
层次化反匿名联盟构建方法*
2019-10-24 05:50王尚广史闻博杨放春
软件学报 2019年9期
鲁 宁,李 峰,王尚广,史闻博,杨放春
1(东北大学 信息科学与工程学院,辽宁 沈阳 110819)
2(网络与交换技术国家重点实验室(北京邮电大学),北京 100876)
通讯作者:李峰,E-mail:lifeng@neuq.edu.cn
当前,互联网转发数据包的依据是目的IP 地址,通常不对源地址做真实性检查,这就使得网络中充斥了大量源地址虚假的匿名包,从而给网络安全运营带来了管理和计费问题.因此,如何在互联网上建立面向源IP 地址的真实性验证机制,解决其安全性弱、可信度低问题,进而为用户提供高度可信的网络服务,就显得极其重要.
与互联网本身的分层结构相对应,源地址验证体系结构通常也划分为3 个层次,自底向上分别为接入网络地址验证、域内网络地址验证和域间网络地址验证,其中:前两层都部署在自治域内,任务是阻止匿名包在域内网络传播;第3 层通常部署在域边界路由器,主要任务是通过识别和过滤域间匿名流来实现自治域粒度的网络保护.由于自治域之间的关系要远比域内关系复杂,因此域间网络地址验证就成为整个验证体系结构中最为关键的一个层次.按照是否需要对已有地址和路由协议进行扩展和改革,域间源地址验证研究方法一般又可分为“革新型”和“改良型”两大类.其中,前者集中于设计一种新的可绑定身份安全机制的地址系统和路由协议,以达到从根本上解决源地址伪造问题的目的[1-6];而后者主要关注如何在保证现有地址体系和路由协议稳定的前提下,通过增加检测机制来弥补现有网络体系结构的缺陷[7-9],因此更适合在现有网络上部署.事实上,确实已有3种经典的“改良型”域间源地址验证方法被当前路由器市场所广泛接受,它们分别是反向路径转发(unicast reverse path forwarding,简称uRPF)[7]、入边界过滤(ingress filtering,简称I-filtering)[8]和出边界过滤(egress filtering,简称E-filtering)[9].而本文主要关注其中过滤精度较高、操作开销较小的E-filtering 方法.
虽然E-filtering 因性能优势而倍受主流网络设备提供商的青睐,但是当前互联网至今仍有38.5%的自治域未加入反匿名联盟,这就说明它并未被网络服务提供商(Internet service provider,简称ISP)所广泛接受,其中的主要原因是它没有遵循“谁部署、谁受益”的激励原则,存在搭便车问题,阻碍了它的推广应用.针对该问题,已有研究者提出了一种基于对等过滤的域间源地址验证方法(mutual egress filtering,简称MEF),其主要任务就是构建一种面向Stub 域的反匿名联盟,将未部署E-filtering 的Stub 域从受益者列表中严格剥离,只有联盟成员才享有域间地址安全的权利[9].为了完成上述功能,该系统首先需要随时发现联盟成员状态(加入和退出)的变化,并将相关信息广播给其他成员,然后在联盟成员的Stub 域边界路由器的访问控制列表(access control list,简称ACL)上配置面向对等成员的E-filtering 过滤规则.但是该方法存在可扩展性差、难以适应增量部署问题,原因如下:过于扁平化、单一化的联盟体系结构,使得过滤器需求量和成员更新传播范围随联盟规模的扩张而急剧增大;过于随机的非成员判定方式和低效的数据处理方式,使得过滤规则优化的计算开销和精度都有待改善.
针对上述挑战,本文提出一种层次化的基于对等过滤的反匿名联盟构建方法(hierarchical anti-spoofing alliance construction approach based on egress filtering,简称EAGLE).与已有扁平化的反匿名联盟构建方法相比,本方法着力解决了以下3 个问题:(1)立足于实际自治域网络可分层的拓扑结构,通过对联盟成员分级划分,构建了新型的层次化的反匿名联盟体系结构,摒弃了传统方法中扁平的、单一的体系结构,避免成员之间建立不必要的全连接双向过滤关系,实现了过滤规则的精简,进而降低了过滤器需求量;(2)通过引入Transit 域对等过滤模块作为联盟边界,将每一层级联盟和外界成员隔离,使得不同层级联盟内部网络环境彼此互不可见,在确保域间高速通信的同时,排除了拓扑结构和成员变化带来的影响,有效控制了过滤规则信息更新的范围和频度,进而降低了系统通信开销;(3)聚焦因联盟划分不均造成高层成员的过滤器资源不足问题,通过定量分析网络前缀与过滤规则之间的关系,结合联盟成员动态变化的特征,设计一种高精度、可增量更新的过滤规则优化算法,在加快求解速度的同时提高解的质量.
为了验证本文提出的EAGLE 方法,首先对其高效性进行了理论分析;然后,在基于真实互联网拓扑的网络仿真环境下中对其进行了实验验证,并与其他经典方法进行了对比.结果表明:EAGLE 不仅延续了传统方法的优势,而且通过改善过滤器开销、通信开销、计算开销和优化精度来提高可扩展性.
本文第1 节给出扁平化的基于对等过滤的反匿名联盟构建方法形式化描述.第2 节介绍本文提出的EAGLE 方法,其中,第2.1 节介绍层次化反匿名联盟的基本概念,第2.2 节给出联盟的构建方法,包括系统结构模型、协同流程、安全策略、可靠性策略、过滤规则优化策略等实现细节.第3 节对EAGLE 的性能进行评估,其中,第3.1 节给出理论评估,第3.2 节则采用实验仿真手段对分析结果进行补充.第4 节介绍相关工作.第5 节总结全文并指出下一步的工作重点.
1 回顾扁平化的基于对等过滤的反匿名联盟构建方法
本节首先构建基于C2P 商业关系的层次网络模型,说明上下层自治域的网络前缀应该存在包含关系;然后回顾基于对等过滤的反匿名联盟构建方法,证明它可以解决传统方法部署激励性缺乏的问题;最后,通过指出该方法存在可扩展性差等问题,表明本文研究动机.
1.1 基于C2P商业关系的层次网络模型
一方面,研究者通过分析自治域(automous system,简称AS)路由策略,发现AS 路径符合“无谷模型”的特征,即存在严格的层次结构,下层AS 只有通过上层或同层AS 才能将它的数据包路由转发出去.本文将这种由上层向下层提供穿越服务并根据流量收费的商业关系称为客户-提供商关系(customer-to-provider,简称C2P),上层AS 称为提供商,下层AS 就是它的客户.另一方面,当前互联网为了解决因路由规模过大而造成路由器的处理能力和内存分配趋于饱和问题,广泛采用了更具层次化的无类别域间路由(classless inter-domain routing,简称CIDR)技术来为AS 分配前缀地址块,使得下层AS 的网络前缀能够直接取自它的上层,进而完成下层到上次的路由聚合,减少上层网络中明细路由的数量.基于此,本文建立了一种基于C2P 商业关系的层次网络模型.
如图1 所示,该模型是典型的树形结构,其中,Stub AS 是叶子节点,负责生成数据流,它只能充当Customer;而Transit AS 是非叶子节点,负责转发数据流,既能充当Customer,又能充当Provider.此外,该模型具备以下特征:(1)只包含单宿主自治域;(2)客户地址块全部取自上层提供商;(3)不包含对等体-对等体(peering-to-peering,简称P2P)和同胞-同胞(sibling-to-sibling,简称S2S)关系,只突出C2P 商业关系.

Fig.1 Hierarchical network model based on C2P business relationship图1 基于C2P 商业关系的层次网络模型
提出上述假设的原因在于[10]:
(1)互联网中虽然存在一个客户连接多个提供商的多宿主现象,但是这会引入大量无法聚合的明细路由.因而,绝大多数客户仍然在使用单宿主连接方式,只有当网络规模超过早期容量规划时或为了实现备用路由和可靠通信,才会购买不同提供商的地址块.然而,即使在多宿主连接下,我们也可按照地址块将客户逻辑划分为多个单宿主,而这种逻辑单宿主依然适合本文关注的出边界过滤技术,边界路由器就是先前客户与提供商的连接接口;
(2)虽然存在因历史遗留或临时更换提供商而造成客户的地址块与提供商不相符的现象,但是这种连接方式非常少见,因为它相当于在提供商的地址空间钻了个洞,使得它们不得不针对新引入地址块设置明细路由.不过,即使客户采用这种连接,也只是妨碍局部网络的层次化,但并不影响系统的正常运行以及整个联盟的层次化.基于此,该模型未包含这种非常规连接;
(3)P2P 和S2S 用于说明同层AS 及其客户之间是否直接可达.就同层直连AS 产生的匿名流来说,采用入边界过滤(ingress filtering,简称I-Filtering)来防御更加合适,因为这种场景既不会引发I-Filtering 的漏报率较高问题,也不会带来较大的操作开销.例如:假设ASA和ASB同层直连,那么在A和B的直连入接口上配置两条规则:1)permitASBASA;2)deny any any.其中:规则1)允许所有源地址包含在ASB,且目的地址包含在ASA的IP 包进入自治域A;规则2)则指出,凡是不满足前一规则的数据包都被过滤.由于本文偏向出边界过滤,因此不包含P2P 和S2S.
定义1.基于C2P 的层次网络模型定义为前缀树G=(V,E,A),其中,节点集V={v|v是G中节点},边集E={(u,v)|u,v∈V且u,v互为父子},前缀集A={a(v)|a(v)是节点v的前缀地址},∀u,v∈V且a(u)⊂a(v),∃u-v路径.
定义2.给定层次网络模型G=(V,E,A),如果∀u∈V,∄v∈V,s.t.a(v)⊂a(u),那么u为Stub 节点,记为ustub,所有Stub 节点构成Vstub集合,记为Vstub;反之,若存在v∈V,使得条件成立,u为Transit 节点,记为utrst,所有Transit 节点构成Vtransit集合,Vstub∪Vtransit=V.
定义3.匿名流定义为三元组F=(s,i,d),其中,s表示发送匿名流的自治域,i表示匿名流所携带源地址的域前缀,d表示被匿名流攻击的自治域.一般情况下,在正常网络环境中,给定数据流F,都有a(F.s)=F.i.然而在匿名网络环境下,∃匿名流F=(s,i,d),s.t.F.i≠a(F.s)和F.i∈Ωstub,其中,Ωstub表示网络中Stub 域网络前缀的全集.针对不同的网络协议漏洞,攻击者通过伪造源地址能够发起多种匿名攻击.根据源地址与攻击目标的联系,匿名攻击可划分为直接攻击和间接攻击:前者是由攻击者直接向受害主机发起匿名流,其中,匿名流的目的地址就是指向攻击目标,而源地址可设置为任何虚假IP,常见类型有SYN 风暴攻击;后者利用网络协议中请求和回复包数量不对称的特点,先由攻击者向中转服务器发起少量匿名请求,使它误以为该请求由受害主机发起,进而向受害主机发送大量回复信息,造成其瘫痪,常见类型有DNS 放大攻击.基于上述分析,给定匿名流F=(s,i,d),如果F属于前者,那么d是指匿名流所携带目的地址的域前缀;如果F属于后者,那么d是指匿名流所携带源地址的域前缀.为了同时防御二者,反匿名联盟成员之间既不应该彼此发送匿名流,也不应该发送源地址涉及彼此网络前缀的匿名流,也就是说,凡是目的地址或源地址隶属于成员网络前缀的匿名流都应该被过滤.
