
基于射线穿透法的GPU 并行阶梯型有限差分网格生成算法*
2020-04-09 11:10麻铁昌许香照马天宝
爆炸与冲击 2020年2期
李 平,麻铁昌,许香照,马天宝
(北京理工大学机电学院,北京 100081)
爆炸力学是武器装备研发,工业安全防护等问题的理论基础。爆炸的特点为在极短的时间内,爆炸场中各个物理量发生巨大的变化。爆炸过程的研究十分复杂,通常伴随有化学变化、物理变化和核变化等。因此在理论研究和实验研究中都存在诸多困难。数值计算是研究爆炸与冲击问题的重要手段之一。计算爆炸力学是以计算机为工具,探索爆炸力学的规律,丰富力学数据,解决爆炸力学问题。随着计算机科学的飞速发展,数值模拟以其精度高,经济成本低,揭示规律清晰完整等诸多优点越来越成为人们的研究热点。爆炸力学的数值模拟按照其采用的坐标形式可以分为欧拉方法和拉格朗日方法。基于欧拉坐标的有限差分方法是爆炸与冲击问题数值模拟的常用方法[1],其特点为在固定的阶梯型网格上进行有限差分计算,网格位置和形状不会随着计算而改变,克服了拉格朗日方法中可能出现的网格畸变问题,因此能够很好的模拟多物质的大变形问题[2-3]。本文涉及的有限差分计算中使用的网格数据是一种阶梯型笛卡尔网格,其特点是使用正六面体对整个区域进行离散,不同物质被离散为不同属性的单元,不同属性单元构成的不同区域之间的交界面为阶梯形[4-5]。相比于传统贴体网格,阶梯型有限差分网格的生成速度快,无需手动划分区域,生成过程自动化程度高。阶梯型有限差分网格是一种结构网格,每个单元之间的连接关系固定并不随着计算而变化,可以使用像所有结构网格一样的IJK 下标来访问网格单元和节点。它适用于所有的有限差分离散方法。
阶梯型有限差分网格生成方法主要包含两种:一种是射线穿透法,这种方法即根据网格步长作出一系列射线直接与实体模型进行求交计算[6],这种方法的优点是思路清晰,步骤简单;但是由于空间中的射线与几何模型的求交计算会消耗大量的时间,因此算法运行效率不高。切片法的思路借鉴了快速成型加工领域的方法[7-8],用一系列互相平行的平面截取几何模型,得到一系列二维平面中的封闭轮廓线,进而将三维空间中的几何问题转换成二维平面上的问题;此方法省去了部分几何判断、查询占用的时间,网格生成效率相对较高。但是此种算法执行过程中网格线的生成和介质属性映射两个主要步骤耦合在一起,算法执行的稳定性和并行能力都有待提高。在三维有限差分计算中,网格尺寸越小,网格构成的计算空间与实际物理空间越接近。因此为了保证数值模拟的精度,进行三维有限差分计算通常需要至少千万量级的网格[9],如何高效的生成数量如此巨大的数值网格一直是研究热点之一。MacGrillivray[10]使用高效的数据存储方法和高效的空间线面相交判别方法实现了万亿量级的网格生成,网格生成过程内存管理方法合理,使整个网格生成过程可以在小型工作站中完成。