
基于动态命令树算法的软件老化趋势预测方法
2021-12-10 08:31陈晓璠邓砚谷
计算机仿真 2021年11期
陈晓璠,邓砚谷
(南昌航空大学,江西南昌330063)
1 引言
计算机系统的功能日益强大,软件系统的复杂性也逐渐凸显,软件系统的维护难度逐渐增大,与软件有关的程序失效问题层出不穷,而人们对计算机系统软件应用的可靠性需求并未降低,反而逐渐增多。目前军事国防、金融、通信等领域均离不开计算机系统,若计算机不能长时间稳定运行,在一定程度上对社会经济存在不可忽视的影响。
计算机系统中软件老化可理解为服务器软件在长时间工作后,性能出现衰退。大部分人认为老化仅出现于计算机硬件系统里,但针对软件来讲,软件老化问题已不少见[1]。一个软件工作后,伴随时间的积累,软件内部潜藏的缺陷将逐渐凸显,致使软件系统性能老化。通俗来讲,软件系统使用时间较长后,系统资源将出现明显耗损,服务速度、服务质量也大大降低。为此,软件老化趋势预测,能够为软件系统失效起到决定性作用。文献[2]与文献[3]的研究人员均对软件缺陷问题进行研究,分别提出了半监督集成跨项目软件缺陷预测方法、融合多策略特征筛选的跨项目软件缺陷预测方法,可对软件缺陷进行准确预测,但未曾考虑到软件老化的动态性,仅可以识别软件缺陷模式,未能对缺陷模式下的老化趋势进行准确预测。为此,提出基于动态命令树算法的软件老化趋势预测方法,该方法与同类方法的差异在于使用动态命令树算法优化软件老化预测效果,可动态预测软件老化趋势,这对软件系统维护存在十分重要的意义。
2 基于动态命令树算法的软件老化趋势预测方法
2.1 降噪自编码器与混合趋势粒子滤波的软件老化趋势预测方法
考虑传统粒子滤波方法的状态方程具有单一性,未能适应动态的软件老化趋势,且在软件老化趋势预测过程中,对软件老化特征的提取必须根据经验判断,训练过程需要大量软件老化数据,应用成本较多[4]。为此,本文使用基于降噪自编码器与混合趋势粒子滤波的软件老化趋势预测方法,克服上述问题。
2.1.1 混合轨迹粒子滤波
本文使用混合轨迹粒子滤波方法,通过最小二乘拟合最新阶段软件老化观测值,选取当中拟合误差平方和最低的函数设成粒子滤波的状态方程,此方法能够伴随软件老化趋势的变化而自主变化粒子滤波状态方程[5-6]。
混合轨迹粒子滤波方法原理如图1所示。
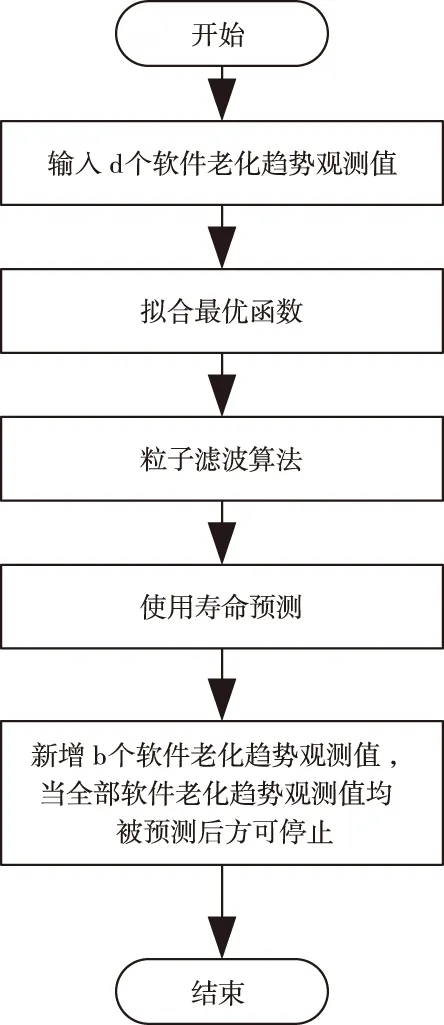
图1 混合轨迹粒子滤波方法原理
如图1所示,混合轨迹粒子滤波方法应用步骤是:
步骤一:初始化软件老化趋势预测数据特征数目j=1;
步骤二:输入d个软件老化趋势观测值,使用最小二乘方法拟合多个老化趋势种类函数,运算获取平方误差与最小函数并设成粒子滤波状态方程;
步骤三:通过粒子滤波算法对状态方程时变参数实施优化,判断软件老化趋势,设置阈值运算软件剩下应用寿命[7];
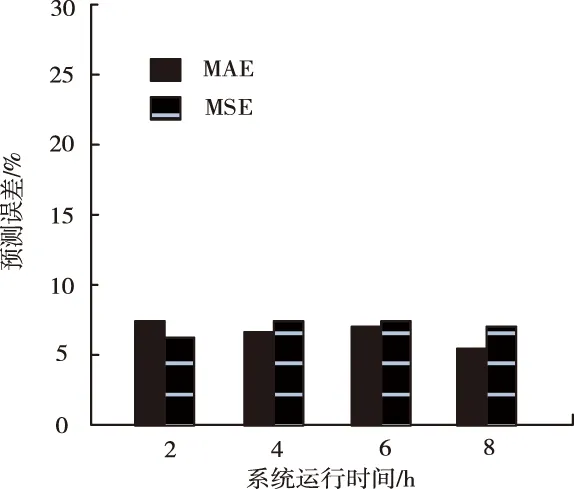
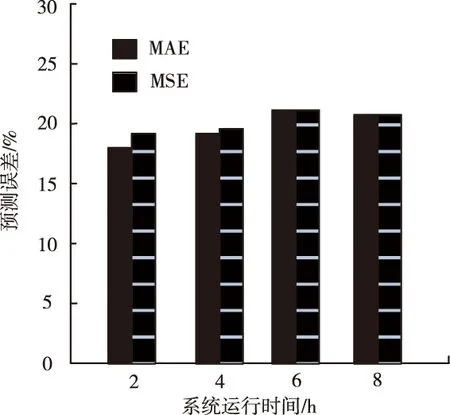
