
面向概念漂移数据流的自适应分类算法
2022-03-09 05:49陆克中伍启荣吴定明
计算机研究与发展 2022年3期
蔡 桓 陆克中 伍启荣 吴定明
(深圳大学计算机与软件学院 广东深圳 518061)
在当今的数字时代,数据起着至关重要的作用,它以惊人的速度增长,如何处理和分析这些数据变得越来越重要[1].与在静态场景中构建模型的批处理学习不同,在线学习面临2个重大挑战:1)分类器必须在每个实例到达后立即进行处理,而无需使用存储或重新处理[2].2)数据流可能会发生概念漂移,即数据分布与输入变量和输出变量之间的关系可能会随时间发生变化[3].因此,部署在非平稳数据流中的分类器必须通过1次遍历来学习,同时能适应数据分布的动态变化.
近些年来,在处理概念漂移数据流分类问题上取得了很多研究成果.围绕概念漂移的研究可以归纳为主动检测[4-6]和被动适应[7-8]2大类.主动检测算法通过检测分类器性能或数据流的特征分布来确定数据流的稳定性,当判断发生概念漂移时触发概念漂移处理机制来适应新环境.被动适应方法不去主动检测是否发生概念漂移,而是通过不断对数据或者模型进行更新以适应新环境,主要有块学习、增量更新、遗忘因子机制和集成方法等.主动检测方法通常具有更好的概念漂移适应能力,但也往往具有更高的时间和空间复杂度.
随着神经网络的迅速发展,研究人员已开始开发基于神经网络的数据流分类方法.由新加坡南洋理工大学Huang等人[9]提出的极限学习机(extreme learning machine, ELM)是一种具有单隐层的高效前馈神经网络,研究人员被广泛吸引来开发ELM方法.ELM随机选择输入层权重和隐含层偏差.一旦确定了输入权重,就不会通过迭代进行调整.因此,与传统的神经网络相比,ELM具有学习时间短、泛化能力强的优势[10].而Liang等人[11]进一步提出的在线顺序极限学习机(online sequential extreme learning machine, OSELM)是一种增量学习算法,可满足数据流分类的要求[12].该算法可以逐步更新分类模型而无需重新训练.由于OSELM相对于其他算法具有速度快、分类性能好的优势,基于OSELM算法进行优化成为数据流分类研究的一个重要方向,也产生了很多衍生算法[13-17].但OSELM算法也存在不足,比如只能处理渐进的概念漂移,而无法适应突然改变的概念[18].而大多数基于OSELM优化的算法直接提前指定1个隐含层节点数且在不同数据集上保持固定,这很容易产生欠拟合或过拟合问题.也有学者将遗忘因子引入OSELM,但同样提前指定1个固定的遗忘因子,导致分类器无法在数据流稳定阶段和概念漂移阶段取得良好的平衡.此外,数据流往往存在噪音,而原始OSELM及大多数优化算法没有对噪音进行有效区分,而是对每个新到达的实例都相同处理,因此分类决策边界很容易被噪音(异常值)破坏.
针对上面提到的问题,以及在FROSELM(online sequential extreme learning machine based on regularization and forgetting factor)[19]和FGROSELM(online sequential extreme learning machine with generalized regularization and adaptive forgetting factor)[20]等算法的启发下,本文提出了一种自适应在线顺序极限学习机(adaptive online sequential extreme learning machine, AOSELM)分类算法.AOSELM算法首先引入自适应模型复杂度机制,在初始化阶段可以自适应确定出最佳隐含层节点数,并加入正则项,优化模型复杂度.其次通过自适应遗忘因子和概念漂移检测机制,将概念漂移和遗忘因子结合,使分类模型在发生概念漂移时自动调小遗忘因子,而在数据流稳定时自动调大遗忘因子,从而适应数据流的动态变化.最后通过引入异常点检测机制,增强模型抗噪音能力.
1 相关工作
本节我们将重点介绍OSELM和FROSELM这2种算法.为了简单起见,2种算法都考虑用于2分类问题,即只有单个输出节点.
1.1 OSELM算法
在线顺序极限学习机OSELM算法是由Liang等人[11]于2006年提出,该算法是Huang等人[9]提出的ELM算法的在线学习方法.算法分为初始化阶段和在线学习阶段2个阶段.
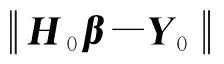
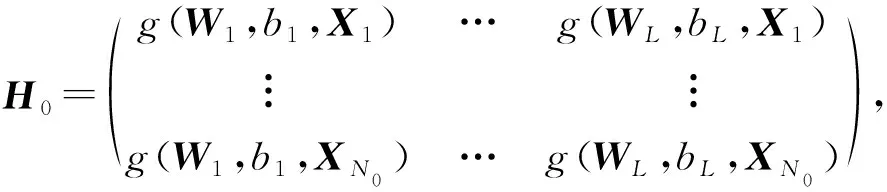
(1)
Wi和bi分别为输入权重和第i个隐含层偏置,而Y0=(y1,y2,…,yN0)T.根据广义逆求解方法可计算得:
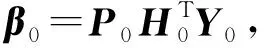
(2)
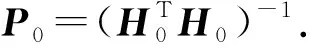
在线学习阶段,数据流逐条被处理,无需保存历史数据.当新实例(Xk+1,yk+1)到达时,记hk+1=(g(W1,b1,Xk+1)…g(WL,bL,Xk+1)),可计算得过渡矩阵P和输出层权重β的更新:
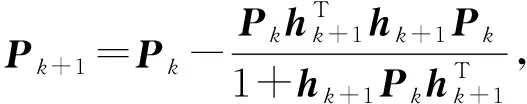
(3)
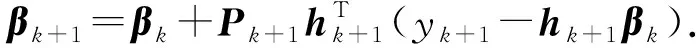
(4)
从式(3)(4)可以看出,OSELM的输出权重是根据最后一次迭代的结果和新到达的数据进行递归更新的,一旦新数据被学习,就可以立即丢弃,符合在线学习处理方式的要求,因此该算法的计算开销和内存要求大大降低.OSELM具备速度快和泛化能力强的特点,并且可以增量更新模型.
1.2 FROSELM算法
具有遗忘机制的正则在线顺序极限学习机FROSELM算法是由杜占龙等人[19]于2015年提出.该算法将遗忘因子(forgetting factor, FF)方法和正则化技术引入OSELM,根据实例的时间顺序分别为每个样本分配不同的权重.初始化阶段过渡矩阵P0和输出层权重β0分别为
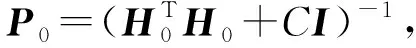
(5)
(6)
其中,C为惩罚项系数,I为单位矩阵.在线学习阶段过渡矩阵P和输出层权重β的更新公式分别为
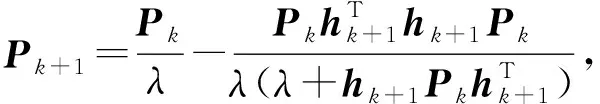
(7)
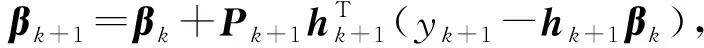
(8)
其中,λ为遗忘因子,当λ=1且C=0时,FROSELM退化为原始OSELM.FROSELM算法为最近的样本分配较高的权重,而为旧的样本分配较低的权重,以表示它们对学习模型的不同贡献,因此使模型能够适应数据流的动态变化.
2 自适应在线顺序极限学习机算法
数据流的动态变化特点要求分类器能够不断地更新,以便更改分类器使其适应当前的数据分布.而概念漂移的发生使得不同时刻目标概念与当前特征的映射关系不断变化,且是否发生概念漂移、概念漂移的位置以及概念漂移的类型均无法提前获知.目前大多数算法都采用提前指定模型参数的方式进行学习,比如对模型复杂度直接影响的隐含层节点数以及决定概念漂移适应能力的遗忘因子等.这种做法使得分类模型只能在特定的数据集才能发挥较好的性能,因此,本文提出的AOSELM算法引入自适应机制来增强模型的分类效果和概念漂移适应能力,此外,还引入异常点检测机制,增强模型抗噪音能力.本节将对AOSELM算法的基本思想及其实现过程进行详细介绍.
2.1 算法基本思想
现有的数据流分类算法大致可分为3种:1)大部分传统算法是对数据流新到达实例(Xi,yi)进行增量式处理(称为批学习),这种方法需要保存大量的历史数据,且反复学习会消耗大量时间,因此逐渐不适合用于处理大规模数据流任务;2)将数据流划分为相同大小的数据块B1,B2,…,Bi,…(称为块学习),分类器只针对最新的数据块进行学习和更新;3)分类器只针对最新的单个实例进行1对1的分类和学习,而不保存历史实例数据(称为在线学习),这种方法更适合大数据时代数据不断快速产生的特点,也是当前研究的热门方向,因此本文采用这种方式进行处理.
AOSELM算法分为初始化阶段和在线学习阶段.在初始化阶段,在OSELM算法初始化阶段的基础上,引入自适应模型复杂度机制.采用2折交叉验证的方法,确定最佳的隐含层节点数(number of hidden layer nodes),记为Nh.然后使用最优的隐含层节点数以及加入惩罚项学习训练集,得到自适应优化后的初始模型,并保存输出层权重β0.在在线学习阶段,AOSELM算法针对每个到达的实例,先进行分类.如果分类正确,则直接结束本轮学习并进入下一个实例,不对模型进行更新.如果分类不正确,则引入自适应遗忘因子和概念漂移检测机制,提出概念漂移指数(concept drift index),记为ICD.通过ICD判断数据流是否产生概念漂移,如果发生概念漂移,则将ICD和遗忘因子λ结合,使模型根据当前数据流自适应调整遗忘因子λ大小,从而使模型更好地适应数据流的变化.此外还引入异常点检测机制,防止模型因异常点而过度更新,从而增强分类器的抗噪音能力.图1展示了所提出的自适应在线顺序极限学习机算法的总体框架:

Fig. 1 The overall framework of AOSELM图1 AOSELM算法的整体框架
2.2 自适应模型复杂度机制
分类器的分类性能通常都会受到模型复杂度的影响,如图2所示.当模型复杂度太低时,分类决策边界就会像线条1那样欠拟合;而当模型复杂度太高时,分类决策边界又会像线条2那样过拟合.机器学习的目的就是学习产生如线条3那样的理想决策边界.因此,选择合适的模型复杂度对分类器的性能起着至关重要的影响.
