
基于自组织特征神经网络和最小二乘支持向量机的短期电力负荷预测方法
2021-02-22 10:22魏明奎叶葳沈靖周泓蔡绍荣王渝红沈力
现代电力 2021年1期
魏明奎,叶葳,沈靖,周泓,蔡绍荣,王渝红,沈力
(1. 国家电网有限公司西南分部,四川省成都市 6100315;2. 四川大学电气工程学院,四川省成都市 610065)
0 引言
电力系统负荷预测一般分为超短期、短期、中期、长期四类负荷预测[1],随着市场化改革的逐步推进,短期负荷预测的重要性日益提升[2]。近年来,国内外学者对于短期负荷预测进行了广泛的研究,围绕具体预测思路的差异,可将预测方法分为两类,其一是传统的时间序列分析方法,包括回归分析法[3]、指数平滑法[4]、多元线性回归法[5]、卡尔曼滤波法[6]等;其二是机器学习算法,由于其可以较好的解决负荷非线性的问题,受到了广泛的应用和研究。目前已有较多机器学习算法在负荷预测领域应用,在这些方法上又存在着很多的改进算法,目前使用较多的方法有基于极限学习机(Extreme Learning Machine, ELM)的预测方法[7-8]、基于支持向量机(Support Vector Machine,SVM)的预测方法[9]、基于BP 神经网络的预测方法[10]等。
近年来,由于SVM 具有较好的鲁棒性和有效规避维数灾等优点,得到了学者的重视,在其基础上,一些改进方法也在不断被提出,而目前已有的应用较广泛的改进模型是利用最小二乘方法改进的最小二乘支持向量机(Least Squares Support Vector Machine,LSSVM)。现有研究中已有学者将LSSVM 应用于负荷预测领域,如文献[11]中为了避免传统负荷预测需要针对整个负荷数据集建立预测模型所存在的学习不充分和计算量大的问题,提出基于即时学习算法和LSSVM的局部预测模型,并配置了局部模型更新策略,最后通过仿真验证了其所提模型的有效性;文献[12]中立足于大气污染的背景下,依据大气污染防治措施与负荷变化之间的关联关系,将空气质量指标作为预测的状态变量引入预测模型,结合K-means 和LSSVM 