
复杂异构计算系统HPL 的优化∗
2021-11-09 02:45黎雷生杨文浩马文静赵海涛李会元孙家昶
软件学报 2021年8期
黎雷生 ,杨文浩 ,马文静 ,张 娅 ,赵 慧 ,赵海涛 ,李会元,孙家昶
1(中国科学院 软件研究所 并行软件与计算科学实验室,北京 100190)
2(计算机科学国家重点实验室(中国科学院 软件研究所),北京 100190)
HPL(high performance Linpack)是评测计算系统性能的程序,是早期Linpack 评测程序的并行版本,支持大规模并行超级计算系统[1],其报告的每秒浮点运算次数(floating-point operations per second,简称FLOPS)是世界超级计算机Top500 列表排名的依据.
基于Linpack 的Top500 排名开始于1993 年,每年发表两次.2007 年11 月及之前的列表,排名前10 位的超级计算机的计算能力全部由同构CPU提供.2008年6月Top500首台性能超过1 PFLOPS 的超计算机Roadrunner使用异构CPU 结构,通用CPU 执行调度、管理等任务,加速CPU 主要负责计算密集任务.2009 年11 月排名第5 位的Tianhe-1 使用了CPU+GPU 的异构架构.此后榜单上排名前10 的系统CPU+加速器的架构成为趋势.2019年6 月最新的排名显示,前10 位中有7 台系统使用CPU+加速器架构,其中使用GPU 加速器的5 台,使用XEON Phi 的1 台,使用Matrix-2000 的1 台[2].
HPL 浮点计算集中在BLAS 函数,特别是DGEMM.对于同构CPU 架构,优化BLAS 函数特别是DGEMM性能是提高HPL 的浮点效率的关键.Dongarra 等人[1]总结了2002 年之前Linpack 发展历史和BLAS 函数的优化方法.
对于CPU+加速器架构,优化方向集中于CPU端BLAS 函数、加速器端BLAS 函数、CPU 与加速器之间负载分配和数据传输等.Kurzak 等人[3]优化多核CPU 多GPU 的HPL,其4 个GPU 的DGEMM 浮点性能达到1 200 GFLOPS.Bach 等人[4]面向AMD CPU 与Cypress GPU 架构优化了DGEMM 和HPL,HPL 效率达到70%.Wang 等人[5]采用自适应负载分配方法优化CPU 与GPU 混合系统HPL 性能,并调优HPL 参数,目标系统Tianhe1A 浮点性能达到0.563 PFLOPS.Heinecke 等人[6]基于Intel Xeon Phi Knights Corner 优化了DGEMM,使用动态调度和改进的look-ahead 优化HPL,100 节点集群HPL 效率达到76%.Gan 等人[7]优化基于加速器的DGEMM,并应用于Tianhe-2 HPL 评测.
随着以GPU 为代表的加速器技术的发展,加速器浮点性能越来越高,CPU 与加速器的浮点性能差距越来越大.2019 年6 月,Top500 排名第一的Summit 系统[8]的1 个节点装备2 个CPU,理论浮点性能1 TFLOPS,装备6个GPU,理论浮点性能42 TFLOPS.本文研究的目标系统使用CPU+GPU 异构架构,每个节点装备1 个32 核CPU,4 个GPU,CPU 浮点计算性能约是GPU 的1/61.同时加速器本身的结构也变得越来越复杂,通过增加特定的硬件满足特定领域的需求,如Nvidia GPU 的Tensor Core 等.已有研究使用Tensor Core 的强大的半精度运算能力混合双精度计算开发了HPL-AI[9],报告Summit 的HPL-AI 性能是全双精度HPL 的2.9 倍.并且已有应用采用混合精度算法加速计算,从HPL 和应用角度来看,混合精度都是值得研究的方向.面对这种新的计算架构,内存、总线、网络以及系统设计都要与之相适应,形成复杂的异构计算系统,这为HPL 评测带来很多机遇与挑战.
本文在基础HPL 代码之上,针对目标系统实现HPL 并研究其优化方法.第1 节简要介绍基础算法.第2 节介绍目标系统基本情况.第3 节描述复杂异构系统HPL 平衡点理论.第4 节介绍复杂异构系统HPL 高效并行算法.第5 节介绍基础模块的性能优化,包括panel 分解优化和行交换long算法的优化.第6 节介绍目标系统HPL实验和结果分析.第7 节总结并展望未来的工作.
