
基于子图分解的图聚类神经网络
2022-05-27 15:45邓祥俞璐姚昌华朱瑾
计算机时代 2022年5期
邓祥 俞璐 姚昌华 朱瑾


摘 要: 聚类是机器学习的核心任务之一,其主要目的是将无标签数据中的不同簇数据进行分离。深度聚类算法使用深度神经网络联合优化聚类目标与特征提取,极大地提高了聚类性能。图聚类是深度聚类领域近两年研究的一个重要分支,其在处理图结构数据上有极大的优势。提出一种新的图聚类方案:基于子图分解的图聚网络,该模型在图自编码器的基础上通过构建多个子图,并在子图的嵌入空间中加以组稀疏约束达到最终的聚类目的。
关键词: 模式识别; 图神经网络; 深度学习; 深度聚类
中图分类号:TP181 文献标识码:A 文章编号:1006-8228(2022)05-06-05
Graph clustering neural network based on subgraph decomposition
Deng Xiang Yu Lu Yao Changhua Zhu Jin
Abstract: Clustering is one of the core tasks of machine learning. Its main purpose is to separate different cluster data from unlabeled data. Deep clustering algorithm uses deep neural network to jointly optimize clustering objectives and feature extraction, which greatly improves the clustering performance. Graph clustering is an important branch in the field of deep clustering in past two years. It has great advantages in processing graph structure data. In this paper, a new graph clustering scheme, graph clustering network based on subgraph decomposition, is proposed. Based on graph Auto-encoder, this model achieves the final clustering purpose by constructing multiple subgraphs and imposing group sparse constraints in the embedded space of subgraphs.
Key words: pattern recognition; graph neural network; deep learning; deep clustering
引言
聚類任务的主要目的是把相似的数据聚成一簇,其关键是如何有效地度量样本之间的相似性。在人工数据集中由于数据没有冗余信息、具有分离的数据结构所以聚类难度较低。在大数据时代数据包含了大量的冗余信息且有高度复杂的结构,极大地增加了聚类的难度,所以近些年的聚类算法更多的关注如何进行特征提取,在保持有效特征的同时去除冗余噪声的干扰以降低聚类的难度。
随着近些年深度学习的发展,神经网络的表示学习能力越来越强,因此使用神经网络进行特征处理是现如今聚类方案应对复杂数据集的方法之一。基于深度学习的聚类方案主要有两种方式。其一是使用神经网络进行无监督特征学习,学得一个高维数据的低维嵌入,之后在这个低维嵌入特征上进行传统聚类。这类方法虽然在一定程度上去除了冗余噪声,但是由于缺少全局的聚类聚目标函数,导致提取的特征不是利于聚类的特征,并没有充分地发挥神经网络的优势。其二是以聚类目标为导向的深度聚类方案,让聚类目标指导神经网络的特征提取工作,使神经网络提取的特征是利于聚类的特征。这种方案可以更好地利用神经网络的表示学习能力和非线性逼近能力,可以很好地处理现如今越加复杂的数据集。
1 相关工作
1.1 相关理论
近年来随着深度聚类不断发展涌现出了大量杰出的算法,根据深度聚类算法所使用的神经网络不同,文献[1,2]将现有的深度聚类方法划分为基于不同神经网络的聚类方法,其大致可以分为以下几个类别:基于自编码器的聚类算法、基于生成对抗网络的聚类算法、基于变分自编码器的聚类算法等。发展这些基于不同神经网络的深度聚类算法的目的是为了应对不同类型、不同应用环境的复杂数据集。
以上这些深度聚类算法能够处理大多数的结构化数据,但面对非结构化数据如图数据集时却无能为力。而近两年,随着图神经网络的提出,非结构化数据的处理不再是一个困扰性的问题,因此人们期望借助图神经网络的能力来获取无标签数据的簇结构信息,以此来提取利于聚类的特征表示,达到提升聚类效果的目的。