Berens 等[11]提出了非均匀笛卡尔网格的生成方法,详细描述了根据计算需求而对网格尺寸的选取方法。以上都是串行的网格生成方法。并行计算是提高网格生成效率的最常用的方法。在计算集群中运行的程序最常使用的是利用MPI(message passing interface)库进行并行计算,在小型工作站中常用的是OpenMP 库实现共享内存的并行计算,Ning 等[12]使用多线程技术实现了并行阶梯型有限差分网格生成,但是其采用的是切片法生成网格,单个几何体分别由单个线程执行计算,并行化程度较低,对大型的网格数据生成效率不高。Ishida 等[13]提出采用OpenMP 并行生成自适应笛卡尔网格。Foteinos 等[14]将并行计算应用在“图到网格”的网格生成算法中,采用分布式集群计算机对算法进行加速。
最近,GPU (graphic processing unit)并行技术吸引了各个领域研究者的注意,不仅仅被应用在图形图像相关算法,还被广泛应用于各种通用计算中。相对于CPU (central process unit)并行,GPU 对于大规模密集型数据的并行计算拥有巨大的优势。许多学者也对将GPU 应用到网格生成领域做了相关研究。Qi 等[15]利用GPU 并行实现了二维Delaunay 非结构网格的生成。Park 等[16]提出了基于GPU 生成3D 自适应笛卡尔网格的方法。Schwarz 等[17]提出了一种方法使用GPU 来生成八叉树结构,并将其应用于计算机图形学中的像素化显示。但是他们使用的基于三角形并行化的方法生成的单元数量较少,不适用于进行有限差分计算。根据文献调研情况,目前运用GPU 并行技术生成三维笛卡尔网格的研究很少。本文中提出的并行算法能够应用GPU 并行技术在短时间内生成大规模的阶梯型有限差分网格,并且对多个拥有复杂外形的几何体的大规模网格生成过程有很高的效率和准确性。
本文中,选用STL (stereolithography)文件来存储几何实体信息,并用其作为算法的输入文件。在STL 文件中,几何实体被离散为三角面片的形式,所有三角面片的三维坐标和法向量都存贮其中[18]。在一些切片算法中,STL 文件需要过滤冗余几何信息并重构出拓扑信息。对于射线穿透法,STL 文件中的信息不再需要任何的处理,STL 文件中的三角形集合T 可以直接作为算法的输入。阶梯型有限差分网格生成算法的核心部分就是由T 作为输入生成整个计算域大小的数据场F,F 中每一坐标点的值为介质标志。
1 射线穿透法
1.1 计算域设置
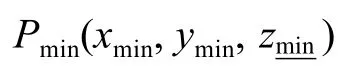
(1)计算域的边界线和计算域内各个几何体的AABB 包围盒的边线同时也是网格线。三维空间中几何对象的AABB 包围盒为包含该对象,且边平行于坐标轴的最小六面体。
