
面向地下停车场的轻量级目标检测算法研究
2022-02-21 03:16张小俊曹梓楼张明路
汽车实用技术 2022年2期
张小俊,曹梓楼,张明路
面向地下停车场的轻量级目标检测算法研究
张小俊,曹梓楼,张明路
(河北工业大学机械工程学院,天津 300400)
基于深度学习的目标检测算法能够取得良好的检测速度离不开高性能GPU硬件设备的支持。然而,在智能车中搭载高性能、高功耗、大尺寸的硬件设备与汽车的长续航理念不符。因此,文章以YOLOv3目标检测算法为基线模型进行改进,提出轻量化的目标检测模型Mobile-YOLO,并在采集制作的地下停车场数据集中进行训练测试。实验结果表明,提出了Mobile-YOLO相较于YOLOv3,在平均精度均值略微提升的情况下,检测速度提升了47.1%。在移动端平台TX2上每秒能够检测31张图像。
深度学习;目标检测;轻量化;移动端
引言
近几年,自动驾驶得到了广泛关注。环境感知系统主要通过摄像头、激光雷达及毫米波雷达等传感器检测识别车辆周围的场景信息,为路径规划和决策提供依据。基于视觉的目标检测技术主要负责检测车辆、行人。传统的检测方法大都利用一些诸如颜色、形状、纹理、对称性等简单特征进行检测。随着深度学习技术的发展,行人和车辆检测技术也取得了突破性的进展。
Jiang等人[1]将深度学习目标检测算法与汽车尾灯特征相结合提出了一种夜间车辆检测方法。Sri等人[2]在YOLOv3的基础上改进特征提取网络和金字塔池化得到一种轻量级车辆检测方法。俞依杰[3]利用双路金字塔结构改善了小目标车辆漏检的问题。Liu等人[4]利用卷积网络直接检测行人的中心和尺寸,将行人检测作为一种高级的特征检测任务。Chen等人[5]利用热感相机和深度相机共同检测行人,两种相机信息互补,大幅度地减小了行人误检率。
基于深度学习的目标检测算法的高效性依赖于高性能硬件设备,导致算法落地较为困难。因此,本文在YOLOv3的基础上提出一种轻量级目标检测算法,并将其应用于地下停车场中。
1 轻量化模型Mobile-YOLO
1.1 深度可分离卷积
MobileNet系列[6-8]检测算法的核心为深度可分离卷积。常规卷积在空间维度是稀疏连接,但是在通道维度确实全连接形式。深度可分离卷积将卷积操作分解为用于深度卷积和逐点卷积。深度卷积分别进行单通道的卷积操作,逐点卷积采用1×1的卷积对深度卷积地输出进行调节使其与常规卷积地输出维度相同。
