
面向异构计算机平台的HPL 方案∗
2021-11-09 02:45孙家昶马文静赵玉文
软件学报 2021年8期
孙 乔 ,孙家昶 ,马文静,2 ,赵玉文,3
1(中国科学院 软件研究所 并行软件与计算科学实验室,北京 100190)
2(计算机科学国家重点实验室(中国科学院 软件研究所),北京 100190)
3(中国科学院大学,北京 100049)
1 HPL 基准测试及主流异构并行架构
HPL(high performance Linpack)[1]是一套被广泛用于测量计算机实际峰值计算性能的基准测试程序(benchmark).以其实际运行性能为标准,国际超级计算机性能排行榜TOP-500[2]每年会对众多超算进行性能排名.例如,2019 年,来自美国的超算“Summit”[3]以实测HPL 148.6 PFLOPS 双精度浮点性能位居TOP-500 榜首,而来自中国的神威-太湖之光则以93.0 PFLOPS 位居第三.TOP-500 排行榜是衡量全世界超级计算机发展的重要指标,而其核心测试程序HPL 的性能优化问题历来是各个超算厂商乃至各个国家发展高性能计算事业所关注的重点.在不断提高HPL 运行效率的过程中,程序的性能表现也为计算机系统及其基础软件的开发者提供有效的反馈信息,能够有效促进计算机系统的向前发展.
由于众核协处理器(如GPGPU)的普及,目前高性能计算机一般采用多路(socket)多核CPU+众核协处理器架构,如在2019 年TOP-500 榜单中名列前茅的Summit、Sierra 及天河2 号等.CPU 和协处理器往往采用不同的体系结构及指令集,这样的计算机架构被称为异构计算机架构.在这样的系统中,传统多核CPU 负责执行程序的逻辑密集部分,众核协处理器则高效地处理程序中计算密集的部分.由于协处理器的高性能主要依赖于大量轻量级核心提供的并行处理能力,因此可大幅度提高计算机系统整体的计算功耗比.鉴于异构众核架构诸多优势,其如今已在事实上成为了当今高性能计算机建设的主流解决方案.
图1 展示了目前典型的异构众核架构,从总体上来说,该架构可以简单地区分为Host端和Device端.Host端采用的CPU 具有多个物理上分开的Socket,而每个Socket 中有若干物理核心.这些核心是常规CPU 核心,能够有效处理程序中复杂的逻辑判断部分,因此程序的主进程运行在这些核心上.从内存层次结构上看,当今多路多核CPU 一般具有多级数据和指令缓存.如图1 所示,每个CPU 核心具有独立的一级缓存(L1-cache),而处于同一Socket 的若干CPU 核心共享二级Cache(L2-cache),可有效加速多个CPU 核心间共享数据或指令的访问.而作为CPU 与内存之间的桥梁,三级Cache(L3-cache)用来提高CPU 整体的访存速度.从图1 中还可以看到,异构众核系统的内存和CPU 的各个Socket 一样也是物理上独立的,每个Socket 都有与自己邻近的一块物理内存,该Socket 上的CPU 核心能够以较低的延迟访问近端内存,但若访问远端内存则延迟大幅度提高.各个Socket直接由高速网络互联,并在硬件上实现了访存一致性协议,形成cc-NUMA(cache coherent non-uniform memory access)结构,使得各个CPU 核心能在逻辑上共享一致的内存空间.值得注意的是,缓存一致性协议及远端内存访问会带来较大的开销,一种比较通用的方法是将各个进程分布在不同的Socket 上使得各个进程仅利用与该Socket 毗邻的资源.
目前Device端可以配备多个协处理器设备.这些协处理器相对于CPU 来说具有很高的计算能力.这样强大的计算能力一般是通过大规模并行计算实现.以当今主流的GPGPU 为例,一块GPGPU 卡中包含了众多流处理器,这些处理器结构相对简单而不适合处理逻辑复杂的代码,但这些流处理器在硬件上整合了大量的向量计算部件并实现了高效的线程切换机制.这样,一个流处理器能够高效地调度大量线程予以向量化并行执行.协处理器拥有独立的内存空间,一般通过PCI-e 总线与Host端的内存进行数据交换.
虽然上述异构架构较为普及,但以往对 大规模超级计算机上HPL 测试程序的优化工作的开展大多基于进程与协处理器一一对应这一前提[4−6].这种方案易于优化,也可避免缓存一致性协议及访问远端内存带来的开销.但在HPL 程序的实际执行过程中,这种方案将不可避免地导致大量处理器空闲,并增加结点内进程间通信开销.在本文中,我们面向高度异构架构提出一套新型HPL 测试程序Hetero-HPL,突破以往进程与协处理必须一一对应这一限制,使用进程内多协处理级并行方案,进而研究基于此方案的性能优化方法,在执行过程中更充分地利用各种硬件资源.
