
基于卷积神经网络的小样本车牌号码识别方法研究
2020-07-07 07:47刘孟莹吕小纳
商丘职业技术学院学报 2020年2期
刘孟莹,吕小纳
(1.商丘市质量技术监督检验测试中心, 河南 商丘 476100;2郑州商学院, 河南 郑州 451200)
随着我国国民生活水平的日益提高,汽车的保有量也在急剧上升,车辆管理问题也越来越突出.对于车牌号码的快速准确识别,特别是在特殊环境下的准确识别,已成为车辆管理入口信息的重要一环.
车牌号码的识别属于2D图像识别[1]的一种.本文主要研究的是基于卷积神经网络的数字图像识别技术.图像识别的原理是将已有信息与当前所输入图像的关键信息进行比对,根据比对的结果将输入的图像识别为已有信息的一种.已有信息的维度决定了图像识别的复杂度.例如,对英文字母的识别与对汉字的识别复杂度就不一样,英文字母只需识别出26个字母的大小写,而汉字的个数远远大于英文字母数,所以二者识别的复杂度就不一样.相同像素点的英文字母和汉字的识别在准确率上,英文字母就会高于汉字;同理,要获得同样的准确率,汉字的像素点就必须要多于英文字母的像素点.
大多数机器识别的方法,一般是通过两个步骤完成对的图像识别[2],分别为特征值的提取和识别分类.特征值的提取就是将图像中的关键信息提取出来,这些关键信息是可以用来区分不同的图像.同时,特征值提取的效果会直接影响识别效率.识别分类步骤在特征值提取的基础之上将图像识别为具体的某一种.如果特征值的维度小于分类的维度,一定会出现分类错误的情况,所以一般情形下特征值的维度要大于分类的维度.
机器学习方法有一定的局限性,需要人为的预先设定特征.预先设定的图像特征往往以数据的方式存在,而输入的需要识别的图像由于光线、角度、对比度等自然因素的影响,所提取的特征值和预先设定的特征值往往有一定的偏差.在最终的识别分类过程中允许一定范围的容错,容错的阈值是分类阶段需要考虑的因素.机器学习方法还有一个缺点就是计算量比较大,实时性很难完成.如图1所示.
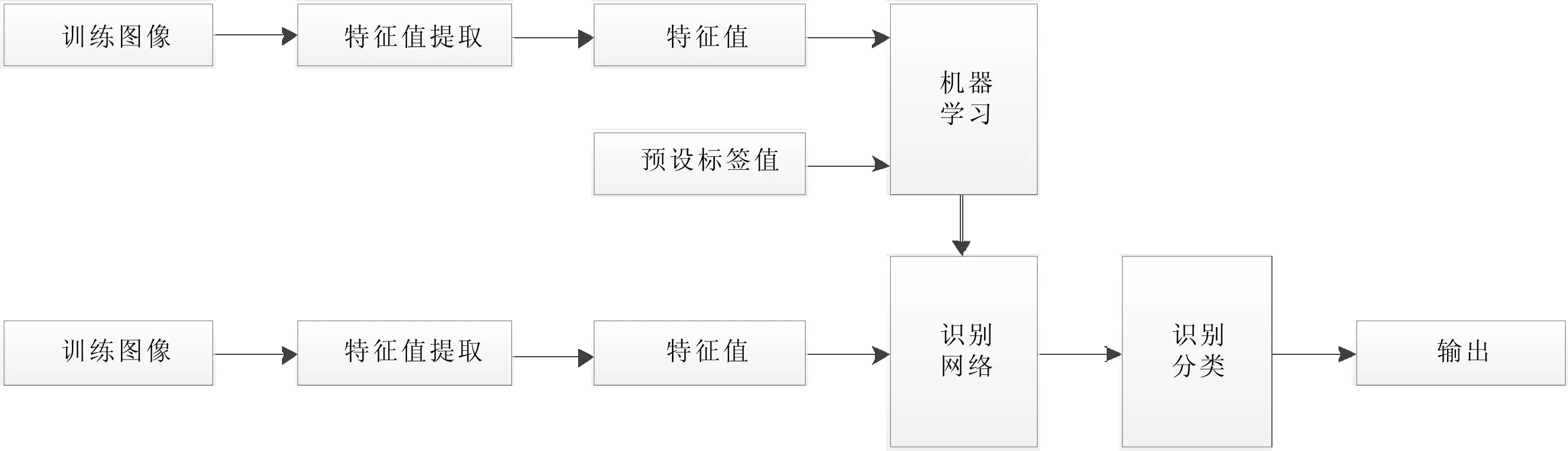
图1 人工神经网络中识别方法流程
基于上述的缺点,深度学习[3]以其不用预先设定特征,只用根据被识别图像的自身学习特征优势,越来越被研究人员所重视.