(2)计算域内同一维度方向上的网格尺寸s 相同。
条件1 和条件2 同时限定了整个计算域中网格尺寸大小相同。同时,条件1 消除了在几何体AABB 包围盒边缘存在的狭窄网格单元。为了满足上述两个条件,网格单元尺寸需要根据输入的尺寸进行优化。如下列方程分别为X、Y 和Z 方向上的网格尺寸函数:
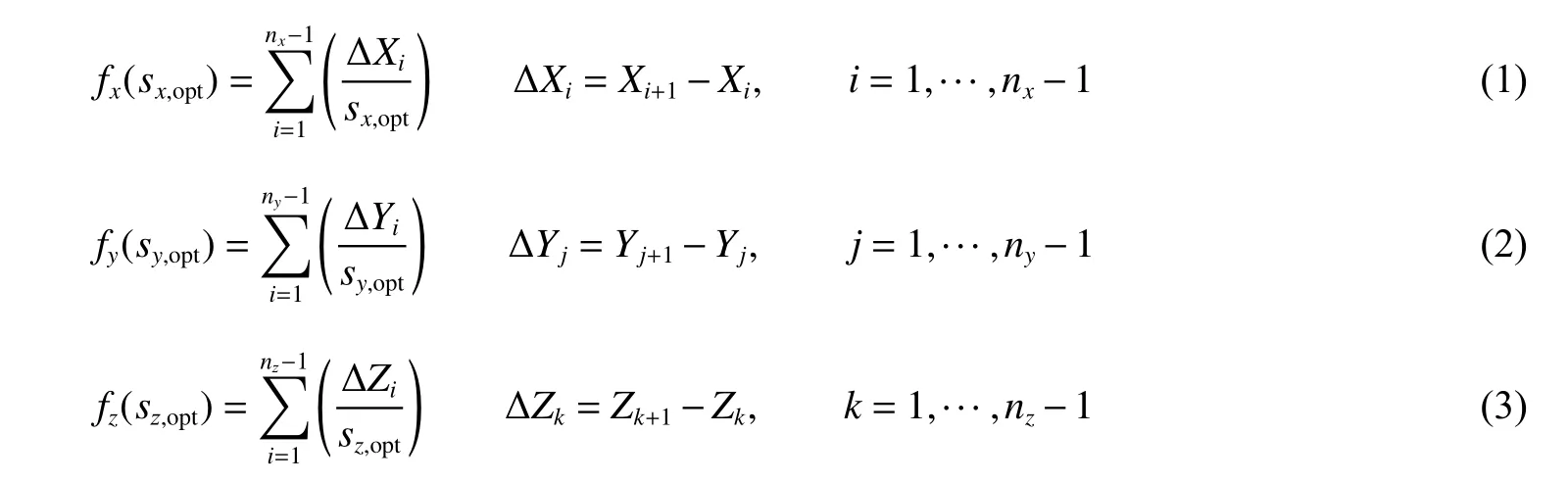
式中:sopt为待优化的网格尺寸,nx、ny和nz分别为X、Y 和Z 方向上的网格单元数,ΔXi为计算域被几何体AABB 包围盒边界线分割出的子计算区域。
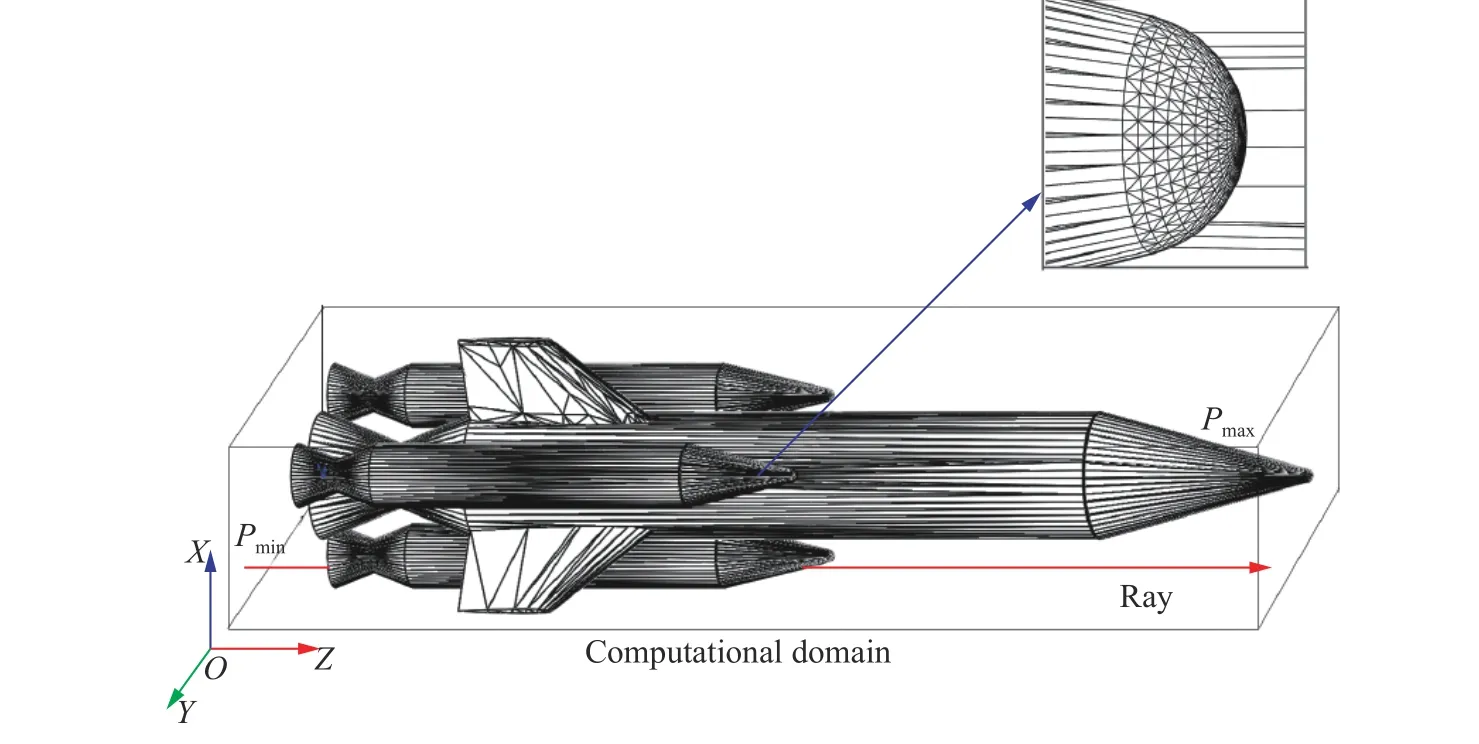
图1 三维计算域,内部几何体和几何体局部图Fig. 1 Three-dimensional computational domain, the geometries in the domain and the details of the geometry
优化方程(1)~(3)中的sopt,计算使得3 个方程同时取得最小值同时又不大于初始的网格尺寸s 的sopt,即为优化后的网格单元尺寸。
获得优化的网格单元尺寸后,可以按照下列公式生成整个计算域中网格线:
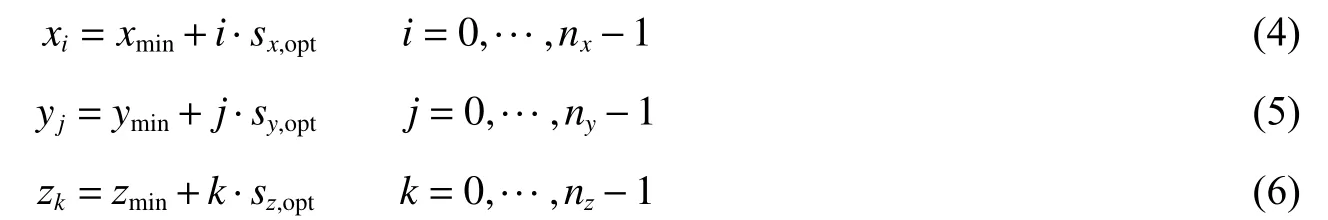
1.2 射线与几何体表面的相交判断
对于任意一条射线穿过计算区域,可能与一些三角面片相交,也可能不相交。如图2 中所示,由投影平面出发的射线穿过计算区域与几何体相交,射线簇与几何体的相交计算的本质是空间中射线r 与三角面片的相交计算,V1、V2和V3为三角面片3 个顶点。为了计算射线与三角面片的交点,首先要判断射线与哪些面片相交。为了减少机器误差,这里采用一种没有除法计算的判断方法。对于一条射线和一个三角面片,通过下列方程计算射线与三角面片第i 条边的相对位置Oi:
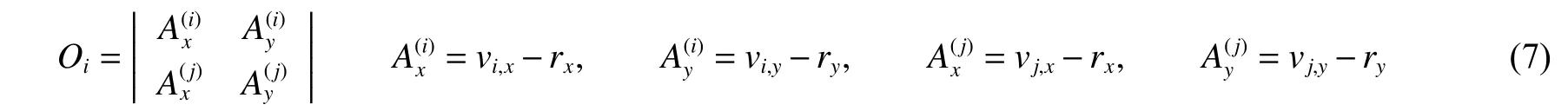
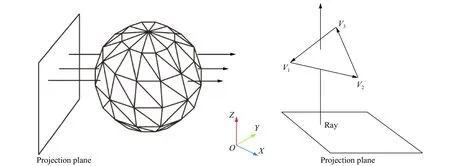
图2 射线穿透法原理(以XY 平面为射线投射平面,Z 轴方向为射线方向)Fig. 2 Principle of ray casting method (set the XY plane as the projection plane, and the Z dimension as the ray direction)
Oi表示射线与三角面片的一条边的相对位置,如果Oi>0,则射线r 在边V1V2的左侧,如果Oi<0,则射线r 在边V1V2的右侧,Oi=0 时,射线与该边相交。分别计算三角面片三条边与射线的Oi值,如果Oi全部为正或全部为负值,则射线在3 条边的同侧,表明射线穿过了三角形,否则射线与三角形不相交。
