
基于稀疏表示的不平衡数据集过采样算法
2020-10-15 12:16訾壮壮
计算机应用与软件 2020年10期
訾壮壮 何 涛 赵 停
1(南京邮电大学电子与光学工程学院 江苏 南京 210023) 2(南京邮电大学工程训练中心 江苏 南京 210023)
0 引 言
不平衡数据作为数据挖掘中最具挑战性的问题之一[1],越来越受到人们的重视。不平衡数据是指不同类别样本数量存在比例失衡的数据集。尽管大多数据具有多类属性,但是许多情况下仍然可以转换为二分类问题,因此本文主要研究二分类问题。在只有两个类别的数据集中,多数类是指样本数量相对较多的类,少数类是指样本数量相对较少的类。不平衡数据集在欺诈检测、文本分类、医疗诊断、推荐系统和其他实际应用中非常普遍。在上述应用中,人们通常对少数类样本更感兴趣,然而传统的分类器通常偏向多数类,无法对少数类样本进行正确分类,因此性能较差。
有两种方法可以用于解决类不平衡问题,它们分别是数据层面的解决方案和算法层面的解决方案。数据层面的解决方案是通过欠采样和过采样或二者的组合来平衡少数类样本和多数类样本的分布。算法层面的解决方案是通过改进传统的分类算法或优化学习算法的性能来提高少数类样本的识别率[2]。数据层面解决方案由于其独立于分类算法,可与任何传统的分类算法相结合而更受欢迎。
大多数不平衡数据集过采样方法通过生成新的少数类样本以减轻类不平衡问题,这些方法通常依赖于欧几里得特征空间中少数类样本的空间位置,收集少数类样本的局部信息以生成新的少数类样本。使得新生成的样本不遵循原始少数类样本的分布,因此含有较少的信息量。而更好的想法是利用少数类样本的全局信息,这可以在生成新样本的同时考虑稀疏表示来实现。
本文提出一种基于稀疏表示的不平衡数据集过采样算法KSOS。在样本生成阶段,使用少数类样本来构造稀疏字典,通过求解L1范数最小化来获得当前点的稀疏解,然后使用稀疏解中的非零项所对应的少数类样本来生成新样本。在样本确认阶段,计算每一个新生成样本的置信度,然后将所有新生成样本按其置信度排序,从中选取符合要求的新生成样本。
1 相关工作
不平衡主要有三种:类间不平衡、类内不平衡和类重叠。几乎所有的过采样方法都可以通过重复原始少数类样本或生成新的少数类样本来解决类间不平衡问题。对于类内不平衡问题,常见方法是首先使用聚类技术来发现少数类子群,然后应用过采样方法来处理这些子群,或者在用其局部分布衡量学习难度后,对难以学习的少数群体样本进行加权。而当原始非重叠区域被噪声和错误的生成样本入侵时,就会出现类重叠问题。
随机过采样通过简单重复部分少数类样本的方式来达成少数类和多数类样本在训练规模上的平衡。然而随机过采样技术可能导致过拟合问题,因为它可能创建比原始数据集更小且更具特异性的决策区域。
