
多尺度分割与特征优选下的盐碱地提取
2022-02-06 06:35国巧真吴正鹏吴欢欢何云海
地球环境学报 2022年6期
朱 丽,国巧真*,吴正鹏,吴欢欢,何云海
1.天津城建大学 地质与测绘学院,天津 300384
2.天津市测绘院有限公司,天津 300381
盐碱地是盐土和碱土的总称,其形成的根本原因是土壤中水盐失衡导致盐分在土壤表面移动与积累(翁永玲和宫鹏,2006)。盐碱地的碱性性质会抑制甚至危害作物的生长发育,因此盐碱地的存在会造成粮食减产、土壤退化等问题,严重制约经济和生态环境的发展。盐碱地作为潜在的土地资源,对其进行监测与改良,对于缓解土地资源紧张、挖掘农业发展潜力具有重要意义。
传统的盐碱地监测主要采用实地土壤调查取样的方法,通过分析土壤各组分含量来验证土壤类型,其精度较高,但在大范围区域监测中,该方法需要消耗大量的社会资源且及时性不强,实现实时动态监测存在一定的困难。随着空间信息技术的不断发展,国内外已经开始广泛利用影像数据如 Landsat、QuickBird、SPOT、IKONOS、GF-1等对土地的盐渍化信息进行提取,以此提高土地盐渍化的监测效率(Elnaggar and Noller,2009;Ivits et al,2013;Allbed et al,2014;Sidike et al,2014;牛增懿等,2016)。由于高空间分辨率遥感影像包含了更丰富的地物信息,因此选择合适的图像分割算法能够提高目标识别的精确度和稳健性(高仁强等,2020)。随着影像分辨率的不断提高和影像特征的不断增加,传统的图像分割方法如阈值分割、区域合成、边缘检测等方法也在不断发展,分形网络演化算法(FNEA)作为一种基于区域合成的多尺度分割算法,能综合考虑地物之间的光谱、纹理信息等特征差异,目前已被广泛运用于图像分割中。
从20世纪80年代至今,国内外针对盐碱地的提取方法研究也在不断发展,决策树、支持向量机、神经网络、随机森林等机器学习方法也普遍用于盐碱地信息的提取和反演(李晋等,2014;姜红等,2017;徐存东等,2018;Jiang et al,2019;Wang et al,2019;杨练兵等,2021),随机森林作为一种并行的集成学习算法,在决策树的基础上进行集成,突破了单分类器的性能提升瓶颈,各个树之间的独立运行让它可以在高维数据上实现并行处理,但其在高维数据上性能仍有提升空间(王奕森和夏树涛,2018)。Rodríguez et al(2006)通过主成分变换(PCA)对随机森林的特征进行降维,但使用该方法时只保留了主成分值较大的值,一些主成分值小但相关性强的特征会被过滤掉。还有学者通过构建特征子空间来优化随机森林,主要思想都是通过分析特征的信息量和相互关系来构建算法(Amaratunga et al,2008;Ye et al,2013)。盐碱地信息由于受到季节变化、土壤湿度等影响,利用机器学习需要充分考虑盐碱地的信息复杂性,需结合盐碱地的形状、纹理等特征,但当特征维数过大,会造成数据冗余和无关特征的增加,反而会导致机器学习能力下降,也会使得分类精度降低(Cui et al,2020),因此在机器学习前需进行特征优选,进而提高机器学习的分类性能。目前特征优选在干旱区精细植被分类、沙化土地识别、湿地分类等方向皆有所应用,而在盐碱地提取方向,仍需要进一步的研究(李长龙等,2015;张磊等,2019;张文博等,2021)。
本文基于GF-6多光谱影像数据,利用分形网络演化算法(FNEA)对影像对象进行多尺度分割,针对多维数和数据不平衡问题,使用数据挖掘中的经典算法 —— CFS算法与Relief F算法进行数据降维,精简特征子集,再利用这两种特征优选算法对面向对象的随机森林算法进行优化。