通过一条穿过几何体的射线将会计算出多个交点,将这些交点按照射线方向排序,得到交点集合P。在三维空间中,直线与三角面片的位置关系可分为7 类:穿过、错过、穿点、穿边、平行、共面不相交和共面相交。很显然,穿过和错过可以由上述方法判断并计算交点。穿点是直线穿过三角面片任意一顶点,同时由于三角面片组成的是闭合几何体,此直线一定也穿过其他三角面片的顶点。在这种情况下,在判别式中,O1、O2、O3中有两个为0,另外一个不为0。交点计算公式仍然成立,但是会计算出多个相同的交点,在排序后所得的集合P 中,相同的交点只保留一个。对于穿边的情况,依据相同的原理,O1、O2、O3中有一个为0,另外两个同号。交点计算公式依然成立,在这个位置会有两个交点,在P 中保留其中的一个。在直线与三角面片平行时,O1、O2、O3一定不会符号相同,因此会判定为错过,不计算交点。当直线与三角面片共面不相交时,O1、O2、O3全部等于0,会判定为不相交,不计算交点。当直线与三角面片共面并穿过面片时,说明这个面片为几何物体的边界,边界上不会有网格点,因此判别式可以正确将其判断为不相交。
综上所述,在穿点与穿边的情况中,会出现一项或两项Oi为0,这种情况同样应视为相交,计算出的交点可能会在其相邻三角面片中再次出现,使用上述原理仅保留一个交点即可。
2 GPU 并行网格生成策略
三维空间中几何图元的搜索、查找和相交计算是射线穿透法的主要耗时部分。同时,这些计算都可以转化为某一简单计算流程的叠加。因此,将这些耗时巨大的计算转移到高度并行化的GPU 中并行执行可以大大提高算法效率。GPU 采用单程序多数据(single program/multiple data,SPMD)模型,其目的就是通过其内部大量的线程、线程束、线程块和线程网格等并行层级来执行大量的、比较简单的计算任务。GPU 并行算法的效率主要由2 个部分决定:(1)单个线程中计算时间;(2)主机内存与GPU 内存数据交换时间。
下面,针对上述两部分分别优化并行算法。
2.1 几何数据传输优化
下面以一个单独几何体G 为例说明数据传输过程。作为输入,STL 中的三角面片数据被存储到内存序列中,以数组T 表示。几何体G 的AABB 包围盒被一系列水平平面二次划分为M 个包围盒子区域。随后,将三角形序列T 按照其在空间中所属的包围盒子区域分解为M 个子三角形序列,将一个包围盒子区域的信息SubAABB 和与其对应的子三角形序列Tsub作为一个批次(batch),则输入数据被划分为M 个批次,每个批次都包含了处理每个批次中所有射线计算所需的全部数据。随后,将M 个批次数据逐个传入GPU 内存中执行并行计算。每一个线程执行计算后的输出数据为一条射线r 方向上的网格个数序列Cr,Cr中元素的数量表示射线r 方向上的总网格数被几何体分割出的段数,每段的网格数由Cr中一个元素表示。