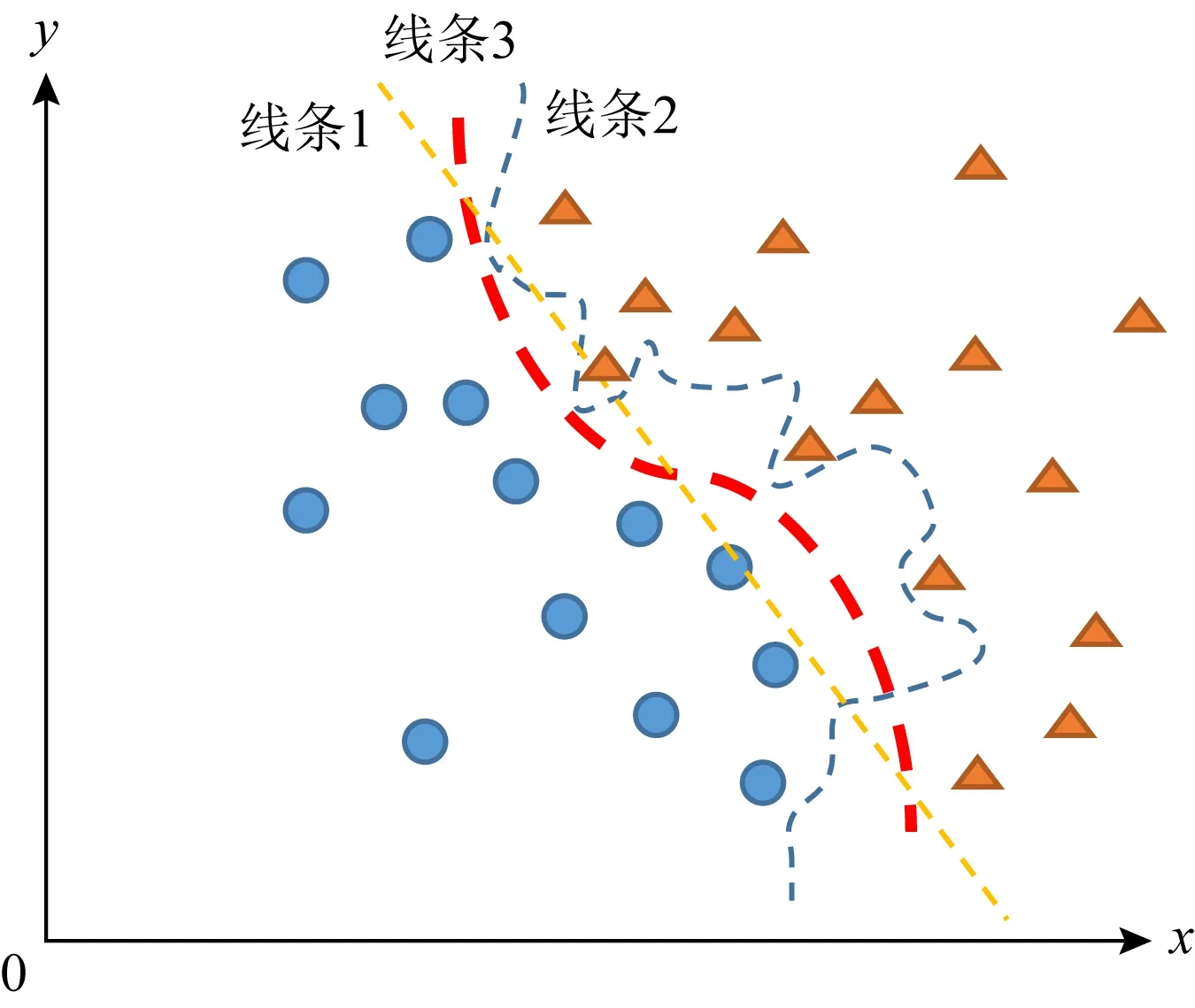
Fig. 2 Model complexity and decision boundary图2 模型复杂度与决策边界示意图
对于OSELM算法而言,隐含层节点数是决定模型复杂度的关键参数,Nh的选择也对分类器的分类性能和泛化能力起着重要影响.在处理分类任务时,不同数据流因为特征数不同、输入和输出之间的映射关系复杂程度不同等原因,往往适合不同大小的模型复杂度.然而大多数算法直接提前指定1个隐含层节点数且在不同数据集上保持固定,明显不符合现实需求.因此,AOSELM算法引入了自适应模型复杂度(adaptive model complexity, AMC)机制.
自适应模型复杂度机制的具体方法是在初始化学习阶段,与大多数算法直接指定1个固定的隐含层节点数Nh不同,首先设定Nh∈[2,2Nin],其中Nin为输入层节点数,即数据流的特征数,使用2折交叉验证的方式计算每个Nh对应的平均分类准确率.然后通过加入节点数量惩罚项来选出最佳的隐含层节点数Nh.进一步使用最佳的Nh和训练集进行学习,并加入惩罚项,最终学习得到更加合适的初始分类模型.这样算法在处理不同数据流任务时,就会自适应地计算出最合适的Nh,从而确定最合适的模型复杂度,避免出现欠拟合或者过拟合问题.另外,在处理数据流任务中,在线学习阶段规模往往比初始化阶段大很多,比如本文的实验中初始化阶段实例数占比均小于3%,因此,AMC机制并不会明显增加模型整体的时间开销.
2.3 自适应遗忘因子和概念漂移检测机制
在FROSELM算法中,遗忘因子λ大小是决定分类器遗忘速度和适应速度的关键参数,而算法提前指定遗忘因子λ值且一直保持固定,无法有效地适应数据流的概念漂移.另外,由于我们往往无法提前获知是否发生概念漂移、概念漂移发生的位置以及概念漂移发生的类型,因此有必要引入自适应遗忘因子机制.AOSELM算法引入自适应遗忘因子和概念漂移检测(adaptive forgetting factor and concept drift detection, AFF)机制.该机制借鉴漂移检测方法(drift detection method, DDM)提出概念漂移指数ICD,并将概念漂移指数ICD和遗忘因子λ相结合,使模型能够根据当前数据流概念漂移情况自适应地调整遗忘因子λ大小,从而使模型能更好地适应数据流的变化.

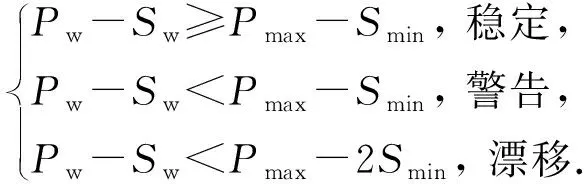
(9)
基于DDM本文提出了概念漂移指数ICD来描述当前数据流概念漂移的程度,ICD的计算方法:
ICD=(Pw-Sw-Pmax)/Smin.
(10)
将遗忘因子λ与概念漂移指数ICD结合,使遗忘因子λ能够随概念漂移指数ICD自适应地调整.遗忘因子λ的计算方法:
λ=1+0.01ICD.
(11)
当遗忘因子λ=1时,则退化为OSELM,不具备遗忘能力,因此将λ最大值设为0.999.结合式(9)~(11)可以看出,当概念漂移系数ICD≥-1时,则判断数据流处于稳定阶段;当概念漂移系数ICD←1时,则发出概念漂移警告,在线更新模型;当概念漂移系数ICD←2时,则判定数据流已经发生概念漂移,根据式(11)自适应更新遗忘因子λ.随着概念漂移系数ICD的变小,遗忘因子λ也在自适应变小,从而使分类器具有更强的遗忘能力,能更快地适应新概念.
2.4 异常点检测机制
数据流往往存在噪音,而原始OSELM算法及大多数改进算法没有对噪音进行有效区分,而是对每一个新到达的实例都相同处理,全部进行更新,因此分类决策边界很容易被噪音(异常值)破坏.
AOSELM算法引入异常点检测(outlier detection, OD)机制,对预测错误且概念漂移系数ICD≥-1(即数据流处于稳定状态)的实例进行异常点检测.如果判断为异常点,则直接跳过该实例,不在线更新分类器;如果判断不是异常点,则按照OSELM算法在线更新分类器.OD机制可以避免决策边界过多受到异常点的影响,从而提升模型整体的抗噪音能力.
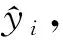
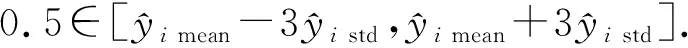
(12)
如果式(12)成立,则认为当前实例没有远离分类决策边界,从而判断不是异常点;否则认为当前实例远离分类决策边界,判断属于异常点.
2.5 算法伪代码
AOSELM算法通过引入自适应策略和异常点检测形成较优分类模型,使其更好地适应概念漂移,算法伪代码见算法1所示:
算法1.AOSELM算法.
输入:数据流(X,y)、训练集实例数N0、保留模型数Nm、保留预测数Np;
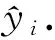
① 初始化阶段,随机生成输入层权重和隐含层偏置;
② 基于训练集(Xtrain,ytrain)进行交叉验证;
③ 引入AMC机制,计算最佳隐含层节点数Nh;
④ 加入L2正则化参数C;
⑤ 计算出输出层权重β0,得到初始分类模型;
⑥ 将β0保存到模型表中,结束初始化阶段;
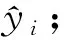
⑧ 计算相关参数P,Pw,Sw,Pmax,Smin;
⑨ 将P保存到预测表中;
⑩ 更新Pnew=(Pnew+1)%Np;
2.6 复杂度分析
本节将从时间复杂度与空间复杂度2个层面分析AOSELM算法的计算复杂度.初始化阶段,假设用于训练的实例数为N0,由于AMC模块需要交叉验证确定最佳的隐含层节点数,因此初始化阶段时间开销为O(N0×(Tp+Tu)×2Nin),其中Tp和Tu分别为OSELM算法1次预测和更新的时间开销,Nin为输入层的节点数.但由于实验中N0占总实例数的比值均小于3%,且实际应用中数据流往往不断产生,因此我们更关心在线学习阶段的时间和空间复杂度.
在时间复杂度方面,假设在线学习阶段数据总数为N.首先所有实例都需要进行预测,因此时间开销为O(N×Tp).假设有N1个正确预测实例,由于预测正确则直接结束这一轮的在线学习,避免更新模型,所以这部分额外的时间开销可以忽略.对于预测错误的N-N1个实例,首先需要进行概念漂移检测,当发生概念漂移检测结果是警告或漂移时(假设有N2个实例),均需要在线更新模型,由于概念漂移检测和更新遗忘因子的时间开销可以忽略,因此AFF模块时间开销为O(N2×Tu).剩下的N-N1-N2个实例需要进行异常点检测,由于需要Nm个模型进行预测,因此OD模块时间开销为O((N-N1-N2)×Nm×Tp)的时间.最后,当判断为异常点时,直接跳过本次实例,而当判断不是异常点时(假设有N3个实例),需要在线更新模型,这部分时间消耗为O(N3×Tu).因此AOSELM在线学习阶段时间开销为O(N×Tp+(N2+N3)×Tu+(N-N1-N2)×Nm×Tp).由于Tu≫Tp,因此AOSELM算法的时间复杂度与模型预测错误的实例个数(N-N1)成正比.
在空间复杂度方面,AOSELM算法采取的是在线学习方式,对每个实例逐个处理,学习完后直接删除旧的实例数据,只是额外增加了1个(Nh×No+1,Nm)大小的矩阵储存模型参数β以及1个(Np,1)大小的矩阵储存最近的Np个预测结果.由于本文实验中输出层节点数No均为1,因此,额外增加的内存消耗约为O(Nh×Nm+Nm+Np),由于Nh,Nm和Np都是常量,且实验中设定的数值都很小,所以AOSELM算法的空间复杂度为O(1).
3 实验与结果
为了验证本文提出的AOSELM算法的性能以及其对概念漂移数据流的适应性,本文在理论研究的基础上进行了大量的实验.本节主要介绍实验环境和数据集、参数敏感性分析、算法性能对比以及通过消融实验来衡量AOSELM算法所引入的3个机制的效果.验证实验的设计、性能评估以及算法机制分析是本节的核心内容.
3.1 实验数据集
为了验证AOSELM算法的性能,实验数据集选取5个人工合成数据集和2个真实数据集,实验数据集简要信息如表1所示.实验中默认所有算法的训练集实例数为500,惩罚参数C=0.1.本文实验平台为Windows 10,CPU为Intel i7-2.5 GHz,内存为8 GB,所有分类算法均基于Python语言实现.
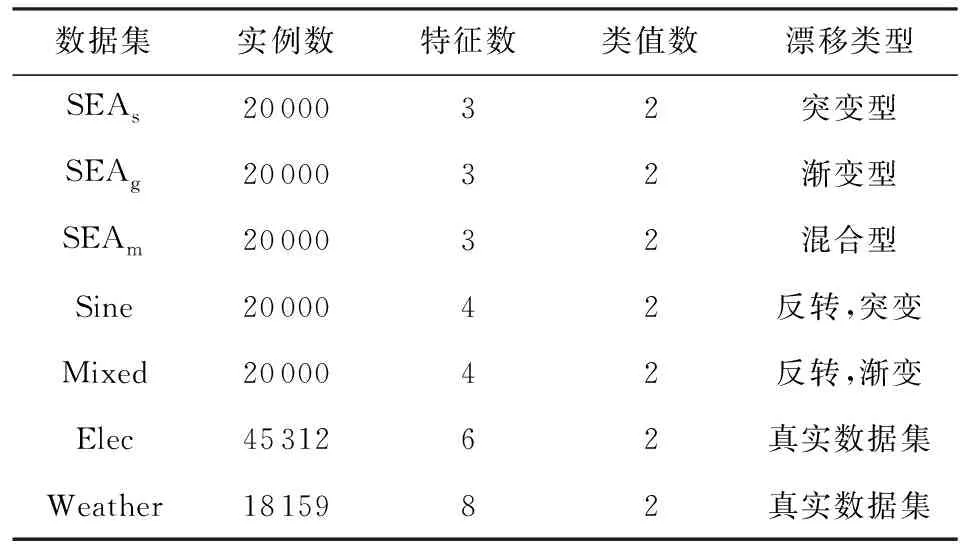
Table 1 Experimental Data Set Information表1 实验数据集信息
1) SEAs,SEAg和SEAm数据集.SEA生成器在SEA算法[22]中被提出.通过改变阈值,可以模拟概念漂移.数据集中含有3个属性,其中只有2个属性是相关的.通过使用SEA生成器生成了3个数据集,每个数据集包含20 000个实例,并添加了3%的噪声.另外,3个数据集均包含2次概念漂移,且都发生在实例编号为5 000和15 000的位置.其中,SEAs数据集包含2次突变型概念漂移;SEAg数据集包含2次渐变型概念漂移;SEAm数据集包含1次突变型概念漂移和1次渐变型概念漂移.