假设卷积层的输入为D×D×,输出的尺寸为D×D×。卷积核尺寸为D×D。则常规卷积的计算量为D×D×××D×D。深度可分离卷积打断空间与通道之间的连接,深度卷积的计算量为D×D××D×D,逐点卷积的计算量为××D×D。相较于常规卷积,深度可分离卷积的计算量变为了原来的1/D2。当采用3×3卷积时,计算量减小到原来的1/9。
1.2 激活函数
采用swish激活函数代替Leaky ReLU。swish同样具有下界、平滑等特性,但由于其中包含指数运算,这在移动端设备上计算成本较高,可将swish函数中的sigmoid替换为ReLU。但当>0时,ReLU进行正向激活,可能造成激活后的值无限大,影响模型稳定性,并且在低性能的移动端设备上可能带来误差。因此,将其替换为更适用于移动端的ReLU6激活函数。改进后的swish激活函数计算方式为:
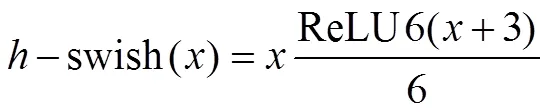
在网络的深层中,随着特征图尺寸的下降,应用非线性激活函数的计算成本会降低。因此,在网络的后半段采用-swish激活函数。
1.3 网络结构
骨干网络主要有三部分组成:其起始分、中间部分和分类输出层。其实部分一般采用32或者64通道的卷积层进行滤波,为了减少参数计算量,在其实部分采用16通道的卷积层,卷积核大小为3×3,卷积步长为2,实现对输入图像的下采样功能,激活函数采用-swish。
中间部分用来进一步提取图像特征,主要由多个卷积层、深度可分离卷积、批归一化层、激活层和跳跃连接组成的四种块结构组成。第一种结构由1个1×1卷积层、深度卷积和逐点卷积组成。每层卷积后都接有批归一化层和激活层,激活层采用ReLU6,深度卷积的尺寸为3×3或5×5。第二种结构在第一种结构的基础上增加跳跃连接。将两种结构分别称为bneck1和bneck2。
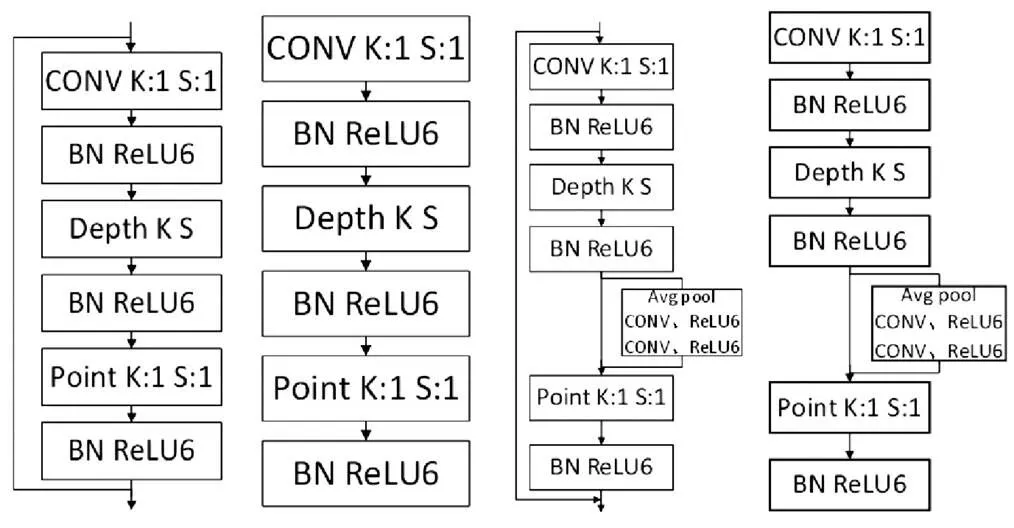
图1 Bneck1、bneck2、bneck1-SE和bneck2-SE
第三种结构在bneck1的基础上增加轻量级SE注意力机制。SE注意力机制能够通过显示建模道之间的相互依赖关系,自适适应的校准道的特征响应[9]。换句话说,就是使得网络能够自动评价每个通道的重要程度,使得网络更关注信息量大的通道。将SE注意力模块添加到深度卷积与逐点卷积之间。SE注意力机制首先对深度卷积的输出进行全局池化,得到一个1×1×C大小的通道描述符。