
基于生成对抗单分类网络的异常声音检测
2021-11-26 08:48薛英杰周松斌刘忆森
吉林大学学报(理学版) 2021年6期
薛英杰, 韩 威, 周松斌, 刘忆森
(1. 昆明理工大学 信息工程与自动化学院, 昆明 650504; 2. 广东省科学院智能制造研究所 广东省现代控制技术重点实验室, 广州 510070)
声音中所包含的信息与视频、图像、文字等媒介有强烈的互补性. 通过声音, 可以获得不可见、无法接触的诸多信息, 在材料内部结构探测、无损检测、日常生活等领域应用广泛, 如家禽的鸣叫声、工厂中的管路探伤、车辆行驶中的异响等. 电机、家畜等可通过主动发声判断其所处的状态, 而对于不能主动发声的物体可通过气锤敲击、电磁脉冲击打等方式使物体被动发声, 判断其是否损坏. 这种检测方法尽管具有简单有效的优点, 但也存在着方法单一、没有统一标准、过于依赖经验、不能实时监控等缺点.
异常声音检测[1]是指对与目标类声音不一致的声音识别, 近年在军事、畜牧业、工业、医学等领域已有少量相关报道. 目前, 异常声音检测的方法主要有直接观察声音时域、频域波形和通过有监督地训练神经网络模型, 利用网络模型进行异常声音检测两类方法. Jeon等[2]利用声音探测了恐怖主义等恶意目的的无人机; Du等[3]通过检测家禽夜间鸣叫声判断家禽是否处于异常状态; 李江丽等[4]为了预防生猪呼吸道传染病的传播, 通过生猪咳嗽声监测生猪的健康状态; 祁骁杰等[5]通过直接对比分析杨树木段中害虫幼虫的声音时域和频域波形检测害虫幼虫数量, 达到保护树木的目的; 王中旂等[6]通过直接观察气锤敲击石墨电极声音频谱图检测石墨电极内部是否缺损, 因为电极的缺陷处对信号具有滤波的作用, 缺损电极的频率成分比无损电极频率成分更简单; 李春雷等[7]采集了发电机正常状态声音和其他3种异常声音, 通过有监督学习的方式训练BP神经网络达到检测发电机状态的目的; 李朋湃[8]通过检测人类的心音诊断心血管疾病; 李春阳等[9]因洗衣机异常声音数据稀疏, 首先通过生成对抗网络生成大量的洗衣机异常声音, 然后使用有监督的方式训练卷积神经网络达到洗衣机异常声音检测的目的; 杨毫鸽[10]通过提取航空发动机声音的Mel频率倒谱系数(MFCC)和Gammatone频率倒谱系数(GFCC)特征作为神经网络的输入, 使用训练好的模型进行航空发动机异常声音检测.
深度学习神经网络因其强大的学习能力, 在异常声音检测中具有准确率高、误判率低、抗干扰性强的特点, 节约了人工成本, 提高了检测效率. 在已有的神经网络模型中, 自编码器是一种成熟的深度学习单分类网络方法, 其以无监督的方式学习目标数据特征, 只学习正常样本特征即可获得检测模型, 适合用于异常情况具有复杂多样性的异常检测. 相比于有监督学习训练神经网络, 自编码器网络只需正常样本数据即可完成训练, 克服了异常样本数据定义不明确、采集难等问题. 本文在自编码器神经网络方法的基础上, 并受生成对抗网络(GAN)的启发, 针对声音数据提出一种生成对抗单分类网络方法(简称网络)进行异常声音检测. 实验结果表明, 该方法在异常声音检测中准确率更高.
1 基于生成对抗单分类网络的异常声音检测方法设计
异常声音检测流程如图1所示. 其中, 生成对抗单分类网络模型是异常声音检测方法的核心. 首先利用麦克风传感器采集待测声源的正常声音数据, 对声音数据进行降噪、滤波等预处理并输入计算机, 然后由计算机中已设计好的生成对抗单分类网络进行学习和训练, 建立对正常声音特征的普遍认知. 训练完成后, 对于输入的正常声音, 网络模型以极小的误差重构正常声音; 而对于输入的异常声音, 网络模型重构效果较差, 从而可进行正常或异常的声音判断, 所给出的判断结果可用于提醒警示、实时监控、应急反馈处理等目的.