1.2 扁平化的反匿名联盟构建方法FAGLE
当前,互联网协议通常不对源地址做真实性检查,因此,攻击者能够将其他自治域IP 地址写入数据包的源地址字段,误导受害者.本文将这种源地址虚假的数据流称为匿名流,如定义3 所描述.出边界过滤(egress filtering,简称E-filtering)技术的主要任务就是过滤匿名流和净化域间网络,其基本原理正是利用第1.1 节提到的数据流源地址与自治域网络前缀的隶属关系来判定数据流的合法性,具体过程是在边界路由器的访问控制列表(access control list,简称ACL)上配置特定的包过滤规则,对每个流出数据包进行验证:如果发现其源地址不属于本网络范围,则丢弃;反之,正常转发.本文将这种配置ACL 过滤规则的边界路由器称为边界过滤路由器(border filtering router,简称BFR).以图1 为例,假设Stub 域AS2的网络前缀是198.1.2.0/24,那么对于所有从AS2流出的数据包来说,其源地址必须隶属于该前缀,否则就过滤它.基于此,AS2的边界路由器需要配置以下两条规则:(1)permitAS2any;(2)deny any any.其中:规则(1)允许所有源地址包含在网络前缀AS2的数据包正常转发;规则(2)指出凡是不满足规则(1)的数据包都被过滤,无论其源地址和目的地址是多少.本文将部署E-Filtering 的Stub域记为EStub,将具备匿名包过滤能力的网络称为反匿名网络(anti-spoofing network,简称ASN).虽然E-Filtering因轻量、高效等优点在提出伊始就被标准化,然而近年的网络测量惊人地发现,该方法的部署率连续多年都维持在一个极低的水平.造成这种后果主要原因是,它缺乏部署激励性.在本文中,部署激励(incentive for deployment,简称Inc)就是指网络服务提供商对一个反匿名方法的部署意愿程度,它通常表现在部署收益和非部署收益两方面:前者主要针对已部署反匿名机制的自治域,其部署收益越大,说明该方法的部署激励越大,反之越小;后者主要针对尚未部署反匿名机制的自治域,若它们总能不劳而获,那么收益越大,方法部署激励就越小,反之越大.基于此,本文借鉴文献[11]定义部署激励的思想,首先采用对偶方式来定义部署收益f1和非部署收益f2,然后通过逐一累加反匿名网络中所有自治域的收益就可评估出方法的部署激励,如定义4 所述.
定义4.部署激励可被定义为一个累加函数.
给定反匿名网络ASN=(G,RA-stub):

为了强化E-Filtering 的激励功能,Liu 等人借鉴社会学的互动关系理论,定义了一种基于对等过滤的反匿名联盟[9],其中,对等过滤(mutual egress filtering,简称MEF)是指StubASi能够阻止流向StubASj匿名流的充分条件是ASj也阻止流向ASi的匿名流,而反匿名联盟(anti-spoofing alliance,简称AA)就是由具备对等过滤关系AS 组成的集合.虽然反匿名网络上可能存在多个AA,甚至其成员彼此交叉,但通过定义4 不难推断出:为了最大化激励效果,所有成员域都应该加入同一个AA.因此,不失一般性,本文假设整个网络只有一个AA.部署MEF 方法的Stub 域称为MStub.在已有的方法中,反匿名联盟的所有成员都是MStub,而且它们必须保持完全双向过滤关系,根据定义5,它被称为扁平化的反匿名联盟(flat AA,简称FAA).
定义5.扁平化的反匿名联盟定义为FAA={uMStub∈RA-stub|具备对等过滤关系的MStub 节点}.∀数据流F=(s,i,d),已知F.s∈FAA,F满足以下条件:(1)如果F.d∈FAA,那么F.i=a(uMStub);(2)如果F.d∉FAA,那么或,其中,.
如图2 所示:在FAA 中,每个MStub 的边界路由器都需配置4 组ACL 规则.
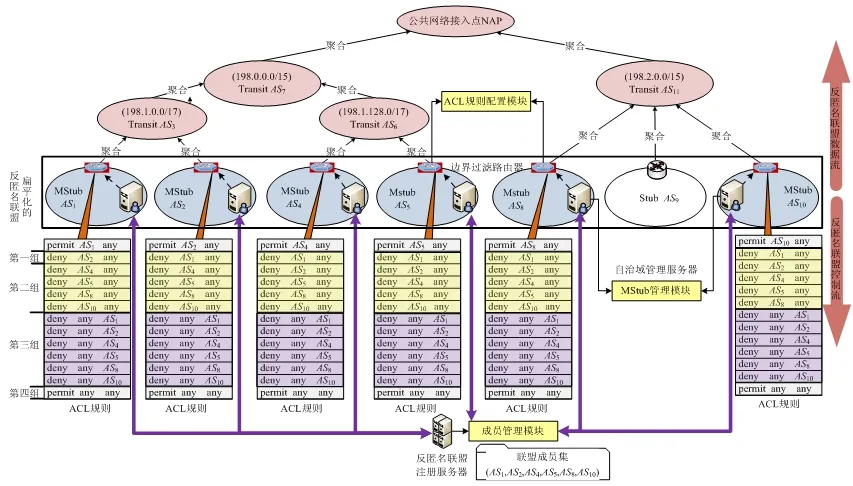
Fig.2 An example of FAA图2 扁平化的反匿名联盟举例
以AS1为例,它的边界过滤路由器配置规则如下:(1)permitAS1any;(2)denyAS2&AS4&AS5&AS8&AS10any;(3)deny anyAS1&AS2&AS4&AS5&AS8&AS10;(4)permit any any.其中,
· 规则(1)允许通过源地址包含在AS1网络前缀的数据包;
· 在前面规则不满足的条件下,规则(2)指出:无论目的地址是多少,所有源地址包含于成员域网络前缀的数据包都将被过滤;
· 在前面规则都不满足的条件下,规则(3)指出:无论源地址是多少,所有目的地址包含于成员域网络前缀的数据包也都将被过滤;
· 规则(4)则指出,凡是不满足规则(1)~规则(3)的数据包都将允许通过.
在基于MEF 的反匿名网络ASN=(G,RA-stub)中,RA-stub等于反匿名联盟AA.∀匿名流F=(s,i,d),如果d∈RA-stub,那么F.i=a(F.s);如果d∈Rc-stub,那么F.i≠a(F.s).与E-Filtering 相比,MEF 能防止非部署者不劳而获,而仅让部署者受益,有效地解决了搭便车问题,使得非部署收益f2恒等于0.
1.3 研究动机
在扁平化的反匿名联盟中,
· 一方面,为确保对等过滤机制能够有效运转,MStub 域的边界路由器必须维护面向全部成员的过滤规则,这就产生以下问题:
(1)过滤器需求量过大.所谓过滤器是指访问控制列表ACL 的表项,每个表项对应一条ACL 规则.过滤器不足就意味着ACL 过滤规则数量超过了其表项,例如:当联盟成员域数量为N时,每个域的边界过滤路由器都需要配置o(2N)量级的ACL 过滤规则.虽然当前路由器大都已提供ACL 过滤平台,但是它们全都由昂贵的三态内容寻址存储器(ternary content addressable memory,简称TCAM)来实现,为此,路由器设备商只能通过限制每台路由器的过滤器数量来降低成本[12,13].以常见的中端路由器Cisco Catalyst4500 为例,它的ACL 平台最多只有64 000 个过滤器,而且同时还被384 个接口共享;
(2)较大的通信开销.例如:当联盟成员域数量为N时,每当新成员加入或旧成员退出的时候,规则更新消息都将辐射到整个联盟范围,其代价达到o(N);
· 另一方面,当出现过滤规则数量超过过滤器需求的时候,MSM 模块会执行过滤规则优化算法.然而已有算法的效率较低,原因如下:非成员列表作为优化算法的重要输入参数,却采用随机性较大的排他法来判定,这会影响优化解的质量,使得过滤器利用率较差;面对不断变更的联盟成员,每次都只能将新旧数据重复处理,这会增加计算开销,影响系统响应时间.
简言之,以上问题终究会制约反匿名联盟的可扩展性.为此,本文希望在继承原有方法优势的前提下,构建一种层次化的体系结构,取代扁平化联盟的双向过滤关系,以达到降低通信开销和过滤器需求量的目的;设计一种可增量更新、高精度的过滤规则优化算法:一方面,利用已测量的拓扑数据来判定非成员域;另一方面,通过参考历史计算结果来处理新增数据,并将它们融合以求得最优解.
2 一种层次化的基于对等过滤的反匿名联盟构建方法
针对上述问题,本文提出了一种可自下而上分层、基于对等过滤的反匿名联盟构建方法(hierarchical antispoofing alliance construction approach based on egress filtering,简称EAGLE).本节将详细阐述本方法的设计思想和具体实现机制.
2.1 层次化反匿名联盟的基本概念
为了保证部署激励性,本方法依然采用对等过滤思想来建立反匿名联盟.随着越来越多的Stub 域加入联盟,反匿名网络的局部区域可能出现以下情形:与提供商Transitutrst直接关联的所有客户Stub 都成为MStub,例如,图3 中TransitAS3的两个客户Stub 域AS1和AS2都是MStub.本文将它们前缀的并集AS3∪AS2∪AS1称为内部前缀(inner prefix,简称INp).除此之外,联盟其他成员前缀的并集统称为外部前缀(out prefix,简称OUTp).就AS1~AS3发送的匿名流来说,根据源地址src 和目的地址dst 的可能组合方式,它们分为以下4 种:src∈INp∧dst∈INp,src∈INp∧dst∈OUTp,src∈OUTp∧dst∈INp,src∈OUTp∧dst∈OUTp.前3 种都涉及区域内成员前缀,称为区域内匿名流(inner anonymous flow,简称INf),第4 种只涉及区域外成员,称为区域外匿名流(out anonymous flow,简称OUTf).鉴于AS1~AS3是客户-提供商关系,通过路由策略可推断出OUTf必然经由提供商AS3转发.利用这个特点,我们可以实现层次化的对等过滤,基本原理就是由AS1和AS2来共同过滤INf,而由AS3来过滤OUTf.相应的ACL 规则配置方法如下:首先,鉴于AS1和AS2的任务相同且关系对等,它们的规则配置方法也相同.因此,本文只介绍AS1的规则配置情况.在AS1的边界过滤路由器上,共需配置4 组规则:(1)permitAS1any;(2)denyAS2&AS3any;(3)deny anyAS2&AS3;(4)permit any any.其中,第1 组用于判断数据包是否真实,第2 组和第3 组将侵犯同层MStub 域的匿名包全部过滤掉,第4 组用于剪除搭便车的非MStub 域.如果上述场景发生在第1.1 节建立的层次网络中,利用提供商包含客户前缀的特点,第2 组、第3 组规则可简化为图3 所示:(2)denyAS3any;(3)deny anyAS3.然后,AS3的配置规则为:(1)permitAS1&AS2&AS3any;(2)denyAS4&AS5&AS6&AS7any;(3)deny anyAS4&AS5&AS6&AS7;(4)permit any any.利用层次网络的前缀包含关系,第1 组~第3 组规则则可简化为图3所示:(1)permitAS3any;(2)denyAS7any;(3)deny anyAS7.到此为止,完成了由{AS1,AS2,AS3}组成的局部区域的层次化过滤.从联盟其他成员来看,该区域可被看为一个规模较大、以INp为前缀的可信逻辑Stub(trusted logical mef-stub,简称TMStub),图3 将它称为sub-TMStub1.随着联盟规模的进一步扩大,就有可能生成更高层级的TMStub.例如,随着sub-TMStub1={AS1,AS2,AS3}和sub-TMStub2={AS4,AS5,AS6}的加入,即可生成TMStub3={sub-TMStub1,sub-TMStub2,AS7}.基于此,本文将TMStub 表示为一个嵌套二元组(uTrst,ISMStub),如定义6 所示,其中,uTrst表示边界Transit 域,ISMStub表示内部其他成员集合.通过层次网络的前缀包含关系,可推断出TMStub 的前缀就是utrst的前缀.综上所述,TMStub 所配置过滤规则的特点可归纳如下:虽然边界规则较为复杂(最高层边界需要与其他成员实现完全双向过滤),但是内部规则较为简单(只需4 条)和稳定(既不因外部成员的变化而频繁更新,又不因联盟规则的增大而加大过滤器需求量).