步骤四:增多b个软件老化趋势观测值(b 图中使用的拟合函数是 rt+1=β1rt+β2 (1) 式中,rt表示t时刻的软件状态值;rt+1表示h+1时刻的软件状态值;βn表示状态函数参数。 2.1.2 特征提取 在实施降噪自编码器训练时,对软件老化特征的归一化十分重要,归一化后的软件老化数据能够优化降噪自编码器的学习效率,优化降噪自编码器的学习准确性[8]。所以,本文扩展频域能量占比,实现软件老化特征的归一化,将归一化后的软件老化数据设成降噪自编码器的输入,扩展频域能量占比的方法是 (2) 式中,软件老化趋势预测数据的频谱与特征数目是v(g);软件老化趋势预测数据的频域区间宽度与频谱能量占比的扩展系数是h;频谱能量占比的偏置系数是δ。 预测实际软件老化趋势时,可能会存在软件老化趋势预测数据样本数量低于软件老化特征数量的问题,此时训练过程将出现过拟合问题,所以,需要在有限的训练样本里导入噪声扩展训练样本,以此抑制过拟合问题[9-10]。 2.1.3 降噪自编码验证集误差提取 在软件全寿命周期里均匀采集并提取软件老化数据特征样本,将软件老化特征样本集合设成Q。训练时,把样本集合Q导入噪声后设成训练样本和测试样本,最小化代价函数,以此实现软件老化特征重构。 在预测软件老化趋势时,使用训练完毕的降噪自编码器运算测试样本P的各个输入和输出的重构误差DV,把它设成描述软件老化趋势的观测值。DV可使用重构值φ和原始特征值φ运算获取 (3) 由于正常情况下,软件老化特征在训练完毕的自编码器里重构误差较小,伴随软件老化程度变大,获取的软件老化特征样本和软件未老化样本差异也日益变大,此时DV也开始变大。DV属于一种单一曲线,所以仅需要获取软件完全老化时的重构误差阈值便能够使用混合轨迹粒子滤波方法实施软件老化趋势预测。此方法能够降低训练过程里采集的软件老化特征数据量,训练成本变小,训练效率变高。 2.1.4 预测流程 降噪自编码器与混合趋势粒子滤波的软件老化趋势预测方法的预测流程图如图2所示。 图2 降噪自编码器与混合趋势粒子滤波的软件老化趋势预测方法流程图 综上所述,基于降噪自编码器与混合趋势粒子滤波的软件老化趋势预测方法的步骤是: 步骤一:训练软件老化趋势预测样本:采集软件老化数据,得到软件在没有出现老化时的数据特征,导入高斯噪声,增多训练样本数目; 步骤二:训练降噪自编码器,提取阈值:设定网络结构参数,建立降噪自编码器神经网络。将训练样本输入至降噪自编码器神经网络中,代价函数实施最小化,按照测试样本调节降噪自编码器神经网络的超参数,完成训练集特征重构。把软件完全老化的数据特征输入训练完毕的降噪自编码器神经网络之中,获取软件老化阈值; 步骤三:软件老化数据特征重构误差获取。把软件老化数据特征输入到降噪自编码器神经网络,得到重构误差; 步骤四:软件老化趋势预测。把重构误差进行平滑处理后,设成观测值分别输入的混合趋势粒子滤波算法里,实施软件老化趋势预测。 因预测软件老化趋势时,软件老化趋势数据具有动态性,软件老化趋势预测样本也存在变化,前一阶段的数据样本将不适用于后一阶段的预测任务,为此,预测指令也分为新增、重写、去除等。为实现高精度的软件老化趋势预测,本小节使用基于动态命令树算法的软件老化趋势预测命令管理方法,优化管理软件老化趋势预测命令,实现软件老化趋势预测效果优化。 2.2.1 动态命令树的构建 在软件老化趋势预测时,使用动态命令树合理的组织与管理预测命令,动态命令树结构中包含双向链表、多个平衡二叉子树链表,其可以在软件老化趋势预测命令中动态变化预测指令,且应用效率显著。存储结构如图3所示。 图3 动态命令树结构示意图 双向链表是按照软件老化趋势预测命令集中命令行的命令关键字而建立的,软件老化趋势预测命令集里相应的命令域,是链表里各个结点所存储的数据信息,且各个结点具有相应的命令行处理入口,此入口与二级链表存在连接性[11]。