
融合区块链和Rsync的边缘节点数据同步
2021-04-22 12:45梁任纲
桂林电子科技大学学报 2021年6期
梁任纲, 何 倩,2, 刘 鹏, 蒋 明
(1.桂林电子科技大学 卫星导航定位与位置服务国家地方联合工程研究中心,广西 桂林 541004;2.桂林电子科技大学 广西密码学与信息安全重点实验室,广西 桂林 541004)
在万物互联时代,随着信息与通信技术的飞快发展,物联网应用的规模变得越来越庞大[1]。截至2021年,物联网中的服务设备数量预测将超过400亿,由物联网服务设备产生的数据流量呈现爆炸式的增长趋势,基于传统的云计算模型处理海量多源异构数据存在网络带宽受限、计算资源受限、高时延和隐私数据泄露等安全问题,以网络边缘设备为核心的边缘计算模型应运而生。
边缘计算因为高计算能力和靠近用户群体从而就近处理,可减少网络堵塞、提高网络的传输速率,最终降低网络时延,即时响应用户请求,明显提高用户的使用体验,使边缘计算在各行各业的应用中呈现出“病毒式”传播的趋势,物联网应用中的边缘节点数量也变的越来越多。边缘计算和人工智能的有力结合形成边缘智能[2],为在边缘智能中提供更优质的智能服务,让跨域的边缘节点收敛于相同的模型参数,边缘节点之间的模型同步共享不可或缺。例如,市场经济规模早已突破百亿大关的短视频抖音平台2021年数据用户预计将达到7亿,仅仅依靠传统的云存储方式不能即时响应巨大的用户服务请求,云边结合更加具有优势,为了使抖音短视频的推荐更具有针对性,在多边缘节点之间进行热门短视频、个性化推荐模型的更新和同步必不可少。综上所述,打通数据孤岛,实现跨域边缘节点之间的可信数据同步至关重要。
现阶段存在多种数据同步工具,如Rsync、Syncany、Hadoop等[3-5],但是现有的边缘服务应用对数据同步提出了更高的要求,传统的数据同步工具已无法满足,例如不能实现一对多的数据同步、同步过程中传输大量的冗余数据、同步过程缺少可信监管和存在安全隐患、无法跨平台数据同步和无可视化界面进行数据同步的控制和管理等。因此,跨域边缘节点之间便捷、有效、可信的数据同步是当前亟需解决的问题。
区块链作为近年来的新兴技术之一,本质上是分布式数据库,没有集中式数据库存在的单点故障问题,并且区块链不可篡改、可溯源的特性可以为链上数据进行强有力的背书,区块链还具有匿名性,在传输信息时不需要披露或验证身份信息,具有高安全性。
面向跨域的可信数据同步,提出一个基于区块链和Rsync的可信数据同步机制,主要贡献有:
1)针对跨域边缘节点的可信数据同步需求,引入去中心化、不可篡改、可溯源的区块链技术为边缘节点之间的数据同步提供可信环境,并且设计了基于区块链的可信数据同步模型架构;
2)针对传统数据同步存在大量冗余数据传输问题,基于Rsync算法实现跨域的数据同步,可提高跨域边缘节点之间数据同步的效率和边缘网络带宽的利用率;
3)针对传统数据同步过程缺乏可信监管等问题,基于区块链实现数据同步监控与溯源,将服务接口调用日志和数据同步信息存储至区块链中进行溯源,可提高跨域边缘节点之间数据同步的安全性和可靠性;
4)以跨域边缘节点的可信数据同步需求为背景,基于Hyperledger Fabric平台实现了提出的可信数据同步系统,实验结果表明,该数据同步系统安全有效,目前该系统已经实地部署并应用。
1 相关工作
