
基于概率矩阵分解的多失真图像质量评估算法
2019-07-15 11:18王同乐
计算机应用与软件 2019年7期
王同乐 王 慈
(华东师范大学计算机科学与技术系 上海 200062)
0 引 言
图像在采集、压缩、传输和存储过程中会产生各种各样的失真, 失真使得人眼对于图像的视觉观感变差[1],因此在接收端进行图像质量评价极为重要。图像质量评价有客观和主观之分,主观图像质量评价采用平均主观意见分或者主观差异评分衡量人的主观视觉感受。虽然主观意见评分合理准确,但是非常耗时耗力,因此通过图像质量评价算法进行自动化地客观评分非常必要[2]。IQA算法可作为图像处理系统的基本指标,也可作为图像去噪、增强和修复算法的性能比较标准,所以图像质量评价算法具有很大的应用和研究价值。
过去的数十年浮现了大量优秀的IQA算法,从不同的分类角度概括为以下三类。
根据是否需要参考图像,可分为全参考、半参考和无参考质量评价算法。早期著名的全参考算法有SSIM[3]和VIF[4]等,SSIM基于人眼视觉系统对结构信息敏感的假设,从亮度、对比度和结构三个方面度量失真图和参考图的相似性。VIF将HVS视为一个退化通道,通过在小波域中计算互信息比值定义信息保真度。文献[5]和文献[6]是近期比较优秀的全参考算法,文献[5]基于VIF思想解决了参考图像和失真图像分辨率大小不一致的全参考图像质量评价问题。文献[6]将失真视为真实细节损失和虚假细节增加的过程,利用梯度和梯度残差信息分别对损失的细节和增加的细节加以描述。考虑到全参考算法需要使用参考图像信息的局限性,文献[7]中提出了从使用全部参考信息到几乎不用任何参考信息的半参考算法,由于半参考算法仍然需要使用参考信息,所以研究者更多的是设计无参考算法。2012年Mittal等提出了基于自然场景统计的BRISQUE[8],BRISQUE不但具有性能优势而且计算复杂度低,对无参考算法研究来说具有里程碑意义。总之,全参考算法评价准确,但参考图像一般不容易获得;半参考是全参考向无参考算法的过度,需要使用参考图像的部分信息;无参考算法不需要任何参考信息,但性能得不到保证。
根据图像失真类型,IQA算法可分为单失真(只包含一种降质类型)和多失真评价算法。近年来多失真IQA研究多于单失真,因此多失真图像质量评价成为研究热点。 Gu等[9]首先提出了多失真图像质量评估的六步法,受Challer[10]的研究启发,该工作之后引入免能量项以描述不同失真类型之间的相互作用,但是此类方法针对具体的失真类型,对未知失真类型效果并不理想。Ghadiyaram等[11]为描述失真,从一组质量相关的感知图中提取了大量统计特征,虽然该方法在自然多失真数据库上取得了最佳结果,但计算复杂度较高。Li等[12]为了刻画失真对图像带来的结构信息影响,提出了基于梯度图计算LBP加权直方图的GWH-GLBP方法,GWH-GLBP在合成的多失真数据库上性能优异,但面对失真因素复杂的自然失真图像性能略显不足。总之,从实用性角度来看,单失真质量评估算法针对只包含一种失真类型的图像设计,使用场景十分有限,现实生活中的失真图像往往包含了多种失真,并且各种失真类型之间存在相互作用,因此多失真评价方法才更加贴合实际应用。
