
基于张量分解的跨领域推荐方法∗
2019-07-31 09:54孙华成王永利陈广生
计算机与数字工程 2019年7期
孙华成 王永利 赵 亮 陈广生
(1.南京理工大学计算机科学与工程学院 南京 210094)(2.华电能源股份有限公司佳木斯热电厂 佳木斯 154000)
1 引言
推荐系统越来越受欢迎,因为可以帮助用户找到感兴趣的项目(比如电影、书籍、音乐等)所以可以缓解信息过载问题。一些通用的推荐系统比如Amazon,LastFm,MovieLens。这些系统推荐在线商品,电影和音乐给用户。在过去的十几年,很多研究人员开发了一些推荐系统[1~2],但是仍然有些挑战比如冷启动[3~5]和数据稀疏性问题[6]。
大量推荐系统提供的推荐结果只是单领域的,事实上,在不同的领域之间存在很多依赖和相关关系。一个领域的信息可以通过转化到其他领域提高推荐效果,而不是单纯的独立考虑。比如,如果一些用户喜欢歌手的歌(音乐作为源领域),一些电影(作为目标领域)由该歌手出演的可以推荐该用户。这样,可以解决目标领域冷启动问题[7],和数据稀疏性问题[8]。因此,跨领域推荐最近在推荐系统领域成为热门研究。
目前相关的跨领域推荐通常需要不同领域的评分信息共享用户和项目,现实场景中很少存在。本文专注于没有共同用户和项目的跨领域推荐系统研究。本文提出了一种跨领域推荐方法,可以利用不同领域之间用户对项目的偏好即评分模式构建关联。本文首先从辅助领域进行聚类取出冗余信息,利用聚类后的信息构建张量,提取评分模式。下一步,将从源领域获取的评分模式迁移到目标领域,填补目标领域空缺值。最终,本文利用填补空缺值后的评分张量推荐。
本文的主要贡献如下:
1)在聚类基础上进行张量分解提取评分模式。
2)提出了一种推荐方法利用辅助领域评分模式迁移学习至目标领域。
3)使用相关实验验证方法的可行性。
2 相关工作
跨领域推荐已经成为解决冷启动和减轻稀疏性问题的重要手段。一些研究人员调研了跨领域的相关工作如文献[9]中定义的,这里有两个跨领域推荐的任务。
第一个任务就是利用源领域的知识提高目标领域项目推荐质量。Li[10]等提出了一种跨领域协同滤波降低稀疏性。他们通过聚类压缩得到用户项目间的评分模式,然后他们以codebook的形式将其他领域的知识转移到目标领域。Kumar[11~12]等提出了一种跨领域话题模型来缓解数据稀疏性问题。他们假设每个领域有N个不同的话题,每个用户在这些话题服从某种分布。利用话题匹配进行跨领域协同推荐而不是传统的根据共享作者匹配。Karatzoglou[13]等提出了一种使用机器学习的方法将稠密的源领域知识迁移到稀疏的目标领域用来解决数据稀疏问题的方法。他们开发了一种迁移学习技术从包含丰富数据的多个领域提取知识,然后对稀疏目标领域生成推荐。这项技术学习了相关性和线性整合所有源领域的评分模式到一个模型中使得可以预测目标领域未知的评分模式。Enrich[14]等提出了使用用户标签作为不同领域之间的桥梁,他们从源领域中学习用户的评分模式(例如,用户如何在源领域进行评分,这些标签和评分之间的关系)来提高目标领域的预测表现。
第二个任务就是对不同领域的项目进行联合推荐。Li[15]等提出了一种通过将多任务的评分数据池化的方式共享知识。他们创建了一种多领域共享隐含评分因子聚类评分矩阵,然后这个共享评分矩阵被扩展为通用聚类评分模型,称为评分矩阵生成模型。任何相关用户的评分矩阵可以通过这个生成模型和user-item 联合混合模型进行生成或者预测。Shi[16]等提出了一种标签推导的协同滤波跨领域推荐。他们利用用户产生的标签作为跨领域的纽带。这些标签可以用来计算跨领域用户之间的相似性和项目之间的相似性,并且这种相似性被整合到一个矩阵分解模型可用于矩阵分解过程从而提高推荐的效果。Gao[17]等提出了一种聚类的潜在因子模型(CLFM)基于联合非负矩阵框架。跟文献[10]不同的是,他们使用CLFM 不只是学习多领域的共享评分模式,还从每个包含重要信息的领域学习特定领域聚类评分模式。Hu[18]提出了对于user-item-domain进行建模三元关系作为一个三阶张量。然后,他们利用标准的CANDECOMP/PARAFAC(CP)张量分解模型来提取不同领域用户因子和项目因子之间的关系,这样就可以预测每个领域的评分了。
本文专注于第一种跨领域推荐任务。通过跨领域迁移多维评分模式来解决第一个任务。
2.1 问题与定义
跨领域推荐目前主要解决的问题就是没有共享覆盖信息如文献[19]的情况,本文借助于张量分解提取两个领域的评分模式再结合迁移模式的跨领域方法来解决稀疏性问题和冷启动问题[20]。本节主要介绍张量分解和跨领域迁移学习的相关定义[21~23]。
2.2 张量基础知识
形式上,张量是个多维矩阵。一个张量的阶数就是维度的数目,也称为模式。本文中张量用粗体脚本字母表示,比如X 。矩阵使用粗体大写字母表示,如X 。向量使用粗体小写字母表示,比如x 。元素使用小写字母下标表示,比如xi,j,k。矩阵 X 的第i 行表示为 Xi,*,第 j 列表示为 X*,j,元素(i,j)表示为 Xi,j。
定义 1(矩阵展开,matrix unfolding)张量的模展开操作就是将张量映射成矩阵形式,比如X(2)表示 将 XI×J×K→ XJ×(IK)。 一 个 N 阶 张 量 A 设 为A ∊ RI1…IN,拥有元素a,以三阶张量为例就需i1,…,iN要在三个方向上模展卡 A∊RI1×(I2I3),A∊ RI2×( I2I3),(1)(2)A(3)∊R( I1I2)×I3这 里 的 A(1),A(2),A(3)就 是 A 的mode-1,mod e-2,mode-3 展开。