使用基于样本生成的过采样技术来解决类不平衡问题也很普遍。SMOTE[3]被提出用于生成少数类样本,以扩大少数类样本的原始决策区域。SMOTE随机选择一个少数类样本x,使用KNN在其余所有少数类样本中选出x的K个近邻样本,并取出其中任意一个x′,然后在x和x′之间连线的任一位置生成新的少数类样本。SMOTE虽然在减少过拟合方面取得了进展,但却引发了过度泛化的问题。许多SMOTE的扩展算法也相继被提出,例如B-SMOTE[4]、Safe-Level-SMOTE[5]、Random-SMOTE[6],实验表明生成的样本比简单复制的样本更具信息量。
自适应技术也被广泛用于不平衡数据集过采样。自适应合成采样ADASYN[7]考虑到难以学习的少数类样本,并根据其局部分布自动合成少数类样本。自适应半无监督加权过采样A-SUWO[8],应用半无监督分层聚类方法对少数类样本进行聚类,并根据其特定大小自适应地对每个子聚类进行过采样。
2 算法设计
2.1 压缩感知和稀疏表示
压缩感知(也称为压缩感测、压缩采样或稀疏采样)是通过寻找欠定线性系统的解,来有效地获取和重建信号的信号处理技术。奈奎斯特-香农采样定理表明:如果信号x(t)不包含高于B赫兹的频率,那么其可以通过一系列间隔1/2B的点处的值来完全确定。过去几十年中该定理一直被应用于数字信号处理。然而压缩感知定理指出信号带宽不是采样的基本要求,信号采样率仅取决于采样系统的稀疏性和非相干性,该理论可以同时实现信号的压缩和采样,在学术界和工业界得到了广泛的应用。
压缩感知的核心问题是稀疏字典和测量矩阵的设计,以及信号重构算法的构造,其中信号重构算法的构造也被称为稀疏表示。
观测数据y是长度为M的列向量,即y∈RM×1,采样信号A∈RM×N(M≪N)为一组基向量。压缩感知的目标是使用线性联立方程y=Ax从观测数据y中恢复被测信号x。由于未知数的数量大于方程组的个数使得欠定方程组是病态的,它的解不存在。
如果使被测信号x变得稀疏,可能意味着‖x‖0(x的L0范数)尽可能小,那么未知数的数量将会显著下降,这使得信号重建成为可能。
因此,压缩感知问题归结为求解如下约束优化问题:
min‖x‖0s.t.y=Ax
(1)
2005年,Starck等[11]证明式(1)具有唯一解,但是L0范数最小化是非凸优化问题。由于在多项式时间内不能获得可行解,因此式(1)的求解是个NP难问题。2006年,Tsaig等[12]证明L1范数最小化可以基于RIP条件替代L0范数最小化[12]。尽管两种形式都具有相同的稀疏解,但压缩感知的框架变为凸优化问题,其优化目标如下:
min‖x‖1s.t.y=Ax
(2)
使用它,形成了压缩感知最初的框架。实际上,当考虑到噪声问题时我们通常使用式(3)而不是式(2)。
min‖x‖1s.t. ‖Ax-y‖2≤ε