几何体G 的AABB 包围盒内全部射线对应的网格个数序列的集合可以表示为C={Cr1,Cr2,···,Cri,···,Crn},C 中包含的数据即可表示几何体G 的网格数据。对于计算域中的每一个几何体,重复上述过程,将每个几何体计算所得的网格个数序列集合C 合并在一起,即可得到整个计算域中的阶梯型有限差分网格划分结果。上述数据转换与计算过程如图3 所示。图中左上部分表示待计算区域及计算区域中的几何体,其中几何体以三角面片形式被表示。右上图表示几何体的AABB 包围盒构成的子计算区域。图中下半部分表示几何数据及边界条件等被组织为数据批次,并逐批次传如GPU 进行计算的并行计算流程。
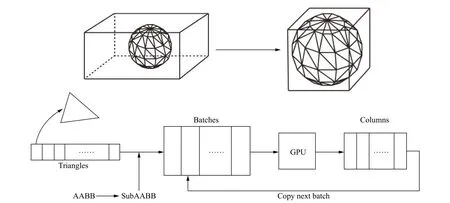
图3 三维几何数据转换与并行计算过程图Fig. 3 Diagram of three-dimensional geometric data conversion and parallel computing process
2.2 线程内射线生成
GPU 并行计算开始执行之后,大量的线程会同时执行相同的指令,这些指令的设计直接影响并行算法的并行执行效率。对于域中的每个几何体,网格线和射线的分布可以通过AABB 包围盒及包围盒子区域的对角点坐标(x1, y1)和(x2, y2)与网格尺寸sx和sy来确定。当GPU 执行某个计算任务时,通常需要将输入数据从主机内存复制到GPU 中的设备内存。为了避免主机和设备之间数据传输的时间消耗和GPU 内存中的容量消耗,可以在GPU 中的每个线程中自动生成网格线和射线的起点坐标。
假设几何模型G 的AABB 包围盒可以表示为两个对角点坐标(x1, y1)和(x2, y2)。X 与Y 方向上的网格尺寸可以分别表示为sx和sy。在GPU 的每个线程中,当前线程开始计算时,可以通过下列公式生成射线的起点坐标(xr, yr):
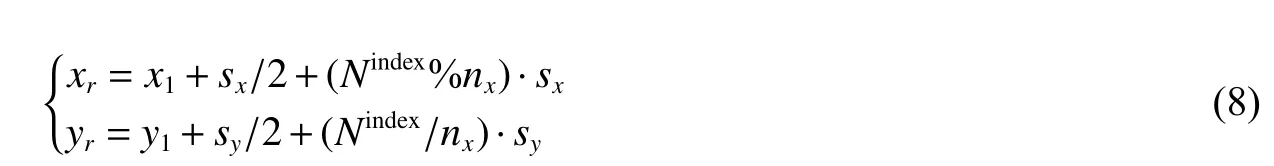
式中:Nindex和nx分别表示GPU 中当前线程的索引序号和当前包围盒子区域中X 坐标方向的网格数。Nindex和nx分别可以由下式计算:

生成射线起点坐标以后,应用1.2 节中所述方法判断射线与哪些三角形相交并计算出交点坐标。将各个交点Z 坐标连同计算域Z 方向的最大、最小值按照由小到大的次序排列,可得到Z 坐标序列(0<i<2n)。由于计算域中几何体都是封闭的,交点个数必定为偶数,以2n 表示。则对于射线r 方向上所有的网格单元,第i 个网格单元的属性可以按照下列公式赋值:

式中:sz为计算域Z 方向上的网格尺寸。这一步骤通常称为介质属性映射。本节所述计算全部由单个线程独立完成,计算流程如图4 所示。