图1 张量mode-n矩阵展开
定义 2(模式乘积,mode product)n 模式乘积为张量 A ∊ RI1×I2×…×IN,与矩阵 U ∊ RJn×In在第n 模式上的乘积,表示为 A×nU ,结果大小为RI1×…×Jn×…×IN,简称模乘。并且模乘满足交换律和结合律[23]:

2.3 张量分解
张量分解有很多种方式,本文使用的是HOSVD。高阶奇异值分解(HOSVD)是在矩阵奇异值分解(SVD)的概念上的延伸。对于一个mode-n 展开式,二维上的奇异值分解可以重写如下:

通过扩展,三阶的张量HOSVD可以写成如下:
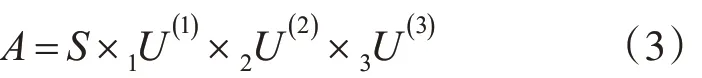
HOSVD 分解可以将N 阶张量分解为一个核心张量和N 个因子矩阵乘积的形式如图1。图1 中是一个三阶张量分解一个张量核和三个因子矩阵,这个张量核心S 可以看作是对原始张量A 的压缩。

图2 三阶张量的HOSVD分解图示
当因子矩阵确定时,核心张量可以通过张量和因子矩阵计算得到:
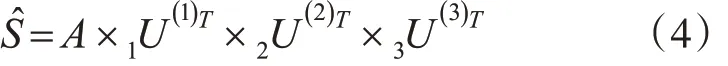
再使用式(1)可以得到张量A 的低秩近似,达到填补空缺值和数据压缩的效果。
2.4 张量分解用于推荐
对于含有标签的评分预测系统,可以定义为如下关系结构F ≔(U ,I,T,Y )。
1)U,I,T 非空有限集合,元素分别称为用户,项目,标签。
2)Y 是三元组的可观测关系,Y ⊆U×I×T 。
3)三元组(u,i,Tu,i)表示一个用户对于一个项目的标签这里的 u ∊U,i ∊I 和一个非空集合Tu,i≔{t ∊ T|(u ,i,t )∊Y}。
Y 表示用户,项目与标签的三元关系,可以用二值张量表示A=(au,i,t) ∊ R|U|×|I|×|T|,这里有标签的值为1缺失值为0。
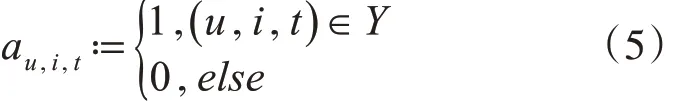
此时,张量分解表示为

