
基于无监督深度学习的多聚焦图像融合
2022-05-25 13:21侯幸林周培培
常州工学院学报 2022年2期
侯幸林,周培培
(1.常州工学院汽车工程学院,江苏 常州 213032;2.常州工学院电气信息工程学院,江苏 常州 213032)
由于光学透镜的局限性,很难让不同景深的所有物体在一幅图像中都聚焦[1]。在这种背景下,多聚焦图像融合作为一种图像增强方法,可以将不同聚焦区域的图像进行融合,得到一幅完整清晰的图像,在多个领域具有良好的应用前景。近年来,多聚焦图像融合成为图像融合的热门领域[2]。
在过去的几十年里,研究人员提出了许多解决多聚焦图像融合问题的方法,可大致分为两类:空间域方法和变换域方法。在空间域融合方法中,通常基于像素、块或区域[3]。变换域方法的思想是将图像变换到其他域,并利用这些域的特征更有效地实现图像融合,如多尺度变换[4-5]、稀疏表示[6]或其他域表达方法[7-9]。
虽然已有方法都能产生融合结果,但仍有几个方面有待改进。一是传统方法需要手动设计图像度量指标和融合规则,这限制了融合结果。二是已有的许多方法通过生成决策图来进行多聚焦图像融合,如基于引导滤波器的方法GFDF[10],本质上更像是一个基于清晰度检测的分类问题。这些方法往往无法很好地对边界线附近的聚焦和散焦区域进行分类。三是多数基于深度学习的方法,如SESF[11]在生成决策图时都需要后处理,例如一致性检查,这大大增加了方法的复杂性。此外,这些方法通常需要人工构建决策图作为训练网络的基本依据,这进一步限制了此类方法的应用范围。
近年来,卷积神经网络发展迅速,凭借其较强的特征提取能力,基于神经网络的多聚焦图像融合方法在众多传统算法中脱颖而出。采用卷积神经网络的图像融合方法鲁棒性好[12],得力于深度模型的特征表征能力强。总的来说,图像融合的方法涉及监督和无监督两种,并往无监督的方向发展,但能否生成准确的决策图是整个问题的关键。Liu等[13]使用卷积神经网络(CNN)对聚焦和散焦区域进行分类,从而生成用于融合的决策图。值得注意的是,他们使用人工构建的决策图作为监督训练的基本依据,以提高分类的准确性。蒋留兵等[14]提出了一种基于U-Net的生成对抗网络模型,能够有效地提取多聚焦图像中的模糊特征, 且融合图像在信息全面性、相位一致性和感知相似性等方面表现优异。Guo等[15]基于条件生成对抗网络提出了一种新的多聚焦图像融合网络,该方法为多聚焦图像中的聚焦区域提供了更准确的决策图,然而,该网络需要有标签的训练数据进行监督学习。
本文构建了一个基于自编码器的深度学习网络模型,编码和解码网络均基于VGG-Net[16]设计,网络输出对应输入图像的权值,网络训练不需要对训练集数据进行标签标注,以输入-输出图像的结构相似度为评价指标,属于无监督训练网络。与现有方法相比,本文方法在定量与定性评价指标上均有较大改进。
1 无监督深度神经网络
本文设计了一个基于自编码器的无监督深度神经网络,网络输入为两幅不同聚焦的图像,网络输出为对应于两幅输入图像的权值大小,对输入、输出图像进行加权求和即可得到融合后的图像,融合图像的质量以结构相似度为目标,从而网络可以完成无监督训练。