1 研究区概况及数据源
1.1 研究区概况
研究区位于天津市滨海新区东北部,位置范围北纬38°40′ — 39°00′,东经117°20′ — 118°00′。天津市北面区域紧邻燕山山脉,山区南部与华北平原地区相连,自此至东南区域地势总体上平缓,海拔在8 m以下,一般处于3 — 5 m。滨海新区濒临渤海,处于海陆交接处,多年以来受海水浸渍土壤,在温带季风气候影响下,年降水量在500 mm左右,而年蒸发量达到降水量的4倍(杨晓潇等,2019),因此导致该地区土壤的浅层不断积累盐分,从而形成盐渍化土壤。其次,工业化的迅速发展、农业耕作中不合理的灌溉方式也在加重该区域的土壤盐渍化程度。由于土壤含盐量高,肥力低,区域正常植被生长受到抑制,多生长碱蓬(Suaeda glauca)、柽柳(Tamarix chinensis)等盐生植物。本文选择研究区域位于滨海新区北大港水库附近,研究区大小为1500× 1500个像元,研究区内主要包含的土地利用类型为裸露盐碱地、盐生植被、建筑区、道路、水体等地物,土地盐渍化程度不均匀,土壤环境复杂。
1.2 数据源
研究区采用的数据源为高分六号PMS多光谱波段数据,主要参数如表1所示。研究区遥感影像获取时间为2019年9月30日,处于夏季旱期,植被生长旺盛,日照强烈,降水少且蒸发量大,在盐碱地形成过程中正处于脱盐末期,较适合对其进行提取。

表1 高分六号主要参数Tab.1 Main parameters of GF-6
2 研究方法
2.1 多尺度分割
高空间分辨率遥感影像的优势在于展现地物丰富的形态特征,对于小目标的识别能力也更强,利用传统基于像元的分类方法往往会造成空间数据的冗余,产生椒盐图像,进而降低分类效果。本文选取面向对象方法,其基本思想是通过综合分析不同对象在特征和属性上的差异,将具有相同特质的像元归为一个研究对象。面向对象的分类方法过程主要包含影像分割、影像对象构建、分类规则的建立、信息提取(陈云浩等,2006)。
影像分割是面向对象分类方法中关键的过程之一,其分割尺度的确定对影像分类精度有直接影响。本文利用一种基于区域生长的多尺度分割算法 —— 分形网络演化算法(FNEA)进行图像分割,该算法通过将影像对象间的平均异质性(average heterogeneity)最小化,并将其各自的同质性(homogeneity)最大化,综合考虑影像的光谱和空间纹理信息,基于成对区域合并技术进行自下而上的影像对象合并(Benz et al,2004)。该算法中异质性由光谱异质性与形状异质性共同决定,其中形状异质性又由紧致度与光滑度两部分组成。FNEA算法(张萌,2019)如下:

式中:H为异质性值;ω为光谱异质性值的权重;Hcolor为光谱异质性值;Hshape为形状异质性值;ωn为某一波段权重;σn为某一波段的像元标准差;Hsmooth为光滑度;Hcompact为紧致度。
不同的地物类型,由于各自的属性特征,在不同分割尺度上有不同的分割效果,因此本文利用ESP(estimation of scale parameter)尺度评价工具进行盐碱地的最优尺度选择,多尺度分割中的尺度参数需要进行多次人为调试,而ESP则通过计算不同分割尺度下影像对象的局部变化(local variance,LV),通过变化率(rate of change,ROC)峰值来确定适宜的分割尺度,来消除人工调试的主观因素影响(Drǎguţ et al,2010)。由于影像中存在多种地物,通过计算得到的ROC峰值一般也不止1个,针对出现的若干分割尺度,需要进行试验确定地物对应的分割尺度。
2.2 特征选择
