
国产异构系统上HPL 的优化与分析∗
2021-11-09 02:45水超洋于献智王银山谭光明
软件学报 2021年8期
水超洋 ,于献智 ,王银山 ,谭光明
1(中国科学院 计算技术研究所,北京 100190)
2(中国科学院大学,北京 100190)
HPL(high performance linpack)是目前HPC 领域中最重要的基准测试程序之一,其性能被用作TOP500 的排名依据[1,2].HPL 可以从超级计算机的计算性能、访存性能、网络性能、可用性和稳定性等各个方面给予超级计算机综合评价.HPL 的优化具有重要意义,在学界长期受到关注和研究.HPL 的优化可以为其他科学计算应用的并行优化提供有价值的参考.
自1993 年TOP500[3]排名开始,榜单中的超级计算机的体系结构一直在发生变化.图1 展示了排名第一的计算机的体系结构的变化.从图1 中我们可以看到超算的体系结构从早期的向量处理器和单核通用CPU 时代开始,然后演进到多核CPU 时代,超级计算机的计算能力也从GFLOPS 提升到TFLOPS.2008 年的超算Roadrunner[4]标志着异构架构的超级计算机体系结构的兴起,随后异构架构开始频繁涌现,超级计算机进入了PFLOPS 的时代.各种加速器,如GPU、DSP、FPGA、MIC 等都作为加速卡出现在各种超算中,我国有也了自己的国产加速器和国产处理器.伴随着超算体系结构的变化,HPL算法的设计与实现也应该适应新的体系结构.在这种背景下,本文建立了国产处理器-国产加速器异构架构上的HPL 性能模型,重点研究了国产处理器-国产加速器异构架构下的HPL算法的设计与实现.本文的主要贡献如下:
•本文建立了一个HPL 性能模型.
•针对国产处理器-国产加速器异构架构,本文设计了一种多线程细粒度流水HPL算法,充分利用异构系统中的多种硬件,取得了超过同类系统其他实现的效率.
•本文实现了轻量级跨平台的异构加速框架HPCX.
本文第1 节分析相关研究.第2 节介绍HPL 的性能模型.第3 节给出针对异构架构的多线程细粒度流水HPL算法及异构加速框架HPCX.第4 节呈现新HPL算法的性能以及分析.第5 节总结全文.
1 相关研究
HPL 是横量超算性能最重要的基准测试程序之一,其性能作为TOP500 排名的依据.由于HPL 的重要地位,国内外有许多针对Linpack 的优化工作.这些工作主要集中在HPL算法优化,双精度矩阵乘法效率优化和HPL性能模型3 个方面.
在Linpack算法优化方面,Dongarra 等人基于消息通信接口(message pass interface,简称MPI)和基本线性数学库(basic linear arithmetic subroutine,简称BLAS)的Level 3 函数实现了分布式的HPL算法[1].在此基础上,文献[5]提出了一种单边通信和动态look-ahead算法,通过重叠第i+1 轮迭代的panel 分解与第i轮迭代的尾矩阵更新来实现部分通信与计算的重叠.针对异构架构,Fatica 通过将尾矩阵划分为固定比例的两块分别分配给加速器和CPU 以实现CPU 和加速器的协同计算[6].Yang 扩展了Fatica 的工作实现了动态的CPU 和加速器计算任务划分,采取根据上一次计算的CPU/加速器性能比决定下一轮任务划分比例的策略[7].文献[8]实现了一种work-stealing 的策略来实现CPU 和加速器的计算任务动态平衡,并且利用有向无环图来维护算法中的计算依赖关系.通过这种对依赖关系的分析,文献[8]将行交换的过程分成几个部分,通过行交换和尾矩阵更新的相互重叠探索了一种粗粒度的流水线算法.