构成预测模型,取得了较好的预测结果;文献[13]从负荷数据集入手,利用经验模态分解将原始负荷时间序列分解为多个不同的子序列,减弱了负荷波动性,同时利用特征相关分析法选取了最佳特征集,最后利用LSSVM 建立负荷预测模型,最后通过仿真实验,验证了该方法对于短期负荷预测精度的提升作用;文献[14]利用小波变异果蝇优化算法对LSSVM的学习过程进行了优化处理,改进了预测模型的性能,提高了最后模型的预测精度。上述有关LSSVM 的负荷预测方法多单独针对LSSVM 本身或者负荷数据集本身做出改进,而忽视了二者协同改进所带来的预测精度提升作用。
在上述研究和相关研究的基础上,本文同时对负荷数据和预测模型进行处理,一方面针对负荷数据集,考虑使用粒子群优化算法[15](Particle Swarm Optimization,PSO)对自组织特征映射神经网络[16](Self-organizing Feature Mapping,SOFM)训练过程进行优化,使用优化后的PSO-SOFM 对收集到的负荷数据进行聚类分析,得到多组典型训练集;另一方面针对不同训练集建立LSSVM预测模型,并引入遗传算法[17](Genetic Algorithm,GA)对每个模型的关键参数进行优化处理得到最终的GA-LSSVM 预测模型。最后选取了某地区的负荷进行仿真实验,结果表明本文所提方法通过对负荷数据集和LSSVM 做出协同改进措施后,能够显著提升原模型的性能,同时对提升负荷预测的精度效果明显。
1 短期负荷预测模型框架
本文采用改进后的SOFM 对原始负荷数据进行特征挖掘及聚类处理,使用自适应权重的粒子群算法(PSO)优化其学习过程;对经由PSOSOFM 模型处理后的原始数据建立起LSSVM 模型,采用GA 优化参数。首先依据已有信息归类待预测日所属类别,然后选用相应GA-LSSVM模型进行预测,得到预测结果,整体预测模型框架如图1 所示。
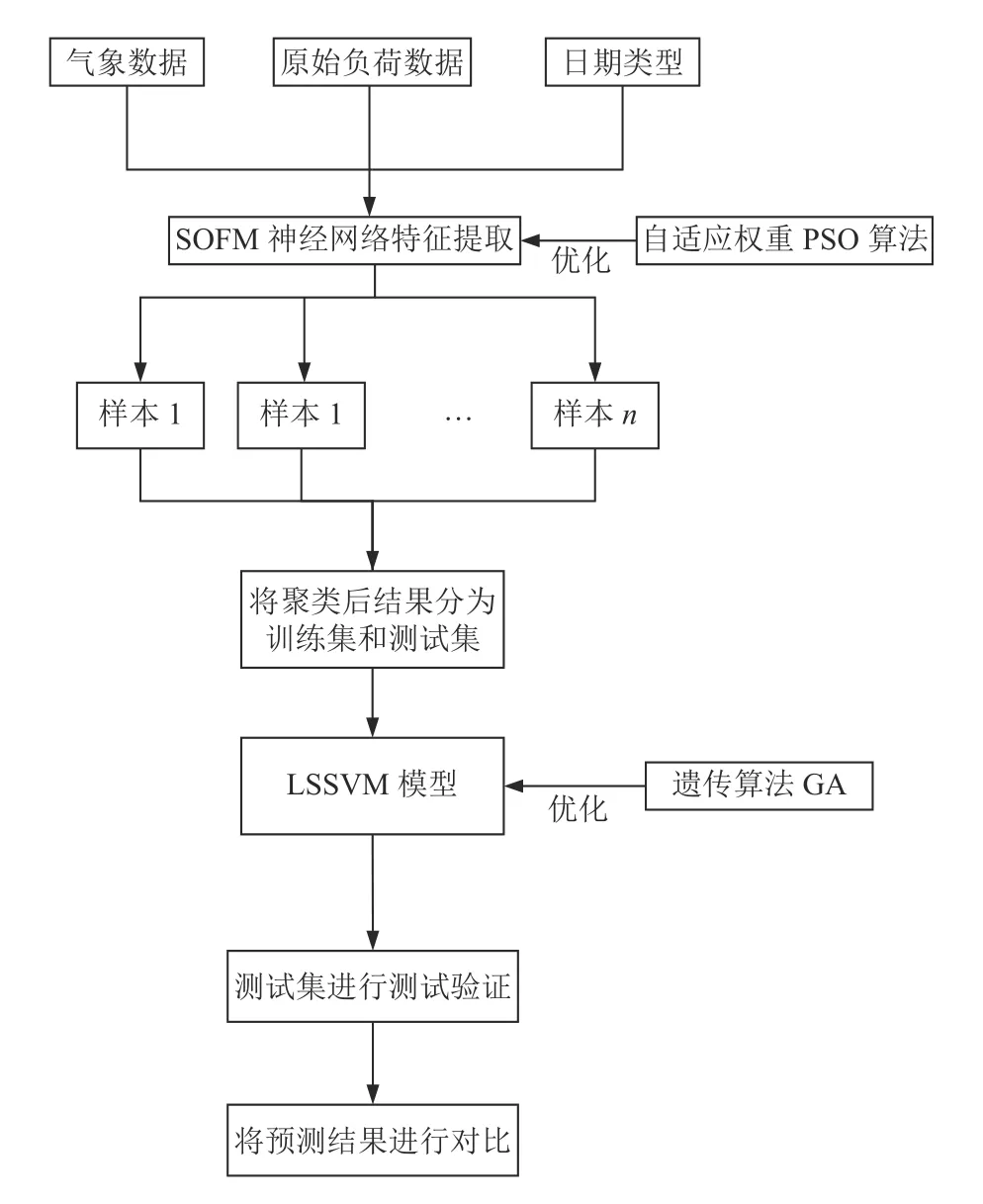
图1 短期负荷预测流程图Fig.1 Flow chart of short-term load forecasting
2 数据特征挖掘及聚类