本文将这种层次化的反匿名联盟(hierarchical anti-spoofing alliance,简称HAA)表示为{MStub1,…,MStubn,TMStub1,…,TMStubm},其中,MStubi是MStub 类型的成员域,TMStubi是TMStub 类型的成员域,如定义7 所示.与扁平化联盟中单一双向过滤不同,HAA 的过滤场景需要被扩展成3 类.
(1)最高层级联盟成员之间过滤——在反匿名联盟中,最高层级成员之间互为过滤端,把侵犯彼此的匿名流全部过滤.在这类场景中,每个成员的ACL 规则都要满足双向过滤,并且要实现物理MStub 之间、TMStub 之间以及物理MStub 与TMStub 之间的匿名包过滤,例如图3 中HAA={TMStub3,Stub8,Stub10},它们之间需要配置双向过滤规则,因此该层次的规则配置最为复杂,开销也最大;
(2)TMStub 内部过滤——TMStub 的内部成员域(其成员类型可能是MStub 或sub-TMStub)作为单向过滤端,把侵犯其他内部域的所有匿名流全部过滤.在这类场景中,内部成员域只需配置面向TMStub 网络前缀的 ACL 规则,例如图 3 中TMStub3={uTrst,ISMStub},其中,uTrst=AS7,ISMStub={sub-TMStub1,sub-TMStub2}.uTrst是边界Transit 域,鉴于TMStub3已属于最高层级成员,因此uTrst需配置双向过滤规则;而sub-TMStub1和sub-TMStub2作为内部成员,分别配置面向AS7的过滤规则即可.该场景的规则配置最简单,开销也较小;
(3)反匿名联盟与非成员之间过滤——联盟成员不过滤任意流向非成员域的匿名包.在这类场景中,每个成员既不应该单独配置面向非成员域的ACL 规则,也不应该配置可能涵盖非成员域地址块的ACL规则.例如图3 中Stub9是非联盟成员,成员域不会配置任何涉及Stub9网络前缀的ACL 规则,允许匿名流进入该域.
综上所述,虽然定理1 已经证明FAA 和HAA 在过滤效果和激励效果方面理论上相同,但是后者通过引入TMStub,使得Mstub 之间不必保持完全双向过滤关系,降低了联盟建立开销:(1)成员更新不会辐射到全联盟的Mstub 域,只在最高层级联盟成员之间传播,无需通知TMStub 内部成员,减少了通信开销;(2)过滤规则配置数量与Mstub 数量无关,只与最高层级联盟成员数量有关,缩减了过滤器需求量.很明显,在联盟规模一定的条件下,TMStub 成员数量越多,最高层级联盟成员数量就会越少,它的性能优势就越明显.但是,受限于自身策略、网络结构和经济、政治、军事利益等因素,某些Transit 域可能无法或不愿意开启过滤功能,从而影响联盟中TMStub成员数量.本文将开启过滤功能的Transit 域,记为Mtransit.不过,即使只有少量TMStub 成员,与FAA 相比,HAA在开销方面也具明显优势.这就意味着:我们可以在维持HAA 优势的同时,采用松耦合的方式来生成TMStub,并不要求所有满足定义6 的局部网络都建立TMStub,从而能够更灵活的构建反匿名联盟.

Fig.3 An example of HAA图3 层次化的反匿名联盟举例
定义6.逻辑可信Stub 域定义为二元组TMStub={uTrst,ISMstub},其中,uTrst表示TMStub 的边界Transit域,ISMstub表示TMStub 的内部Mstub 域集合,.∀数据流F=(s,I,d),已知a(F.s)⊂a(TMStub),F满足以下条件:(1)若a(F.d)⊂a(TMStub),则F.i=a(F.s);(2)若F.d⊄a(TMStub),则F.i=a(F.s)或F.i∈a(TMStub)-.
性质1.给定TMStub,∀数据流F=(s,I,d),a(F.s)⊂a(TMStub)且a(F.d)⊄a(TMStub),如果F.i⊂a(TMStub),就有F.i=a(F.s).
证明:运用定义6 即可证明.
定义7.层次化的反匿名联盟定义为HAA={MStub1,…,MStubn,TMStub1,…,TMStubm},其中,MStub 是物理MStub 域,TMStub 是最高层的逻辑可信Stub 域.给定u∈HAA,∀匿名流F=(s,i,d),已知F.s=u,F需满足以下条件:
(1)若∃v∈HAA,s.t.a(F.d)⊂a(F.v),那么F.i=a(u);
(2)若∀v∈HAA都不存在a(F.d)⊂a(F.v),那么.
离心泵在运行过程中因发生汽蚀直接影响到泵的性能,使泵的效率下降,扬程降低,严重时还会产生噪声和振动,腐蚀破坏叶轮等过流部件[1]。因此,对离心泵的汽蚀性能进行深入的研究,是很有必要且具有重要意义。
定理1.层次化的反匿名联盟HAA 与扁平化的反匿名联盟FAA 在过滤效果和激励效果方面理论上相同.
证明:首先,把FAA 的MStub 成员按照HAA 中TMStub 的组成结构划分为若干组.以图3 的HAA={TMStub3,AS8,AS10}为例,已知T1={AS1,AS2,AS4,AS5}隶属于TMStub3,因此,图2 中FAA 可划分为两组,即FAA=T1∪T2,其中,T2={AS8,AS10}.然后,为了证明FAA 和HAA 的过滤效果相同,将FAA 的匿名包过滤场景分为三类:组内成员互相发送匿名包、组内向组间发送匿名包、组间向组内发送匿名包,从而只需证明3 个场景分别相同即可.
· 场景1:∀匿名流F=(s,i,d),如果F.s∈T1且F.d∈T1,根据定义5 可知F.i=a(F.s).已知∀u∈T1都有a(u)⊂a(TMStub3),根据定义6 可知F.i=a(F.s).这就意味着FAA 和HAA 在场景1 下过滤效果相同;
· 场景2:∀匿名流F=(s,i,d),如果F.s∈T1且F.d∈T2,根据定义5 可知F.i=a(F.s).已知F.d∈HAA且a(F.d)⊄a(TMStub3),根据定义7,可知F.i⊂a(TMStub3).进一步通过性质1 可得F.i=a(F.s).因此,FAA 和HAA 在场景2 下过滤效果相同;
· 场景3:∀匿名流F=(s,i,d),如果F.s∈T2且F.d∈T1,根据定义5 可知F.i=a(F.s).已知F.d∈HAA且a(F.d)⊂a(TMStub3),根据定义7,可知F.i=a(F.s).FAA 和HAA 在场景3 下过滤效果也相同.
最后,为了证明FAA 和HAA 的激励效果相同,只需说明它们都不存在搭便车自治域.也就是说:∀匿名流F=(s,i,d),如果F.d∉AA,那么不存在F.s∈AA,s.t.F.i=a(F.s).为此,将FAA 的匿名包过滤场景分为两类:组内成员向非联盟成员发送匿名流和组外成员向非联盟成员发送匿名流.
场景1:∀匿名流F=(s,i,d),如果F.d∉FAA且F.s∈T1,根据定义5,可知.如果∃u∈TMStub3,s.t.a(F.s)⊂a(u),且∀v∈TMStub3,st.a3,s.t.a(F.d)⊄a(v),根据定义7,可知.因此,FAA 和HAA在场景1 下不存在搭便车自治域;
场景2 与场景1 相同,也不存在搭便车自治域.
2.2 层次化反匿名联盟的构建方法
传统的E-Filtering 通常是被各个自治域独立部署,然而层次化反匿名联盟HAA 却要求部署E-Filtering 的自治域之间既能够及时发现彼此,也能够互相交换网络前缀,因此它的构建必然依赖于一种分布式协同控制系统.鉴于HAA 立足于实际网络体系结构,与网络控制系统相似,该协同控制系统应具备开放性、简单性、可扩展性、可靠性等特征.围绕实现这些特征,接下来我们主要阐述HAA 分布式协同控制系统的结构模型、协同流程、安全策略、可靠性策略、过滤规则优化等.
2.2.1 系统结构模型
一般来说,按照分布式协同系统中各部分的位置、角色以及它们之间的关系,其结构模型可分为两类:对等结构和客户/服务器结构.若使用前者来构建HAA,为了完成TMStub 成员判别和对等过滤,每个成员域必须通过建立一对多的通信关系来收集其他成员信息,进而获取联盟成员列表.除此之外,鉴于联盟与成员之间宽松的绑定关系,每个成员域还需具备邻接成员资格检测功能,以便随时感知新成员的加入和旧成员的退出,进而更新成员列表并将其通知至整个联盟,保证元数据的一致性.简言之,这既会加大设计的复杂性,又会产生巨大的通信开销,进而影响系统的可扩展性.然而,若采用后者来构建HAA,联盟成员列表的维护工作(包括成员的动态加入或退出)将全部由服务器来完成,而成员域作为客户端,只需提交加入或退出请求即可,成员域之间无需建立任何关系,这既能简化成员注册/退出流程,实现系统高效扩展,又能省去邻接成员资格检测,降低系统通信开销.不过,客户/服务器结构将所有操作都集中于服务器端,从而使它极易成为整个系统的瓶颈.为了解决该问题,一种直观的方法是利用TMStub 分层嵌套结构的特点,将中心服务器的部分管理功能逐层下放到MTransit 域中,由它们负责TMStub 成员的维护以及其内部ACL 规则参数的传递,而服务器只承担最高层级成员的管理工作.在这种可分层的客户/服务器结构模型中,下层自治域若提出注册/退出请求,正常情况下需要先与上层MTransit域建立通信连接,逐层向上转发请求信息,以便各层MTransit 域随时判断下层成员是否已满足TMStub 生成条件,直至中心服务器.此外,为了降低系统运行条件,使它更符合真实的网络环境,我们不能要求每个Transit 域都成为MTransit.在这种特殊情况下,因上层不存在MTransit,下层自治域只能将注册/退出请求直接发送给中心服务器.基于此,上层MTransit 的不确定性导致下层自治域必须具备关于它的检测功能,然后依据检测结果来选定请求消息的发送对象,进而再次引发因系统设计难度大和通信开销高的问题.因此,利用该模型来构建HAA 并不合适.另一种方法是采用多副本存储技术,由多个配置完全一致、功能地位对等、所处地区不同的副本服务器共同组成中心服务器,而由地位完全相等的MTransit 和MStub 成员域组成客户端.由于该方法的上下层级的成员域之间无需执行主从式通信,因此不会引发可扩展性差的问题.综上所述,本文最终选定基于多副本均衡负载的客户/服务器系统结构模型来构建HAA.