图4 单个GPU 线程内数据计算流程Fig. 4 Data computing process in a single GPU thread
3 数值试验结果和讨论
应用文中提出的基于射线穿透法的GPU 并行网格生成方法,使用Visual C++和Nvida CUDA[19]编制基于GPU 的并行阶梯型有限差分网格生成程序并对程序进行性能测试。所用测试服务器配置如下:CPU 型号,Intel Xeon E5-2650 v2(2.6 GHz);GPU 型号,Nvidia Quadro K2200;显存容量,4 GB。
3.1 网格生成结果与可视化
如图5(a)所示桥梁模型包含3 种材质,由多个几何体组合而成。模型总计包含24 184 个三角面片,被划分为1.15×109个网格单元。总计用时21.45 s。图5(b)为网格图,由放大后的局部网格图可以清晰地看出,三角面片构成的几何模型被转变为由不同材质的六面体单元构成的阶梯型有限差分网格。
为了验证并行算法的网格生成效率,将上述模型分别离散为不同网格规模的阶梯型有限差分网格,并对比网格生成时间与传统串行射线穿透法的网格生成时间。如图6 所示,桥梁模型分别被离散为1.44×108、1.15×109和9.2×109个网格单元。可以看出,对同一计算模型应用本文提出的GPU 并行算法的网格生成效率远高于传统串行CPU 算法的执行效率。传统串行算法在生成网格规模达到1×1010数量级的时候耗费的时间超过2 000 s,这无疑大大影响了建模与计算时的灵活性,在很多需要多次调整计算域参数的数值模拟中是难以接受的。另外,表示这种数量级的网格数据通常可以达到4 GB 以上,本文中提出的分批次的数据处理方法使得算法能够处理的数据规模不依赖于GPU 内存大小,使程序在常见的4 GB 显存容量的GPU 中可以高效执行。CPU 的硬件发展已趋于稳定,短时间内难以有巨大的提升。本文中提出的并行算法可以解决这些瓶颈,使得在拥有一颗普通GPU 的PC 机上就足以进行1×1010数量级的网格生成。对于不同的初始几何模型,网格生成算法的效率应该不受模型的复杂程度的影响。表1 中展示了3 种不同的初始几何模型分别包含19 202、78 354 和95 062 个三角面片,分别生成相同规模(1×109个网格单元)的三维笛卡尔网格。表中分别给出了CPU 串行算法和GPU 并行算法的生成时间。可以看出,对于复杂程度不同的几何模型生成相同规模的网格,本文提出的并行算法的效率是传统串行算法的8~11 倍。
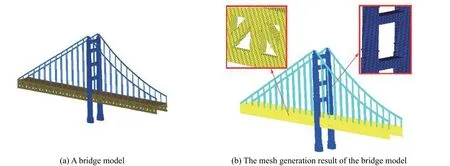
图5 桥梁模型及其阶梯型有限差分网格生成结果图及细节放大图Fig. 5 A bridge model, the finite difference mesh generated and the details of the mesh