作为HPL 的核心运算,双精度矩阵乘法的优化在HPL 的优化中占有重要地位并且得到了全面而深入的研究.在传统CPU 平台上,文献[9]给出了CPU 上的矩阵乘法的分层算法,通过对CPU 存储层次的模拟设计出相应的多级分块缓存策略,以尽可能地利用高速缓存中的数据.在包含加速器的异构架构上,李佳佳等提出了五阶段流水的异构矩阵乘算法来掩盖CPU 与加速器之间的PCIe 数据传输[10,11].MAGMA[12]通过细粒度的任务划分并且灵活地在CPU 和加速器上调度这些任务来实现负载的动态平衡.为充分利用加速器如GPU 的计算能力,文献[13]通过微基准测试来探测GPU 的体系结构,在汇编语言层面做了多种优化,以实现接近GPU 理论浮点峰值性能的双精度矩阵乘效率[13].
关于HPL 的性能建模,文献[14]以预测HPL 的扩展性为目的给出了HPL 在CPU 系统上的性能模型.HPL的求解时间被建模为panel 分解,panel 广播,行交换和尾矩阵更新的时间之和,并给出了模型中一些常量系数的经验值.王申等人在这个基础上考虑了look-ahead算法中部分广播开销可以被尾矩阵的更新和行交换所掩盖的情况[15],给出了更为精确的模型.文献[16]认为上述模型的计算都不够精确,因为模型中的常量值都是经验值,而CPU 计算效率以及通信带宽等模型常量都会受数据量大小的影响.他们主张将这些常量系数视为可变的,通过已有的测试结果去学习这些系数,用学习得到得系数建模预测大规模求解的性能.
已有文献中对HPL 的优化主要集中在同构架构上的简单算法优化和性能建模以及异构架构上的双精度矩阵乘的优化上,而缺少异构架构上的HPL 的算法建模和算法流水层面的优化.本文在CPU 的HPL 性能模型的基础上建立了国产处理器-国产加速器异构架构上的HPL 性能模型,并提出了多线程细粒度的HPL 流水线算法,以充分发挥异构系统中国产处理器的巨大计算能力.在实现上,我们实现了一个轻量级的跨平台异构加速框架HPCX,并用生产者消费者模型来协调多线程和多流的协同计算.
2 HPL算法和性能模型
2.1 HPL算法简介
HPL算法通过迭代法求解N 阶线性方程组Ax=b.求解过程包含两个步骤,首先通过带行交换的高斯消元法对系数矩阵进行 LU 分解得到[Ab] =[[L,U]y],然后进行三角回带求解x.其中 LU 分解的计算量为,三角回带的计算量为2N2[1].给定系统的理论浮点峰值性能和HPL 的求解时间T,系统的实测浮点峰值性能Rmax可以表示为,HPL 的效率E=Rmax/Rpeak.
HPL 的两个步骤中LU 分解的计算量为O(N3),三角回带的计算量为O(N2),相比于LU 分解的时间,三角回带的时间基本可以忽略[17],所以我们的优化也集中在LU 分解上.式(1)给出了LU 分解的符号表示,详细的算法数学证明请参考文献[1].在实现上,LU 分解以NB列为迭代步进行迭代求解,算法1 给出了LU 分解的详细算法描述.每一轮迭代包含4 个子过程,分别是panel 分解、panel 广播、行交换和尾矩阵更新.其中panel 分解(panel_factorization)通过递归高斯消元求解得到L11,U11和L21;panel 广播(panel_bcast)将L11和L21广播给同行的行进程;行交换(row_swap)根据panel 广播收到的行交换信息做行交换;尾矩阵更新(update)首先执行双精度三角矩阵求逆(DTRSM)得到U12,然后通过将L21和U12做双精度矩阵乘(DGEMM)更新A22矩阵.

2.2 HPL性能模型.
在已有的CPU HPL 建模分析的基础上[14,16−19],我们提出了适应于处理器-加速器异构架构的HPL 性能模型.在具体介绍我们的HPL 性能模型之前,我们先给出一些符号及其含义,大部分符号采取与文献[17]中一致的名称.矩阵A是N×(N+1)的系数矩阵,以NB×NB的块大小均匀分布在P×Q的二维进程网格中,mp×nq表示每个进程处理的子矩阵的大小.ffact表示panel 分解中浮点操作的比例,Pcpu和Ecpu分别表示国产处理器双精度浮点峰值性能和浮点操作的效率,Pacc表示国产加速器双精度浮点峰值性能,Edgemm和Edtrsm分别表示国产加速器上DGEMM 和DTRSM 的效率,网络延迟为Lats,带宽为BWbyte/s.对于panel 分解子过程,我们通过估计子过程中矩阵乘的计算量乘以一个系数来估计整体的浮点计算量,式(2)给出了这一子过程的时间估计.其中需要特别指出的是,我们将panel分解中大矩阵放到国产加速器上进行计算,这在式(2)的分母中体现了出来.

