
基于树结构的高维晶格编解码算法
2019-10-28 11:14别玉涛李兆玺张宇楠赵宏伟
吉林大学学报(信息科学版) 2019年5期
别玉涛, 李兆玺, 李 蛟, 张宇楠, 赵宏伟
(吉林大学 a.公共计算机教学与研究中心; b.通信工程学院; c.图书馆; d.教务处; e.计算机科学与技术学院, 长春 130012)
0 引 言
随着云计算、大数据技术的不断发展, 4K视频、虚拟现实(VR: Virtual Reality)、视频直播等应用模式的出现, 多因素促使光传输网不断向高速大容量发展[1]。如何在不增加干线重建成本的基础上, 实现光传输网向超高速大容量的平滑升级, 是当前光通信系统面临的主要问题之一。研究表明, 采用高阶调制格式可以有效提升系统传输容量[2]。
高维调制的基本思想是:将比特标签映射到N维实数向量代表的N维空间星座点上, 并同时应用光场中的模式[3]、偏振态[4]、载波[5]、时隙和轨道角动量等多个自由度对N维信息向量统一进行编码调制[6]。在复用的基础上, 通过进一步利用这些维度资源, 实现了在不损失谱效率的前提下, 最大化星座点间的最小欧氏距离, 从而增大了信号的功率效率。通过调制格式的优化, 较好地解决了谱效率与功率效率之间的矛盾, 大幅提升了现有系统的传输距离。
在高维调制中, 为获得较高的编码增益, 通常在高维晶格点中选取一定数目的格点作为星座点集[7], 将比特信息映射到这些选定的格点上的过程即为晶格编码(LC: Lattice Code), 逆过程即为晶格解码(LD: Lattice Decode)[8-9]。与二维调制相比, 调制维度的增加使相同谱效率下星座点集规模更大, 星座图结构更复杂。如何在高速传输下, 实现比特信息到大规模高维晶格点集的实时映射和解映射至关重要。因此, 高维晶格编解码技术是高维调制系统的关键技术之一。
1 晶格编解码策略
目前, 实现高维晶格编解码的方法主要有两类。
第1类:公式化方法。该方法的基本思想是:建立比特标签与晶格点的代数关系, 通过公式化方法使编码时间复杂度独立于星座点集规模。Conway等[10]提出了Voronoi编码, 首次实现了公式化晶格编解码。但由于Voronoi编码星座点集的选取与晶格的Voronoi区域的形状有关, 无法选取点数恰为M=2n(n∈Z+)的星座点集, 格点总功率也无法控制, 从而严重影响了Voronoi编码的实用性。为了弥补这一不足, Kurkoski[11]又提出了嵌套晶格编码方法, 该方法通过分别选取编码格和成型域, 将成型域内满足点数要求的格点作为星座点集, 实现了任意点数M的选取。但该方法要求编码格的生成矩阵是三角矩阵, 否则无法完成公式化编码, 但生成矩阵为三角矩阵的格, 其编码增益无法保证, 导致功率效率较低。Sommer等[12]提出了低密度晶格编码方法 LDLC(Low-Density Lattice Codes), 该方法的编码过程与 Voronoi编码相同, 解码时采用校验矩阵迭代译码实现, 迭代译码器的收敛性和复杂度受调制维度限制。同时, 该方法需要对编码格设计, 以确保校验矩阵的稀疏性。此外, 还出现了在LDLC基础上演变的迭代译码型方法[13-14], 这些方法虽然能实现公式化编码, 但译码器复杂, 对编码格也具有选择性。可见, 目前的公式化编码方法虽然能通过简单代数运算实现比特到星座点的实时映射, 但不能普适于各种高维调制格式。因此, 公式化晶格编码方法在高维调制系统中并没有得到广泛应用。
