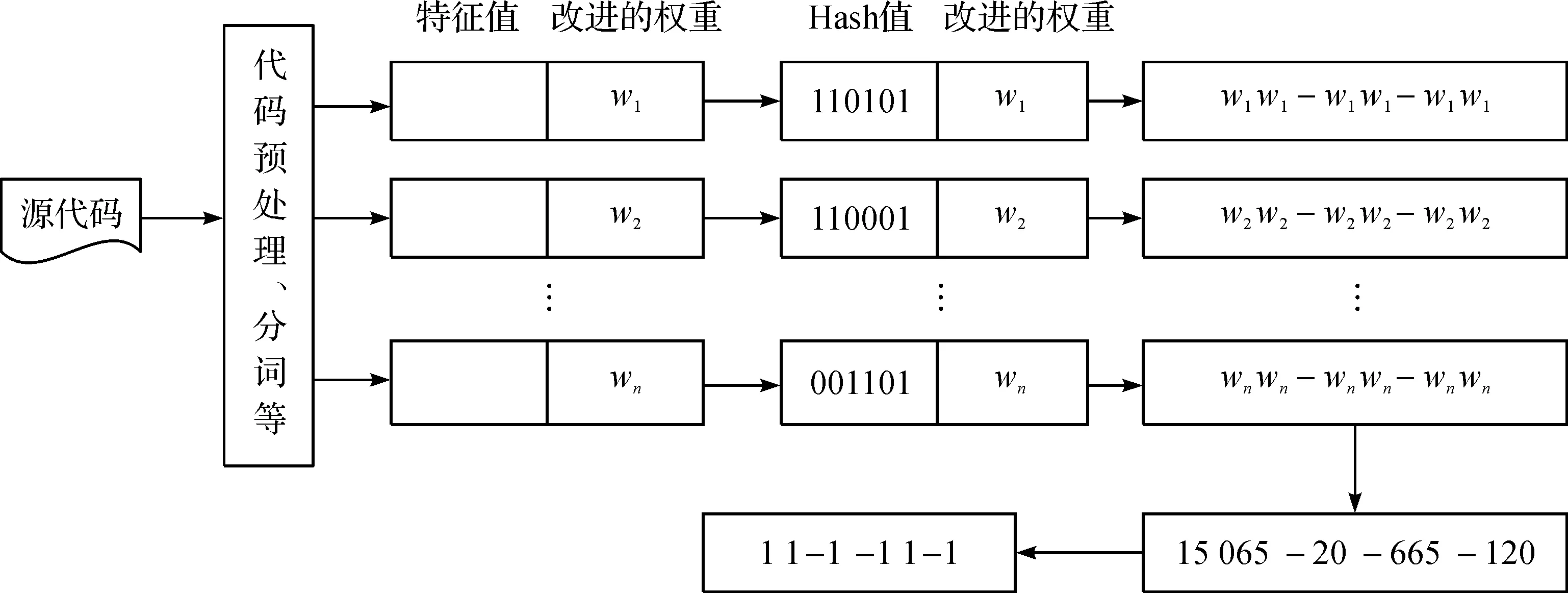
图1 Simhash算法流程图Fig.1 The flow chart of Simhash algorithm
Simhash算法的核心优势在于可以将一篇高维特征的文档转换为二进制指纹签名,提高相似度检测速度,但该算法是将代码中的所有单词作为关键词,代码中单词出现的次数作为关键词的权重,以此作为衡量标准计算得到的权重准确度不高,计算得到的指纹签名准确度也会降低。此外,Simhash算法是基于大量网页文档的查重技术,在少量文档的情况下,检测准确率较低。结合Simhash算法的优缺点,并针对Simhash算法中权重计算准确度等问题,提出了一种结合TF-IDF及马尔科夫模型的Simhash优化算法Ad-Sim。
2 Simhash算法研究与改进
2.1 代码预处理
为了提高代码检测的准确率,剔除代码中一些无关特征或者毫无意义特征对代码的影响,需要在指纹计算前进行代码归一化预处理。Ad-Sim算法中归一化处理过程主要包括:去除引用代码、词法分析和转换。
实验中代码克隆检测的测试用例代码使用的语言为Java,首先去除项目代码中参考引入或开源项目的部分代码;其次利用Java本身的词法规则对待检测代码进行词法分析,将每行代码解析成关键词序列。在经过词法分析后得到的关键词序列,为了提高检测准确率,还需要对关键词序列进行必要的添加、删除或修改,具体规则如下:
1) 删除单行注释、块注释以及文档注释等无关内容。
2) 删除package包名与类导入语句、数字和字符串等常量的无关代码。
3) 替换变量名、方法名和类名关键词为VARIABLE。
4) 替换各符号关键词为SYMBOL。
2.2 基于TF-IDF的关键词权重计算
(1)
用IDF表示逆向文件频率,即该关键词在所有文件中出现的频率。假设代码库中文件总数为M,包含关键词i的文件数为Ni,那么关键词i的逆向文件词频IDF为
(2)
关键词i对这份代码文档的重要程度为
(3)
Ad-Sim算法中采用TF-IDF计算代码中关键词的权重,优势在于可以过滤掉代码中对代码克隆检测没有用处的关键词。在计算IDF时,假设关键词序列中的代码文件总数以及包含某一关键词的代码文件总数相等,从而计算出该关键词IDF值为0,即表明该关键词在克隆检测中不起作用。例如在Java代码中,几乎所有的Java文件都会出现“public”“class”等关键词,利用TF-IDF去掉这些词后使得相对重要的关键词得到保留,从而提高指纹签名计算的精确度。
2.3 基于马尔科夫模型的关键词权重优化
