
国产异构系统上的HPCG 并行算法及高效实现∗
2021-11-09 02:45刘芳芳王志军吴丽鑫马文静孙家昶
软件学报 2021年8期
刘芳芳 ,王志军 ,汪 荃 ,吴丽鑫 ,马文静 ,杨 超 ,孙家昶
1(中国科学院 软件研究所 并行软件与计算科学实验室,北京 100190)
2(中国科学院大学,北京 100049)
3(计算机科学国家重点实验室(中国科学院 软件研究所),北京 100190)
4(北京大学 数学科学学院,北京 100871)
HPCG(high performance conjugate gradients)基准测试程序是一种新的超级计算机排名度量标准[1].该测试基准主要用于衡量超级计算机解决大规模稀疏线性系统的能力,相比于HPL(high performance Linpack)[2],其计算、访存与通信模式与当前主流高性能计算机应用程序更为契合,能够更全面地反映系统的访存带宽和延迟的性能.HPL 和HPCG 排名每年发布两次,一次在德国的ISC[3]大会上,另一次在美国的SC[4]大会上.位于世界前列的超级计算机均提交HPL 和HPCG 两个基准测试程序的结果,2019 年德国举办的ISC 大会同时发布了HPL和HPCG 结果.越来越多的应用研究人员开始关注HPCG 的测试结果,期望从中可以了解超级计算机访存、通信等的特点,一些HPCG 并行和优化方法也可能对某些应用有所启示.
目前超级计算机的体系结构日趋复杂,早已从同构转向异构,且同节点异构部件的运算性能差异越来越大,这对异构并行算法的设计将有很大的影响.本文主要面向一类国产复杂异构系统研究HPCG 并行算法和高效实现方法.目前Dongarra 教授课题组研究了HPL-AI 混合精度算法[5,6],我们也正在关注该方向的研究.
本文工作是在国产超级计算机研制方大力支持下完成的,在此表示感谢.
1 HPCG 简介
HPCG 来源于半结构网格上的三维热传导应用,其核心是在三维规则区域上对Poisson 方程进行有限差分离散化后,转换成一个稀疏线性方程组的求解问题.其方程如式(1)所示.采用如图1 所示的27 点stencil 格式进行离散化.

其中,每个网格点的更新都依赖其周围紧邻的点.由于参与计算的点只能在三维网格区域范围内,所以每个网格点最多依赖26 个邻点,具体的邻点的个数,分别为26(内部点,邻点都在域内)、17(边界面上的点,某一邻面上的9 个点都在域外)、11(边界线上的点,比边界面上的点又少了2/3 个面的点,即又少了6 个点)和7(边界顶点,仅有一个小立方体上的8个点在域内,即图1的1/8,包括其自身).最终得到的稀疏矩阵A是由27 条对角线组成,并且是一个对称正定矩阵.
在大规模并行环境中,HPCG 使用三维区域分解策略,也就是按照3 个维度将整个计算区域划分成若干个子区域,每个子区域被分配一个MPI 进程,其规模由输入参数指定.每个MPI 进程处理的计算区域中的内部点所依赖的26 个邻点,全部来自于该计算区域,而对于计算区域边界上的点,其依赖的邻点一部分来自于该计算区域内部,一部分则来自于邻居进程所处理的子区域.不妨称计算区域为内区,其对应的点为内点,计算区域所依赖的邻居进程的点构成的区域为外区,其对应的点为外点.由于我们使用的是27 点stencil,所以每个进程最多有26 个邻居进程.
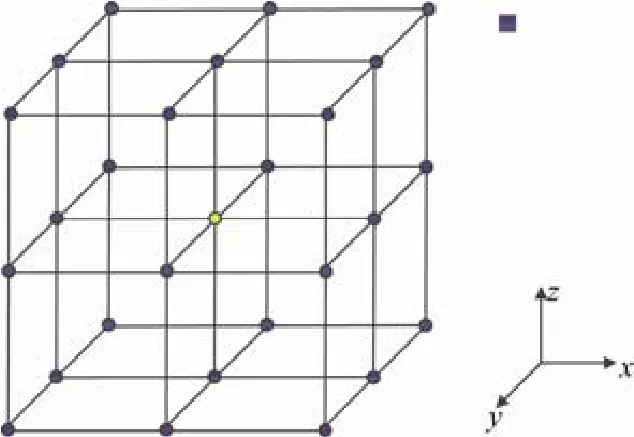
Fig.1 3D 27-point stencil in HPCG图1 HPCG 三维27 点stencil 格式
在HPCG 中,该线性系统使用预处理共轭梯度(preconditioned conjugate gradient,简称PCG)法来求解,计算流程如图2 所示.