图1 异常声音检测流程Fig.1 Flow chart of abnormal sound detection
1.1 自编码器

图2 自编码器结构Fig.2 Structure of autoencoder
在深度学习方法中, 自编码器是无监督学习方法之一. 传统自编码器网络是一对相互连接的子网络[11], 包括编码器和解码器. 编码器和解码器分别由一个全连接层组成. 编码器中的全连接层将输入数据进行压缩, 提取出输入数据中最具有代表性的特征; 解码器中的全连接层将提取的特征解压, 尽可能地再现生成原始输入. 自编码器结构如图2所示.
传统自编码器编码和解码的过程可描述为
编码过程:h1=σe(W1x+b1),
(1)
解码过程:y=σd(W2h1+b2),
(2)
其中x表示自编码器的输入,h1表示编码器提取出的特征,y表示解码器重构数据, 即自编码器的输出,σe,σd表示非线性变换,W1,W2,b1,b2表示神经网络的参数, 通过优化器最小化x和y之间的重构误差获得. 重构误差ε可表示为

(3)
其中xi表示原始输入数据的第i维,yi表示生成器生成数据的第i维,n表示数据长度.
由于传统自编码器网络结构简单, 有时无法从数据中提取具有代表性的特征, 因此产生了深度自编码器和卷积自编码器. 深度自编码器类似于传统自编码器, 包含一个编码器和一个解码器, 编码器和解码器分别由多个全连接层组成: 编码器中多个全连接层共同将输入数据进行压缩, 提取数据特征; 解码器中多个全连接层根据特征再现生成原始输入. 卷积自编码器[12]也包含一个编码器和一个解码器: 编码器包括若干卷积层, 卷积层将输入的数据进行压缩, 提取输入数据特征; 解码器也包括若干卷积层, 解码器中卷积层将提取的特征进行解压, 再现生成原始输入. 此外, 为增加网络结构的稳定性, 本文在每个卷积层都进行批量归一化[13]操作.
深度自编码器和卷积自编码器常被用于异常检测领域, 目前已有许多研究结果, 如: 梁凤勤等[14]使用深度自编码器检测了油气管道是否存在异常; 蒋爱国等[15]使用深度自编码器检测了感应电机故障; 佘博等[16]使用卷积自编码器检测了机械传动部件故障; Wu等[17]使用卷积自编码进行了图像异常检测; Khalilian等[18]使用卷积自编码检测了电路板缺陷; Chen等[19]使用深度自编码器检测了网络是否异常; Ulutas等[20]使用深度自编码器检测了表面缺陷等. 利用各种自编码器进行异常检测时, 一般包含训练和检测两个过程. 首先使用正常数据训练一个自编码器, 自编码器只学习正常数据特征, 故能以较小的误差重构再现正常数据, 而检测过程中的异常数据重构误差较高. 因此可将重构误差大小作为异常检测的判断标准, 最后设置一个阈值α, 重构误差大于该阈值则为异常, 否则为正常.
1.2 生成对抗单分类网络
目前, 自编码器已成为异常检测的主要方法. 但在一些声学场景中, 由于正常和异常样本具有较大的相似性, 从而导致异常样本重构误差也较小, 因此有时无法直接利用重构误差大小区分正常和异常样本. 受生成对抗网络GAN[21]启发, 针对声音数据, 本文提出一种生成对抗单分类网络方法, 利用联合对抗方式训练卷积自编码器和卷积判别器, 用卷积判别器代替重构误差进行分类. 在联合对抗训练过程中, 卷积自编码器和卷积判别器相互博弈, 卷积判别器的判别结果反馈到卷积自编码器, 促进卷积自编码器更好地学习正常数据特征, 从而能更好地重构目标类数据. 同时, 卷积自编码器的重构数据输入卷积判别器, 促进卷积判别器更好地学习正常数据特征, 提高卷积判别器的判别能力. 网络整体框架如图3所示, 其中: 卷积自编码器相当于生成对抗网络中生成器G; 卷积判别器的结构是一系列卷积层, 其被训练以最终区分异常声音样本, 相当于生成对抗网络中的判别器D, 使用正常样本训练生成器G和判别器D, 同时使用生成器G重构的数据训练判别器D.将判别器D来自真实正常样本的输入标注为1, 并将来自生成器G重构数据的输入标注为0, 则判别器D的输出结果为0~1之间的数值, 表示其输入所遵循目标类数据特征分布的可能性. 判别器D的目标是实现对数据来源的二分类判别: 真(来源于真实正常样本)或假(来源于生成器G重构数据); 生成器G的目标是自己重构的数据能成功欺骗判别器D, 即判别器D将生成器G重构数据判别为真.
神经网络的训练过程是优化器优化训练损失值的过程, 根据训练数据进入网络输出的结果和定义好的损失函数求出训练损失值, 优化器会根据训练损失值更新网络参数, 经过多次迭代训练后, 网络便可输出预期的结果. 生成对抗单分类网络目标函数[21]为

