
基于卷积降噪自编码器的苹果树种鉴别模型研究
2022-05-27 04:42罗佳杰王宝张馨嫣蔡耀仪吴浩粼阳波
计算机时代 2022年5期
罗佳杰 王宝 张馨嫣 蔡耀仪 吴浩粼 阳波


摘 要: 结合卷积降噪自编码器与随机森林算法,提出一种新型的卷积降噪自编码器-随机森林(CDAE-RF)模型,并基于可见-近红外光谱数据集来识别苹果树种。首先,通过网格式搜索、平行实验的方法优化了L1范数等参数,提高了模型的鲁棒性;然后,对比实验分析了CDAE-RF、主成分分析-随机森林模型(PCA-RF)、K最近邻分类算法等方法在不同噪声水平下光谱识别的准确性和鲁棒性。实验结果表明,相对于传统算法,新提出的CDAE-RF模型识别准确率达97.92%,在加噪情況下具有更高的鲁棒性。CDAE-RF模型降低了随机森林算法对噪声的敏感性,提高了噪声光谱图像识别的准确性,为地物波谱识别提供了一种新的方法。
关键词: 可见-近红外光谱; 苹果果树品种鉴别; 卷积降噪自编码器; 随机森林算法
中图分类号:TP391.4 文献标识码:A 文章编号:1006-8228(2022)05-01-05
A study on identification model of apple tree varieties based on
convolutional denoising autoencoder
Luo Jiajie Wang Bao Zhang Xinyan Cai Yaoyi Wu Haolin Yang Bo
Abstract: Combining the convolutional denoising autoencoder and random forest algorithm, a new convolutional denoising autoencoder-random forest (CDAE-RF) model is proposed to identify apple varieties based on the VIS-NIR spectrum data. Firstly, the L1 norm and other parameters are optimized through grid search or parallel experiments in order to improve the robustness of the model; then, under different noise level, the accuracy and robustness of the proposed CDAE-RF model, principal component analysis-random forest model (PCA-RF) and K-nearest neighbor classification algorithm are analyzed by comparative experiments. Experimental results show that compared with traditional algorithm, the accuracy of the proposed CDAE-RF model is as high as 97.92%, and has higher robustness when noise increases. The CDAE-RF model reduces the sensitivity of random forests algorithm to noise, improves the accuracy of noise spectral identification, and provides a new method for feature spectral identification.
Key words: VIS-NIR spectrum; identification of apple tree varieties; convolutional denoising autoencoder; random forest algorithm
引言