2) Sine数据集.数据集中含有4个属性,其中只有2个属性是相关的.数据集包含20 000个实例,且在5 000,10 000,15 000这3个位置发生突变型反转,即概念漂移前后目标值刚好相反.
3) Mixed数据集.数据集中含有4个属性,其中只有2个属性是相关的.数据集包含20 000个实例,且在5 000,10 000,15 000这3个位置发生渐变型反转,即概念漂移前后目标值刚好相反.
4) Elec数据集.是广泛应用于数据流学习中的真实数据集.该数据集是来自澳大利亚新南威尔士州电力市场1995—1998年的部分数据,包含45 312个实例.数据集一共包含6个相关属性,由于那里的电力价格不是固定的,而是根据供求关系而变化,因此目标是预测每天电力价格的变化(1表示上升,0表示下降).
5) Weather数据集.包含1949—1999年在内布拉斯加州Bellevue收集的天气信息,包含18 159个实例.数据集一共包含8个相关属性,目的是预测给定日期是否下雨.
3.2 对比算法
将本文提出的AOSELM算法与其他6种数据流在线分类算法进行性能比较,分别是:
1) OSELM算法.由Liang等人[11]于2006年提出,该算法是Huang等人[9]提出的极限学习机ELM算法的在线学习方法,具有速度快、分类性能好的优势,被广泛应用.
2) ROSELM(regularized online sequential extreme learning machine)算法.由Huynh等人[23]于2011年提出,该算法将正则化技术引入OSELM,从而提高了分类器的泛化能力.
3) FROSELM算法.由杜占龙等人[19]于2015年提出,该算法将将遗忘因子FF方法和正则化技术引入OSELM,根据实例的时间顺序分别为每个样本分配不同的权重.
4) FGROSELM算法.由Guo等人[20]于2018年提出,该算法采用一种新的广义正则化方法来代替传统的指数遗忘正则化,使算法具有恒定的正则化效果以及更好的概念漂移适应能力.
5) 霍夫丁树(Hoeffding tree, HT)算法.由Domingos等人[24]提出,是一个流行的增量决策树算法,其创造性地使用Hoeffding界确定选择划分属性时所需的样本数,在很多研究中具有优秀的分类性能.
6) 朴素贝叶斯(naive Bayes, NB)[25]算法.是一种广泛应用的分类算法,以其简单性和低计算量而闻名,实验中使用的是传统朴素贝叶斯算法的在线学习版.
3.3 参数敏感性分析
为了解释引入自适应模型复杂度机制(AMC)、自适应遗忘因子和概念漂移检测机制(AFF)的动机,本节设计了参数敏感性分析实验,用来验证隐含层节点数Nh和遗忘因子λ对模型分类性能的影响.
图3展示了不同隐含层节点数Nh值下OSELM算法在不同数据集上的分类准确率.从中可以发现,当隐含层节点数Nh太小时,模型的学习能力不够,因此分类器的性能不佳.而隐含层节点数Nh太大又会加大模型的复杂度,从而大大增加模型的学习时间.目前大多数算法都采用提前指定隐含层节点数Nh的方式进行学习,这显然不能取得最佳的性能,不同数据流因为特征数不同、输入和输出之间的映射关系复杂程度不同等原因,具有不同的最佳隐含层节点数Nh.因此AOSELM算法引入了自适应模型复杂度机制,在初始化阶段,采用交叉验证的方式确定该数据集的最佳隐含层节点数.
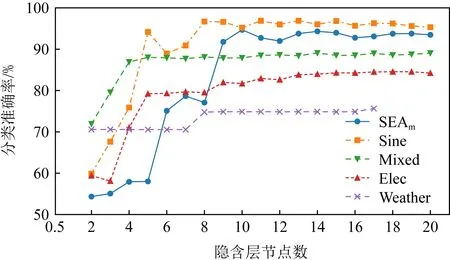
Fig. 3 Classification accuracy of OSELM with different Nh values on different data sets图3 不同Nh值OSELM在不同数据集的分类准确率
图4和图5分别展示了不同遗忘因子λ值下FROSELM算法在Sine数据集上的分类准确率和累计分类准确率.从图4、图5中可以发现,当遗忘因子λ较大时,虽然分类器能够在数据流稳定时期取得更好的分类准确率,但当数据流发生概念漂移时却更难适应新概念,从而降低了模型累计分类准确率.相反地,当遗忘因子λ较小时,虽然分类器能够更快地遗忘旧模型,从而更好地适应概念漂移,但在数据流稳定时期却丧失了更好的分类性能.由于我们往往无法提前获知是否发生概念漂移、概念漂移发生的位置以及概念漂移发生的类型,因此有必要引入自适应遗忘因子机制.
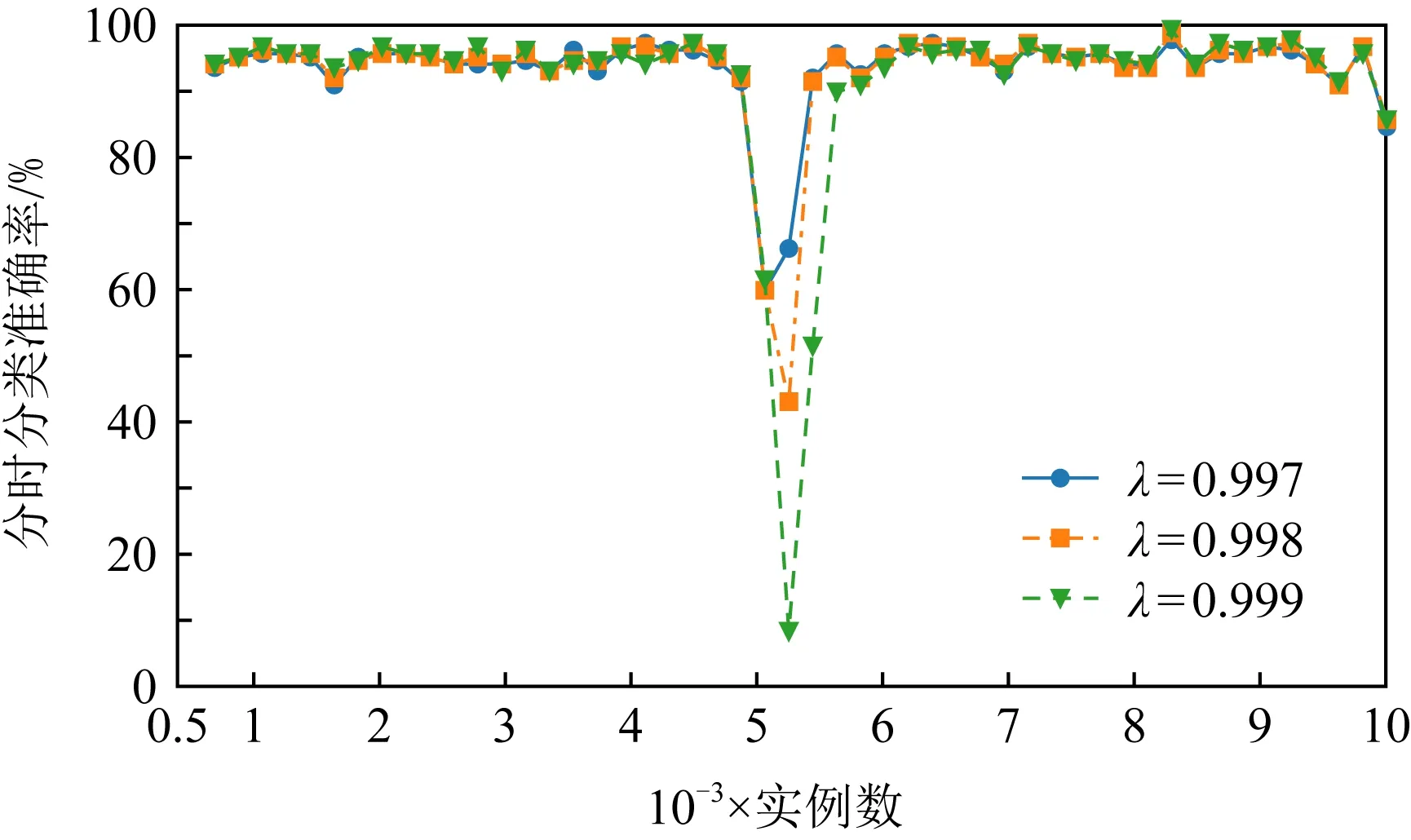
Fig. 4 Classification accuracy of FROSELM with different λ on Sine图4 不同λ值FROSELM在Sine的分类准确率

Fig. 5 Cumulative classification accuracy of FROSELM with different λ on Sine图5 不同λ值FROSELM在Sine的累计分类准确率
AOSELM算法借鉴DDM方法提出了概念漂移指数ICD,并将概念漂移指数ICD和遗忘因子λ相结合,使模型能够根据当前数据流概念漂移情况自适应地调整遗忘因子λ大小,从而使模型能更好地适应数据流的变化.
3.4 对比实验
在对比实验中,将AOSELM算法与相关的算法进行对比,包括FGROSELM,FROSELM,ROSELM,OSELM,HT,NB.其中HT和NB是传统分类器的在线方法,具有简单、高效、易于理解的特点.而FGROSELM,FROSELM,ROSELM以及本文所提出来的AOSELM均是基于OSELM优化的算法.在对比的7种算法中,只有FGROSELM,FROSELM,AOSELM这3种算法引入了遗忘机制.