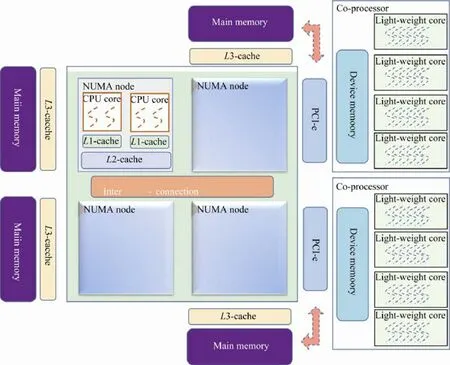
Fig.1 Typical architecture of multi-device heterogeneous platform图1 典型多设备异构平台架构
2 HPL算法概要
本节仅简要介绍HPL 程序执行过程中与本文工作相关的大致流程,关于各种算法细节可以参考[3,7−9]等,在此不再赘述.HPL 测试程序以多进程分布式的方式求解线性方程组Ax=b.矩阵A以二维循环块卷帘(block cyclic)的方式分布在二维矩形进程拓扑上.由于进程拓扑设置具有自由性,而HPL 测试常常基于正方形进程拓扑结构而展开,因此本文仅讨论典型的正方形进程拓扑下的HPL 分解算法,但本文工作也可用于非正方形进程拓扑结构的HPL 测试.
HPL 程序首先采用部分选主元(patial pivoting)的方式对随机矩阵A进行LU 分解,之后进行回代求解向量b.由于其绝大部分计算量集中在对矩阵A的LU 分解部分,对HPL算法的性能优化工作主要围绕该部分展开.对矩阵A的LU 分解操作从逻辑上可以分为Panel 分解及Update(尾子矩阵更新)两个部分.图2 展示了HPL 程序在3×3 进程拓扑下的大体执行流程.
在图2 中我们可以看到,对矩阵A的LU 分解过程以由多个迭代步骤完成.在每次迭代过程中,首先处于某一特定列(简称P-Fact 列)的所有进程协作完成Panel 的分解.Panel 分解完成对当前瘦高子矩阵(panel)的部分选主元过程的LU 分解操作.从具体算法上看,Panel 分解可选择向左或向右看(left/right looking)或Crout LU 分解算法.这三者计算量大致相等,具体的选择可根据实际运行的效率决定.P-Fact 列的进程在Panel 分解执行之后,通过数据传输,将产生的行交换信息(dpiv),Panel 分解的结果矩阵(L1 和L2)分享给同一进程行中的其他进程列,并开始接下来的Update 操作.在此值得一提的是,在Panel 分解过程所涉及的计算从形式上说具有逻辑复杂,小规模反复执行等特点,并行度较小.因此线程启停开销,函数调用,数据传输开销将严重制约Panel 分解过程的效率.因此其不适合采用Device端加速设备执行.
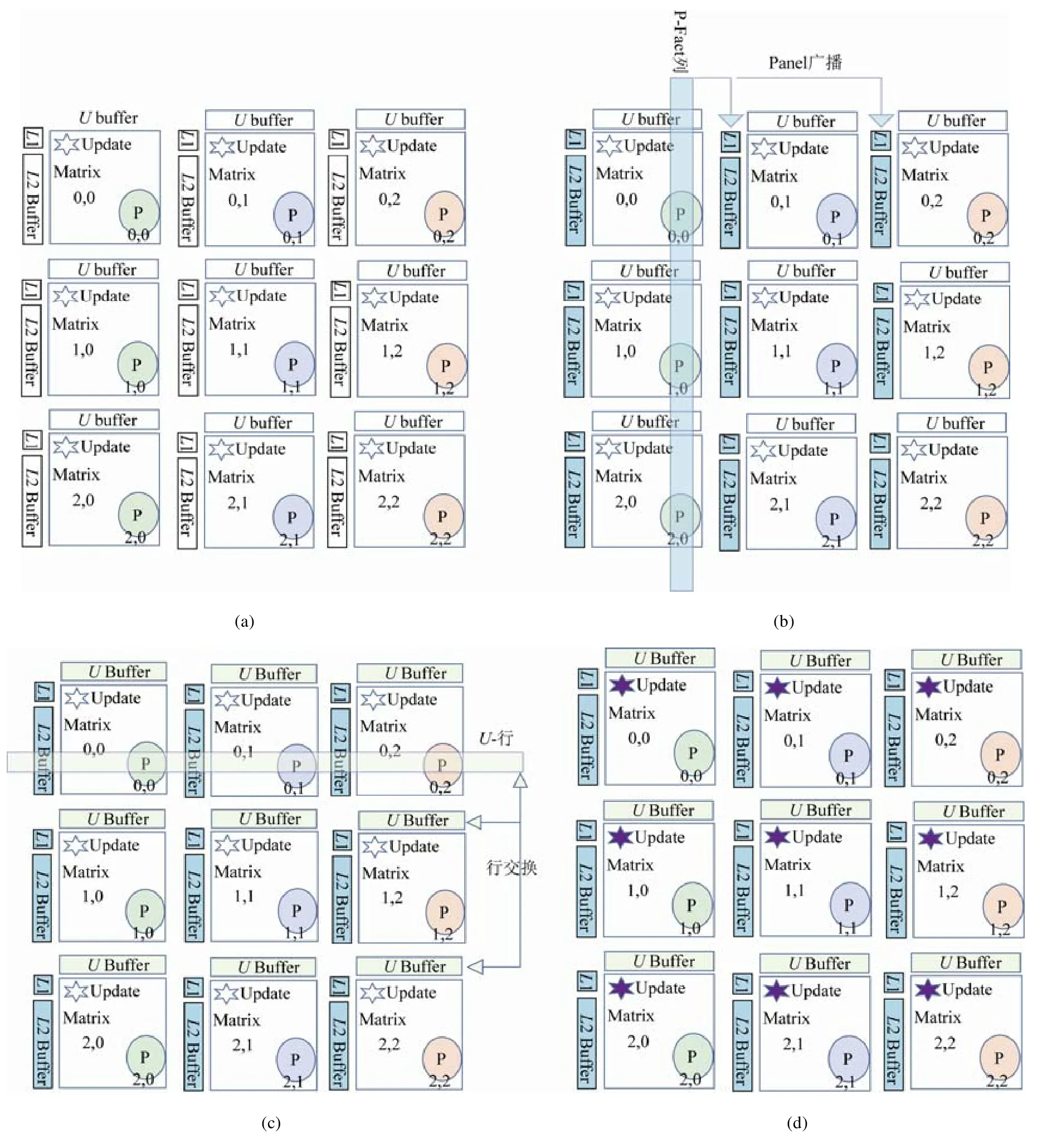
Fig.2 One iteration of HPL algorithm图2 HPL算法单次迭代
