
基于视听具身指称表达任务的数据集制作研究
2021-11-18 00:42王凯丽董言治
科技信息·学术版 2021年26期
关键词:目标识别
王凯丽 董言治

摘要:指称表达通常在人们寻找某个特定对象时应用广泛,机器人通过视觉和听觉的融合信息来理解指称表达指令,并执行相应的操作。针对上述任务,通过建立一个结合视听融合的指称表达的数据集,根据该数据集在真实世界中进行物体的操作,验证数据集的有效性。并且使用程序获得严格控制的指令分布,提出一种新的验证指标,以验证数据集的有效性。实验结果表明,该数据集能够有效的应用于视听具身指称表达任务,获得满意的实验结果。
关键词:视听融合 指称表达 目标识别
中图分类号:TP39 文献标志码:A
引言
为了成为人类的有效助手,机器人必须通过理解我们的物质世界,并且通过自然语言与人类进行互动。例如,“左手边的玻璃杯”、“递给我装有胶囊的瓶子”等。这些看似简单的任务需要一系列丰富的能力,包括物体识别,音频分类,机械臂抓取,跨越视觉、听觉和语言、操作领域。
近年来,已经提出很多方法,来解决人机交互的自然语言的基础问题。与传统的视觉问答任务不同,指称表达任务不仅要与语言文本进行理解,还要结合视觉信息,利用两种模态的特征进行定位预测。为了解决这个问题,现有的两阶段方法主要通过从一组候选区域内选择最优的匹配区域,首先利用传统的算法或者预先训练好的检测网络,对给定图像的显著区域提取它们的特征,之后在第二阶段进行进一步的细致推理。这类方法通常具有很高的性能,但他们耗费的计算时间较长,计算效率低下。而单阶段的方法则是主要利用目标检测领域的单阶段模型,仅从经过一次的输入图像中提取特征,然后直接预测输出区域的位置。
相比之下,我们的任务不仅仅要对物体进行简单的识别,并且需要根据操作指令的指示表达部分定位到指定物体,并且在视觉无法判断的情况下,能夠结合听觉进行探索。在现存的数据集中,并没有适合我们任务的数据集,因此,在我们的工作中,结合指称表达以实现多模态融合的任务显得十分重要。
1相关数据集介绍
近年来,很多研究进行了多次尝试来减轻VQA数据集的系统性偏差,但它们未能提供一个充分的解决方案。
与此同时,Goyal等人将VQA1.0中的大多数问题与一对相似的图片联系起来,结果是不同的答案。虽然提供了部分的缓解,但这种方法不能解决开放的问题,使他们的答案分布很大程度上不平衡。
在创建适应视听融合的指称表达任务时,我们从CLEVR任务中获得了灵感,该任务由合成图像上的合成问题组成。然而,它只有少量的对象类别和属性,使得它特别容易记忆所有组合,从而降低了其有效的组合程度。
我们的视听融合的指称表达数据集操作的是真实图像和大型语义空间,这使得它更具挑战性。尽管我们的问题不像其他VQA数据集那样自然,但它们显示了丰富的词汇和多样化的语言和语法结构[8]。
2数据集制作方法
2.1听觉数据集
