
基于滤波器注意力机制与特征缩放系数的动态网络剪枝
2019-09-09 03:44卢海伟夏海峰袁晓彤
小型微型计算机系统 2019年9期
卢海伟,夏海峰,袁晓彤
1(南京信息工程大学 自动化学院,南京 210044)2(江苏省大数据分析技术重点实验室,大气环境与装备技术协同创新中心,南京 210044) E-mail:761227301@qq.com
1 引 言
自Alexnet[1]夺得ISVRC2012冠军以来,深度神经网络在计算机视觉上取得了巨大的发展,尤其在图像分类、目标检测、面部识别、语义分割等多个领域取得了一系列的进展.如AlexNet[1]、VGG[2],GoogleNet[3]、ResNet[4]等许多经典卷积神经网络,随着这些神经网络复杂度的提高,一方面,深度神经网络在各种视觉任务上不断逼近精度极限;另一方面,浮点运算率和存储空间也在不断的增加.由于移动设备和嵌入式设备的资源限制,如计算能力,存储容量、电池消耗等,使得网络模型很难部署在这些移动装置上.如表1所示,随着这些经典卷积神经网络层数的增加,神经网络的计算量和存储量都在显著的增加.在深度神经网络中,卷积层占据了绝大多数的计算量,巨大的计算量消耗了大量的CPU以及GPU等硬件资源,由于这些问题的存在,模型压缩得到了快速的发展,在保证网络精度基本不变的情况下,尽可能地压缩网络模型,无论是存储量还是浮点运算率都得到了有效的减少.
剪枝是一种流行的模型压缩方法,能够有效地降低网络运算量以及存储量.早期阶段,Han等人[5]提出了迭代剪枝,其思想是不断剪枝训练收敛后的神经网络,得到一个精简的网络模型.在此基础上,Han等人[6]进一步提出对剪枝后的网络模型参数进行量化和哈夫曼编码(Huffman Coding),有效地减小了模型大小.然而,裁剪神经元连接是一种非结构化剪枝方法,难以应用于现有的硬件设备,无法得到实际的加速.针对这些问题,结构化剪枝解决了非结构化剪枝存在的局限性.
表1 不同卷积神经网络模型的对比
Table 1 Comparison of different convolutional neural network models

网 络层 数Imagenet Top5(%)存储量(MB)浮点运算率(GFLOPs)AlexNet[1]879.09223~2.5VGG[2]1690.38518~31GoogleNet[3]2293.33~44~3ResNet[4]15294.04226~23
目前,结构化剪枝能够兼容现有的硬件设备和深度学习库(BLAS),在不破坏网络结构的情况下,裁剪网络每层中的冗余滤波器.同时,在保证网络精度基本不变的前提下,搜索到最优的网络结构.Li等人[7]通过计算每层滤波器的L1范数,评价每一个滤波器的重要性.此外,Liu等人[8]在损失函数中加入每层特征缩放值的稀疏项,并根据给定的阈值裁剪每一层的滤波器.虽然这些方法最终都得到了一个精简网络,但经过本文的实验表明,只考虑网络单层的参数信息裁剪每层滤波器,并不能准确判别滤波器的重要性,神经网络损失的精度较多.针对这个问题,本文提出了一个新的剪枝准则,基于滤波器注意力机制与特征缩放系数得到滤波器的重要性函数,一方面,利用滤波器的注意力信息得到滤波器重要性值,并作为滤波器的重要性评判指标之一;另一方面,利用BN层的参数信息,每一个BN层缩放系数都对应着上一层的激活通道,因此,缩放系数作为滤波器的重要性的另一个评判指标,利用这两个评判指标精准地判定冗余滤波器,并对其进行裁剪,由第4部分实验发现,在相同剪枝率的情况下,本文的方法取得了更好的精度.
2 相关工作
模型压缩是一种减小网络复杂度的有效方式,神经网络的压缩和加速方式可以被分为以下五类:矩阵分解、结构紧凑型网络、量化、剪枝、知识蒸馏.
矩阵分解是将一个卷积层分解成几个小的有效层,用两个低秩矩阵代替卷积网络的每一层的权重矩阵.Denil等人[9]重构权重矩阵的误差,将权重矩阵分解为多个小的低秩矩阵.降低了参数的冗余性.Denton等人[10]提出了低秩近似和聚类方法分解每一层的滤波器.然而,虽然分解后的矩阵运算量减少,但是矩阵分解本身增加了巨大的计算量,训练过程依然需要花费较长的时间,占用较多的硬件资源.此外,为了减少计算量,Inception[11],GoogleNet[2],Xception[12]这些网络都采用了1×1、3×3大小的卷积核,增加了矩阵分解的难度.