1.1 基于自编码器的网络设计
图1所示为本文设计的基于自编码器的无监督深度网络结构示意图,为了避免彩色图像融合造成的色偏效应,将彩色多聚焦图像灰度化,以多聚焦灰度图像作为网络输入,网络输出为与输入图像同等大小的两幅权值图像,对输入输出加权求和,即可得到融合后的图像。如图1,基于自编码器的深度神经网络由两部分构成,前半部分为编码子网络,后半部分为解码子网络。
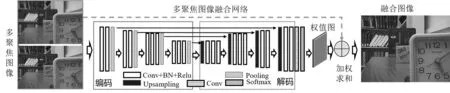
图1 基于自编码器的多聚焦图像融合网络示意图
如图1所示,定义重复出现次数最多的模块为子模块M:由卷积层(Conv)、归一化操作(BN)[17]和修正线性单元(ReLu)[18]共3部分组成。为了使两幅多聚焦图像在小的空间位移时具有平移不变性,模块M之后采用最大池化操作。编码子网络中多次使用最大池化操作使得原图可连续采样,为了在解码子网络的上采样中引用空间信息,需要在编码子网络的输出特征图中记录中间最大池化的输出数据。本文设计的编码子网络采用了VGG-Net网络的前10个卷积层。
解码子网络的设计以编码子网络的结构为参考,由图1可见,对称设计解码子网络即可,其中编码子网络中的最大池化层,在解码子网络中对应于上采样层,同样设计子模块M。解码器输出为64维的图像大小的特征图,再经过卷积层和回归层,可得到权值图。
1.2 损失函数
本文网络无需对训练数据进行标签标注,属于无监督训练,因此,网络能够自动收敛到最优目标是损失函数设计的初衷。网络的两幅多聚焦融合图像记为f1和f2,融合后的图像记为F,为了在融合图像中保留不同输入图像中的聚焦部分,即需要获取不同图像中同一区域下细节更丰富的部分,因此,损失函数的设计应以图像中局部细节的丰富程度来度量。
局部图像结构相似度[19]往往被用来定量评估融合图像的细节质量,本文中基于图像结构相似度设计损失函数,如式(1)所示:
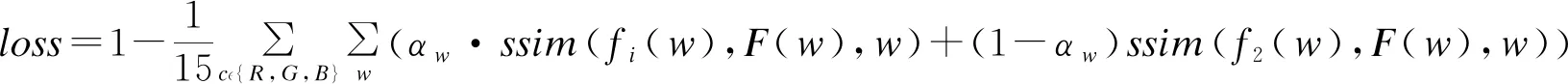
(1)
式中:αw是加权系数,该值的设计参考图像的局部方差;ssim用于衡量两个图像块的结构相似度,如式(2)所示:
ssim(x,y,w)=
(2)
本文中图像局部区域质量评价指标中加权系数以局部方差来表示,不同聚焦条件下的输入图像局部方差越大,对应图像区域的加权系数取值越大,αw如式(3)所示:
(3)
图像局部区域的方差s在图像区域窗口w内的计算方法如式(4)所示:
(4)
式中:为避免出现奇点,设置s(w) = max(s(w),0.000 1)。
1.3 无监督网络的训练
为了提升多聚焦图像的融合效果,训练过程中,本文提出的无监督深度神经网络采用了多尺度图像区域来评价多聚焦融合图像与多聚焦输入图像的结构相似度,实验中选择了5种不同尺度的窗口,分别为3×3、5×5、7×7、9×9、11×11,此外,本文通过对RGB三通道的结构相似度分别计算后取均值得到权值图,从而得到公式(1)中的系数1/15。
2 实验与分析
2.1 准备阶段