如果把代码中出现的关键词作为一个状态来看的话,那么马尔科夫模型的状态转移矩阵恰好弥补TF-IDF的缺点。TF-IDF的缺点在于它只是记录单个关键词对代码文档相似度计算方面的影响,即TF-IDF关注的是个体,而马尔科夫模型则主要研究的是链,仅仅将TF-IDF值作为权重,还是会降低检测的准确度,于是将两者有机的结合起来以达到更好的检测效果。根据Java代码语义、语法规范可知:代码中所有关键词存在较强的相关性,如Java关键字之间的先后关系等,并据此在Ad-Sim算法中引入马尔科夫模型。首先建立源代码的关键词的马尔科夫链;其次计算马尔科夫链中前一关键词到后一关键词之间的马尔科夫转移概率,得出所有代码中所有关键词的马尔科夫概率转移矩阵;最后结合TF-IDF计算待检测代码中关键词的权重。
马尔科夫模型描述的是具有一定规律的离散状态随时间变化而不断转移的过程的模型化[14]。马尔科夫过程是指具有马尔科夫性的随机过程,而参数集与状态集均为离散的马尔科夫过程称为马尔科夫链[15]。
在关键词转移概率矩阵的构建中,转移概率通过代码库关键词各种状态转移出现的概率来获得,即每种关键词状态转移占代码库中所有状态转移百分比。利用马尔科夫状态转移矩阵计算方法求算出现有代码库部分关键词状态转移概率如表1所示,表1中行为前一个关键词,列为后一个关键词。
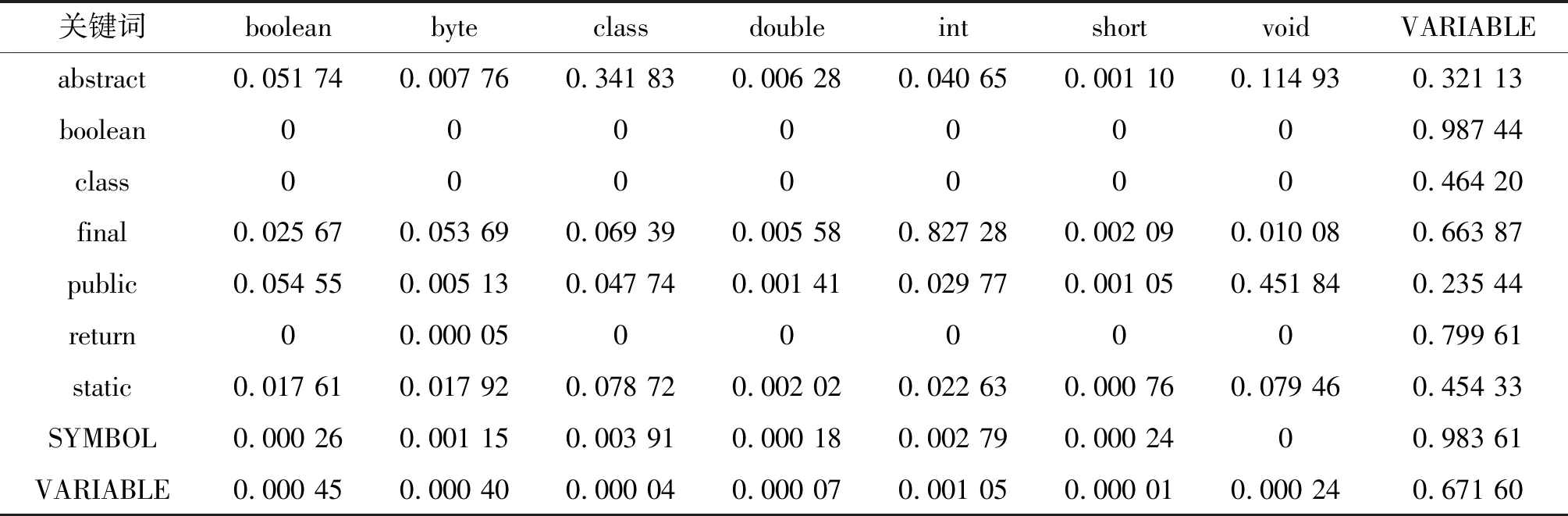
表1 代码库中部分关键词状态转移概率Table 1 State transition probability of part keywords in code library
通过对关键词TF-IDF以及马尔科夫模型的研究,在结合TF-IDF以及马尔科夫模型两者计算待检测代码中每个关键词的权重时,需要符合以下原则:
原则1权重的计算公式要体现出马尔科夫模型的作用,考虑代码中关键词的前后关系,利用马尔科夫转移矩阵来表示代码上下文对关键词权重的影响。
原则2与关键词的IDF值相结合,利用关键词的IDF值来表示关键词的稀有程度对权重的影响,使之能够继承TF-IDF的优点。
原则3在条件允许的情况下适当考虑算法的时间和空间复杂度的影响。
根据以上原则,权重计算式为

(4)
式中:i为第i个关键词;jn为原代码中第n个词。
2.4 代码克隆检测步骤
根据上述算法基本思想,给出结合基于汉明距离、TF-IDF及马尔科夫模型的代码克隆检测流程如图2所示,具体步骤如下:
输入:待检测代码
输出:是否存在克隆代码
1) 对实验样本代码进行归一化预处理,消除对克隆检测无关的代码。
2) 对实验样本代码进行分词处理,建立代码关键词序列,并使用mmh 3计算关键词Hash值。
3) 利用TF-IDF计算代码中所有关键词权重,并结合使用马尔科夫模型优化关键词权重,使用式(4)。