为了减轻计算量,将原有的两层全连接层替换为组卷积,第一层卷积起到降维的作用,第二层卷积进行升维,激活函数均采用ReLU6。将各个通道的权重系数与输入特征相乘即得到输出,最后经过逐点卷积输出。第四种结构在第三种结构的基础上增加跳跃连接。第三种、第四种结构分别称为bneck1-SE和bneck2- SE。四种结构的结构图如图1所示。图中conv表示卷积层,表示卷积核的尺寸,表示卷积核滑动的步长,BN表示批归一化层,Depth表示深度卷积,Point表示逐点卷积,Avg pool表示平均池化层。
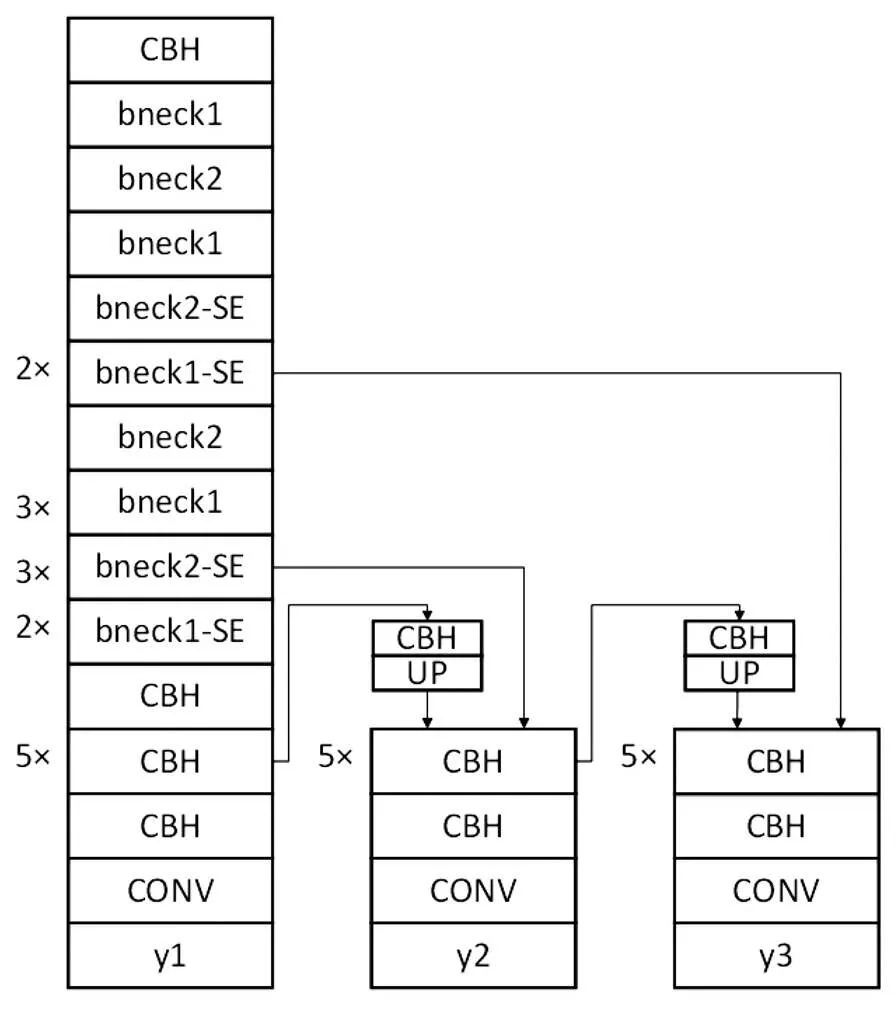
图2 Mobile-YOLO网络结构图
将MobileNetv3中用于输出分类结果的全连接层裁剪,得到用于目标检测的骨干网络将该骨干网络作为YOLOv3中Darknet53的替换,并将特征金字塔结构中的激活函数全部替换为-swish,组成新的目标检测网络Mobile-YOLO。其结构图如图2所示,图中CBH表示卷积层、批归一化层、-swish组成的基本卷积单元,UP表示对特征图进行上采样,1、2、3分别表示三种不同尺度的输出。
2 实验与分析
2.1 实验参数设置
为了训练适用于地下停车场的目标检测算法,在地下停车场中采集包含行人和车辆两种目标的图像共2 888张,并采用Labelimg和Makesense软件对图像进行标注,标注格式与MS COCO数据集格式相同。采用Mixup、mosaic、cutout、随即擦除、随机亮度变化、翻转、随机裁剪等方式进行数据增强。
将Mobile-YOLO在8G NVIDIA RTX 2080显卡上进行训练。共训练400轮,初始学习率为0.001,batch size为16,采用余弦衰减方式进行学习率衰减。采用多尺度训练方式进行训练,每10轮随机更换一种尺度,图像尺寸范围为416~618。模型的初始化权重为在公开数据集MS COCO中训练好的骨干网络权重参数。
余弦学习率衰减是指学习率按照COS函数进行衰减,从0.001按照公式(2)的计算方式逐步衰减为0。
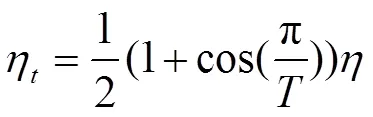
2.2 实验结果
根据上述参数对Mobile-YOLO进行训练,图3为IOU阈值为0.5时的平均精度均值随训练过程的变化曲线。在训练到第350轮之后,模型逐渐趋于稳定,在第372轮时,模型的平均精度均值达到了最大值0.806,之后,模型的平均精度均值在0.804上下进行小幅度震荡。