对于panel 广播算法的选择,我们实现中采用的是HPL 软件包中复杂度较低的Long算法.它的复杂度为log级别,体现在式(3)前半部分的系数.每次广播,我们需要传输大小为NB×NB的L11和mp×NB的L12以及少量索引,这些数据均为双精度类型(8 字节),公式的后半部分给出了每一跳(从一个节点传往下一个节点)的时间估计.式(3)给出了对这一过程的时间估计.
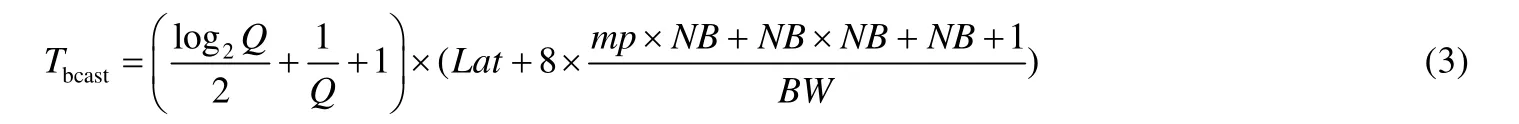
行交换时间的估计方式与panel 广播的估计方式类似,区别在于采取的算法和传输的数据量不同.出于避免冗余数据传输的目的,行交换采用的是spread-roll算法[11],式(4)给出了这一子过程的时间估计.
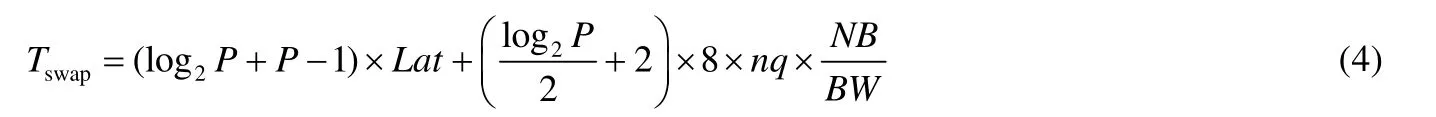
尾矩阵更新的过程主要是在国产加速器上执行两个BLAS库函数DGEMM 和DTRSM,其计算量分别是2×mp×nq×NB和nq×NB×NB.式(5)给出了尾矩阵更新的时间估计.
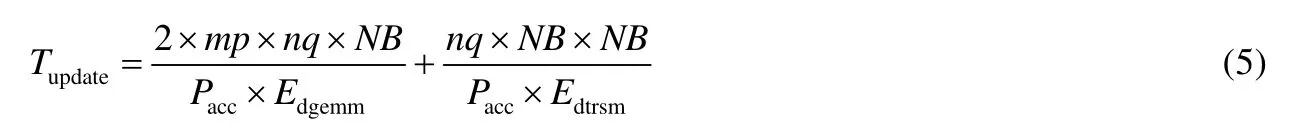
性能模型中参数的值,我们分为两类.一类是可以预知的,比如问题的规模,分块的大小以及硬件的峰值浮点性能等等,对于这一类参数,我们根据系统硬件以及求解问题的实际规模设定好对应的值;另一类是不可以预知的,比如双精度矩阵乘的效率可能和矩阵的规模相关,网络的实际带宽和延迟可能受发送的数据量的影响等等,对于这一类参数,我们通过小规模实际测试给出其实测值.
我们用TOP500 榜单中排名靠前的与国产处理器-国产加速器类似的异构系统,如Summit[20]、Serria[21]、ABCI[22]以及曙光E 级超算原型机对上述HPL 性能预测模型进行了检验,结果见表1[17].在大规模系统HPL 性能预测的准确性上,最大误差值不到5%.可以看到,我们建立的国产处理器-国产加速器异构HPL 性能模型较为准确,可以给将来E 级机的建造提供参考.