在农业管理和资源勘探等活动中,常常需要使用遥感技术对苹果树种进行识别。例如,李子艺[1]运用地物波谱仪采集到的可见-近红外光谱数据结合遥感研究了对南疆苹果和梨等常见果树苹果进行分类,檀博轩[2]研究了运用遥感影像对阿克苏地区果树果林进行面积测算,姬兴辉[3]使用遥感技术研究了赣南油茶种植区域适宜性。他们的研究重点是光谱成像技术,没有对光谱分析技术做系统研究,其算法简单,鲁棒性差。
将随机森林算法与降噪自编码器结合起来,可成为改善光谱分析鲁棒性的一种方法。自编码器是一种基于神经网络的无监督学习模型,具有良好的非线性特征提取能力[4]。随机森林是一种基于集成学习,包含多个决策树的机器学习分类器,其对特征值的缩放和各种变换具有更稳定的表现,对无关特征是鲁棒的[5]。郑淋文[6]等人将深度稀疏自编码器结合支持向量机用于ECG特征提取;宋辉[6]等人将卷积降噪自编码器用于地震数据去噪,优化模型鲁棒性;武峥[7]等人证明了将稀疏降噪自编码器用于特征提取结合随机森林算法能够进一步提高随机森林算法的分类性能。
为了提高地物波谱识别模型的准确率和鲁棒性,本文改进了原有的经典自编码器,设计出一种卷积降噪自编码器,并与随机森林算法结合提出了一种基于可见-近红外光谱(地物波谱)的苹果果树种分类模型。本文可分为两大部分,即改进模型的设计与实验验证部分。实验验证部分主要是进行了模型优化和模型评价。首先,将数据分别进行五种常见的光谱预处理,并采用CDAE-RF模型进行训练,选出了准确率最高的光谱处理方式;然后,通过网格式参数搜索,平行实验的方式优化了CDAE-RF模型;最后,将不同强度的噪声引入数据集,用CDAE-RF模型对其进行训练,并与传统的卷积自编码器、PCA-RF模型、K最近邻分类算法、支持向量机和随机森林算法进行对比,得出CDAE-RF模型特征提取性能好,鲁棒性强的结论。
1 算法设计
1.1 卷积降噪自编码器
传统的自编码器采用密集连接的人工神经网络来进行特征提取。为了能高效提取序列信息,本文使用了改进的自编码器做特征提取。采用深度可分离卷积[8]提取特征,相较于普通的一维卷积,能反映空间轴与轴之间的特征信息,更好地提取序列特征;引入批处理标准化层[9],可以很好的解决梯度消失或梯度爆炸问题,使训练能够更好的收敛;采用堆栈式自编码器[10]结构,使提取的特征表达能力更强。借鉴降噪自编码器[11]的设计思想,在每一个深度可分离一维卷积模块的末尾加入了Dropout[12]层,降低缺失值等异常数据对其的影响;在训练过程中引入一定范围的高斯噪声,降低模型对噪声的敏感性。
本文提出的CDAE-RF模型由卷积降噪自编码器与随机森林算法构成,数据首先经过卷积降噪自编码器进行特征提取,从2151维降到231维。然后将特征数据输入随机森林算法进行分类处理。其中卷积降噪自编码器部分(以下简称CDAE)结构如图1所示。
CDAE由编码器网络和解码器网络组成。编码器网络由两个深度可分离卷积(Depthwise separable convolution)模块组成,接受形状为(batchsize,2151,1)的三维张量作为输入。每个深度可分离卷积模块有4层。首先,数据经过采用tanh函数作为激活函数,使用0.0001的L1范数进行正则化的一维深度可分离卷积层进行数据蒸馏,同时填充到输入数据大小;然后,经过批处理标准化层进行批处理标准化(Batch Normalization);其次,进入最大池化层进行三倍下采样操作;最后,在训练过程中随机断开25%的与下一卷积层的连接。按照数据处理的顺序,两个模块的过滤器个数和卷积窗口大小分别是32,5和64,5。从数据输入,到两个卷积模块数据处理结束,数据维度呈2151-717-239变化,深度加深到64层。
在编码器完成编码之后,中间由一个一维卷积层对数据深度进行降维,最后得到(batchsize,239,1)的中间隐层数据,完成降维操作,随后数据接入解码器。解码器和编码器的结构基本对称,每个模块中只是最大池化层换为了上采样层,对数据进行两次三倍上采样,数据维度由239-717-2151变化,最后连接一个一维卷积层将深度降到1,获得与输入数据维度大小相同的输出数据。通过定义合适的误差函数,使数据经过CDAE网络前后信息损失最小,而其中的编码器尾部输出的压缩数据则包含了浓缩后数据的丰富特征。