Relief F算法是Kononenko et al(1997)在只适用于处理二分类问题的Relief算法上进行改进的支持多分类的数据分析方法。作为数据挖掘中经典的Filter算法,其基本思想是对每一个特征进行评价,根据每一个特征与已定义样本类别的相关性,赋予特征权重,每个特征的权重是通过在样本集D中随机选择一个样本S,计算样本S特征值与同类的其他特征值的k个最近邻距离与不同类样本的k个最近邻距离,通过循环迭代M次,类别相关性高的特征将会赋予高的权重。权重计算公式(何牧宇和周晖,2019)如下:
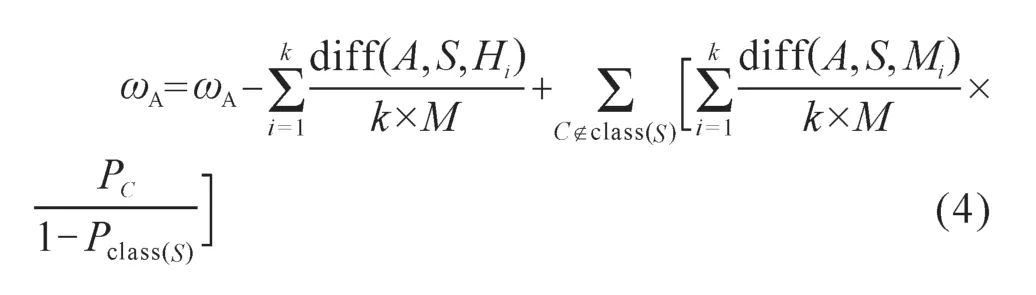
式中:ωA为特征A的权重;Hi为与S同类的最近邻样本;Mi为与S不同类的最近邻样本;PC为类别为C的概率;class(S)为样本S所属的同类别样本子集;diff(A,S,Mi)为样本S1与S2在特征A上的差,当特征为数值变量时,将数据归一化至[0, 1]。
CFS算法是一种关联性的Filter算法,通过计算特征与类别、特征与特征之间的相关性进行评估,从而实现数据清洗(Li et al,2011)。CFS算法首先针对初始特征空间,采用前向选择或后向选择进行特征子空间的搜索,构建特征子空间T,基于启发式估计方法对特征子空间内特征与特征、特征与类别间的相关性进行评估,其相关性强弱利用皮尔逊相关系数进行计算,去除特征与类别间相关性低的特征以及特征与特征相关性过高的特征。启发式评估公式(孙宁青,2010)如下:
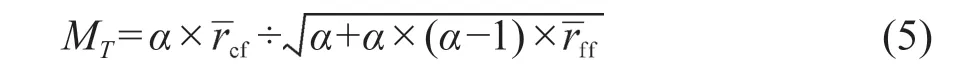
式中:MT为特征子集T的评估值;为类别与特征的平均相关性;为特征与特征间的相关性;α表示特征子集包含的特征个数。
2.3 影像分类算法
随机森林(random forest,RF)算法作为集成决策树的机器学习方法,通过在训练集中随机抽取样本且放回的方法,进行每一个决策树的无剪枝生长,来消除决策树受训练集影响而泛化能力弱的问题(Breiman,2001)。高维数据下随机森林产生的并行分类器在处理速度和分类精度都有较好的效果,但当数据噪声量过大时,随机森林仍然缺少去除多余噪声的能力,在分类过程中出现过拟合(Wang et al,2018),特征个数过大,会产生过拟合问题,而特征个数不够,则会降低每个树的分类能力,从而增加了算法的错误率,针对该问题,该算法采用基于OOB(out of bag)误差的无偏估计进行随机选择最大特征数的确定。
3 结果与讨论
3.1 分割结果
使用ESP分割尺度工具时需要先确定分割的起始尺度,本文每隔10单位进行一次分割,目视对比分割效果和各分割尺度下的LV与ROC的曲线变化,当分割尺度为70时,既可以较好地将盐碱地与其他地物分割开,又避免了内部的过分割现象。尺度分割LV与ROC变化如图1所示,可以看出当分割尺度为71、97、123、132、152、166时为峰值,分别使用这些尺度对影像进行分割,当分割尺度为123时,能较好地区分盐碱地与周围地物类型。对于异质性相关因子权重的设置,采用单一参数设定法进行多次试验,发现增加近红外波段的权重,可以使盐碱地在该波段光谱信息更为丰富;将形状异质性与紧致度因子分别设定为0.5和0.6,能够最大化体现目标的边界特征。

图1 分割尺度效果图Fig.1 Effect of segmentation scale
3.2 特征优选
从目标对象纹理特征、光谱特征、形状特征以及遥感指数等自定义特征中选择适宜的特征数量和类型,可以提高分类的精度,减少数据的冗余计算。本文针对盐碱地的特征信息,构建了初始特征空间,在光谱特征与纹理特征中,每一个特征属性均在蓝、绿、红、近红波段上进行特征构建,最大化保留每一个波段的特征信息,选择遥感指数SAVI(土壤调节植被指数)、NDVI(归一化植被指数)、SI(盐度指数)作为独立波段参与分类。该初始特征空间包含93个特征。初始特征空间中各属性数据量级不同,为防止数据数值之间差异过大而导致数据被吞噬问题,对各属性数据进行Min-max标准化处理,将各属性值限定至[ −1, 1]。