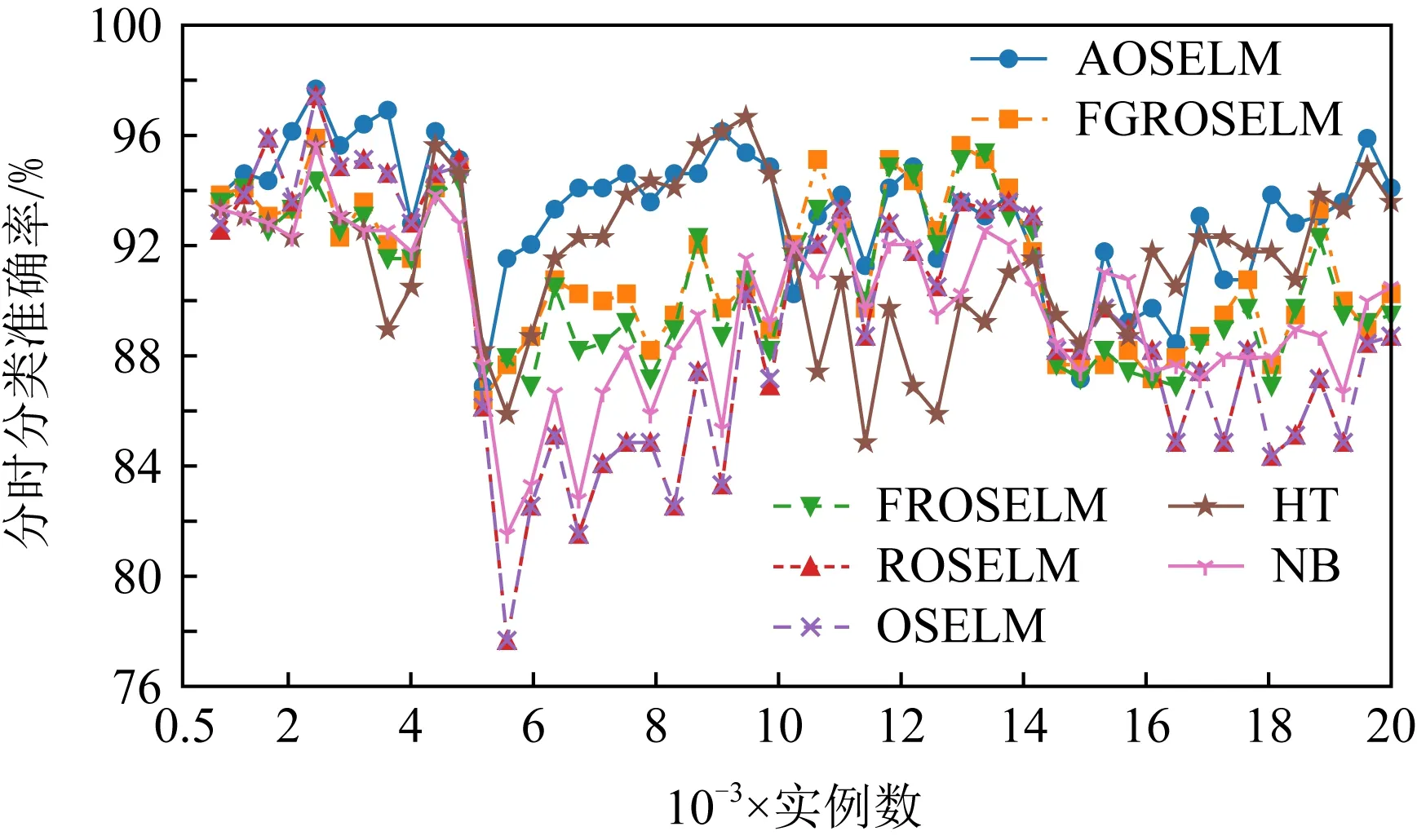
Fig. 6 Classification accuracy of contrast algorithm on SEAm图6 对比算法在SEAm上的分类准确率
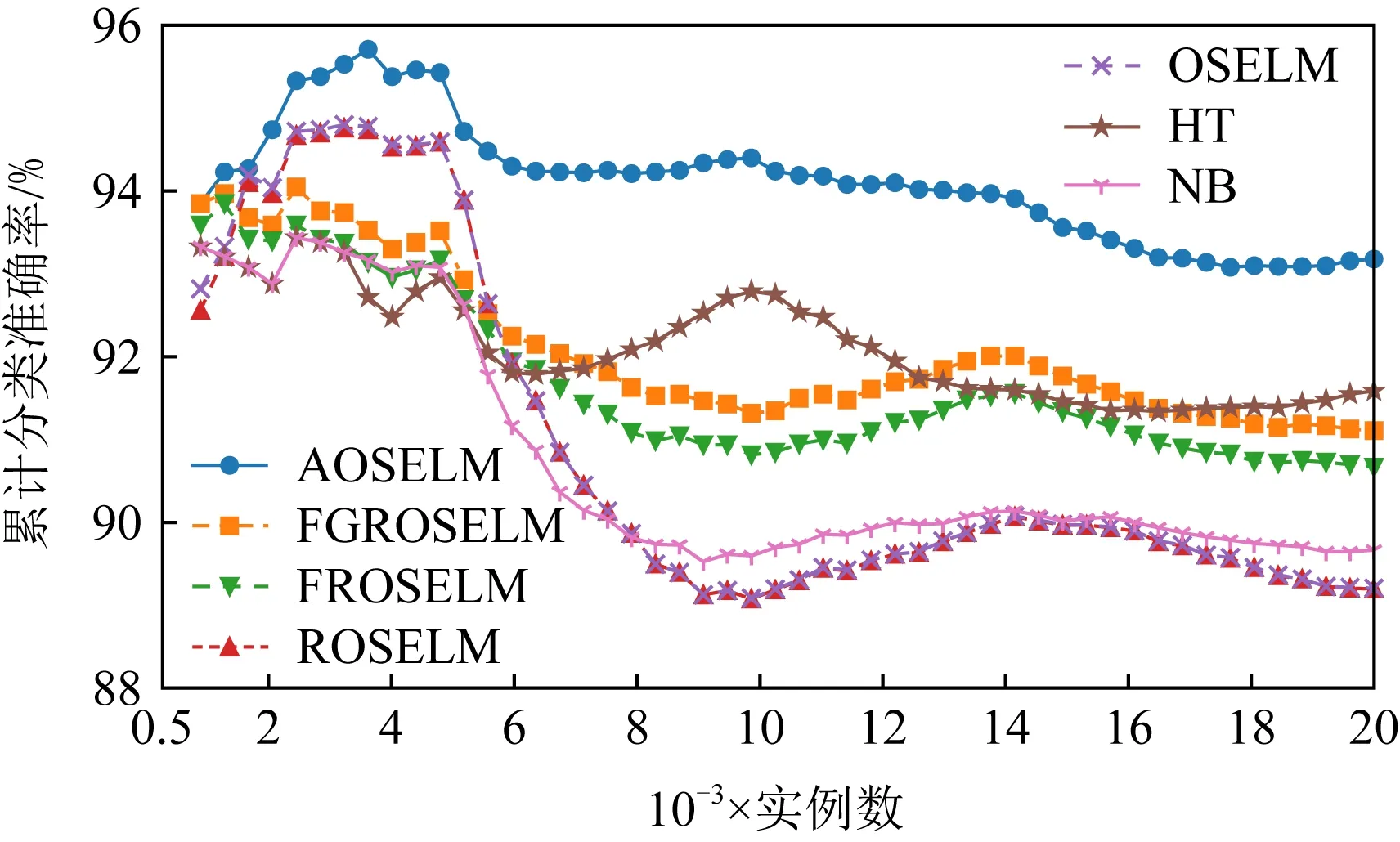
Fig. 7 Cumulative classification accuracy of contrast algorithm on SEAm图7 对比算法在SEAm上的累计分类准确率
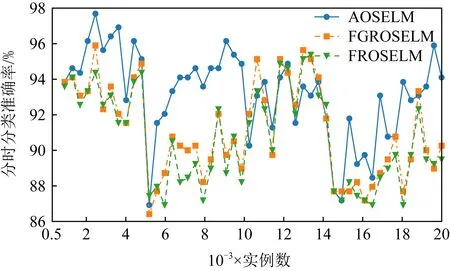
Fig. 8 Classification accuracy of OSELM optimization algorithm on SEAm图8 OSELM优化算法在SEAm上的分类准确率
图6~9分别展示了全部7种对比算法和具有遗忘机制的3种OSELM优化算法在SEAm数据集上的分类准确率和累计分类准确率.从图7中可以看出7种算法均能在面对概念漂移时更新分类器,从而适应新概念,但ROSELM,OSELM,NB这3种算法表现较差.而从图8的分类准确率中可以看出,当发生概念漂移后,AOSELM算法相比另外2种同样具有遗忘机制的FGROSELM和FROSELM算法能够更快地适应概念漂移,分类性能也能在概念漂移发生后更快反弹.从累计分类准确率中可以看出,AOSELM算法具有更好的分类性能,分类准确率比FGROSELM和FROSELM这2种算法提高了大约2.5%.
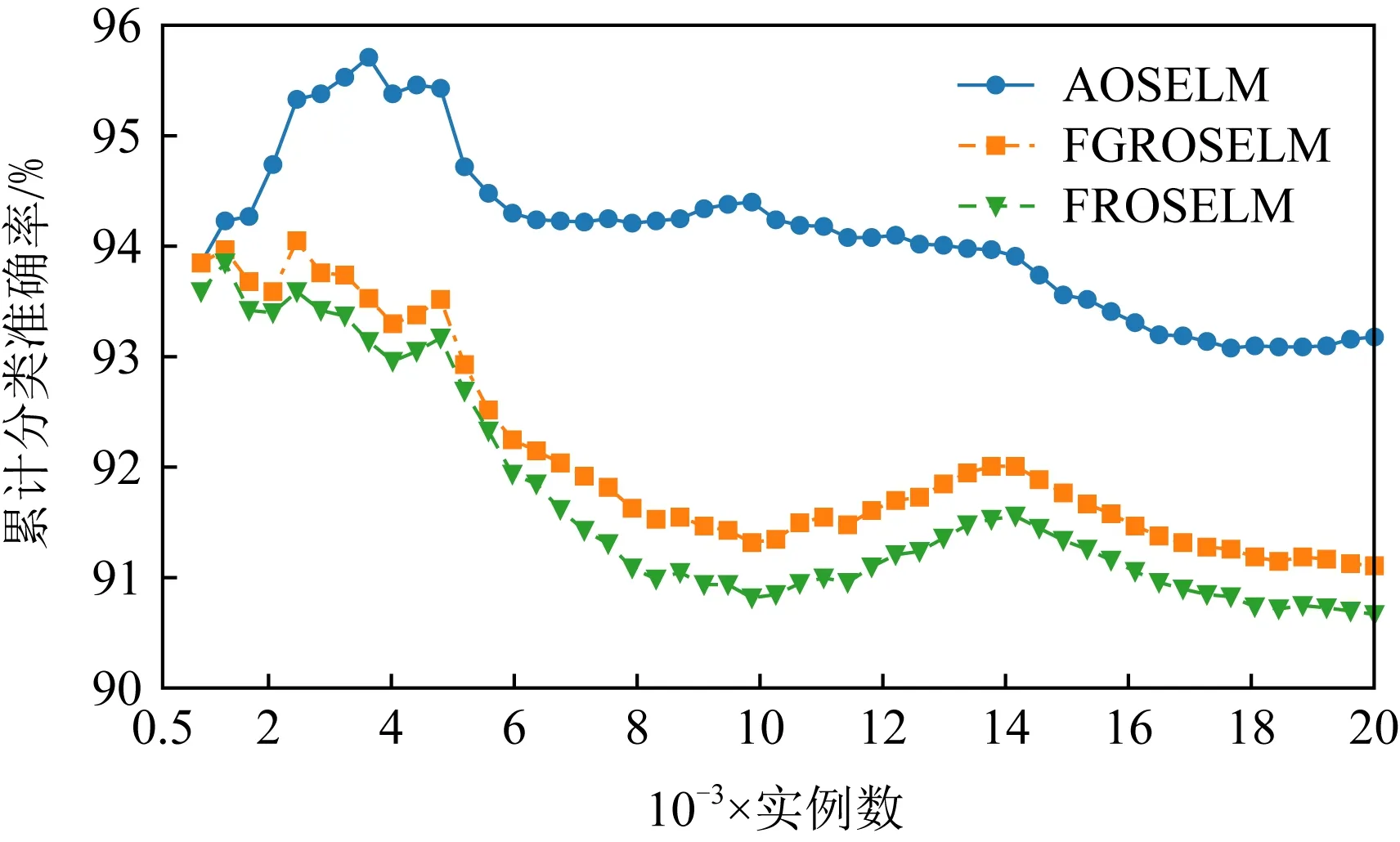
Fig. 9 Cumulative classification accuracy of OSELM optimization algorithm on SEAm图9 OSELM优化算法在SEAm上的累计分类准确率
图10~13分别展示了全部7种对比算法和具有遗忘机制的3种OSELM优化算法在Sine数据集上的分类准确率和累计分类准确率.从图10~13中可以看出,当出现反转型概念漂移时,ROSELM,OSELM,HT,NB这4种算法由于不具备遗忘机制,因此完全无法适应反转型概念漂移,整体分类性能也非常糟糕.而具有遗忘机制的AOSELM,FGROSELM,FROSELM这3种算法在面对反转型概念漂移时均能做出有效反应,适应新概念.其中,AOSELM算法又比另外2种算法具有更高的分类准确率以及更快的概念漂移适应能力.当检测到发生概念漂移时,AOSELM算法能够自适应地调小遗忘因子λ,可以更快地遗忘旧概念,从而具有更高的整体分类准确率,实验结果显示比FGROSELM和FROSELM算法高大约3%.