结构紧凑型网络主要是设计新型的网络模型,设计更加紧凑的滤波器,减小模型的大小.Inception[11]运用大量的1×1卷积代替3×3卷积,减小了卷积层的运算量.DenseNet[13]是一种密集连接的神经网络,任意两层之间都有连接,将前面所有层的信息合并作为下一层的信息,减少了参数量.ShuffleNet[14]将1×1卷积分组并将特征通道随机打乱,增加不同通道之间的信息交流,虽然这些轻量化网络减小了网络的计算量,但仍然存在着很大的冗余性且对网络的设计要求较高.
量化是通过将高精度的模型参数转变为低精度表示,Courbariaux等人[15]将浮点权重量化为1 bit表示,极大地减少了网络模型的存储大小和运算量.然而,通过这种极少的量化位表示权重信息,使得网络精度下降较大.为了缩小量化误差,Rastegari等人[16]不仅将浮点权重和激活值都量化为1bit,而且对量化权重和激活都增加了一个缩放因子,提高了网络精度.最近,受到剪枝方法的启发,Zhou[17]提出了增量量化,将浮点权重量化为2的指数幂和0,进一步减小了模型存储量.虽然这些量化方式有效地减小了模型的计算量和存储量,但是,在训练过程中,量化后的参数往往是不可导的,这需要使用直通估计(straight-through estimator),采用近似梯度代替原梯度反向传播,因此,网络参数更新必定会存在误差,造成网络精度损失.
知识蒸馏是通过训练出一个大网络(教师网络),并在小网络(学生网络)的损失中加入大网络的输出作为指导,训练一个模型小且性能高的网络.Hinton等人[18]首次提出了知识蒸馏,并将一个小网络训练成一个高精度网络,在此基础上,Lei等人[19]运用知识蒸馏,在网络性能基本不变的情况下,得到压缩后的网络,有效地减小了网络参数量.但是,与其它压缩方法相比,这种方式训练时间较长,且只适用具有SoftMax层的神经网络中.
剪枝是一种快速且有效的模型压缩方法,裁剪掉网络中不重要的神经元或者滤波器,得到存储容量小且推理速度快的网络模型.早期,LeCun等人[20]和Hassibi等人[21]运用损失函数的 Hessian 矩阵来确定网络中的冗余连接,然而,Hessian矩阵的二阶计算本身消耗了大量的计算时间,训练时间较长.Han等人[5]提出了迭代剪枝,根据设定阈值裁剪神经元,与LeCun等人[20]的方法相比较,缩短了网络训练时间.此外,Guo等人[22]对Han等人[5]的方法进行了改进,在训练过程中,裁剪掉的神经元可以再次恢复,动态搜索最优的剪枝策略.同样,Zhou等人[23]提出了根据激活值的大小裁剪不重要的节点.然而,上述的剪枝方法都是一种非结构化剪枝,破坏了网络的原有结构,难以利用现有的深度学习库加速和现有的硬件支持.与其相比,结构化剪枝是一种有效且实用性高的方法,Jin等人[24]提出了对神经网络结构化剪枝后再进行权重剪枝,进一步压缩网络模型.Li等人[7]利用L1范数准则和层敏感度分析方法逐层裁剪冗余滤波器.此外,He等人[25]通过优化网络每层输出的LASSO误差选择冗余滤波器.然而,上述的这些结构性剪枝方法都仅仅利用了单层的参数信息选择冗余滤波器,且没有利用网络参数更新的动态性,灵活地选取冗余滤波器,此外,滤波器本身参数存在噪声,这些方法没有缩小干扰信息的影响,影响了冗余滤波器的正确选择.
基于以上的讨论,本文提出了一种基于滤波器注意力机制与特征缩放系数的剪枝准则,利用卷积层和BN层这两层的参数信息更加精准地选取冗余滤波器,并对其裁剪,并且首次将注意力图运用到滤波器上,通过提出的注意力函数得到滤波器的注意力图,将注意力集中在滤波器中的重要参数,缩小干扰信息的影响,得到滤波器的一级重要性判断值.另外,以BN层的缩放系数作为滤波器的二级重要性判断值,联合利用两级滤波器重要性值,不但提高了选择冗余滤波器的准确性,而且在残差网络这种冗余性较低的网络框架上表现出有效性.