如图4 所示,HAA 构建系统需要由联盟成员管理模块(alliance management module,简称AMM)、Transit 对等过滤模块(mef-transit module,简称MTM)、MStub 对等过滤模块(mef-stub module,简称MSM)、ACL 规则配置模块(ACL rule configuration module,简称RCM)协同工作来完成联盟成员列表的管理、ACL 规则的生成和匿名包的过滤.为了降低部署成本,本文借鉴了第1.2 节提到的文献[9]中有关控制层面的部署方式,将上述模块依次部署于联盟注册服务器(alliance registration,简称AR)、网络管理服务器(network management,简称NM)、边界过滤路由器,其中,AR 是由Internet 号码分配局(Internet assigned number authority,简称IANA)或地区注册处(regional Internet registries,简称RIRs)负责维护的新增互联网实体设备,而NM 是由网络服务提供商负责维护的已存在的网络实体设备.所不同的是:在EAGLE 中,上述模块分别被赋予新的职能.MSM 作为核心功能模块,主要任务有:(1)向AMM 提交成员注册/退出请求,其内容须包含成员的AS 编号和AS 网络前缀等;(2)接收AMM向它传递的ACL 规则参数,以此为依据,结合RCM 提供的过滤器数量,生成ACL 规则;(3)向同层RCM 发起ACL 规则配置请求.MTM 作为新添加模块,绝大部分任务都与MSM 重合,唯一的区别是:MTM 向AMM 提交的请求信息中,除了本自治域的AS 编号和AS 网络前缀,还应包含它所覆盖下层所有自治域的AS 编号和AS 前缀.RCM 作为过滤执行模块,一边向同层MTM 或MSM 上传边界过滤路由器所拥有的过滤器数量,一边接收和配置由它们下发的过滤规则.与基于路由的反匿名方法不同[14],本文的过滤规则表是基于ACL 平台的,而不是路由转发表,因此它的下发过程不依赖于BGP 扩展协议,而是SSH,TELNET 等远程通信协议.鉴于联盟成员的动态性,本文的过滤规则表无法一次性完全生成,只能增量装载.为了降低开销、提升效率,本文建议通过组合当前路由器操作系统(例如Cisco IOS v8.3)已支持的增删改操作来完成表增量,而不是先删除后重建.AMM 作为信息汇聚模块,主要任务有:
(1)利用已有的拓扑测量方法和自治域商业关系推测方法来获取AS 级网络结构数据,进而建立第1.1 节提到的层次网络结构模型.在该模型中,Transit 节点配置两个属性:过滤状态位和TMStub 状态位,前者记为FS,用于声明相关自治域是否已注册为成员域;后者记为TS,用于声明相关Transit 域管辖区域能否构成TMStub.而Stub 节点只配置过滤状态位FS;
(2)接收和保存MTransit 和MStub 成员域的注册请求信息,修订其在层次网络结构模型中节点状态信息;
(3)遍历拓扑结构模型,依据定义6 来判别部分注册成员是否能生成TMStub,在修改节点状态位的同时更新联盟成员列表(alliance member list,简称M-List),以此为基础,结合第2.1 节的过滤场景,给每个成员下发相应的ACL 规则参数.

Fig.4 System structure overview for HAA (HAA from Fig.3)图4 HAA 构建系统的结构模型(联盟结构源于图3)
2.2.2 协同流程
在层次化反匿名联盟中,数据包的过滤动作受联盟成员列表的控制,而成员列表又因MTransit 和MStub 域的加入或退出发生变化,原因是它们可能引发TMStub 的生灭,进而造成列表成员的聚合和裂变.因此,MTransit和MStub 域的加入或退出是触发系统运行的主要事件.本文以图4 为例来分别阐述当上述事件发生后,各模块之间是如何协同、完成列表更新的.假设StubAS2,AS4,AS5,AS7都已注册为成员域,AMM 的网络拓扑结构模型如图1 所示,成员列表M-List={AS2,AS4,AS5,AS7}.
(1)非成员域若想加入联盟,先得向AMM 提出注册申请.
AMM 在收到申请后,首先在拓扑结构模型中查找注册域对应节点,修改其过滤状态位,并将其孩子节点与申请消息中下层自治域逐一匹配,纠正拓扑模型的节点漏报;然后判定TMStub 域的生成,依据判定结果,修改相关边界域的TMStub 状态位,同时更新成员列表,最后向联盟成员(包括ASi)下发新的ACL 规则参数;成员域收到参数后,依据过滤器数据,优化过滤规则,并将其下发到RCM;RCM 通过配置规则,完成匿名包过滤.整个过程需AMM 完成定位、判定、更新这3 个任务,接下来主要说明它们的实现方式.
a.鉴于拓扑结构模型存在逐层汇聚的特点,本文将它定义为一种可用于快速检索的多叉树结构——前缀树(retrieval tree,简称Trie),通过它的查找方法即能快速定位自治域;
b.不同类型申请域的判定方法也不同.若Transit 域ASi申请加入,首先查验以ASi为首的局部网络是否生成TMStub,然后采用向上就近查验原则,逐层判定高层级的TMStub.例如:若AS3希望成为MTransit,因为在其管辖的局部网络中AS1尚未注册,所以不满足TMStub 生成条件,判定结果为MTransit.AS6在AS3加盟后也提出注册请求,因其管辖的AS4和AS5都已加入联盟,生成sub-TMStub2.然后查验以AS6为首、覆盖sub-TMStub2的局部网络,条件不再匹配,最终判定结果为TMStub.若Stub 域ASj申请加入,直接采用向上就近查验原则即可.例如:继AS3和AS6后,AS8提出申请,因以AS11为首、覆盖AS8的局部网络存在非成员域,TMStub 判定结果为MStub.此后,AS1选择加入,生成sub-TMStub1,然后查证以AS7为首、覆盖sub-TMStub1的局部网络,生成TMStub3,最终判定结果为TMStub;
c.依据TMStub 判定结果,选择成员列表更新方法.若结果为Transit 域,无需更新.例如,加入AS3既没有生成新TMStub,也不影响对等过滤,因此M-List={AS2,AS4,AS5,AS7}.若结果为TMStub 域,需要将成员列表的部分成员聚合为该自治域.例如:加入AS6生成sub-TMStub2,先将该TMStub 添加到成员列表,后将它覆盖的成员前缀AS4和AS5删除,M-List={AS2,AS7,sub-TMStub2}.若结果为Stub 域,直接将它添加到成员列表.例如,加入AS8虽然没有生成新TMStub,但是为了不影响对等过滤效果,M-List更新为{AS2,AS7,AS8,sub-TMStub2}.
(2)成员域若想退出联盟,先得向AMM 提出退出请求.
AMM 在收到请求后,首先在拓扑结构模型中修改相关节点的过滤状态位,然后将该节点及其祖先节点的TMStub 状态位都改为False,最后更新成员列表,向联盟成员下发规则参数;成员域和RCM 的处理过程与步骤(1)相同.值得说明的是,列表更新方法取决于退出成员类型及其前缀与成员列表的关系.若MTransitASi选择退出且它的前缀等于或包含于最高层级的TMStub 成员,首先分裂与ASi相关的所有TMStub,然后将剩余TMStub和MStub 添加到成员列表,例如:当M-List={sub-TMStub3,AS8}运行一段时间后,MTransitAS3因经济或政治原因选择退出,希望重新变为Transit 域,与AS3相关的TMStub 域(包括sub-TMStub1和sub-TMStub3)全部发生裂变,最终剩余MStubAS1,AS2和sub-TMStub2,从而将M-List更新为{AS1,AS2,sub-TMStub2,AS8};若ASi的前缀与任何成员不发生关系,无需更新,例如:继AS3后,AS7也选择退出,它就与M-List成员无交集;若MStubASj选择退出且它的前缀等于最高层级成员,就直接将它从列表中删除,例如:AS8退出不会引发TMStub 分类,只需更新M-List={AS1,AS2,sub-TMStub2};若ASj前缀包含于某TMStub 成员,其处理过程与MTransit 退出相同,例如:AS4退出造成sub-TMStub2的裂变,使M-List更新为{AS1,AS2,AS5}.
2.2.3 安全和可靠性策略
就安全性而言,HAA 构建系统的开放性允许任何陌生自治域都能向AMM 提出成员注册、退出请求,这为匿名、中间人等恶意攻击的发起提供了可能,究其原因在于:(1)AMM 无法通过成员域的网络前缀来识别其身份;(2)成员域MTM/MSM 无法确认AMM 发送的消息中ACL 规则参数是否被篡改.基于此,系统模块之间的通信只有嵌入身份认证和消息验证才能预防上述攻击.为此,本文以节约部署成本、保证执行效率为出发点,先使用资源公共密钥基础架构(resource public key infrastructure,简称RPKI)来保障MTM/MSM→AMM 的通信安全,后使用RSA 数字签名来完成AMM→MTM/MSM 的安全通信,最终实现它们之间安全的双向通信.
鉴于核心管理模块AMM 的负载较重,本文采用多副本存储技术来构建AMM,这虽然提升了HAA 系统的可靠性和可用性,但是也带来管理难题,包括如何放置副本、如何均衡副本负载、如何保持副本之间的成员数据一致性、如何处理副本故障等.本文以高效、实用为出发点,分别选用如下技术来解决上述问题.
· 为了降低通信时延、缩短响应时间,引入数据分区技术,将AMM 按照RIRs 的组织方式划分为5 份,每个注册地区至少放置一个AMM 副本,除了少量的跨分区通信外,大部分的分区都可独自地处理服务请求;
· 若所属注册地区存在多个副本,客户端通过循环域名服务技术(round-robin DNS,简称RR)来选定与它通信的副本服务器,从而保证各副本之间的负载平衡;
· 通过对AMM 业务特点进行分析,选定通信开销较小的最终一致性模型来完成副本数据之间的同步,通过牺牲一致性来换取高可靠性和可用性;
· 采用自适应检查点机制和Merkle 哈希树来解决临时故障和永久性故障.
2.2.4 过滤规则优化
在HAA 构建初期,联盟中MStub 成员类型较多而TMStub 成员类型较少,进而造成绝大部分成员位于联盟最高层.根据过滤场景1 可知,最高层成员之间需要维持双向过滤关系,因此这会产生过多过滤规则,从而使边界过滤路由器的过滤器资源发生短缺.为此,MTM 和MSM 模块如何在不损害激励机制的前提下优化过滤规则、降低过滤规则对过滤器的需求,成为决定HAA 激励性能的关键问题.