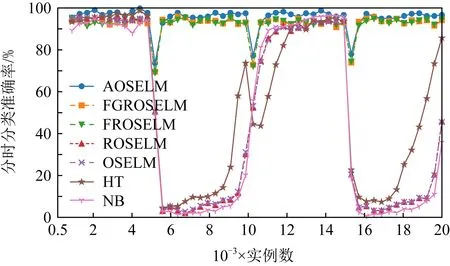
Fig. 10 Classification accuracy of contrast algorithm on Sine图10 对比算法在Sine上的分类准确率
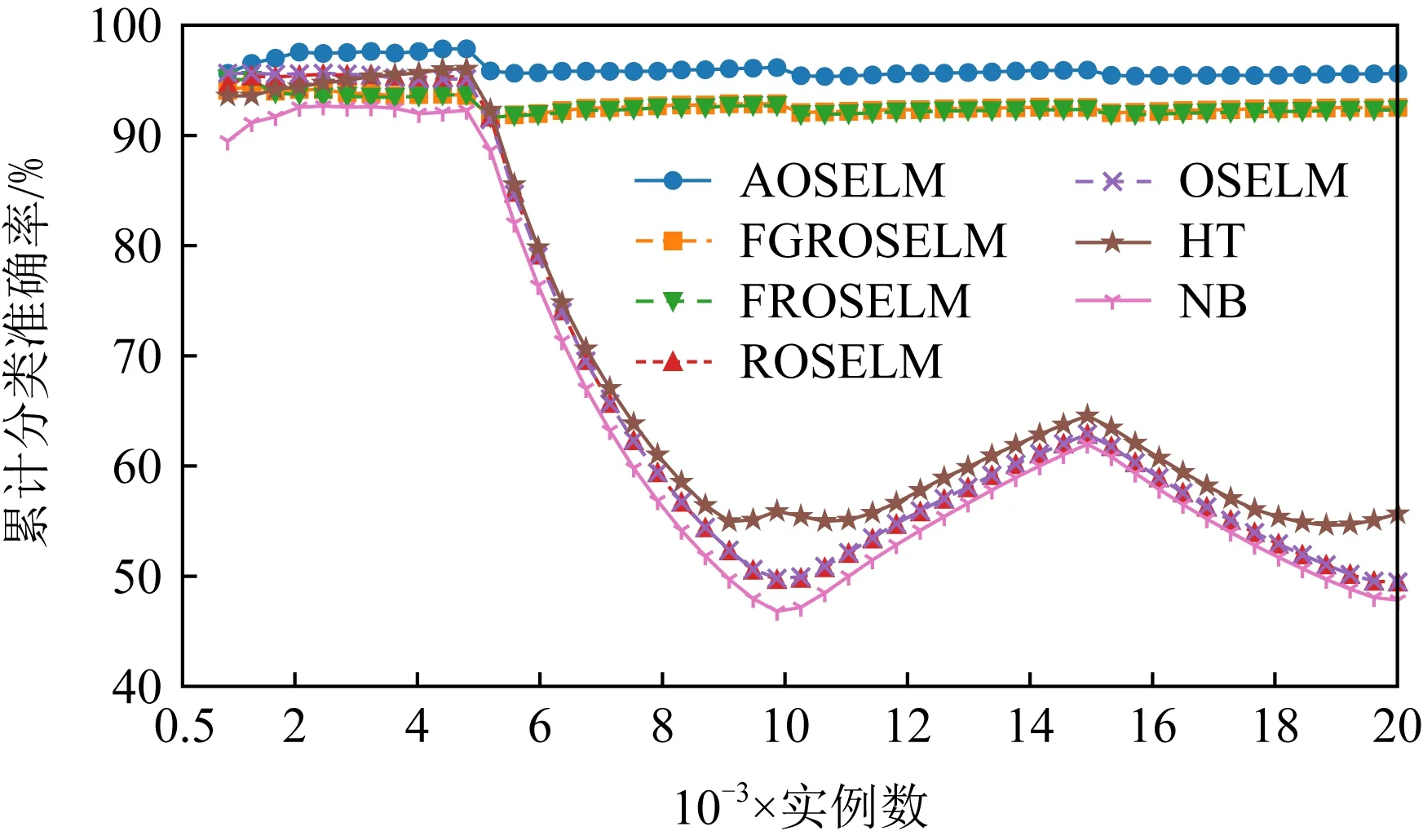
Fig. 11 Cumulative classification accuracy of contrast algorithm on Sine图11 对比算法在Sine上的累计分类准确率
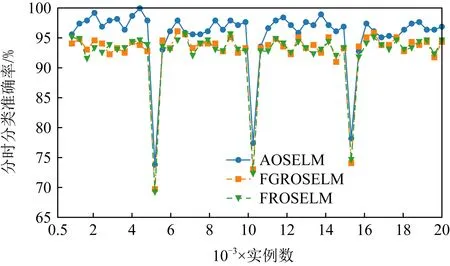
Fig. 12 Classification accuracy of OSELM optimization algorithm on Sine图12 OSELM优化算法在Sine上的分类准确率
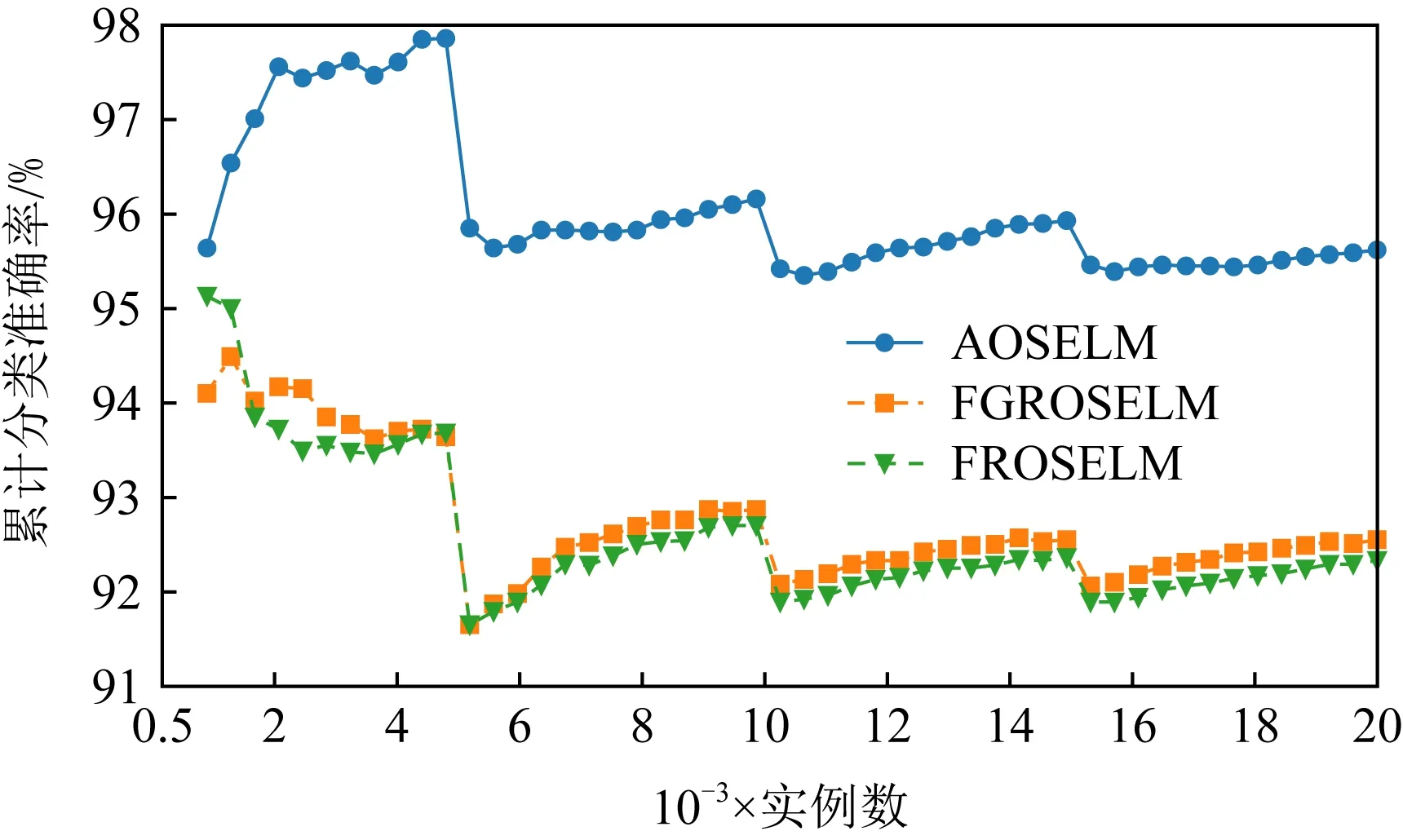
Fig. 13 Cumulative classification accuracy of OSELM optimization algorithm on Sine图13 OSELM优化算法在Sine上的累计分类准确率
表2、图14和图15展示了AOSELM算法和对比算法在不同数据集上的平均分类准确率.从表2中可以看出,在5个人工数据集上,AOSELM均展示了更好的分类性能,分类准确率比其他对比算法提高明显.尤其是在反转型数据集Sine和Mixed上,不具备遗忘机制的ROSELM,OSELM,HT,NB这4种算法表现十分糟糕,而AOSELM却仍然能保持很高的预测准确率.相比另外2种具有遗忘机制的FGROSELM和FROSELM算法,AOSELM也能提高2~3%.