3 基于滤波器注意力与特征缩放系数的剪枝方法
在不破坏网络结构的情况下,减少CNN的滤波器数目能够有效地减少网络的参数量和运算量,加速网络的推理速度.随着深度神经网络的发展,卷积层和BN层被广泛应用于卷积神经网络当中,一方面,相对于全连接层,卷积层具有局部感受野和参数共享的特点,有效地减少了计算量和参数量;另一方面,BN层具有加速网络学习和正则化的优势,在先前的一些剪枝方法中,通过卷积层的权重参数选择冗余滤波器,并对其进行裁剪.在卷积层中,滤波器值的绝对值的大小代表了其重要程度,重要的滤波器值能够提取出具有判别性的特征信息,但是,滤波器中的一些较小值往往会成为干扰信息,误导网络提取到不重要的特征信息.在BN层中,对输出激活值归一化,并通过缩放系数和偏移系数调整值的分布,由于每个缩放系数对应输出激活的每一个通道,每一个缩放系数代表其对应激活通道的重要性程度.因此,本文利用卷积层和BN层的参数信息,提出了基于滤波器注意力机制与特征缩放系数的剪枝方法.
3.1 基于滤波器注意力与特征缩放系数的剪枝框架
为了有效地提取滤波器中重要参数信息,本文提出了一种新的滤波器重要性判断指标,即联合滤波器的注意力重要性值和BN层缩放系数判断指标,滤波器的注意力重要性值指标利用注意力机制得到滤波器注意力图,将注意力集中在滤波器的重要参数值,缩小滤波器中不重要值的影响,放大滤波器中重要值的贡献.此外,BN层对每一层的特征图进行了归一化且BN层的缩放系数是对应每一个激活通道,缩放系数的大小和对应激活通道上值的大小紧密相关,用缩放系数表示每一个通道的重要性程度是一种简单且有效的方式,并且没有额外的开销.在训练过程中,滤波器参数和BN层缩放系数都在不断更新.因此,提出的剪枝方法能够重复利用滤波器注意力重要性值和BN层缩放系数作为选取冗余滤波器的判断指标,动态裁剪冗余滤波器,网络剪枝框架如图1所示.
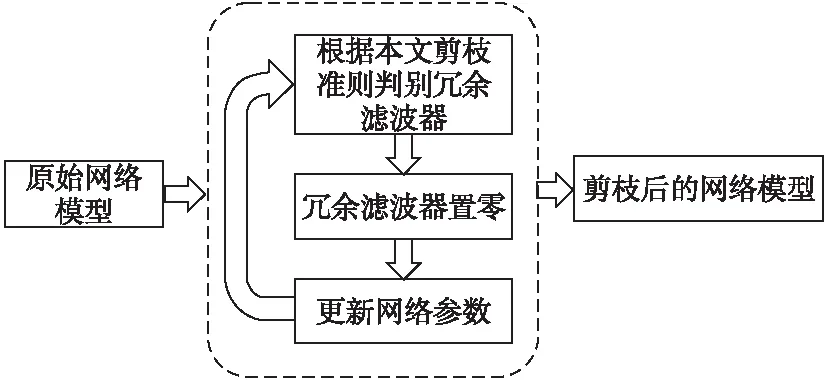
图1 基于滤波器注意力与特征缩放系数的剪枝框架Fig.1 Pruning frame based on filter attention and feature scaling factor
3.2 利用滤波器注意力机制评价滤波器的重要性
注意力机制是一种用于提取图片主要特征信息的方式,被广泛应用于神经网络中,将注意力集中在需要重点关注的目标区域,提取特征图中的主要特征信息,忽略一些次要特征信息.这样,从大量信息中.神经网络可以快速地筛选出有价值的信息,利用这些信息作为网络最终判断的主要特征依据,增强了网络的泛化性能.因此,利用注意力机制提取重要信息的原理,本文将注意力机制应用在滤波器上,得到滤波器注意力图.假设滤波器表示为Fi∈RC×H×W,C代表每一个滤波器的通道个数,i代表滤波器的第i个通道,注意力函数A如公式(1)所示:
(1)
为了得到滤波器重要值的分布,如图2所示,将公式(1)运用在每一个滤波器上,得到了滤波器的注意图.每一个3D滤波器变为了2D滤波器注意力图,2D滤波器注意力图上的每一个值都代表了该值通道维度上的整体重要性,包含了该值通道维度的主要信息,在映射的过程中,注意力机制将干扰信息缩小化,放大了重要信息值.最终,2D滤波器注意力图反映了每个值通道维度的不同重要性程度.

图2 滤波器注意力示意图Fig.2 Filter attention map
如图3所示,在不同Epoch下,ResNet20中相同层的一个滤波器的注意力图,可见,随着训练时间增加,同一滤波器的注意力值也在不断的变化,剪枝网络不断调整每层中需要裁剪的滤波器,直到网络收敛,搜索到最优的剪枝网络结构.