2.1 自组织特征映射神经网络
为避免传统聚类方法存在的求解复杂、收敛速度慢、易陷入局部最优的问题,采用改进后的SOFM 神经网络对原始负荷数据进行特征挖掘、聚类。SOFM 神经网络由Kohonen 提出,是一种无监督的学习网络,通过神经元之间的竞争实现大脑神经系统中的“近兴奋远抑制”功能。如图2所示,SOFM 神经网络为输入层与竞争层的组织方式,更贴近大脑皮层的形象。学习过程依据权值向量与输入向量的欧式距离来修改权值向量,且只对输入向量欧式距离最小的权值向量进行修改。
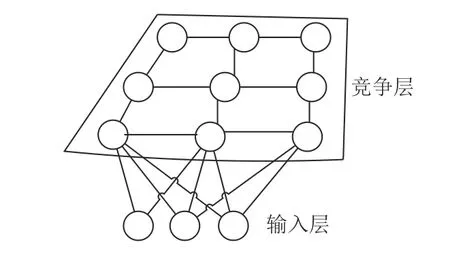
图2 SOFM 神经网络结构Fig.2 Structure of SOFM neural network
SOFM 神经网络的聚类步骤如下:
1)输入向量归一化,避免向量长度的影响。
2)计算输入向量与权值向量之间的欧式距离:

式中:xi为输入向量的第i 个分量;wij为输入层的第i 个神经元和竞争层第j 个神经元之间的权值。
3)记输入向量和权值向量的欧式距离最小的神经元为j*,此神经元及其邻接神经元的权值修改公式为:
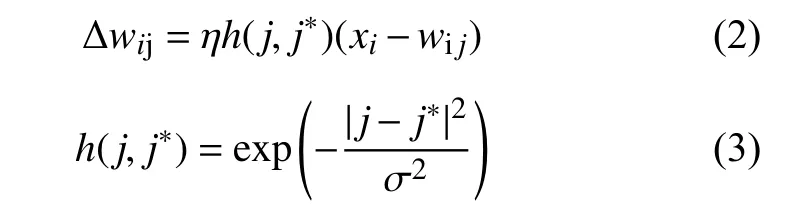
式中:σ 为邻域;η∈(0,1),σ2随着学习过程的进行而减小,因此在学习初期邻域函数h(j, j*)较宽,到学习后期逐渐变窄,能够起到有效映射的作用。
通过不断调整权值向量的方向,使得与某些相似输入向量欧式距离最近的权值向量在学习过程中不断逼近聚类中心。
2.2 自适应权重粒子群算法优化
粒子群算法源于对鸟类捕食的行为研究,是一种全局寻优的算法。采用自适应权重的粒子群算法对SOFM 神经网络学习过程进行优化,加速胜利单元接近聚类中心。优化过程为:
1) 初始化粒子的位置和速度。
2) 计算各粒子适应度,记录个体及全局最优粒子。
3) 对粒子的位置及速度进行修改:

式中:vi为粒子当前速度;vi+1为下一次迭代速度;ni为当前位置;ni+1为下一次迭代位置;m为惯性权重;C1、C2为学习因子;r1、r2∈(0,1),pi及gi分别为全局最优粒子及个体最优粒子。为平衡其局部与全局搜索能力,采用非线性动态惯性权重系数m:

式中:mmax、mmin为权重最大值及最小值;f、favg、fmin分别为当前粒子适应度、平均适应度及最小适应度。以每次获胜单元权值与输入向量之间的欧式距离最小值为目标函数,每次权值修改方式为:
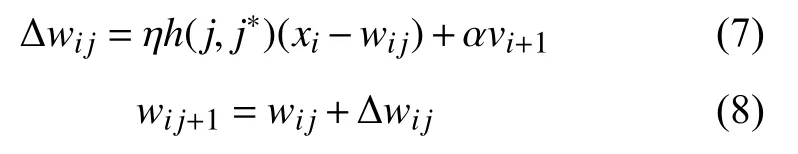
式中:vi+1通过式(5)进行计算;wij为当前权值向量;wij+1为下一次迭代的权值向量;Δwij为权值向量修改值;α 为一较小的值。这样既能保证加快分类速度,同时保证了权值向量不超过聚类中心。
2.3 数据特征挖掘及聚类步骤
为加快求解过程,提取和挖掘出同类原始负荷序列特征,避免求解过程复杂,时间及空间复杂度大,本文将对原始负荷数据及其相关影响数据进行预处理,采用改进后的SOFM 神经网络对其进行特征挖掘及聚类。具体处理方法如下:
1)原始负荷数据及其相关影响数据归一化处理
2)采用改进后SOFM 神经网络的自组织学习特性进行数据序列特征挖掘、聚类。
3)采用自适应权重的粒子群算法优化SOFM神经网络学习过程,得到聚类结果。
3 负荷预测方法
3.1 最小二乘支持向量机
SVM 具有很好的非线性映射能力,通过这种转化方式,能够实现由低维到高维的转化过程,从而使得样本的线性不可分问题变为高维可分,同时由于引入核函数,降低了转化过程中维度升高带来计算难度增加量。LSSVM 是SVM 模型上改进而来的一种新模型,LSSVM 将SVM 中不等式约束条件转化为等式条件,实现了将求解二次规划问题向求解线性方程组转化,从而大大加快了算法的收敛速度。
式(9)为常规的非线性负荷预测模型:

式中:负荷数据(xi, yi),i=1, 2,···, N, xi表示与负荷预测相关的输入向量,其维数由输入向量维数决定;yi为与输入向量xi对应的期望输出;N 为负荷数据点个数;φ(x)表式输入变量与高维特征空间的非线性映射关系;w 为权向量,b 为输出偏置量。
SVM 中以风险结构最小化原则进行优化,因此在LSSVM 中优化目标为:
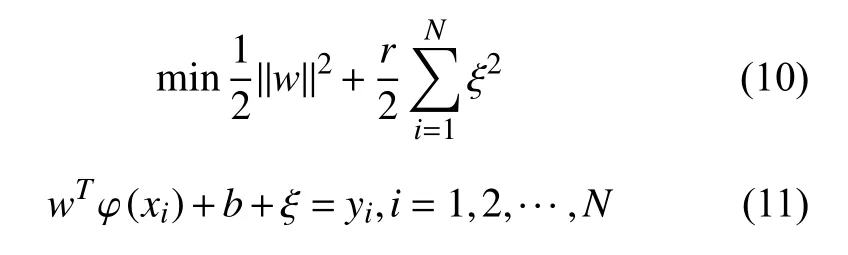