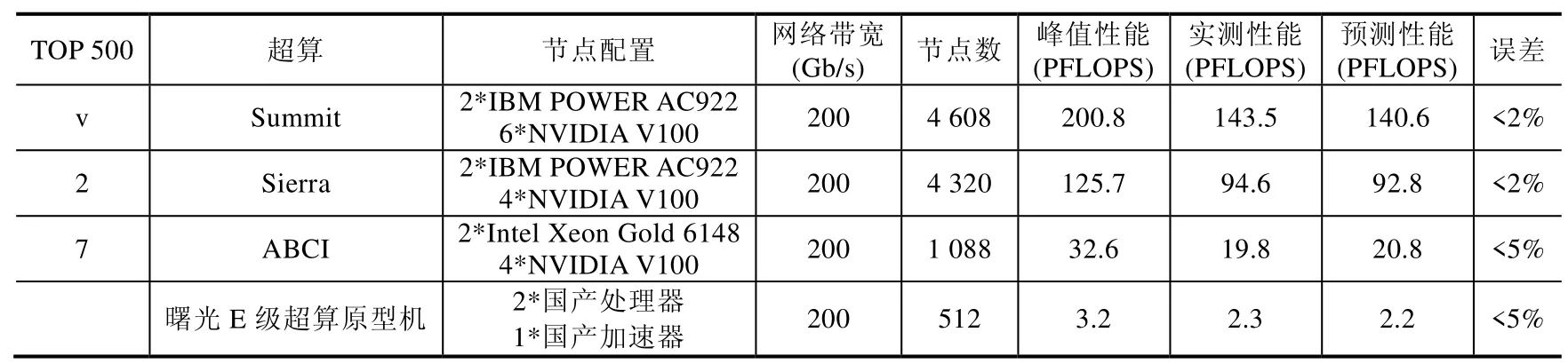
Table 1 TOP500 supercomputer performance prediction表1 TOP500 超级计算机性能预测
3 多线程细粒度HPL算法设计及实现
在已有的文献中,LU 分解的4 个子过程,panel 分解,panel 广播,行交换和尾矩阵的更新都是顺序执行的.在过去纯CPU 时代,由于尾矩阵更新占据了90%以上的时间,HPL 的效率主要由DGEMM 的效率决定,其他3 个子过程对性能的影响不大.此时这种顺序执行4 个步骤,或者通过简单的look-ahead算法[5]实现粗粒度流水的算法也能取得很好的效果.但是对于国产处理器-国产加速器异构架构,由于国产加速器计算能力与国产处理器的计算能力存在1~2 个数量级的差距,尾矩阵更新的时间占比减少到了50%左右,此时panel 分解,panel 广播和行交换对性能的影响就不能忽略.在这样的背景下,探索一个新的细粒度流水算法用update 的有用计算去掩盖panel 分解、panel 广播和行交换的开销对于提升HPL 的效率,充分发挥国产加速器的强大计算能力显得尤为重要.
3.1 多线程细粒度HPL算法的设计
HPL 耗时最多的计算是尾矩阵A22更新的矩阵乘法计算,异构HPL算法加速的核心是利用国产加速器加速矩阵乘法.传统的CPU-加速器异构HPL算法通过把panel 分解的结果L11,U12,L21矩阵拷贝到加速器内存,同时将更新前的尾矩阵A22拷贝到加速器内存,利用加速器求解U12和更新尾矩阵,将更新后的尾矩阵~A22拷贝回CPU 内存[17].这种做法将系数矩阵放在CPU端内存中,每次调用加速器的DGEMM 都需要把数据通过PCIe 拷贝到加速器内存,在完成计算后又需要把结果矩阵拷贝回CPU 内存.在文献[6]中通过三阶段流水的办法用加速器上的计算来掩盖PCIe 数据传输的开销,但是加速器算力增加的速度远远高于PCIe 带宽的增加速度,它们之间越来越大的差距使得加速器计算的时间无法掩盖PCIe 传输的时间.为了解决这个问题,我们将系数矩阵放在国产加速器的内存上,这样就避免了国产处理器和国产加速器之间大量的数据交换.只需要在国产处理器做panel 分解之前,从国产加速器把panel 需要的NB列数据拷贝回来就可以了.假设当前迭代中剩余待求解系数矩阵大小为n× (n+1),原来粗粒度并行的算法中,我们需要通过PCIe 移动字节的数据,现在只需要移动字节数据,通过PCIe 的数据传输量大大减少了.这个版本的HPL算法我们称为粗粒度HPL算法.