利用Relief F算法对初始特征空间进行降维,采取Ranker搜索策略对每一个特征进行权重计算并按顺序排列,得到的特征重要性排序如图2所示。按排序可知前9个特征得分较高,依次为HIS变换、土壤调节植被指数、归一化植被指数、最大差分、近红外波段、红波段、盐度指数、蓝波段、绿波段;第10 — 20个特征处于中等得分,主要是灰度共生矩阵纹理特征以及部分形状特征,说明光谱特征与遥感指数在盐碱地提取中占有重要地位,纹理特征次之,形状特征最末。这是由于盐碱地的含盐量越高,在近红外区域反射率则越高,而裸露盐碱地多与盐生植被混合存在,因此纹理方向不定,纹理特征复杂。盐生植被的簇状生长,在土壤含盐量高的地方生长受抑制,土壤含盐量低则生长旺盛,盐碱地也受到其影响,形状呈簇状聚集,边缘形状弯曲多变。Relief F算法虽然赋予了每个特征权重,但不能确定特征子集的数目,本文利用随机森林方法对数据集进行建模,通过得到不同特征数目下的分类总体精度(overall accuracy)与Kappa系数来确定最优特征数目。建模过程中对训练集采用十折交叉验证法进行训练,即将数据集分为十等份,将其中9份作为训练集,1份作为验证集,直到每份数据都作为验证子集进行验证且验证1次。十折交叉验证法使得每个数据都参与了训练与测试两个环节,避免了模型的过度学习以及欠学习。由图3可知:随着特征变量数目逐渐增加,总体精度与Kappa系数也在快速增加,当特征变量达到15之后,曲线开始转变为波动状态,直到当特征数目为40时,精度达到峰值,分类总体精度达到96%,Kappa系数为0.95,因此选择前40个特征作为优选特征,选择特征如表2所示。
针对CFS算法,采用全局最优算法(best first)作为搜索策略进行启发式搜索,进行特征预选,去除不相关变量。CFS算法并不对每个特征变量进行排序,通过对特征子集的评估直接得到最优特征空间。通过CFS筛选后共有17个特征,结果如表2所示。通过比较可得两个算法所获得的特征中共有14个重合特征。基于Relief F得到的特征结果包括了82%的CFS筛选的特征,说明两种算法对重要特征均有较好的搜索效果,通过对比可以看出:各波段的光谱信息与自定义遥感指数在两种算法中都得到了保留,与上述重要性得分排序表现的结论相同,说明光谱信息在识别盐碱地类中的重要性,是区分其与其他地类的重要特征。CFS算法在纹理特征与形状特征中相对于Relief F算法则约简了更多属性。
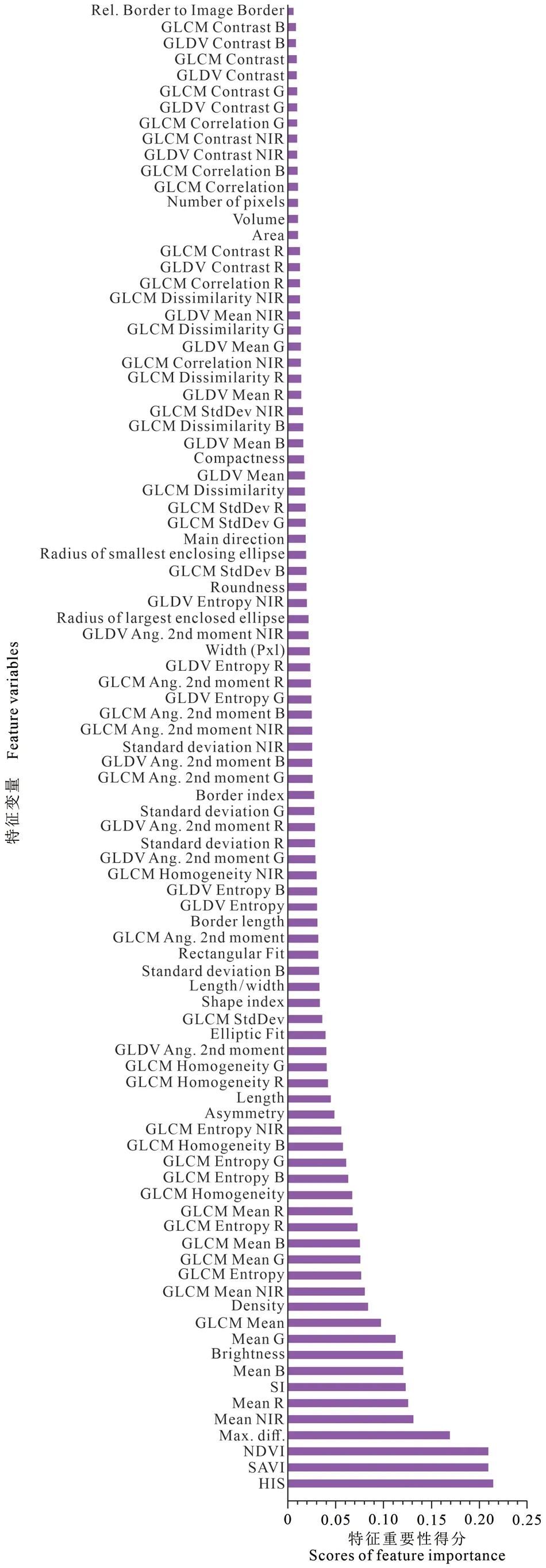
图2 特征重要性得分Fig.2 Scores of feature importance
3.3 分类结果及精度验证
通过Relief F与CFS算法筛选后的特征对研究区域进行随机森林分类,通过选取的随机样本点利用解译标志以及Google Earth目视解译赋予样本数据属性,利用生产者精度(produce accuracy)、用户精度(user accuracy)统计不同算法下漏分误差与错分误差,利用总体分类精度(overall accuracy)、Kappa系数评价总体分类效果。由表3可知:Relief F-RF在盐碱地与盐化植被的分类上,生产者精度与用户精度均有所提高,但在其他类别上精度降低了0.7%与1.6%,原因是Relief F算法进行特征筛选时,对于相关性较强的特征过滤效果不好,导致冗余特征,进而影响了分类性能;Relief F-RF算法的总体精度提高了1.1%。而CFS基于相关性的特征筛选算法则在分类效果有了明显提升,相较于直接建立随机森林,总体精度达到83.7%,提高了7.4%,Kappa系数为0.74,盐碱地的生产者精度提高了8.9%,用户精度提高了6.8%。盐化植被的生产者精度提高了10.4%,用户精度提高了12.2%。