式中:r 表示惩罚参数,用于控制误差的惩罚修正程度;ξ 表示误差向量。
将优化目标函数与拉格朗日函数约束条件结合:
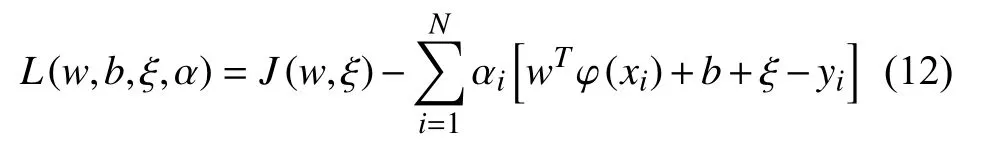
式中:αi含义为拉格朗日乘子。由KKT(Karush-Kuhn-Tucker)条件可以得到线性方程组:
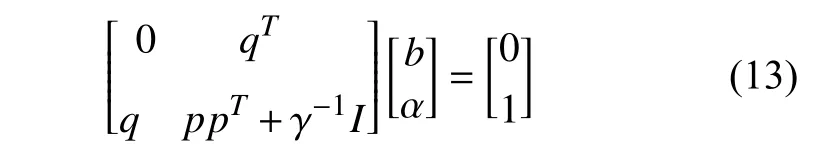
式中:
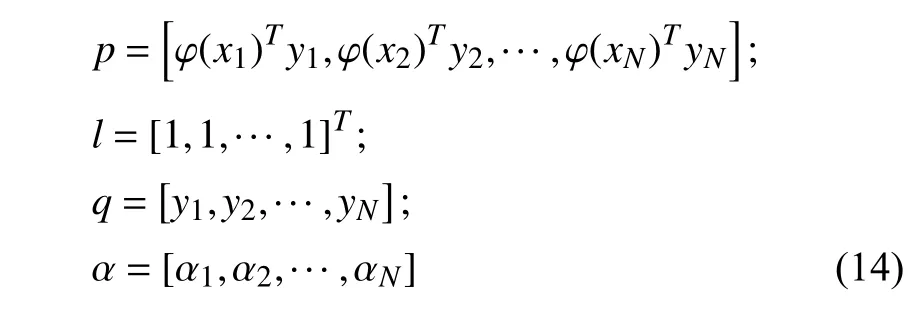
I 为单位矩阵。
依据Mercer 条件,核函数为:
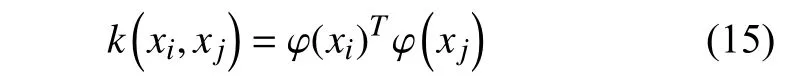
非线性预测模型变换为:
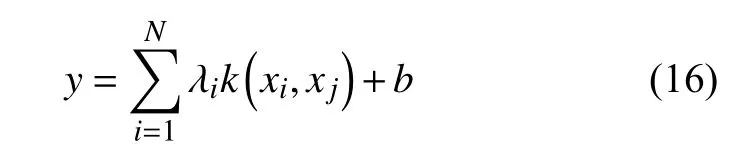
由于径向基函数(Radial Basis Function,RBF)的非线性映射性能很好,适合LSSVM 的需求,所以本文选择RBF 函数作为核函数,其定义为:
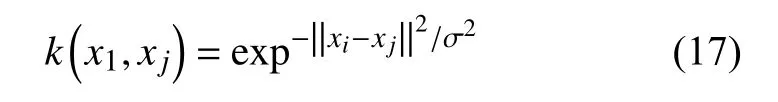
3.2 数据预处理及评价指标
对于原始数据异常的情况,利用解析法基于数据点相邻数据对其进行修正;对于数据缺失的情况,则考虑相邻数据变化趋势采用趋势外推填补空缺数据。
对原始负荷数据归一化处理,将数据值放缩到[−1,1],气象数据采用分段归一化,预测当日及前一日的日期类型采用独热编码。
设置平均绝对误差(EMAPE)及均方根误差(ERMSE)[17-18]对负荷预测模型进行评价,两者越小预测效果越好。各模型的训练过程结束后,利用各模型来预测同一日的负荷水平,比较各模型预测结果与实际负荷水平的差距,利用EMAPE及ERMSE评价模型的预测精度:

式中:N 为目标日预测数据点个数;yi和mi为同一数据点的实际值和预测值。
4 算例分析
4.1 算例介绍