CG算法中一次迭代计算包含3 个向量点积操作(第4、7、10 行)和3 个向量更新操作(WAXPBY,第6、8、9 行)以及1 个稀疏矩阵向量乘操作(SpMV,第7 行).
HPCG 中使用的预条件子M–1是基于V-cycle 几何多重网格,其计算流程如图3 所示.多重网格通过将细网格上频率变化较缓慢的低频分量映射到粗网格上来处理,以达到加快收敛速度的目的.作为预条件子,多重网格的计算同样包含4 个主要操作:前磨光操作(第4 行)和后磨光操作(第8 行)、限制算子(第5 行)、插值算子(第7行)、底部解法器(第2 行).在HPCG 中,多重网格的层数被固定为4 层,前后磨光操作以及底部解法器都是使用对称Gauss-Seidel 迭代法的一次迭代来实现,并且磨光操作只执行一次,不可修改.使用SymGS(x,r)表示一次对称Gauss-Seidel 迭代,其中r是右端项,x是解向量的初始猜测值.

Fig.2 Conjugate gradient algorithm图2 共轭梯度法

Fig.3 Multigrid pre-conditioner图3 多重网格预条件子
在HPCG 中主要存在两种通信类型:全局通信和邻居通信.
1.全局通信.主要为MPI_Allreduce 通信,发生在向量点积操作中.在一次CG 迭代中总共需要计算3 次向量的点积,因此需要调用3 次MPI_Allreduce.
2.邻居通信.主要发生在与稀疏矩阵相关的两个核心函数中:SpMV 和SymGS,使用MPI 点到点的通信实现halo 区数据交换.HPCG 采用27 点stencil 格式,每个网格点的计算依赖周围紧邻的26 个邻居.在SpMV 和SymGS 计算开始前,需要与周围的邻居进程交换边界数据(halo),以便将计算过程中所需要访问到的邻居数据传输到本地进程中.
3.目前超级计算机的体系结构日趋复杂,早已从同构转向异构,且同节点异构部件的运算性能比差异越来越大,这对异构并行算法的设计将有很大的影响.本文主要面向一类国产复杂异构超级计算机研究HPCG 异构众核并行算法.首先介绍了国内外进展,然后提出两种适用于该平台的HPCG 异构众核并行算法.对于实际使用的第2 种算法中,还存在图着色的问题,本文也开展了相关工作,并单独使用一节进行介绍.接下来介绍在该超级计算机上的实现问题,包括CPU 和GPU 之间的任务划分、为了隐藏邻居通信实现的内外区划分方法,以及一些稀疏矩阵重排等优化方法,最后介绍了实验结果.
2 国内外进展介绍
HPCG 的优化工作主要是针对热点函数SpMV 和SymGS 来开展.SpMV 的性能与存储格式以及计算方式有关.Bell 等人[7]在GPU 平台上实现了常用的CSR、COO、ELL 等基本格式,提出了一种新的HYB 格式来提高SpMV 的性能,并分析了不同矩阵适合使用的格式以及并行方法.另外,还有一些其他格式包括ELLPACKR[8]、BRC[9]、BCCOO[10]等被提出.还有一些学者研究稀疏矩阵的重排技术[11]及压缩格式[12],以减少访存开销.在计算方式方面,Williams 等人[13]在多种不同架构的多核平台上使用了线程分块、缓存分块、向量化等优化手段,并取得了很好的结果.另外还有学者研究自动调优技术[14],通过分析稀疏矩阵的特征来选择参数以提升性能.