在Panel 分解执行完毕之后,所有列的进程开始执行Update 过程.在该过程中拥有矩阵U(或其某一部分)的进程行我们称为U行进程.这些进程将U中待交换的矩阵行集合后配合其他行进程完成矩阵对应列的分布式行交换过程,其结果是每一进程都拥有自身矩阵对应所需的U矩阵.之后,参与Update 操作的所有进程分别利用得到的L1 矩阵对交换后的U矩阵进行dtrsm(三角矩阵求解)更新,并利用得到的L2 矩阵和矩阵U对所属自身的尾子矩阵调用dgemm(矩阵乘法)完成更新.
不论进程与CPU 以怎样的方式对应,HPL算法中占据绝大部分计算量的尾子矩阵更新操作都能完全利用所有协处理器完成.在该过程通过协处理进行充分加速之后,其余的零散计算的资源使用率将成为性能瓶颈.其中典型的有Panel 分解操作及处于Update 阶段的分布式行交换操作.从算法流程上,在HPL 的每一次迭代步骤中,只有特定P-Fact 列进程完成本次迭代所需的Panel 分解操作,同时也只有U行进程参与矩阵U的广播.因此不同的进程与处理器的映射关系会导致不同的资源使用情况.图3 展示了一个由4 个实验节点(具体参数介绍见第5.1 节)组成的分布式环境.图3 左侧展示了进程与Socket 一一对应的情况.由于每一个Socket 仅管理8 个CPU 核心和一个协处理设备.因此在P-Fact 过程中只有共计8×4=32 个CPU 核心参与Panel 分解运算,而在Update 阶段的行交换过程中,仅有4 个协处理器完成对U矩阵的打包并由对应的4 道PCI-e 总线进行传输.若采用图3 右侧进程与节点(node)一一对应的方式执行HPL 程序,每个进程管控4 个协处理器设备,则在Panel 分解部分将有8×4×2=64 个CPU 核心参与计算,而在Update 阶段的行交换过程中会有8 个协处理器及其PCI-e总线参与.随着协处理器运算能力的进一步增长,占绝大部分计算量的BLAS 3 级函数能够很快完成,而诸如Panel 分解,数据打包等必要步骤的运行时间比重将进一步加大,因此应在这些步骤中应尽可能地充分利用各种硬件资源.
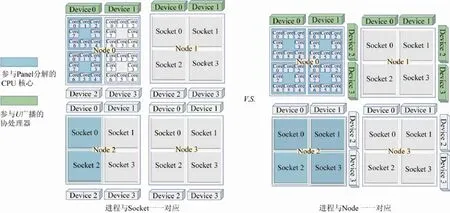
Fig.3 Different mappings between processes and nodes图3 进程与节点的不同对应关系
3 Hetero-HPL 总体结构
为了提高HPL 各个阶段的资源利用率.本文提出Hetero-HPL 方案.总体上,Hetero-HPL 中每一个进程能够管理任意数量的协处理器,在大幅度提高上述关键计算步骤的资源利用率的前提下,以协处理器间高度负载均衡的方式完成HPL 计算.Hetero-HPL 对原始HPL算法做出的改动可归纳为数据映射及操作映射两个方面,分别对应于如图4 所示的MD_Mapping 框架及MD_Primitive算法库.它们将在本节中分别予以介绍.