原始负荷数据及相关负荷影响数据采用某地区2016 年至2018 年电力负荷数据和气象数据作为数据集,每日负荷共24 个数据点,间隔1 h。前两年的数据集作为训练集,最后一年数据作为测试集。训练好的负荷预测模型对该地区2019 年6 月30 日的工业、居民负荷进行预测。由于模型参数值直接影响其预测性能,采用交叉验证法进行参数选取,为对历史负荷数据进行有效地聚合分类且避免分类过多而造成收敛速度慢的问题,SOFM 神经网络竞争层神经元数为5,初始粒子数为40,mmax=0.9,mmin=0.6,最大迭代次数为100,遗传算法初始种群为30,最大遗传代数为200。为进一步验证提出的负荷预测模型,采用了几种不同的预测模型作为比较,包括LSSVM 模型、GA-LSSVM 模型、PSO-SOFM-LSSVM 模型。
4.2 实际算例分析
首先采取本文所提的基于SOFM 神经网络的聚类方法对所有原始数据集进行数据挖掘、聚类,对输入向量进行归一化处理,建立SOFM 神经网络结构,初始化SOFM 神经网络权重和阈值,将输入向量导入神经网络进行学习分类,以kohonen原则修改权重向量,最后得到图3 的SOFM 神经网络训练完成后其权重位置,在训练过程中采用改进粒子群算法对其优化。如图4 所示,类一到类五的数量分别为282,216,264,193,141。表1 为采用LSSVM、GA-LSSVM、PSO-SOFMLSSVM 和PSO-GA-SOFM-LSSVM 对工业及居民负荷的预测结果指标。
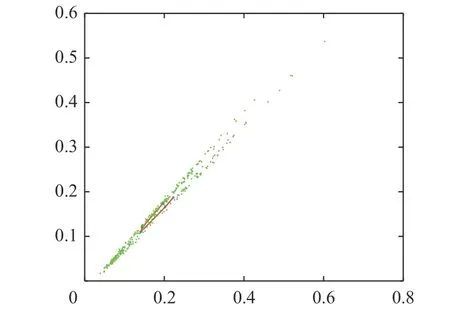
图3 权重位置Fig.3 Position of weights
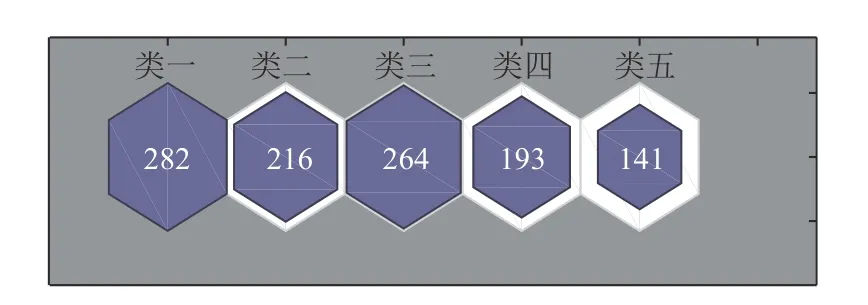
图4 聚类结果Fig.4 Results of clustering
由图5 可以看出,居民负荷波峰及波谷较为明显,其负荷水平变化较大,有较强的波动性,四种预测模型的误差为8.3743%、7.7548%、5.8304%、4.7961%,本文所采用的PSO-SOFMGA-LSSVM 方法在跟踪负荷变化水平上效果突出,较其他方法精度高。LSSM 由于其参数的局限性,无法表现出良好的预测效果,在进行GA 优化后能提高其预测精度,但此类方法并未考虑不同负荷类型的特征性,采用串行化的输入输出方式,泛化能力不足。