第2类:查找表方法。查找表法即是建立以比特标签为地址索引, 以高维星座点坐标为存储内容的映射表, 发送端直接查表完成高维晶格编码, 接收端经判决后查表完成晶格解码[15-18], 是二维调制常用的映射方法。由于其对调制维度、编码格、星座点数均透明, 具有通用性, 因此, 目前高维调制系统中依然采用查找表法完成晶格编解码[19-20]。然而, 由于现有的查找表方法中的比特标签与格点的存储是线性无序的, 只能顺序查找,M点的线性无序查找表, 顺序查表时间复杂度高达O(M), 而对于高维调制系统, 相同谱效率下的星座点总数M随维度陡增, 顺序查表会带来较大的时间延迟。要实现与16QAM相同的谱效率, 仅8维调制格式, 就要面临65 536个8维星座点的查表规模。这样, 即使中等谱效率的高维调制格式, 晶格编解码产生的时间延迟仍然很大, 无法满足高速大容量实时通信要求。因此, 在现有报道的高维调制系统的实验验证中, 只给出了维度较小, 谱效率和传输速率较低的实验结果[21]。目前, Ciena公司已投入使用的8维调制技术下的跨太平洋相干通信系统, 也仅实现了与BPSK(Binary Phase Shift Keying)和QPSK(Differential Phase Shift Keying)同谱效率的高速通信[22]。可见, 由线性查表完成高维晶格编解码带来的时间延迟, 严重阻碍了高维调制技术在高速大容量光通信系统中的应用。
为此, 笔者提出了一种基于树存储的低复杂度高维晶格编解码方法。该方法的基本思想是:利用晶格的空间分布规律, 提取高维晶格点的空间分布特征, 以这些特征为关键字, 将空间内无序的高维格点存储为有序的树结构, 通过建立树存储结构下更高效的索引算法, 将高维晶格编解码过程简化为由根到叶子的路径寻址过程, 路径即为地址;解码过程简化为特征检测, 路径恢复过程。该方法大大降低了高维晶格编解码顺序查表带来的时间延迟, 使高维调制系统向更高传输容量升级成为可能。
2 基于树结构的晶格编解码
由比特标签(索引)搜索到它所对应的星座点, 以及从接收星座点找到比特标签, 即是高维晶格编码和解码过程。笔者希望通过构造能体现星座点分布规律的特征向量, 以此特征向量为结点生成树结构。这样, 高维晶格编码过程就可以简化成从根到叶子的路径寻址过程, 而高维晶格解码过程可以通过检测接收信号的幅度特征和相位特征恢复出寻址路径以完成。
2.1 建 树
树是由结点和边组成的(可能是非线性的)且不存在任何环的一种数据结构, 完美二叉树是树中一种特殊的结构, 除了叶子结点外的每个结点都有且只有两个孩子结点, 即对层数为k的树, 结点总数是2k-1。二叉搜索树作为一种字典类型的数据结构, 能快速有效地支持搜索和插入操作, 对于有n个结点的二叉树, 操作的时间复杂度是O(logn)。笔者应用完美二叉搜索树进行晶格的编解码, 能有效减少执行时间。
建树的基本过程为:把M个星座点作为叶子结点, 为每个特征参量选取相应的权重值, 构造成代价值C, 然后以C为关键字排序建立星座点优先队列Q, 由自底向上的顺序按照贪心选择的原则一次确定当前要合并的2棵具有最小代价值的树, 并依次给组合的左分支指定为0, 右分支指定为1。按照这样的组合原则, 每次2棵具有最小代价值的树合并后, 都会产生一棵新的树, 并根据代价值算法重新为根结点计算代价值。将这棵树添加到优先队列Q′中, 同时从队列Q中删除已选择的两棵树, 经过M/2次合并后, 队列Q变为空, 完成一层建树操作。按照上述原则经过log2M次递归, 即可得到要求的树T。T是一棵二叉搜索树, 从根结点到每个叶子结点都有唯一的路径, 组成路径的01序列即为该叶结点的索引。