无论是最开始的文件与文件同步、物理机与物理机之间的同步,还是服务器与服务器之间的同步,学者对于数据同步的研究从未间断。随着物联网应用的飞速发展,跨域边缘节点之间的数据同步再次得到越来越多的关注。文献[6]是文件同步的较早研究,它在2004年讨论了文件同步器的正式规范和参考实现模型。基于Rsync的文件同步由Yan[7]等和Gupta, Sagar[8]开发,他们研究的重点是通过提供单循环消息传递技术,而不是多消息传递技术来提高Rsync的性能。针对分布在多个设备上的文件同步需求,文献[9]提出了一种基于云的同步方法,它可以有效同步任意数量的分布式文件系统,该方法保持了点对点同步和基于云的主副本方法的优点,但是它不假定任何文件数据存储在云中,解决了容量、成本、安全和隐私问题。此外,以点对点的方式执行数据同步,消除了“云主从复制”方法中出现的成本和带宽问题,但是系统原型并没有提供实现细节或评估结果。Fatih作为土耳其最重要的教育项目之一,师生通过教学设备获取存储在云服务器上的教育数据,因为网络带宽限制、用户数量和数据流量的剧增导致Fatih性能降低,针对该问题,文献[10]通过引入代理服务器减少网络流量和云终端之间的数据传输速率,针对代理服务器之间的同步问题,该文献回顾并比较了SyncML、Rsync和CouchDB等分布式文件同步方法在代理服务器之间应用的可行性,并对SyncML和CouchDB方法在样本教育数据上的有效性进行了测试。文献[11]实现了一种名为Granary的分布式存储系统,Granary通过DHT层来存储文件元数据并具备可信赖的数据共享功能。文献[12]提出了一种名为RAM的高吞吐量无哈希分块方法,在CDC中,RAM不使用散列,而使用字节值声明切点。针对云存储用户设备转移时,设备数据的自动和连续地同步和云存储用户之间数据共享需求,文献[13]提出了同步数据协议及其相关的体系结构,以减少跨设备之间的文件同步时间,确保文件同步的高质量和最小的资源消耗。文献[14]作为一篇综述性论文,介绍了文件同步和共享在云存储科学、教育和研究中的应用,并对云存储同步理论的研究进行了论述。针对Kettle、Sqoop等开源同步工具将历史数据、实时增量等数据同步至Hive仓库过程中存在的操作复杂、延迟高、文件安全性低等问题,文献[15]搭建了一个异构数据同步系统,不仅实现了功能且对大数据同步平台的建设具有借鉴作用。针对商城与分销业务系统间存在的数据同步高成本和不可靠等问题,文献[16]基于SOA的思想实现了数据同步系统且已被实施应用。针对各级指挥系统的数据同步需求,文献[17]提出并实现了一种基于Oracle Logminer的数据同步技术,该技术简便、高效且安全可靠,具备很高的实用价值,但是其只针对不同系统的数据库表。
去中心化的区块链由对等方共同维护账本,通过密码学等技术确保区块链上的账本信息不轻易被对等方篡改,从而为对等节点建立信任,并利用脚本语言或者智能合约自动执行繁杂的逻辑操作,其对解决安全问题具有现实意义。为解决文件同步性能、高可用性、安全性、验证方便等存在的问题,研究者将数据同步和具有去中心化、可溯源、分布式数据库特性的区块链结合,文献[18]利用区块链和Rsync算法实现数据同步,直接将文件非匹配数据上传至区块链,区块链节点下载非匹配数据并进行拼接,最终实现各节点的数据同步,但由于区块存储数据有限,当文件非匹配数据过大时,区块链存储的区块过多,导致节点之间数据同步效率降低、区块链节点的存储压力和成本提高。