基于图神经网络的深度聚类模型中较成功的有Embedding Graph Auto-Encoder(EGAE)[3],DeepAttentional Embedded GraphClustering(DAEGC)[4],Structural Deep Clustering Network(SDCN)[5],adaptive graph convolution (AGC)[6],Adversarial Graph Auto-Encoders(AGAE)[7]等。其中AGAE的输入是相似性矩阵,利用图卷积神经网络处理相似性矩阵提取特征,并把它与特征先验分布中得到的特征一同进行对抗性训练, 得到一个能完成聚类的概率分布。DAEGC将注意力机制引入图神经网络,在图自编码器的图结构重构过程中关注边的权重变化,之后在这个图神经网络提取的特征上进行自训练聚类,其自训练聚类参考了DEC[8]模型,把特征与聚类中心的相似度转化为概率分布p,对分布p进行置信度加强形成分布q,最小化分布p,q的KL散度达到聚类目标。SDCN模型则是在引入图自编码器的同时引入经典自编码器,使用双重自监督模块使两类自编码器提取特征时能够互相监督,这里的双重自监督模块与DAEGC模型一样都借鉴了DEC模型提出的聚类分布,即求自编码器中间特征与聚类中心相似度转化的概率分布p与置信度加强分布q的KL散度。AGC模型与SDCN模型相似都使用了多层图卷积神经网络来提取高阶结构信息,并通过逐渐增加K的方式来达到自适应地选择聚合信息的阶数。EGAE模型同样是在多层图卷积神经网络的基础上设计的聚类模型,该模型在图卷积神经网络提取的带有结构信息的特征上设计两个类似于k-means聚类和谱聚类的损失项,通过这种联合训练的方式来取得更好的聚类效果。
对上述基于图卷积神经网络的聚类模型研究可以发现,图神经网络聚类算法都需要在图自编码器网络上设计的聚类损失函数,其主要原因是借助图自编码的结构捕捉能力来获取带有簇结构信息的低维嵌入特征,本文同样选择在图自编码器上开发聚类算法,不同于上述算法对中间特征设计聚类的损失项,本文算法从图自编码器的结构重构能力出发,将数据的图结构划分为不同的子图,这些子图代表不同的聚类簇,利用图自编码器重构出子图结构,以达到聚类的目的。本文主要贡献:使用图自编码器神经网络探索聚类簇的子图结构。
1.2 图卷积
结构化数据可以用卷积操作来提取特征信息,而卷积操作并不能处理非结构化数据,如社交网络、知识图谱、蛋白质结构、万维网等,对于这些非结构化数据,如何像卷积操作一样提取有效的特征信息是一些应用的关键。图卷积[9]操作是在图上进行的卷积操作,能够捕获数据的结构信息。图卷积操作定义如下:给定一个图G(V,E,X),V代表图的顶点集合,E代表图上存在的边的集合,X代表节点的特征矩阵,由此可以得到图的邻接矩阵A,和邻接矩阵的度矩阵D,该矩阵是一个对角矩阵,对角线上的值为对应节点的度。如图卷积操作表示中,[?()]是激活函数,Z是图卷积操作提取的特征信息。
⑴
在具体实现中,我们对图卷积操作做如下处理:
⑵
其中[A=A+I]、[D]是(A+I)的度矩阵,其同样是一个对角矩阵,对角线上的点是(A+I)节点的度。
1.3 图自编码器
图自编码器[10]利用多层图卷积操作提取节点的特征信息,经典自编码器的目标是重构出原始样本的信息,而图自编码器不同于经典自编码器,它的目标是使用图卷积操作提取的特征来重构出原始的图结构,在保证图结构信息不变的情况下,捕获带有聚类簇结构的节点信息。其定义如下:
⑶
其中[Zl]是第l层图卷积的输出,[Wl]是第l层的权重。这里输入层图卷积的[Zl]为节点的特征矩阵X,编码器输出层图卷积的[Zl+1]为嵌入特征Z。
对编码器的嵌入特征Z与Z的转置,做矩阵运算得到一个图结构矩阵[A],使用这个矩阵重构原图,以达到图结构不变的目的。
⑷
⑸
2 基于子图分解的图聚类网络
2.1 本文算法的聚类思想
谱聚类算法是最著名的图聚类算法,对于非图结构的数据集,谱聚类通过k近邻、全连接、[ε-]领域等方法将数据样本之间的相似性转化为图的边权重。再将构建的图结构切割成不同的子图,这些不同的子图代表了不同的聚类簇结构,谱聚类的核心聚类思想是让切割之后的子图间边权重低,而子图内边权重高。因此如何进行子图切割是谱聚类的关键。
本文受谱聚类的启发使用神经网络进行子图切割,借助图卷积神经网络提取不同子图的嵌入特征,再使用不同的嵌入特征重构出不同的子图结构,达到聚类的目的。
2.2 子图划分
本文算法借助图卷积神经网络将数据集的图结构划分为K个子图,其具体的结构如图1所示,划分的思想是将来自浅层图卷积F的特征送入K个子图网络中,每个子图网络都将生成一个对应的子图。其中[ZlkN×d']是第k个子图第l层的图卷积输出特征,[AkN×N]是第k个子图的邻接矩阵。
⑹
⑺
