
基于门控机制和卷积神经网络的中文文本情感分析模型
2021-11-05 01:29何明祥
计算机应用 2021年10期
杨 璐,何明祥
(山东科技大学计算机科学与工程学院,山东青岛 266590)
0 引言
随着互联网的快速发展,人们在诸多平台上留下了大量带有情感观点的主观性文本,例如微博私信、微信聊天、淘宝咨询等,这些文本蕴含着丰富的情感信息,通过对这些文本进行分析,可以挖掘出有效的观点信息[1];然而,人工提取这类文本数据工作量较大,因此如何构建自动化提取文本情感倾向的模型引起人们的关注。
文献[2]提出了文本评论情感极性分类的概念,并且利用统计学的方法对电影评论数据集进行分类。文本情感分析指的是利用自然语言处理(Natural Language Processing,NLP)或者文本分析技术自动识别文本数据的情感极性。情感分析方法包括基于情感词典和规则的情感分析方法[2]和基于机器学习技术的情感分析方法[3],其中基于情感词典的方法主要利用情感词典与分词后的文本进行比较,通过制定规则来获取整个句子的情感分数,达到识别情感极性的目的,例如:文献[4]通过对HowNet 情感词典和台湾大学的情感词典(National Taiwan University Sentiment Dictionary,NTUSD)进行扩展,建立了一个具有不同情感倾向程度的情感词典,并基于此开发了一个半自动化网络舆情分析系统;文献[5]提出将多个现有的情感词典进行合并去重作为基于HowNet 和SentiWordNet的中文情感词典(Sentiment Lexicon based on HowNet and SentiWordNet,SLHS)的基础词语集,采用支持向量机(Support Vector Machine,SVM)的方法对文本进行情感分析,与台湾大学情感词典方法进行对比可知,该情感词典具有较优的结果。
基于机器学习技术的情感分析方法又分为监督学习的情感分析方法和无监督学习[6]的情感分析方法,有监督学习凭借带标签的数据训练分类器,所得到的准确率和F1值略优于无监督方法;然而,在应对大规模数据集时,两种方法的效果都有所欠缺。深度学习的出现,凭借其自动表征信息的学习功能和较好的识别效果[7],引起了学者的关注。
随着深度学习技术的发展,神经网络被广泛地应用到各项任务,其中包括文本情感分析。例如,文献[8]提出了一种利用卷积神经网络(Convolutional Neural Network,CNN)对文本进行分类的算法,利用具有局部特征提取功能的卷积层来提取句子中的关键信息,达到了理想的效果。针对提取句子的序列特征,文献[9]提出了一种深度记忆网络,该模型利用双向长短期记忆网络获取句子的上下文特征,再经过多计算层,从而挖掘句子和目标的特征信息。文献[10]提出了一种多注意力的卷积神经网络模型,该模型能够接收平行化的文本信息,并且针对特定目标识别出其情感极性。尽管神经网络模型取得了较好的效果,然而中文文本情感分析领域中由于中文文本分词的特殊性,容易产生噪声信息,噪声信息在情感分类时会影响分类结果,而且传统的卷积神经网络不能挖掘深层的情感信息。门控机制在长短期记忆(Long Short-Term Memory,LSTM)网络中已经证明了其可用性,在控制信息传递方面能够发挥优势,因此本文利用门控机制和现有的情感词典来剔除噪声信息,挖掘深层情感信息。