(3)
式中:ε表示大于0的很小的数;A表示稀疏字典;x为稀疏解。
重建算法的目的是找到解x,其中整个问题的核心是y的稀疏表示。
2.2 KSOS
稀疏字典的构造包括人工构造和训练学习。前者包含各向同性Gabor字典、各向异性精化-高斯字典等;后者包含字典学习算法K-SVD。本文直接采用训练样本构造稀疏字典。
首先将所有少数类Smin从训练集S中分离出来。其中Smin∈Rm×n,m为少数类样本数目,n为少数类样本的维度。对于当前采样点xi,xi∈Smin,使用除xi之外的其余少数类样本来构造系数字典D,D∈Rn×(m-1)。
接着,按照式(4)对每个样本进行标准化并计算它们的L2范数。
i=1,2,…,m-1j=1,2,…,n
(4)
式中:yi,j是稀疏字典D的样本点。在得到稀疏D之后,可以通过求解L1最小化问题来求解少数类样本的稀疏解w。
优化目标如下:
(5)
s.t. ‖Dw-x‖2≤ε
通过使用同伦算法[9]来求解方程的解。为了降低噪声,同伦算法考虑以下基本问题:
(6)
式中:λ是拉格朗日乘子。
在获得稀疏解后,选择w中非零项标识的样本点与xi一起合成新样本。例如,得到xi的非零稀疏解的下标,并将其索引保存在A中。然后选择A中所有的元素,它代表数据点yk的下标,其中k代表A中元素个数。通过式(7)合成一个新样本。
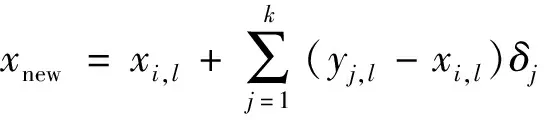
(7)
式中:
δ∈[0,1]
δ1∈[0,1-δ]
δ2∈[0,1-δ-δ1]
⋮
δk∈[0,1-δ-δ1-…-δk-1]
M为特征数,n为样本维度。
在样本确认阶段,KNN模型中定义了一个样本的置信度,这表明样本最近邻的分布。样本的置信度定义如下:
(8)
式中:T是合成少数类样本最近邻的总数;M是K近邻中属于少数样本的数目。例如,如果一个样本的5个最近邻中的4个属于少数类,那么该样本的置信度为3.2。然后将所有新生成样本按置信度从大到小排序并从中选取样本。
算法1KSOS算法
输入:训练集S={(xi,zi),i=1,2,…,N,zi∈{0,1}};多数类样本N-,少数类样本N+,其中,N++N-=N;采样率SR%。
输出:过采样后的训练集S′={(xi,zi),i=1,2,…,N+N+×SR,zi∈{0,1}}。
1.从训练集S中取出全部多数类样本与少数类样本,组成多数类训练样本集及少数类训练样本集S+
2.置新生成样本集Snew为空
3.fori=1:N+
4.用除xi外的所有少数类训练样本构建稀疏字典D,其中xi∈S+
5.用同伦算法解决式(5)所示的L1优化问题得出非零稀疏解所对应D中的少数类样本点,并将其置于稀疏解对应样本集Snew中
6.fori=(SR/100)×2