为了达到子图划分的目的,我们增加了一个判别网络用来输出样本属于各簇的概率[QN×K],用这个概率向量对重构的图结构进行筛选,得到K个聚类簇的结构图。筛选的方法为:样本属于第i簇概率乘以第i个子网络产生的特征[Zi]和子图[Ai]。其具体的筛选步骤为如下两种情况(其中[(x)p,q]是定义的维度扩展操作将x扩展到p、q维):
⑴ 样本j属于第i簇则理想状态[QN×Kj,i=1],对[QN×Kj,i=1]进行维度扩展,将第二维扩展到N维,得到[Q1=(QN×Kj,i=1)1×N],将第二维扩展到d'维得到[Q2=(QN×Kj,i=1)1×d'],再分别与[Aij:]和[Zij:]做点乘,从而将样本j的嵌入特征和子图结构保留在第i簇。
⑵ 样本j不属于第i簇则理想状态[QN×Kj,i=0],对[QN×Kj,i=0]进行维度扩展,将第二维扩展到N维得到[Q1=(QN×Kj,i=0)1×N],将第二维扩展到d'维得到[Q2=(QN×Kj,i=0)1×d']再分别与[Aij:]和[Zij:]进行点乘,从而将样本j的嵌入特征和子图结构从第i簇中去除。
以上这两种情况可以统一为如下公式:
⑻
⑼
⑽
這里我们对判别网络输出的概率分布进行一个加权指数的操作[QαN×K],用来增加模型的自由度和灵活性。
2.3 先验知识
先验知识能够辅助聚类,不同的先验知识对聚类算法的影响程度不同,在聚类算法中最常见的先验知识是聚类簇的数目K,根据聚类算法设计角度的不同,可能需要设置不同的先验知识。在本文中由于我们需要使用样本属于各簇的概率向量来筛选子图,为了使样本在筛选子图时不陷入极端解(如预测为同一簇),我们假设模型预测样本簇的概率分布的先验知识为均匀分布。模型预测的簇分布为q ,先验分布为均匀分布p,则本文算法的先验损失项为q和p的KL散度。
⑾
⑿
⒀
2.4 本文算法描述
前文中,我们生成了K个子图,并引入了均匀分布作为聚类簇分布的先验知识,至此,我们完成了使用图卷积神经网络定义聚类簇结构,但仍然缺少关键的聚类引导项来保证不同簇的嵌入特征和子图结构向正确的方向划分。这里我们使用图自编码器来完成这个工作,假设得到K个正确的子图划分,则这个K个子图的合并将逼近原数据的图结构。
⒁
⒂
因此,本文提出的深度聚类算法的聚类引导项选择使用图自编码器让图结构[A]重构出原数据的图结构A。在保证每个子图都在原始图结构中时,使用图卷积提取各自子图的嵌入特征,同时选择均匀分布保证了模型的解不至于陷入极端解,如把所有样本划分为同一簇。本文的算法描述如表1所示,由此可以得出本文聚类算法的损失公式:
⒃
3 实验及结果分析
3.1 数据集
本文选择Cora数据集[11]用来验证本文提出的图深度聚类算法,Cora数据集由七类深度学习论文组成,其中包含基于案例、遗传算法、神经网络、概率网络、强化学习、规则学习、理论这七方面的论文。整个数据语料库中共包含2708篇论文,每篇论文至少被一篇论文引用,同时至少引用一篇论文。数据集包含了论文之间引用关系的索引,依据这些索引位置可以建立论文之间引用关系的邻接矩阵。对每篇论文进行词干提取、去除词尾,删去词频小于10的词等操作后保留了1433个特有的词,对这些词建立词向量,形成了图节点的特征矩阵X。
3.2 评估指标
本文选用互信息(NMI)[12]指标,来评估本文提出的深度聚类算法的聚类性能。NMI指标能够评估一个变量包含另一个变量的信息量。NMI 指标的取值范围是[0,1],越接近1说明变量Y包含变量X的信息量越小,变量X确定性越大。
⒄
3.3 模型的实现
模型的具体实现图卷积网络F采用一层图卷积操作。网络G是七个并列的子网络,每个网络都是一层图卷积操作,且其输入是来自网络F的浅层嵌入特征。网络Q是四层线性网络,其输入是节点的特征矩阵X,输出是样本所属簇的预测结果。聚类簇数目设为7,迭代周期设置为10000,优化函数选择Adam[13]算法,学习率lr=0.01,加权指数[α=2]。
3.4 实验结果
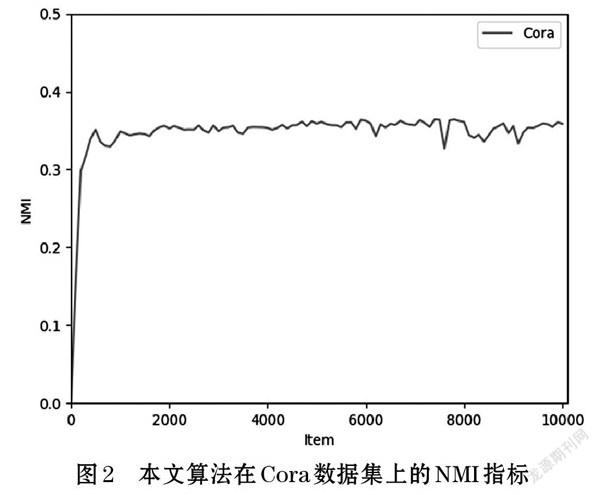
表2展示了本文算法在Cora数据集上的实验结果,该结果取自多次实验的最优结果,图2展示了算法的NMI指标在模型训练过程中的变化情况。表2中我们选择了三类作用在不同输入上的聚类算法与本文提出的算法做比较。
观察表2可以看出本文提出的图神经网络聚类算法要明显优于只作用于数据特征上的聚类算法和只作用图结构上的聚类算法。这表明基于图卷积神经网络的聚类算法有效地利用了数据集的图结构和节点的特征。
观察图2可以看出本文的算法在轮次为0的时候NMI指标为0,此時不具备聚类能力,随着训练地进行在各损失项的相互约束下,逐渐具备聚类的能力,最终结果收敛在0.36附近。
图2和表2的结果表明本文提出的基于子图分解的图聚类网络具有聚类划分的能力。
4 结束语
本文提出的基于子图分解的图聚类网络在图自编码器的基础上对原始数据集的图结构进行子图划分,以不同的子图结构来区分数据集中的不同簇结构以达到聚类划分的目的。该算法在Cora数据集上取得了较好的结果。本文算法的下一步工作是对划分的子图做进一步的约束以期能够达到更高的聚类效果。
参考文献(References):