本文提出了一种结合情感词典的双输入通道门控卷积神经网络(Dual-Channel Gated Convolutional Neural Network with Sentiment Lexicon,DC-GCNN-SL)模型,该模型利用情感词典对分词文本进行情感分数标记,将情感分数高的词筛选出来,从而有效地剔除文本中含有的噪声。为了防止破坏原有语义信息,将分词的文本和筛选后的文本分别经过两个通道输入到卷积神经网络中,可以使模型学习到更多的信息,使用基于GTRU(Gated Tanh-ReLU Unit)的门控层处理特征信息,进一步挖掘深层特征信息,控制训练过程中信息在网络中的传递。通过在不同数据集上的实验,验证了本文模型的有效性。
本文的主要工作如下:
1)提出了一种DC-GCNN-SL 模型用于中文情感分析任务。该模型将情感词典和门控卷积神经网络相结合,有效提高了情感分析的性能。
2)提出了一种使用情感词典标记和筛选句子中的词的方法。该方法通过使用词典中的情感分数,提供情感先验知识,去除情感分数不高的词,达到了控制噪声信息的目的。
3)提出了一种基于GTRU 的门控卷积层,通过与双通道的卷积核单元相连接,控制信息在网络中的传递,进一步挖掘文本情感特征。
在三个不同数据集上进行对比,实验结果表明,本文提出的DC-GCNN-SL 模型具有更好的情感表达能力,在中文情感分析任务中取得了更好的准确率、召回率和F1值。
1 相关工作
1.1 卷积神经网络
卷积神经网络是一种典型的前馈神经网络,源于生物中感受野[11]的概念。卷积神经网络凭借强大的特性,逐渐被应用在各种领域,其中就包括自然语言处理(Natural Language Processing,NLP)领域。在NLP 领域,卷积神经网络涉及的数据为文本数据,词向量决定卷积核的宽度,再利用不同高度的卷积核对词向量矩阵进行卷积操作。因此,卷积神经网络可以利用不同大小的卷积核自动地学习到文本不同粒度的隐藏特征,也可以将学习到的特征传递到其他模型进行分类。
文献[12]提出了一种双通道的卷积神经网络来学习文本特征,将使用Word2Vec训练的词向量和字向量通过两个不同的通道进行卷积运算,使用不同尺寸的卷积核获取特征,完成文本分类;然而模型只是简单地将两个通道的特征进行合并,不能充分利用提取到的特征。文献[13]将双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)网络和CNN模型串联起来,提取文本的上下文特征和局部语义特征,从而提供文本情感准确率,但是同时也带来了模型不能并行处理数据、训练时间长的问题。文献[14]提出了一种卷积神经网络融合图文信息的情感分析方法,输入数据变成了图片和文本的结合,融合了图文特征进行情感分析。
1.2 门控机制
基于GTU(Gated Tanh Unit)、GLU(Gated Linear Unit)和GTRU 的门控机制在自然语言处理领域中应用广泛[15],获取了较好的效果。文献[16]提出了一种基于非残差封装的门控卷积机制和层次注意力的方法来解决单一词变量引发的歧义问题,该模型利用卷积神经网络计算多语义词向量,构建了一种非对称语义窗口,利用注意力机制计算目标单词语义权重的方法来合成语义向量;文献[17]使用带有方向的门控单元来处理基于aspect 的情感分析任务,利用非线性门与卷积层连接,进行重要特征的筛选,并使用SemEval 数据集验证了模型的有效性;文献[18]针对远程监督关系抽取任务中存在的噪声过滤问题,提出了一种融合门控过滤机制的分段池化卷积神经网络方法,显著地提升了模型的整体性能。可见,门控卷积神经网络在自然语言处理所用的效果较好,其中包括利用基于GTRU 的特定目标情感分析、基于GLU的事件监测,然而门控卷积神经网络处理句子层面文本情感分析任务的模型较少,凭借门控机制在控制信息传递的良好特性,本文提出了一种基于GTRU 的门控卷积网络模型,用于处理双通道的特征信息,完成文本情感分析任务。