4) 在Hash值的基础上进行加权累加、合并和降维得出指纹签名。
5) 使用汉明距离计算待检测代码的相似度,根据阈值判断是否存在克隆代码。
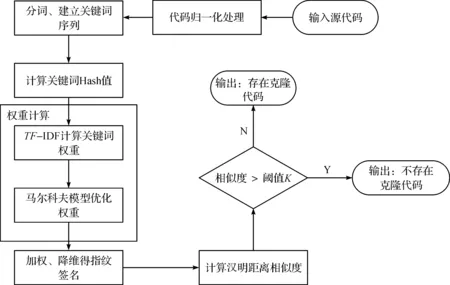
图2 优化算法代码克隆检测流程图Fig.2 The flow chart of optimized code clone detection
3 实验结果及分析
3.1 实验数据及评价方法
实验选取100 组Java代码作为测试用例,测试用例均取自开源项目的不同迭代版本。测试用例代码库中代码总量在150 万行以上,代码数量上保证了足够的测试样本用例,其中包含算法、框架、设计模式和应用系统,在代码复用和扩展等方面都具有代表性。
基于改进的Simhash算法代码克隆检测方法通过准确率、召回率及F-Measure值等3 方面来综合性评价。
1) 准确率:用于衡量代码克隆检测方法的查准率,通过算法检测出正确的组数与检测出克隆的所有组数的比值来计算。计算式为
(5)
2) 召回率:用于衡量代码克隆检测方法的查全率,通过算法检测正确的结果数与人工检测出克隆的所有组数的比值来计算。计算式为
(6)
3)F-Measure值:用于综合评价准确率及召回率,因为单一的准确率或召回率高并不能综合算法检测效果,F-Measure值通过准确率和召回率的调和平均值来计算。计算式为
(7)
3.2 实验对比
3.2.1 不同K,L值下Simhash及Ad-Sim算法F-Measure比较
根据相似度判断源代码是否是克隆代码,而指纹签名长度L及汉明距离K对实验最终结果的影响比较大,因此需要分析不同的K,L对克隆代码检测效果的影响,分别取不同的K,L值对Simhash算法及优化后Ad-Sim算法进行分析,计算克隆代码检测的F-Measure值。使用Simhash及Ad-Sim算法下,不同K值情况下的F值如图3,4所示。

图3 Ad-Sim算法下不同K,L值下F-Measure值情况Fig.3 F-Measure of Ad-Sim algorithm with different K,L
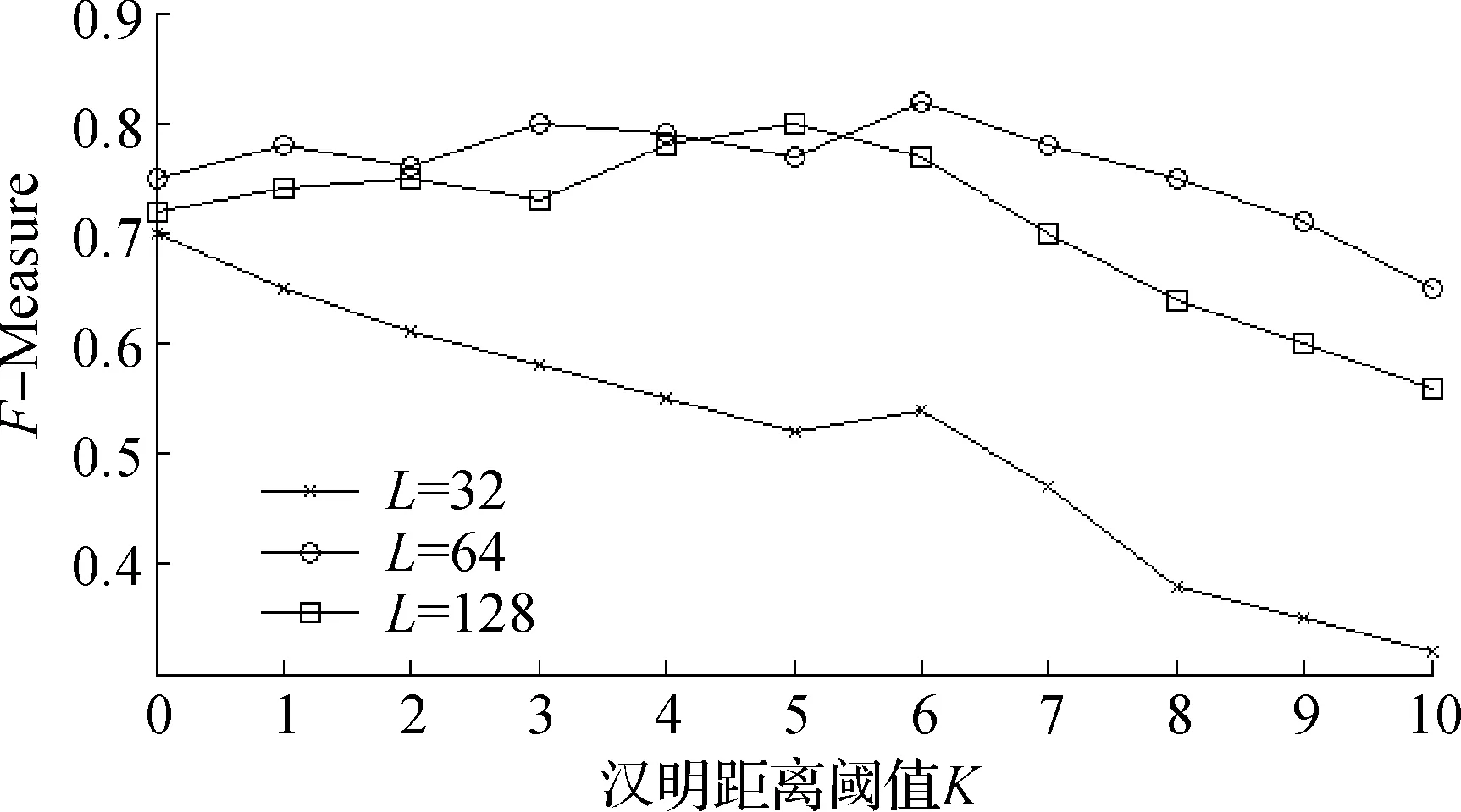
图4 Simhash算法下不同K,L值下F-Measure值情况Fig.4 F-Measure of Simhash algorithm with different K,L
当K取值较小时,有较高的准确率但召回率很低,而K取值较大时,会导致检测准确率较低,此外不同位数的二进制指纹签名也会影响检测准确率,不同位数的指纹签名能代表源代码的关键词信息不同。从图3,4可知:当K=4,L=64时,优化后Ad-Sim算法克隆检测的F-Measure值最大;当K=6,L=64时,Simhash算法克隆检测的F-Measure值最大。