1 基础算法
HPL算法使用64 位浮点精度矩阵行偏主元LU 分解加回代求解线性系统.矩阵是稠密实矩阵,矩阵单元由伪随机数生成器产生,符合正态分布.
线性系统定义为:

行偏主元LU 分解N×(N+1)系数矩阵[A,b]:
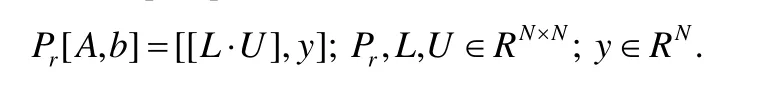
其中,Pr表示行主元交换矩阵,分解过程中下三角矩阵因子L已经作用于b,解x通过求解上三角矩阵系统得到:
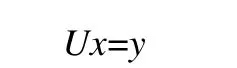
HPL 采用分块LU算法,每个分块是一个NB列的细长矩阵,称为panel.LU 分解主循环采用right-looking算法,单步循环计算panel 的LU 分解和更新剩余矩阵.基本算法如图1 所示,其中A1,1和A2,1表示panel 数据.需要特别说明的是,图示矩阵是行主顺序,HPL 代码中矩阵是列主存储的.
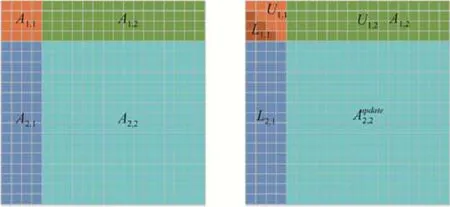
Fig.1 Block LU algorithm图1 分块LU算法
计算公式如下:

第1 个公式表示panel 的LU 分解,第2 个公式表示求解U,一般使用DTRSM 函数,第3 个公式表示矩阵更新,一般使用DGEMM 函数.
对于分布式内存计算系统,HPL 并行计算模式基于MPI,每个进程是基本计算单元.进程组织成二维网格.矩阵A被划分为NB×NB的逻辑块,以Block-Cycle 方式分配到二维进程网格,数据布局示例如图2 所示.
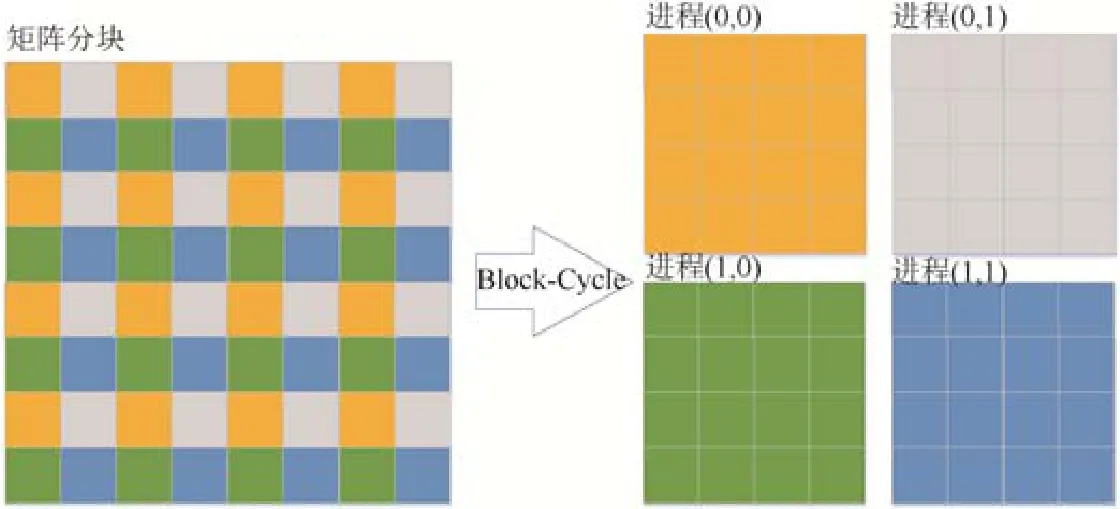
Fig.2 Block-Cycle algorithm图2 Block-Cycle算法
对于具有多列的进程网格,单步循环只有一列进程执行panel 分解计算,panel 分解过程中每一列执行一次panel 的行交换算法选择并通信最大主元行.Panel 分解计算完成后,把已分解数据广播到其他进程列.HPL 基础代码包含6 类广播算法,可以通过测试选择较优的算法.
