
基于深度学习下的卷积神经网络参数学习
2021-03-17 10:35张书玉宋英楠王长忠李雯琦牛嘉瑞
渤海大学学报(自然科学版) 2021年4期
吕 响,张书玉,宋英楠,王长忠,李雯琦,牛嘉瑞
(渤海大学 数学科学学院,辽宁 锦州 121013)
0 引言
在机器学习算法中,深度学习作为一个新兴技术,是建立并且模拟人脑进行分析学习的神经网络,已经极大地促进了机器学习的发展,目前深度学习应用最广泛的三个领域是语音识别,图像识别和自然语言处理[1].深度学习目前的主要形式是深层神经网络,而深度卷积神经网络(Convolutional neural net⁃works,CNN)则是其中一种经典而广泛应用的结构.近些年来,深度卷积神经网络已经在许多领域应用中表现出了优异的结果[2].
卷积神经网络是一类具有深度结构且包含卷积计算的神经网络,它具有权值共享、局部连接及卷积池化操作等特性.这些特性可以有效的减少训练参数的数目、降低网络的复杂计算度,使得模型具有强鲁棒性和容错能力.正因为有这些特性,卷积神经网络在各种信号和信息处理任务中的性能比全连接神经网络好很多[3].当前关于卷积神经网络的大多数参考书目仅仅是说明了原理,却缺少对中间参数的计算过程进行推导.鉴于此,本文给出了CNN各层参数及其反向传播计算公式的推导过程,这不仅有助于加强初学者对网络结构的了解、对网络参数的学习有一个深刻的认识,而且对以后的学习及建立模型有很大的帮助.
1 CNN的模型
CNN是当前深度学习领域中处理图像的一种典型算法,具有局部连接、权重共享等性质,CNN从结构上来看是由卷积层、池化层和全连接层交替组成的[4].而全连接前馈神经网络也可用来处理图像信息问题.通过对两种方法进行对比,可以发现,当利用全连接网络处理图像信息时会出现以下两个问题:
(1)参数太多.每个连接上都存在一个权重参数,如果隐藏层的神经元数量增多,则权重参数的数量也会随之增多.当训练该神经网络时,会产生参数迭代时间过长、收敛速度变慢的现象,同时也会容易发生过拟合现象[5].
(2)很难提取图像的局部不变性特征.局部不变性特征是指局部图像特征不随图像的变形而改变.全连接前馈神经网络要提取图像中的局部不变性特征是非常难的[1].
而利用CNN处理图像信息时可以有效解决以上两个问题.在CNN中,卷积层的每一个神经元仅仅与下一层中的部分神经元相连,形成局部连接网络,故层与层之间的连接数大量减少,参数也随之减少,所以网络训练效率增加,有效解决上述参数过多问题.除此之外,CNN中可利用多种卷积核提取图像的局部不变性特征.
1.1 卷积的定义
卷积是分析数学中一种内积运算,工程领域经常用一维或二维卷积来对信号或图像进行处理.根据卷积内积计算的不同,卷积分为正序卷积和逆序卷积.