[1] ALJALBOUT E.Clustering with deep learning: taxonomy
and new methods[J/OL].(2018-09-13) [2021-04-02].http://export.arxiv.org/abs/1801.07648
[2] MINE.A survey of clustering with deep learning:from the
perspective of network architecture[J].IEEE Access,2018,6:39501-39514
[3] Li X, Zhang H, Zhang R. Embedding graph auto-encoder
with joint clustering via adjacency sharing[J].arXiv e-prints,2020: arXiv:2002.08643
[4] Wang C, Pan S, Hu R, et al. Attributed graph clustering:A
deep attentional embedding approach[J]. arXiv preprint arXiv:1906.06532,2019
[5] Bo D, Wang X, Shi C, et al. Structural deep clustering
network[C]//Proceedings of The Web Conference 2020,2020:1400-1410
[6] Zhang X, Liu H, Li Q, et al. Attributed graph clustering via
adaptive graph convolution[J]. arXiv preprint arXiv:1906.01210,2019
[7] TAO Z,LIU H,LI J,etal.Adversarial graph embedding for
ensemble clustering[C]//Twenty-Eighth International Joint Conference on Artificial Intelligence IJCAI-19,2019
[8] Xie J, Girshick R, Farhadi A. Unsupervised deep
embedding for clustering analysis[C]//International conference on machine learning. PMLR,2016:478-487
[9] Niepert M, Ahmed M, Kutzkov K. Learning convolutional
neural networks for graphs[C]//International conference on machine learning. PMLR,2016:2014-2023
[10] Kipf T N, Welling M. Variational graph auto-encoders[J].
arXiv preprint arXiv:1611.07308,2016
[11] Sen P, Namata G, Bilgic M, et al. Collective classification
in network data[J]. AI magazine,2008,29(3):93-93
[12] P. A. Estévez, M. Tesmer, C. A. Perez, and J. M. Zurada,
“Normalized mutual information feature selection,” IEEE Trans. Neural Netw.,2009,20(2):189-201
[13] DiederikKingma and Jimmy Ba. Adam: A method for
stochastic optimization. arXiv preprint arXiv:1412.6980,2014
收稿日期:2021-09-22
*基金項目:国家自然科学基金面上项目(No.61971439); 江苏省自然科学基金面上项目(No.BK20191329); 中国博士后科学基金项目(No.2019T120987); 南京信息工程大学人才启动经费(No.2020r100)
作者简介:邓祥(1994-),男,安徽六安人,硕士研究生,主要研究方向:模式识别与深度学习。
猜你喜欢
中成药(2018年2期)2018-05-09
电子测试(2017年23期)2017-04-04
智能系统学报(2017年5期)2017-01-22
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
海军航空大学学报(2015年1期)2015-11-11