根据是否需要训练IQA模型,图像质量评价算法有有训练和无训练之分。随着IQA研究的不断深入,人们更希望设计出泛化能力较强的无训练IQA算法。文献[13]收集了一组无失真图像的自然场景统计特征,使用多元高斯模型拟合特征参数,将拟合结果作为无失真图像的理想统计分布,失真分布与理想分布之间的距离被作为失真度量,该方法开启了无训练IQA研究的先河。文献[14]在文献[13]的基础上丰富特征表达,提出了更具竞争优势的IL-NIQE。文献[15]发现原始分辨率图像与其低通/高通版本的不相似性随着原始分辨率图像失真程度的变化而改变,据此提出一种多尺度空间下的无训练方法。文献[11]为了同时适应单失真和多失真图像质量评估,首先判断失真类型,对不同失真类型预测不同失真参数,最后聚合失真参数形成质量分数。 总之,有训练算法需要训练IQA模型,无训练算法直接输出质量分数,但无训练算法普遍存在性能瓶颈。
本文提出一种基于PMF的多失真图像质量评价算法。首先对失真图像进行降噪以去除冗余信息影响,然后计算降噪图像的平均对比归一化系数(Mean Subtracted Contrast Normalized coefficients, MSCN),从中筛选信息保真度较高的低频MSCN系数块,并使用PMF方法对其参考块进行估计。失真系数块和估计的参考块符合一定的统计分布,因此对二者的MSCN系数进行曲线拟合以提取统计特征。为降低特征维度,对提取的块特征进行了特征聚合,最后使用聚合特征构建出描述失真图像信息损失的特征向量,借助SVR完成IQA模型的训练,图 1给出了算法流程图。本文方法没有使用参考图像,但需要SVR训练IQA模型,因此是一种基于训练的无参考图像质量评估算法。
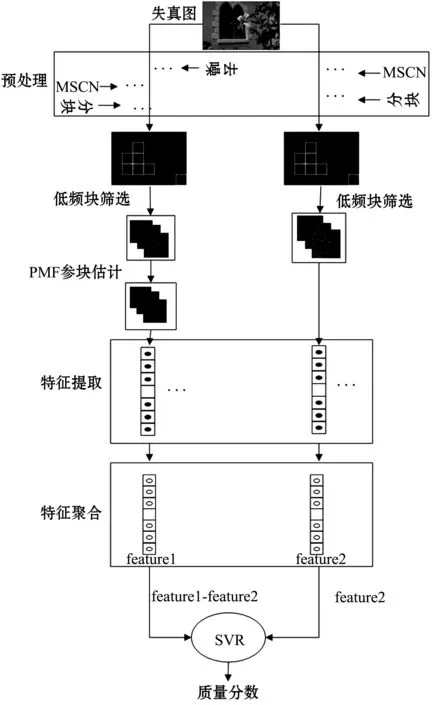
图1 算法流程图
1 相关工作
1.1 图像平均对比归一化系数MSCN
Mittal在文献[8]中提出了MSCN的概念,给定一幅图像X,其MSCN系数通过下式给出:
(1)
其中:
(2)
(3)
式中:x∈{1,2,…,H},j∈{1,2,…,W}是图像像素索引,H和W分别表示图像的高度和宽度;ω={ωk,l|k=-K,…,K,l=-L,…,L}是高斯加权窗口;X(x,y)表示图像X在空间域坐标(x,y)点的像素值;C是一个很小的常数,以防止除数为零;局部均值χ(x,y)以及标准差ζ(x,y)分别用来表示图像X在(x,y)点的平均亮度以及对比度。