HPL 采用行主元算法,单步矩阵更新之前,要把panel 分解时选出的最大主元行交换到U矩阵中,需要执行未更新矩阵的主元行交换和广播.主元行交换和广播后,每个进程获得完整的主元行数据.
矩阵更新包括两部分计算,一是使用DTRSM 求解U,二是使用DGEMM 更新矩阵数据.
LU 分解完成后,HPL 使用回代求解x,并验证解的正确性.
2 系统介绍
2.1 系统硬件
优化HPL 的目标系统是典型的复杂异构系统,计算部件由通用CPU 和计算加速器GPU 组成,网络接口和互联系统是高速Infiniband 网络.
2.2 基础软件
目标CPU 兼容x86 指令集.编译器使用gcc,MPI 使用OpenMPI.
HPL 基础代码使用2.3 版本.HPL 会调用多个BLAS 函数.CPU端BLAS 使用针对目标CPU 优化的OpenBLIS,支持OpenMP 实现多核并行.GPU端BLAS 使用针对目标GPU 优化的BLAS.
3 复杂异构系统HPL 平衡点理论
从硬件的角度来看,CPU 的每个Die 与对应的内存系统、GPU 和网络接口组成相对独立的系统.因此,在选择并行方案时,采用1 个进程使用1 个Die,并且与相应的内存、GPU 和网络接口绑定的架构.HPL 基础代码中只有1 列或1 行进程时执行流程不同,较大规模并行一般是多行多列进程,因此使用1 个节点4 进程作为研究对象,覆盖多行多列进程执行流程.
对于复杂异构系统HPL 计算,需要协同调度CPU、GPU、PCIe 和通信网络等资源.首先研究CPU 与GPU计算任务分配方式,进程内CPU 与GPU 以及进程间的数据传输,并且建立线程模型控制CPU、GPU 和网络接口协同计算.然后分析HPL 各部分的性能,提出复杂异构系统的平衡点理论指导性能优化.
3.1 计算任务分配
文献[4,6]等研究的异构系统中,CPU 执行panel 分解计算,加速器执行矩阵更新的DTRSM 和DGEMM 计算.CPU 计算能力可以达到加速器计算能力的10%或更高,除了panel 分解,CPU 还可以计算部分矩阵更新.并且由于加速器内存限制,矩阵不能完全存储在加速器,矩阵更新一般采用流水的方式.
经过分析和实验对比,由于panel 分解控制流程复杂,并且大量调用GPU 计算效率较低的DGEMV、DSCAL等函数,不适合在GPU端实现,因此,仍然采用CPU 计算panel 分解的方案.
对于矩阵更新来说,目标系统CPU 和GPU 之间的数据传输成为瓶颈,导致矩阵更新流水线方法不再适用.针对单个GPU 分析,假设矩阵规模N=58368(占用约80%的系统内存),NB=384,矩阵更新的DGEMM 效率为85%.可以计算出矩阵更新计算时间0.52s.PCIe 单向传输矩阵数据的理论时间1.70s.数据传输时间超过GPU 的计算时间,导致GPU 超过2/3 处于空闲状态,GPU 计算能力不能充分利用.
因此,采用矩阵数据常驻GPU 内存的方式,矩阵更新时避免传输整个剩余矩阵.这种模式下,矩阵的规模受限于GPU 设备内存的容量.为了运算方便,CPU端内存保留GPU端数据存储的镜像.
3.2 数据传输
数据传输包括进程内主机内存与GPU 设备内存之间数据传输和进程间数据传输.主机内存与GPU 设备内存数据传输使用PCIe 总线,一般采用DMA 异步模式,数据传输的同时CPU 和GPU 可以执行计算任务.进程间数据传输使用MPI.如果数据传输的进程位于同一个节点,MPI 使用共享内存等技术提高数据传输性能.节点之间的数据传输通过网络接口.