叶子结点的寻址过程即是编码过程。路径恢复过程即是解码过程。需要指出的是, 树结点的生成过程离线完成, 结点信息存储在发射和接收端用于高维晶格编解码, 编解码的在线处理过程只需按照树存储结构读取结点信息即可完成。
要建立树存储结构, 需要构建以晶格分布特征为关键字的树结点。高维晶格编解码过程可通过这些特征向量包含的信息完成寻址。如何利用晶格的空间分布规律设计特征向量, 以尽量小的向量维度包含可实现寻址的有效信息, 是构建树结点特征向量的关键问题。根据晶格的几何特点, 高维空间格点按照一定几何规律分布在多个超球壳上, 格点在幅度, 偏振态, 相位等方面具备一定规律性。笔者选取能最大程度表征格点特征的参量组成特征向量, 比如星座点的层半径、功率分配比、坐标相位角等, 并将这些分布特征融合成用于索引的特征值。
设需要编码的星座点集合为ζ={χ1,χ2,…,χi,…,χM},χi(i∈[1,M])为N维实数向量。χi的幅度特征向量、功率分配比和相位特征向量分别为r、p、α和β, 计算代价值时将按照顺序给每个关键字分配不同的权重值, 并融合成为一个实数代价值C, 最后以代价值排序。对于二叉树T, T.lChild和T.rChild分别表示左右子树。
树结构生成步骤:
1)以χ1,χ2,…,χM为叶结点, 按照C升序排列, 构造M棵只有一个叶结点的二叉树Ti, 从而得到一个二叉树的有序队列Q={Τ1,Τ2,…,ΤM}。
2)从队列Q中选取最前端的两棵二叉树Ti、Tj分别作为左、右子树构造一棵新的二叉树Tk(左子树Ci小, 右子树Cj大), 由代价函数重新计算根结点Tk的代价值Ck, 并指定左分支为0, 右分支为1。
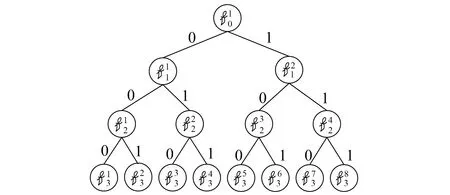
图1 由8个星座点建立的树结构
3)在队列Q中删除Ti、Tj, 并将新建立的二叉树Tk加入到有序队列Q′中。
4)重复2),3)两步, 直到Q为空。再令Q=Q′,Q′={}。
5)重复2),3),4)3步, 直到Q′中只剩下一棵二叉树时, 这棵二叉树便是所要建立的编解码树T。由根结点到叶结点χi的路径即为该星座点的索引号, Index(χi), 长度为树的高度log2M-1。
定义代价值C的计算方法如下
C=w1r+w2p+w3α+β
(1)

2.2 编 码
编码过程是根据索引码查找星座点的过程。对于给定的索引码Index(χi), 根据索引号对应到树结构的路径上, 从而找到对应的星座点。
编码算法
输入:T是由星座点建立的树, Index(χi)是星座点对应的索引码。
输出:索引码对应的星座点。
变量:flag标识当前索引码的位置。
begin
flag=0;
while (T!=null)
flag=flag+1;
if Index(χi)[flag]==0
T←T.lChild;
elseT←T.rChild;
end
end
returnT;
end
编码算法中, 根据索引码的01序列, 从根结点开始查找叶子结点, 当前索引码为0时, 查找左孩子, 索引码为1时, 查找右孩子。对于M个叶子结点的完美二叉树, 路径(索引码)长度n=log2M, 算法执行过程中, 加法运算2(n+1)次, 乘法运算2n次, 共计4n+2次运算。而查找表方法在编码时, 无需乘法运算, 但是加法运算需要24n+4n次, 树结构的编码算法复杂度明显优于查找表法。
2.3 解 码
解码过程是给定星座点的坐标, 通过确定该星座点是树结构中哪个叶子结点, 进而确定根结点到该叶子结点的路径(即索引码)的过程。算法Search(T,χ)实现在二叉树T中递归查找结点χ。