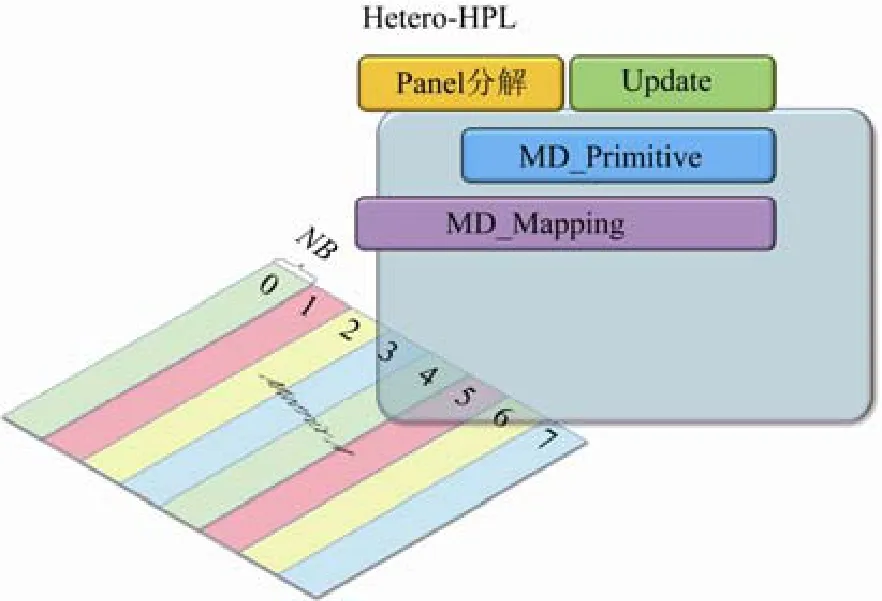
Fig.4 Architecture of Hetero-HPL图4 Hetero-HPL 总体结构
3.1 Hetero-HPL数据映射
在数据映射部分,Hetero-HPL 要解决如下3 个问题:(1) 确保Update 中BLAS 3 函数完全由协处理器(组)完成,以接近计算平台的理论性能峰值;(2) 各个协处理器间计算相互独立,以避免冗余的跨协处理器的数据交换及相互依赖;(3) 在每一次迭代过程中,各个协处理器间应保持负载均衡.为同时解决这3 个问题,我们为稠密矩阵在协处理器间进行数据划分提供一套框架,名为Matrix-Device_Mapping(简称MD_Mapping),提供高层接口便于开发者在逻辑上访问任意子矩阵,屏蔽了数据物理分布细节.
如图5 所示,在每一个进程中MD_Mapping 框架将HPL 程序生成的初始伪随机矩阵划分到各个协处理器.由于在Update 阶段,同一进程上的各个矩阵列间的操作是独立的,因此最自然的数据划分策略即为按矩阵列进行划分,以NB为宽度形成若干个列块.由于计算过程中,尾子矩阵的规模逐渐变小,若按照列方向线性划分并指派到各个协处理,则会导致协处理负载不均衡问题.因此,我们在MD_Mapping库中采用按列块循环卷帘的方式将诸多列块平均分配到各个协处理上.MD_Mapping库以描述符的方式选取原始矩阵的任意子矩阵,即便这些子矩阵在物理上分布于不同的协处理器.运算围绕相关子矩阵实现.值得注意的是,假如我们对各个协处理器从0 开始依次进行编号,并采用MD_Mapping 中使用的列块循环卷帘数据排布方式,在同一列的不同进程上,原始矩阵中同一列元素所在的协处理器编号是相等的.这便于今后采用协处理间直接通信机制来优化Hetero-HPL程序性能.
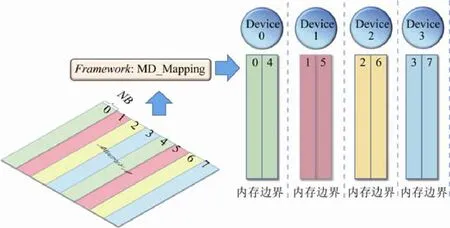
Fig.5 Matrix partition based on MD_Mapping framework图5 基于MD_Mapping 框架的矩阵划分
3.2 Hetero-HPL操作映射
在Update 阶段,HPL算法主要涉及3 种操作:(1) (分布式)行交换;(2) 上三角矩阵更新dtrsm;(3) 尾子矩阵乘更新dgemm.而在具有多设备的异构众核平台上,数据在Host 及Device 之间数据一致性也需要通过数据传递来实现.因此,我们在 MD_Mapping 框架上实现了 MD_Primitive库.MD_Primitive 层以MD_Mapping 提供的子矩阵描述符为操作对象,调用所有相关协处理器协同(并行)完成施加于目标子矩阵的操作,如数据传递,三角矩阵更新和矩阵乘更新等.另外,MD_Primitive 中的函数调用接口皆为异步接口,可以方便实施多操作重叠执行.在具备MD_Mapping 框架及MD_Primitive库之后,Hetero-HPL 的大致程序结构如图6 所示,其中,绿色字体代表同步调用,红色字体代表异步调用.