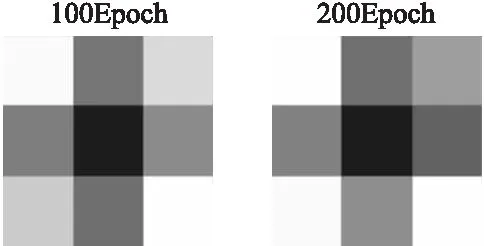
图3 不同Epoch下的滤波器注意力图Fig.3 Filter attention graph under different Epoch
为了能够表达出每个滤波器的重要性程度,运用公式(2),通过LF范数,将公式(1)每一个2D滤波器注意力图A转变为一个滤波器的重要性值M,并将每个滤波器重要性值M作为评判滤波器的重要性指标之一,在第4部分实验中,验证了该重要性指标的有效性.
M=‖A‖F
(2)
3.3 利用特征缩放系数评价滤波器的重要性
由于BN层具有加速网络收敛的作用,BN层已被广泛应用于神经网络中,一般置于卷积层的下一层,对卷积层的输出特征归一化,使得网络每层都可以自己学习,稍微独立于其他层.BN层有两个优化参数,分别为缩放系数和偏移系数,这两个参数微调归一化后的特征数据,使得特征值能够学习到每一层的特征分布,BN层的运算过程如公式(3)所示,其中,Zin为输入,Zout为输出,μC和σC分别为输入激活值的均值和方差,α和β分别为对应激活通道的缩放系数和偏移系数.
(3)
如公式(3)所示,由于BN层的缩放系数α对应每一个激活通道,表示每个激活通道的重要性,每一个激活通道是由上一层的卷积层卷积操作后得到,每一个激活通道都对应着上一层的一个滤波器,通过缩放值α确定冗余的激活通道,再根据激活通道选择裁剪上一层相应的滤波器.因此,缩放值α间接反映了对应滤波器的重要性.,可以根据BN层的缩放值的大小,裁剪卷积层的滤波器和BN层的偏移系数.本文将缩放α作为评判滤波器重要性的另一个指标,能够更加精准地裁剪网络中的冗余滤波器.
3.4 联合滤波器注意力机制与特征缩放值剪枝滤波器
3.2节和3.3节介绍了卷积层参数和BN的缩放系数对选择冗余滤波器的指导作用.一方面,卷积层利用了每个滤波器的注意力图,重点关注重要的滤波器参数,并将注意力图通过LF范数转化为评价滤波器的注意力重要性值,另一方面,BN层的缩放系数作为评价滤波器的另一个重要性值,如公式(4)所示,结合了3.2节和3.3节中的滤波器重要性指标判断滤波器的重要性程度,得到滤波器重要性函数I.
I=‖A‖F×α
(4)
假设网络共有L层,第i层共有Ni个滤波器,如算法1所示,展示了本文提出的动态网络剪枝算法的过程.
算法1.基于滤波器注意力与特征缩放系数的剪枝算法
输入:训练样本X,初始化权重W={w(i),1≤i≤l},剪枝率P
输出:收敛后的模型参数W
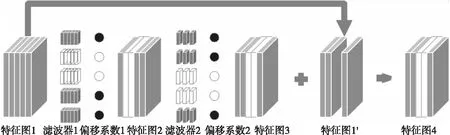
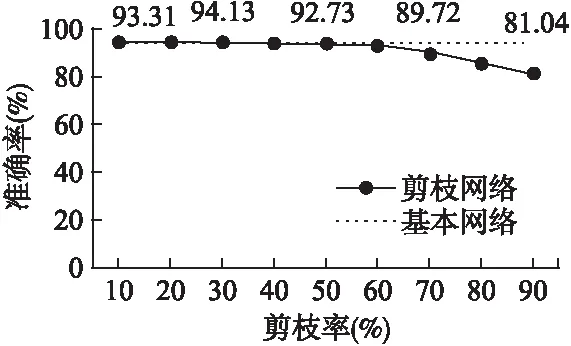
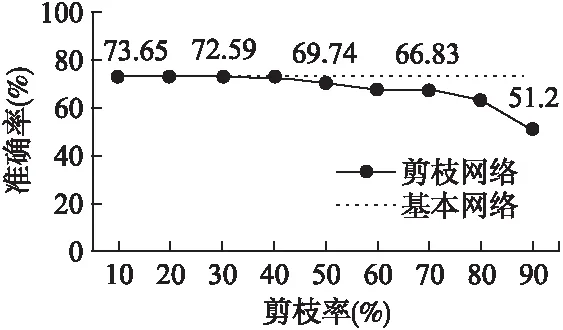
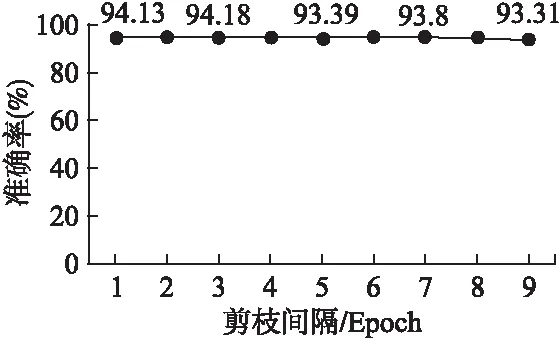