由于矩阵数据常驻GPU 内存,panel 分解前把当前的panel 数据从GPU 传输到CPU.Panel 分解在CPU端执行panel 的主元选取与广播,使用基础代码的算法.已完成panel 分解的数据,进程内部通过PCIe 传输到GPU.进程之间通过MPI 传输,非当前panel 分解进程接收到panel 数据后,再通过PCIe 传输到GPU.
相比于基础代码,矩阵更新行交换和广播增加了CPU 与GPU 数据传输过程.矩阵的行在GPU 内存不连续,数据传输前后需要执行封装和重排.数据传输关系如图3 所示.

Fig.3 Data transmisson图3 数据传输
3.3 多线程模型
在1 个节点4 个进程的架构下,每个进程使用8 个CPU 核心,使用多线程管理和调度这些核心.Panel 分解和panel 广播共享数据,执行顺序存在依赖关系,放在同一个线程.矩阵行交换和矩阵更新共享数据,执行顺序存在依赖关系,放在同一个线程.两组操作之间相对独立,分别绑定到特定核心.两个线程之间通过信号量同步.
Panel 分解线程调用和管理OpenBLIS 函数,OpenBLIS 使用OpenMP 线程模型.Panel 分解调用OpenBLIS函数时,与panel 分解的其他过程没有资源共享和冲突,OpenBLIS 的OpenMP 线程绑定的核心可以包括panel分解主线程的核心,也就是最多可绑定7 个核心.
3.4 复杂异构系统协同计算平衡点理论
目标系统是复杂异构系统,涉及CPU、GPU、PCIe 和网络接口等部件的协同计算.为了更好分析和评测各部分对HPL 性能的影响,指导性能优化,提出平衡点理论.
HPL算法中,矩阵更新的浮点计算占据绝大部分,这部分计算由GPU 完成.性能分析过程中,矩阵更新被认为是有效计算,其他功能模块包括panel 分解和矩阵行交换的目标是为矩阵更新提供数据准备.为了获得较高的效率,要尽可能保证GPU 处于工作状态,发挥GPU 浮点计算能力.对于panel 分解和矩阵行交换,尽可能让它们与GPU 计算并行,使用GPU 计算隐藏panel 分解和矩阵行交换.
研究没有使用特殊优化、单步循环各部分时间以及串行执行的总时间,如图4 所示.采用2×2 进程布局,图中是进程0 的时间曲线.进程0 在计算过程中处于不同的位置,包括当前列-当前行和非当前行-非当前列两种情况,图中”A”代表当前列-当前行,”B”代表非当前行-非当前列.两种情况下执行的计算有差异,每种运算有两条时间曲线.panel 分解时间在不同规模下稍有波动.可以看出,单步循环串行执行时间远大于GPU 执行有效计算的时间.那么首先必须做好矩阵更新与panel 分解和行交换的并行,GPU 计算时间隐藏panel 分解与和行交换时间.
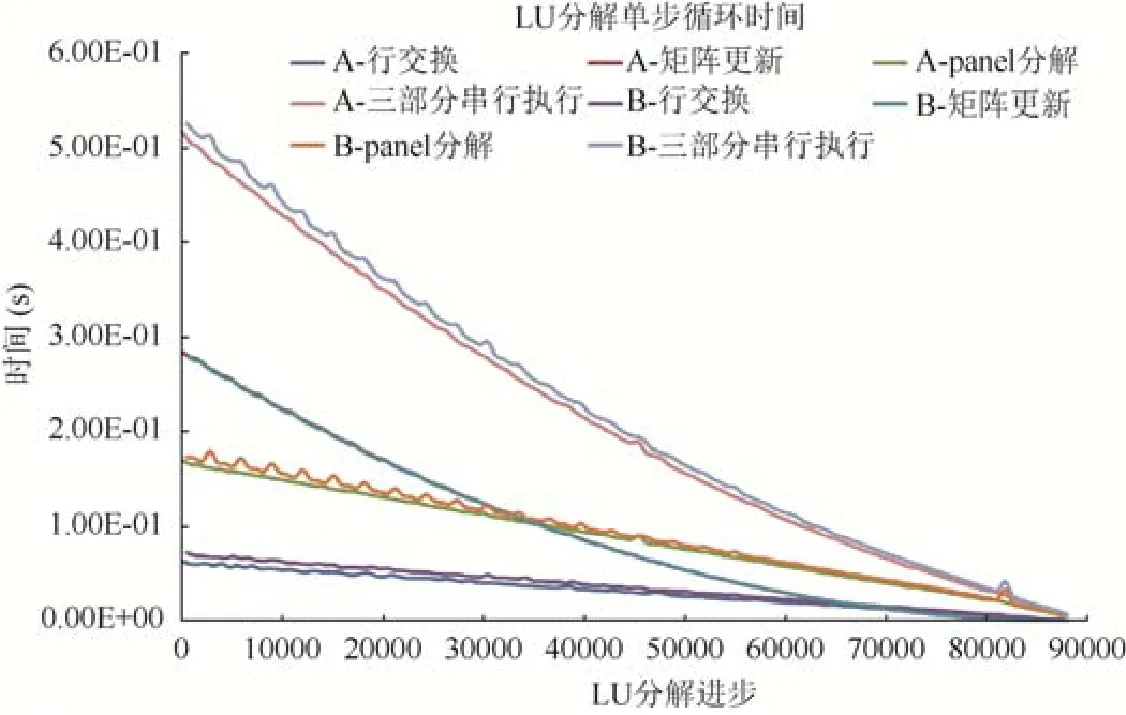
Fig.4 Time of panel factorization,row swap,matrix update and each loop图4 Panel 分解、行交换、矩阵更新和三部分串行执行累加时间