2 结合情感词典的双输入通道门控卷积神经网络模型
本文构建的模型如图1 所示,可分为预处理部分、词嵌入层、基于GTRU 的门控卷积层、池化层和全连接层及分类层。首先,使用Word2Vec模型训练情感词典监督的数据和原始数据后得到对应的词向量,分别通过两个不同的通道输入到卷积层中;然后,利用卷积层的卷积操作来获取文本的初步特征表示,再使用基于GTRU 的门控机制对初步特征进行优化,并控制信息传递;再用池化层对上一层的特征进行池化操作,得到最优特征;最后,使用全连接层和分类层处理特征,完成文本的情感分类。
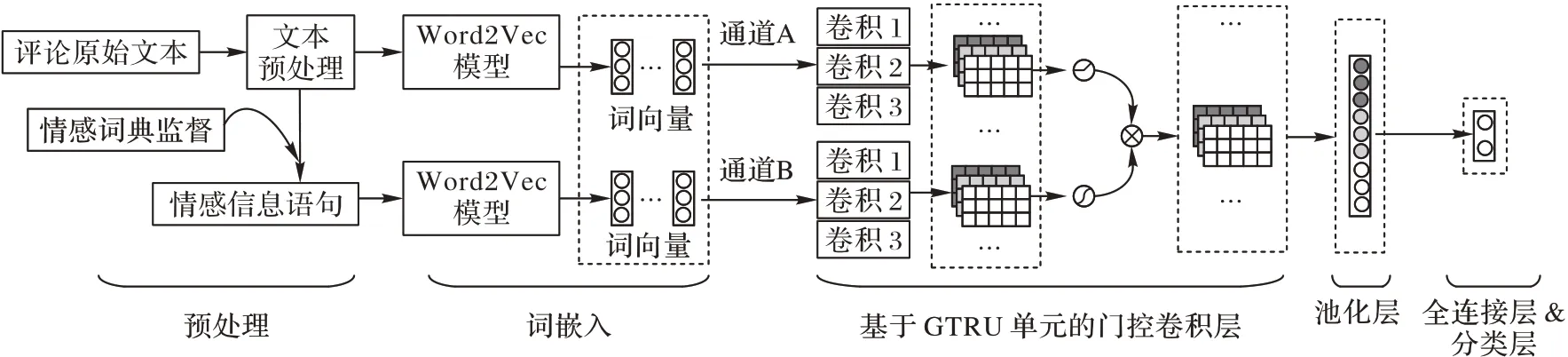
图1 DC-GCNN-SL模型结构Fig.1 Structure of DC-GCNN-SL model
2.1 情感词典监督算法
中文文本情感分析需要模型对当前的文本进行特征提取和情感特征学习,完成情感极性的判别。在文本特征提取之前,需要进行文本预处理操作,本文使用jieba 分词工具(https://github.com/fxsjy/jieba)对中文文本进行分词处理,得到组成句子的每一个词。传统的神经网络模型在分词后直接训练词向量,这会导致在分词后存在噪声信息,噪声信息会随着词向量进入网络参与训练,导致模型的效果下降;另外,神经网络模型忽视了现有的一些情感知识,导致了情感资源的浪费。
因此,为了增强网络先验知识、去除噪声信息、提高模型情感分析的准确率,本文利用情感词典对分词后的数据进行标记,记录下词典中该词的情感分数,如果词典中不存在该词,则分数为0;再根据词语的情感分数绝对值筛选词语。例如句子“不怎么样的酒店。我是1 月11 日住的,天气特别冷,房间空调根本就不管用,我在房间待了4 个小时,手脚冰凉,最后没有办法打电话投诉,给我加了个电暖气。反正以后不会在住这里了,青岛有好多好酒店,我自己也遗憾为什么选择这里。”经过分词处理和情感词典监督后,得到“不怎么样,的,酒店,,是,的,天气,特别,冷,空调,根本,就,不管,用,在,待,最后,没有,办法,打电话,投诉,效果,反正,以后,不会,在,住,这里,了,青岛,有,好多,好,酒店,我,自己,遗憾,为什么,选择,这里”。可以看出,处理后的句子去除了一定的噪声,没有改变句子的极性信息。情感词典监督算法过程如下:
算法1 情感词典监督算法。
输入 中文文本数据X,情感词典D;
输出 经过词典筛选的数据S。
步骤1 逐步输入中文文本数据,对文本数据进行预处理操作,删除特殊字符,清洗数据。
步骤2 对中文数据进行分词,去除停用词,得到中文数据X'。
步骤3 将中文数据X'的情感分数都设置成0。
步骤4 对i从1 到n进行判断,对比中文数据第i个词是否在情感词典中出现:若出现,分数设置成情感词典中的分数,并将该中文数据xi加入S中;否则i+1,重复步骤4。
步骤5 输出中文数据S。
2.2 DC-GCNN-SL模型构建
2.2.1 词嵌入层
为了将自然语言数字化,本文使用skip-gram 模型[19]对分词后的单词进行词向量训练,使用三层神经网络将词表示为空间向量形式。对具有n个词的句子,经词嵌入表示后可得到S=[x1,x2,…,xn],xi∈Rd,其中,d表示词向量的维度,即每个词用d个实数表示。则句子S可以用x1:n表示为:

其中:⊕表示拼接操作;x1:n∈Rd×n。
2.2.2 原始句子卷积通道
为了保证情感词典筛选后不丢失信息,本文所提模型由两个输入通道获取句子信息,无词典标记的原始通道和带有词典监督的通道,分别通过两个输入通道使用卷积神经网络进行特征提取,利用不同尺寸的卷积核对词嵌入层的向量矩阵作卷积操作,提取序列中不同粒度的文本特征,可以获得较好的特征序列矩阵,生成不同的特征矩阵输入到下一层。取卷积核为h的滤波器与无词典标记通道的输入向量进行卷积运算得到特征序列,生成的特征序列如式(2)所示:

其中:WA表示权重矩阵;bA表示偏置向量表示句子矩阵中从i到i+h-1的词语向量矩阵;f(·)表示用于非线性变换的激活函数。步长为1的卷积,在长度为n的序列上计算结束后,可得到n-h+1个输出,最终生成的特征集合为:

2.2.3 情感词典监督卷积通道
句子经过词典监督后筛选出文本情感倾向最强的特征,对于该输入向量使用相同大小的卷积核处理,经过卷积操作,来完成输入句子的情感特征层面特征的提取。对于窗口大小为h的卷积,得到的特征序列可以表示为式(4):

其中:WB表示权重矩阵;bB表示偏置向量表示经过词典监督后的句子矩阵,通过卷积操作可得到特征序列矩阵合并后得CB。
2.2.4 基于GTRU的门控卷积层
考虑到充分挖掘文本情感特征,获取深层次的特征信息,模型使用基于GTRU 的门控卷积层,来结合两个通道得到的特征信息。基于GTRU 的门控运算可以获得与较强情感信息的词的信息,控制情感信息和噪声数据的传递,将两个特征序列CA和CB作为门控卷积层的输入,通过对位相乘的方法可以得到:

则生成的特征组合可以表示为:

2.2.5 池化层
为了将门控层得到的特征矩阵CG固定在同一维度,解决特征维度过高产生的问题,往往加入池化操作。本文采用最大池化层,提取出句子最重要的特征,生成固定维度的特征向量。最大池化目的是从卷积神经网络中提取关键特征,降低向量维度,进一步缩小网络的规模。对每个门控卷积通道单独进行池化操作,选取特征向量中的最大值来表示这一特征,其计算式如式(7)所示:

假设卷积核的数量为m,则最终生成的池化特征集可以表示为:
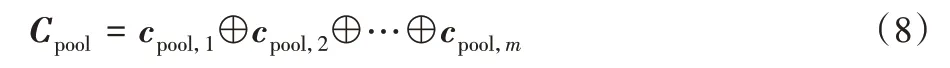
2.2.6 输出层
将池化得到的特征作为全连接层的输入,使用tanh 函数作为激活函数,全连接层可以表示为:

其中:O∈Rq为全连接层的输出,q表示输出向量的维度;Wh∈Rq×m为全连接层的权重矩阵;bh∈Rq为全连接层的偏置向量。通过全连接层可以更好地过滤影响分类性能的特征,为防止过拟合加入dropout 机制,在每次训练时舍弃一部分神经元,最后将得到的结果输入到sigmoid 分类器中,完成情感分类。
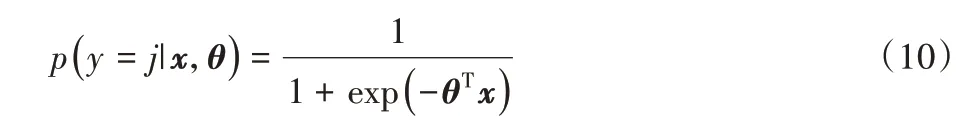
其中:j表示类别数,在二分类中取值为0 或1;θ表示模型的所有参数。
2.3 模型训练
本文使用带标签的数据,利用反向传播算法训练模型,训练目标是将模型最小化损失函数,损失函数使用交叉熵(categorical Cross-entropy)函数,其计算式为:

3 实验与结果分析
3.1 实验环境
本文的实验环境如下:操作系统为Windows 10,处理器为AMD Ryzen 5 2600 Processor 3.40 GHz,内存大小为16 GB,开发工具使用的是Python 3.6,深度学习框架为Keras 2.1.2。
3.2 实验数据
为了评估模型的有效性,本文使用真实外卖评论数据集、真实商品评论数据集和谭松波博士整理的酒店评论数据集(http://www.searchforum.org.cn/tansongbo/senti_corpus.jsp),如表1~2所示。

表1 实验所使用的数据集Tab.1 Datasets used in experiments
按照8∶2 的比例划分训练集和测试集。情感词典选择BosonNLP 情感词典(http://bosonnlp.com),表3 给出了部分词典示例。

表2 不同数据集的数据示例Tab.2 Data samples of different datasets
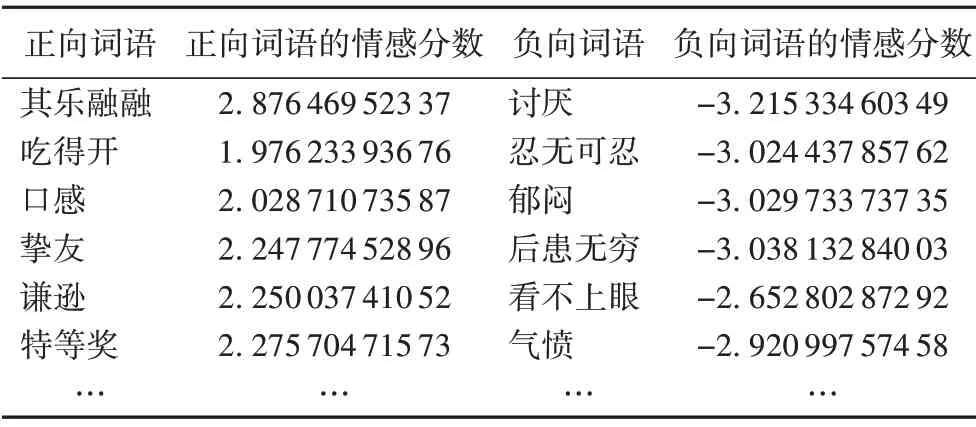
表3 BosonNLP情感词典部分示例Tab.3 Some samples of BosonNLP sentiment lexicon
3.3 实验参数
本文使用的实验参数如表4 所示,为了损失函数最小化,使用1E-3 学习率的Adam 算法训练模型。网络训练流程如图2所示。
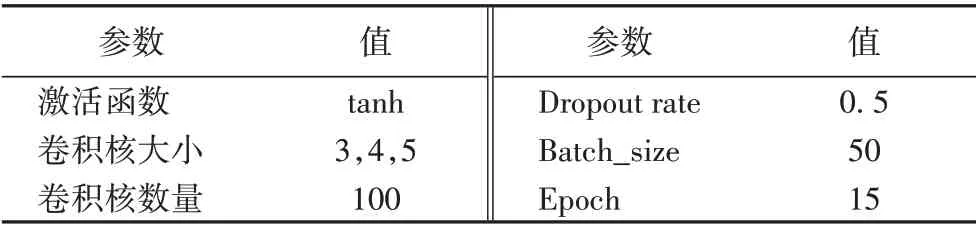
表4 实验参数配置Tab.4 Experimental parameter setting