在整体算法开始之前,MD_Mapping 已经完成了对初始系统Ax=b的映射,生成映射实例MatrixMapping.由于Hetero-HPL 主要对HPL算法的Update 阶段进行了重构,因此我们围绕Update 阶段进行阐述,其伪代码如图6 左侧所示.通过MatrixMapping 实例,程序获取两个子矩阵描述符(第3 行~第6 行),分别为 NextPanel(下一 Panel)及 TrailingMatrix(尾子矩阵).这两个子矩阵实例的实际数据分布细节被MD_Mapping 框架屏蔽.MD_Mapping 为每个设备预留了数据缓存L(可进一步划分为L1 和L2)用来放置分解完毕的Panel 数据.各个子矩阵实例可按需要分配属于自身的Device端数据缓存U.数据缓存L及U将在接下来的步骤中使用,包括行交换(第11 行及第18 行),上三角矩阵更新(第12 行及第19 行)和矩阵乘更新(第13 行及第20 行).这些步骤由MD_Primitive库中函数实现.我们将施加于NextPanel 的所有运算完成之后,开启异步传输(第15 行),从对应的设备上将NextPanel 的数据拷贝回Host端内存,进而完成下一次Panel 分解操作.与此同时,对TrailingMatrix 的上三角矩阵更新及矩阵乘更新可以通过异步接口与下一次Panel 分解并行执行,如图6 右侧所示.

Fig.6 Pesudo-code of Hetero-HPL based on MD_Mapping and MD_Primitive图6 基于MD_Mapping 及MD_Primitive 实现的Hetero-HPL 伪代码
4 面向异构平台的实现及优化
4.1 突破锁页内存分配大小限制
在现在主流异构平台上,Host端内存和Device端协处理器内存的数据交换主要通过PCI-e 总线完成.若要尽可能充分地利用PCI-e 总线的带宽(约32GB/s,全双工)则需要在Host端开辟锁页内存(pinned memory).锁页内存的最大特点是其不会被操作系统换出到硬盘交换区,以便于设备端建立物理地址映射,因此对协处理器来说可以通过DMA 机制高速访问.相比于以常规方式申请的内存空间来说,锁页内存能够拥有2~3 倍的访问速率.然而,锁页内存一般为连续的物理内存空间,其申请受到单一NUMA 节点上内存大小的限制.为确保数据在Host端及Device端对应,在拥有若干协处理平台上,单次申请的锁页内存容量很可能远小于所有设备内存的总和[10].因此,面向 Hetero-HPL,我们对原始矩阵建立软件缓存,采用若干锁页内存来替代非锁页内存.
如图7 所示,以目标平台为例,假设原始矩阵大小为64GB,在Hetero-HPL 中,我们开辟两片(或多片)锁页内存区域(大小都为32GB),然后采用同样的伪随机数生成算法直接初始化这两片内存区域.之后,在LU 分解的过程中,Hetero-HPL 直接与这两片锁页内存完成多次矩阵Panel 的相互交换.值得一提的是,原始的64GB非锁页内存区域在Hetero-HPL 执行过程中并不需要真实存在,因此Hetero-HPL 并不会带来冗余内存消耗.通过简单的地址变换,Hetero-HPL 也不会通过大量冗余操作来进行数据传输.在Hetero-HPL 执行完成之后,我们获取解向量b并释放掉所有锁页内存.之后再由验证程序在64GB 非锁页内存中重建整个线性系统,进而完成结果验证.