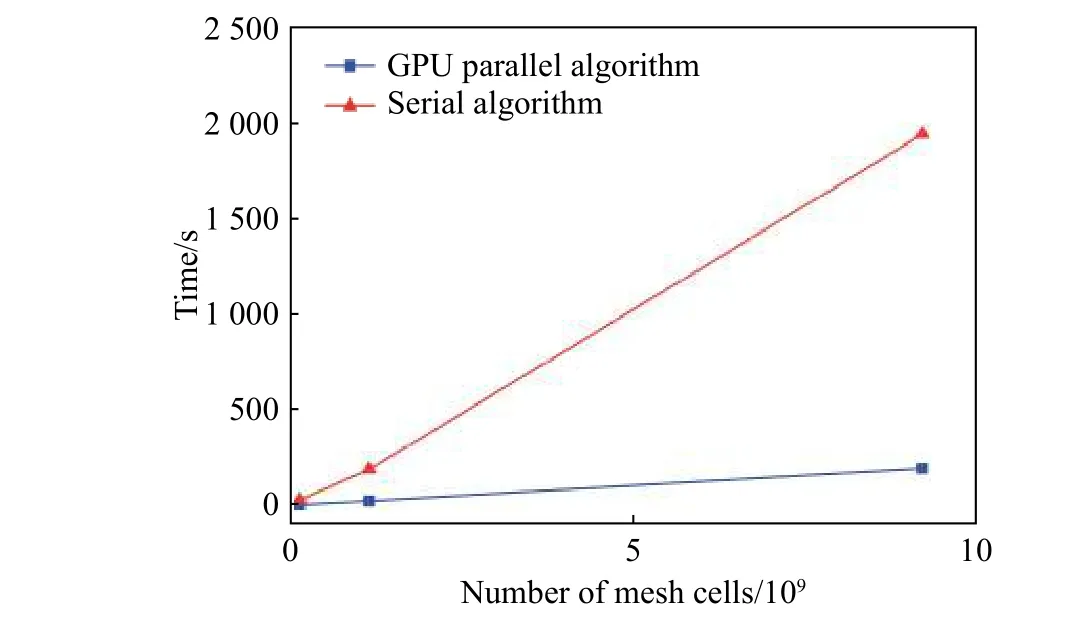
图6 本文提出的并行算法与传统算法的网格生成时间比较折线图Fig. 6 Mesh generation time comparison curve between the proposed parallel algorithm and the traditional algorithm

表1 不同模型生成相同数量网格单元(1×109)的执行时间Table 1 Generation times of different models with the cell number of 1×109
综上所述,本文中提出的并行算法的网格生成效率是传统串行算法的8~11 倍。随着网格数量级和模型复杂度的增高,并行算法节省的网格生成时间越来越多。
3.2 数值模拟结果
工厂厂房内的爆炸是工业生产中危害巨大的一种安全事故。厂房合理的结构设计是降低厂房爆炸造成的损失的有效手段。在这一节,通过文中提出的并行阶梯型有限差分网格生成方法,对某工厂厂房进行网格划分,并对厂房内爆炸问题进行数值模拟研究。如图7 所示,计算域中包括墙壁、立柱、屋顶、炸药和空气5 种介质。厂房为一座两层建筑,上下两层有楼梯连接,64 kg TNT 炸药位于厂房一层中间位置。为了应用有限差分法进行数值模拟,将计算域离散为三维阶梯型有限差分网格,如图8 所示。为了清晰显示网格生成结果,空气网格被隐藏掉,图8 中的炸药,墙壁、立柱和屋顶4 种介质分别以4 种颜色显示。网格生成单元总数为1.5×108个。并行生成消耗总时间为2.47 s。
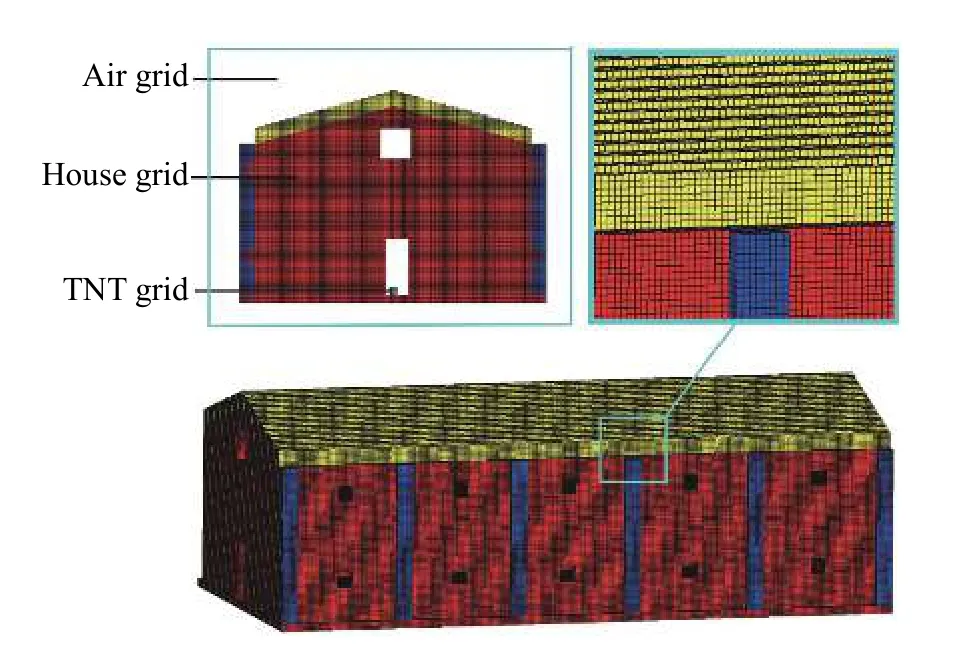
图8 某厂房三维阶梯型有限差分网格Fig. 8 Three-dimensional finite difference mesh of a factory model
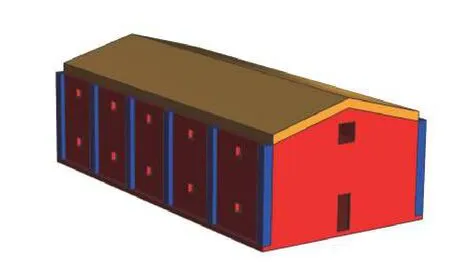
图7 某厂房三维几何模型Fig. 7 A three-dimensional factory model
应用北京理工大学爆炸与科学国家重点实验室自主开发的三维多介质流体动力学仿真软件PMMIC-3D[20]对上述网格数据进行数值模拟,得到计算结果如图9 所示。图9(a)中左侧为爆炸产生后3 个有代表性的时刻的三维可视化结果,右侧为与左侧对应的时刻的二维剖面可视化结果。从图9(a)可以清晰地看到爆炸在厂房一层发生后,形成冲击波(图中以白色表示)并膨胀扩散到二层的过程。图9(b)为厂房二层2 维剖面图,以压力的变化为可视化属性显示了在4 个典型的时刻冲击波在二层传播过程。