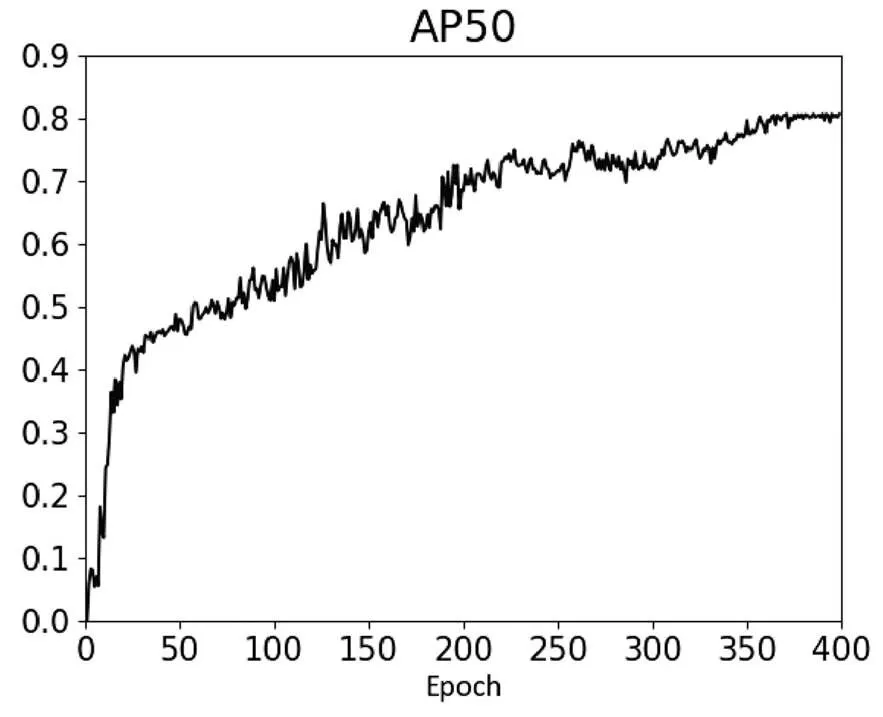
图3 IOU阈值为0.5时的AP变化曲线
将YOLOv3与YOLOv3-tiny在同等参数设置下进行训练。表1为三者之间的性能对比,测试平台为高性能主机。Mobile-YOLO相较于YOLOv3的平均精度均值提升了0.55%,速度却增长了41.7%,达到了83.3帧每秒。虽然速度与YOLOv3-tiny相差较大,但二者的平均精度均值却相差了19.14%。
表1 模型性能对比
模型APAP50AP75APFLOPs YOLOv371.9579.774.758.850G YOLO−t53.3660.156.8166.64.24G M−YOLO72.580.677.383.314.5G

图4 Mobile-YOLO检测结果
将训练好的模型在改装智能车奇瑞eQ1上进行车载实验,摄像头放置于挡风玻璃前,算法嵌入到NVIDIA Jetson TX2开发板上。测试过程中保持车辆的行驶速度在8 km/h左右,Mobile-YOLO的运行速度为31帧每秒,能够满足实时检测的要求。图4为Mobile-YOLO对测试集中图像的检测结果。
3 总结
正文提出适用于地下停车场的了轻量化目标检测模型Mobile-YOLO。将常规卷积、深度卷积、轻量化注意力模块SE、逐点卷积和跳跃连接组成四种块结构,在注意力机制中采用组卷积代替全连接层以减小计算量,并且网络的前半段采用更适用于移动端的ReLU6激活函数,在网络的第一层和后半段采用-swish激活函数。将改进后的MobileNetv3与三个尺度的特征金字塔结构组成轻量化目标检测模型Mobile- YOLO,并在采集的地下停车场数据集中进行训练测试。试验结果表明,提出了Mobile-YOLO相较于YOLOv3的平均精度均值提升了0.55%,检测速度提升了41.7%,在移动端测试平台TX2中运行速度达到了31帧每秒。
[1] Jiang S, Qin H, Zhang B, et al. Optimized Loss Functions for Object detection and Application on Nighttime Vehicle De- tection[J]. arXiv e-prints,2020:arXiv:2011.05523.