(4)
其中G为生成器,D为判别器,x为训练声音样本,G(x)为生成器生成的样本,D(x)表示判别器判断x为真的概率,D(G(x)))表示判别器判断生成器G生成的样本为真的概率,Ex~pdata(x)表示按pdata(x)的分布对x求期望. 判别器D的目的是使式(4)最大, 即第一项和第二项都要最大. 第一项最大是D(x)接近于1, 即真实数据进入判别器输出接近于1. 而第二项最大, 需要D(G(x))接近于0, 即生成器G重构的样本进入判别器输出接近于0. 而生成器G的目的是使式(4)最小, 即第一项和第二项都最小.
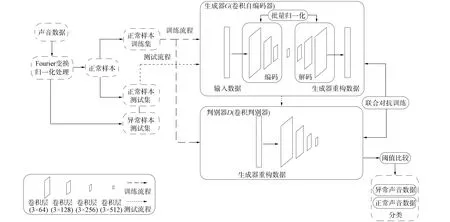
图3 网络整体框架Fig.3 Overall framework of network
当生成器G能重构正常训练样本时, 停止训练. 此时生成器G以较小的误差重构其输入(即(X-X′)2<ρ,ρ为一个很小的正数,X′为生成器G输出数据). 网络训练完成后, 生成器G能重构正常样本, 正常样本X输入生成器G输出X′,X′服从正常样本的特征分布. 由于生成器G未学习异常样本特征分布, 因此异常样本X*输入生成器G输出一个具有未知分布的(X*)′, 重构效果较差, 在某些频率波段, 重构的样本会发生畸变. 判别器D也学习了正常样本的特征, 故重构的正常样本输入判别器D输出的结果比阈值大, 而重构的异常样本输入判别器D输出的结果比阈值小. 与原始样本相比, 判别器D可以更好地区分经过生成器G输出的数据.
2 实 验
为验证生成对抗单分类网络的有效性, 本文使用UrbanSound8K公开数据集作为标准数据输入网络进行正确性检验. 在此基础上, 对实验室采集的吹风机电机数据集进行实际测试. 所有Python程序都使用Quardro RTX5000显卡运行.
按图3所示的程序框架结构, 对所有输入程序的声音数据首先进行Fourier变换, 得到其频谱数据. 为提高模型收敛速度、模型精度并防止模型梯度爆炸, 对频谱数据进行如下必要的归一化处理:
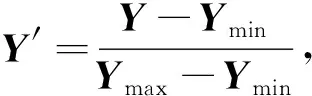
(5)
其中Y表示原始数据,Y′表示归一化后的数据,Ymax表示Y中的最大值,Ymin表示Y中的最小值. 以归一化后的声音频谱数据对卷积自编码器和卷积判别器组成的生成对抗单分类网络进行训练, 直至重构误差趋于稳定结束训练. 待测试的声音数据同样经过归一化Fourier变换后, 输入卷积自编码器, 对输出的重构数据由卷积判别器进行阈值判别, 即可得到正常或异常的声音分类. 本文对网络判别结果与真实值进行比较并统计, 得到4种分类结果: 正常类被正确判别(TP), 正常类被错误判别(FN), 异常类被错误判别(FP), 异常类被正确判别(TN). 由此可定义精准率、召回率、准确率和误警率等指标参数: 精准率(Precision)是指测试结果为正常的数据中识别正确的比例,
Precision=TP/(TP+FP);
召回率(Recall)是指真实为正常的数据中识别正确的比例,
Recall=TP/(TP+FN);
误警率(false alarm rate, FAR)是指正常类被判别为异常类的样本个数占真实类别为正常样本总数的比例,
FAR=FN/(TP+FN);
准确率(Accuracy)是指所有测试样本被正确识别的比例,
Accuracy=(TP+TN)/(TP+TN+FP+FN).
2.1 UrbanSound8K数据集
UrbanSound8K数据集是由美国纽约大学音乐与音频实验室收集的声音数据, 共包括10类声音. 本文选择空调正常运行声音和机器空转声音两种最相似的声音进行检验测试. 空调正常运行声音作为正常样本, 机器空转声音作为异常样本. 空调声音和机器声音时长均为3 s, 将其切割成1 s的片段. 其中3 200个空调声音样本作为训练数据, 388个空调声音样本和400个机器声音样本作为测试数据. 测试数据频谱和生成器输出频谱如图4所示. 其中空调正常运行声音(图4(A))作为正常声音样本, 生成器能以很小的误差重构出测试空调声音的频谱(图4(B)), 重构谱图与原始谱图有非常高的相似度. 而机器空转声音(图4(C))作为异常声音, 生成器重构出的频谱(图4(D))约在500 Hz和1 000 Hz出现畸变, 重构效果较差, 重构谱图与原始谱图有明显区别. 生成器生成的样本继续输入判别器进行最终判别.