相对机器学习而言,深度学习最大的区别在于特征值的提取上,机器学习依赖于预先设定的特征值,而深度学习的特征值依赖于自身算法的自动处理.深度学习需要多层网络,每层网络向上层传递特征值,上层网络根据传递过来的数值进行语义抽象,再次提取特征值,然后再向上层传递.其整个过程不需要人工预先设定,特征值提取和分类识别由深度学习算法自动完成.相比于需要预先设定特征值的机器学习,深度学习可以节省下特征值设计的成本,具体如图2所示.

图2 机器学习与深度学习流程对比
本文通过基于卷积神经网络的深度学习算法,将特征值的提取与识别分类整合到一起,实现图像的直接识别.卷积神经网络在训练过程中,往往需要输入标记过的样本作为训练数据.样本数越多,识别的准确度就会越高.但在样本数有限的情况,如何构造网络模型以提高识别准确度是本文研究的重点.
1 卷积神经网络模型和算法
1.1 神经网络
20世纪50年代,神经网络被首次提出,由于当时计算机的能力有限,相关技术一直被搁置.电子技术的发展,特别是高速计算机技术的发展,使得大量数据的存储和运算得以实现.到20世纪80年代,神经网络研究再一次成为热点.早期的神经网络主要是用在分类场景下,通过输入值和目标值之间的关系,调整神经元的参数和偏移量,以及神经元之间的参数,来进行输入值和目标值之间的学习过程.
为了实现更精确的细分,神经网络可以使用多层结构.其相邻两层可直接连接,非相邻层之间不能连接.且层与层之间以及层与端口之间的连接方式根据神经网络模型的不同而不同.同时,相邻两层之间一般使用全连接形式.
神经网络类似于人的神经组织,由很多个神经单元组成,神经元结构如图3所示.

图3 神经元结构
神经元的计算公式为:
(1)
一般的神经网络会由多个层构成,每个层往往又由多个神经单元组成,相邻的层与层之间通过神经单元进行连接.神经网络就是包含一个隐藏层的网络,如图4所示.
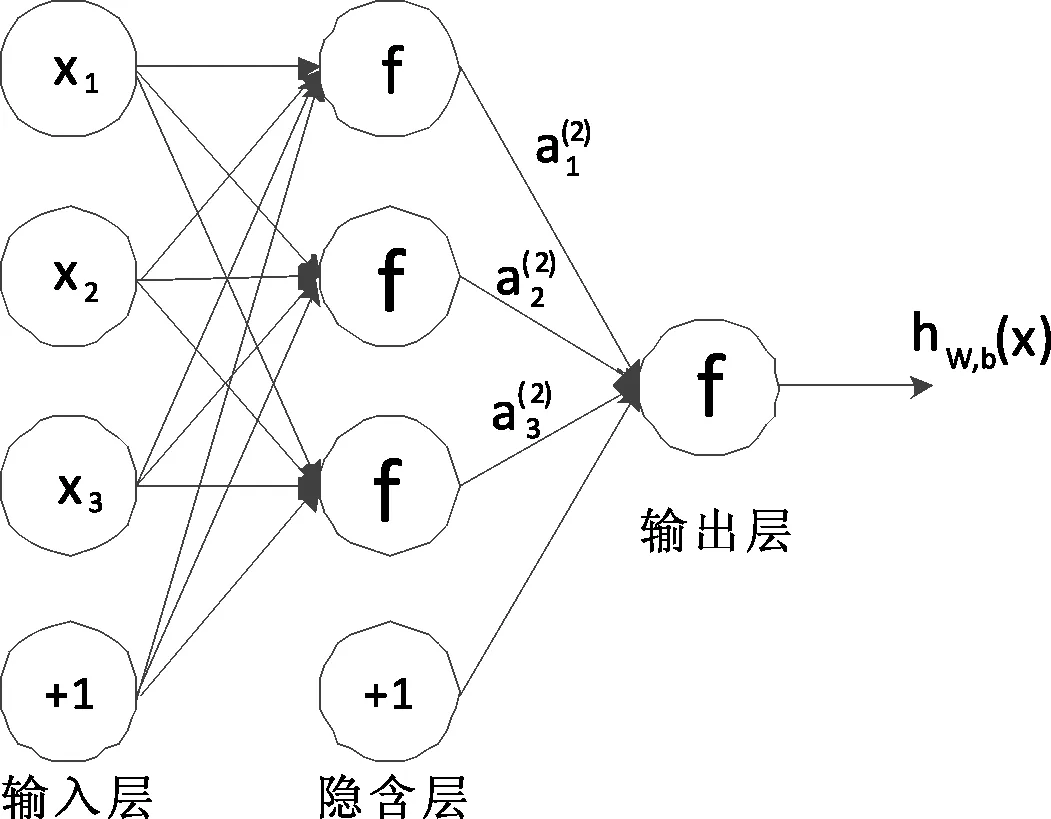
图4 一般神经网络结构图
神经网络根据实际需求可以拥有多个隐藏层.神经网络的训练方法与单个神经元的训练方法类似.其区别在于神经网络一般包含多个层,且神经元的个数以及神经元之间的连接非常多,其训练过程需要遵循一定的规则,最常用的求导法则有链式求导和梯度下降法则.