粗粒度HPL算法存在两个问题导致其不能取得很高的性能.一个问题是由于尾矩阵更新时间占比减少,行交换的网络传输的开销显得越来越大.另一个问题是通过简单使用国产加速器的异步流机制让国产处理器端的panel 分解和国产加速器端的update 并行,国产处理器与国产加速器只有很弱的并行工作的效果,大部分时间国产处理器与国产加速器都是串行执行,这造成了国产加速器大量的空闲等待时间.为了解决这两个问题,我们设计了一种国产处理器-国产加速器异构多线程细粒度流水算法.我们通过对数据依赖的分析发现尾矩阵更新与行交换在列与列之间是没有数据依赖的.受此启发,我们在列方向上对尾矩阵进行分块,如图2 所示,将完整的尾矩阵行交换和更新划分成一个个由若干NB列块组成的单元进行行交换和更新.行交换主要利用PCIe 和网络,对国产加速器的计算资源占用率不高,这样就用尾矩阵更新的计算掩盖了行交换的开销[17].在上面细粒度任务划分的基础上,我们引入了多线程多流机制来协调国产处理器与国产加速器的计算.具体来说,我们引入了4个线程,如图3 所示,thread 0 负责panel 分解和panel 广播,thread 1 负责PCIe 的数据传输,thread 2 负责行交换,thread 3 负责尾矩阵更新.thread 1 和thread 2 两个线程运行在同一个国产处理器物理核心上,thread 0 和thread 3 分别运行在其他两个国产处理器物理核心上.除线程0 外,每个线程管理各自的异步流.通过利用线程间同步和流之间的同步来协调国产处理器与国产加速器的计算,最终实现了如图3 所示的流水线.
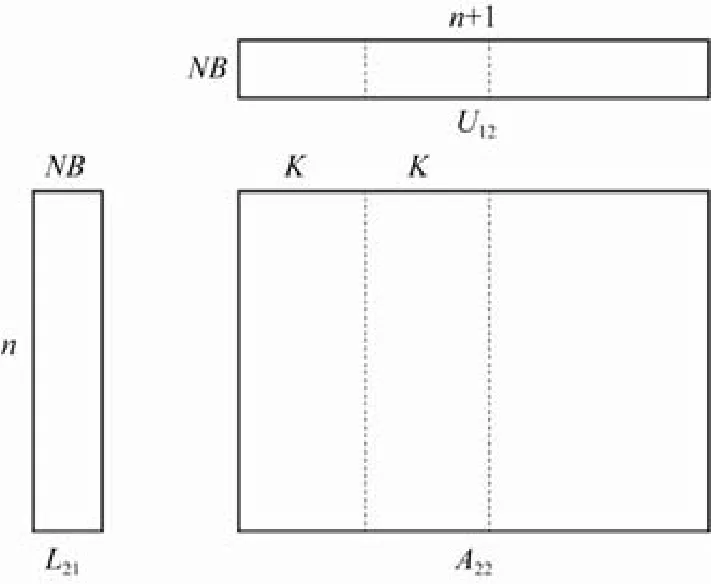
Fig.2 HPL fine-grained parallel data splitting (K is a multiple of NB)图2 HPL 细粒度并行数据划分(K 是NB 的倍数)

Fig.3 HPL multithread fine-grained parallel algorithm flow图3 HPL 多线程细粒度并行算法流程图
3.2 多线程细粒度HPL算法的实现
我们通过引入简单的生产者消费者模式来维护细粒度算法的依赖关系,以降低多线程带来的开销,实现与文献[17]中做法一致.如图4 所示,行交换生产者做完一个列块的行交换之后,生成一个更新任务放到更新任务队列里边;负责尾矩阵更新的线程作为消费者,取出更新队列里面的任务并执行,同时尾矩阵更新线程还是传输任务的生产者,在执行完一个更新任务后,生成一个传输任务放到传输任务队列里边;负责传输的线程从传输队列里取任务完成传输;负责panel分解的进程在等待自己需要的列块数据更新完成之后就可以并行开始做下一轮的panel分解[17].各个线程间利用信号量实现等待和唤醒,当任务队列为空的时候,相应线程就挂起,避免忙等待带来的开销.