2.2.4.1 过滤规则优化问题形式化描述
如图3 所示,按照功能不同,位于联盟最高层成员的BFR 所配置的过滤规则可划分为4 组,其中:第1 组和第4 组分别只含一条规则,而第2 组和第3 组所含规则较复杂.因此,BFR 通常能够容纳第1 组、第4 组规则,却无法容纳其余两组.基于此,本文主要集中于优化第2 组、第3 组规则.鉴于这两组规则都具备一维特性(其规则参数仅局限于源地址或目的地址且二者只能取其一),过滤规则优化可归为同一前缀压缩问题(same prefixes compression,简称SPC).给定一组去本地化且彼此不重叠的成员列表M-List、一组彼此不重叠的非成员列表W-List、过滤器投入量Rmax以及一组归一化的地址权重集W.为了覆盖所有M-List成员,同时最小化搭便车率(free riding ratio,简称FRR),SPC 可被形式化为如下方程:
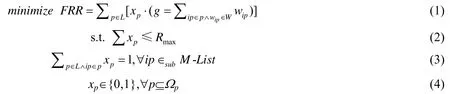
其中,公式(1)表明优化目标,g是FRR的决定因子;公式(2)表明过滤器投入数量不高于Rmax;公式(3)表明每个成员前缀有且只能被过滤一次,否则会浪费过滤器;公式(4)表明决策变量的取值范围.
定义8.成员列表,其中,表示HAA 中最高层成员ASi的网络前缀(若是TMStub,则ASi就是TMStub 边界域).M-List的成员具备两个性质.
其中,Ωp表示IP 前缀全集.
定义9.亚属于∈sub:ip∈subList,当且仅当,其中,List表示M-List或W-List,ip表示IP地址.
定义10.非成员列表,其中,表示未加入联盟的StubASi网络前缀.W-List具备以下性质:
定义11.决策变量xp∈{0,1},当p∈L时,xp=1;当P∉L时,xp=0.其中,L表示规则优化算法输出的网络前缀集.Rmax是指过滤器最大投入数,也就是说|L|≤Rmax.
定义12.地址权重wip∈[0,1],表示免费保护地址ip可能带来多大程度的不良影响.若ip∈subM-List,wip=0;若ip∈subW-List,wip>0.
定义13.地址权重集,为了描述简单,对权重进行归一化处理,使得.给定W,∀网络前缀P∈L,它的权重.
定义14.搭便车率是指得到免费保护的网络前缀的总权重.
2.2.4.2 过滤规则优化算法
文献[13]指出,SPC 问题可归为多维背包问题(multidimensional knapsack problem,简称dKP).众所周知,dKP属于NP-hard 范畴,若使用常规解法,例如分支界限法和割平面法,虽然能够求得精确解,但是运行时间随着反匿名联盟规模的增大会呈指数增长,从而使得各成员域的MTM 或MSM 模块无法快速求得最优解.其次,联盟规模的逐渐扩张要求过滤规则优化算法必须具备增量更新的特点,否则,若新旧过滤规则合并后再优化,那么这一方面会因数据集过大而消耗太多的时间和存储空间,另一方面则会因全局优化使得原有过滤规则也需重新配置,产生额外处理开销.Soldo[13]曾经提出一种基于最长公共前缀树(longest common prefix tree,简称LCP)、可增量更新的动态规划算法,用来解决IP 地址优化问题.经过碎片化处理,虽然能够将本文所关注的前缀优化也转化为上述的IP 地址优化,但是这会造成IP 数量激增,进而带来庞大的计算开销.为此,Liu[9]提出了基于扩展LCP 树(extended LCP,简称ELCP)的动态规划算法,它在保证解质量的同时提高了求解速度.然而该算法存在两点不足.
(1)采用排他法来建立非成员列表W-List,即∀ip,ip∈M-List⇔ip∉W-List.由于W-List是构建ELCP 树的重要数据源,这既会生成大量碎片IP,进而造成ELCP 树的规模过大,产生较大内存开销,又会因多余的W-List成员而影响ELCP 树非叶子节点中误报率属性的计算结果,进而降低了算法优化精度.原因如下:假设两个自治域执行聚合操作,判断其结果是否引入误报的依据应该在于它有没有夹杂其他真实自治域的网络前缀,而与这两个自治域的网络前缀是否连续没有直接关系.也就是说:即使它们不连续,只要聚合结果不包含真实自治域,它也就不会引发误报.然而在上述方法中,鉴于W-List包含大量非真实自治域IP,这会造成ELCP 树包含许多无用白色叶子节点,进而影响非叶子节点中误报率属性的计算,最终误导算法的优化方向,降低它的求解精度;
(2)不再支持增量更新,降低了算法重新求解的效率.
针对上述两个问题,本文提出了一种可增量的高效过滤规则优化算法.
从聚合角度来看,SPC 问题就是在指定数量的条件下搜索一组误报率最小的M-List成员聚合前缀.基于此,可增量的过滤规则优化过程可划分为3 步:第1 步,以最小化聚合误报为目标,推测M-List成员最优聚合次序,提取它们的聚合前缀,组成最优前缀集I-Set;第2 步,从I-Set 中挑选数量不超过|Rmax|个、彼此不相交、累积聚合误报最小的前缀,组成最终结果F-Set;第3 步是在成员加入或退出的时候,及时更新I-Set,以便重新计算F-Set.每一步的实现方式如下所述.
根据定义15 可知:聚合操作属于二元运算,且满足交换律和结合律,因此任何加括号的方法都会得到相同的计算结果.例如,则共有3 种加括号方式:,它们的计算结果完全相等.然而不同的加括号方法通常会产生不同的累积聚合误报,例如:根据定义 16,,而且.此时,如果,那么不难推断.因此,如何优化聚合次序(即加括号),使M-List成员聚合操作产生最小的累积误报率,成为首先需要解决的关键问题.
在提出解决方案之前,本文对聚合优化问题做了如下分析.
· 首先,给定一个规模为n的M-List,令P(n)表示可供选择的括号化方案的数量,不难推出,这意味着括号化方案数量与n呈指数关系,因而穷举法的效率会非常差;
· 其次,根据定理2,聚合优化问题具备最优子结构和重叠子问题等基本要素,因此我们可以利用基于自底向上的动态规划方法来对它求解,即,通过子问题的最优解来逐层向上递归构造出原问题最优解.整个过程可看做是在构建一颗二叉树:首先,从M-List中挑选聚合误报最小的两个成员作为参数;然后建立一颗以参数为叶子、聚合前缀为根的二叉子树;最后,将该子树插入M-List,同时删除M-List中与子树相关的成员.逐层向上重复上述动作,最终生成一颗前缀聚合二叉树,树中所有非叶子节点就可组成最优聚合前缀集I-Set.
基于上述分析,因为二叉线索树能够标识出哪些节点对应最优聚合前缀,所以通过遍历就能获取最优聚合前缀集I-Set.此外,由于M-List和W-List成员因联盟规模变化而不断更新(加入或退出),因此树的建立过程除了在BT 中标识最优聚合前缀和计算聚合误报两个阶段,还应包括更新阶段.更新操作由成员变化类型而决定.例如:当M-List加入新成员m时,如果m之前属于W-list,说明树中已包含m;如果m不属于W-List,先遍历已存在节点,不做任何操作,后插入新节点.当W-List加入新成员n时,操作过程与第二阶段相同.退出M-List相当于是向W-List添加新成员,因此该操作与上一过程相同.
定理2.聚合优化问题能够采用动态规划方法来求解.
证明:众所周知,只有具备最优子结构和子问题重叠特征的最优化问题才适合使用动态规划方法来求解.基于此,我们首先发掘聚合优化问题的最优子结构,该证明过程通常遵循如下模式.
a.如果对M-List所有成员执行聚合操作,那么必先将M-List划分为两个子集sub1和sub2,聚合误报ρ(M-List)=ρ(sub1)+ρ(sub2)+ΔM-List,其中,Δ表示包含于M-List的聚合前缀、与sub1和sub2无交集的聚合误报;
b.假设sub1和sub2是M-List的最优分割子集,那么对子集sub1进行聚合优化,直接采用独立求解该子集时所得的最优方案即可.这样做的原因可采用“剪切-粘贴”技术证明:如果不采用独立求解sub1所得的最优分割方案来对它进行聚合操作,那么可以将此最优方案带入M-List的最优方案中,代替原来对子集sub1进行分割的方案,显然,这样得到的方案比M-List原来最优方案的误报更低,这与之前假设相矛盾.对子集sub2来说,可得到相似的结论:在原问题M-List的最优分割方案中,对子集sub2进行分割的方法,就是它自身的最优分割方案.然后,证明聚合优化问题的的递归算法会反复地求解相同的子问题,而不是一直生成新的子问题,这也就证明它具备子问题重叠性质.
假设m[An]表示在聚合基数为n的前缀集An时所生成的最小误报,根据最优子结构可知m[An]=m[Ai]+m[An-i]+.考虑到子集Ai与An-i彼此关系对等,An的分割方案有种.由于最优分割方案必在其中,我们只需检查所有可能情况,找到最优者即可.因此,An最优分割方案的递归求解公式变为
通过观察该函数的递归调用树不难发现:在求解高层的子问题时,底层子问题的解会被反复调用,这也就满足了子问题重叠的特征.
定义15.聚合∞:Pi,j=Pi∞Pj,当且仅当(Pi⊆Pi,j)∧(Pj⊆Pi,j),且∀P′∈Ωp,s.t.,(Pi⊆P′)∧(Pj⊆P′),都有(Pi,j⊆P′).
定义16.聚合误报ρ(Pi,Pj),当且仅当,其中Pi,j=Pi∞Pj,也可记为ρ(Pi,j).
性质2.给定M-List={P1,P2,…,Pn},如果LCP(Pi,Pj)≥LCP(Pi,Pk),其中,Pi,Pj,Pk∈M-List,LCP表示最长公共前缀,那么ρ(Pi,Pj)≤ρ(Pi,Pk).
证明:鉴于最长公共前缀具备网络前缀的性质,已知LCP(Pi,Pj)≥LCP(Pi,Pk),可推出Pi,j⊆Pi,k,其中,Pi,j=Pi∞Pj,Pi,k=Pi∞Pk,根据定义16,就可得到ρ(Pi,Pj)≤ρ(Pi,Pk).
定义17.网络前缀序列空间被定义为一种三元组H=(I,S,P),其中,
· 前缀变量集I:I={P1,P2,…,Pm}为所涉及网络前缀的定义范围;
· 操作P:关于S中的前缀变量的操作集.
由于变量集实际上是由二进制字符串构成,因此,传统的绝大部分字符串操作对它仍然是适用的,例如属于(∈)、包含(⊆)、交(∩).然而,对于网络前缀集格来说,仅有这些操作是不够的,还需要扩展它的操作能力.首先,遵循全序关系的自反性、反对称性和传递性原则,给定pi,pj∈I,网络前缀之间可能存在的“=”、“>”和“<”关系重新定义如下:(1)若pi=pj,那么∀m∈[1,32],;(2)若pi>pj,那么∃m∈[1,32],使得且∀k<m,;(3)若pi<pj,那么∃m∈[1,32],使得且∀k<m,.