7.在稀疏解对应样本集Snew中取出对应的少数类样本点yj,j=1,2,…,k,其中k为xi对应非零稀疏解的个数
9.添加xnew;k至Snew,Snew=Snew∪xnew
10.置Sner为空
11. end for
12.end for
13.计算每个新生成样本的置信度,并将其从大到小排列,从中选取前N+×(SR/100)个置于Snew中
14.得到过采样后的训练集S′=S∪Snew
为对比KSOS算法与SMOTE和ADASYN的采样效果,在一个合成数据集上进行实验。为了方便可视化,该合成数据集的维度为2,其中少数类样本20个,多数类样本200个。少数类样本以(2.5,2.5)为中心,分别以0.1和0.4作为第一维和第二维数据的标准差生成的高斯随机变量,多数类样本以(0.3,0.3)为中心,分别以0.2和0.2作为第一维和第二维数据的标准差生成的高斯随机变量。图1为在合成数据集上三种采样算法的采样结果。可以看出,ADASYN和SMOTE都一定程度上在位于多数类样本区域的少数类样本附近生成了新样本,造成噪声信息的传播。而KSOS利用少数类样本的全局信息进行样本生成,新生成的样本多位于少数类样本及其边缘,不仅能改善噪声信息的传播问题,也增强了少数类样本的决策边界。
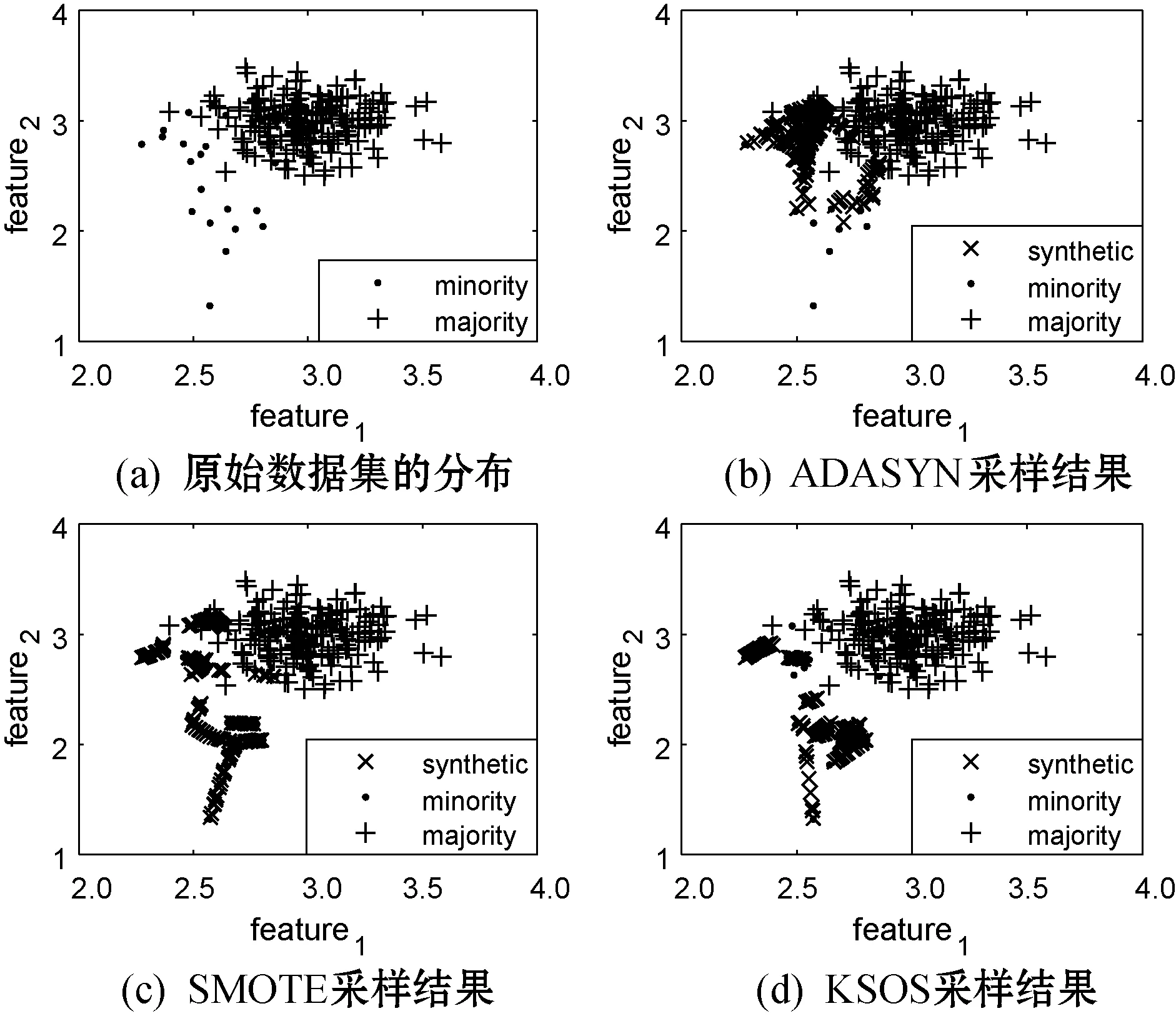
图1 三种采样算法的效果对比图
3 实 验
3.1 数据集描述
为了测试本文提出方法的分类性能,实验采用4组KEEL1(表1前4组)和2组HDDT2(表1后2组)类别不平衡数据集。这些数据集的不平衡比率范围从9.29到28.1。表1列出了数据集的基本信息,每个数据集有6个属性,即数据集的名称、数据集的特征维度、数据集的大小、少数类和多数类样数以及不平衡率。本文仅考虑含两个类别的数据集,因此需要对含有多类属性的数据集进行转换,以得到二分类标签。根据文献[10]中的方法来修改数据标签,即选取其中某一类作为少数类,并将其余所有的类合并为多数类。
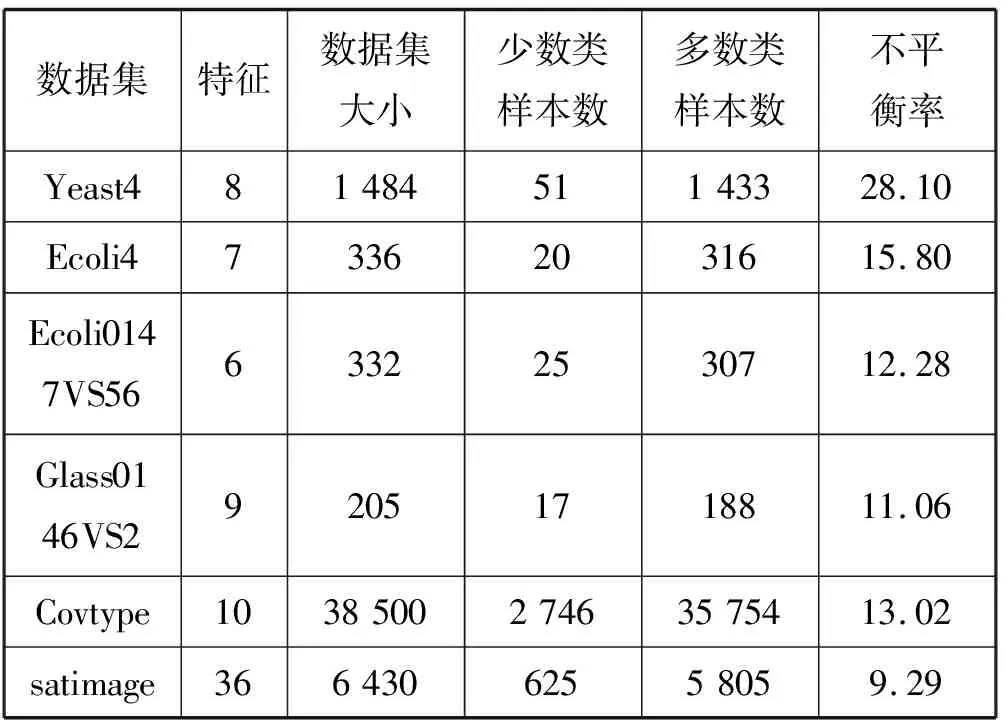
表1 不平衡数据集的基本信息
3.2 评价指标
F-Measure:用于分类器查准率和召回率的性能度量,计算公式如下:
(9)
式中:precision表示查准率;recall表示召回率。
G-Mean:用于度量分类器在两类数据上的平均性能,计算公式如下:
(10)
式中:TP是实际为少数类且预测正确的样本个数;TN是实际为多数类且预测正确的样本数量;FN是实际为少数类且预测错误的样本数量;FP是实际为多数类且预测错误的样本数量。
AUC:用于衡量分类器性能的指标,计算公式如下:
(11)
式中:M和N分别表示数据集中少数类样本个数和多数类样本个数。
3.3 结果分析