3.2.2 Ad-Sim算法与Simhash,Dup,CCFinder的准确率比较
确定Ad-Sim,Simhash算法K,L值后,对Simhash及Ad-Sim算法的准确率及召回率进行测试,使用Simhash算法及优化后Ad-Sim算法计算100 组测试用例的64 位指纹签名,并比较每组测试用例的汉明距离及相似度,汉明距离及其相似度使用文献[12]中的公式计算,Simhash算法及优化后Ad-Sim算法部分测试结果如表2所示。
表2 原算法与优化算法汉明距离及相似度结果
Table 2 Results of Simhash and Ad-Sims’ Hamming distance and similarity

序号Simhash算法汉明距离汉明距离相似度Ad-Sim算法汉明距离汉明距离相似度150.960 940.968 8260.953 130.976 63320.750 0470.632 84410.679 7350.726 6540.968 840.968 8︙︙︙︙︙96280.781 3410.679 79750.960 930.976 698690.460 9560.562 59960.953 1390.695 310030.976 640.968 8
由表2可知:100 组实验中,每组实验的汉明距离及其相似度的原算法以及优化后Ad-Sim算法的克隆检测结果。表2第99 号数据中,Ad-Sim算法计算得到的汉明距离大于Simhash算法,进一步分析发现该组的2 份源代码关键词词频接近,使用Simhash算法出现误检现象,而Ad-Sim算法很好地解决了该问题。将笔者提出的Ad-Sim算法与Simhash算法、Dup[3]及CCFinder[4]代码克隆检测工具进行对比实验,表3为人工检测与各种算法检测的对比结果,从表3可以看出:优化后的Ad-Sim算法在代码克隆检测准确率及召回率相比较Simhash算法有所提高,且Ad-Sim算法相较于基于Text方法的Dup有更高的检测准确率,因为基于Text的方法在检测对源代码进行修改后的检测准确度、召回率较低,但相对于基于Token的CCFinder的检测准确率和召回率相对较低。
表3 Simhash算法与优化Ad-Sim算法检测结果准确率及召回率对比表
Table 3 Results of original and optimized algorithm’s precision and recall rate