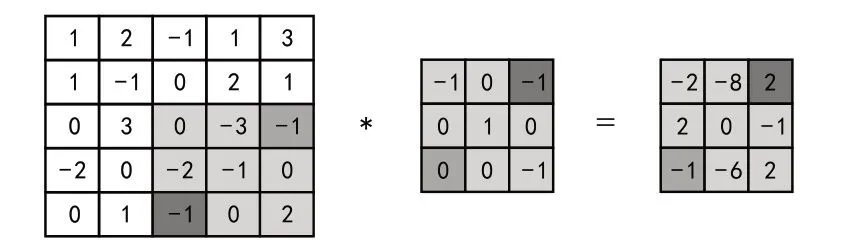
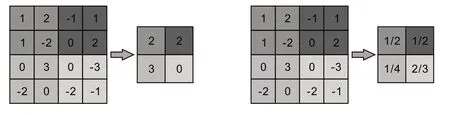
设一个图像X ∈RM×N和一个卷积核W ∈RU×V,其中U< 其中wuv和xi+u-1,j+v-1分别为W和X中的元素.将图像X和卷积核W的正序卷积运算记为Y = W ⊗X. 将W和X的逆序卷积定义为 与正序卷积不同,逆序卷积中yij的下标(i,j)从(U,V)开始.将图像X和W的逆序卷积运算记为Y = W∗X.正序卷积与逆序卷积有如下关系: 其中rot180(W)表示将卷积核W以左上角为原点旋转180度. 在卷积过程中,可通过卷积核的个数来得到多个特征映射,具体的卷积计算过程是卷积核与对应区域做卷积运算,期间通过引入卷积核的滑动步长和零填充来进行卷积计算.其中,步长是指卷积核在滑动时的间隔.零填充是指在输入向量两端进行补零操作.若一个卷积层的输入神经元个数为N,卷积大小为K,步长为S,使用零填充,且两端各填补Q个0,那么该卷积层输出的神经元数量为(+ 1). 根据是否对输入向量进行零填充,可将卷积分为以下三类[1]: (1)窄卷积:输入向量两端不填充,即Q= 0,步长S= 1,则经过卷积运算后输出长度为N-K+ 1.图1给出了一个二维逆序窄卷积示例. 图1 二维逆序窄卷积示例 (2)宽卷积:输入向量两端用全零填充,且Q=K- 1,步长S= 1,则经过卷积运算后输出长度为N+K- 1.正序宽卷积运算符用⊗表示,逆序宽卷积运算符用∗͂表示.正序宽卷积具有如下的性质: (3)等宽卷积:输入向量两端用全零填充,且Q=,步长S=1,则经过卷积运算后输出长度仍为N. 在卷积层中,首先由人工指定卷积核的大小和深度,再将这个可学习的卷积核对上一层的特征图进行卷积.而在初始化时程序会随机生成权重参数,并且这些权重值可以在之后的训练中被不断优化,进而来实现最好的分类结果.最后,由一个激活函数得到输出特征图. 假设卷积层的输入特征映射组为XM×N×D,其中每一个输入特征映射为Xd∈RM×N,1 ≤d≤D.卷积核为W ∈RU×V×P×D,其中每一个矩阵Wp,d∈RU×V为 一个二维卷积核,1 ≤p≤P,1 ≤d≤D.输出映射组YM'×N'×P,其中每一个输出特征映射为Yp∈RM'×N',1 ≤p≤P. 计算输出特征映射YP∈RM'×N',首先要用卷积核W(p,1),W(p,2),…,W(p,D)分别对输入特征映射X1,X2,…,XD进行卷积,卷积后把每个结果相加到一起,再加一个偏置bp便可以得出卷积层的净输入Zp,然后通过一个激活函数后就得到输出特征映射[7]. 常用的激活函数有Sigmoid、Tanh、Relu等,Sigmoid、Tanh比较常见于全连接层,Relu常见于卷积层.Relu常见于卷积层.激活函数的作用是用来加入非线性因素,因而把卷积层输出结果叫做非线性映射. 池化层一般加在卷积层后,用来减少特征的数量,对特征进行选择,缩小输入图片的像素,进而减少全连接层学习参数的数量.池化层也可以看做一个的卷积层,卷积核为max函数或mean函数.使用最大值操作的池化层被称之为最大池化层.最大池化保留了每个区域内的最大值,即保留了这一区域内的最佳匹配结果.使用平均值操作的池化层被称之为平均池化层.池化层卷积核的尺寸、步长是人工设置的[7-8]. 假设XM×N×D为池化层的输入特征映射组,将每个特征映射Xd∈RM×N,1 ≤d≤D划分成多个区域,xi为指定区域内每个神经元的值.池化指的是对每一个区域进行下采样操作并得到一个值,该值作为这个区域的概括[1]. (1)最大池化:选取指定区域Rdm,n内最大的一个数来代表整片区域,即 其中xi为指定区域内每个神经元的值. (2)平均池化:选取指定区域内数值的平均值来代表整片区域,即 通过对输入特征映射Xd的M'×N'个区域都进行子采样操作,便得到代表每个区域的特征值,进而得到池化层的输出映射Yd={} ,1 ≤m≤M',1 ≤n≤N'.图2给出池化层中最大池化和平均池化示例. 图2 最大池化和平均池化示例 全连接层是特征提取的输出表达,它的作用就是CNN中的“分类器”.把最终输出的特征映射作为全连接层的输入特征向量,其维数等于最后一个输出特征映射层的网络节点的数量.基于该输入的特征向量,在全连接层训练分类器模型以进行分类识别[9]. 在全连接网络中,损失函数的梯度是通过每一层的敏感度δ进行反向传播,来计算参数的梯度.