文献[19]提出了一种创新的文件夹和文件同步模型:ChainFileSynch,它涉及一种基于区块链的快速云存储文件同步架构、进程和处理算法,该模型充分利用了区块链的分布式分布和可溯源的特征,与传统的云同步技术相比,ChainFileSynch提高了云存储的同步效率和网络可靠性并提供数据同步一致性验证。但其同步方式是利用区块链网络进行文件的完全覆盖,当大文件只是修改部分时,进行多节点的数据同步传输大量冗余数据容易造成网络拥塞。
虽然上述方案实现了数据同步,但有些方案仍存在以下问题:不能实现一对多的数据同步、同步过程中传输大量的冗余数据和缺少可信监管、无法跨平台数据同步和无可视化界面进行数据同步的控制和管理等。
2 数据同步系统模型
2.1 同步机制模型架构
随着物联网的快速发展,边缘服务在各行各业快速应用,由边缘服务产生的服务数据剧增,跨域边缘节点之间的数据同步对边缘服务应用不可或缺。针对传统数据同步存在无法一对多数据同步、缺乏可信监管、安全隐患、无可视化控制界面等问题,基于Rsync算法实现跨域边缘节点之间的数据同步,引入区块链技术为跨域的数据同步提供可信环境。
基于区块链和Rsync[20]的数据同步架构由数据同步模块和溯源模块组成,其中数据同步模块的设计是基于跨地域、跨平台、多边缘服务器之间的数据同步需求,引入溯源模块是基于区块链具备的高安全性、去中心化、可溯源、不可篡改特征,从而实现边缘服务器之间数据同步的安全透明。基于区块链和Rsync的同步机制模型架构如图1所示。
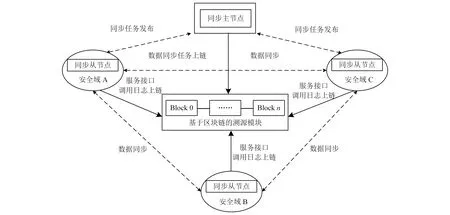
图1 同步机制模型架构
数据同步模块主要由同步主节点和跨多安全域A、B、C的若干同步从节点组成,其中同步从节点根据数据发送端与接收端的不同分为数据同步源端和数据同步终端。数据同步模块的主要功能是实现跨多安全域的边缘节点之间的数据同步。
溯源模块主要基于Fabric实现,其主要功能是同步主节点将数据同步信息上传至数据同步链,数据同步源端和数据同步终端在数据同步过程中通过数据同步智能合约将服务接口调用的相关信息存储上链,从而实现从同步主节点的同步任务发布、同步过程的服务接口调用到同步任务结束全过程的透明可溯源。
2.1.1 同步主节点
同步主节点是数据同步模块的控制中枢,数据同步模块中的若干同步从节点在同步主节点控制下利用Rsync算法并选定合适的分块参数实现一对多的跨多安全域数据同步。同步主节点的功能模块主要由主节点控制模块、通信模块、区块链模块等组成。
主节点控制模块:控制同步从节点进行数据同步操作。
通信模块:该模块主要用于同步主节点和同步从节点之间的通信。在多对多的数据同步应用场景,针对同步从节点在短时间内向同步主节点发送大量的数据同步请求,导致数据同步系统对数据同步请求处理不及时,最终导致数据同步产生瓶颈、系统资源耗尽的问题,通过在同步主节点部署消息中间件RabbitMQ将待处理的数据同步请求缓存至消息队列中,然后同步主节点再从消息队列中按照定时响应获取数据同步请求,控制同步从节点进行数据同步。采用消息队列存储数据同步请求,可避免数据同步系统短时间出现大量数据同步请求的处理瓶颈问题,从而提高数据同步系统的健壮性、稳定性和准确性。