另一方面,HPL 的LU 分解过程分为两个阶段,矩阵更新时间大于panel 分解和行交换的时间的阶段和矩阵更新时间小于panel 分解直至小于行交换时间的阶段.在panel 分解与矩阵行交换并行的情况下,两个阶段的分界点即矩阵更新与panel 分解时间曲线的交点就是CPU 与GPU 协同计算的平衡点.
针对1 节点4 进程进行分析,N=88320 情况下,从计算规模来看,平衡点在37.82%,LU 计算量占76.00%,之后GPU 不能充分发挥性能.有必要继续优化panel 分解和行交换,减少执行时间,平衡点后移,延长GPU 高效率计算时间,进而提高整体的计算效率.平衡点理论可以很好地指导HPL 的优化工作.
4 复杂异构系统HPL 高效并行算法
根据第3.4 节的分析,首先做好GPU 计算与panel 分解和行交换的并行算法,实现GPU 计算重叠其他部分的时间.
4.1 GPU参与计算的look-ahead算法
基础代码用look-ahead算法实现panel 分解与panel 广播重叠执行.计算过程中保存两个panel 的数据结构.执行当前panel 分解的进程列,优先执行当前panel 列数据的行交换和矩阵更新,然后执行panel 分解计算并发起panel 广播,广播数据传输的同时更新剩余矩阵.对于当前不计算panel 分解的进程列,执行上一次循环的行交换和矩阵更新,行交换和矩阵更新计算过程中监测本次panel 广播数据通信,数据到达后,执行广播通信流程.
由于加入了GPU 计算资源,look-ahead算法相比于基础版本有所改变.按照第3.3 节的线程模型,在执行当前panel 分解计算的进程中,panel 分解线程CPU 优先执行panel 列的行交换,然后GPU 优先更新panel 分解的列.CPU 等待panel 数据更新后,发起panel 数据从GPU 内存到CPU 内存的传输,传输结束后执行panel 分解计算,最后发起panel 广播.矩阵更新线程在panel 分解列行交换完成后发起剩余矩阵的行交换,然后调用GPU 矩阵更新计算.对于非当前panel 分解计算进程,矩阵更新线程执行行交换和调用GPU 矩阵更新.Panel 分解线程只负责处理panel 广播的操作.
4.2 行交换连续流水线算法
矩阵行交换的前提是已接收panel 分解计算的行交换索引数据(包含在panel 广播数据中),并且上一次迭代矩阵更新已完成.HPL 基础代码中,行交换完成后启动矩阵更新计算,如果采用这种算法,GPU 在行交换执行的过程是空闲的.文献[6]提出行交换流水线算法优化行交换流程.在使用GPU 的环境,也可以采用这一算法.使用行交换流水线算法,对矩阵更新的行分段,首先执行第1 段的行交换,然后GPU 执行第1 段的矩阵更新,同时执行第2 段的行交换,依次类推.采用这种算法,GPU 计算与行交换数据传输重叠执行,减少了GPU 的空闲时间.但是,单步循环执行第1 段行交换的这段时间内GPU 是空闲的.