1.2 卷积神经网络
人工神经网络中,相邻层之间的神经元是全连接形式,每一个连接在计算过程中要赋一个权重值.假设每一层是n个神经元,每增加一层,就需要增加n2个权重值.所以,随着层数的增多,相关参数所占用的内存空间也急剧增多.
当识别目标后的分类较多时,就会需要较多的神经元和更多的网络层数.这样需要的内存空间就会比较多,同时运算的成本也会比较高.除此之外,神经网络的容量(记忆能力)比较大,如果输入的样本没达到一定的限度(网络容量)时,网络会记忆下所给的样本,这就是所谓的过拟合问题.过拟合会使网络对新数据不准确识别.出现上述问题主要是由于权重数过多,如果直接减少权重数,又会带来学习能力[4]的下降.为了改善这些情况,后来就出现了卷积神经网络.卷积神经网络可以在保证相同学习能力的情况下,减少权重的个数和神经元的个数.
现如今卷积神经网络已得到广泛的应用.由于其减少了神经元之间的参数,所以其在数据存储、运算要求和过拟合问题上都有较好的表现.因为是基于人工神经网络的改进,所以其结构依然是层级结构.其特点有如下几点:局部感知、权值共享、多卷积核、Down-pooling、多层卷积等.
1.3 LeNet-5模型
用卷积神经网络来识别数字图像,其识别准确度比较高.卷积神经网络经过多年的发展,现有很多种模型,其中,LeNet-5[5]是卷积神经网络中一种典型模型.该模型网络结构分层合理,学习和匹配过程中有较好的性能,而且其运行的效率也比较高.
LeNet-5基本思想是用一个卷积核对二维图形进行局部的特征值提取,使用卷积核对整张图进行遍历取值,这样就可以得到整张图的特征值.由于卷积核较小,就可以使用较少的参数来完成对整张图特征值的提取.由于要遍历整张图,所以其运算速度比较慢.
当前使用的LeNet-5网络一般包含的层有:输入层(Input)、卷积层(Convolution layer)、池化层(Pooling)、全连接层(FC)、输出层(Output)等.本文使用的LeNet-5结构, 如图5所示.