软件老化趋势预测命令建立后,需要先根据命令关键字,检索双向链表定位至相应的结点,然后在此节点入口位置进入相应的平衡二叉子树里,实施第二次定位,获取匹配节点,此节点相应的位置即为命令行管理的位置。 动态命令树双向链表结点的存储结构分为四部分,第一部分是软件老化趋势预测命令行节点属性结构入口指针;第二部分是孩子结点指针;第三部分是前驱结点指针;第四部分是后继节点指针。软件老化趋势预测命令行节点属性结构入口指针可存储命令行记录,其属于动态命令树执行命令的凭据。孩子结点指针指向命令处理的入口地址;前驱结点指针、后继节点指针依次指向节点的前驱和后继,可较好的管理双向链表。 使用双向链表结点数据建立软件老化趋势预测命令树时,双向链表是按照软件老化趋势预测命令关键字顺序构建,若双向链表里某结点的命令关键字和软件老化趋势预测命令行的关键词一致,便把相应操作变换至此结点相应的子树中。软件老化趋势预测命令行节点属性的结构分为命令关键字、命令参数掩码值、命令属性R/A、命令优先级。 命令关键字即为软件老化趋势预测命令的首个关键字;命令参数掩码值为除了命令关键词之外全部参数关键字大小对比值;命令属性R/A与命令行管理存在直接联系;命令优先级是软件老化趋势预测命令的先后顺序,命令集里命令行记录均根据结点模式保存在双向链表里。 2.2.2 动态命令树算法 为优化动态命令树算法效率,让它可以高效的更新软件老化趋势预测命令信息,把平衡二叉树设计为动态命令树的形式[12]。在动态命令树双向链表里检索获取命令行的命令关键字所匹配的结点信息域后,将此匹配节点设成入口,进入平衡二叉树,然后将输入的软件老化趋势预测命令信息按照具体情况实施新增、重写或去除等管理。 针对软件老化趋势预测命令重写问题,可在双链表中操作,其不存在结点空间释放情况。例如针对软件老化趋势预测命令新增问题,需要融合双向链表与平衡二茬子树链表的双向应用,不论是新增或去除,使用递归搜索模式便可获取最合适的操作位置。 在软件老化趋势预测命令管理中,若软件老化趋势预测命令在平衡二叉子树里,便表示此命令已存在,直接进行编辑处理即可。若没软件老化趋势预测命令不在平衡二叉子树里,变需要在此树中实施新增处理。 使用动态命令树算法管理软件老化趋势预测命令,能够降低命令行的对比次数,提高命令查询效率,优化软件老化趋势的动态预测效果。 实验在Linux系统中设计应用服务器,由于Linux系统稳定性与安全性显著,且使用性能较好。目前很多企业服务器都把自家企业的服务设置在Linux系统中。实验里本文使用的Linux系统处理器核数是4核,网站服务器使用Tomcat服务器,Tomcat服务器是一种轻量级应用服务器,可独立运行。为模拟软件老化过程,使用压力测试工具siege模拟,实验环境使用的工具信息如表1所示。 表1 实验环境使用工具 在体现软件老化趋势的多个指标里,内存使用是核心指标之一。所以把内存设成软件老化特征,使用本文方法预测内存衰退趋势,实现软件老化趋势预测。Linux操作系统长时间使用后,内存损耗将逐渐严重,每日需要重启4次以上,可用内存的日变化详情如图4所示。 图4 可用内存的日变化详情 使用本文方法预测Linux操作系统内存衰退趋势,实现Linux操作系统软件老化趋势预测。使用平均绝对误差、均方误差评价本文方法对Linux操作系统软件老化趋势预测效果,平均绝对误差MAE、均方误差MSE的表达式如下式所示 (4) (5) 式中,m是软件老化特征数;i是软件老化趋势预测次数;o1、o2依次是实际值与预测值。 