在卷积网络中,参数为卷积核中的权重和偏置.设第l层为卷积层,且第l-1层的输出特征映射组为X(l-1)∈RM×N×D,即第l层的输入特征映射组为{X(l-1,1),X(l-1,2),…,X(l-1,D)}.再设第l层的第p个卷积核为{W(l,p,1),W(l,p,2),…,W(l,p,D)} 及第p个偏置为b(l,p),即卷积核的深度为D.其中W(l,p,d)∈RU×V,1 ≤p≤P,1 ≤d≤D.则经过卷积计算得到的第l层的第p个特征映射的净输入为 第l层中共有P个卷积核和P个偏置,每个卷积核的深度为D,因此共P×D个二维卷积核,可以使用链式法则来计算卷积核的参数和偏置的梯度[1]. 性质1 损失函数loss关于第l层的卷积核W(l,p,d)的偏导数为 证明:设第l层的输入特征映射组为{X(l-1,1),X(l-1,2),…,X(l-1,D)} ,其中X(l-1,d)∈RM×N;第l层第p个的卷积核为{W(l,p,1),W(l,p,2),…,W(l,p,D)} ,其中W(l,p,d)∈RU×V.根据卷积定义公式(1)可知,在零填充步长为1的情况下第l层第p个特征映射共有(M-U+ 1) ×(N-V+ 1)个神经元,其集合记为,其中1 ≤i≤M-U+ 1,1 ≤j≤N-V+ 1.每个神经元都是二维卷积核W(l,p,d)的函数. 由公式(1)和(11)知,第l层第p个特征映射的任意一个神经元的净输入为 因此,对于任意的权值,由导数的链式法则有 由公式(13) 故可知 性质2 损失函数loss关于第l层第p个特征映射的偏置b(l,p)的偏导数为 证明:设第l层的输入特征映射组为{X(l-1,1),X(l-1,2),…,X(l-1,D)} ,其中X(l-1,d)∈RM×N;第l层第p个的卷积核为{W(l,p,1),W(l,p,2),…,W(l,p,D)} ,其中W(l,p,d)∈RU×V.根据卷积定义公式(1)可知,在零填充步长为1的情况下第l层第p个特征映射共有(M-U+ 1) ×(N-V+ 1)个神经元,其集合记为,其中1 ≤i≤M-U+ 1,1 ≤j≤N-V+ 1.每个神经元都是二维卷积核W(l,p,d)的函数. 由公式(12)知,对于偏置b(l,p),由导数的链式法则有 性质3 当第l+ 1层为卷积层时,第l层第d个特征映射的敏感度矩阵为 其中fl(⋅)是第l层的激活函数,fl′(⋅)是fl(⋅)的导数,⊙表示矩阵的点对点乘积. 证明:设第l+ 1层的输入特征映射组为{X(l,1),X(l,2),…,X(l,D)} ,其中X(l,d)∈RM'×N';第l+ 1层第p个的卷积核 为{W(l+1,p,1),W(l+1,p,2),…,W(l+1,p,D)} ,其 中W(l+1,p,d)∈RU'×V';第l+ 1层的第p个 偏置为b(l+1,p).由公式(11)知,第l+ 1层的第p个特征映射净输入为 因 为X(l,d)=fl(Z(l,d)),所 以 对 于X(l,d)的 任 意 一 个 元 素和 其 相 对 应 的Z(l,d)中 的 元 素由公式(20)知 设为第l层第d个特征映射的敏感度矩阵δ(l,d)中的一个元素.由的定义可知, 性质4 当第l+ 1层为池化层时,第l层第p个特征映射的敏感度为 其中up(δ(l+1,p))为上采样结果. 证明:设第l层的第p个特征映射净输入为Z(l,p),相应的特征映射输出为X(l,p)=fl(Z(l,p)),第l+ 1层的第p个特征映射的池化核为W(l+1,p)∈RU × V,其中fl(⋅)是第l层的激活函数.再设的由W(l+1,p)覆盖的任意子区域,为与对应的Z(l,p)的子区域,则有为第l+ 1层的第p个特征映射的与相对应的神经元的净输入,即 其中g(⋅)是池化函数,(m,n)为左上角的坐标.设是的任意元素,则中存在相对应的元素,它们都与唯一对应,且有=fl().因此 深度学习是模拟人脑进行分析学习的神经网络,已经极大地促进了机器学习的发展.随着深度学习方法在诸多领域的不断深入研究,深层卷积神经网络在特征学习、目标分类、边框回归等方面的应用表现出的优势已愈发突出.本文主要介绍了深度卷积神经网络模型、卷积神经网络算法定义以及卷积层和池化层的参数计算方法和反向传播下参数的计算方法的推导公式.深度卷积神经网络模型原理并不复杂,但要从数学符号来描述并且真正的理解掌握它,就必须要理解其数学公式的表示以及推导过程.