上述结果表明:基于Relief F与CFS对随机森林进行优化均能提高对盐渍化土地的提取精度,未进行特征优选的随机森林算法提取精度最低,表现出多维数问题对机器学习的分类性能存在一定的影响。Relief F算法在特征中筛选出40个特征,相较来说CFS算法只保留了17个特征,却得到了更高的提取精度,说明特征数目与精度不呈现正相关性,特征之间的高相关性也会影响机器的学习能力(李文杰等,2020)。
不同算法下的分类结果以及局部细节如图4所示。通过对比遥感影像图,可以看出CFS-RF算法对盐碱地识别精度更高。究其原因,是受到土壤含盐量高低的影响,盐渍化土地上会生长较为单一的植被如碱蓬、芦苇(Phragmites australis)等,分布稀疏,呈簇状聚集。植被的生长发育受到抑制,NDVI值会比正常植被低,在假彩色图像上呈现暗红色,而盐渍化严重区域则会表现出亮斑现象。盐碱地与盐化植被在影像上通常呈交错分布,盐渍化植被分布不均,与盐碱地成为混合像元。对于盐碱地与盐化植被的混分现象,通过多尺度分割以及CFS的特征筛选,增大了类别之间的可分离性,CFS优化后盐化植被的分类精度提升最多。有些盐碱地区域由于排水不畅、土壤湿度增大造成的地表反射率降低,在影像上呈现暗色调,CFS-RF对此也有很好的识别效果。
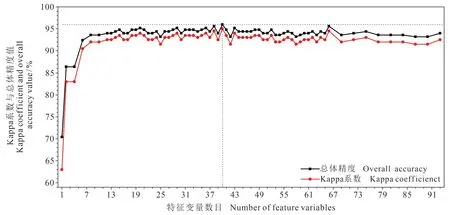
图3 特征数目与精度关系Fig.3 Relationship between feature numbers and accuracy

表2 Relief F与CFS特征优选结果Tab.2 Results of Relief F and CFS feature selection

表3 基于不同算法的分类精度统计Tab.3 Statistics of classification accuracy based on different algorithms
4 结论
本文通过对GF-6遥感影像利用FNEA算法进行面向对象的多尺度分割,确定适宜盐碱地提取的分割尺度,利用Relief F与CFS算法进行特征筛选,以此实现对随机森林的优化。得到结论如下:(1)确定了在GF-6高空间分辨率下盐碱地的分割尺度,为盐渍化土地信息的提取提供参考依据;(2)特征筛选可以过滤冗余数据,提高机器学习的分类精度,CFS算法对特征的过滤程度大于Relief F算法;(3)本文提出的利用CFS算法对随机森林进行优化,在盐碱地提取应用上有较好的分类效果,特征变量减至17个,且总体精度达到83.7%,提高了7.4%,Kappa系数为0.74;(4)对于高维属性数据特征复杂问题,本文提出的方法也可以适用于其他地类信息的提取,可以有效提高特征子集的数据质量与数据挖掘的效率。
猜你喜欢
临床肝胆病杂志(2022年8期)2022-11-23
中国临床医学影像杂志(2022年6期)2022-07-26
现代企业(2021年2期)2021-07-20
河北画报(2020年21期)2020-12-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
河北果树(2020年1期)2020-02-09
河北果树(2020年1期)2020-01-09
铁道学报(2018年5期)2018-06-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