SymGS 的求解过程类似于稀疏三角解法器,其关键是如何在这种强依赖的限制下获得并行度.研究人员已经提出了很多不同的并行方法,如Park 等人[15]提出了level scheduling 方法,这种方法使用层次遍历稀疏矩阵对应的有向无环图,保证每一层的节点间没有依赖关系,从而可以并行更新.但是这种方法获得的并行度不高,且各层之间的负载不均衡.Iwashita 等人[16]提出了适合结构化稀疏三角求解器问题的分块图着色技术,这种方法以块为单位对图进行着色,保证一个块与其相邻块颜色不同,相同颜色的块一起执行.这种方法虽然会破坏部分依赖,但是可以获得较大的并行度.
HPCG 的整体优化工作也受到了很多研究者们的关注.Kumahata 等人[17]在基于CPU 的日本超级计算机K上的HPCG 优化工作使用了分块图着色排序来挖掘SymGS 中的并行度,并通过改变反向更新时的计算顺序来提高cache 命中率,在82 944 个CPU 上取得了0.461 PFLOPS 的成绩,达到整机峰值性能的4.34%.Phillips 等人[18]在NVIDIA GPU 平台上使用图着色方法对SymGS 进行并行.刘益群等人[19,20]基于天河2 号超级计算机的特征提出了混合的CPU-MIC 协作的异构计算方法,通过区域划分充分利用CPU 与MIC 的计算资源,在整机16 000 个节点上取得了0.623 PFLOPS 的性能,位列2014 年11 月排行榜第一名.敖玉龙等人[21]设计了基于申威架构的并行算法,该算法使用分块着色的方式挖掘SymGS 中的并行度,并使用神威特色的片上寄存器通信机制优化了核间的数据交换,在163 840 个节点上取得了0.481 PFLOPS 的性能.Ruiz 等人[22]基于ARM 平台研究了多色重排和分块多色重排两个算法的性能,并从cache miss 等角度进行了分析.目前世界排名第一的是IBM 研制的超级计算机Summit,其HPCG 性能达到了2.92 PFLOPS,是整机峰值性能的1.5%,但目前还没有相关文献详细介绍其并行算法和优化技术.面向一类国产复杂异构系统研制众核并行版HPCG 软件,且峰值性能和整机效率达到或超过Summit 的水平,是一项具有巨大挑战的工作.
3 异构众核并行算法设计
GPU 是最近十几年被广泛使用的高性能计算机加速部件.一个GPU 由多个计算单元(computing unit,简称CU)组成,每个CU 里有多个SIMD,可以同时进行多路向量运算.CU 内部具有高速的软件可控缓存LDS(local data share).所有CU 共享L2 cache 和设备内存.程序运行时组织成多个workgroup,每个workgroup 可包含一个或若干个wavefront.每个workgroup 只能在一个CU 上运行,在我们使用的平台上,每个wavefront 包含64 个线程,一个workgroup 内所包含的线程数不能超过1 024 个.在这种高并行度的复杂架构上并行和优化HPCG,是一个非常大的挑战.在并行算法层面,不仅要求高并行度,还要求整体迭代次数不能有较大增长.在优化方面,不仅要从算法层面尽量减少访存和通信,并将通信与计算重叠,还需要充分利用硬件的特性减少访存开销.
3.1 分块着色+level scheduling算法
3.1.1 基本算法
如第2 节所述,HPCG 中SymGS 模块的经典优化方法包括点着色方法、按层计算方法(level scheduling)以及分块着色算法等.考虑计算平台的特点及收敛速度的需求,我们选择了分块着色算法作为程序的基本框架.我们将SymGS 和SpMV 等基本算子在分块着色算法的基础上进行并行化,并提出了针对GPU 异构平台的优化方法.
分块着色算法的基础是将三维网格分块,然后对每一个数据块进行着色.在预条件子中使用的四重网格里,每一层网格都需要分块及着色.参考文献[21]的工作,我们选取了类似的分块着色算法,既方便数据在GPU 上的分配,又保证了较高的并行度,且不会大幅度增加迭代次数.如图4 所示,三维空间中相邻的8 个数据块使用8 种不同的颜色,每次SymGS 计算时,同样颜色的数据块被同时处理.