以图5 为例,已知M-List={AS1,AS4,AS8,AS9},W-List={AS2,AS5,AS10}和全部源自图1.树的构建分为两个阶段:M-List成员插入和W-List成员插入.每个节点都有两个属性:最优聚合前缀和误报量.前一阶段负责在尚未插入W-List的二叉树中标识最优聚合前缀,即将叶子和度为2 的节点的最优聚合前缀设置为True,如图5(1)所示;后一阶段负责在原有树的基础上标识误报量,如图5(2)所示.
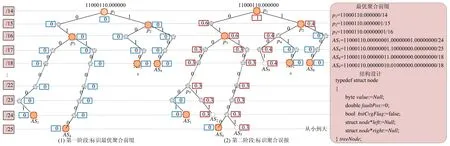
Fig.5 An example of BT图5 二叉字典树(BT)举例
定义18.二叉线索树(binary trie tree,简称BT)定义为BT(H.I),其中,H.I=M-List∪W-List表示无序的前缀变量集.BT 具备以下几个特征.
1)每条从节点到根的路径都对应一个网络前缀的网络号;
2)非叶子节点的左孩子取值为0,右孩子取值为1,这能使得树节点满足序列空间所定义的前缀比较方法从左到右依次增大;
3)以最优聚合前缀为判别依据,将树节点分为白、黑两种:若某节点与最优聚合前缀(包括M-List成员前缀和它们之间的最长公共前缀)对应,那么该叶子为黑色;否则,为白色;
4)每个节点前缀所累计的聚合误报用矩形框来标识到它的附近.
(2)给定二叉线索树BT,从中搜索|Rmax|个、彼此不相交且标识最优聚合前缀的树节点.
通过分析不难发现:不同的节点组合会累积不同的聚合误报.以图5 为例,假设|Rmax|=3,满足上述条件的树节点组合有两种:A={AS1,AS4,p2}和B={AS10,AS8,p3},其中,,也就是说A比B更高效.基于此,如何获取累积聚合误报最小的节点组合就成为第2 个需要解决的问题.
最优前缀选择问题可描述如下:给定|Rmax|个过滤器序列,通过遍历二叉线索树中拥有最优聚合前缀的节点来求取一种分配方案,使得累积聚合误报最小.首先,令Lp(k)表示当使用k个过滤器来覆盖最优聚合前缀p时可供选择的分配方案.当k=1 时,只有一种分配方案;当p=leaf时,也只有一种分配方案;当k≥2 时,分配方案可描述为两个子方案相乘的形式,而两个子方案的划分点在第k个过滤器和第k+1 个过滤器之间,k为1,2,…,|Rmax|-1中的任意一个值.基于此,可以得到如下递归公式:
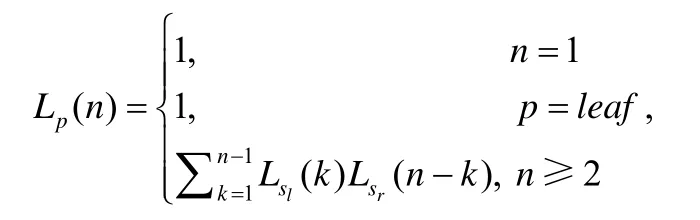
其中,sl和sr分别表示在p的左子树和右子树中离p最近的最优聚合前缀节点,而Lsl(k)和Lsr(n-k)则表示关于sl和sr的分配方案.该公式与矩阵链相乘问题的递归公式相似,它的序列增长速度接近Ω(2n),也就是说分配方案数量与n呈指数关系.因此,通过暴力搜索所有分配方案来寻求最优组合并不高效.然后,最优前缀选择问题也能够使用基于自底向上的动态规划方法来对它求解,其证明过程与定理2 相似.
(3)假设二叉线索树BT 已成功建立,每当有新成员加入或旧成员退出时,BT 都需要被更新.
例如:自治域s准备加入联盟,如果s包含于已选定的过滤器,那么只需将它插入到BT 即可;反之,除了插入操作,它还需要重新计算最优前缀.不过,它的计算开销与第(2)步相比减少了很多,原因如下:本次只需计算s的上游节点,其他结果可直接从之前的结果中提取.当s选择退出联盟时,首先从BT 中删除一个成员s,然后重新计算位于s上游的最优前缀.简言之,利用第(2)步已保存的所有中间结果,更新算法只需重新计算与新增节点相关的最优解.
3 性能评价
为了验证提出的EAGLE 方法,本文进行了理论分析和仿真实验,其中,第3.1 节将使用理论分析来证明方法的高效性,第3.2 节则通过基于真实网络拓扑的实验仿真来补充分析结果.
3.1 理论分析
通过与经典的反匿名联盟构建方法(包括E-Filtering,FAGLE 等)进行比较,本节将使用数学方法来分析EAGLE 方法的性能,涉及的指标包括部署激励(deployment incentive,简称Inc)、过滤器需求(filter demanded,简称FD)、通信开销(system communication overhead,简称SC)、存储开销(system storage overhead,简称SS)、规则优化误报(false positive of filter optimization,简称FP)、规则优化的时间复杂度(time overhead for filter optimization,简称TF)和规则优化的空间复杂度(space overhead for filter optimization,简称SF).
3.1.1 部署激励
部署激励指网络服务提供商ISP 对反匿名方法的部署意愿程度.鉴于ISP 部署新技术的动力是追求潜在的经济利益,Inc 的大小取决于部署收益和非部署收益两方面:前者是当一个自治域部署了反匿名方法后,其受到的伪造攻击中匿名报文减少比率的期望增量;后者是就一个尚未部署反匿名方法的自治域而言,其获得匿名报文的减少比率.很明显,Inc 与部署收益成正比,而与非部署收益成反比.基于此,本文采用对偶方式来定义部署收益f1>0 和非部署收益f2<0,而将Inc 定义为二者之和f1+f2,见定义5.在基于E-Filtering 的反匿名网络中,各自治域除了部署收益,还存在非部署收益,因此IncE-Filtering<f1;在基于对等过滤的反匿名网络中,各自治域只具备部署收益而没有非部署收益,因此IncMEF=f1.此外,根据定理2 可知,FAGLE 和EAGLE 的过滤效果在理想情况下是相同的,进而推出IncFAGLE=IncEAGLE.然而在过滤器短缺和规则优化精度等因素影响下,上述两个方法都会产生聚合误报ρFAGLE和ρEAGLE,从而使得部分自治域再次获得非部署收益.在M-List和Fmax给定的条件下,一方面,鉴于聚合操作是在过滤器需求量FD 超过过滤器供应量的时候发生的,FD 越缺乏,聚合执行越频繁,误报量也越大,可得ρ与FD 成正比关系;另一方面,鉴于聚合结果会受规则优化算法求解质量的影响,优化解的误报越高,聚合误报也越高,可得ρ与规则优化误报FP 也成正比关系.基于此,本文将ρ定义为一种以FD 和FP 为变量的单调递增函数.
根据第 3.1.2 节和第 3.1.5 节可知,FDFAGLE≥FDEAGLE和FPFAGLE≥FPEAGLE,因此,ρFAGLE(FDFAGLE)≥ρEAGLE(FDEAGLE),进而得到IncE-Filtering<<IncFAGLE≤IncEAGLE.
3.1.2 过滤器需求
过滤器需求是指在不执行规则优化的前提下,每个AS的边界过滤路由器平均配置过滤规则的数量,它会间接影响构建系统的部署激励性.给定一个反匿名网络ASN=(G,RA-stub),不失一般性,假设每个AS只有一个网络前缀,通过第1.3 节和第1.4 节所述,不难推出:E-Filtering 的过滤器开销FDE-Filtering=2;FAGLE 的过滤器开销FDFAGLE=2|RA-stub|+1;在EAGLE 中,最高层成员分为TMStub 和MStub 两类,其中,TMStub 内部成员(包括MStub和MTransit)的过滤器开销FDEAGLE-Intra=4,最高层成员的过滤器开销FDEAGLE-Inter=2×最高层成员数量+1.在|RA-stub|为常数的情况下,如果RA-stub的成员压缩比r=最高层成员数量/所有MStub 成员数量|RA-stub|,那么EAGLE的过滤器需求FDEAGLE可定义为一元整数分段函数,如下所示:

很明显,r越大,FDEAGLE越大,当r=1 时,FDEAGLE=FDM;r越小,FDEAGLE越小.需要说明的是,当r=1/|RA-stub|时,相当于最高层只有一个成员,FDEAGLE等于2.因此,FDEAGLE<<FDM.这就意味着:即使只有极少量MStub 聚集成为TMStub,与FAGLE 相比,EAGLE 在过滤器需求方面也会有明显优势.综上所述,FDE-Filtering≤FDEAGLE≤FDFAGLE.
3.1.3 通信开销
通信开销是指因构建反匿名网络而产生的数据通信量,它能反映构建系统对网络带宽的影响.在基于E-Filtering 的反匿名网络中,每个EStub 独立过滤匿名流,因此通信开销SCE-Filtering=0.然而,在基于对等过滤的反匿名网络中,因为MStub 之间需要通过交换彼此前缀来实现对等过滤,所以FAGLE 或EAGLE 会因成员加入和退出而产生通信开销(主要是AMM 模块与MStub 和MTransit 的交互次数).鉴于成员更新不会频繁发生,无论是FAGLE 还是EAGLE 构建系统,其通信开销都不会很大.即使这样,若能进一步降低通信开销,也会非常有意义.给定一个反匿名网络ASN=(G,RA-stub),鉴于FAGLE 扁平化的体系结构,每次加入或退出产生的通信开销都为|RA-stub|-1,因此,它的通信开销SCFAGLE=n×(|RA-stub|-1),其中,n表示成员更新发生次数.鉴于EAGLE 层次化的体系结构,每次成员加入或退出都有两种情况发生.
(1)如果生成新的TMStub 或分裂已有的TMStub,那么AMM 不仅需要通知最高层成员,还有TMStub 的内部成员.假设当前RA-stub的成员压缩比为r∈[0,1],且相关TMStub 由m1个成员组成(包括Mstub,Mtransit 和sub-TMStub),前者的最大通信开销都为(r×|RA-stub|-1),后者的最大通信开销为m1.基于此,它的最大通信开销为SCEAGLE=n×[(r×|RA-stub|-1)+m1].在联盟构建初期,有时会生成规模较大的TMStub,特别是该TMStub 所含成员数量超过构建联盟MStub 数量,即m1>|RA-stub|,此时,SCEAGLE略大于SCFAGLE;
(2)如果没有生成新的TMStub 或分裂已有的TMStub,那么仅需通知最高层,此时,SCE-Filtering<<SCEAGLE=n×[(r×|RA-stub|-1)]<<SCFAGLE.
证毕.
3.1.4 存储开销
存储开销是指因记录联盟成员信息而带来的内存开销,它能反映构建系统的可扩展性.在基于E-Filtering的反匿名网络中,成员之间互相独立,无需记录信息,因此SSE-Filtering=0.在基于对等过滤的反匿名网络中,构建系统需要收集和管理成员信息,因此FAGLE 或EAGLE 都会产生存储开销.