1.2 算法流程
本文提出的CDAE-RF模型由卷积降噪自编码器与随机森林算法构成。类比经典的降维+机器学习模型的结构,CDAE可以理解成一种改进的数据降维方式。数据首先经过卷积降噪自编码器进行特征提取,从2151维降到231维,然后将特征数据输入随机森林算法进行分类处理。具体步骤如下。
步骤一 对输入的光谱数据进行数据预处理,尽量消除基线漂移等情况。以预处理后的数据作为训练集。
步骤二 训练卷积降噪自编码器网络,实现一个近似恒等的映射,使得输入输出数据之间的差别尽可能小,此时神经网络中保留了尽可能多的关于数据的信息。
步骤三 冻结编码器权重,让训练数据通过编码器从2151维降到231维。
步骤四 将编码器处理后的数据输入随机森林进行训练。至此,CDAE-RF模型训练完毕。
步骤五 对于测试数据,依次经过数据预处理,训练好冻结权重的编码器,随机森林得到最终结果。
2 实验方法
2.1 数据集
本次实验采用中国农业科学院農业信息研究所于2015年采集的“苹果品种标准叶片图像和光谱数据集”[13](以下简称数据集)。数据集的采集地点是隶属中国农业科学院果树研究所的果树种质资源圃,共采集了174种苹果品种的叶片数据,能够代表国内种植苹果的绝大多数品种。
数据集由苹果叶片的图像数据和可见-近红外光谱数据两部分数据组成,本次实验采用其可见-近红外光谱数据进行研究。其可见-近红外光谱数据的采集仪器是美国ASD公司生产的ASD FieldSpec3系列地物波谱仪。原始数据经其配套软件粗处理导出后,每个样本共有350nm~2500nm波段的2151个透射率数据。
通常,受光程差异、漫反射和光散射、样本颗粒的大小等噪声信息的影响,采集的光谱往往会有一定的基线漂移和倾斜等,需要进行矫正。在数据使用前,依次进行Savitzky-Golay卷积平滑与最大最小归一化两种数据预处理[14]。
2.2 模型调参
模型调参包括CDAE模型调参与随机森林调参两个部分。
首先是CDAE模型的调参。L1惩罚项系数以及神经网络层与层之间连接随机断开的概率(即Dropout比率)是CDAE-RF模型的重要参数。它们相互影响,共同控制着模型的容差能力和鲁棒性,但是与模型的容差能力和鲁棒性之间又非简单线性关系。为优化模型,在L1惩罚项系数1e-5~0.1,dropout比率为0~0.5的范围内,以网格参数搜索的方法确定最佳参数。
然后是随机森林模型的调参。在随机森林算法中,子树数量的多少将影响模型的计算复杂度及准确率。显然,随着子树数量的增加,随机森林算法的分类性能也随之提高。 但增加到一定程度后,会趋于稳定。 在性能相差不大的情况下,应该用尽可能少的子树,因为子树越多,算法运行的时间就越长,模型的泛化能力也会有所降低。为了确定CDAE-RF模型最佳的子树个数,取子树为1~100,其他参数相同的CDAE-RF模型进行对比测试,确定最佳子树数量。
2.3 模型评估
为了比较CDAE-RF模型及其他模型的特征提取能力及进行分类的准确率,选取CAE-RF,PCA-RF,随机森林算法,支持向量机和K最近邻分类算法与之进行对比。其中CAE-RF即卷积自编码器-随机森林模型,其结构与CDAE-RF类似,不同之处在于其前端特征提取结构为卷积自编码器。卷积自编码器是在卷积降噪自编码器的基础上去掉Dropout层和设计公式中L1范数惩罚项的自编码器,相比CDAE模型结构更简单。以此类推,PCA-RF模型即将主成分分析作为前端特征提取。其结构也与CDAE-RF模型类似,不同之处在于将主成分分析用于特征提取后,再将数据输入随机森林算法。CAE-RF,CDAE-RF,PCA-RF,随机森林算法四者相互对比,可以探究CDAE作为前端特征提取的能力;CDAE-RF,随机森林算法,支持向量机和K最近邻分类算法四者相互对比,可以探究CDAE-RF相对于传统机器学习模型进行学习的能力。在模型的评价指标上,由于该数据集为一个平衡的数据集,每一类的数据相差不大。因此,准确率(Accuracy)即衡量的正确分类的比例将被用于模型的对比评价。
2.4 鲁棒性测试