区块链模块:该模块主要包括数据同步信息上链和服务接口调用日志上链,可实现从同步任务发布、同步服务接口调用到同步任务结束全过程的透明可溯源。在同步主节点中,区块链模块主要实现同步主节点的同步任务发布和溯源。
2.1.2 同步从节点
同步从节点的功能模块主要由从节点控制模块、通信模块、区块链模块、文件监控模块、数据传输模块等组成。
文件监控模块:该模块主要用于实时监控同步从节点(数据同步源端)的数据变更(例如监控目录或者文件内容的新建、修改和删除),并将数据变化的状态信息发送给从节点控制模块。
从节点控制模块:该模块根据文件监控模块反馈的数据变化状态信息发送数据同步请求至消息中间件,在主节点控制模块的控制下参与一对多的边缘服务数据同步。
数据传输模块:该模块主要实现数据同步源端与数据同步终端之间的同步数据传输。
区块链模块:在数据同步过程中,同步从节点将服务接口调用日志存储至上链,实现服务接口调用过程的透明和可溯源。
通信模块:同步从节点向同步主节点发送数据同步请求并存储至消息中间件RabbitMQ中。
2.2 工作流程
基于区块链和Rsync的数据同步工作流程主要分为数据预同步和同步两个阶段,其中主要包括同步主节点发布一对一或者一对多的数据同步任务、数据同步任务上链、数据同步请求存储至消息队列、数据同步溯源信息上传至区块链等过程。
2.2.1 数据预同步
数据同步源端:本地文件系统发生数据变更的同步从节点,数据同步源端需要将变更数据同步至其他的同步从节点(数据同步终端)。
数据同步终端:本地文件系统需要被数据同步的同步从节点,在同步主节点的控制下,同数据同步源端进行数据同步操作并更新本地数据。
数据预同步阶段的工作流程如图2所示。
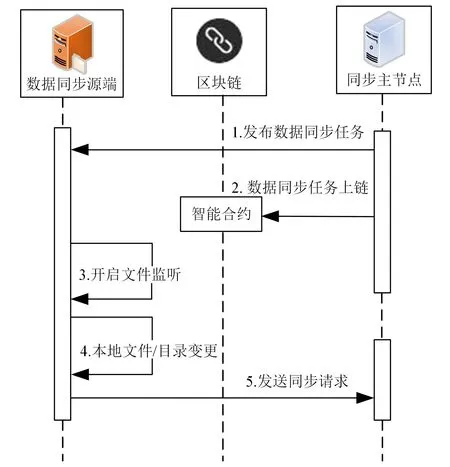
图2 数据预同步阶段的工作流程
1)同步主节点通过Eurake 服务注册与发现技术搜寻所有的同步从节点,指定数据同步源端、数据同步终端,通过目录服务接口调用检索数据同步源端和数据同步终端的文件目录,从而指定需要同步和被同步的文件或者目录,最后发布一对一或者一对多的数据同步任务。
2)将数据同步任务信息(数据同步任务的ID、数据同步任务的发布者、同步目录/文件的监控ID、数据同步源端IP、数据同步源端的目录地址、数据同步源端的文件名、同步终端列表等)上传至数据同步链上。
3)数据同步源端使用Inotify工具实时监控本地文件系统中同步的文件或者目录,监控其是否发生文件或者目录的新增、删除或者修改。
4)数据同步源端监控的文件或者目录发生数据变更。
5)数据同步源端发送数据同步请求至同步主节点所部署的RabbitMQ消息中间件进行缓存。
2.2.2 数据同步
基于Rsync 算法将数据同步源端和数据同步终端的数据按照固定长度进行分块,分别使用Adler-32算法和MD4算法[21]计算数据块的弱校验和和强校验和,数据同步源端通过滑动块寻找出数据同步源端和数据同步终端的差异数据,然后在数据同步过程中只传送差异数据和相同数据块的匹配信息,减少传统数据同步方式中存在的大量冗余数据传输,从而提高网络资源的利用率。数据同步阶段的工作流程如图3所示。
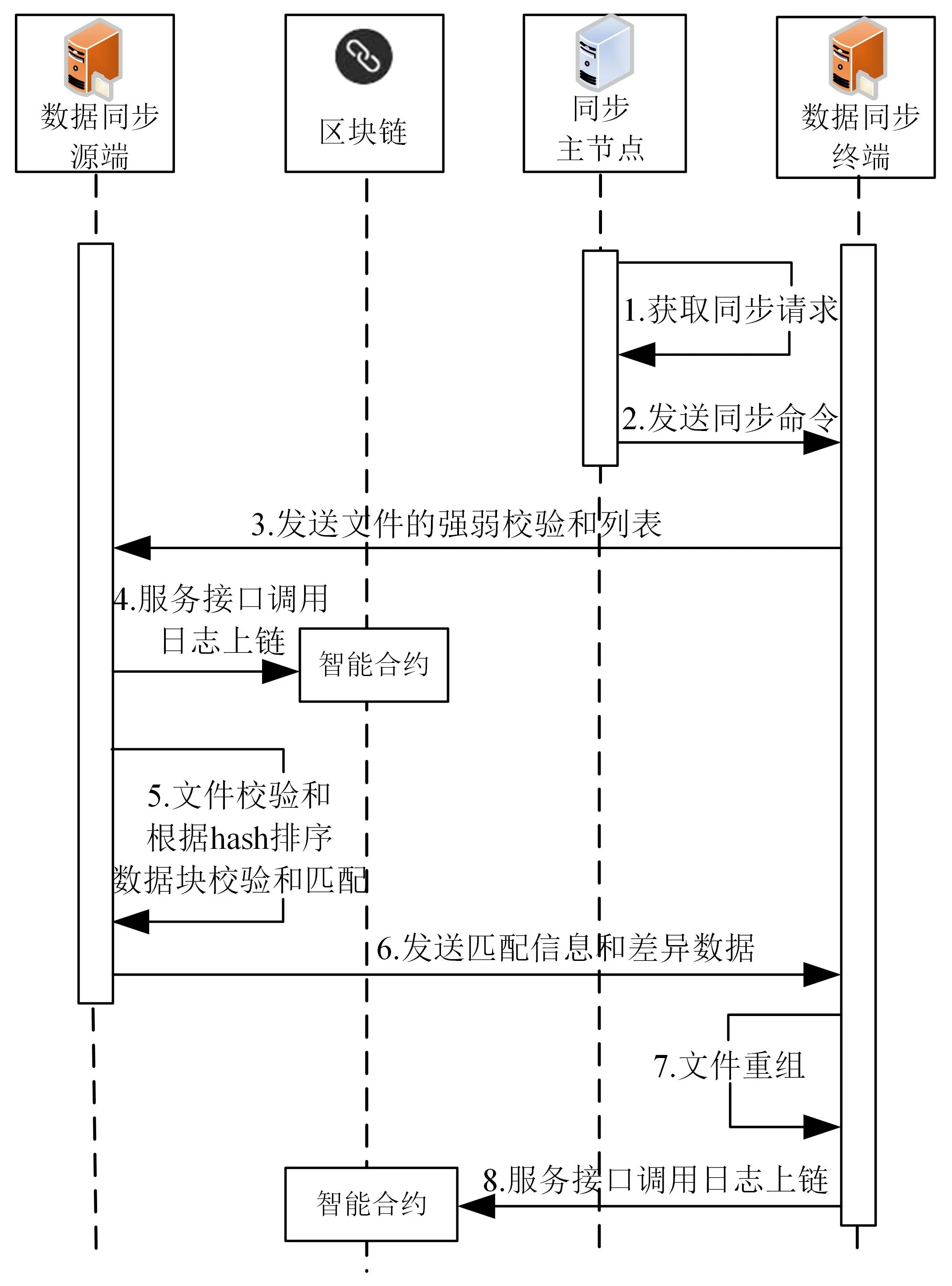