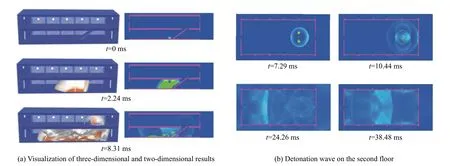
图9 厂房爆炸数值模拟结果图Fig. 9 Numerical simulation results of factory explosion
为了更进一步分析数值模拟的准确性,选取了厂房二层距楼梯口10 m 处的点作为关键点M 进行超压测试。记录点M 超压随时间的变化如图10 所示。可以看到,点M 处初始超压为0,随后冲击波传入二楼并传到点M 处,压力值开始上升达到第一个峰值。冲击波传播到墙壁后反射再次到达点M,压力值达到第二个峰值。随后,随着不断的反射,M 点超压值逐渐减小直至衰减为0。可以看出数值模拟与冲击波传播反射理论和实际经验相吻合,说明计算域的网格剖分能够满足大规模有限差分计算的需要。
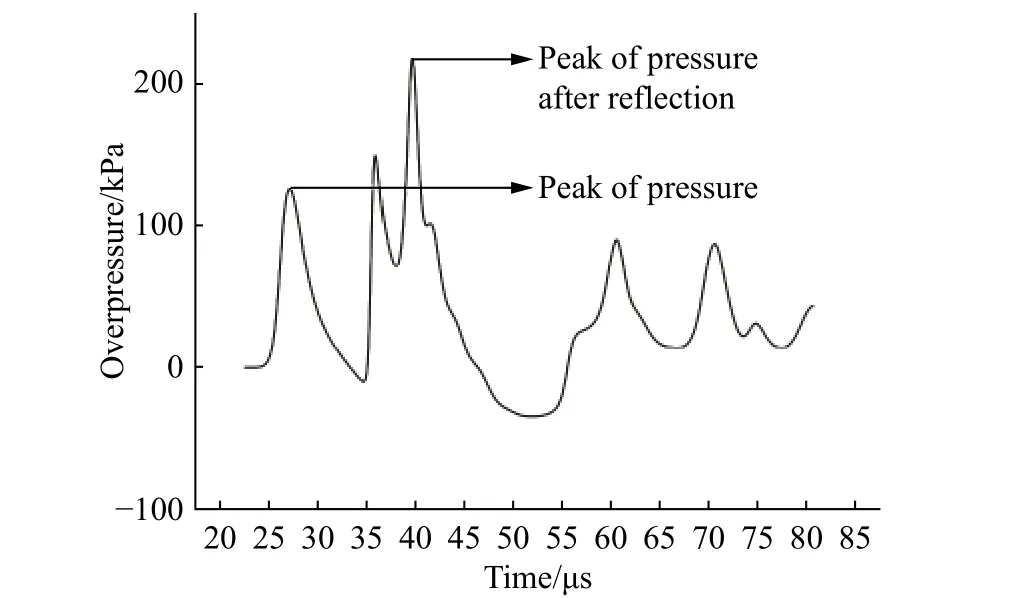
图10 厂房二层距离楼梯口10 m 处关键点的超压变化曲线Fig. 10 Change of overpressure with time at a key point which is 10 m from stairway entrance on the second floor
4 结 论
本文提出了一种基于传统射线穿透法的GPU 并行阶梯型有限差分网格生成方法。在这种并行方法中,提出了一种分批次的数据传输策略,使得算法能够处理的数据规模不依赖于GPU 内存大小,打破了硬件对网格划分规模的限制,平衡了数据传输效率和网格生成规模之间的关系。为了减少数据传输量,本文提出的并行算法可以由GPU 线程相互独立的生成射线起点坐标,射线相交计算在GPU 的每个线程中独自计算,进一步提高了并行算法的执行效率,通过数值试验的对比可以看出,并行算法的执行效率是传统射线穿透法执行效率的8~11 倍,并且随着计算规模的提升,并行算法的加速比有上升趋势。最后,通过有限差分计算实例验证了应用并行算法生成的阶梯型有限差分网格能够满足基于有限差分的数值模拟需求,得到了与理论和实验一致的数值模拟结果。
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
上海师范大学学报·自然科学版(2022年3期)2022-07-11
现代电子技术(2022年8期)2022-04-13
体育科技文献通报(2022年1期)2022-01-15
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
上海师范大学学报·自然科学版(2018年3期)2018-05-14
计算机应用(2016年10期)2017-05-12
饮食科学(2016年5期)2016-07-05
饮食科学(2016年5期)2016-07-05
幸福家庭(2016年3期)2016-04-05