HOSVD[22]的基础思想就是最小化估计误差,可以利用均方差做为优化函数:

当参数优化后,可以利用下面公式进行预测推荐:
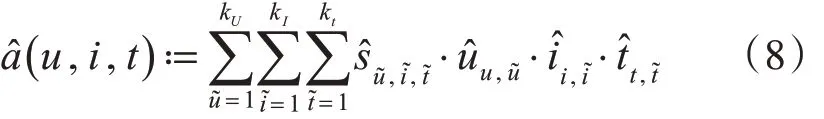
2.5 跨领域基础知识

表2 本节用到的符号表
在跨领域迁移学习方面目前公认的有四种不同的跨领域情景,如图3。

图3 跨领域情景
1)用户重叠。这里有一些用户跨越不同领域而且这些用户在两个领域都有评分,比如UST≠Ø。
2)项目重叠。这里有一些项目跨越不同领域而且这些项目在两个领域都被评分过如IST≠Ø。
3)全重叠。这两个领域同时有重叠的用户和项目,如UST≠Ø and IST≠Ø 。
4)无重叠。就是在两个领域中既没有用户重叠也没有项目重叠如,UST=Ø and IST=Ø。
任何的协同滤波算法可以应用在前三个场景来解决跨领域问题。大体上这些场景下的跨领域问题通过将两个领域的评分信息整合到统一的数据集使其转化为单领域。但是,最后一个场景由于缺少共有用户和项目所以很少被解决。下一步,我们将主要集中在最后一种情境下的跨领域推荐,跨领域的推荐目前公认的分为两类:
1)整合知识。知识从多个源领域被整合到目标领域。
合并用户偏好。将用户的偏好进行整合,如评分、标签、交易记录等。
调和用户建模数据。整合的知识来自用户建模数据如用户相似性和用户领域。
组合推荐。整合的知识是由单领域推荐组合,如评分评估和评分概率分布。
2)知识迁移与关联,知识通过关联或者迁移来进行推荐。
关联领域。通过共享知识关联领域。如项目属性、关联规则、语义网络和领域间相关性。
共享潜在特征。源领域和目标领域通过潜在的特征进行关联。
迁移评分模式。源领域显式或隐式的评分模式用于目标领域。