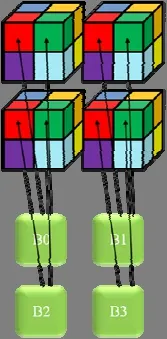
Fig.4 Block coloring algorithm图4 分块着色算法
3.1.2 数据及任务映射
块内SymGS 需要严格保持依赖关系,否则迭代次数将大幅度上升.因此,本文采用level scheduling算法进行并行,方程4x+2y+z=k所定义的平面上的点都可以算作一层(每个点的坐标为(x,y,z)),因为它们所依赖的数据都已经计算完毕.如图5 所示,从上到下是时间轴,第1 个点的计算不需要本次迭代的任何数据,可以在此数据块处理过程的第1 次迭代进行更新;然后,下一个点仅依赖于第1 个点,而第1 个点已经有最新数据,因此第2 个点可以进行计算,此为第2 层;再然后,我们可以分析出第3 层,第4 层,...,直到整块数据被处理完.依照这种排序,每层数据的更新可以并行操作.通过实验不同的块大小,我们选出能够适应高速缓存LDS 大小且保证一定的块间及块内并行度的分块方案.
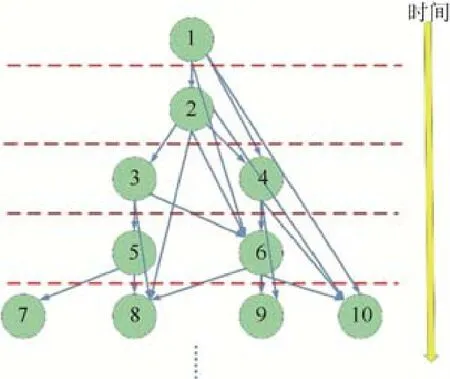
Fig.5 Data dependence and levels inside a block图5 块内数据依赖及分层
3.1.4 SymGS 内核优化
在分块着色+块内level scheduling算法的基础上,我们对SpMV 和SymGS 的内核函数进行了优化.SpMV函数的优化参考文献[23]的方法,每线程计算一个双精度乘法,将中间结果保存在LDS 中,然后将LDS 中的乘积进行相加.这种方法保证对矩阵A的读取都是连续访存(coalesced access),因而能够充分利用内存带宽.
对SymGS函数,我们对每一level 采用类似的方式在一个workgroup 内运行.这就需要对整个矩阵进行重排,使之在计算开始之前,就按分块之后所需要的顺序排列好.在SymGS 函数被调用时,矩阵A也能实现连续访存.由于level 内并行度较小,我们将workgroup 大小定为一个wavefront 的大小,即64 线程.
在进行归约操作时,我们通过实验不同的归约方法,选出了一种尽量充分利用处理器单元的方式.
3.2 分块图着色算法
由于HPCG 采用27 点stencil 格式进行离散,第3.1 节分块方式使得每个子块内部网格点依赖关系比较强,只有严格保持其依赖关系整个问题才能收敛.而上一节提到,块内采用level scheduling 的并行方式不能有效利用硬件资源,所以本节提出一种新的分块图着色算法,如图6 所示.将网格y方向一条作为一个块进行处理,这样块内依赖较少,可以对其进行并行计算,同时块内向量x可以进行重用,以提升访存带宽利用率.将所有子块进行着色,每一个颜色的子块并行执行.着色方案需要精细设计,以确保整个算法可以以较少的迭代次数收敛,从而提升整体性能.

Fig.6 Blocked graph coloring algorithm图6 分块图着色算法
该方案可以实现两级并行:同色子块并行执行和子块内部网格点并行执行.这样可以更好的利用GPU 的硬件资源,充分发挥硬件的性能.同时块内可以利用LDS 对向量x进行重用,从而减少向量x从设备内存访存的次数,提升访存带宽利用率.
4 图着色算法研究
第3.2 节的方案中需要对所有子块进行着色,且着色算法对整个HPCG 的迭代次数有很大的影响.本文首先尝试了国际上著名的并行图着色算法JPL[24]、CC[25]等,基于国产处理器进行了并行实现并将其运用于HPCG中.对JPL算法,本文尝试了贪心着色策略和随机着色策略.对CC算法,本文也进行了多种尝试,如每轮迭代的遍历次数选为1,2,3,13,27 这5 种.对于256×256×256 的测试规模,迭代次数介于58~67 之间,且最低迭代次数时颜色数为70.这些算法的测试结果无论颜色数还是迭代次数都偏高.