在整个实验设置当中,我们设置了12类常见的对象,图1为容器内容物的展示。所有的容器形状大小颜色都是相同的,仅仅依靠视觉信息难以分别出类别,在我们的实验环境下,我们收集听觉信息来辨别物体种类。
实验物体的种类设置多元化,如图2所示,在不同的动作下,我们绘制了典型物体的波形图展示了分类的可能性。
2.2指令数据集
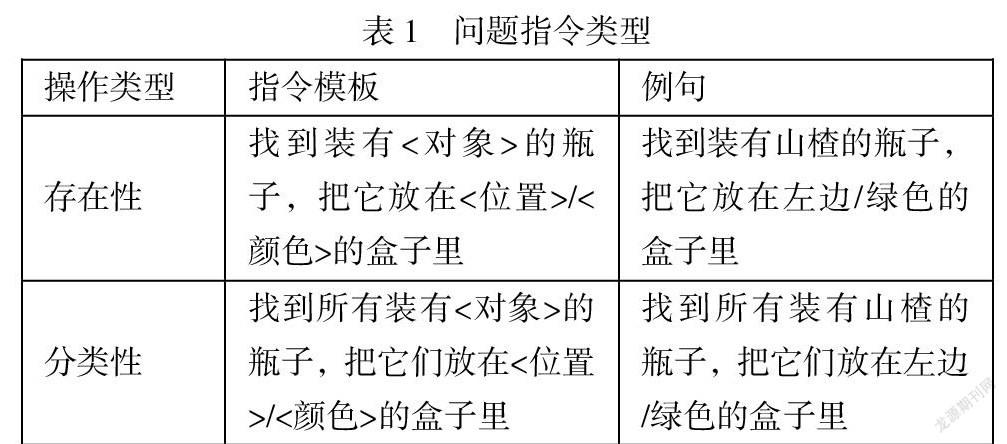
我们设计了两种类型的操作指令,其中对整个场景的位置关系的表述,以及相应的操作任务。分别为存在性指令、分类性指令,如表1所示。举例来说“找到中间的瓶子,并把它放在红色的碗中”根据这样的指令,可以找出特定的目标物体。
这些模板涵盖了各种各样的情况,需要机器人与环境之间不同程度的交互。例如,存在性指令可能需要来自机器人的一次操作就能够获得答案,因为机械臂在探索瓶子内的物体时,可能第一个探索的对象就是我们要寻找的目标物体。然而,分类性指令需要探索所有的瓶子,直到将我们分类的目标物体全部放在对应的指称表达的位置关系当中。
2.3数据集制作
对于视听融合任务指称表达的数据集的制作,我们采用数据集标注的方法进行研究。
对于听觉数据集,每个类别的物体,分别利用机械臂按照坐标轴的三个轴进行晃动以及增加一个贴合人类的晃动作用来收集声音数据。声音数据集的大小为每个类别通过不同的动作采集了400组数据,整个数据大小为4800,这样充分囊括了在实际情况下可能出现的音频。
对于指称表达模块的标注,我们采用人工标注的方法进行研究。
通过以上方法可以按照我们设计的模板来自动生成,模板包含了几个基本的函数生成器,其子函数包含了物体的位置关系、尺寸、颜色等基本属性。对应于不同的指令类别,我们根据其属性关系以及整个场景的复杂度设计了符合实际情况的指令集。存在性指令和分类性指令的大小为每个144,这部分也充分包含了实际情况下可能出现的场景和操作需求。
3验证结果
我们分别单独测试了两种数据集的实用性,对于指示表达部分,通常的指示表达模型用预先训练过的CNN来提取图像特征,利用单词编码和循环神经网络来获取操作指令的特征部分,并把它们投影到一个公共的向量空间,之后在计算它们的相似度,选择最近的候选特征框作为最终的预测结果。
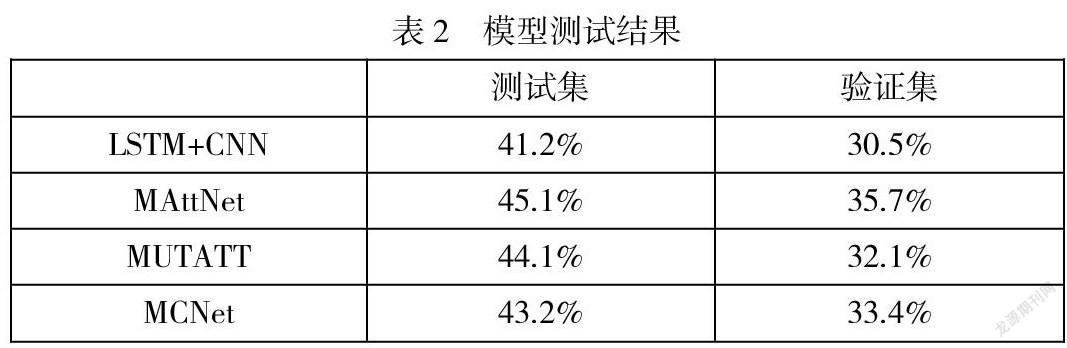
我们构建了一个类似的CNN+LSTM 的模型测试其性能,并且同样使用了最先进的模型测试我们的数据集,分别是利用了MAttNet、MUTATT、MCNet测试其整个性能。实验结果如表2所示:
实验结果表明,在最先进的模型下,我们的操作指令数据集依然能够在测试集和验证集下保持可观的准确率,这为整体视听任务提供了有效的保障。
对于音频信号,需要提取其梅尔倒谱系数(MFCC)并把它作为送入深度学习网络中的特征向量。这种预处理过程中可为整个模型提供良好的鲁棒性和识别率。
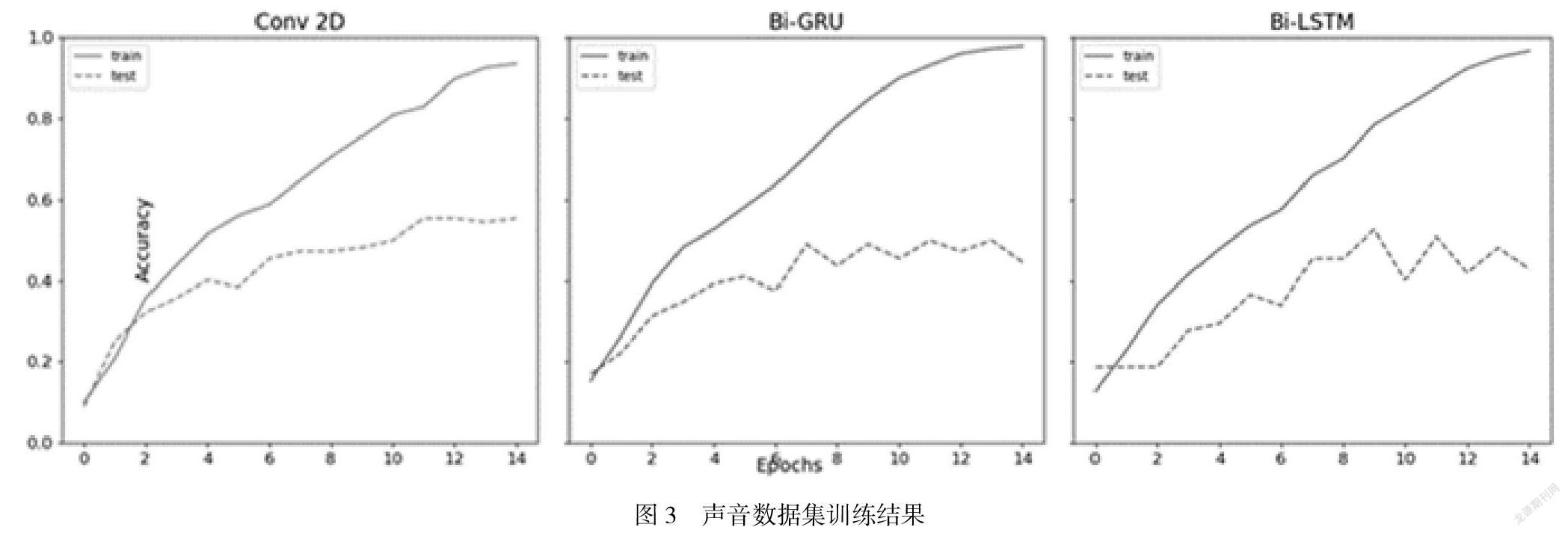