为了测试本文提出的多聚焦图像融合网络性能的优越性,采用了一个常用的公开数据库Lytro数据集图像与已有算法进行比较,该数据集包括20对彩色多聚焦图像。如图2所示,Lytro数据集中的场景多样,涉及室内外不同的光照条件、自然场景与人造建筑等不同的多聚焦图像,图像的分辨率均为520×520。在训练阶段,本文随机抽取数据集中的10组图像,剩余图像用于网络性能测试。训练阶段采用4种数据扩充方法把10组多聚焦图像进行数据增强:1)训练过程中的图像块大小均取为60×60,以此把训练集的数据块个数扩充到2万个以上;2)采用图像翻转扩充数据;3)采用图像旋转进行数据扩充;4)采用图像亮度整体变化一个随机值来扩充数据。

图2 Lytro数据集示例图
本文网络输入端为一对不同聚焦的图像,两幅图像已配准,除聚焦点不同之外,其他均相同。实验过程中使用Adam优化[20]对训练过程优化,学习率初值设定为0.000 1,衰减率设定为0.99,训练50次 。
为了证明所提算法的有效性,基于Lytro数据集,本文方法与5种最先进的方法进行比较,包括DSIFT 、S-A[21]、CNN、SESF和MFF[22]。其中,DSIFT和S-A是传统方法,而CNN、SESF和MFF是基于深度学习的方法。
评价指标方面,采用定性和定量指标对融合结果进行评估。定性评估依赖于人的主观视觉体验。良好的融合结果在保持源图像清晰度的同时保留了细节,尤其是聚焦区域和散焦区域之间连接的细节。定量评估采用通用的评价指标来衡量融合图像的性能。本文选择了5种流行的统计数据作为衡量融合结果的客观指标,即标准差(SD)、熵(EN)、空间频率(SF)、视觉信息保真度(VIF)[23]、差异相关性总和(SCD)[24]。
标准差SD定义如下:
(5)
式中:M、N分为别图像F的行与列;u为图像均值。通常来说,SD越大,图像的对比度越大。
图像信息熵EN定义如下:
(6)
式中:L是图像的灰度级;pl是灰度级为l的概率统计值。一般来说,图像信息熵EN越大,图像包含的信息越丰富。
图像空间分辨率SF定义如下:
(7)
(8)
(9)
图像分辨率SF反映的是融合图像的结构纹理信息,SF值越大,结构纹理越丰富。
2.2 多聚焦图像融合网络定性指标对比
本文的多聚焦图像融合网络的输入数据为两幅聚焦条件不同的图像,采用视觉感受作为定性指标,对本文网络与已有方法进行比较。我们选取了具有代表性的图像,定性地证明了本文方法的优越性,融合结果如图3所示。

图3 Lytro数据集上本文方法与5种已有多聚焦融合方法的定性对比结果
从结果来看,本文方法比其他方法有明显的优势。首先,本文方法能够更多地保留原图像的细节,包括聚焦和散焦区域边界线附近的细节,而大多数已有方法仅仅保留远离边界线的细节,但会丢失边界线附近的细节。此外,本文方法可以更好地保持规则的纹理,如轮廓线。基于决策图的方法,如CNN、SESF和DSIFT,由于错误分类,它们通常会在聚焦区域和散焦区域的交界处丢失细节。S-A方法通常会使规则的边缘模糊或包含块效应,如图3(d)所示,该方法不能很好地保持猴子脸颊的边缘。相比之下,本文方法更像是结合了不同方法的优点。一方面,本文方法可以精确地保持了聚焦和散焦区域边界附近的细节。另一方面,本文方法的融合图像具有良好的整体视觉感知,保持了规则的边缘,不包含块效应,视觉感受更为自然舒适。可见,本文提出的网络对多聚焦图像融合任务是有效的。