图4 跨领域推荐分类
当和矩阵分解或张量分解结合时一般使用共享潜在特征或迁移评分模式。
2.6 跨领域知识迁移
潜在因子模型是协同滤波(CF)领域比较流行的方法。这些模型中的用户偏好和项目属性通常都非常的稀疏,可以通过数据中潜在因子进行压缩表示。在基于潜在因子分析的协同滤波系统中,潜在的用户偏好和项目属性可以更好地捕捉和匹配。在潜在因子迁移学习方面有两种方法:适应模型和联合模型。前者是将源领域学习到的潜在因子,整合到目标领域的推荐模型中。后者是将两个领域整合来学习出潜在因子。
除了通过共享用户或项目的潜在因子还有另一种主流的方式用于知识迁移。在很多现实场景中,即使用户和项目不同,相近的领域也会有相似的用户偏好与流行度。因此潜在关联可以是一组用户对一组项目的偏好,称为评分模式。可以将这个评分模式里结果两个领域间的桥梁,这样知识的迁移可以不需要适配或整合。本文提出的方法就是基于从源领域提取出评分模式迁移至目标领域进行推荐。如图6 所示,图中展示的源领域和目标领域对应的是用户项目的评分矩阵,模式提取是通过张量分解完成的,对应本文的方法就是利用张量分解提取三元关系模式,保留更多的信息达到提高准确率的效果。
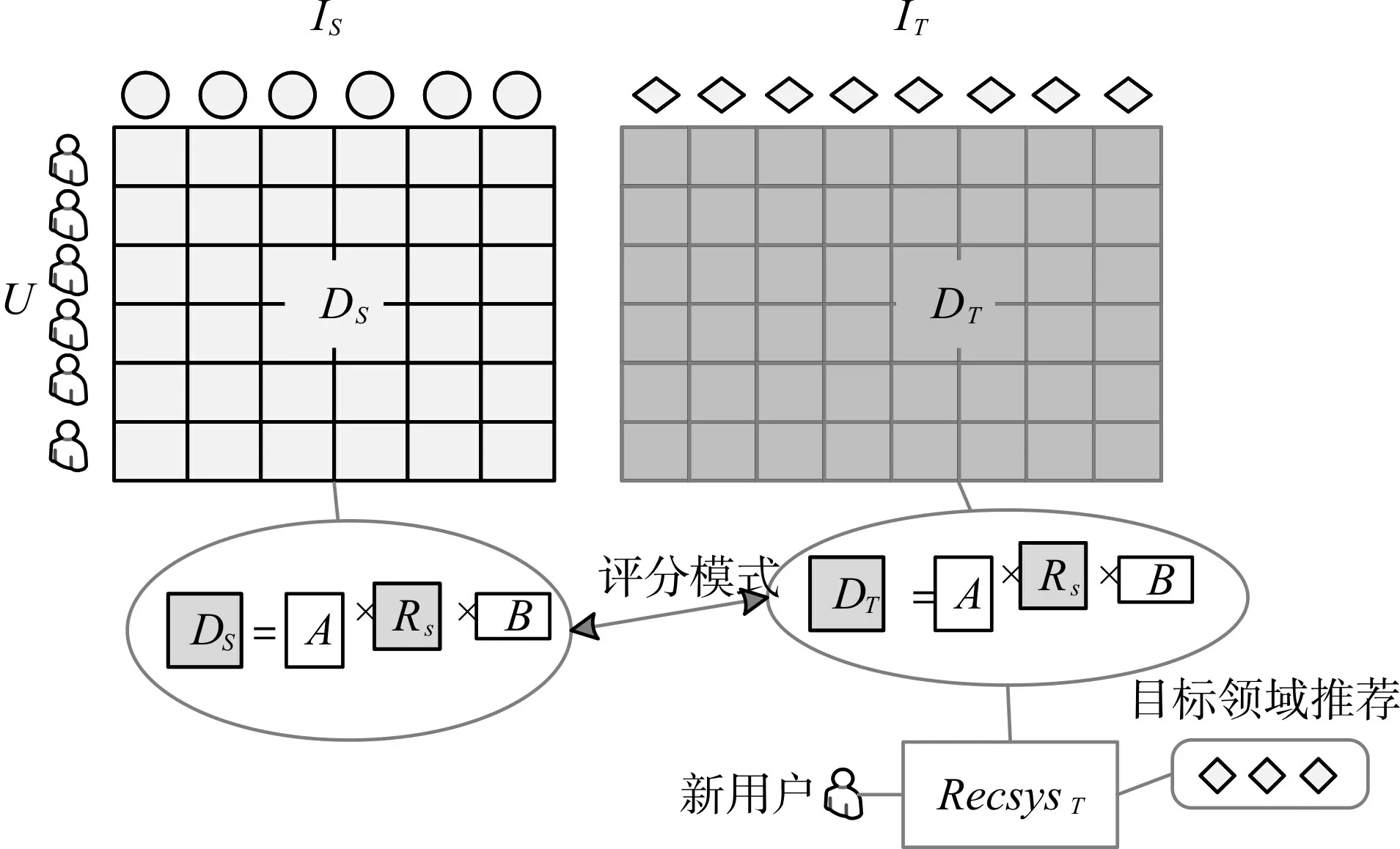
图5 共享评分模式的跨领域推荐
3 基于张量分解跨领域推荐算法
本文提出的方法张量评分模式跨领域迁移主要分为两个阶段,第一阶段从辅助领域提取出聚类后评分模式,第二阶段将第一阶段的评分模式迁移到目标领域填补目标领域的空缺值。
3.1 评分模式提取
在协同过滤系统中,相同偏好的用户和拥有相似属性的项目行为表现上是相似的。因此可以将用户和项目进行聚类分组,聚类后的评分张量只包含了用户和项目的簇信息很好地去除原评分张量的冗余信息。在此基础上,只需要保留聚类的ID无需考虑其他信息就可以表示原评分张量。
定义3(评分模式,RatingKernel)。RatingKernel 是一个大小为kU×kI×kT的张量,压缩表示原评分张量上kU个用户聚类和kI个项目聚类和kT个标签聚类上的聚类层次上的评分模式。类比文献[10]中的codebook,不同的是本文的评分模式基于张量核,保留更多信息,并且在模式提取和迁移方面适用范围更广。
理想情况下,如果user/item/tag 在同一个簇中是相同的,只需要从user/item/tag 簇中选择一个user/item/tag 对即可构建RatingKernel。但是,在现实情况下,同一个簇中的user/item/tag 不可能完全相同。普遍的做法是选择每个簇的聚类中心来表示该簇。这种情况下,需要同时对评分张量中的第一维(user)、第二维(item)和第三维(tag)进行聚类。对于RatingKernel 的构建,只需要保留用户和项目的聚类编号,这种情况下就可以选择任意的聚类算法。辅助评分张量Xaux可以分解如下:
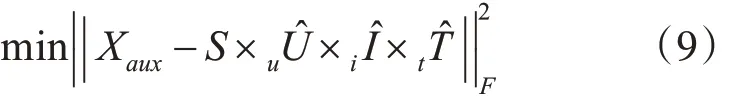
当前用户/项目的聚类编号表示形式,U、I和T不能表示user/item/tag 的字面意思。为了简化,本文中使用二值数据表示U,I,T ,通过设置每行非负元素为1其余为0。这些来自辅助评分矩阵的二值user/item/tag 聚类编号记为Uaux、Iaux和Taux。
构建评分模式S 的方式如下:

算法1 提取评分模式
Input:The initial tensor Xaux∊ RI1×I2×I3with user,tag,and item dimensions.
kU,kIand kT:The approximate tensor Xˆauxleft leading eigenvectors of each dimension,respectively。
Output:S
1:Initialize core tensor S and left singular vectorsof A1,A2andA3,respectively。
2:repeat
3:S=Xaux×
9:return S
算法1 第3 行张量核与第4 行计算近似张量的的复杂度相同为O(I )。算法 1 第 5、6、7 行为i每次循环过程中SVD 展开,复杂度为O(I1+I2+I3) ,所以整体复杂度为O(T (2Π1Ii+I1+I2+I3) ),T 表示迭代次数,几次迭代即可收敛。因此可以多次随机初始化获取更优的局部最小值。由于张量维度远远大于共享模式的维度,近似记为O(TIi),取决于张量维度。
剩余的任务是选择user/item/tag 的聚类数目kU、kI和kT。聚类数目即隐藏因子数目过多会包含冗余信息容易产生过拟合,较高的特征维度会增加计算复杂度。聚类的数目过少时,构建user/item/tag 数据不足,导致算法丢失过多有效信息。因此选择合适的RatingKernel大小不仅需要充分压缩以便计算也能充分表示大部分原信息,实验部分会针对实验场景验证聚类数目即隐藏因子数目的影响。
3.2 评分模式迁移
在获取评分模式S 之后,可以将评分模式从Xaux迁移到Xtgt假设辅助领域任务中的user/item/tag 类簇与目标领域任务之间存在隐含关系,Xtgt可以通过扩展评分模式重构出来,例如,通过评分模式中3 维矩阵因子作为基底组合。评分模式中,表示 Xtgt中的user/item/tag 组合行为类似Xaux中 user/item/tag 类簇原型。
Xtgt的重构过程就是将RatingKernel 扩展,因为这样可以减少观察评分Xtgt与重构评分张量之间在损失函数上(本文使用的平方损失函数)的差异。这里,我们应用大小等同于Xtgt的二值权重矩阵W 来遮盖未观察到的元素,当[ ]Xtgtijk已评分Wijk=1,否则Wijk=0 。最后,目标函数中只包括Xtgt中观察到的元素的平方差。
类比 MF(Matrix Factorization)方法,定义损失函数如下:

直接最小化损失函数会导致过拟合,因此考虑目标函数中添加正则项,对于给定的矩阵因子Utgt,Itgt,Ttgt的F范数正则项表示如下:
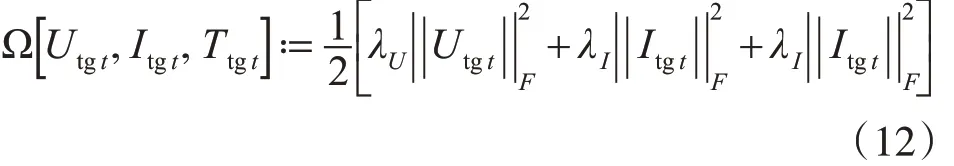
添加正则项后的目标函数为
算法2 迁移评分模式
Input Xtgt∊ Rp×q×r, kU,kI,kT,S
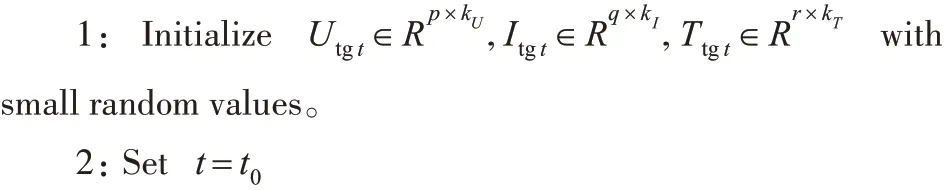

对于目标函数的优化,为了面对不断增长的数据集时能尽快收敛使用随机梯度下降(SGD)进行优化。
算法2 中第5 行求解近似张量复杂度近似为O( )
pqr ,第6、7、8 行使用的是随机梯度下降方法,每遍历一个元素更新一次复杂度为O( )pkU+qkI+rkT,所以可以在一次元素遍历的过程中完成。 因此总体的计算复杂度O( )pqr(pqr+pkU+qkI+rkT) ,因为算法一次遍历即可完成,所以多次实验取均值。
目标函数的值表示的是目标领域和辅助领域相关性。值越小,两者的评分模式越相关。相比较而言,较大的值以为弱相关性导致了负迁移。获取填补空缺值后的推荐函数利用填补空缺值后的评分张量进行推荐。
对于目标函数的优化,为了面对不断增长的数据集时能尽快收敛使用随机梯度下降(SGD)进行优化。
算法2 中第5 行求解近似张量复杂度近似为O(p qr ),第6、7、8 行使用的是随机梯度下降方法,每遍历一个元素更新一次复杂度为O(p kU+qkI+rkT),所以可以在一次元素遍历的过程中完成。 因此总体的计算复杂度O(p qr(pqr+pkU+qkI+rkT)) ,因为算法一次遍历即可完成,所以多次实验取均值。
目标函数的值表示的是目标领域和辅助领域相关性。值越小,两者的评分模式越相关。相比较而言,较大的值意味着弱相关性导致了负迁移。获取填补空缺值后的推荐函数利用填补空缺值后的评分张量进行推荐。
4 实验
为了验证本文所提出的张量分解评分模式迁移模型的高效性,将进行一组大范围实验,验证在三个数据集上的表现,同时与几个先进的推荐方法进行比较。本实验拟从MAE(Mean Absolute Error,平均绝对误差)作为衡量标准来评估算法的性能。我们利用Matlab语言实现了本文算法,实验使用的是实验室集群环境如表3所示。

表3 集群实验环境
4.1 数据集
我们基于下面三个公用的真实数据集进行试验评估:MovieLens 数据集,含有 270,000 个用户、45,000 部电影和超过26,000,000 个评分数据(取值范围 1~5 分),750,000 个标签;EachMovie 数据集,含有 72916 个用户、1628 部电影和超过 2,811,983 个评分数据(取值范围1~6 分,本文将其映射到 1~5 分);Book-Crossing 数据集,含有 278858 个用户、271379 本书和 1,149,780 个评分数据(取值范围0~9分,本文将其映射到1~5分)。实验中将上述数据集中70%的用户及其评分作为训练数据样本,剩余部分作为测试样本。针对跨领域实验,设定 EachMovie 作为源领域,MovieLens 与Book-Crossing作为目标领域的测试环境,验证跨领域推荐算法,在每个测试环境下重复实验10 次并计算其平均值作为实验结果。
本文选择了其他3 中相关算法与本文算法进行比较:
UPCC 算法,通过皮尔森相关系数对相似的用户进行推荐;
RMGM(rating-matrix generative model,评分矩阵生成模型)算法,作为当前跨领域推荐的最好算法来测试跨领域的推荐性能。
CBT(codebook transfer,密码本迁移模型)算法,一种先进的跨领域协同过滤模型,假设领域间完全共享一个评分模式,并利用聚类层次的密码本描述共享的评分模式,然后基于密码本进行跨领域的信息迁移。
TKT(Tensor kernel transfer,张量模式迁移)本文提出的方法,利用聚类层次的张量核作为共享模式进行跨领域迁移。
所有的实验测试均采用MAE(mean absolute error,平均绝对误差)作为衡量标准,MAE 的值越小,算法的性能越好。MAE的计算方式如下:

4.2 实验结果
本文通过实验对比验证本文算法在跨领域推荐中的效果。随机从每个数据集中选取300 个用户和评分作为训练集(ML300 表示从MovieLens 数据集中取300,BC300表示从Book-Crossing取300),再选200 个作为测试集。对于每个测试用户,初始化时考虑不同的评分数量,比如5、10、15 个评分记为(Given5、Given10、Given15),其他的评分用来评估。参考RMGM,CBT 等实验隐藏因子空间(即聚类数目)的设置为50,在本文中为了简化实验过程,实验中聚类后隐藏因子空间设置相同,R=kU=kI=kT=50。后面将进行实验分析R的取值。

表4 10次实验不同目标领域的MAE平均值
通过表4 结果可以看出,本文的方法效果在所有目标数据测试集上效果好于其他对比的方法。由CBT,RMGM 效果优于UPCC 可见,跨领域知识迁移可以提高推荐准确率,RMGM、CBT 提取不同领域中二维矩阵评分模式分别进行整合与迁移推荐。TKT 充分利用标签信息和用户项目的三元关系,从源领域学习到的模式在目标领域上进行学习,使其适应目标领域的一些特殊性。从试验结果可知,通过增加共享模式的隐藏因子维度可以提高推荐准确率,缓解目标领域稀疏性等问题。
R 的取值不同对算法影响不同。本文针对不同的隐藏特征空间选取进行了试验结果如图7。
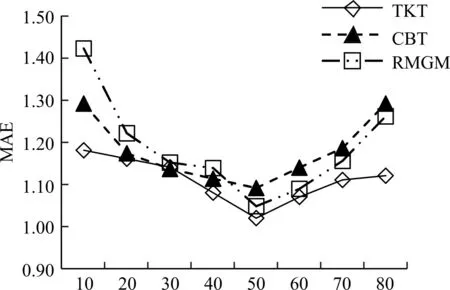
图6 隐藏因子数目对MAE的影响

图7 超参数λ 对MAE影响
从图7 可以看出,推荐结果的平均绝对误差MAE 随着隐藏因子数目先减少后增加,在因子数在50 左右达到最优效果,后面随着因子数目增多,MAE 上升可能原因是产生了过拟合导致推荐效果下降。
λ 的取值,反映了目标领域的特殊性,选取合适的λ 避免过拟合或者欠拟合。图7 是以Eachmovie 为源领域 MovieLens 为目标领域,R=50,选取Given10的实验结果。从图中可以看出较λ 越大则弱化了源领域的模式,λ 越小便会产生较大的误差,在此实验设定中,λ 取15 可以取得良好的实验结果。
5 结语
在本文中,我们提出了一种新颖的跨领域协同过滤方法,通过共享张量的评分模式进行推荐系统,可以从辅助评分张量中传递有用的知识,以补充其他一些评分稀疏的目标域。知识以评分模式的形式转移,评分模式则是通过从辅助领域中学习聚类后的用户评分模式压缩为信息丰富且紧凑的表示。因此,可以通过扩展评分模式来重构稀疏目标领域。实验结果表明,评分模式迁移可以明显优于许多最先进的方法。这可以证实,在协同过滤中,确实可以从其他域中的辅助领域获得额外的有用信息来帮助目标领域。
在未来的工作中可以使用多种优化技术优化聚类过程和张量分解的过程。可以尝试使用不同的相似性度量方法来提高推荐结果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
科技信息·学术版(2022年8期)2022-02-25
井冈山大学学报(自然科学版)(2021年4期)2021-10-13
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
北华大学学报(自然科学版)(2020年6期)2021-01-05
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
读与写·教育教学版(2017年10期)2017-11-10
互联网天地(2016年1期)2016-05-04
南都周刊(2015年4期)2015-09-10