利用处理好的声音数据,我们按照4:1的比例用作训练集和测试集,我们实验对比了2D卷积网络(Conv2d),双向长短期记忆网络(Bi-LSTM),双向门控循环单元(Bi-GRU)。随着迭代次数的不断增加,我们的准确率在训练集和测试集上不断提高,训练曲线如图3所示。实验结果表面在不同的模型下,听觉数据的准确率依旧能够保持正常的水准。
4总结
在本文中,我们设计了一个新的多模态数据集来展示日常生活中的任务需求。并且我们对此数据集进行有效的分析。利用了较为先进的指示表达模型,并进行了实验评价,在听觉数据部分,我们同样利用多个模型验证其有效性。未来的工作包括为更多真实世界场景中的开发全自动视觉识别方法,并结合语言学和听觉的端对端的模型。
参考文献
[1]Michal Nazarczuk and Krystian Mikolajczyk. V2a-vision to action:Learning robotic arm actions based on vision and language. In Proceedings of the Asian Conference on Computer Vision,2020.
[2]任泽裕,王振超,柯尊旺,李哲,吾守尔·斯拉木.多模态数据融合综述[J].计算机工程与应用,2021,57(18):49-64.
[3]张康. 基于深度学习的多模态数据特征融合问题的研究[D].齐鲁工业大学,2021.
[4]丁祥武,谭佳,王梅.一种分类数据聚类算法及其高效并行实现[J].计算机应用与软件,2017,34(07):249-256.
[5]张值铭,杨德刚.基于多线程爬虫和OpenCV的人脸数据集制作方法[J].现代信息科技,2020,4(18):98-103.
[6]陈海燕,高原鼠兔图像数据集制作软件. 甘肃省,兰州理工大学,2019-11-01.
[7]李子康. 基于视听融合的导盲机器人的设计与研究[D].河北工业大学,2017.
[8]高晴晴. 基于深度学习的视听信息融合方法研究[D].河北工业大学,2016.
[9]祁艳飞. 智能机器人双传感融合技术研究[D].南京理工大学,2016.
烟台大学科技创新基金项目(YDYB2109)。
作者簡介:王凯丽,主研领域:人工智能 董言治,副教授。
猜你喜欢
数字技术与应用(2016年10期)2017-04-01
科技创新与应用(2017年6期)2017-03-23
中国新通信(2017年3期)2017-03-11
中国水运(2017年1期)2017-02-27
中国水运(2016年11期)2017-01-04
电脑知识与技术(2016年28期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
科学与财富(2016年28期)2016-10-14
现代电子技术(2014年22期)2014-11-14