图3 数据同步阶段的工作流程
1)同步主节点获取消息队列中缓存的数据同步请求,在其控制下数据同步源端和数据同步终端进行数据同步操作。
2)同步主节点将数据同步命令发送给数据同步终端。
3)数据同步终端根据数据同步命令中的同步文件在本地文件系统中查询,并将旧文件Fold按照指定的字节数进行分块,分别使用Adler-32算法和MD4算法计算数据块的弱校验和和强校验和,最后将文件的校验和列表发送给数据同步源端。
4)数据同步源端通过智能合约将服务接口调用日志(接口调用者的IP、接口被调用者的Url(IP+接口名)、接口调用时间)上传至数据同步链。
5)数据同步源端接收到文件Fold的校验和列表后,依照强、弱校验和对接收到的数据进行排序并建立 Hash Table。数据同步源端根据Fold的校验和列表同新文件Fnew进行数据块匹配校验,首先,数据同步源端将Fnew从第1个字节开始取相同字节大小的数据块,同样分别使用Adler-32算法和MD4算法计算数据块的弱校验和与强校验和,并且和校验和列表中的校验和进行匹配。如果2个数据块的弱校验和和强校验和均匹配成功,则该数据块在数据同步终端存在,从该数据块的末地址开始下一轮的校验匹配;如果弱校验和或者强校验和匹配不成功,则该数据块在数据同步终端不存在,从该数据块首地址的下一个偏移地址的位置开始下一轮的校验匹配。
6)数据同步源端发送Fnew和Fold的匹配信息和差异数据给数据同步终端。
7)数据同步终端接收Fnew和Fold的匹配信息和差异数据,并进行文件重组。
8)数据同步终端通过智能合约将服务接口调用日志上传至数据同步链。
3 数据同步智能合约
3.1 数据同步智能合约结构体
数据同步智能合约的结构体主要包括数据同步任务结构体DataSyncTask、数据同步终端列表结构体DataDestinations和接口调用结构体InterfaceCall。
1)DataSyncTask结构体的属性、数据类型等信息如表1所示。
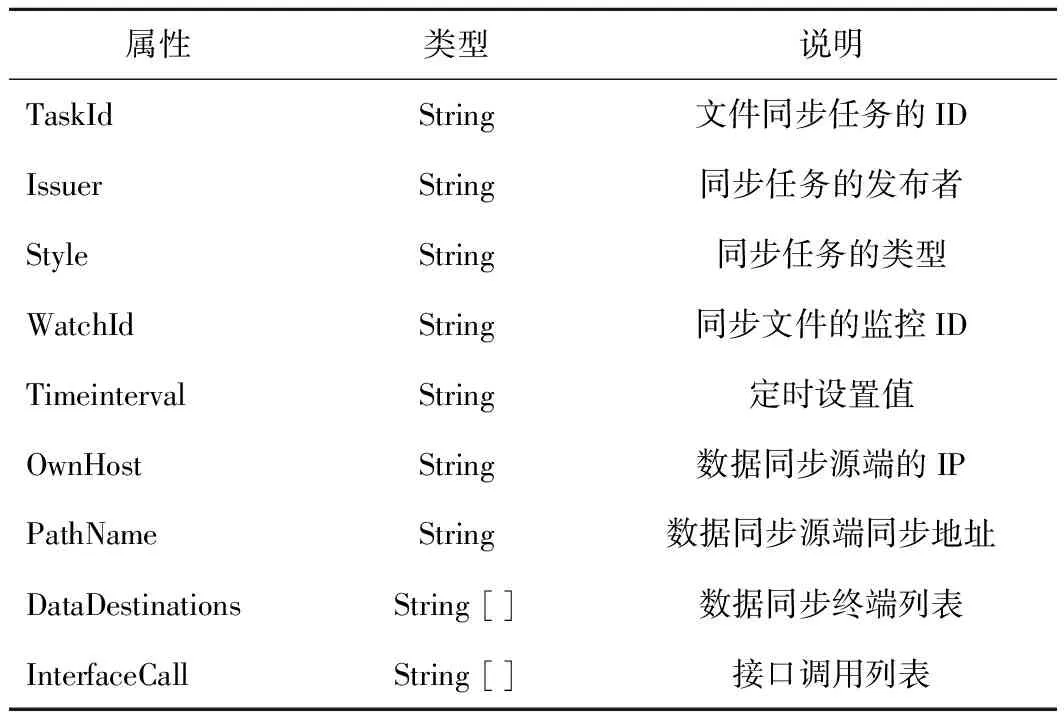
表1 DataSyncTask结构体
2)DataDestinations结构体的属性、数据类型等信息如表2所示。

表2 DataDestinations结构体
3)InterfaceCall结构体的属性、数据类型等信息如表3所示。

表3 InterfaceCall结构体
3.2 数据同步智能合约函数
数据同步智能合约主要具备数据同步任务的链上存储、数据同步任务的链上删除、服务接口调用日志的链上存储、数据同步任务的信息查询等功能。其智能合约函数如表4所示。

表4 数据同步智能合约接口函数
4 基于区块链的数据同步监控与溯源
4.1 数据同步信息存储上链
同步主节点发布数据同步任务后,数据同步系统通过Fabric-java-sdk调用数据同步智能合约的dataSyncTaskEnroll()方法进行数据同步信息的存储上链。算法伪代码如算法1所示。智能合约获取数据同步任务信息,并对dSTask对象进行属性赋值。同步任务的ID(task_Id)和数据同步任务对象序列化后的JSON数据存储在状态数据库中。如果返回的值为空,则表示数据同步信息上链成功,否则返回错误的消息。
算法1dataSyncTaskEnroll
