
深度残差网络应用与实践
2021-10-12 07:12翟高粤高乾龙
客联 2021年8期
关键词:深度学习
翟高粤 高乾龙
摘 要:本文先介绍深层神经网络模型特点和应用,并指出其随着层数的加深发展的瓶颈及不足之处;然后引入深度残差网络的概念,以其实现代码为例,详细介绍深度残差神经网络的关键技术特点,最后通过一个实例说明深度残差神经网络在深度学习方面的应用。
关键词:深度学习;残差网络;梯度弥散;梯度爆炸
自2012年AlexNet的提出以来,各种各样的深度卷积神经网络模型相继被提出,其中比较有代表性的有VGG系列,GoogLeNet系列等,它们的网络层数整体趋势逐渐增多。以网络模型在ILSVRC 挑战赛ImageNet数据集上面的分类性能表现为例,在AlexNet出现之前的网络模型都是浅层的神经网络,Top-5错误率均在25%以上,AlexNet 8层的深层神经网络将Top-5错误率降低至16.4%,性能提升巨大,后续的VGG、GoogleNet模型继续将错误率降低至6.7%。
AlexNet、VGG、GoogLeNet等网络模型的出现将神经网络的发展带入了几十层的阶段,研究人员发现网络的层数越深,越有可能获得更好的泛化能力。但是当模型加深以后,网络变得越来越难训练,这主要是由于梯度弥散和梯度爆炸现象造成的。在较深层数的神经网络中,梯度信息由网络的末层逐层传向网络的首层时,传递的过程中会出现梯度接近于0 或梯度值非常大的现象。网络层数越深,这种现象可能会越严重。
一、深度残差网络简介
针对上述问题,如何解决由于层数加深而引起的梯度弥散和梯度爆炸的现象?一个很自然的想法是,既然浅层神经网络不容易出现这些梯度现象,那么可以尝试给深层神经网络添加一种回退到浅层神经网络的机制。当深层神经网络可以轻松地回退到浅层神经网络时,深层神经网络可以获得与浅层神经网络相当的模型性能,而不至于更糟糕。通过在输入和输出之间添加一条直接连接的Skip Connection可以让神经网络具有回退的能力。以 VGG13深度神经网络为例,假设观察到VGG13模型出现梯度弥散现象,而10层的网络模型并没有观测到梯度弥散现象,那么可以考虑在最后的两个卷积层添加Skip Connection。通过这种方式,网络模型可以自动选择是否经由这两个卷积层完成特征变换,还是直接跳过这两个卷积层而选择Skip Connection,亦或结合两个卷积层和Skip Connection的输出。这就是深度残差网络的由来。
2015年,微软亚洲研究院何凯明等人发表了基于Skip Connection 的深度残差网络(Residual Neural Network,简称ResNet)算法,并提出了18层、34层、50层、101层、152 层的ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152等模型,甚至成功训练出层数达到1202层的极深层神经网络。
二、深度残差网络原理
一般来说,网络层数越深,就可以越好的拟合出真实的函数。然而,在网络深度较深时,由于梯度消失,网络的性能反而变差。残差网络很好的解决了梯度消失问题。残差网络的主要思想是通过恒等映射,保证深层的效果不弱于浅层。
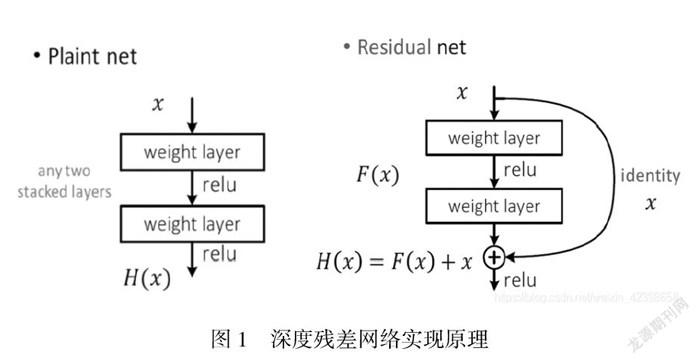
残差网络借鉴了高速网络(Highway Network)的跨层链接思想,但对其进行改进(残差项原本是带权值的,但ResNet用恒等映射代替之)。假定某段神經网络的输入是x,期望输出是H(x),即H(x)是期望的复杂潜在映射,如果是要学习这样的模型,则训练难度会比较大;回想前面的假设,如果已经学习到较饱和的准确率(或者当发现下层的误差变大时),那么接下来的学习目标就转变为恒等映射的学习,也就是使输入x近似于输出H(x),以保持在后面的层次中不会造成精度下降。在残差网络结构图中,通过shortcut connections(捷径连接)的方式,直接把输入x传到输出作为初始结果,输出结果为H(x)=F(x)+x,当F(x)=0时,那么H(x)=x,也就是上面所提到的恒等映射。于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(X)和x的差值,也就是所谓的残差F(x) = H(x)-x,因此,后面的训练目标就是要将残差结果逼近于0,使到随着网络加深,准确率不下降。