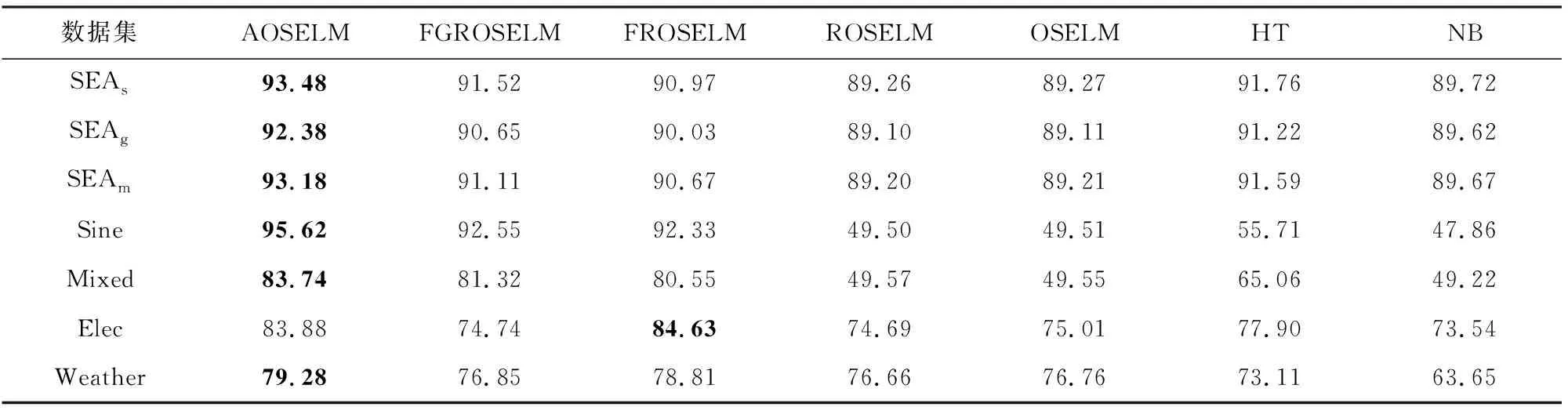
Table 2 Classification Accuracy of Contrast Algorithms on Different Data Sets表2 对比算法在不同数据集上的分类准确率 %
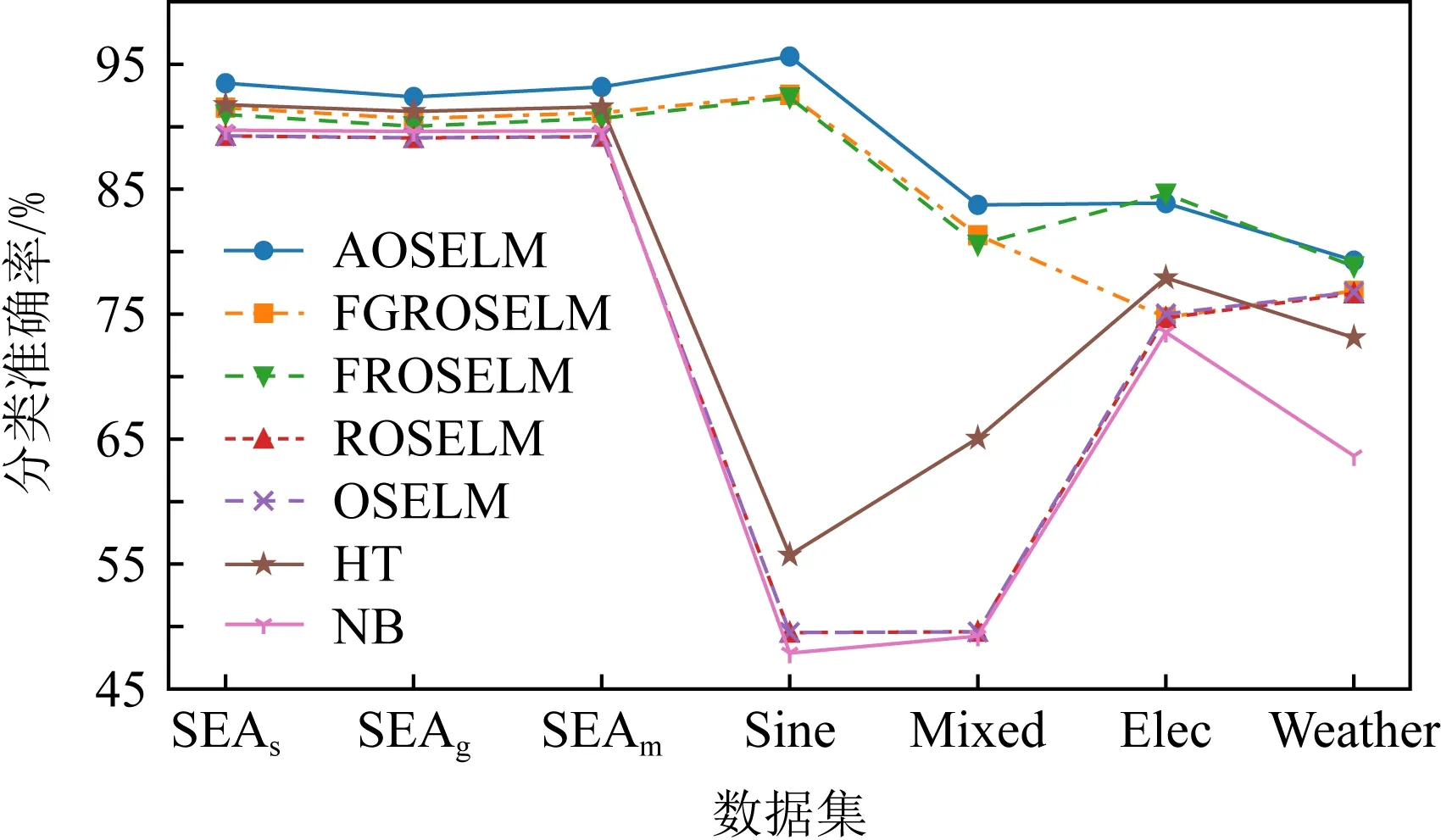
Fig. 14 Classification accuracy of contrast algorithm on different data sets图14 对比算法在不同数据集上的分类准确率
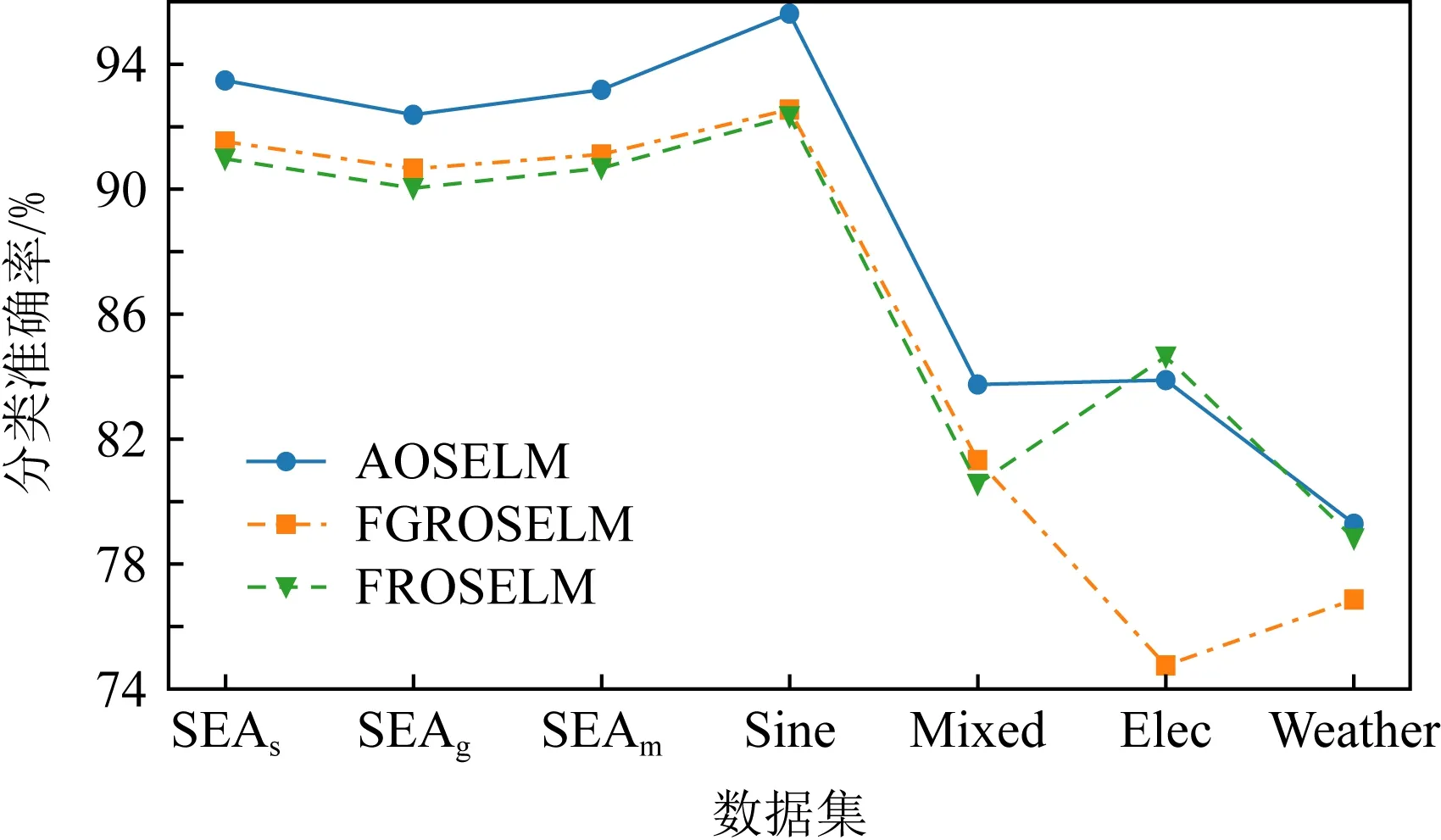
Fig. 15 Classification accuracy of OSELM optimization algorithm on different data sets图15 OSELM优化算法在不同数据集的分类准确率
但在2个人工数据集上,AOSELM算法虽然比多数对比算法具有明显性能优势,但与FROSELM算法表现相当,并未能取得更高的分类准确率.针对这种情况,画出人工数据集Sine、真实数据集Elec和Weather的概念漂移指数ICD监控过程图,如图16~18所示.
图16~18分别展示了人工数据集Sine、真实数据集Elec以及真实数据集Weather的概念漂移监控过程图.对比可以发现,在人工数据集中,概念漂移是明确发生的,且在非概念漂移位置,数据流是稳定的,概念漂移指数ICD也基本稳定在[-1, 0]之间.而在真实数据集Elec和Weather中,数据流一直处于混乱的状态,概念漂移指数ICD一直在-1上下波动,同时没有明确的概念漂移发生点,并不能激活AOSELM算法中的自适应遗忘因子和概念漂移检测机制.这解释了为何AOSELM算法没有比FROSELM算法在真实数据集上具有更好的分类性能.
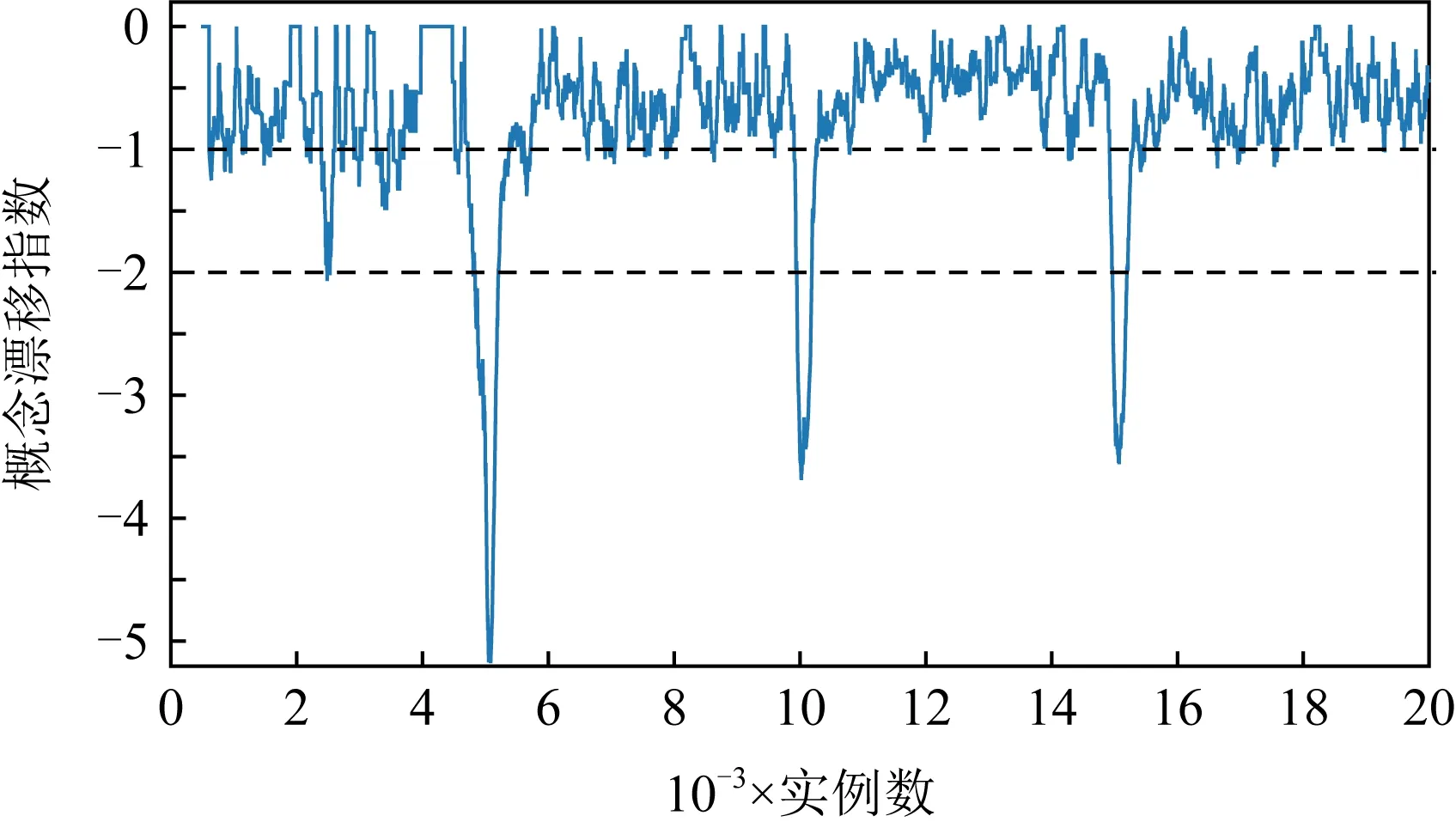
Fig. 16 Concept drift monitoring diagram on Sine图16 人工数据集Sine概念漂移监控过程图
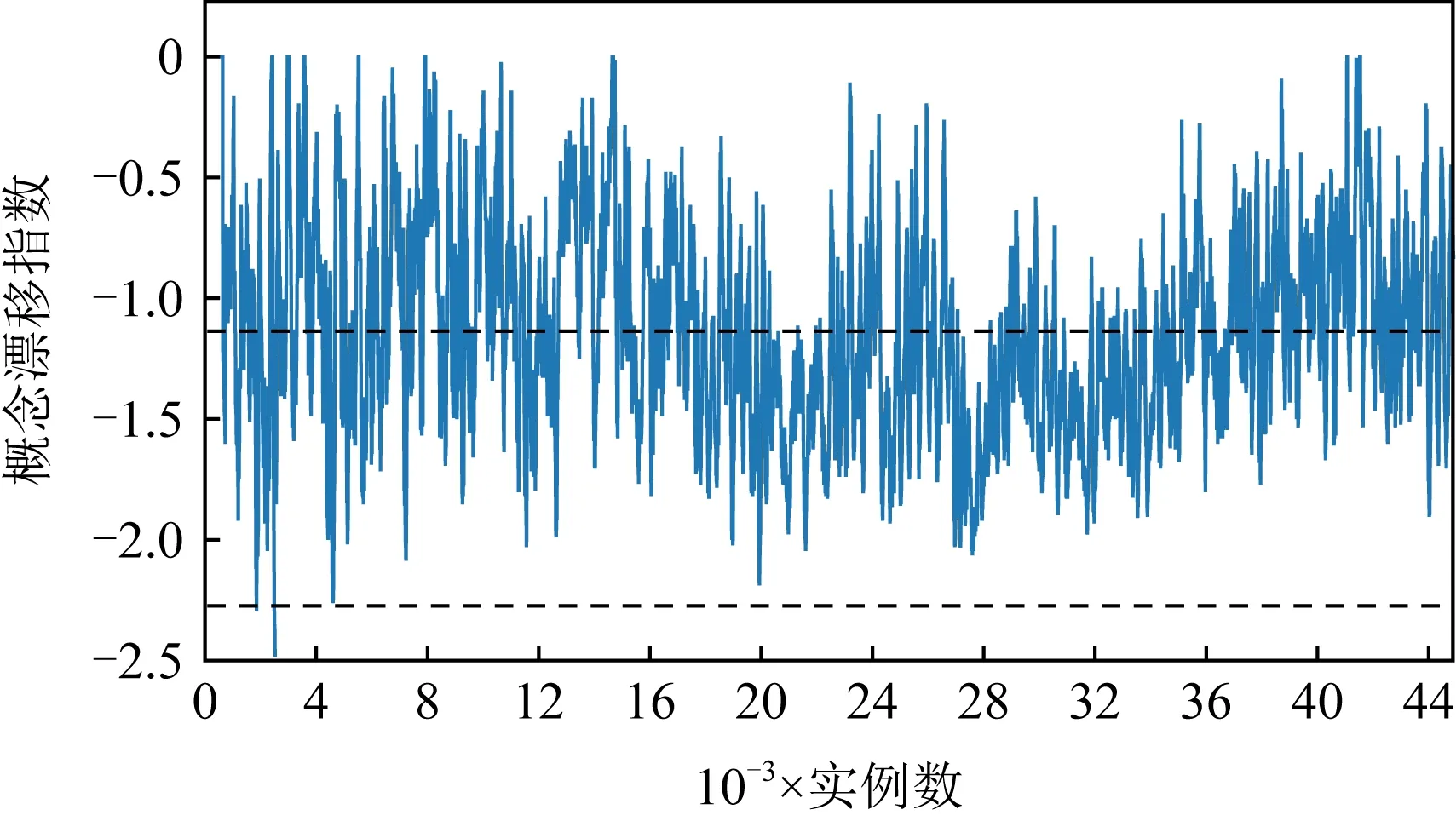
Fig. 17 Concept drift monitoring diagram on Elec图17 真实数据集Elec概念漂移监控过程图