图2 DC-GCNN-SL网络训练流程Fig.2 Flowchart of DC-GCNN-SL network training
3.4 评价指标
采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值作为评价指标,计算方法如下:

其中:TP(True Positive)表示事实为正样本,预测也为正样本的数量;TN(True Negative)表示事实为负样本,预测也为负样本的数量;FP(False Positive)表示事实为负样本,预测为正样本的数量;FN(False Negative)表示事实为正样本,预测为负样本的数量。Accuracy 表示所有文本正确识别情感倾向的比例,Precision 表示正样本中正确识别情感倾向的比例,Recall表示正确预测的正样本占所有正样本的比例,F1 值为Precision 和Recall 的调和平均值,指标的值越大表示分类效果越好。
3.5 结果分析
本文设置了3 组不同实验来测试模型的性能,选取部分实验结果作为展示。
实验1 为了测试词嵌入维度对DC-GCNN-SL 模型分类性能的影响,本文取词向量维度为[10,30,50,100,200,300],测试不同的取值对其准确率的影响。
图3 是DC-GCNN-SL 模型在3 个数据集上词嵌入维度不同取值时的准确率结果。

图3 DC-GCNN-SL模型在三个数据集上的实验结果Fig.3 Experimental results of DC-GCNN-SL model on three datasets
从图3 中可以看出,当选取的维度值较小,则得到的文本特征不充分;选取的维度值太大,则文本特征冗余。由此可以看出随着词向量维度的增加,DC-GCNN-SL 模型的准确率会上升;但是当词向量维度取值为300 时,与词向量维度取值为200 时相比,DC-GCNN-SL 模型的准确率有所下降。从实验1可以看出,综合考虑,在后续所有实验中,选择的词向量维度为100。
实验2 为了测试模型的情感分析性能,本文将其与以下神经网络模型进行对比,包括:
1)融合卷积神经网络和注意力的情感分析模型(ADCNN)[20]。输入为Word2Vec 训练的词向量,使用卷积神经网络和K最近邻(K-NearestNeighbor,KNN)算法,融合注意力机制,获取文本更多的信息。网络参数按照文献[20]设置。
2)递归卷积神经(Recursive Convolutional Neural Network,RCNN)[21]。使用递归结构卷积神经网络,能捕获上下文信息,使用自动判断的池化层获取关键信息。
3)卷积神经网络(CNN)。普通的卷积神经网络,实验参数设置与3.3 节保持一致,使用相同的词向量作为输入,经过卷积层、池化层、全连接层和分类层输出结果。
4)循环神经网络(Recurrent Neural Network,RNN)[22]。使用流行的循环神经网络分析句子的情感,输入为Word2Vec训练的词向量,使用RNN结构提取句子特征。
5)长短期记忆(LSTM)网络[23]。使用单方向的长短期记忆网络进行训练,神经元数量为128。
6)双向长短期记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)网络[24]。输入为Word2Vec训练的词向量,使用双向的长短期记忆网络进行训练,神经元数量为128。
表5~7 给出了不同模型在酒店评论数据集、外卖评论数据集和商品评论数据集上的实验结果。