2.3 多聚焦图像融合定量指标对比
在Lytro数据集中的10对测试图像上,本文方法与已有的5种相关方法进行定量比较,选取标准差(SD)、熵(EN)、空间频率(SF)、视觉信息保真度(VIF)、差异相关性总和(SCD)、图像融合耗时共6个量化评价指标进行对比分析。统计结果如表1所示,6个量化指标均为10对测试图像的平均值,其中耗时指标选取平均用时以及标准差进行比较。可见,本文方法在EN、VIF和SCD指标上实现了最大的平均值,在SD、SF和耗时方面,本文方法远胜于多数已有的方法,显示了本文方法的有效性。从表1 的结果,我们可以得出结论,运用本文方法得到的多聚焦图像融合效果具有较好对比度,包含更多的信息,能够保持更好的边缘信息。由VIF指标可见,本文方法具有最高的视觉保真度,即该方法引入的伪信息量最少。从SF指标可见,本文方法还可以很好地保留纹理细节,这只比SESF方法差一点点。由耗时指标可见,本文方法在Lytro数据集上都实现了较高的运行效率,与最优的MFF网络方法在一个运行级别上,可以得出结论,本文方法在运行时间方面具有显著优势。综合6个量化指标都证实了本文方法融合结果的良好效果。总体而言,本文提出的多聚焦图像融合网络在客观评估方面优于多数比较方法。
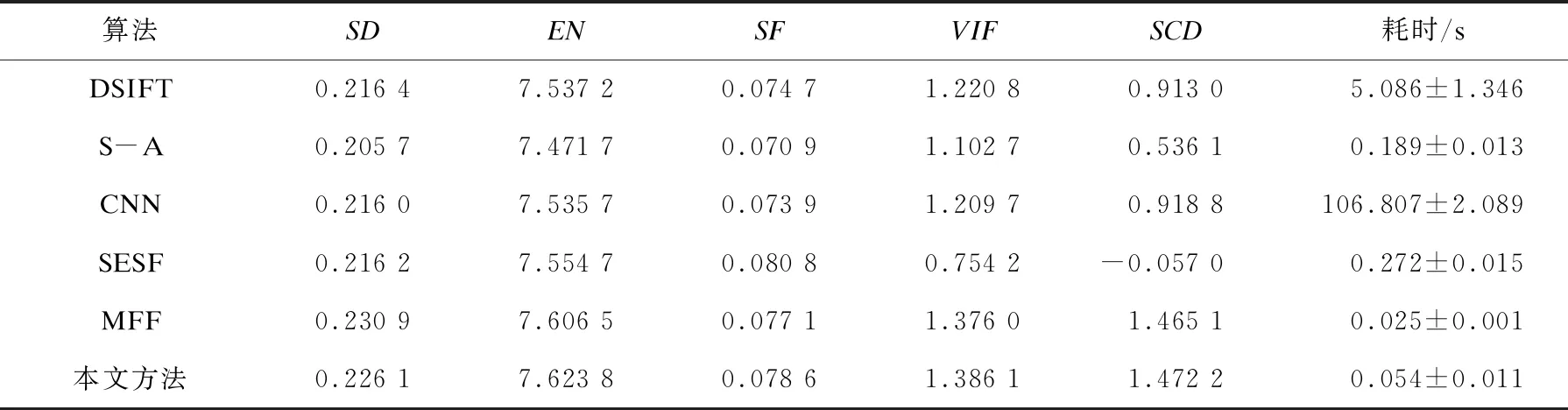
表1 在Lytro数据集下,多聚焦图像融合算法比较结果
综上,本文提出的多聚焦图像融合网络在定性和定量评价指标上,较已有方法取得了较大的进步,可见,本文网络结构、损失函数设计是适合于多聚焦图像融合任务的。
3 结论
针对同一场景拍摄的不同聚焦条件下的图像融合任务,本文提出了一种包括编码和解码两个子网络的端到端的无监督深度网络。此外,针对不同图像中清晰块的提取及融合,设计了特定的损失函数,通过无监督的方法训练并提升网络性能。为了验证网络的有效性,本文选择了Lytro数据集进行网络测试,通过对不同组图像序列的融合结果进行比较,本文提出的多聚焦图像融合网络在定性与定量评价指标上均取得了较大的进步。可见,本文设计的无监督深度神经网络可以进行多聚焦图像融合。
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
人大建设(2020年4期)2020-09-21
作文小学中年级(2020年6期)2020-07-24
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
人大建设(2017年2期)2017-07-21
人大建设(2017年9期)2017-02-03
重型机械(2016年1期)2016-03-01
海军航空大学学报(2015年4期)2015-02-27
浙江人大(2014年4期)2014-03-20