· 前者的构建系统包括3 个模块,分别为RCM,MSM 和AMM.其中,RCM 只记录ACL 规则参数,存储开销可忽略不计,SSF-R=0;MSM 需要记录所有成员的前缀,每个前缀占5B,那么SSF-M=5|RA-stub|B;AMM 除了成员前缀,还记录AS号与前缀的映射表,假设每个AS号占4B 且每个AS只有一个网络前缀,那么SSF-A=(5|RA-stub|+9|RA-stub|)B;
· 后者的构建系统除了上述3 个模块,还增加了MTM 模块.只有RCM 的开销没有变化:SSE-R=0,其余模块都有不同.
➢ 就MSM 来说,如果它位于联盟最高层且成员压缩比为r,那么SSE-MSM=(5r×|RA-stub|)B;反之,位于TMStub 内部的MSM 只需记录其上层提供商的前缀,因此SSE-MSM=5B;
➢ MTM 除了上述开销,还需记录下层客户前缀.假设每个提供商的平均客户数量为m,那么SSE-MTM=(5r×|RA-stub|+5m)B 或者SSE-MTM=(5+5m)B;
➢ AMM 需要建立面向全网的层次结构模型(如图1 所示),模型中,树节点的数据结构描述为{过滤状态位,TMStub 状态位,网络前缀,AS号,孩子(客户)指针},共占(11+4m)B.假设全网的自治域数量为z,那么SSE-A=z×(11+4m)B.通过统计可知z约为45k[31],进而可推出SSE-A是在可接受范围内.
综上所述,EAGLE 的MSM 和MTM 存储开销要小于FAGLE,而AMM 存储开销要大于FAGLE.不过,当所有AS都加入联盟时,它们的AMM 开销相差并不大.
3.1.5 规则优化误报
规则优化误报是指因运行过滤规则优化算法而带来的误报,这会间接影响构建系统的部署激励性.基于EFiltering 的反匿名网络对匿名包进行无差别过滤,不存在过滤器短缺问题,不需要规则优化,因此FPE-Filtering=0;基于对等过滤的反匿名网络对匿名包进行选择性过滤,过滤器需求量较大,需要规则优化.在M-List和Fmax给定的条件下,影响规则优化误报的主要因素包括地址权重的准确度σ和优化解的质量.鉴于EAGLE 和FAGLE方法都能求得最优解,误报率的计算公式可简化为FP=f(σ),σ越准确,FP越小;反之,则越大.根据定义12 可知,地址权重源于W-List,这也就是说,它的准确度σ取决于W-List是否客观.已知EAGLE 中的W-List成员是真实自治域,而FAGLE 采用排他法来推测W-List成员,后者增加了随意性,不难推出σEAGLE≥σFAGLE,因此FPEAGLE≤FPFAGLE.
3.1.6 规则优化的时间复杂度
规则优化的时间复杂度是指因运行规则优化算法而产生的的时间开销,这会间接影响构建系统的响应时间.基于E-Filtering 的反匿名网络不存在过滤器缺乏问题,因此TFE-Filtering=0.给定M-List,W-List和Fmax,FAGLE的规则优化算法主要包括建立树(build tree,简称BT)、裁剪树(prune tree,简称PT)和压缩树(compress tree,简称CT),其中,BT 需要进行(|M-List|+|W-List|)次节点插入操作,而每次插入最多执行H次比较,H表示树的高度,最大值为32,时间开销为o(32×(|M-List|+|W-List|));PT 需要对树至少执行5 次遍历,已知树节点数量最多为((|M-List|+|W-List|)×(|M-List|+|W-List|-1)/2),它的开销为o(5×(|M-List|+|W-List|)×(|M-List|+|W-List|-1)/2);CT 需要为每个树节点计算过滤器分配方案,最大开销为o(|M-List|×).基于此,=o(BT)+o(CT)+o(PT).需要注意的是:因为FAGLE 的规则优化算法不支持增量更新,所以每当有成员加入或退出,必须重新运行一次算法,也就是说假设先后有s个成员需更新,那么时间开销为TFFAGLE=s×.EAGLE 的规则优化算法主要包括建立树BT、前缀选择(prefix selection,简称PS)和成员更新(member update,简称MU),其中:BT 需要进行(|M-List|+|W-List|)次节点插入操作,而每次插入最多执行32 次比较,因此它的开销为o(32×(|M-List|+|W-List|));PS需计算每个最优聚合前缀节点的过滤器分配方案,它的开销为o(N×Fmax×(Fmax-1)),N表示树中最优聚合前缀节点数量,在最坏的情况下(即文献[9]提高的非平衡树,它的每个叶子节点几乎都对应一个最优聚合前缀),N=|M-List|-1;MU只需重新计算更新节点上游的过滤器分配方案,而且可重用已有分支的分配方案,因此它的开销为o(H×Fmax×(Fmax-1)),最坏情况下,H=Fmax-1.基于此,假设先后有s个更新成员,EAGLE 的时间开销为TFEAGLE=o(BT)+o(PS)+s×o(MU).通过比较不难发现,TFE-Filtering<TFEAGLE<<TFFAGLE,联盟成员更新越频繁,这种优势越明显.
3.1.7 规则优化的空间复杂度
规则优化的空间复杂度是指因运行规则优化算法而产生的内存开销,这会间接影响构建系统的可扩展性.基于E-Filtering 的反匿名网络不存在过滤器缺乏问题,因此SFE-Filtering=0.FAGLE 的规则优化算法会先后引入3种数据结构:ELCP 树T、误报率数组Z和过滤器分配数组R,其中:T的最大节点数量为(|M-List|+|W-List|)×(|M-List|+|W-List|-1)/2,内存开销约为o(1/2×(|M-List|+|W-List|)2);Z和R的最大长度为H×|M-List|,H表示树的最大高度,它们的内存开销为o(32×|M-List|).EAGLE 的规则优化算法先后引入3 种结构:ELCP 树T、误报率数组Z和过滤器分配数组R,其中:T的最大节点数量为(|M-List|+|W-List|)×(|M-List|+|W-List|-1)/2,它的内存开销约为o(1/2×(|M-List|+|W-List|)2);Z和R的最大长度为H×|M-List|,H表示树的最大高度,内存开销为o(32×|M-List|).基于此,SFFAGLE=o(1/2×(|M-List|+|W-List|)2+64×|M-List|).与FAGLE 相似,EAGLE 的规则优化算法也引入3 种结构,其中:BT 树的最大节点数量为32×|M-List|,最优解集Sec和误报率集f的最大长度也为H×|M-List|,内存开销为o(32×|M-List|).基于此,SFEAGLE=o(96×|M-List|).通过比较不难发现,SFE-Filtering<<SFEAGLE≤SFFAGLE.不过,FAGLE 中的T和Z都是中间数据,一旦运行结束,就会释放空间;而EAGLE 为了实现增量更新,上述结构都不会被中途释放.简言之,就是用空间换取时间.
3.2 仿真实验
鉴于第3.1 节的理论分析都是基于层次结构的网络拓扑,本节的仿真实验将在结构特征更加多样的真实网络拓扑上运行,以便对上述分析结果进行补充.考虑到真实环境的复杂性和实现的困难性,出于简化实验的目的,与文献[9]相同,本文也是通过搭建面向BGP 的网络仿真平台来模拟域间网络的IP 包活动情况.平台搭建过程分两步.
(1)对美国UCLA 大学收集到的自治域级拓扑数据集进行清理以及二次开发,获取可支持C-BGP 的网络拓扑[15];
(2)以真实拓扑作为输入参数,通过搭建面向网络模拟器C-BGP 的开发环境来构建自治域级网络[16].
该仿真平台运行在一台PC 虚拟机上(Intel 4core 2.2GHz processor,16GB of RAM,Parallels Desktop 12,Ubuntu 16.04).除了仿真任务,还需要提取网络特征、收集过滤器需求量以及优化过滤规则,上述计算任务都在另一台PC 机(Windows XP SP3,Intel 2core 2.40GHz processor,2.0GB of RAM,VS 2008)上运行.
与FAGLE 相比,EAGLE 的先进性在于提高了联盟成员的部署激励性,而这又取决于反匿名联盟的层次化程度.基于此,本节实验都将围绕能够反映联盟层次化的网络拓扑特征和影响部署激励性的因素(包括过滤器需求量、规则优化准确度)而展开.首先,从真实网络中提取与层次化相关的网络拓扑特征;然后,比较过滤器需求量的分布情况;最后,比较因规则优化而产生误报率的分布情况.
此外,E-Filtering 部署激励性差是因非部署收益,而与网络拓扑无关,因此它不必参与实验比较.
3.2.1 网络结构特征
根据第2.1 节的描述可知,反匿名联盟的层次化程度源于网络结构的层次化,而后者又取决于以下拓扑因素:AS之间是否存在大量C2P 关系;AS的前缀数量;上下层AS前缀之间的包含情况;AS的路由备份情况;上下层AS的累积高度.基于此,本节将运行以下5 组实验来反映真实网络的层次化程度.
(1)第1 组实验分别统计真实网络中Stub 域、Transit 域、C2P、P2P 占AS总量或AS商业关系的比重,结果见表1.在真实网络中,一方面C2P 关系所占比例明显要高于P2P 关系,这为联盟层次化奠定了基础;另一方面,Stub 域所占比例要远高于Transit 域,这又为大规模逻辑域的建立提供了可能;

Table 1 Basic parameters of topological structure (%)表1 拓扑基本参数 (%)
(2)第2 组实验用来计算真实网络中拥有不同前缀数量的AS占总数量的比例,进而统计它的补充累积分布函数,结果如图6 所示.虽然网络中存在少量前缀数量较大的AS,但是绝大部分AS的前缀数量都只有1 或2 个,这与第3.1 节的假设基本相同;
(3)第3 组实验用来计算上下层前缀存在不同包含关系的C2P 数量占总数量的比例,进而统计它的补充累积分布函数,结果如图7 所示.在真实网络中,上下层前缀之间存在包含关系的C2P 数量只占了10%左右,其中只有不足一半C2P 的前缀包含比例超过50%,这与第3.1 节的假设(供应商前缀包含客户前缀)略不相同.原因可能是:虽然设备商已提供CIDR 技术,但是由于AS管理协商困难或历史等原因,该技术并没有被广泛推广.但即使这样,依据EAGLE 的松耦合性,相比于FAGLE,它依然会带来少量收益.更何况在某些属权较为统一且CIDR 技术使用率较高的专用网络(例如教育网)上,C2P 关系的前缀包含比例必然会大幅度提升.这也就意味着,本文方法更适合教育网等专属网络;

Fig.6 Number of prefixes on different AS图6 不同自治域的前缀数量变化情况

Fig.7 Prefix coverage ratio in different C2P图7 不同C2P 关系的前缀包含比情况
(4)第4 组实验通过统计拥有多个提供商的客户数量占总数量的比例以及相关补充累积分布函数来说明单宿主或多宿主连接概率,结果如图8 所示.无论客户是Stub 域或Transit 域,单宿主连接概率都会接近50%及以上,这也就证明第3.1 节的假设基本合理.至于剩余的那些采用多宿主连接的客户,无论它们是因为网络前缀太多或路由备份,都可以在不影响EAGLE 性能的前提下,通过逻辑划分单宿主的方式来满足第3.1 节的假设条件.