1.For epoch=1;epoch 2. Update the model parameters based on X; 3. For i=1;i Calculate the importance value of each filter according to Equation.(4); 4. Zeroize NiP filters and NiP offset value of BN layers; 5. end for 6.end for 在每次迭代过程中,根据滤波器重要性函数公式(4)选择需要裁剪的滤波器和BN层偏置系数,对其进行置零操作,这样使得硬剪枝和网络训练收敛时的精度保持一致.为了避免本次的误裁剪,在下一个Epoch中,对置零的滤波器和其余滤波器再次更新,使得裁剪掉的滤波器能够再次根据滤波器重要性函数公式(4)评估其重要性,不会因为一次的误裁剪降低网络的性能. 在训练过程中,对需要裁剪的滤波器以及BN层的偏置系数不断置零和更新,网络趋于收敛.网络准确地搜索到每层中的冗余滤波器,最终得到冗余参数置零后的网络模型.如图4所示,展示了网络残差块的硬剪枝过程,裁减掉滤波器1中的两个滤波器和BN层中的两个偏移系数后,特征图1经过滤波器1得到了特征图2,裁剪掉特征图2中的两个通道,特征图2经过滤波器2得到了特征图3,同样裁剪掉特征图3中的两个通道,特征图1经过跳跃连接后得到特征图1′,特征图1′和特征图3的通道数目相同,然而特征图3是由特征图1经过一系列裁剪后的滤波器卷积后得到,为了保证特征图3裁剪后的剩余通道能够和特征图1′对应.本文提出一种残差块的硬剪枝方法,提取出特征图3裁剪后的剩余通道的索引,并将特征图1对应这些索引的通道和特征图3组合,保证剪枝后的残差块中的特征图对应,而不用保留每一个残差块的最后一个卷积层的冗余滤波器,增加不必要的运算量.本文提出的硬剪枝方法,解决了跳跃连接与裁剪后的特征图通道不对应的问题,减小了网络运算量和存储量.保证了硬剪枝后的网络精度和训练收敛后的网络精度一致. 图4 网络残差块的硬剪枝Fig.4 Hard pruning of network residual blocks 为了验证本文的方法在深度神经网络上的实际效果.本文采用冗余性较小的残差网络,分别在ResNet20、ResNet32、ResNet56和ResNet110上进行实验,残差块的跳跃连接中没有训练参数,选用了标准CIFAR-10数据集和CIFAR-100数据集.首先,在4.1节中,本文考虑利用3.2节和3.3节提出的网络单层信息(滤波器注意力机制或特征缩放系数)和3.4节提出的双层信息(滤波器注意力机制与特征缩放系数)在相同的参数设置下做了实验,将注意力(滤波器注意力剪枝准则)、缩放系数(特征缩放系数剪枝准则)、双层信息(联合滤波器注意力与特征缩放值剪枝准则)三种剪枝方法分别在冗余性较小的残差网络上做了实验,并对这三种方法做了对比.在训练过程中,结合了动态网络剪枝的策略,剪枝率P设为20%和30%,同时对每层中的滤波器以剪枝率P裁剪,并在下一个Epoch之前再次更新参数,搜索网络的最优权重参数.接着,在4.2节中,将本文提出的剪枝方法与其它先进剪枝方法做了对比实验,验证了本文剪枝方法的有效性.最后,在4.3节中,剪枝率设置为10%~90%,测试了不同的剪枝率和不同剪枝间隔对模型精度的影响. CIFAR-10是一个3通道彩色数据集,共有10类,每张图片的分辨率为32×32,共有60000张图片,分为50000张训练集和10000张测试集.