为了避免GPU 等待,提出了连续流水线算法.算法中,第1 个分段完成上一次循环矩阵更新和当前进程接收到下一次循环的行交换信息之后,不需要等待上一次循环矩阵更新全部完成,就执行第1 分段的下一次循环的行交换.采用这种算法,下一次循环第1 分段的行交换被上一次循环矩阵更新隐藏,下一次循环第1 分段的矩阵更新隐藏第2 分段的行交换,后续分段继续流水.
使用连续流水算法避免单步循环的流水线启动过程,如果接收到行交换信息早于矩阵更新,则GPU 可以一直处于工作状态.从第3.4 节可以看出,行交换信息在平衡点之前是早于矩阵更新的,而这一阶段正是浮点运算量较大的情况,在这一阶段充分发挥GPU 计算能力,可以提高整体的计算效率.
行交换分段方法选择倍数递增,也就是第2 段列数是第1 段列数的倍数,依次类推,增长因子可调.连续行交换流水算法下实现look-ahead算法,对于当前panel 分解,增加panel 分解数据提前行交换和矩阵更新的分段.
5 基础模块性能优化
从平衡点理论来看,平衡点之前的部分GPU 计算时间可以隐藏panel 分解和行交换时间.随着计算的推进,panel 分解和行交换成为系统性能的瓶颈.为了进一步提高效率,需要针对panel 分解和行交换进行优化.
5.1 Panel分解优化
5.1.1 基本参数调优
Panel 分解浮点计算集中在BLAS 函数,使用针对目标系统优化的Hygon OpenBLIS库.Panel 分解使用递归算法,中间递归层次的浮点运算集中在BLAS 的DTRSM 和DGEMM 两个函数.当递归层次包含的列数小于等于阈值时,使用非递归算法,浮点运算集中在BLAS 的DGEMV、DTRSV、DSCAL、IDAMAX 等函数.对于每一列的LU 分解,需要通过交换和广播通信主元所在的panel 行,并记录主元行交换信息.交换和广播通信使用binary-exchange算法.
Panel 分解计算有关参数有NB、NBMIN、PFACT、RFACT、DIV等.NB取决于GPU 执行矩阵更新的效率,同时考虑CPU 与GPU 计算的平衡.当节点规模较小时,NB=384;当节点规模较大时,NB=256.通过参数调优,选择优化的参数组合,见表1.

Table 1 Parameters of panel factorization表1 Panel 分解参数
进一步分析panel 分解各部分时间,0 号进程主要计算函数时间见表2.

Table 2 Time of BLAS functions in panel factorization表2 Panel 分解BLAS 函数时间
5.1.2 GPU 加速panel 分解DGEMM
从第5.1.1 节可以看出,panel 分解中,DGEMM 时间占有最大比例,需要进一步优化.DGEMM 在panel 分解递归层次调用.根据panel 分解的left-looking算法,从左到右执行LU 分解,左侧的subpanel 完成分解之后,执行DGEMM,更新相同层次的右侧的subpanel,GPU 可以加速这部分DGEMM.
GPU 加速DGEMM 的算法过程,首先把左侧subpanel 和相应的U数据传输到GPU 设备内存,然后执行DGEMM 更新GPU 内存的右侧subpanel,更新后数据传输到CPU端内存,继续执行后续的panel 分解.算法增加了CPU 和GPU 之间的数据传输,但由于GPU 执行DGEMM 的速度远高于CPU,在一定规模DGEMM 的情况下,这一过程总的执行时间少于CPU端执行DGEMM 时间,整体性能提高.
并不是所有的panel 分解DGEMM 都可以使用GPU 加速,如果传输的时间开销大于DGEMM 加速的效果,就不能采用这种方式.实际计算中,使用参数控制采用GPU 加速DGEMM 的阈值,通过调优获得最佳的性能.