在实验中使用C4.5决策树作为基础学习模型。为了考察本文算法的分类性能,将其与SMOTE和ADASYN过采样算法进行对比,作为参考,给出基于原始的不平衡数据集的C4.5决策树的学习性能。为保证对比算法的性能,其K近邻的参数设置与原文保持一致,即SMOTE和ADASYN的K近邻参数设置为5,本文算法在样本确认阶段的K近邻参数设置为3。对于每一个数据集,均采用5折交叉验证,每次选取其中4组作为训练集,1组作为测试集,且每组数据中多数类与少数类样本个数的比值,为原始数据集中多数类与少数类样本数量的不平衡比率。采用G-Mean、F-Measure和AUC作为评估指标,为尽量保证实验结果不受随机因素的干扰与影响,实验结果取100次5折交叉验证的均值,并将每个评价指标下的最大值与本文算法的获胜次数用粗体标出,如表2、表3所示。

表2 以C4.5决策树为分类器的G-Mean、F-Measure和AUC结果
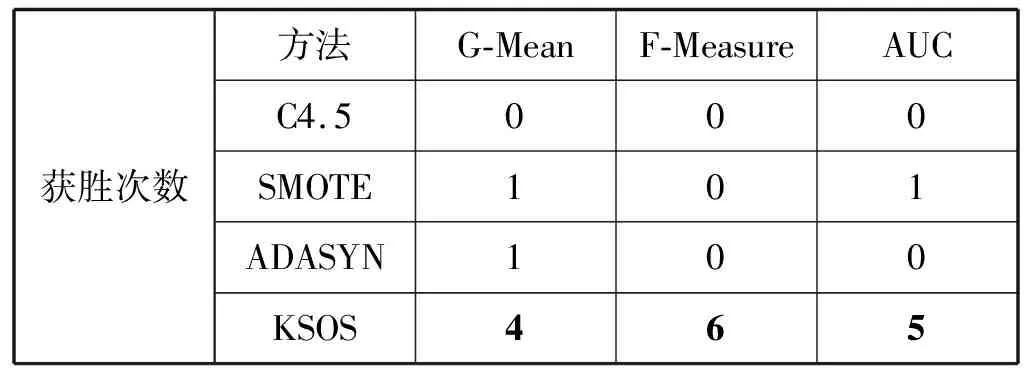
表3 算法获胜次数
从各个算法在不同指标下的获胜次数可以看出,本文的方法在AUC、G-Mean和F-Measure三种评价指标下的性能都优于其他两种算法。其中F-Measure值在6个数据集上全都取得了最大值,而只有当查准率和查全率都比较高时,F-Measure值才比较高,说明KSOS算法在不损害多数类数据分类性能的情况下,对少数类样本的查准率和查全率都有所提升。
4 结 语
为提高传统分类器在不平衡数据集上的分类性能,针对大多数过采样算法仅利用少数类数据的局部信息进行样本少数类生成,使得新生成的少数类样本不能很好地遵循原始少数类样本的分布,具有较少的信息量等问题,提出一种基于稀疏表示不平衡数据的过采样算法。首先利用少数类样本分布的全局信息进行样本合成,其次在样本确认阶段对合成的样本进行清洗,剔除位于多数类样本范围内的合成样本,防止噪声信息的传播。通过在6个不平衡数据集上与其他算法的性能比较,表明本文算法可以有效解决数据失衡问题,提高不平衡数据集的分类性能。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
现代电子技术(2022年15期)2022-07-28
小型微型计算机系统(2022年4期)2022-05-09
电子产品世界(2022年4期)2022-04-21
波谱学杂志(2022年1期)2022-03-15
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
中国校外教育(下旬)(2017年8期)2017-10-30
中国科技纵横(2016年20期)2016-12-28
现代电子技术(2016年5期)2016-05-14