(4)
(5)
本文定义低频MSCN系数取值范围在[ϑ-2δ,ϑ+2δ],否则为高频MSCN系数。
1.2 概率矩阵分解PMF
Ruslan Salakhutdinov在文献[17]中提出了PMF方法,给定观测矩阵R,R∈RQ×S,存在一个较小的潜变量D,使得R=UT×V,其中U∈RD×Q,V∈RD×S,U、V为未知的低维矩阵,R为秩不超过D的低秩矩阵。R中的观测值受系统噪音影响且存在大量的缺失值,因此需要根据已有观测数据计算合适的U、V对R中的缺失值进行预测。为求解上述矩阵分解问题,假设R的条件概率分布如下:
(6)

(7)
(8)
根据最大化后验原则:

(9)
取对数得:
(10)

(11)
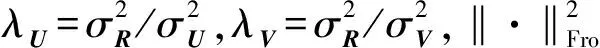
2 基本动机
高清无失真的参考图像通常被认为不含有任何失真类型,但现实中的失真图像往往受多种失真因素影响,相比参考图像而言,这些失真类型对图像造成的失真效果可以概括为两类:① 造成了信息损失;② 增加了冗余信息[19]。比如模糊通常造成细节信息的损失,噪声导致冗余信息的增加,Jpeg压缩引入了模糊和块效应,块效应造成的一系列不连续边缘点也可以视为一种冗余噪声。本文打算去除冗余信息影响,得到仅包含信息损失的图像并从中估计其已损失的信息,这与PMF的思想恰好一致。PMF假设观测矩阵存在大量信息缺失,通过矩阵分解方法可以预测缺失信息。
研究表明图像被失真破坏后,其MSCN系数受到影响[8],图 2证实了这种现象。图 2(a)为一幅参考图像,图 2(b)为图 2(a)经过噪声和模糊破坏的多失真图像,图 2(d)为图 2(a)和图 2(b)的MSCN系数分布,从图 2(d)可以看出参考图像的MSCN系数被改变,但难以辨别哪一部分是由信息损失造成的影响。因此,对图 2(c)去除了图 2(b)中叠加的冗余噪声,得到仅受模糊影响的信息损失图像,为了从信息损失图像MSCN系数中寻找信息损失较少的系数,以便使用这些系数进行精确的估计,我们将信息损失图像的MSCN系数划分成低频和高频进行详细分析。
图 2(e)为信息损失图像和参考图像高频MSCN系数分布,图 2(f)为低频MSCN系数分布,其中高频系数是指在[-2δ,2δ]之外的系数,低频与之相反,δ为信息损失图像MSCN系数标准差。为了便于观察,图 2(e)中的高频系数取了绝对值,通过采用互信作为度量,图 2(e)中两个分布的互信息为0.13,图 2(f)中互信息为0.72,这证实了信息损失图像低频MSCN系数信息保真度较高。


(d) 参考图像和多失真图像MSCN

(e) 参考图像和信息损失图像高频MSCNP

(f) 参考图像和信息损失图像低频MSCN图2 图像失真对MSCN的影响
综上,一个自然的想法就是从信息损失图像中寻找信息保真度较高的低频MSCN系数对其参考MSCN系数进行估计,然后根据失真图像MSCN系数相对于其参考MSCN系数信息损失程度对图像进行质量评估。
3 方法设计
3.1 预处理
多失真图像中包含的冗余噪声信息可以通过降噪去除,但降噪过程不能引入新的低频成份,否则信息损失图像原本的低频MSCN系数受到影响。经查阅文献,近年来优秀的去噪方法BM3D[20]满足要求,BM3D结合空域和频域去噪方法,在去除噪声的同时对图像原有的低频系数保留较好,能够取得不错的效果,因此本文在去噪步骤采用BM3D算法。
去噪后得到信息损失图像,信息损失图像的MSCN系数采用式(1)计算,从式(1)可以看出信息损失图像的MSCN系数和失真图像具有相同的尺寸,对整个MSCN系数直接使用PMF方法存在高维分解困难,并且计算复杂度较高,所以采用分块估计方法。
3.2 PMF估计参考块
(12)
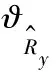


图3 PMF对参考块的估计效果
3.3 特征提取
自然图像MSCN系数分布呈近高斯状,当被失真影响时,MSCN分布曲线发生扭曲,不同的失真类型产生不同形状的扭曲。基于上述事实,我们采用广义高斯分布(Generalized Gaussian Distribution,GGD)对MSCN进行拟合,获取拟合参数作为特征表示。零均值的GGD的概率密度函数如下:
(13)
式中:α为GGD的形状参数,ρ2为方差;Γ(a)和β函数的定义如下:
(14)