在该数据集上,本文分别采用了注意力剪枝准则,缩放系数剪枝准则和双层信息剪枝准则,并对比了这三种剪枝准则的实验效果,CIFAR-100数据集的大小、分辨率和数量与CIFAR-10一致,不同的是,CIFAR-100分为100类,为了验证提出方法的有效性,实验同样选取了冗余性较小的残差网络,在本文提出的三种剪枝准则上进行了实验,并对比三种剪枝准则的精度.剪枝率为20%和30%表示每一层的滤波器个数减少20%和30%,如表2和表3所示,展示了三种剪枝准则的精度与原网络的精度对比,可以明显看出,无论是剪枝率设为20%还是30%,单独运用缩放系数剪枝准则或注意力剪枝准则的精度较低,本文提出的双层信息剪枝准则的效果表现最好,充分利用了网络参数信息.尤其在剪枝率为30%的情况下,CIFAR-10数据集运用双层信息剪枝准则,ResNet56和ResNet110上的精度甚至超过了原网络的精度,CIFAR-100数据集运用双层信息剪枝准则,基本都能够接近原网络的精度.因此,如表2和表3所示,双层信息剪枝准则的实验结果表现最好,说明该准则选择的冗余滤波器更加精准,验证了该剪枝准则的有效性. 表2 三种剪枝准则在CIFAR-10上的实验结果对比 网 络剪枝准则剪枝率%基本精度%剪枝网络精度%下降精度%ResNet56缩放系数注意力双层信息20302030203093.5993.230.3692.171.4293.540.0593.510.0893.91-0.3293.540.05ResNet110缩放系数注意力双层信息20302030203093.6893.590.0993.400.2894.05-0.3793.600.0893.87-0.1994.13-0.45 表3 三种剪枝准则在CIFAR-100上的实验结果对比 网 络剪枝准则剪枝率%基本精度%剪枝网络精度%下降精度%ResNet56缩放系数注意力双层信息20302030203071.6069.412.1968.093.5170.690.9170.601.0071.140.4670.720.88ResNet110缩放系数注意力双层信息20302030203073.8471.492.3569.264.5871.832.0172.221.6272.601.2472.591.25 如表4所示,对比了本文提出的剪枝准则和其它剪枝准则的性能.在相同的剪枝率下,本文提出的剪枝准则的精度明显高于其它剪枝准则,由于SFP[27]在动态剪枝的过程中保留了BN层的偏置系数,硬剪枝引起剪枝网络精度的随机下降,破坏了动态剪枝中搜索到的最优网络结构,此外,其它剪枝方法[7,25,26]都没有对裁剪后的连接再恢复,无法搜索到最优的网络结构.由实验结果可知,得到的仅仅是一个次优解.因此,在与其它剪枝方法比较之下,本文的剪枝方法具有最优的网络性能,在测试数据集上的泛化性能表现最好. 