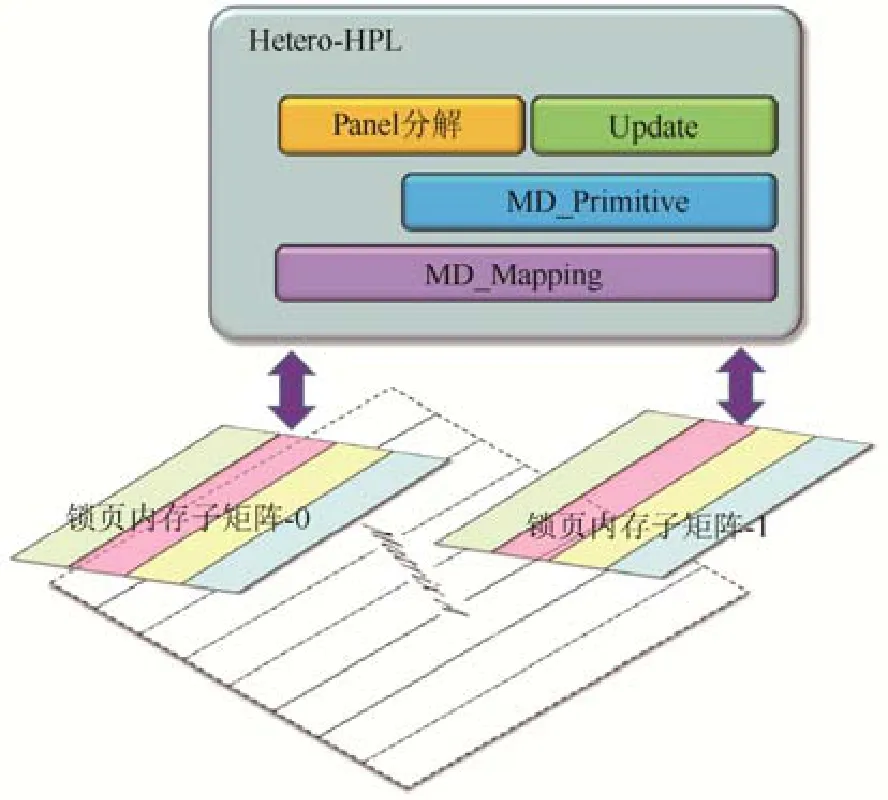
Fig.7 Original un-pinned memory is replaced by two pinned memory regions图7 采用两片锁页内存区域替代原始非锁页内存
4.2 同一协处理器上相同操作的归并
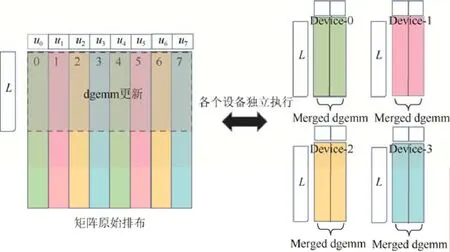
Fig.8 Merge of the same operation on each co-processor图8 协处理器上同种操作的归并
由于我们采用了按列块循环卷帘的方式在各个协处理器上分配矩阵数据,而每一列块的列数仅为NB(通常为128,256,512 等),因此施加在某一列块上的操作(如矩阵乘dgemm 函数)可能会由于其数据规模过小而无法充分发挥协处理器的大规模并行计算能力.针对HPL算法程序,由于各个列块间计算相互独立,我们可以利用矩阵不同列间计算的结合律,让位于同一协处理的所有列块同时执行相同操作,即便这些列块在逻辑上并不相连.如图8 虚线框所示的子矩阵,其由多个列块构成.在每一个协处理器上,我们只需调用一次dgemm 函数就可以完成该协处理器上所有列块的更新.类似地,同一进程中的行交换,dtrsm 等操作也可以进行归并,故不再赘述.
4.3 Panel分解与协处理器组异步并行
Panel 分解过程的各个步骤由于计算规模小,调用频繁而不利于使用协处理器进行加速.因此,在当前的Hetero-HPL 版本中,我们将Panel 分解放置在CPU端执行.如前文所述,相对于进程与协处理一一对应的方案而言,在Hetero-HPL 中Panel 分解操作将有条件利用更多CPU 核心来完成计算.在HPL算法中下一次迭代步的Panel 分解可以和当前次迭代的尾子矩阵dgemm 更新并行执行.我们结合MD_Primitive库中的异步函数接口,可以很轻易地完成上述两个关键步骤的异步并行执行.
4.4 相关Kernel的优化实现.
由于待分解的矩阵被置于协处理器内存中,因此我们需要手工编写协处理器代码以实施相应运算.对于BLAS 函数,我们可以直接调用RocBLAS库.而对于诸如行交换,矩阵转置等操作则需要我们手工编写计算Kernel 完成.在此过程中,我们一方面要利用协处理器的大规模并行能力,另一方面我们也需要利用计算的可结合性,尽量在一次Kernel 启动中完成同一协处理器上所有数据的计算.
5 实 验
5.1 实验平台简介
Hetero-HPL 面向当前主流的多协处理器架构构建,因此我们采用一个多核CPU+多个GPU 的典型异构系统作为实验平台.实验平台具有Host端及Device端.Host端采用4 路8 核Intel 指令集架构.与每路CPU 核心邻近的内存大小为32GB,系统共计128GB 内存空间.Device端为4 个类GPGPU 设备,每块类GPGPU 拥有64 个流处理器,16GB 设备内存.实验平台Host端支持Posix 标准.因此可以采用常用的并行编程模型如MPI、OpenMP 等.而对于Device端的类GPGPU 设备,实验平台提供基础并行编程环境Hip,并拥有开源基础并行算法库Rocm[10].类似于NVIDIA 公司推出的通用显卡计算编程环境CUDA 及其加速算法库CUDA Toolkit[11],实验平台能够支持手工编写并编译适用于Device端运行的计算kernel,还可以直接利用Rocm算法库中的高性能函数实现并优化程序.另外,HPL 程序的高效执行离不开底层高效执行的基础线性代数库 BLAS.在Host端,实验平台采用BLIS[4]数学库,其dgemm 执行效率可以高达CPU 理论峰值性能的98%以上.而在Device端,我们同样可以利用Rocm算法库中的RocBLAS 数学库模块,其dgemm 性能约为单块协处理器理论性能的84%以上.