(15)
GGD拟合完成后获得两个特征参数,分别是α和ρ2。
简单地采用GGD形状参数α和方差ρ2还不足以描述形态各异的MSCN分布,因此对四个方向的MSCN系数还分别做了非对称广义高斯分布(Asymmetric Generalized Gaussian Distribution,AGGD)拟合。四个方向定义如下:
Hr(x,y)=I(x,y)I(x,y+1)
(16)
Vr(x,y)=I(x,y)I(x+1,y)
(17)
Dr1(x,y)=I(x,y)I(x+1,y+1)
(18)
Dr2(x,y)=I(x,y)I(x+1,y-1)
(19)
式中:I为待拟合MSCN系数矩阵,I(x,y)表示坐标为(x,y)处的系数,水平、垂直、主对角和副对角方向(x,y)位置的系数Hr(x,y)、Vr(x,y)、Dr1(x,y)和Dr2(x,y)通过上述四个公式获得。使用的拟合函数AGGD概率密度如下:
(20)
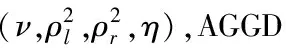
3.4 特征池化

(21)
(22)

vX=[f(X),f(Y*)-f(X)]
(23)
3.5 IQA模型训练
基于训练的图像质量评价方法需要训练IQA模型,支持向量回归SVR常被用来作为训练工具[24-25]。IQA模型获取分为两个阶段,即训练阶段和测试阶段,训练阶段使用SVR从训练样本学习IQA模型,测试阶段使用训练阶段获得的IQA模型进行质量分数预测。
标准SVR具有如下的损失函数:
(24)
subject towTφ(xi)+b-yi≤∈+ξi