表4 不同剪枝准则的实验结果对比 网络剪枝率(%)方法基本精度%剪枝网络精度%下降精度%剪枝网络浮点运算量(FLOPs)浮点运算量减少(FLOPs)%ResNet20-LCCT[26]91.5391.430.103.20E720.3ResNet2030SFP[27]92.2090.831.372.43E742.2ResNet2030本文方法92.2091.280.922.43E742.2ResNet32-LCCT[26]92.3390.741.594.70E731.2ResNet3230SFP[27]92.6392.080.554.03E741.5ResNet3230本文方法92.6392.68-0.054.03E741.5ResNet56-PF[7]93.0491.311.739.09E727.6ResNet56-CP[25]92.8090.901.90-50.0ResNet5630SFP[27]93.5993.100.495.94E741.1ResNet5630本文方法93.5993.540.055.94E741.1ResNet110-PF[7]93.5392.940.591.55E838.6ResNet110-LCCT[26]93.6393.440.19-34.2ResNet11030SFP[27]93.6893.380.301.50E840.8ResNet11030本文方法93.6894.13-0.451.50E840.8 随着剪枝率的增大,网络的运算量和存储量在不断减小,同时神经网络的性能也会受到不同程度的影响,利用本文提出的双层信息剪枝准则,在不同剪枝率下,研究了ResNet110的网络精度变化.剪枝率范围设定为10%~90%,实验结果如图5和图6所示,在一定范围内,随着剪枝率的提高,剪枝网络的精度超过了基本网络的精度;当超过一定范围,随着剪枝率的提高,剪枝网络的精度会逐渐低于基本网络的精度.可以说明,当剪枝率较小时,剪枝会给网络带来正则化的作用,增强了网络的泛化性能;当剪枝率较大时,网络的表征能力受到严重破坏.模型的性能下降明显,如表2所示,运用双层信息剪枝准则,ResNet110在剪枝率为30%时的网络精度比剪枝率为20%的网络精度表现更好,这正是剪枝对网络的正则化作用. 图5 ResNet110在CIFAR-10上不同剪枝率的精度Fig.5 Accuracy of different pruning rates of ResNet110 on CIFAR-10 图6 ResNet110在CIFAR-100上不同剪枝率的精度Fig.6 Accuracy of different pruning rates of ResNet110 on CIFAR-100 在训练过程中,不同剪枝间隔表示在这段时间中网络的参数恢复程度.因此,为了验证不同Epoch更新间隔对网络的精度的影响,本文设置剪枝率为30%、更新间隔单位为1个Epoch,比较在ResNet110上不同Epoch更新间隔的网络精度.如图7和图8所示,随着剪枝间隔的增大,剪枝网络的准确率在很小的范围内上下浮动,能够基本保持不变,.因为在动态剪枝的训练过程中,网络始终在不断调整冗余滤波器的选择,即使本次未能准确的裁剪掉冗余滤波器,在下一个Epoch中必然会选择到冗余滤波器.因此,剪枝间隔的大小对网络精度的影响较小,为了提高了网络的训练速度,本文实验选取剪枝间隔为1个Epoch. 