使用文献[2]提出的半监督集成跨项目软件缺陷预测方法、文献[3]提出的融合多策略特征筛选的跨项目软件缺陷预测方法作为对比方法,以此评价本文方法的预测效果。三种方法的预测效果如图5、图6、图7所示。 图5 本文方法预测效果 图6 文献[2]方法预测效果 图7 文献[3]方法预测效果 对比图5、图6、图7可知,三种方法对Linux操作系统内存衰退趋势的预测效果存在明显差异,本文方法预测结果的平均绝对误差、均方误差小于0.04,半监督集成跨项目软件缺陷预测方法、融合多策略特征筛选的跨项目软件缺陷预测方法预测结果的平均绝对误差、均方误差都大于本文方法,表示本文方法对Linux操作系统内存衰退趋势的预测和实际值偏离较小,精确度较高,软件老化趋势预测效果更好。 测试本文方法中基于动态命令树算法的软件老化趋势预测命令管理方法的使用价值,此方法使用价值主要通过软件老化趋势预测指令的新增、重写、去除三种指令管理效果体现。将软件老化趋势预测指令的数目依次设成5个、10个、15个、20个,测试在使用基于动态命令树算法的软件老化趋势预测命令管理方法前后,软件老化趋势指令新增、重写、去除三种指令操作的响应耗时,结果如图8、图9、图10所示。 图8 新增指令 图9 重写指令 图10 去除指令 分析图8、图9、图10可知,在使用基于动态命令树算法的软件老化趋势预测命令管理方法前后,新增、重写、去除三种指令响应耗时都存在一些变化,在未使用基于动态命令树算法的软件老化趋势预测命令管理方法之前,新增、重写、去除三种指令响应耗时超过300ms,虽然响应耗时不显著,但是和使用基于动态命令树算法的软件老化趋势预测命令管理方法相比,响应耗时较多。使用基于动态命令树算法的软件老化趋势预测命令管理方法后,新增、重写、去除三种指令响应耗时低于200ms,响应速度较快,指令管理效率高,这对软件老化趋势预测效率存在积极影响,可提升本文方法对软件老化趋势预测效果。 为预测软件老化趋势,提出基于动态命令树算法的软件老化趋势预测方法。本文方法和同类软件老化趋势预测方法的差异在于本文方法中使用基于动态命令树算法的软件老化趋势预测命令管理方法,动态管理软件老化趋势预测指令,可实现软件老化趋势预测阶段性指令管理,提升软件老化预测效率。 在实验中,证明了本文方法可以高精度的预测软件老化趋势,比半监督集成跨项目软件缺陷预测方法、融合多策略特征筛选的跨项目软件缺陷预测方法的使用效果更佳,并且本文方法中,基于动态命令树算法的软件老化趋势预测命令管理方法的使用,可大大提升软件老化趋势预测指令管理效率。


2.2 基于动态命令树算法的软件老化趋势预测命令管理方法

3 实验分析



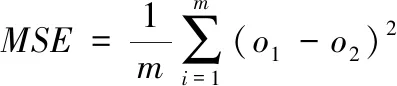




4 结论
猜你喜欢
艺术生活-福州大学厦门工艺美术学院学报(2022年4期)2022-09-22
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年10期)2022-08-22
舰船电子工程(2022年6期)2022-08-02
数字技术与应用(2021年1期)2021-03-24
计算机应用(2016年10期)2017-05-12
科技与创新(2017年5期)2017-03-28
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
Coco薇(2016年2期)2016-03-22