在实际光谱的测量时,经常会有大量的噪声干扰,而随机森林算法对噪声非常敏感。为了降低随机森林算法对输入数据噪声的敏感性,可以在数据输入随机森林分类器前加上卷积降噪自编码器先对数据进行降噪和降维处理。为了探究CDAE-RF模型在不同噪声条件下的鲁棒性,先给数据分别加上40db,35db,30db,25db,20db,15db,10db,7db,5db的高斯分布的白噪声,然后在加噪的情况下,与随机森林算法、PCA-RF模型和CAE-RF模型三个类似模型进行对比。通过随机森林算法、PCA-RF模型、CAE-RF模型与CDAE-RF模型的对比,可以探究在加噪情况下卷积降噪自编码器和其他几种经典特征提取方法在降低随机森林敏感性的效果。
3 结果与讨论
3.1 模型调参
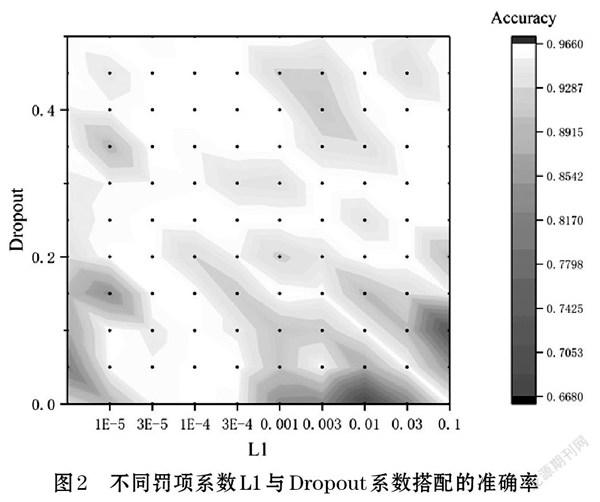
为了确定CDAE模型L1范数和Dropout比率的最佳参数,采用网格式搜索的方式在Dropout率为0-40%,L1范数为1e-5~0.1的范围内进行模型优化,相关结果可见图2。其中横坐标表示L1的值,纵坐标表示Dropout的值,黑点表示数据点,颜色表示准确率。颜色越白,准确率越高。当L1范数为0.003,Dropout比率为30%时,模型准确率最高,确定其为最佳参数。
为了确定最佳的子树个数,设计99个子实验,选取随机森林子树个数从1到100的不同CDAE-RF模型进行对比,在相同光谱数据集上训练并测试,相关结果可见图3。用光滑的曲线拟合实验所得准确率数据,图3中实心点为实际准确率数据,虚线为拟合的趋势线。当子树数量为29时,曲线趋于与x轴平直,认为此时模型性能随着子树数量增多而无显著变化,确定最佳子树数量为29。
3.2 模型评估
为了比较CDAE-RF模型及其他模型的特征提取能力及进行分类的准确率,在同一光谱数据集上训练并测试,相关实验结果可见图4。对比CAE-RF,CDAE-RF,PCA-RF和随机森林算法四种模型的准确率,自编码器类模型(即CDAE-RF和CAE-RF)明显好于其他模型,能够有效浓缩数据集中的数据特征。PCA-RF模型没有能有效的提取特征,还对数据特征造成了损伤,其准确率低于随机森林算法。引入L1范数及Dropout层的CDAE-RF模型提取特征能力优于普通的CAE-RF模型,准确率最佳。对比CDAE-RF,随机森林算法,支持向量机和K最近邻分类算法四种模型的准确率,随机森林算法在2151维的高维度地物波谱数据上,相较于支持向量机和K最近邻分类算法准确率更高。在数据特征进一步浓缩之后,CDAE-RF模型的准确率要比随机森林算法更高。
3.3 鲁棒性测试
在加噪情况下对比卷积降噪自编码器和其他几种经典特征提取方法在降低随机森林敏感性方面的效果,相关结果可见图5。在无噪声加入的情况下,随机森林算法、PCA-RF模型、CAE-RF模型与CDAE-RF模型初始准确率都相差不大,但是在噪声加入后,其鲁棒性各不相同。随机森林模型对噪声非常敏感,在噪声下下降速度最快。传统的主成分分析只能实现降维,不能抗噪,随着噪声强度的增强,准确率同随机森林一样下降速度很快。引入L1范数及Dropout层,经过抗噪设计的CDAE-RF模型比普通的CAE-RF模型具有更好的鲁棒性,在不同噪声下准确率始终比其高3%-5%。实验结果表明,CDAE-RF模型明显有着更高的鲁棒性,在随机森林前加入卷积降噪自编码器能够显著降低随机森林对噪声的敏感性。
4 结束语
本文将卷积降噪自编码器引入光谱分析中,结合随机森林提出了一种CADE-RF模型用于地物波谱分类,实现了苹果果树树种识别。研究结果表明,该模型具有优秀的特征提取能力,能够有效浓缩数据集中的数据特征,提取非线性特征,相较于卷积自编码器-随机森林模型,主成分分析-随机森林模型和随机森林算法具有更佳的性能;具有更强的学习能力,相较于随机森林算法,支持向量机和K最近邻分类算法准确率更高;具有更好的鲁棒性,能够使抑制输入的数据在各个方向上的扰动,降低随机森林模型对噪声的敏感性。CDAE-RF模型提高了對噪声光谱图像识别的准确性,为地物波谱识别提供了一种新的方法,同时也为降低随机森林算法对噪声的敏感性提供了一种思路。
参考文献(References):
[1] 李子艺.基于冠层光谱数据的南疆盆地主栽果树树种遥感
分类研究[D].新疆农业大学,2015