图5 卷积神经网络LeNet-5结构
卷积神经网络依然是层级结构.不同类型的层有着不同的作用,不同的运算关系.常用的层类型及作用如下述.
1.3.1 输入层
输入层的目的是既要保证图像数据的完整性,又要使图像数据干净(减少噪声).所以,输入层一般会对数据做一些处理,一般有去均值(去除直流分量)、归一化、白化(去除各维度之间的相关性)等处理方法.
1.3.2 卷积计算层
卷积计算层就是用来做卷积计算的.对于彩色图片,每个像素点都含有RGB三个色道,三种颜色的数值是相互对立.直接卷积会损失掉某些颜色,往往要对三个颜色分别做卷积.如果放在同一层做,每个像素点就需要三维向量,这样需要的权重数就比较多.为了简化算法,可以使用三层卷积计算层,每一层只负责一种颜色的计算,这样就可以大幅度减少数据存储量和计算的复杂度.
1.3.3 激励层
在卷积层向下一层进行数据传递时,有些场合需要做非线性处理,这时就要在卷积计算层与下一层之间加入激励层,用来实现非线性映射.
1.3.4 池化层
池化层的目的是为了减少权重数.具体的操作过程是将上一层的结果进行抽样,减少权重数,同时也减少过拟合的问题.池化的方法有很多种,最常用的是最大池化和平均池化.在图像识别中,平均池化用得比较多.如图6所示.
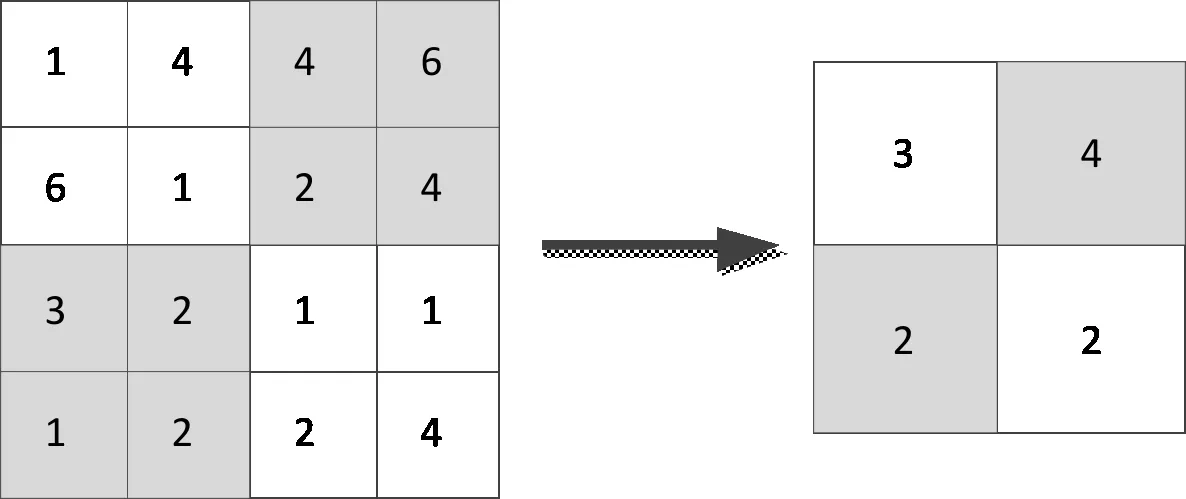
图6 平均池化示意图
1.3.5 全连接层
全连接层主要的目的是加大学习力度.全连接层的前后两层与全连接层的所有神经元都有对应的权重连接.本层通常放在神经网络的后面.
1.4 LeNet-5卷积算法
相比于人工神经网络,卷积神经网络的优势在于不同类型的网络层完成不同的功能,每次需要完成的功能单一,便于进行算法的优化.下面主要介绍卷积层的算法优化.