异构系统的加速器有多种,比如GPU、MIC、FPGA、国产加速器等等.为了让异构HPL算法具有可移植性,能够运行在多种异构平台上,我们完成了一个轻量级的异构加速框架HPCX[17].其实现与文献[17]一致,如图5 所示,我们抽象出了异构加速平台的一些共有特性,比如内存管理,并行计算,数据传输,异步调用等等.同时我们对不同厂商的异构加速器编程模型和基础数学库进行总结,定义了一套统一的编程结构.在不同的加速器上,使用不同的编程模型(HIP、CUDA、C)实现,底层用不同的编译器编译成不同平台上的二进制程序.目前HPCX 支持国产加速器、AMD GPU 和NVIDIA GPU 以及国产处理器、Intel CPU 和AMD CPU.对于其他异构加速器,结合硬件平台给出HPCX 定义抽象接口的具体实现就可以方便整理到HPCX 框架中.异构并行HPL算法通过调用HPCX 提供的编程接口实现跨平台加速.

Fig.4 HPL producer-customer model图4 HPL生产者消费者模型

Fig.5 Heterogeneous acceleration framework HPCX图5 异构加速框架HPCX
4 性能测试与分析
我们实现了包括国产加速器和NVIDIA GPU 两种异构平台上的粗粒度版本HPL 和多线程细粒度版本HPL,在国产加速器和NVIDIA 两个平台上进行了测试.在NVIDIA 平台上,我们将我们实现的两个版本的HPL与开源成果三阶段流水线版本HPL 以及目前NVIDIA 平台上效率最高的NVIDIA 官方非开源程序nvhpl 进行了对比.在国产加速器平台上,我们在曙光E 级超算原型机的512 个节点上进行大规模扩展性测试.
4.1 实验平台简介
表2 给出了我们实验平台的信息.在两种平台上,单个节点内处理器与加速器都通过PCIe 3.0 总线连接.NVIDIA 平台上只有一个节点,配有两张P100 显卡.国产加速器平台上有多个节点,每个节点上装有一个国产加速器,节点之间采用100Gb/s 的EDR 网络连接.
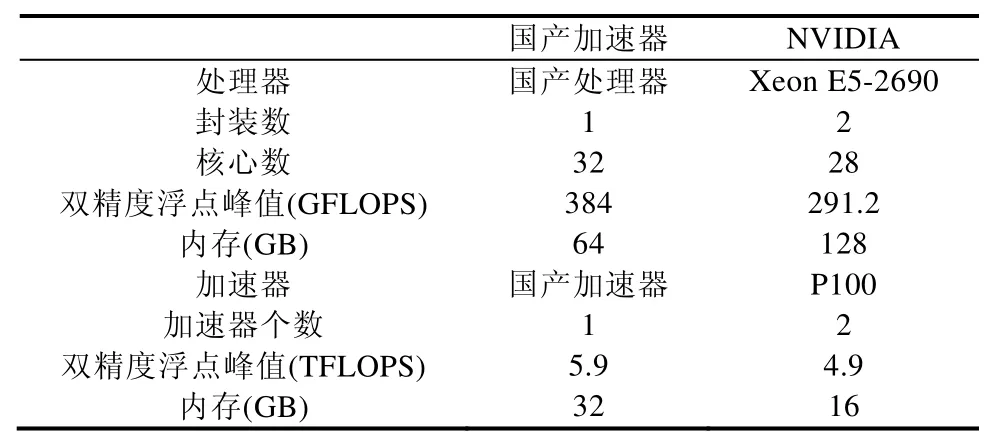
Table 2 Configuration of computing nodes表2 计算节点的配置
4.2 性能与分析
在NVIDIA 平台上的单卡测试结果如图6 所示.从图6 中我们可以看到,随着问题规模的变大,除了开源的3 阶段流水线版本HPL 的性能没有太大提高外,nvhpl 与我们实现的两个版本HPL 均有明显性能提升.出现这种情况是因为3 阶段流水线版本的HPL 的矩阵位于CPU 上,而三阶段流水线无法用加速器的计算掩盖PCIe数据传输的开销.我们可以看到,通过简单地把矩阵放到加速器内存上,粗粒度HPL 就获得了很大的性能提升,说明将矩阵置于加速器内存上是合理的.但是粗粒度HPL算法与nvhpl 相比还是有较大差距,原因是粗粒度HPL算法对加速器与处理器的并行度挖掘不够,以及忽略了行交换中网络通信开销的优化.多线程细粒度HPL算法在做完上述优化之后,性能完全超越了nvhpl 的性能,平均领先nvhpl 达9%.图7 展示了NVIDIA 平台上多卡的测试结果.由于三阶段流水线版本HPL 速度太慢,我们略去了它的多卡测试.从图7 中我们可以发现,粗粒度HPL、多线程细粒度HPL 与nvhpl 都有较好的扩展性.在多卡测试上,我们的细粒度版本HPL 依然领先nvhpl.