[2] Sri J S, Esther R P. Little YOLO-SPP:A Delicate Real-Time Vehicle Detection Algorithm[J].Optik,2020,225.
[3] 俞依杰.基于改进Faster R-CNN的视觉车辆检测算法研究[D].镇江:江苏大学,2020.
[4] Liu W,Liao S,Ren W,et al.High-level semantic feature detec- tion:A new perspective for pedestrian detection[C]//Procee- dings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.2019:5187-5196.
[5] Chen Z,Huang X.Pedestrian detection for autonomous vehicle using multi-spectral cameras[J].IEEE Transactions on Intelli- gent Vehicles, 2019,4(2):211-219.
[6] Howard A G,Zhu M,Chen B,et al.Mobilenets:Efficient conv- olutional neural networks for mobile vision applications [J].arXiv preprint arXiv:1704.04861,2017.
[7] Sandler M,Howard A,Zhu M,et al.Mobilenetv2:Inverted resi- duals and linear bottlenecks[C]/Proceedings of the IEEE con- ference on computer vision and pattern recognition.2018: 4510-4520.
[8] Howard A,Sandler M,Chu G,et al.Searching for mobilenetv3 [C]/Proceedings of the IEEE/CVF International Conference on Compu- ter Vision.2019:1314-1324.
[9] Hu J,Shen L,Sun G.Squeeze-and-excitation networks[C]/Pro- ceedings of the IEEE conference on computer vision and pat- tern recognition.2018:7132-7141.
Lightweight Object Detection Algorithm for Underground Parking
ZHANG Xiaojun, CAO Zilou, ZHANG Minglu
( School of Mechanical Engineering, Hebei University of Technology, Tianjin 300400 )
The object detection algorithm based on deep learning cannot achieve good detection speed without the support of high-performance GPU hardware devices. However, the hardware equipment with high performance, high power consump-tion and large size in the intelligent car does not conform to the concept of long endurance of the car. Therefore, this paper takes YOLOV3 object detection algorithm as the baseline model for improvement, proposes a lightweight object detection model, Mobile-YOLO, and conducts training and testing in the collected and produced underground parking lot dataset. The experimental results show that compared with Yolov3, the proposed Mobile-YOLO has a 47.1% increase in detection speed with a slight increase in the mean accuracy. It can detect 31 images per second on the mobile terminal platform TX2.
Deep learning; Object detection; Lightweight; Mobile terminal
TP183
A
1671-7988(2022)02-16-04
TP183
A
1671-7988(2022)02-16-04
10.16638/j.cnki.1671-7988.2022.002.004
张小俊(1980—),男,博士,教授,就职于河北工业大学机械工程学院,研究方向:自动驾驶技术、汽车电子控制技术等。
天津市新一代人工智能科技重大专项(18ZX ZNGX00230)。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
动漫界·幼教365(大班)(2021年4期)2021-05-23
阅读(快乐英语高年级)(2020年6期)2020-08-28
上海师范大学学报·自然科学版(2019年5期)2019-12-13
数学大王·低年级(2019年12期)2019-08-14
福建基础教育研究(2019年6期)2019-05-28
中国新通信(2017年9期)2017-05-27