输入:task_Id, style, issuer, watch_Id, time_interval, ownHost, path_Name, data_Destinations
输出:空值
1. if {传入参数}=""then {
2. return "dataSyncTaskEnroll invalid args"
3. end
5. if len(dSTaskBytes) !=0 then
6. return "dSTask already exist"
7. end
12.if err !=null then
13. return “save dSTask error”
14.end
15.return null
4.2 服务接口调用日志存储
数据同步源端和数据同步终端在同步主节点的控制下进行跨域边缘节点之间的数据同步。数据同步过程涉及微服务之间的接口调用,为了确保服务接口调用过程的安全性和可溯源,通过智能合约的InterfaceCallInfoEnroll()方法将服务接口调用日志存储上链。算法伪代码如算法2所示,首先在状态数据库中根据数据同步任务的ID进行查询,如果数据同步任务存在,则将task_Id对应的value值反序列化为dSTask对象,然后将获取到的服务接口调用日志参数赋值给dSTask的InterfaceCall属性,最后将dSTask对象重新序列化为JSON格式存储于状态数据库当中。
算法2InterfaceCallInfoEnroll
输入:task_Id, sr_Ip, url, time
输出:空值
1. if {传入参数}=""then {
2. return "Function invalid args"
3. end
7. if len(dSTaskBytes)=0 then
8. return "dataSyncTask not found"
9. end
12.dSTask.InterfaceCall=append(dSTask.
InterfaceCall, string(InCallBytes))
15.if err !=null then
16. return "save dataSyncTask error"
17.end
18.return null
4.3 数据同步信息溯源检索
当边缘节点存在恶意数据的传播行为时,数据同步系统通过Fabric-java-sdk调用数据同步智能合约的querydataSyncTask()方法进行数据同步信息的溯源检索,其算法伪代码如下算法3所示,通过智能合约在数据同步链上根据数据同步任务的ID从状态数据库中获取相应的数据同步任务信息。
算法3querydataSyncTask
输入:task_Id
输出:dataSyncTaskBytes
1. if task_Id=""then {//验证参数的正确性
2. return "querydataSyncTask invalid args"
3. end
5. if len(dataSyncTaskBytes)=0 then
6. return "dataSyncTask not found"
7. end
8. return dataSyncTaskBytes
5 实验分析
5.1 实验环境
1)数据同步的网络环境。数据同步的网络环境包括5个Windows服务器,用于模拟数据同步集群之间的数据同步。服务器的相关配置具体参数如表5所示。