(5)第5 组实验通过统计逻辑域中Stub 域数量占总数量的比例来说明不同高度逻辑域的生成概率,结果如图9 所示.在真实网络中,一方面,高度大于6 的逻辑域所占Stub 域的比例不到5%,而且大多是因为少量非常规的首尾相接的C2P 关系而造成的;另一方面,接近95%的Stub 域位于高度不足5 的逻辑域中,其中,3 层逻辑域就占了一半以上.基于此,本文在第3.2.2 节选择3 层逻辑域作为实验拓扑.

Fig.8 Number of providers on different multi-homed ASs图8 不同多宿主Stub AS 的提供商数量变化情况

Fig.9 Number of stub ASs on different levels图9 不同层次中Stub AS 数量变化情况
3.2.2 部署激励性
根据第3.1 节可知,过滤器需求量和规则优化误报会间接影响反匿名联盟构建方法的部署激励性.为此,本实验主要关注在相同规模的反匿名联盟条件下EAGLE 和FAGLE 方法中过滤器需求量和规则优化误报的变化情况.为了简化实验步骤、突出比较结果,依据第3.2.1 节已推测出的网络结构特征,本实验选则所有3 层逻辑域作为实验拓扑,而且将所有多宿主AS简化为单宿主AS.基于此,本节运行的两组实验如下.
(1)第1 组实验通过搜集不同联盟成员的过滤器需求量来统计它的补充累积分布函数,结果如图10 所示.鉴于EAGLE 方法的最高层成员过滤器需求量FDInter与TMStub 内部成员过滤器需求量FDIntra不同,需要分层搜集;而FAGLE 只包含一种过滤场景,无需分层.首先,在EAGLE 中,联盟成员的过滤器需求量从底层到高层逐层增加,且增幅较大.主要原因是为了完成对等过滤,除了本层前缀,上层的过滤规则还必须包含下层前缀.然后,从总体上看,与FAGLE 相比,EAGLE 的过滤器需求量要降低很多;而且随着层数增多,优势会更明显.然而,实验结果与第3.1.2 节理论分析结果略有不同,原因在于真实网络中上层前缀并不能完全覆盖下层前缀,进而无法简化过滤规则.最后,EAGLE 中最高层的过滤器需求量与FALGE 的几乎相同,因为它们的过滤原理完全相同;

Fig.10 Number of required filters on different members图10 不同联盟成员的过滤器需求量变化情况
(2)根据第3.1.5 节可知:鉴于规则优化误报取决于地址权重准确度,第2 组实验通过搜集所有BT 树节点权重的绝对误差来统计它的补充累积分布函数,结果如图11 所示.已知EAGLE 地址权重的计算方法是客观的,而FAGLE 带有不确定性,为了评估后者与前者的差距,本文提出了地址权重绝对误差.为了突显实验的客观性,一方面假设所有StubAS全部成为联盟成员,因此;另一方面,假设所有TransitAS都不是联盟成员,因为权重计算方法与联盟层次化无关.首先,从总体上看,EAGLE 与FAGLE 的地址权重之间确实存在绝对误差,根附近节点的权重误差甚至达到0.5 以上;然后,虽然绝大部分位于叶子和底部节点的地址权重误差都非常小,接近于0,但是仍存在少量误差较大的节点,这些节点最终会影响规则优化算法;最后,部分节点的地址权重误差可达到0,主要原因是下层自治域前缀之间不存在间隙,这意味着只有规划非常合理,FAGLE 与EAGLE 的规则优化误报才可消除.
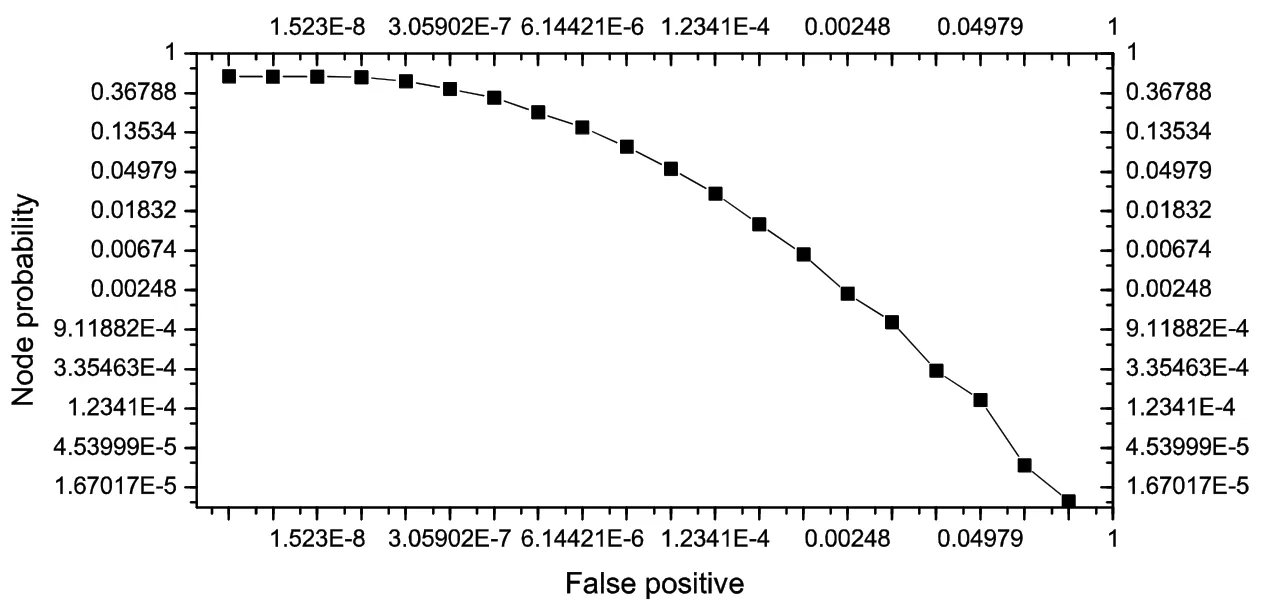
Fig.11 Rate of false positive on different tree nodes图11 不同树节点的过滤误报率变化情况
4 相关工作介绍
按照动作发生的先后顺序,反匿名技术可分为源地址验证和IP 溯源两大类:前者实现事前预防,后者实现事后追责[17,18].二者在功能上互为补充,缺一不可,本文主则要关注前者.学术界已经提出大量的源地址验证方法,经典的有DPF[1],IDPF[2],SAVE[3],SPM[4],Hidasav[5]和Passport[6]等.DPF 方法利用核心网络大都依据最短路由转发IP 包的特点,将凡是不应出现在当前路由上的IP 包当作匿名包,并过滤.然而为实现该功能,部分边界路由器必须掌握全网路由,这并不现实.为此,Hai 等人提出了IDPF 方法,通过配置BGP 路由策略,将原方法的强假设——最短路由弱化为可行性路由,增强了可部署性.然而,这又造成较高的过滤漏报率.SAVE 方法提出了一种新的通信协议,通过在网络路由节点上建立源地址和入接口的映射关系,彻底实现了基于路由的匿名包过滤.不过,该协议没有考虑路由系统的层次结构,源地址或路由变化引发的消息更新范围达到整个网络,这既会产生较大通信开销,又会影响过滤的准确性.SPM 是一种基于加密认证的源地址验证方案,每对通信自治域都需共享一个密钥,其中源自治域负责写入,而目的自治域负责检查.然而,该方法过于扁平化和单一化的体系结构会造成较大的存储和通信开销.为此,吴建平等人提出一种层次化的域间真实源地址验证方法,简称Hidasav,通过合理规划联盟层次和聚类整合,即使部署在大规模网络上,仍能保证验证的简单、轻权、有效.Passport 是一种基于对等密钥MAC 的端到端匿名包过滤方法,通过计算上游AS号对应的MAC 值并将它标记到转发包中,使得下游Transit 域能够对该包进行验证和过滤.通过分析上述方法不难发现:它们都是对现有通信协议进行革新,进而要求彻底升级当前路由器.然而,本文关注的出边界过滤方法E-Filtering 既不需要升级路由器,又不需执行额外操作,因此拥有更小的部署和计算开销.
尽管E-Filtering 具备上述优点并已在路由器广泛实现,但是它的部署率依然较低,其中一个重要原因就是它缺乏部署激励性.为此,刘冰洋等人近年来提出一种基于对等过滤的反匿名联盟构建方法,与已有方案相比,它在可行性和效率方面具有明显优势[9].而本文就是在此工作的基础上做了以下努力:通过改善它的过滤器开销、通信开销、计算开销和过滤规则优化精度,进一步提高方法的可扩展性,适应可增量部署.
5 结论与未来工作展望
出边界过滤是当前网络流行的一种基于过滤器的反匿名技术,但是因为搭便车问题,缺乏部署激励性,致使它一直无法大范围推广.基于对等过滤的域间源地址验证方法就是针对上述问题而提出的,该方法借鉴社会学的互动关系理论,通过建立反匿名联盟,使得未部署运营商从受益者列表中严格剥离.然而,过于扁平化、单一化的联盟体系结构以及过于随机的非成员判定方式和低效的成员数据处理方式,使得它在面对大规模网络时存在可扩展性问题.为此,本文提出一种层次化的反匿名联盟构建方法,通过减小过滤器、通信、计算开销以及提高过滤规则优化精度来增强可扩展性,实现增量部署.与已有方法相比,本文方法具备以下特征:1)构建了新型的层次化的反匿名联盟体系结构,避免成员之间建立不必要的全连接双向过滤关系,降低过滤器需求量;2)引入Transit 域对等过滤模块作为联盟边界,将每一层级联盟和外界成员隔离,减少因成员更新而带来的通信开销;3)设计高精度、可增量更新的过滤规则优化算法,在加快求解速度的同时提高解的质量.
未来的研究工作主要包括:
1)与公用网络(例如互联网)相比,本文的工作更适合于专用网络(例如中国教育网),主要原因如下:一方面,公用网络作为一个松散的商业联盟,很难集中管理所有自治域,更别说让它们服从于一个全局管理服务器AMM;另一方面,由于历史遗留或部署激励不足,公用网络的上下层自治域网络前缀并非完全具备层次结构,虽然本文方法在非层次网络模型下也能正常工作,但是其优势会有所下降.基于此,我们希望在今后,以当前本文研究为基础放宽前缀层次化的假设条件,尽可能设计一种去中心化的体系结构.其目标是在不久的将来为互联网环境中的部署和商业应用提供参考和借鉴,以便为网络用户提供可靠的反匿名机制;
2)虽然本文通过解决搭便车问题增强了传统E-Filtering 的部署激励性,但是在反匿名联盟构建初期,因为联盟成员较少,根据定义4 可知,新部署者只能获得较少的收益,这会再次影响构建方法的部署激励性.因此,如何利用早期少量成员所带来的市场压力刺激更多的新成员加入[19],使联盟构建方法从始至终都能保持较高的部署激励性是非常必要的.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京大学学报(自然科学版)(2022年1期)2022-02-21
吉林大学学报(信息科学版)(2022年1期)2022-01-14
计算机测量与控制(2021年9期)2021-10-08
农机质量与监督(2020年8期)2020-09-29
科技与创新(2019年13期)2019-08-12
汽车文摘(2018年12期)2018-12-05
发明与创新·大科技(2017年5期)2017-05-16
山东青年(2016年1期)2016-02-28
当代修辞学(2014年3期)2014-01-21