表1 评价指标比较Table 1 Comparison of evaluation indicators
对于工业负荷来说,此类负荷水平昼夜变化大,总的来说,傍晚到清晨的负荷水平较低,其余时间负荷水平较高。四种预测模型的误差为9.4522%、7.4632%、6.2954%、4.7648%,工业负荷在白天的负荷水平较高,但15 时以后,其负荷受生产计划、调度管理等因素的影响,负荷水平逐渐上升,LSSVM 及GA-LSSVM 无法跟踪此类变化,究其原因在于未能良好学习其负荷影响因素与负荷之间的内在联系,采用PSO-SOFMLSSVM 及PSO-SOFM-GA-LSSVM 的预测模型精度较以上两种模型精度高,可验证出本文所提模型能在不同类型的负荷下进行较好地预测。
5 结论
将本文所提的PSO-SOFM-GA-LSSVM 的模型依据平均绝对误差及均方根误差进行评估,并与LSSVM,GA-LSSVM,PSO-SOFM-LSSVM 进行比较。由实际仿真算例分析可知,与其他负荷预测模型相比,本文所提负荷预测模型具有更好的预测精度及泛化能力,采用PSO 算法及GA 算法优化后的模型收敛速度更快、性能更好、预测精度更高。基于PSO-SOFM 的分解方法能更好地挖掘原始负荷数据序列及相关影响因素之间的内在联系,能较好学习其强非线性关系。基于GA优化得到的GA-LSSVM 克服了在使用LSSVM 时参数选择的盲目性,不易陷入局部最优,具有很好的普适性,同时也具有很高的预测精度。
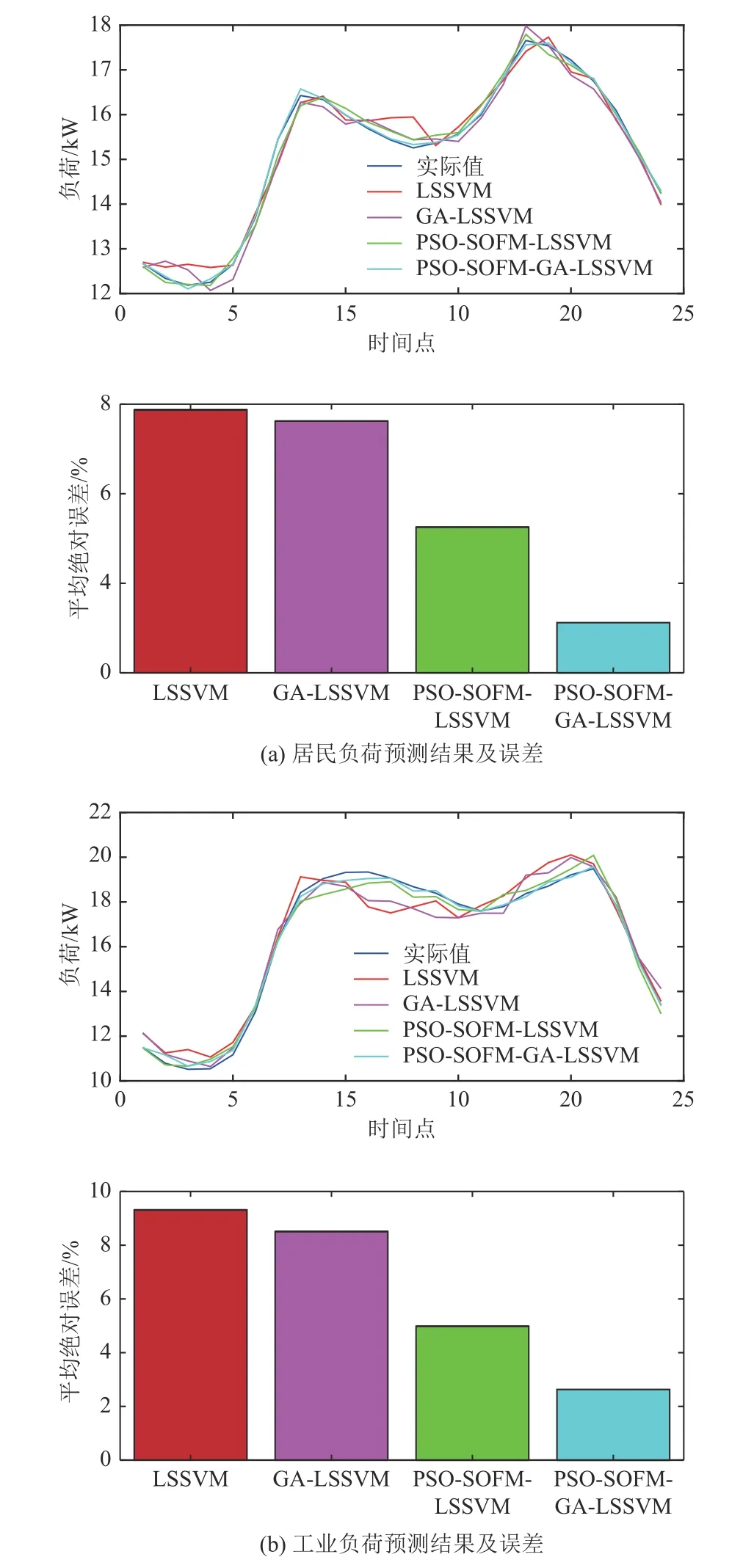
图5 负荷预测结果及误差Fig.5 Results and error of load forecasting
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
铁道通信信号(2019年6期)2019-10-08
自动化学报(2017年7期)2017-04-18
雷达学报(2017年6期)2017-03-26
现代电子技术(2016年15期)2016-12-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