其中:xi表示第i个样本的特征向量,yi表示第i个样本的标签,常量C>0,∈>0,K(xi,xj)表示核函数。
K(xi,xj)=φ(xi)Tφ(xj)
(25)
一般采用径向基核函数RBF(Radial Basis Function):
K(xi,xj)=exp(-γ‖xi-xj‖2)
(26)
在我们的训练过程,特征聚合阶段获取的第i幅图像的特征向量vXi对应于标准SVR的xi,失真图像的DMOS或者MOS值对应于标准SVR的yi。本文采用LibSVM[26]中实现的SVR,选择RBF作为核函数完成上述IQA模型的训练。
4 实 验
4.1 实验数据库和评价标准
著名的多失真图像质量评价数据集有MLIVE[27]、MDID2013[28]和The Live Challenge Database[11]。MLIVE总共有465幅图像,其中参考图像15幅,其余450幅是这15幅图像的降质版本。MD总共分为两个Part。Part1有225幅降质图像,它是由15幅参考图像先进行高斯模糊,后使用Jpeg压缩产生。Part2也有225幅图像,它是由15幅参考图像先进行高斯模糊,后叠加高斯白噪声产生。MDID2013包含了348幅图像,其中参考图像12幅,其余336幅为失真图像,失真图像是由参考图像依次经过高斯模糊,JPEG压缩和高斯白噪声破坏所得,MDID2013和MLIVE最重要的区别是MDID2013每幅失真图像包含了三种失真类型,而MLIVE每幅失真图像仅包含两种失真类型。The Live Challenge Database是第一个真实失真图像质量评价数据库,它包含了1 169幅失真图像,不同于前两个质量评价数据库,它没有参考图像,而且The Live Challenge Database的失真图像都来自于自然界,属于自然退化导致的失真,失真图像包含了复杂的降质类型,因此The Live Challenge Database对图像质量评价算法提出了新的挑战。
所有的图像质量评价数据库都提供了失真图像的质量分数值,质量分数是由图像方面的专家经过合理的打分程序给出的MOS或者DMOS分数,MOS分数值越大,图像越清晰,视觉效果越好,反之亦然,需要注意的是MOS和DMOS的含义恰好相反。通过计算IQA算法给出的图像质量分数和图像专家给出的MOS或DMOS分数值之间的相关性,就可以衡量图像质量评价算法的性能。
IQA算法常用性能评价标准有斯皮尔曼等级相关系数、皮尔逊线性相关系数和均方根误差,后两个评价标准需要将算法给出的质量分数经过非线性拟合再进行计算,常用的5参数拟合函数如下:
(27)
式中:{γ1,γ2,γ3,γ4,γ5}为拟合参数,不同的质量评价数据库有不同的拟合参数,需要训练获得。
4.2 实验细节
基于训练的IQA算法需要将图像库划分为训练集和测试集,通常80%的图像用来训练IQA模型,20%的图像用来测试,训练集和测试集不得重叠。本文对各个图像质量评价数据库的测试结果遵守上述实验原则,为了全面测试IQA的泛化能力,我们每一次测试都将数据库按照80%训练,20%测试进行划分,并且计算SROCC、PLCC、RMSE三个指标,实验结果最终报告的是三种指标100次的平均值。
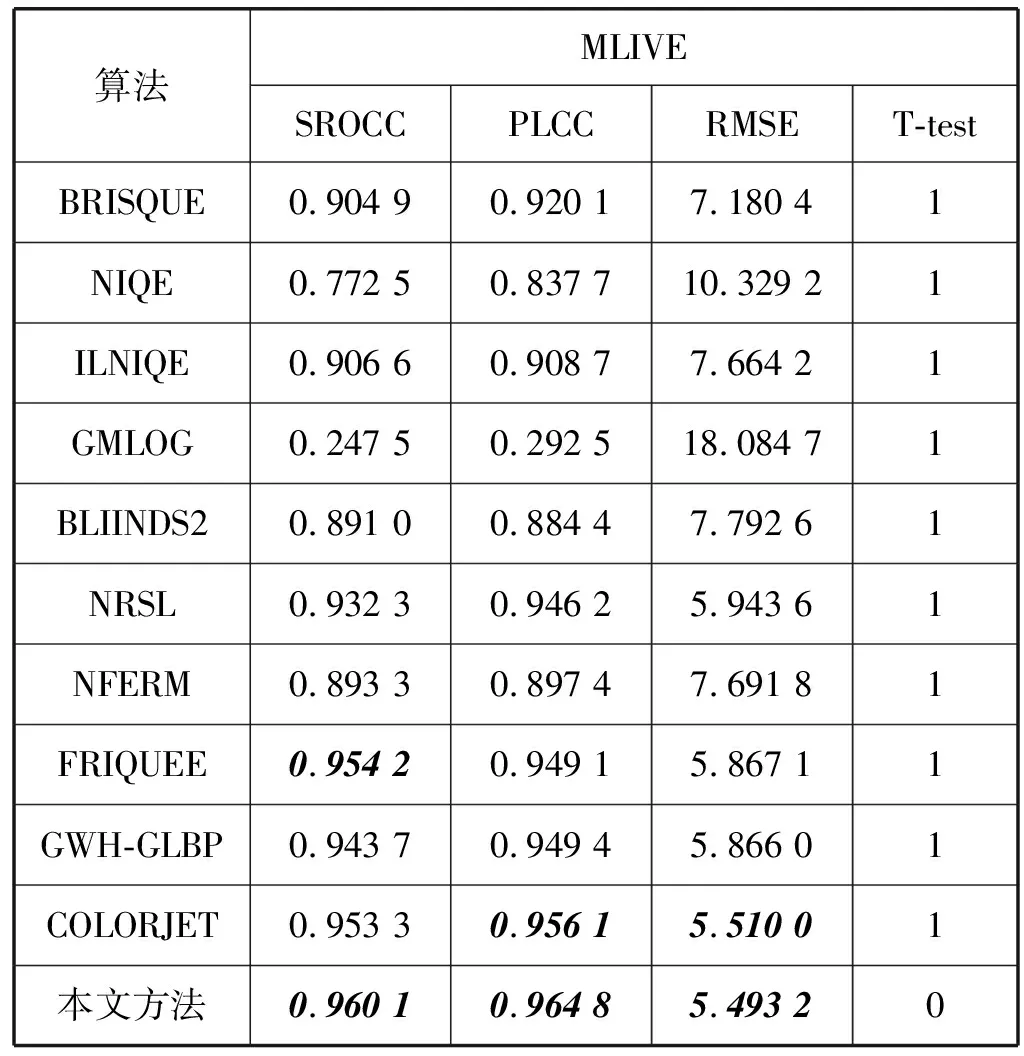