1.2 卷积的类型
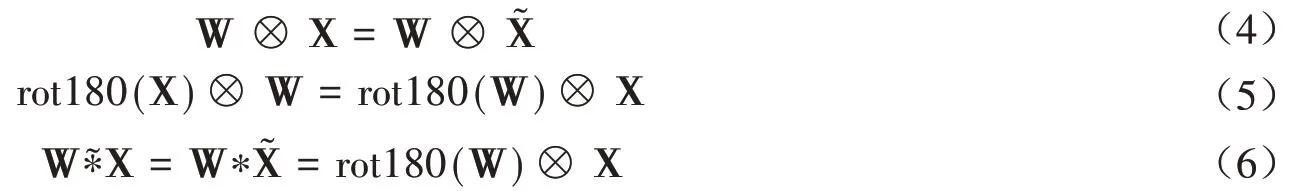
2 CNN的结构
2.1 卷积层

2.2 池化层(下采样层)


2.3 全连接层
3 CNN的参数学习
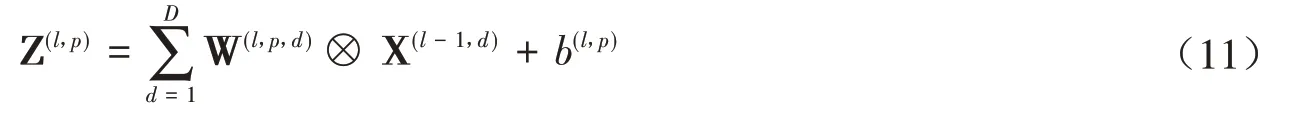
3.1 卷积核和偏置的梯度计算

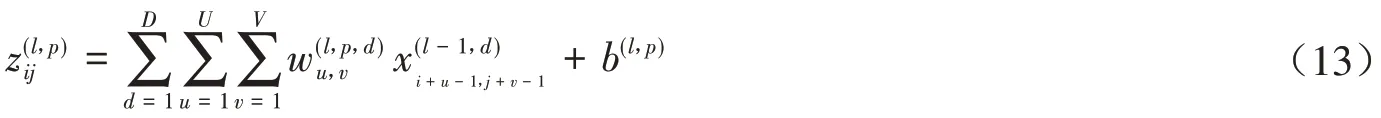
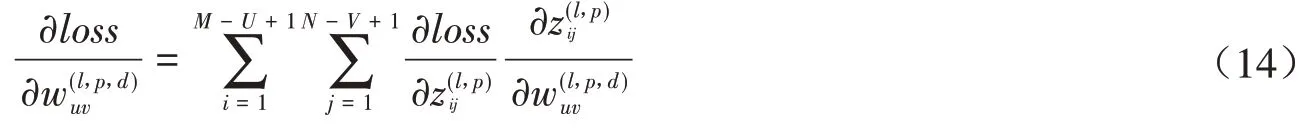



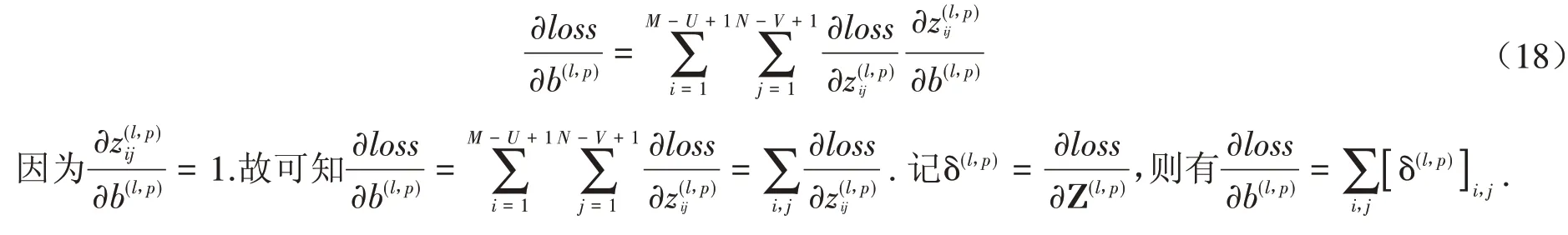
3.2 卷积神经网络的反向传播算法
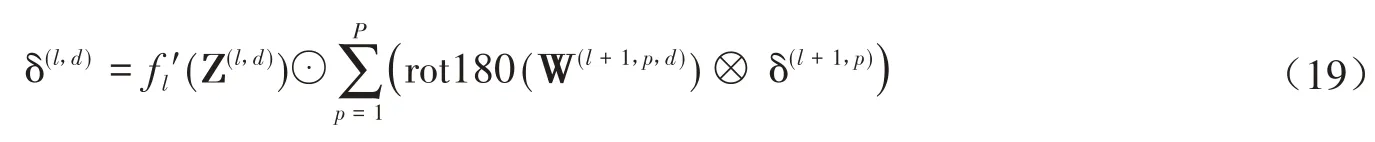

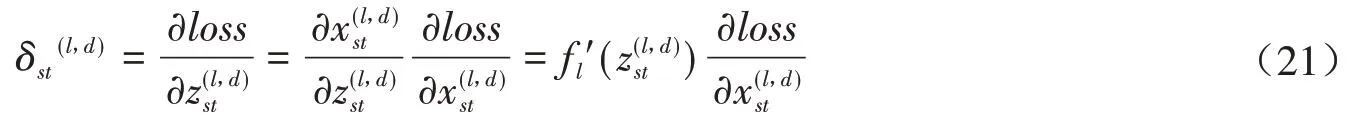