经过分析可知,传统的JPL 和CC算法只考虑一层依赖,即着色时每个网格点只考虑其周围最临近网格点的依赖关系,而实际上依赖关系是会传递的,如图7 中,1 号点和2 号点有依赖,2 号点和3 号点有依赖,则1 号点和3 号点也有依赖.考虑这种依赖传递将有可能在并行算法中保持更多的依赖关系,从而降低迭代次数.为了降低迭代次数的同时减少颜色数(增加并行度),本文还考虑了x,y,z这3 个方向的差异,设计了一些实验,验证了这3 个方向有一个为强依赖方向,其他两个为弱依赖方向.对强依赖方向使用较多的颜色,对弱依赖方向使用较少的颜色,期望整体颜色数尽量减少.最终本文使用了33 色对整个网格进行着色.经测试,对于256×256×256 规模,单进程运行时迭代次数为55 次,相比于JPL 和CC算法的最少迭代次数降低了3 次,即整体性能可提升6%.
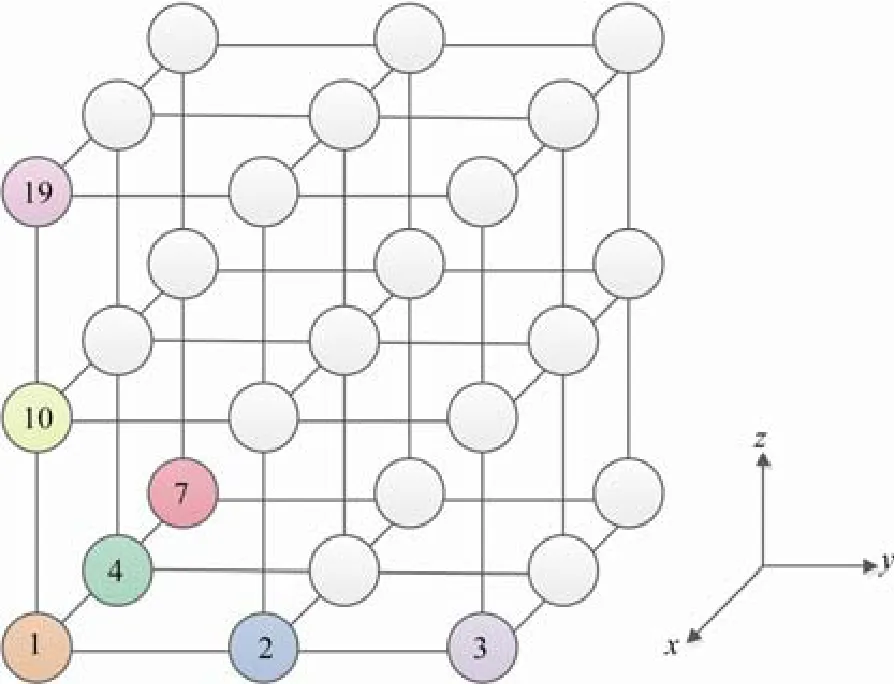
Fig.7 Propagation of dependence图7 依赖传递
5 异构部件任务划分
国产超级计算机每个节点包括CPU、GPU 等部件,CPU、GPU 均拥有独立的内存.HPCG 的数据生成部分耗时较多,本文使用GPU 进行矩阵、向量和其他信息生成,并拷贝回CPU 进行参考版的计算.所有优化版需要的矩阵、向量等常驻GPU 设备内存.整个任务划分时需考虑CPU 和GPU 的任务分工.由于GPU拥有比CPU 更高的访存带宽,更多的计算资源,所以应该尽量把任务放到GPU 上计算.这样就有两种可能的方案:
1.将所有计算任务全部放到GPU 上,CPU 不参与计算,只负责通信.
2.将大部分计算任务放到GPU 上,CPU 并行执行小部分计算任务同时负责通信.
第2 种方案实际执行时需要CPU 和GPU 不断地传输新的计算数据,而这种传输开销较大,传输256×256×256 规模的向量x约需0.035s,而计算一次SpMV 的时间仅为0.008 78s,传输开销远大于计算开销,得不偿失.本文采用第1 种方案,并且通过内外区划分将CPU 通信与GPU 内区的计算进行重叠,如图8 所示,具体介绍见第7 节.