如图8 所示,在曙光E 级原型机的512 个节点上,我们进行了1~512 个节点的扩展性测试.从图8 中可以看出,在不同测试进程规模下,HPL 的扩展性很好,随着节点的增加HPL 的测试效率缓慢下降,从2 个节点约75%的效率下降到512 个节点约71%的效率.需要注意图中单节点效率偏低是因为单节点测试采用的NN 格式(非转置非转置)的矩阵乘,而多节点采用的NT 格式(非转置转置)的矩阵乘,前者的效率低于后者.我们实现的多线程细粒度版本HPL 最终在512 个节点上实现了HPL 实测峰值性能2.3 PFLOPS,实测效率71.1%优秀测试结果.
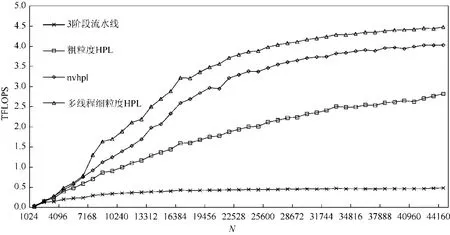
Fig.6 HPL performance on single NVIDIA GPU图6 NVIDIA GPU 单卡HPL 性能
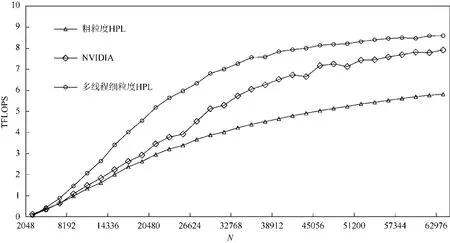
Fig.7 HPL performance on multiple NVIDIA GPUs图7 NVIDIA GPU 多卡HPL 性能

Fig.8 Sugon E-prototype supercomputer HPL performance图8 曙光E 级超算原型机HPL 性能
5 结 论
本文提出的异构HPL算法通过将矩阵存储于国产加速器的内存解决了数据传输瓶颈,通过多线程细粒度的算法软流水实现了对通信开销的掩盖,通过一个轻量级异构加速框架HPCX 提供的对国产加速器的基本操作的抽象实现了跨平台的异构HPL算法.在同类异构系统上,我们实现的算法性能远远超过开源的工作,并且优于NVIDIA 公司的非开源HPL 程序.我们的算法也展示了良好的扩展性,在曙光E 级超算原型机512 个节点HPL 测试中实现了71.1%的效率.同时,我们的性能模型也展示了较高的准确性,可以为未来E 级异构超算的HPL 性能预测提供参考.
猜你喜欢
红外技术(2022年11期)2022-11-25
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
小学教学研究(2022年5期)2022-04-28
少先队活动(2021年6期)2021-07-22
安阳工学院学报(2020年2期)2020-06-05
商周刊(2019年1期)2019-01-31
电脑知识与技术(2017年26期)2017-11-20
中国洗涤用品工业(2017年2期)2017-04-16
信息安全研究(2016年3期)2016-12-01