图4 UrbanSound8K数据集的测试样本频谱和生成器输出频谱Fig.4 Test sample spectra of UrbanSound8K data set and output spectra of generator
使用主流的深度自编码、卷积自编码方法及生成对抗单分类网络, 对完全相同的原始声音数据进行学习和测试, 统计结果列于表1. 由表1可见: 本文生成对抗单分类方法优于其他两种方法, 在精确率、召回率、误警率和准确率等参数指标上有明显提高; 单独使用训练好的判别器进行测试时, 准确率和精确率也高于其他两种方法. 当将生成器和判别器联合使用时, 准确率得到进一步提高, 生成器修改了输入样本, 提高了判别器的区分能力. 对比分析表明, 本文的网络方法在准确率等所有参数指标上均优于已有方法, 相比于卷积自编码器方法, 生成对抗单分类网络在UrbanSound8K公开数据集实验结果准确率提高了5.0%. 证明了本文方法的有效性.

表1 UrbanSound8K数据集检测结果
2.2 电机数据
下面将本文方法用于电机异常声音的检测. 实验室采集吹风机电机声音数据, 采样频率为48 kHz, 采集正常电机声音样本6 000个(其中5 000个作为训练数据, 1 000个作为测试数据), 异常电机声音样本1 000个. 测试数据频谱和生成器输出频谱如图5所示. 相比于图4(A), 尽管吹风机电机声音具有更丰富的频谱分布, 生成器仍能以较小的误差(2.0×10-3)重构出测试电机正常声音频谱, 表明本文网络方法具有较好的频谱分布适应性. 而对于电机异常声音频谱, 生成器重构出的频谱在约1 500 Hz和2 100 Hz出现畸变, 与原始谱差异明显, 重构效果较差. 本文对网络判别分类结果进行统计, 并与深度自编码、卷积自编码方法相比较, 结果列于表2. 由表2可见, 卷积自编码器方法擅长于学习正常声音特征, 但判别准确率相对较低, 实际使用中易发生误报的情形; 而相比于卷积自编码器方法, 生成对抗单分类网络, 在牺牲1.1%的精确率前提下, 准确率得到进一步提高, 在电机数据集实验结果中准确率提高了3.0%, 表明该方法具有频谱分布适应性好、判别准确率高的特点.

图5 电机测试样本频谱和生成器输出频谱Fig.5 Spectra of motor test sample and output spectra of generator

表2 电机数据集检测结果
2.3 实验结果分析
对于本文方法, 何时停止训练网络至关重要, 过早停止, 会导致生成器不能重构正常样本; 过度训练, 可能会导致异常样本输入生成器时, 生成的数据中包含大量的正常样本特征, 影响判别结果. 重构误差拟合公式为
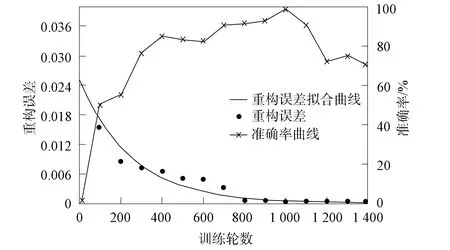
图6 电机训练数据重构误差和测试数据准确率Fig.6 Reconstruction error of motor training data and accuracy of test data
Y=a×exp{b×X},
其中a=0.025 12,b=-0.003 905,Y表示重构误差,X表示训练轮数. 电机训练样本重构误差和准确率如图6所示. 由图6可见: 随着训练轮数X的增加, 重构误差值Y呈现出单调递减并趋于稳定的规律, 当X=1 000时, 重构误差趋于稳定, 此时应停止训练; 当X<1 000时, 生成器和判别器都在不断学习正常样本特征, 测试样本准确率越来越高, 呈现阶梯状上升趋势, 符合一般学习规律; 当X>1 000时, 生成器过度训练, 异常样本输入生成器, 生成的数据包含大量的正常样本特征, 判别器无法区分出异常样本, 导致准确率降低.
综上所述, 本文提出了一种生成对抗单分类网络的异常声音检测方法, 联合对抗训练生成器G(卷积自编码器)和判别器D(卷积判别器), 训练完成后, 生成器G能以较小的误差重构正常样本, 而异常样本重构效果较差. 判别器D在生成对抗博弈中, 学习得到正常样本分布, 因此能对正常声音与异常声音重构信号输出不同的判别结果, 从而成功实现对异常声音的检测. 真实电机声音数据集和UrbanSound8K数据集的实验结果表明, 本文提出的生成对抗单分类网络检测准确率高于深度自编码器和卷积自编码器, 具有适用于所有物体异常声音检测、声音频谱适应性好、误警率低、准确率和精确率高、可在线可实时监控的优点.
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
空间科学学报(2021年6期)2021-03-09
知识经济·中国直销(2018年12期)2018-12-29
测控技术(2018年7期)2018-12-09
成都信息工程大学学报(2018年3期)2018-08-29
商周刊(2017年6期)2017-08-22
西安工程大学学报(2016年6期)2017-01-15
电测与仪表(2014年13期)2014-04-04