Fig.8 Partitioning of inner areas and outer areas图8 内外区划分
6 HPCG 优化方法
6.1 稀疏矩阵存储格式
HPCG 参考版本里矩阵存储采用的是CSR 格式,如图9 所示,矩阵的非零元素和其对应的列索引分别存放在各自的数组里,并用一个指针数组记录每一行的起始位置.这样数据的内存分配比较离散,局部性不高.为了解决这个问题,我们采用了如图10 所示的ELL 格式,按照矩阵中非零元最多的行对其他行进行填充,使每行的长度一样,这样数据在内存中占据了一块连续的空间,在知道这个长度和矩阵起始地址的情况下可以算出每一行的起始位置,节省了CSR 格式中每行起始位置的索引数组.

Fig.9 Storage format used by the reference version of HPCG图9 HPCG 参考版使用的存储格式

Fig.10 Optimized ELL format图10 优化ELL 格式
对规模为256×256×256 的矩阵而言,总非零元个数为450 629 374,CSR 格式总存储量为5.20 GB,ELL 格式总存储量为5.06 GB,减少了3%.
6.2 稀疏矩阵重排
由于使用了分块图着色算法,相同颜色块一起计算,而在原存储空间中,相同颜色的块都是不相邻的,这样无法充分利用L2 Cache,因此,我们根据分块着色的结果对矩阵进行了重排,如图11 所示,我们将相同颜色的块放在一起,进一步提高数据局部性.相应的,我们对解向量x和右端项y也做了同样的重排.
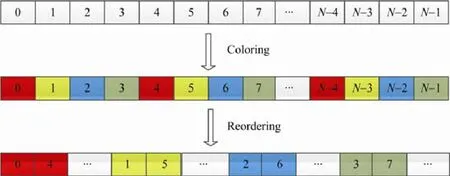
Fig.11 Blocked graph coloring and reordering图11 分块图着色以及重排
6.3 其他优化
分块后,块内的数据存在可能的复用,本文可以通过GPU 卡上的程序员可控高速缓存LDS 来完成这部分的复用,从而进一步提高访存的效率.
除此之外,本文还运用了多种优化手段,如分支消除、循环展开、数据预取、数据管理优化等.在分支消除方面,考虑到GPU 的分支执行特性,本文通过逻辑计算来消除了一些分支指令.在循环展开方面,综合考虑寄存器的数量与性能,本文展开了一些热点函数中的循环.在数据预取方面,本文在计算时先统一预取不规则的内存区域中的数据.数据管理方面,本文采用了内存池的方式对内存进行管理,避免了很多不必要的内存申请与释放,并且在主存分配空间时都声明为pinned memory 以加速数据拷贝.
7 多进程实现与优化
在多进程的实现中,本文采用了内外区划分的方式,将整个计算网格分成内区和外区两个部分,外区宽度为1,如图8 所示.将内区按照第4 节中算法进行着色,将外区看成最后一个颜色.当内区部分所有的计算和外区所需的halo 区数据通信都完成后开始进行外区的计算.具体流程如图12 所示.这样整个HPCG 中核心函数SpMV、SymGS 中的邻居通信均可被内区计算掩盖,从而减少了整体运行时间.
由于矩阵、向量等常驻GPU 设备内存,邻居通信前需要将halo 区的数据先拷贝回CPU 内存,待通信结束后再拷贝到GPU 内存.第1 次拷贝是无法重叠的,因为只有等完全拷贝结束后才能进行邻居通信.