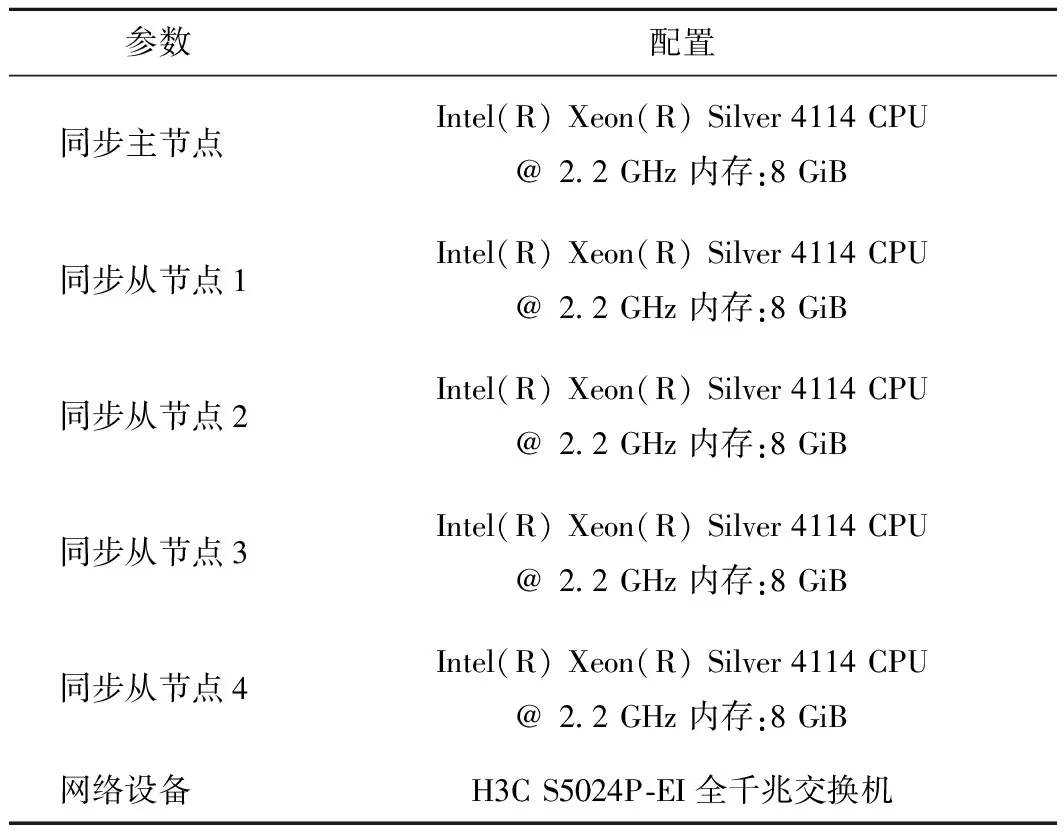
表5 硬件参数表
在一台服务器上部署同步主节点,安装配置RabbitMQ,在其他3台服务器上部署同步从节点,共同构成数据同步集群,模拟在同步主节点的控制下同步从节点之间进行边缘服务器的数据同步。
2)区块链的网络环境。部署区块链平台的服务器、软件信息的基本参数如表6、7所示。

表6 HyperLedger Fabric部署服务器参数表

表7 软件信息表
5.2 实验结果
5.2.1 区块链的性能
用Caliper对Fabric的性能进行测试,在测试过程中,对txNumber分别设置为1 000、5 000、10 000、15 000,txNumber为10 000时,性能测试的结果如表8所示。
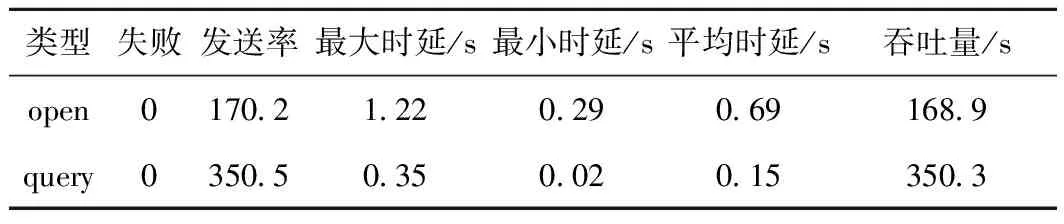
表8 Fabric性能表
由表8可知,在open类型中,将数据写入区块链,区块链的吞吐量能够达到169。在query类型中,从区块链查询数据,区块链的吞吐量能够达到350。在实际的工程应用中能够满足基本的性能要求,并且可以通过提高区块链节点的CPU、内存、磁盘等配置来提升区块链的性能。
5.2.2 数据同步的性能
1)数据的全量同步性能。在相同的网络环境中,在一对三的实验场景下(即数据从一个数据同步源端同步至3个数据同步终端),基于区块链和Rsync的数据同步(Rsync同步)和基于P2P的文件分发(BTS-PD同步)[22]进行1、5、10、50、100、200、250、500 MiB等不同文件大小的数据同步,实验对比结果如图4所示。
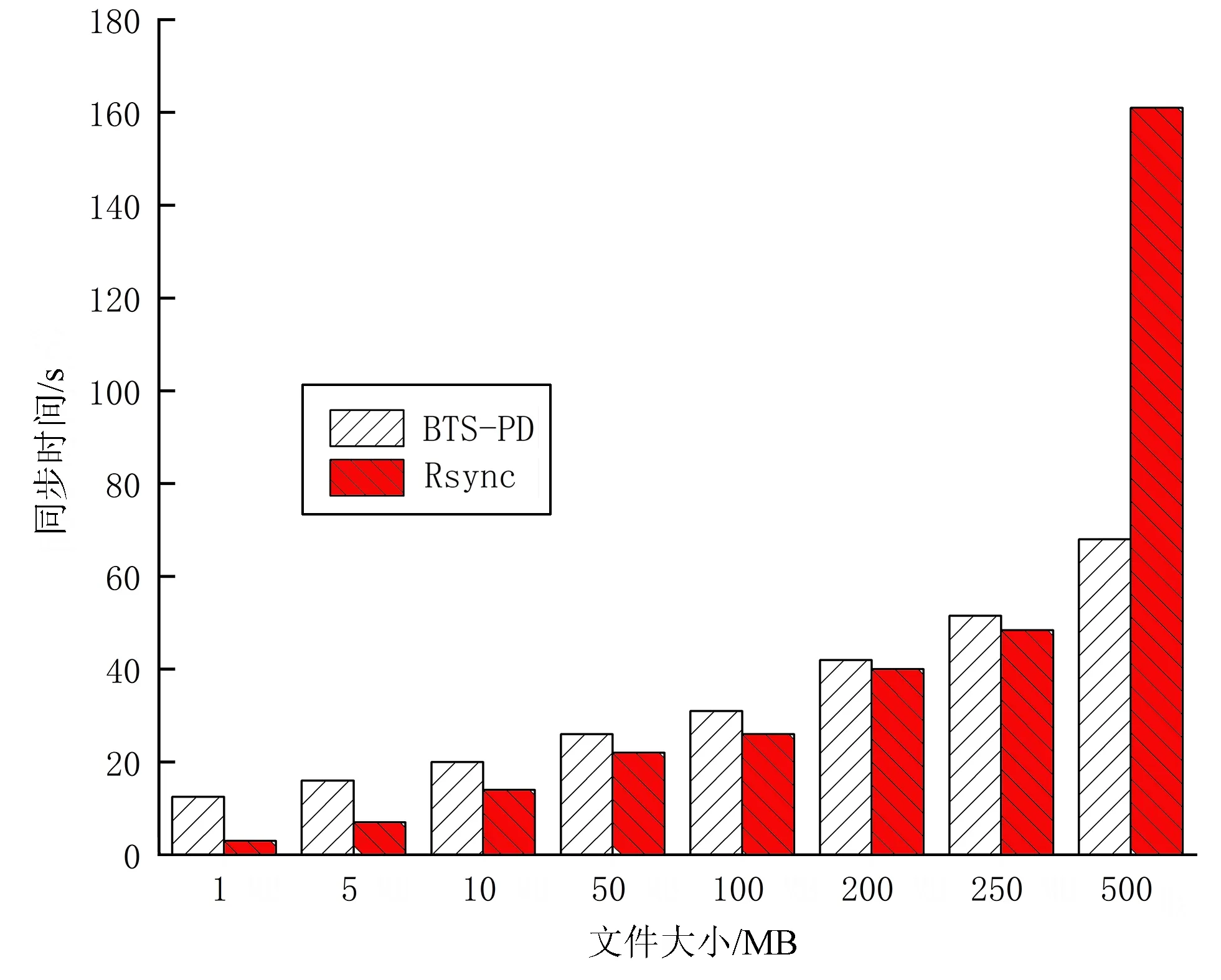
图4 文件的全量同步对比
由图4实验分析可知,当同步的文件小于或者等于250 MiB时,Rsync同步相比于BTS-PD同步更具有优势。当全量同步的文件大小为1 MiB时,BTS-PD同步的时间开销为12.5 s,而Rsync同步的时间开销为仅为3 s,其原因是BTS-PD在进行小文件传输时,其系统初始化等其它额外开销占整个传输过程的比重过大,即在BTS-PD同步中文件做种、种子分发和BTS-PD同步应用启动下载等过程的时间开销相比于文件传输的时间开销大很多。当全量同步的文件大小为250 MiB时,BTS-PD同步的时间开销为51.5 s,Rsync同步的时间开销为47 s左右,其原因是BTS-PD同步随着应用的启动,P2P节点在从其他P2P节点下载数据的同时也向其他P2P节点进行数据的分发共享,以至于BTS-PD同步的下载速度逐渐变大,因此二者的同步时间开销差距总体呈现逐渐缩小的趋势。当全量同步的文件大小为500 MiB时,BTS-PD同步在多节点和大文件的同步中优势较为突出。但本文的研究背景是边缘节点之间的可信数据同步,在边缘节点的数据同步中更多的是小文件同步,其次边缘网络的带宽资源非常重要,基于BTS-PD同步不能实现数据的增量同步,所以BTS-PD同步在边缘节点之间的数据同步存在一定的局限性。