检测方法克隆组检测组数正确组数非克隆组检测组数正确组数准确率/%召回率/%人工检测73732727Simhash算法8065201281.2589.04Ad-Sim算法7669262190.7994.52Dup7866221584.6290.41CCFinder7571252394.6797.26
3.2.3 不同代码量下Ad-Sim算法与Simhash算法比较
为测试代码量对Simhash算法及优化后Ad-Sim算法的影响,实验选择代码量大小从50 kB到800 kB,以50 kB为区间,对Simhash及Ad-Sim算法进行准确率测试。图5为不同代码量对各算法准确率的影响,可以看出:优化后Ad-Sim算法合适的测试代码量范围为250~700 kB,准确率达到90%以上,代码克隆检测范围优于Simhash算法,且优化后Ad-Sim算法的代码克隆检测准确度更趋于稳定。此外,在实验中当代码量小于200 kB时,由于源代码中关键词数量较少,仅通过词频作为权重使得Simhash算法生成的指纹信息准确度不高,导致Simhash算法的检测准确率明显低于Ad-Sim算法。
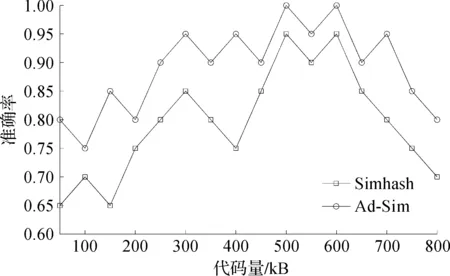
图5 原算法与优化算法随代码量变化下准确率对比图Fig.5 Results of original and optimized algorithm with change of code amount
4 结 论
在Charikar提出的大量网页文档查重的Simhash算法基础上,提出了一种结合TF-IDF及马尔科夫模型的改进Simhash代码克隆检测算法Ad-Sim。首先对代码进行归一化预处理,并进行分词、Hash、加权以及降维;其次在加权过程中对关键词权重计算时引入TF-IDF及马尔科夫模型;最终通过计算待检测代码指纹签名与代码库中代码的指纹签名的汉明距离相似度判断是否存在克隆代码。通过理论分析及实验验证,与Simhash算法相比,优化后Ad-Sim算法在检测准确率及召回率上更高,并且在少量代码的检测准确率提升更明显。
猜你喜欢
环球时报(2022-09-20)2022-09-20
九江学院学报(自然科学版)(2022年2期)2022-07-02
安庆师范大学学报(自然科学版)(2021年3期)2021-09-22
有色金属(矿山部分)(2021年4期)2021-08-30
今日农业(2020年24期)2020-12-15
智富时代(2018年12期)2018-01-12
智富时代(2018年12期)2018-01-12
中国市场(2016年44期)2016-05-17
中国铁路文艺(2016年6期)2016-05-14
小资CHIC!ELEGANCE(2015年14期)2015-09-23