算法Search(T,χ)
输入:T是待搜索的完美二叉树的根结点,χ是待查找的星座点。

Begin

while(T!=null)
计算qi;
if(qi==0)
else
end
end
end

(2)

解码算法中, 先计算待查找路径的星座点的代价值, 然后根据式(2)的策略确定当前索引码的码值, 最终构成长度为n=log2M的索引码。该算法执行过程中需要加法运算5n(5n+13)次, 乘法运算5n(n+11)次, 共计5n(6n+24)次;而查找表法在解码时虽不需要乘法运算, 但加法运算次数达到46(24n+4n)次, 树结构算法在解码时仍明显优于查找表法。
3 实验仿真与性能分析
3.1 实验条件设定
仿真实验在Matlab软件上进行, 选取D4晶格前10层的星座点坐标生成了1 080个星座点, 按照代价函数的计算结果进行升序排列, 截取前1 024个星座点, 创建一棵11层的完美搜索二叉树, 最底层的1 024个叶子结点从左至右按照代价函数值升序排列。
星座点的幅度特征向量r选用星座点距离超球体中心的欧氏距离的平方值, 功率分配比p选择四维坐标的前两位发送功率与星座点发送功率的比值, 相位特征向量α采用四维坐标的前两位形成的相位角,β采用后两位形成的相位角。
3.2 实验结果及分析
1)算法复杂度。图2对比了查找表方法和树结构算法在编码(映射)和解码(解映射)过程中所需要的总计算次数, 其中横轴n表示每符号含有的比特数,n=log2M(M为星座点数),纵轴表示基本操作次数。通过图2可以看出, 算法复杂度上, 查找表算法随着星座点数量的增加, 计算复杂度呈几何倍数增长, 而树结构算法随着星座点数的增多, 计算复杂度并没有明显变化, 计算时间显著优于查找表法。

a 映射复杂度 b 解映射复杂度
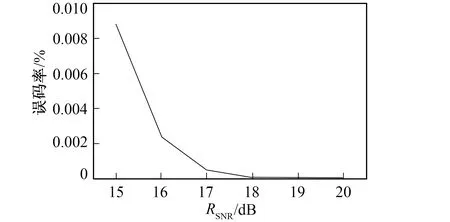
图3 误码率曲线图
2)误码性能分析。对比实验分别用查找表法和树结构算法, 对随机产生的40 960个码元进行编码并解码的操作, 图3给出了误码率随信噪比的变化曲线。从图3中可以看出, 随着信噪比的增加, 误码率不断下降, 当信噪比达到15 dB时, 误码率达到10-3, 可见,该方法可以实现有效编解码。
4 结 语
针对高维调制技术时间延迟的问题, 提出将数据结构理论中的树形结构用于高维晶格编解码中, 通过提取高维晶格点的空间分布特征, 将空间内无序的高维格点存储为有序的树结构。实现了将高维晶格编解码过程转化为树存储结构下的路径搜索和恢复过程的新方法。突破了现有高维晶格编解码时间复杂度高产生的延迟大, 对传输速率和谱效率的限制, 从根本上改变了高维晶格编解码的研究理念。在特征向量的选取和组合方式, 以及代价函数的构造上进一步改进优化, 将会降低高维晶格编解码的误码率。
猜你喜欢
电子制作(2022年16期)2022-09-23
现代计算机(2021年14期)2021-07-09
微处理机(2020年5期)2020-10-20
计算机与数字工程(2020年8期)2020-10-14
空间科学学报(2020年4期)2020-04-22
传播与制作(2019年9期)2019-10-20
学习与科普(2019年21期)2019-09-10
民用飞机设计与研究(2019年2期)2019-08-05
——基于二叉树的图像加密
数字通信世界(2019年4期)2019-06-03
浙江大学学报(理学版)(2017年1期)2017-02-07