2)数据的增量同步性能。文件夹的增量同步:在一对一的实验场景下,Rsync同步和BTS-PD同步模拟跨域边缘节点之间文件夹的增量同步实验。首先在数据同步源端将100 KiB、1 MiB、10 MiB、100 MiB、500 MiB、1 GiB等不同大小的文件分别放入6个文件夹中,其次将该文件夹同步至数据同步终端,同步结束后再往上述6个文件夹中分别新增10 KiB的差异文件,然后再从数据同步源端同步至数据同步终端。BTS-PD同步需要将该文件夹(包含2个文件,分别是原有的文件和新增的10 KiB差异文件)重新做成种子文件进行批量数据同步,而Rsync同步实现了文件夹的增量同步,由图5的对比实验分析可知,随着同步的文件夹越来越大,BTS-PD同步和Rsync同步的同步时间开销差值越来越大,当同步的文件夹为1 GiB时,BTS-PD同步和Rsync同步的同步时间开销差值能够达到38 s左右,随着同步的节点数越多和发生文件差异变化的文件夹越大,二者的同步时间开销差值在一定条件下也会越来越大。
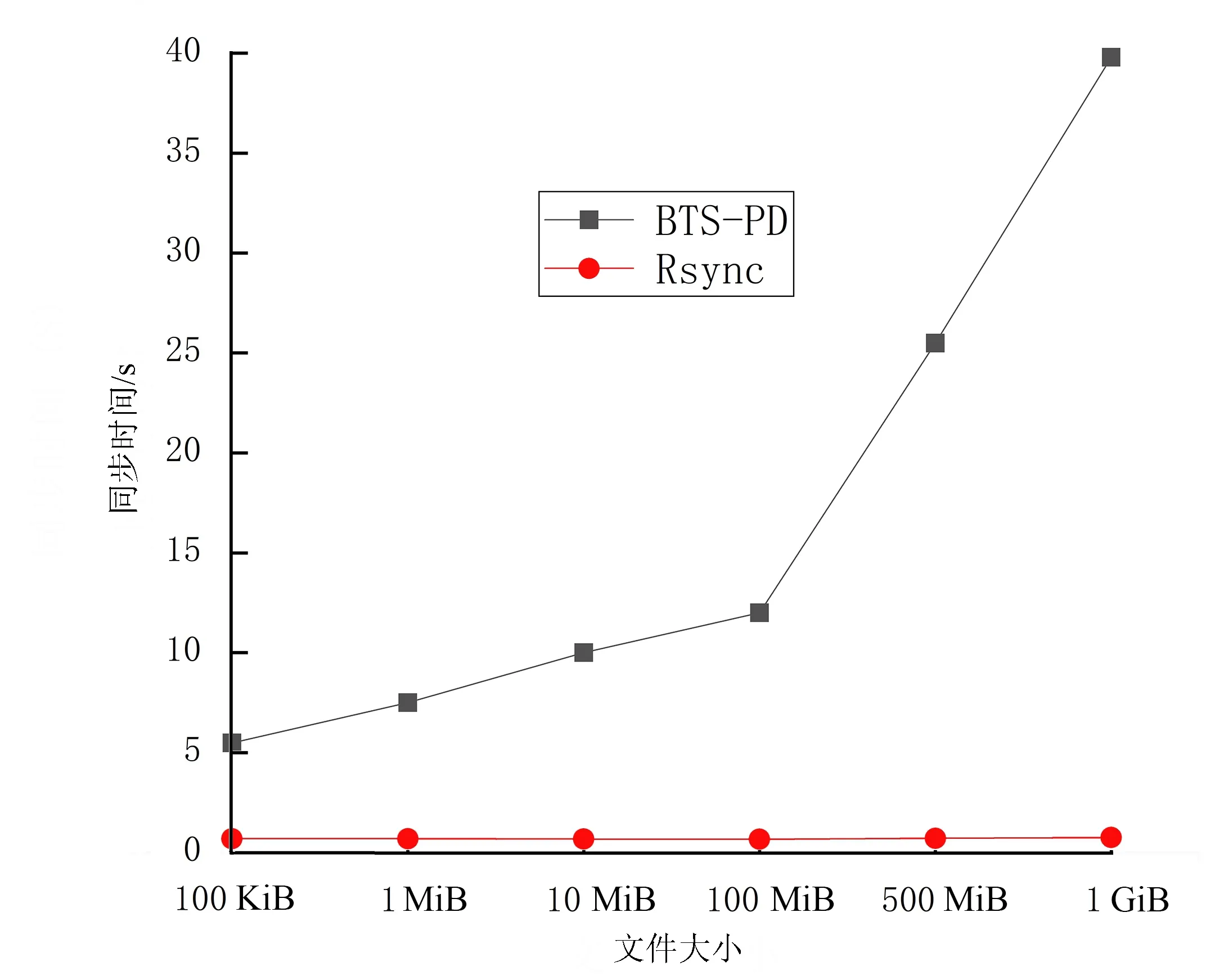
图5 文件夹的增量同步对比
文件的增量同步:在一对一的实验场景下,Rsync同步和BTS-PD同步模拟跨域边缘节点之间文件的增量同步实验。首先在数据同步源端将10 MiB、50 MiB、100 MiB、250 MiB和500 MiB等不同大小文件分别同步至数据同步终端,同步结束后再往上述5个文件中分别新增10 KiB的差异文件,然后再从数据同步源端同步至数据同步终端。BTS-PD同步需要将该变化的文件重新做成种子文件同步至数据同步终端,而Rsync同步可以进行文件的增量同步,由图6的实验结果分析可知,Rsync同步相比于BTS-PD同步而言,其同步时间开销更小,最为重要的是Rsync同步只传文件的匹配信息和差异部分,可减少传统数据同步中存在的大量冗余数据传输问题,提高边缘网络中带宽的利用率。
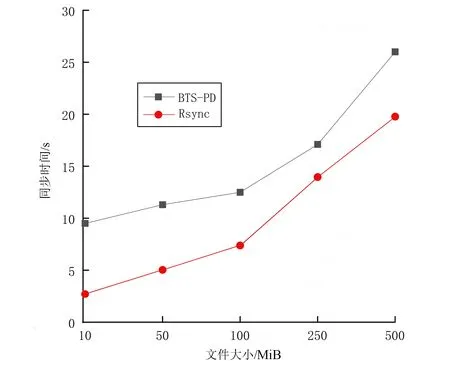
图6 文件的增量同步对比
6 结束语
针对跨域边缘节点之间的可信数据同步需求,引入去中心化、不可篡改、可溯源的区块链技术为数据同步提供可信环境,设计基于区块链的可信数据同步模型架构;基于Rsync算法实现了跨域的数据同步系统,提高了边缘节点之间数据同步的效率和边缘网络带宽的利用率;基于区块链实现数据同步监控与溯源,将服务接口调用日志和数据同步信息存储至区块链中进行溯源,提高了跨域边缘节点之间数据同步的安全性和可靠性;目前该系统已经实地部署并应用。数据同步算法对于数据同步的性能具有重要意义,下一步考虑将同步算法Rsync进行优化,提高增量数据同步的效率。将考虑引入基于P2P的数据同步,制定Rsync和P2P相结合的数据同步策略,完善数据同步机制,提高数据同步的效率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机仿真(2022年6期)2022-07-20
读报参考(2022年1期)2022-04-25
中学生学习报(2022年15期)2022-04-17
机电工程技术(2021年3期)2021-09-10
科学家(2021年24期)2021-04-25
电脑知识与技术·经验技巧(2017年9期)2018-02-24
通信产业报(2016年44期)2017-03-13
电影新作(2014年2期)2014-02-27
雕塑(1999年2期)1999-06-28