[2] 檀博轩.基于遥感影像的阿克苏地区林果种植面积测算
方法研究与实现[D].塔里木大学,2020
[3] 姬兴辉.基于遥感的赣南油茶种植区域适宜性评价研究[D].
江西理工大学,2015
[4] Friedman J, Hastie T, Tibshirani R. The elements of
statistical learning[M]. New York: Springer series in statistics,2001
[5] 郑淋文,周金治,黄静.深度稀疏自编码器在ECG特征提取中的
应用[J].计算机工程与应用,2021:1-13
[6] 宋辉,高洋,陈伟,张翔.基于卷积降噪自编码器的地震数据
去噪[J].石油地球物理勘探,2020,55(6):1210-1219,1160-1161
[7] 武峥,丁冲,景英川.基于稀疏降噪自编码器的随机森林模型[J].
统计与信息论坛,2019,34(8):27-33
[8] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the
inception architecture for computer vision[C]//Proceedings of the IEEE conference on computer vision and pattern recognition,2016:2818-2826
[9] Ioffe S, Szegedy C. Batch normalization: Accelerating deep
network training by reducing internal covariate shift[C]//International conference on machine learning. PMLR,2015:448-456
[10] Zabalza J, Ren J, Zheng J, et al. Novel segmented stacked
autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging[J].Neurocomputing,2016,185:1-10
[11] Vincent P, Larochelle H, Lajoie I, et al. Stacked
denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion[J]. Journal of machine learning research,2010,11(12)
[12] Baldi P, Sadowski P J. Understanding dropout[J].
Advances in neural information processing systems,2013,26:2814-2822
[13] 夏雪,李壯,吴定峰,等.苹果品种标准叶片图像和光谱数据
集[J].中国科学数据(中英文网络版),2016(1):43-48
[14] 第五鹏瑶,卞希慧,王姿方,等.光谱预处理方法选择研究[J].
光谱学与光谱分析,2019,39(9):2800-2806
收稿日期:2021-10-20
基金项目:国家自然科学基金青年基金(No.61903138); 湖南省自然科学基金青年基金(No.2020JJ5366); 湖南省大学生创新创业训练计划项目(No.S202010542084)
作者简介:罗佳杰(2001-),男,湖南衡阳人,本科生,主要研究方向:机器学习,人工智能。
通讯作者:阳波(1976-),男,湖南娄底人,博士,教授,主要研究方向:传感器、机器人、人工智能。
猜你喜欢
数学学习与研究(2019年3期)2019-03-27
中国科技纵横(2018年20期)2018-11-22
小学教学参考(数学)(2017年11期)2017-11-30
湖北农业科学(2016年18期)2016-12-08
分析化学(2014年9期)2014-09-26
分析化学(2014年9期)2014-09-26
江苏农业科学(2014年4期)2014-07-11