图7 ResNet110在CIFAR-10上不同剪枝间隔的精度Fig.7 Accuracy of different pruning intervals on CIFAR-10 for ResNet110 图8 ResNet110在CIFAR-100上不同剪枝间隔的精度Fig.8 Accuracy of different pruning intervals on CIFAR-100 for ResNet110 假设剪枝率为P,i代表神经网络的第i层,滤波器个数为Ni,滤波器的长和宽都为K,输入特征图的长和宽分别为Hi和Wi,特征图的通道数为Ci,步长为1,裁剪第i层P×Ni个滤波器,则运算量减少P×Ni×K×K×Ci×Hi×Wi,相应第i+1层的输出特征图将会减少P×Ni个,运算量再次减少了Ni+1×P×Ni×K×K×Hi+1×Wi+1.因此,裁剪第i层P×Ni个滤波器,则计算量减少: (5) 本文提出一种基于滤波器注意力机制与特征缩放系数的动态网络剪枝方法,利用网络的动态性不断搜索最优网络参数,并结合提出的硬剪枝方法得到压缩后的网络.实验表明,一方面,滤波器的注意力图获取了滤波器上的重要参数信息,提取到具有判别性的信息;另一方面,特征缩放系数衡量了对应滤波器的重要性,综合这两个滤波器的重要性判断指标得到滤波器重要性函数,能够更加精准地选取冗余滤波器,实现了模型的最大程度的压缩,提高了模型的泛化能力.进一步地,可以根据网络的层敏感性,结合剪枝准则搜索最优的网络结构,达到更加理想的效果.3.5 网络残差块的硬剪枝
4 实验结果与分析
4.1 CIFAR-10和CIFAR-100上的剪枝结果对比
Table 2 Comparison of experimental results of three pruning
criteria on CIFAR-10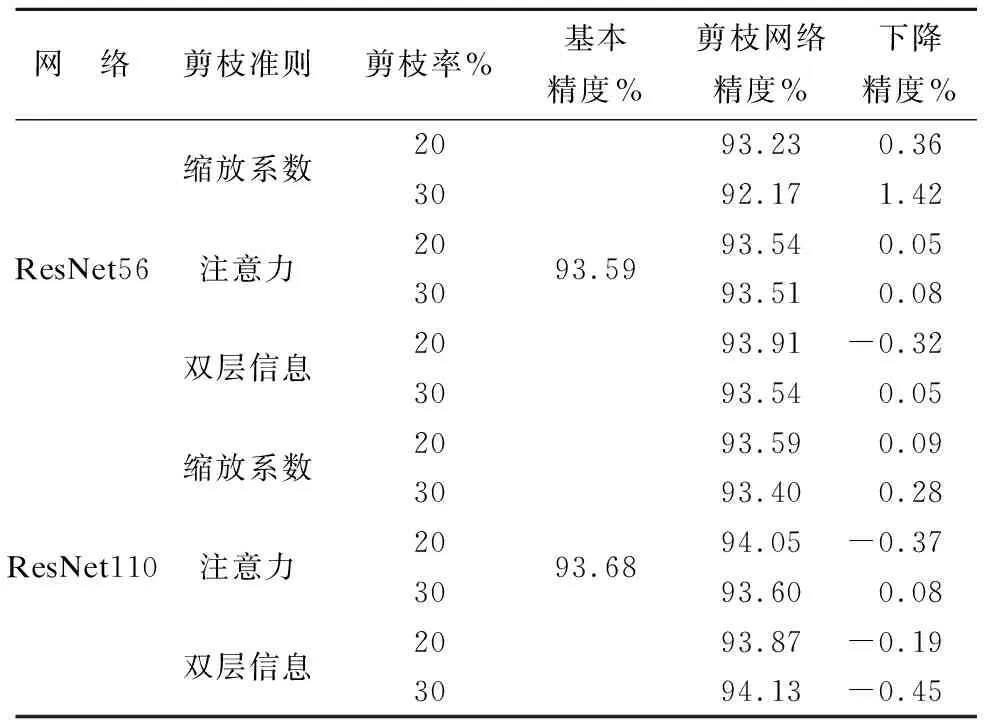
Table 3 Comparison of experimental results of three pruning
criteria on CIFAR-100
4.2 不同剪枝准则的实验结果对比
Table 4 Comparison of experimental results of different pruning criteria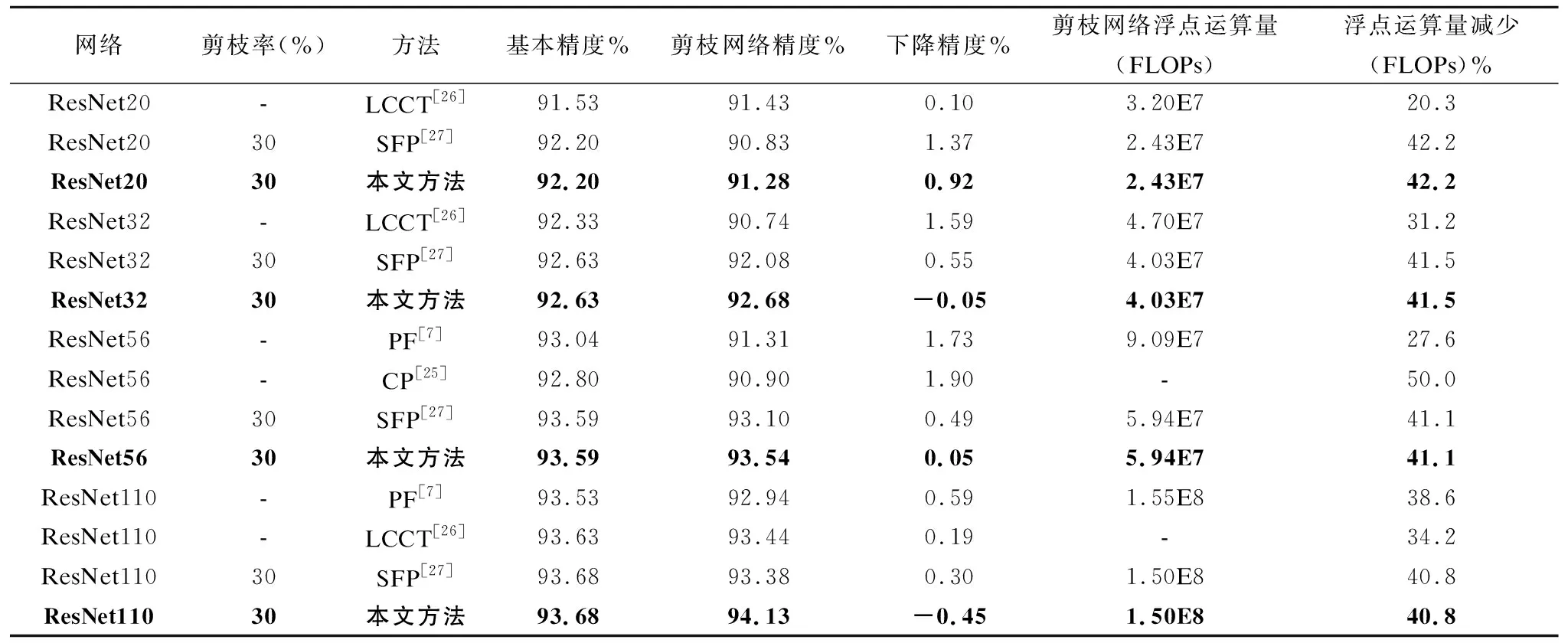
4.3 不同剪枝率对精度的影响
4.4 不同剪枝间隔对精度的影响
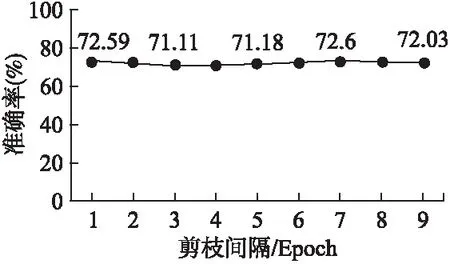
4.5 速度性能分析
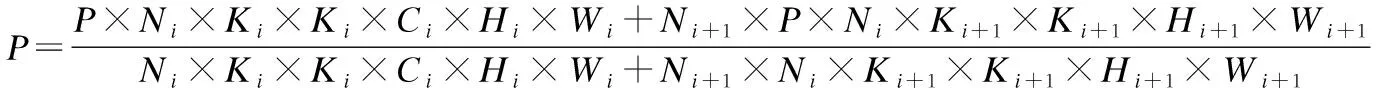
5 结 论
猜你喜欢
客联(2022年4期)2022-07-06成都信息工程大学学报(2022年2期)2022-06-14保健医苑(2022年5期)2022-06-10中国注册会计师(2021年10期)2021-11-22成都信息工程大学学报(2021年6期)2021-02-12计算机应用(2020年5期)2020-06-07电子制作(2019年11期)2019-07-04天津诗人(2017年2期)2017-03-16共产党员(辽宁)(2015年24期)2015-10-18消费导刊(2014年12期)2015-02-13