另外,本文需要讨论的是算法中的3个可变参数,它们分别是分块的大小Q和S,PMF方法分解潜变量D。在我们的实现中取Q=S, 所以可变参数只有Q和D, 并且PMF分解潜变量D< 图4 PMF分解潜变量D值选择 经典的盲图像质量评价算法有BRISQUE[8]、NIQE[13]、ILNIQE[14]、GMLOG[29]、BLIINDS2[30]、GWH-GLBP[12]、NRSL[31]、FRIQUEE[11]、NFERM[32]和COLORJET[33]。其中BRISQUE、NIQE、ILNIQE、GMLOG、BLIINDS2、NRSL和NFERM为单失真评价算法,GWH-GLBP、FRIQUEE和COLORJET为多失真评价算法。表1-表3给出了本文算法和其他10种图像质量评价算法在MLIVE、MDID2013和The Live Challenge Database上的性能比较结果。 表1 MLIVE数据库性能比较结果 表2 MDID2013数据库性能比较结果 表3 The Live Challenge Database数据库性能比较结果 实验结果对SROCC、PLCC和RMSE各自排名前二的算法采用斜黑体表示,从实验结果可以看出:本文方法在MLIVE数据库上超过了所有算法,SROCC超出近年来多失真经典算法GWH-GLBP1.7%,相比最新的FRIQUEE也表现出更好的性能。所有算法在MDID2013数据库上的测试性能都有所下降,因为MDID2013图像失真类型为Blur+Noise+Jpeg,比MLIVE失真要复杂,但本文方法仍然保持了良好的性能优势,各项指标均排据第一。The Live Challenge Database上所有算法性能急剧下降,其主要原因是The Live Challenge Database为自然降质数据集,完全是由自然因素导致的图像降质,不再是可预测的常见降质类型。虽然如此,本文方法和经典算法相比依然性能靠前,比GWH-GLBP提高了16%,比在前两个数据库上性能较好的COLORJET提高了8.3%。FRIQUEE比本文方法出色是因为它从各种感知相关的映射图上提取了多达560维的特征向量(本文仅36维),它能捕捉的失真更加广泛,但它比本文方法在时间复杂度上要高出很多。 为了进一步说明我们算法的优越性,表1-表3还给出了100次SROCC的T检验的结果,T检验的备择假设是本文方法的平均SROCC相关性大于对比算法,T检验结果“1”表示以95%的置信度断定本文算法平均SROCC相关性大于比较算法,“0”表示两种算法性能在统计上不可区分。T检验结果表明了我们提出的算法在性能上比其他竞争算法具有更好的稳定性。 本文提出了一种基于概率矩阵分解的多失真图像质量评估算法。从估计参考图像的角度出发,首先从多失真图像中去除冗余信息影响,得到信息损失图像,从中分离其信息保真度较高的低频MSCN系数块。使用PMF方法对低频MSCN系数块对应的参考块进行估计,通过对失真系数块和估计的参考块抽取统计特征,构建失真图像的特征描述。最后使用SVR完成质量分数预测模型的训练。三个公开数据库的实验结果证明了本文方法的有效性,同时证明本文提出的方法与人眼视觉质量评价具有更好的一致性。
4.3 实验结果


5 结 语
猜你喜欢
今日农业(2022年15期)2022-09-20
小天使·二年级语数英综合(2019年10期)2019-11-08
娃娃乐园·3-7岁综合智能(2017年9期)2018-02-01
娃娃乐园·3-7岁综合智能(2017年8期)2018-02-01
娃娃乐园·3-7岁综合智能(2017年7期)2018-02-01
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
读者·校园版(2015年19期)2015-05-14