表5 不同模型在酒店评论数据集上的实验结果对比 单位:%Tab.5 Experimental result comparison of different models on hotel review dataset unit:%
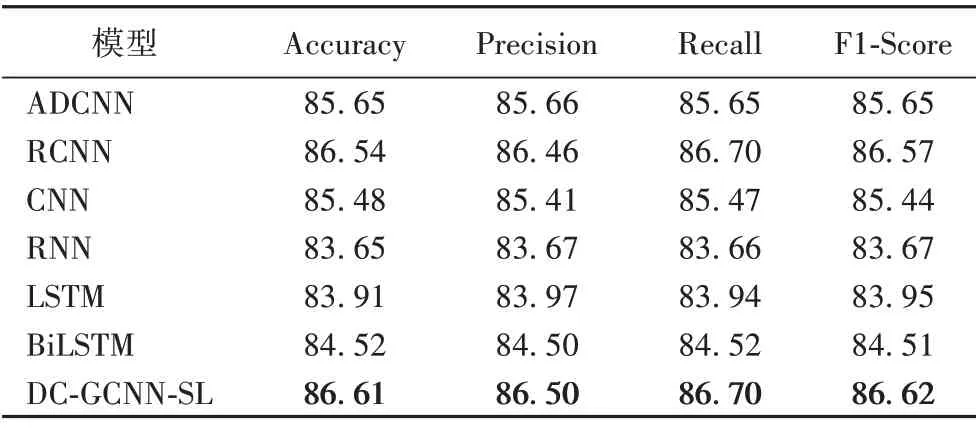
表6 不同模型在外卖评论数据集上的实验结果对比 单位:%Tab.6 Experimental result comparison of different models on takeaway review dataset unit:%
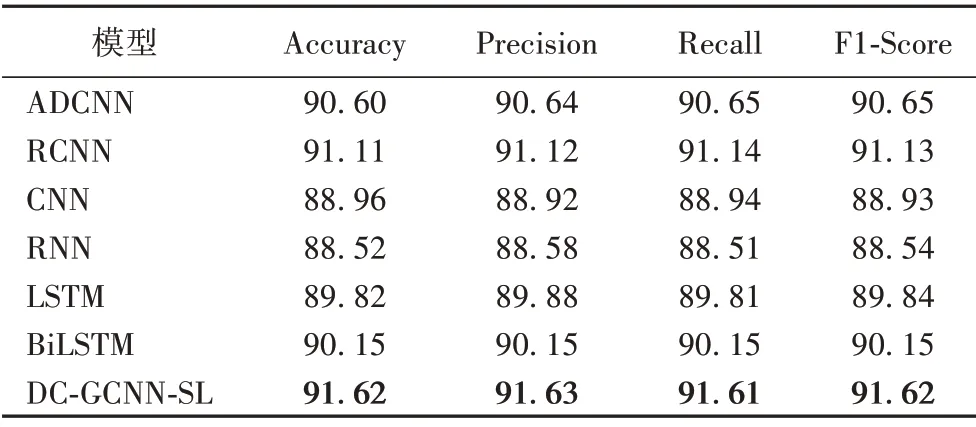
表7 不同模型在商品评论数据集上的实验结果对比 单位:%Tab.7 Experimental result comparison of different models on commodity review dataset unit:%
从表5~7 可以看出,在酒店评论数据集和商品评论数据集的实验结果明显优于外卖评论数据集上的实验结果,原因在于外卖评论数据集的样本数虽然达到12 000 条,但是词典大小明显小于另外两个数据集的词典,导致Word2Vec训练的词向量表达能力不佳,这是由输入所决定的。
通过比较表5~7 的不同模型的实验结果,可以发现:RNN模型的结果相较于LSTM 结果性能较差,原因在于LSTM 避免了梯度消失或爆炸的问题,能够捕捉长距离文本特征;BiLSTM模型相较于LSTM模型,采用了双向结构,能够捕获两个方向的序列特征,效果更好。在外卖评论数据集上的实验结果表明,句子长度较短的文本(平均长度为40)更适用CNN模型,CNN 模型提取局部特征的优势也更容易发挥。通过进一步比较不同模型的实验结果,DC-GCNN-SL 模型的实验结果均优于其他模型,表明使用情感词典监督文本,可以去除文本内含有的噪声信息,使用基于GTRU 的门控卷积机制能够增强神经网络模型的分类能力。
实验3 为了测试卷积神经网络中卷积核大小对模型准确率的影响,设置了不同的卷积核大小来计算情感分类的准确率。本文设置了7 组不同的卷积核大小,卷积核数量设置为100,分别在酒店评论数据集、外卖评论数据集和商品评论数据集上进行实验。
表8 为不同卷积核的DC-GCNN-SL 模型在3 个数据集上的准确率。
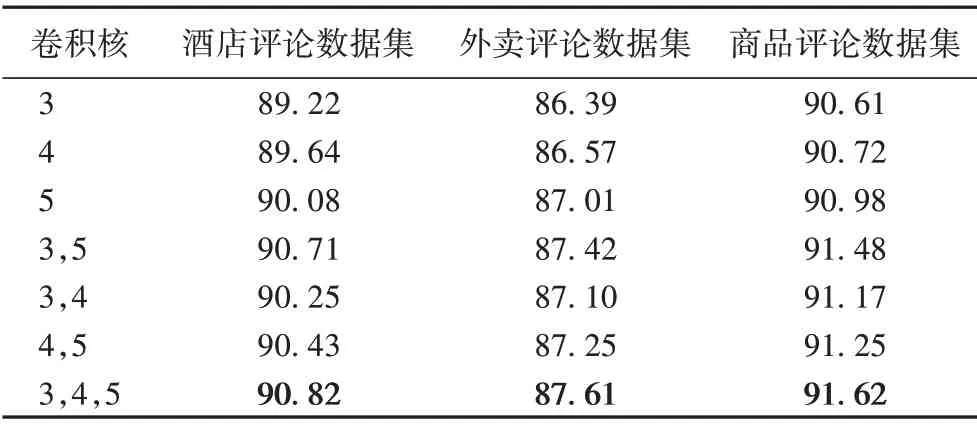
表8 不同卷积核的模型在三个数据集上的准确率对比 单位:%Tab.8 Accuracy comparison of models with different convolution kernels on three datasets unit:%
从表8 中可知,卷积核尺寸为(3,4,5)的模型的在数据集上进行实验得到的准确率均高于其他的卷积核模型,这是因为不同大小的卷积核可以获取到不同粒度的文本特征,得到的局部特征更加丰富,对分类的准确率有促进效果,比使用单一尺寸的卷积核效果要好。因此,本文使用卷积核为(3,4,5)的模型进行实验,有助于获得更好的情感分析结果。
3.6 门控机制
本文中的门控机制使用GTRU 控制信息传递到池化层,可以有效地获取情感信息。门控机制在LSTM 上已经被证明是有效的,而在CNN 中,门控机制的选择有基于GTU、GLU 和GTRU 的结构,不同结构的区别在于门函数的不同:GTU 的门函数为tanh门和sigmoid门,GLU的门函数为线性门和sigmoid门,而GTRU 的门函数为tanh 门和relu 门。为了更好地对比三种不同结构的结果,在酒店评论数据集上进行了实验,模型的区别仅为门控单元的不同,实验结果如表9所示。