5.2 单节点实验结果
Hetero-HPL 可以支持所有128 倍数的NB取值.通过实验我们发现NB=256 能够取得较优的总体性能.另外在NB=256 时,Device端矩阵乘法效率大约为机器峰值性能的84%.我们选取31 个CPU 核心参与Panel 分解计算,也能获得较优的总体性能.
图9 展示了Hetero-HPL 在单节点单进程情况下的运行效率.随着矩阵规模的扩大,执行效率呈现大幅度上升趋势.在矩阵阶数达到88 320(4 个协处理器设备内存占用率达到95.5%)时,Hetero-HPL 的运行效率达到了实验平台峰值性能的76.53%,同时也达到了dgemm 性能的91.11%,因此可见Hetero-HPL 在单节点单进程情况下能够取得较优的性能.
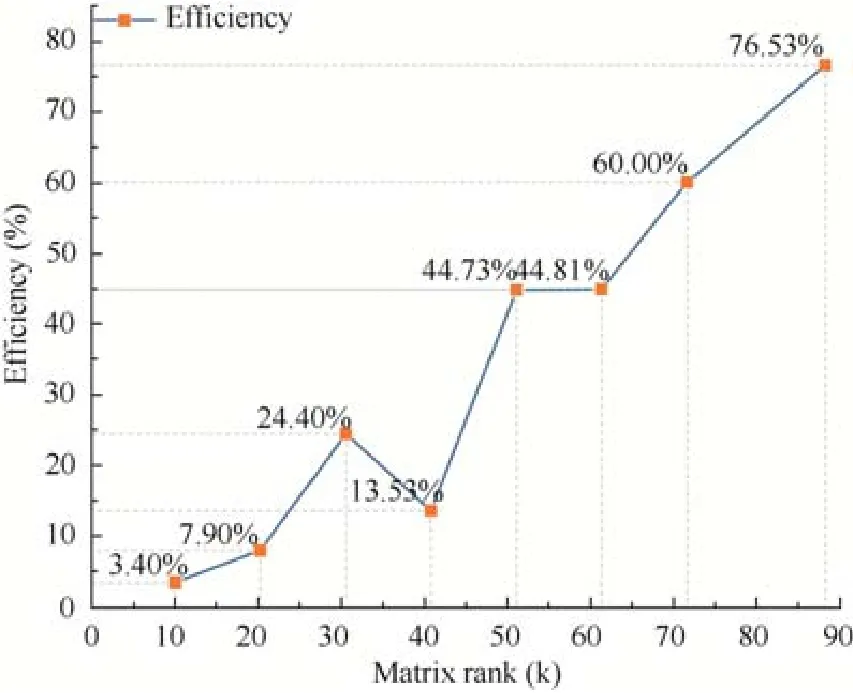
Fig.9 Efficiency trend of single process Hetero-HPL with respect to matrix rank图9 单进程Hetero-HPL 执行效率随着矩阵阶数变化趋势
5.3 多节点实验结果
图10 展示了Hetero-HPL 在4~256 个节点的运行性能.实验中每个进程的Device端内存使用量达到96.0%.我们的工作展示了基于单进程控制多协处理器技术的 HPL算法在分布式环境下的测试结果.但意外的是,Hetero-HPL 虽然在算法层面并没有引入多余的数据传输量,但是程序的性能随着进程数的增加而大幅度降低.由于HPL算法本身具有很好的可扩展性,而在实际测量中我们发现通信所耗费的时间约为总体计算时间的25%~30%,因此我们认为通信效率成为制约Hetero-HPL 在分布式环境下扩展性的一个重要方面.

Fig.10 Scalability of Hetero-HPL on 4~256 nodes图10 Hetero-HPL 在4~256 个节点可扩展性
Hetero-HPL 通信开销表现在3 个方面.第一,PCI-e 总线利用率不高.以Panel 分解相关的节点内传输为例,由于目前采用NB为列数按列方向划分矩阵,使得任意一个Panel 从Device端拷贝到Host端仅能采用一路PCI-e总线.若使用NB/D(D为设备数量)为列数进行矩阵划分并在设备间卷帘排布,则可以确保任意一个Panel 的数据均匀分布于所有设备,上述传输可以使用所有PCI-e 总线并行完成.另外第4.2 节所述的操作归并技术亦可在更细粒度的数据划分方案上使用,可确保设备端的计算性能.第二,Panel 分解阶段并未实现计算通信重叠.我们认为能够利用Panel 分解过程中BLAS 3 级函数来掩盖部分Panel 相关的数据传输.第三,进程间的MPI 通信效率有待考证.由于Hetero-HPL 不能直接控制底层网络资源(如多块网卡),因此如何配置MPI 使其针对Hetero-HPL发挥最优性能也是一个值得深入研究的问题.