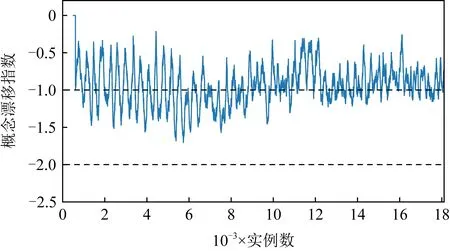
Fig. 18 Concept drift monitoring diagram on Weather图18 真实数据集Weather概念漂移监控过程图
3.5 算法机制分析
本节通过消融实验来测量AOSELM算法所引入的自适应模型复杂度(AMC)、自适应遗忘因子和概念漂移检测(AFF)以及异常点检测(OD)这3种机制的效果.在消融实验中,通过将AOSELM算法中省略机制相应的模块,得到AOSELM_del_AMC,AOSELM_del_AFF,AOSELM_del_OD这3种算法,然后对比性能.
图19~22分别展示了消融实验在SEAm和Sine数据集上的分类准确率和累计分类准确率.从图19~22中可以发现,当删除了AMC机制后,AOSELM_del_AMC算法在在线学习的初始阶段性能表现较差.而当删除了AFF机制后,AOSELM_del_AFF算法在面对概念漂移时适应的速度最慢,整体性能也更容易受到概念漂移的影响,尤其在Sine数据集发生反转型概念漂移时,分类器整体性能损失非常大.
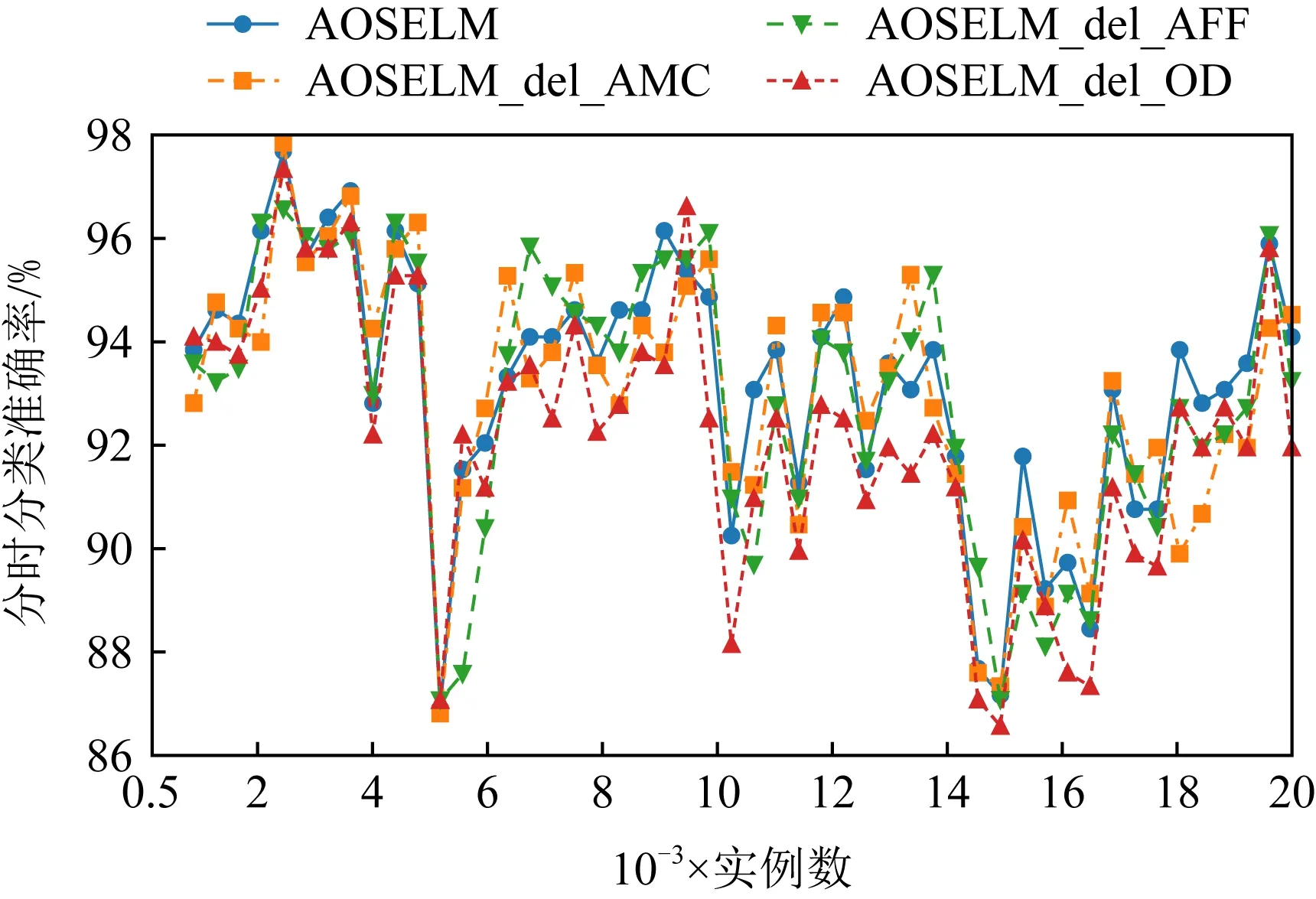
Fig. 19 Classification accuracy of ablation experiment on SEAm图19 消融实验在SEAm上的分类准确率

Fig. 20 Cumulative classification accuracy of ablation experiment on SEAm图20 消融实验在SEAm上的累计分类准确率

Fig. 21 Classification accuracy of ablation experiment on Sine图21 消融实验在Sine上的分类准确率
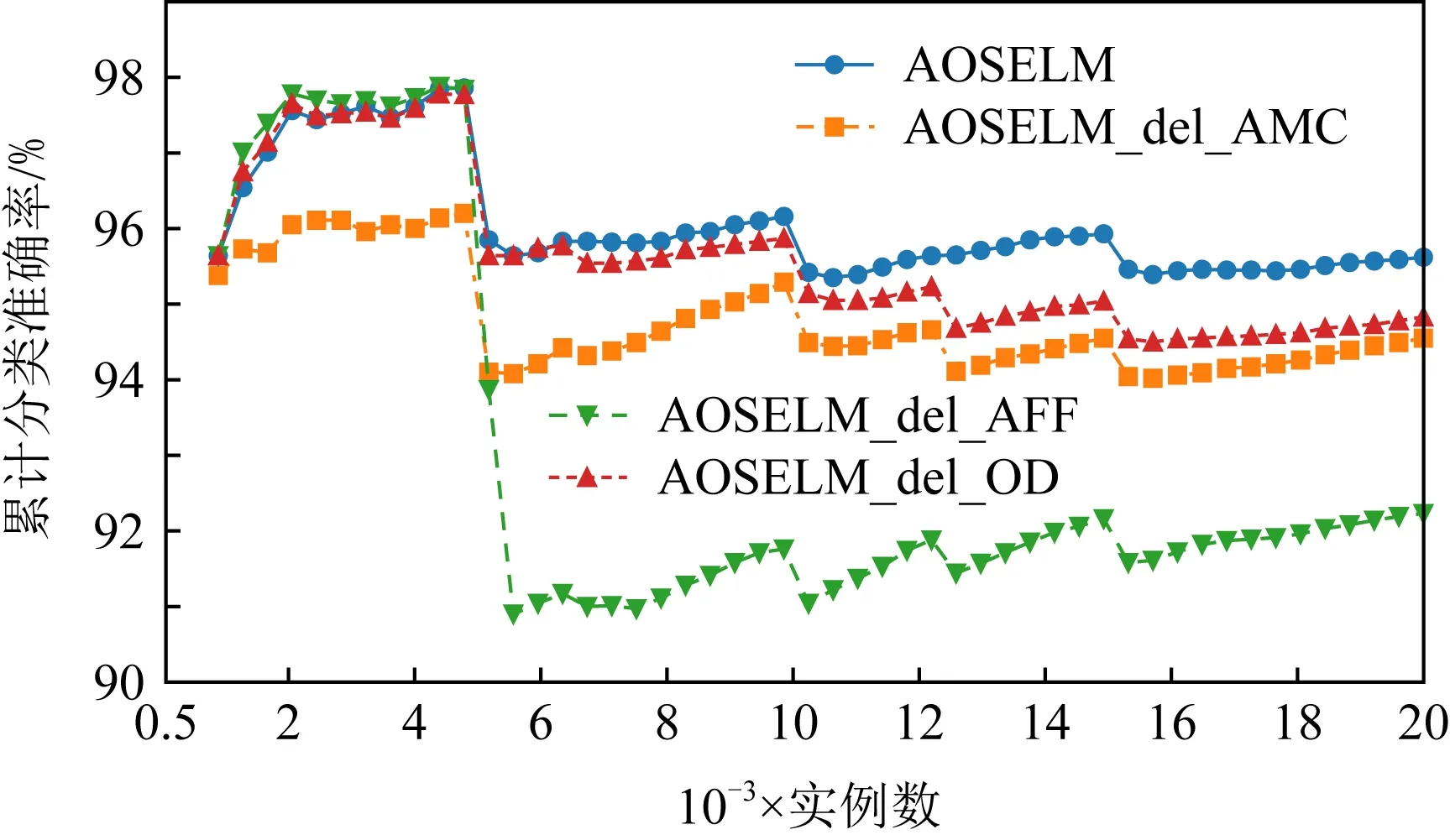
Fig. 22 Cumulative classification accuracy of ablation experiment on Sine图22 消融实验在Sine上的累计分类准确率
表3和图23展示了消融实验在不同数据集上的平均分类准确率.实验结果表明:AOSELM算法引入的自适应模型复杂度(AMC)、自适应遗忘因子和概念漂移检测(AFF)以及异常点检测(OD)这3种机制均起到了很好的效果,在人工数据集上均提高了分类器的分类准确率.