表9 不同门控单元的模型在酒店评论数据集上的实验结果 单位:%Tab.9 Experimental results of models with different gated units on hotel review dataset unit:%
从表9可以看出,使用GTRU的模型与另外两个门控单元的模型进行对比,GTRU 的模型的分类效果略优于GTU 的模型,表明GTRU 能够获取深层情感特征信息,完成文本的情感极性判别。GLU 的分类效果最差,由于模型结构仅有一层卷积层,可知在单一卷积层的网络结构中,GLU在防止梯度消失的作用并不能发挥出来,反而降低了获取特征信息的优势。
4 结语
针对传统神经网络不能挖掘深层情感信息和中文文本噪声的问题,本文提出了一种结合情感词典的门控卷积神经网络模型。所提模型避免了文本噪声信息影响情感极性判断,利用情感词典筛选文本有用信息,获取了情感先验知识,同时利用门控卷积操作,捕获深层情感特征,获取文本情感极性。在不同的数据集上进行了大量实验,实验结果验证了本文所提模型的有效性。
由于数据类型的不同,英文情感分析任务与中文数据相比,英文具有天然优势,不需要进行分词处理。目前也存在大量的英文情感词典,下一步的工作重心是研究本文模型在英文数据情感分类任务的有效性,并且将考虑语法结构与神经网络的结合,引入更多文本特征来提升文本情感分析任务的性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