图像可以看作二维数据组,卷积层在计算卷积时是二维卷积.假设两个函数f(x,y)和 g(x,y),卷积后的函数可以通过式(1)得到:
(2)
式(2)是二维卷积的一般公式.每得到一个卷积函数值都需要从负无穷到正无穷求遍历加权和.实际的图像是有限的,所以卷积函数的积分限是图像的长和宽.卷积过程其实是一种加权过程,卷积核函数就相当于加权值.对于具体一幅图像的卷积公式为:
(3)
卷积神经网络是由前到后的单向传播网络,所以每经过一次训练就会遍历整个神经网络.每次训练后就将输出的数据与预设数据比较,根据误差(或者均方误差)来调整权重,直到误差最小,此时网络训练完成.
2 结果分析
车牌识别主要分为两步,第一步是拍照,第二步是拍照后的图像识别.图像的质量直接影响最终的识别效果.在拍照环节中,环境光、背景色、车牌角度、相关遮挡等都会影响图像的质量.未知场景下对车牌的识别有很多的困难.比如拍照的触发时刻,触发时刻选择不好直接影响图像中有用信息量.如果触发时刻较早,图像中车牌占比太小,如果触发时刻较晚,整幅图像不能全部包含车牌,会造成车牌信息丢失.除此之外,车牌上字符空间的大小、单个字符的大小(图像分辨率)、相似字符之间的相似度等情况都会对车牌的识别带来困难.
2.1 实验数据
我国的车牌只有65个字符.这65个字符包含京、沪、津、渝等31个汉字字符,24个大写英文字母字符(除去I和O)和10个阿拉伯数字字符.
本次实验选取了多组数据集,每组数据集包含500幅图像.按照训练测试比为41来划分.每组500幅图像分为400幅用来训练网络参数,另100幅图像用来测试网络.
2.2 网络性能评判标准
为了评估神经网络的优劣势,这里用识别准确率和过拟合率作为神经网络优劣的评判依据.
识别准确率定义为:识别准确率=识别正确的图像数量/总识别图像.
与其对应的平均准确率为:平均准确率=各组识别率之和/总组数.
过拟合率定义为:过拟合率=训练准确率/识别准确率.
训练准确率=正确分类的图像数量/训练集图像总数.
2.3 实验结果对比及分析
为了验证卷积神经网络的优劣,这里使用BP神经网络[6]和LeNet-5卷积网络[7]两种方法进行对比.其结果如表1所示.

表1 两种算法在数据集上的实验结果对比表
表1中的BP神经网络采用3层网络结构,每次处理选取图像中的32*32=1024点,所以其输入层神经元个数为1024个,中间隐含层节点选择260个,因为字符总数为65,所以输出层节点数选择为65,激活函数公式为:
(4)
损失函数公式为:
(5)
因为输入节点数为1024,所以输入之前将图像数据集归一化为 32×32 的矩阵.
LeNet-5网络由于其网络各层功能确定,所以使用原始结构,只需将输出层改为65,而且LeNet-5网络不需要对预先数据进行归一化处理,使用原始数据集即可.
根据实验结果可以得出如下结论:BP神经网络由于其结构单一,各层之间功能相近,使得图像特征值的准确率不够,过拟合率相对较高;除此之外,BP神经网络对输入数据需要做归一化处理,自身识别性也会受限,训练网络需要的时间也较长.LeNet-5网络通过多层结构,在特征值提取方面有一定的提升.最终的效果是LeNet-5网络在识别准确率、过拟合率和网络训练时间上都优于BP神经网络.
3 总结
本文详细介绍了神经网络的基本原理和卷积神经网络LeNet-5结构和原理.通过实验结果可得,LeNet-5网络在识别准确率、过拟合率和网络训练时间上都优于BP神经网络.同时,也可以看到卷积神经网络的识别能力受制于反馈式的训练过程和大量的数据样本.如果样本增加或者输出量增加时,要想保证识别准确率,就必须增加网络层和训练参数,这必然会影响识别时间和网络性能.要想突破这些瓶颈,就需要从图像的语义层面上识别,对特定的场景,使用更专业化的神经网络,会得到更好的效果.
猜你喜欢
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
数学物理学报(2021年3期)2021-07-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
电子制作(2018年19期)2018-11-14
电子制作(2018年14期)2018-08-21
现代装饰(2018年5期)2018-05-26
中国生化药物杂志(2015年4期)2015-07-07