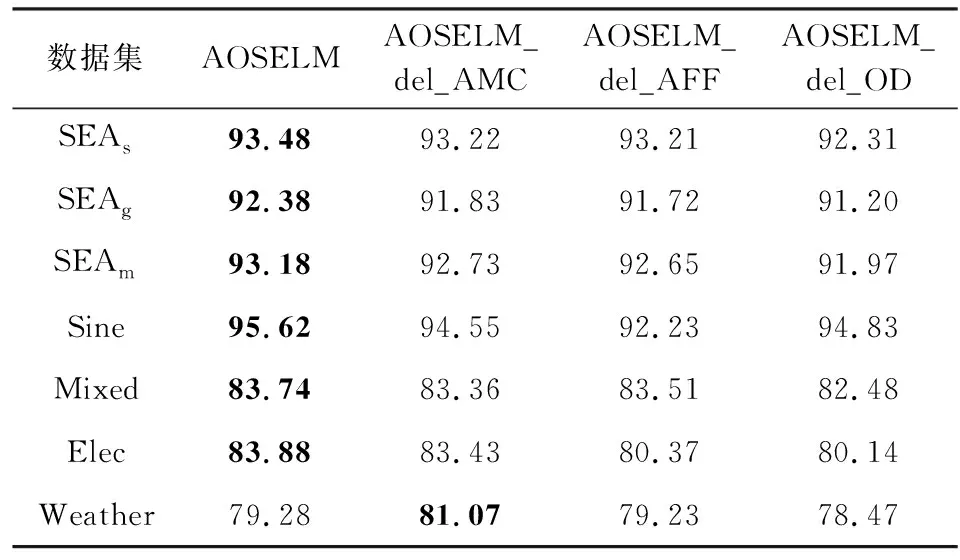
Table 3 Classification Accuracy of Ablation Experiment on Different Data Sets
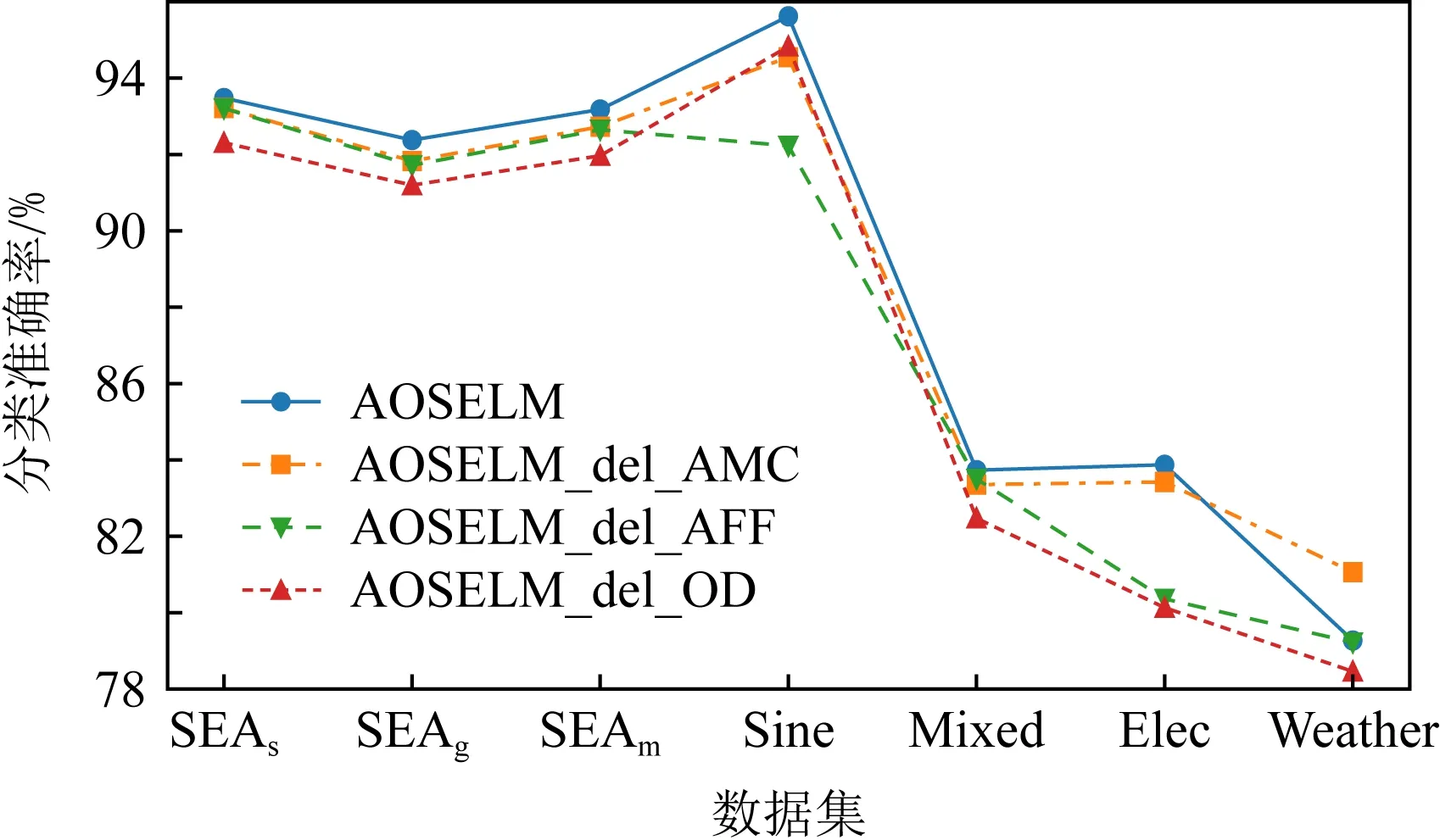
Fig. 23 Classification accuracy of ablation experiment on different data sets图23 消融实验在不同数据集上的分类准确率
3.6 算法效率分析
在线学习要求分类算法能及时反馈分类结果,为了验证AOSELM算法的分类效率,实验统计了AOSELM算法的时间开销,并与原始的OSELM算法进行对比.实验结果为重复10次实验的平均值,如表4所示:
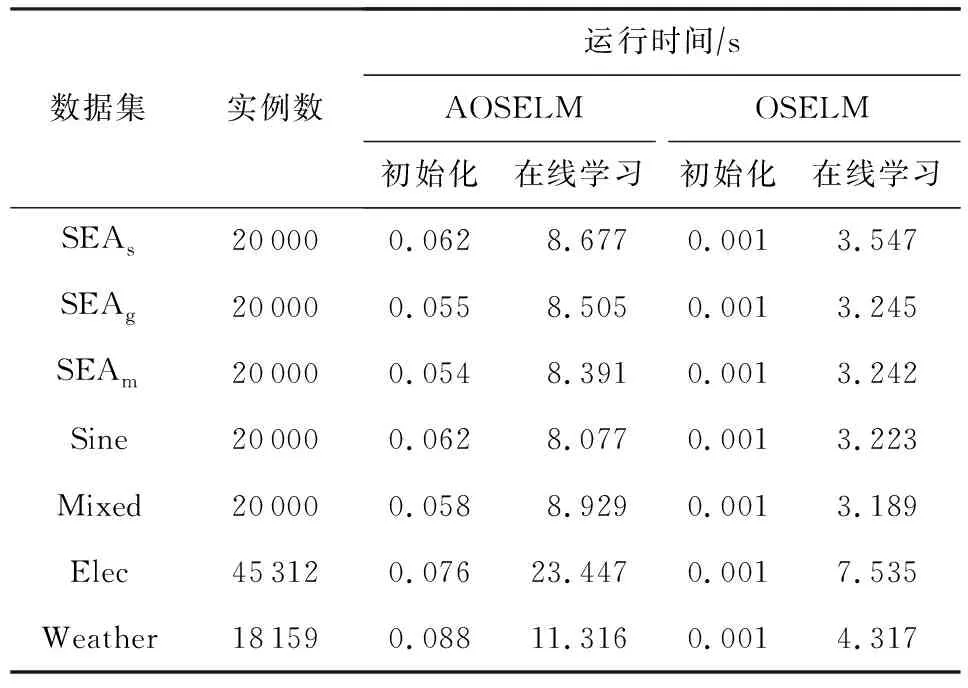
Table 4 Running Time of Contrast Algorithms on Different Data Sets
从表4中可以看出,在初始化阶段,AOSELM算法由于引入AMC机制,运行时间比原始OSELM算法高出50倍以上,但由于用于训练的实例数占比很小,因此初始化阶段的时间消耗在整体上可以忽略.在线学习阶段,AOSELM算法的运行时间为OSELM算法的2~3倍.此外,AOSELM算法的预测准确率越高,运行时间相比OSELM的倍数越低,验证了AOSELM算法的时间复杂度与模型预测错误率成正比.
4 总 结
本文提出了一种自适应在线顺序极限学习机(AOSELM)算法,其基于在线学习方式,引入了自适应模型复杂度机制、自适应遗忘因子和概念漂移检测机制以及异常点检测机制,从而可以在动态变化的数据流环境下应对多种类型的概念漂移.通过自适应模型复杂度机制,在初始化阶段可以自适应确定出最佳的隐含层节点数Nh,并加入正则项,优化模型复杂度.其次通过自适应遗忘因子和概念漂移检测机制,将概念漂移和遗忘因子结合,使分类模型在发生概念漂移时自动调小遗忘因子,而在数据流稳定时自动调大遗忘因子,从而适应数据流的动态变化.最后通过异常点检测机制,增强模型抗噪音能力,使分类的决策边界不易被异常点破坏.因此,AOSELM算法能够自适应地在线处理各种类型的概念漂移数据流.
在仿真实验部分,通过参数敏感性分析验证了隐含层节点数Nh和遗忘因子λ对模型分类性能的影响,解释了引入自适应模型复杂度机制与自适应遗忘因子和概念漂移检测机制的动机.然后在对比实验中,通过将AOSELM算法与其他6个数据流分类器进行对比,验证了AOSELM算法的有效性,尤其是在5个人工数据集上,AOSELM算法表现出了更稳定、更准确的分类效果.最后,通过消融实验验证所引入AMC,AFF,OD这3种机制的效果,证实了3种机制对AOSELM算法性能提升的有效性.然而,如何解决更复杂的真实数据流分类问题仍然是研究的难点,下一步工作将结合代价敏感学习和在线集成方法解决概念漂移数据流中的复杂分布问题.
作者贡献声明:蔡桓提出了算法思路并撰写论文;陆克中提出了实验方案;伍启荣负责完成实验;吴定明提出指导意见并修改论文.
猜你喜欢
航空学报(2022年7期)2022-09-05
现代电子技术(2022年15期)2022-07-28
华文教学与研究(2022年1期)2022-04-27
电子产品世界(2022年4期)2022-04-21
社会科学战线(2022年2期)2022-03-16
内燃机与配件(2022年2期)2022-01-17
计算机系统应用(2021年2期)2021-02-23
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
网络空间安全(2019年10期)2019-03-20