6 相关工作
自从HPL 程序被提出并作为高性能计算评测标准,对其研究和改进及在不同平台上的并行方案、优化方法及计算模型研究就未曾中断过.从早期的Intel Paragon 平台上的实现与测试[12],到现今世界最快的超级计算机上的优化与开拓[13],对HPL算法及优化的研究一直在影响着计算机软硬件设计与发展.异构平台上的HPL 一般是主要由速度较快的加速器来完成矩阵更新操作,CPU 负责通信及Panel 分解[6,7].Wang 等为GPU+多核CPU平台设计了分阶段动态任务划分的方法及软件流水线,以充分利用计算和通信资源[8].Heinecke 等人针对带有MIC 加速卡的平台,做了细粒度多层次的任务划分,从而实现对各部件的充分合理使用[9].Gan 等面向HPL 在国产加速器China accelerator 上对dgemm 进行了优化,并使用静态与动态相结合的调度方式来协调CPU 与加速器之间的工作[3].对多GPU 平台上的HPL 研究,陈任之等人工作采用了与本文工作类似的单进程控制多协处理器案[14].但是由于其并没有将尾子矩阵驻留于Device端,因此数据在Host端和Device端的来回传输对整体性能产生了负面影响.相似的方案也被AMD 公司采用,为HPL 中的dgemm 实现了单进程多设备版本[11].与上述两个方案不同的是Hetero-HPL 在多协处理器环境中也实现了全局数据的驻留,根本上避免了尾子矩阵的搬移.Jia 等人提出了与Hetero-HPL 类似的解决方案,确保了数据多设备端的驻留并采用了按列块循环卷帘数据结构确保数据负载均衡[6].但值得指出的是,Jia 等人没有考虑到锁页内存分配大小限制小于Device端所有设备内存总量这一情况.在如本文所述的平台上,该方案只能处理较小阶数的矩阵,因而无法充分反映平台性能,因此其单节点性能仅达到机器峰值性能的46.06%.另外,由于其方案采用了激进的动态调度策略,其复杂性也进一步降低了该方案在多进程环境中的可行性.在以上两方面,本文工作更为深入.
7 总结与未来的工作
面向当今主流的异构高性能计算平台,本文提出了Hetero-HPL 测试程序.整体上,Hetero-HPL 所依赖的数据对协处理器的映射规则,并行策略等并不依赖于具体的硬件架构及基础软件,因此有能力在现有多种主流众核架构上进行部署.Hetero-HPL 还从根本上突破了进程数量与协处理器数量必须相等的限制,更进一步提高了其实用性.在执行过程中,单个进程携带多个协处理器的配置有利于在Panel 分解和分布式行交换过程中利用更多了的计算资源,有利于执行效率的提高.Hetero-HPL 基于MD_Mapping 框架和MD_Primitive库,使占主要计算量的尾子矩阵更新步骤完全利用多个协处理器提供的大规模并行计算能力,同时也避免了同一进程中多个协处理器间相互数据交换并确保各协处理器间计算量的均衡.面向多设备异构平台,我们突破了锁页内存分配限制,利用多块锁页内存在逻辑上替代原始非锁页内存,使Hetero-HPL Device端与Host端的内存交换仅发生在锁页内存中,确保了执行的高效.在本文中,我们面向多设备异构系统尝试了一些基础但必要的优化手段,其中包括Panel 分解与尾子矩阵dgemm 更新的异步并行,同一协处理器上相同计算的归并及行交换相关操作在协处理器端的并行化实现.实验结果表明,在单节点条件下Hetero-HPL 达到了实验平台峰值性能的76.53%(dgemm实测性能的91.1%).Hetero-HPL 还展示了基于单进程控制多设备技术的HPL算法在多节点分布式环境下的可行性.但目前由于网络通信及PCI-e 数据交换的开销比例过大,程序执行效率还需进一步提高,这是我们将要深入研究的一个重要方面.
基于Hetero-HPL,我们未来将主要开展两方面的工作.一方面,进一步在目标平台上深入优化Hetero-HPL程序.其中包括深入挖掘Hetero-HPL 程序中的并行性,使更多关键步骤,如Panel 在Host端及Device端的来回传递、跨进程的广播和分布式行交换等得以并行执行;在此基础上,分析各个步骤在各次迭代中的时间占比,基于动态信息反馈安排不同的异步并行方案.另一方面,我们可以在若干不同的平台上实现Hetero-HPL,梳理制约Hetero-HPL 性能的一般性因素,为Hetero-HPL 的性能表现建立数学模型.
猜你喜欢
小学教学研究(2022年5期)2022-04-28
中国外汇(2019年20期)2019-11-25
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
中国外汇(2019年8期)2019-07-13
商周刊(2019年1期)2019-01-31
中国洗涤用品工业(2017年2期)2017-04-16
通信电源技术(2016年6期)2016-04-20
电脑爱好者(2015年21期)2015-09-10
民主与科学(2014年3期)2014-02-28