5.1.3 Panel 广播优化
5.1.3.1 避免数据封装
基础代码中,panel 分解数据使用CPU端矩阵A的内存,A是列存储,panel 分解的列是分段连续的.使用MPI传输panel 数据之前,需要执行数据封装,把数据复制到发送缓冲区,而复制操作会带来一定的时间开销.
为此提出一种避免数据封装的方法.待分解的panel 数据是从GPU 内存复制的,通过使用二维复制接口把panel 数据复制到连续存储区域.Panel 分解计算完成后,MPI 接口直接使用缓冲区数据,避免了数据封装.
5.1.3.2 Panel 广播流水
基础代码中,panel 分解完成后才会执行panel 广播,计算与数据传输串行,并且一次性数据传输较大,传输时间较长.通过观察可以看出,left-looking算法中,左侧subpanel计算完成后,主体部分不再变化,后续只有发生行交换的数据变化.
因此,提出一种广播流水算法,对已分解的subpanel 数据提前发起广播,这种情况下,panel 数据广播与后续panel 分解计算并行.采用广播流水算法,panel 计算完成后,只需要传输最后的subpanel 和行交换发生变化的数据,相比于传输整个panel 数据,缩短了传输时间.
广播流水算法与GPU 加速panel 分解DGEMM 协同使用,subpanel 的数据广播与panel 加速DGEMM 过程中的CPU 与GPU 之间数据传输、GPU 执行DGEMM 计算并行,充分利用系统的CPU、GPU、PCIe 和网络接口资源.
HPL 包含的6 种广播算法都可以使用广播流水优化.
第5.1.2 节描述的GPU 加速panel 分解DGEMM 和panel 广播流程紧密耦合,表3 给出了优化前后伪代码对比.

Table 3 Pseudocode of accelerated panel DGEMM and broadcast pipeline表3 Panel DGEMM 加速和广播流水伪代码
5.2 行交换long算法优化
矩阵更新行交换有两种算法可选,bianary-exchange算法和long算法,经过分析和评测选择long算法[10].第4.2 节从行交换与GPU 并行计算的角度针对行交换流程做了优化,本节优化具体的行交换算法.
Long算法包括两个步骤,spread 和roll.基础代码中,首先是spread 过程,当前行进程将需要换出的行分发给其他所有进程.然后,非当前行进程把接收的数据与本地需要换出的数据交换.接着是roll 过程,总共需要进行P–1 次传输.每次传输所有的进程都要参与,每个进程只与自己的邻居交换.第1 步,先把自己所拥有的一部分与左(右)邻居交换,然后,把自己刚刚得到的数据与右(左)邻居交换.这样左右交替,直到所有的数据都交换完毕,每个进程都拥有了全部的U.最后所有进程还需要把所有的数据进行重排,放置到矩阵A相应的位置.
基础代码中,spread 和roll 使用同一块数据缓冲区,为了避免数据冲突,spread 和roll 是严格串行的.通过观察发现,spread 的接收数据与roll 的发送数据并没有依赖关系,spread 和roll算法上是可并行性.基于以上观察与分析,将spread 的接收缓冲与roll 的发送缓冲分离.这样,非当前进程行在等待接收spread 数据时,就可以执行roll数据封装,并把数据传输到发送缓冲区,这部分时间就可以被隐藏.
在使用上述的缓冲区分离算法之后,spread 和roll 已经没有依赖关系,因此提出了一种新的行交换方法,即交换spread 和roll 的执行顺序,如图5(b)所示.对当前行进程来说,在roll 操作之前,只需将本地需要交换的数据拷贝到发送缓冲区即可,也就是减少了行交换的启动时间.在roll 执行网络传输的同时,当前行进程可以将spread 所需的数据封装,并异步传输到发送缓冲区.roll 执行完成后,开启执行spread.同时,把roll 过程接收的数据异步传输到GPU,并执行数据交换.在spread 过程结束后,非当前行进程再将换入的数据传输到GPU,并交换到相应位置,当前行进程对需要进行内部交换的数据执行GPU 上的本地交换.这种算法可以实现网络通信传输、GPU 数据封装和数据交换计算以及CPU 与GPU 数据传输相互重叠,减少行交换执行时间.