这种残差跳跃式的结构,打破了传统的神经网络n-1层的输出只能给n层作为输入的惯例,使某一层的输出可以直接跨过几层作为后面某一层的输入,其意义在于为叠加多层网络而使得整个学习模型的错误率不降反升的难题提供了新的方向。
至此,神经网络的层数可以超越之前的约束,达到几十层、上百层甚至千层,为高级语义特征提取和分类提供了可行性。
三、深度残差网络Python代码实现
深度残差网络并没有增加新的网络层类型,只是通过在输入和输出之间添加一条 Skip Connection,因此并没有针对ResNet的底层实现。在TensorFlow中通过调用普通卷积层即可实现残差模块。
首先创建一个新类,在初始化阶段创建残差块中需要的卷积层、激活函数层等,首先新建卷积层,主要代码如下:
class BasicBlock(layers.Layer):
# 残差模块类
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# f(x)包含了2个普通卷积层,创建卷积层1
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# 创建卷积层2
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
当F(x)的形状与x不同时,无法直接相加,我们需要新建identity(x)卷积层,来完成x的形状转换。紧跟上面代码,实现如下:
if stride != 1: # 插入 identity 层
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else: # 否则,直接连接
self.downsample = lambda x:x
在前向传播时,只需要将F(x)与identity(x)相加,并添加ReLU激活函数即可。前向计算函数代码如下:
def call(self, inputs, training=None):
# 前向传播函数
out = self.conv1(inputs) #通过第一个卷积层
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out) #通过第二个卷积层
out = self.bn2(out)
# 输入通过 identity()转换
identity = self.downsample(inputs)
# f(x)+x 运算
output = layers.add([out, identity])
# 再通过激活函数并返回
output = tf.nn.relu(output)
return output
代码原理图如图1所示。
图1 深度残差网络实现原理
四、总结
残差网络结构简单,解决了极深度条件下深度卷积神经网络性能退化的问题,分类性能表现出色。本文先通过例子说明非常深的网络很难训练,存在梯度消失和梯度爆炸问题,学习 skip connection它可以从某一层获得激活,然后迅速反馈给另外一层甚至更深層,利用 skip connection可以构建残差网络ResNet来训练更深的网络,ResNet网络是由残差模块构建的。这种方式能够到达网络更深层,有助于解决梯度消失和梯度爆炸的问题,让我们训练更深网络同时又能保证良好的性能。
参考文献:
[1] 刘航等.基于深度残差网络的麦穗回归计数方法[J],中国农业大学学报,2021(4).
[2] 张宇等.融入注意力机制的深度学习动作识别方法[J],电讯技术,2021(4).
[3] 闫涛. 深度学习算法实践 [M]. 电子工业出版社出版社,2020.
[4] 王宇石等.一种基于卷积神经网络的违禁品探测系统及部署方法[J],科技创新与应用,2020(7).
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