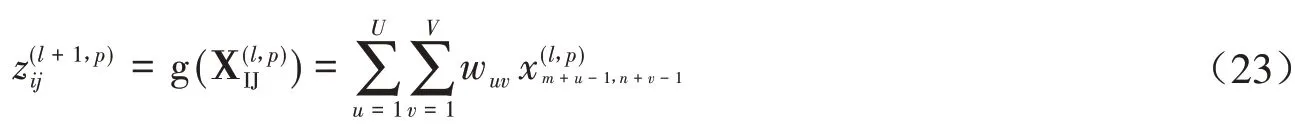
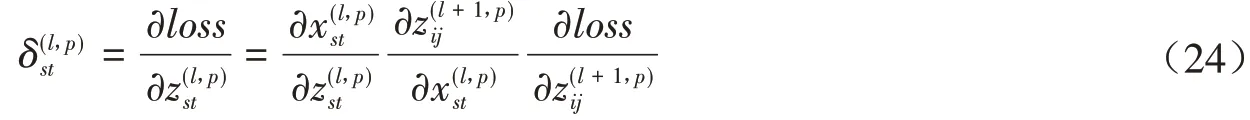

4 总结
猜你喜欢
智能计算机与应用(2022年9期)2022-09-28
计算机应用(2022年9期)2022-09-25
汽车实用技术(2022年15期)2022-08-19
中国信息化(2022年5期)2022-06-13
软件导刊(2022年3期)2022-03-25
西安邮电大学学报(2021年1期)2021-04-19
北京汽车(2021年1期)2021-03-04
无线互联科技(2020年12期)2020-09-03
科学大观园(2019年10期)2019-09-10
中国经济周刊(2019年9期)2019-05-24