Fig.5 Original row swap algorithm (a),and modified row swap procedure (b)图5 原始行交换算法(a)及新的行交换算法(b)
6 实验与分析
6.1 单节点性能分析
首先针对单节点实验,分析评估各种优化方法的效果.根据平衡点理论,优化的目标是GPU 尽可能地处于高效工作状态,执行有效的计算,也即GPU 尽可能地连续执行矩阵更新.图6 对比了优化后单步循环的时间和GPU 矩阵更新时间.图6 给出了1 个节点内0 号进程的时间曲线.”A”表示当前行-当前列,”B”表示非当前行-非当前列.可以看出,N=88320 情况下,LU 分解矩阵规模56.09%之前单步循环时间接近GPU 矩阵更新时间.56.09%之后,当前进程执行panel 分解,单步循环时间仍然接近GPU 矩阵更新时间,GPU 大部分时间处于工作状态,说明算法优化已经达到较好的效果.对于非当前panel 分解进程,增加了等待panel 广播数据的时间开销,GPU 有一段时间处于空闲状态.

Fig.6 GPU time vs.total time of each loop图6 GPU 时间与单步循环总时间
可以看出,图6 优化版本的平衡点是56.09%,图4 未优化版本版本是37.82%.从LU 分解的计算量来看,前56.09%占总的LU 分解计算量的91.53%,大部分时间充分发挥了GPU 的计算能力.优化后单节点HPL 效率达到了79.51%.
和优化有关的参数主要是GPU 加速DGEMM 和panel 广播流水的层次,这里都是3.行交换非当前列第1段列数是待更新列数的1/8,增长因子是2.Panel 分解参数和表1 一致.
6.2 可扩展分析
多节点HPL 较大规模可扩展,目前最大规模4 096 个节点.HPL 较大规模并行有关的参数和效率见表4,表中列出了针对相应节点数执行的实验中效率最高的配置.

Table 4 Parameters and efficiency of multi-nodes HPL表4 多节点HPL 参数和效率
参数N是较大规模节点HPL 评测中比较重要的参数,每个节点计算的矩阵列数一般是NB的倍数,多节点的N正比于节点数平方根.N值越大,计算效率较高的矩阵更新占比越大,一般来说HPL 效率越高,但N受限于GPU 的内存容量,同时还要考虑系统的负载.NB使用384 或256.P和Q确定二维进程网格的组织方式,经过验证,P=Q时目标系统性能最优.Panel 广播和矩阵行交换分别使用优化的long算法和广播流水算法.
从HPL 效率来看,4 节点效率高于单节点效率,原因在于4 节点矩阵规模大于单节点,效率较高的计算占比较大,并且可以抵消4 节点规模下网络传输路径增加带来的性能损失.随着规模的扩大,网络传输对性能的影响增大,HPL 效率逐步降低,但降低的趋势比较平缓.
7 结论与未来的工作
针对复杂异构系统,分析HPL算法的特点,提出CPU 与GPU 协同计算方法,提出平衡点理论指导各方面优化.实现CPU 与GPU 协同计算的look-ahead、行交换连续流水线算法隐藏panel 分解和行交换时间,并优化panel 分解和行交换算法,延长GPU 计算占优的时间,最终提高整个系统的HPL 效率,单节点效率79.51%.
当前的超级计算机正向百亿亿级迈进,目标系统采用的节点内通用CPU 装备加速器,配合高速的节点内总线被认为是较有潜力的一种架构.未来工作主要是针对百亿亿级计算架构,开展加速器DGEMM 优化、CPU 与加速器协同计算和混合精度等相关研究.同时,百亿亿级超级计算机节点规模继续增加,节点数量有可能达到数万甚至更多,节点间的互连也更加重要.需要进一步研究HPL 大规模可扩展能力,评测行交换算法和广播算法的性能,并进行相应的优化.
猜你喜欢
中国外汇(2019年20期)2019-11-25
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
中国外汇(2019年8期)2019-07-13
电子制作(2018年10期)2018-08-04
西部广播电视(2015年9期)2016-01-18
西部广播电视(2015年9期)2016-01-18
电脑爱好者(2015年21期)2015-09-10
民主与科学(2014年3期)2014-02-28
中国火炬(2013年10期)2013-07-24