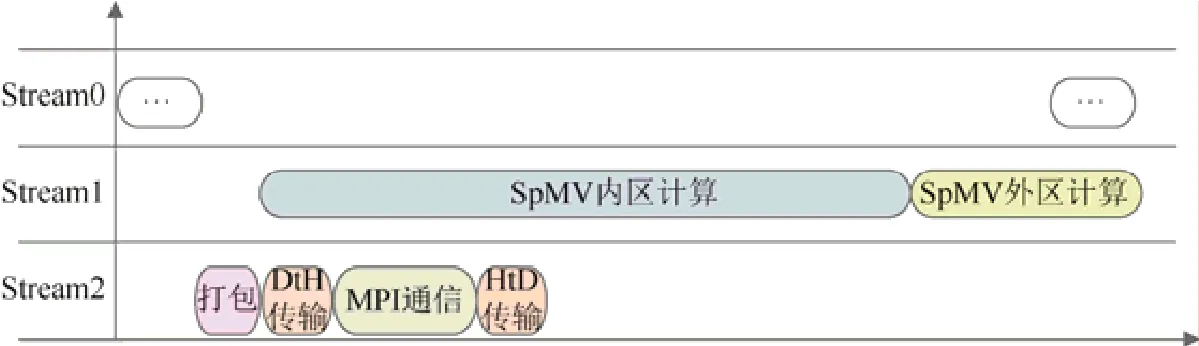
Fig.12 Overlap of computation and communication图12 计算通信重叠
8 HPCG 测试结果
本文对第3.1 节和第3.2 节的算法均进行了实现,并基于某国产复杂异构超级计算机单节点单进程进行了测试,测试结果如图13 所示.图13 中给出了HPCG参考版、两个并行方案的性能结果,对第2 个方案,还给出了多个优化技术所带来的性能提升.从图中可以看出,第3.2 节算法性能较高(见图中para2),约是第3.1 节算法(见图中para1)的2 倍多,因为第3.2 节算法能更好的发挥GPU 的计算能力,并行度更高.图中opt1 是将setup 部分和OptimizeProblem部分进行优化的结果,同时该版本还减少了不必要的同步操作,opt2 是对多重网格中每一层的着色方案进行自适应调整,以增加粗层的并行度,另外该版本中还包括对零元访存的优化.opt2 版本的性能是本文工作单节点可达到的最高性能,在做完内外区划分后,该性能有所下降,见图中inner-outer 部分.
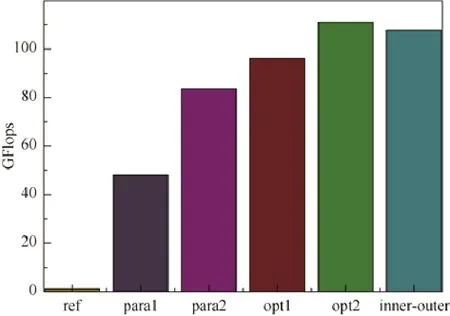
Fig.13 HPCG performance using single process图13 HPCG 单进程性能
本文基于某国产复杂异构超级计算机系统进行测试,分别测试了单节点计算效率和整机计算效率,并测试了整机的弱可扩展性,最终单节点计算效率达到了1.82%,整机计算效率达到了1.67%,整机弱可扩展性并行效率达到了92%.
9 结论及下一步工作
本文面向国产复杂异构超级计算机研制了异构众核并行HPCG 软件,从着色算法、异构任务划分、稀疏矩阵存储格式等角度展开研究,提出了一套适用于结构化网格的着色算法,用于HPCG 后,着色质量与现有算法相比有明显的提升.通过分析异构部件的传输开销,提出了一套异构任务划分方法,并采用ELL 格式存储稀疏矩阵,以减少访存开销.同时采用分支消除、循环展开、数据预取等多种优化方式进行了优化.在多进程实现时,为了尽可能地提升整机性能,本文还采用了内外区划分的算法,将邻居通信与内区计算进行重叠,以隐藏通信开销,提高并行效率.最终整机计算效率达到了峰值性能的1.67%,弱可扩展性并行效率更是提高到了92%.下一步将面向其他国产超级计算机开展HPCG 的并行与优化工作,研究HPCG 混合精度算法,并与相关应用进行合作,提升应用整体性能.
猜你喜欢
凤凰动漫(军事大王)(2022年9期)2022-11-05
房地产导刊(2022年4期)2022-04-19
今日农业(2021年9期)2021-11-26
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
今日农业(2020年16期)2020-12-14
山东农业工程学院学报(2020年12期)2020-03-19
科技传播(2019年22期)2020-01-14
数学杂志(2019年1期)2019-02-18
电影(2018年10期)2018-10-26
中国教育网络(2018年7期)2018-08-10
