
基于RefineNet特征融合的改进EAST场景文本检测方法
2022-06-24 10:02仝明磊施漪涵
计算机应用与软件 2022年4期
张 魁 仝明磊 施漪涵 唐 丽
(上海电力大学电子与信息工程学院 上海 200090)
0 引 言
定位自然场景中的文本是文本分析领域中的必要条件[1-7],也是最困难和最具有挑战性的计算机视觉任务之一,在场景理解,机器人自主导航以及文字图像检索等领域具有潜在的应用价值。通常阅读自然图像文本包括两个子任务[8]:文本检测和文本识别。在文本检测中,使用卷积神经网络对图像进行特征提取,然后利用不同的解码器对区域详细信息,比如位置、角度和形状进行解码。在计算机视觉领域,传统的检测方法[9]已经在该领域的基准数据集上取得了较好的性能,但是由于室外场景中的文本模式具有很大的差异性以及文本的背景高度杂乱性,准确定位室外文字仍然是一项具有挑战性的研究。
现有的文本定位方法主要分为两种,一种是传统方法,另一种是基于深度学习的方法。早期的传统方法分为两大类,一类是基于滑动窗口的方法[10],一类是基于连通域的方法[11]。基于滑动窗口的方法利用不同尺度的窗口在图像上进行滑动,提取出文字候选区域,进而检测出文字。Kim等[12]利用不同尺度的窗口在图像上进行滑动,提取出文字候选区域,之后在文本候选区域投入支持向量机,得出文本区域。基于连通域的方法利用自然场景文字在颜色、光照等低级特征上呈现一定的相似性这一性质,通过某些算法对相似像素进行聚合,找出文字的连通域进而进行文字检测。Huang等[13]提出笔画特征转换(Stroke Feature Transform,SFT)低级特征提取器,用于文本区域候选区的提取,之后训练两个分类器,一个用于单词粒度的分类,一个用于文本线的分类。基于滑动窗口的方法虽然简单,但滑动窗口的位置固定,无法覆盖全部位置,对于位置的定位不够准确。基于连通域的方法虽然速度快,定位位置精准,但无法囊括复杂场景文字的变化。传统的计算机视觉方法将背景和文本进行分割,然后提取文本特征,最后使用分类器定位文本,常用的特征包括笔划宽度和密度特征[14]、关键点特征[15]等。传统的方法在一些特定场景如文本密度较低情形下拥有较好的效果。但是,对于高密度的文本场景,由于文本分布不均导致透视失真等干扰因素,这些传统方法并不合适。
随着深度学习的快速发展,出现了以卷积神经网络作为回归预测模型的文本定位方法。Liao等[5]提出一个基于端到端的文本定位方法TextBoxes,利用多尺度融合进一步提升了检测精度。在此基础上,文献[2]提出一种连接成分进行多方向场景文字检测的方法。该方法检测出文字的Segment,再利用卷积神经网络自动学习出Segment之间的连接信息,最终用结合算法将Segment连接起来得到最终结果。Zhou等[1]提出一种既高效又精确的文本检测器,该方法利用多通道的特征融合丰富语义信息,在网络的最后利用全卷积网络来区分文本和非文本区域,用旋转的矩形来对文本进行检测。虽然这些方法表现出对尺度变化的鲁棒性,但它们仍然无法很好地适用文字在各种情况下的变化,因为受限于卷积神经网络的结构。
为解决上述问题,本文选择目前检测算法较好的EAST算法作为基础算法,改进神经网络结构,使特征图信息更加完善,解决样本不均衡问题,从而改进文本检测算法的性能。
1 改进算法
EAST算法的高层语义特征信息和底层语义特征信息对特征融合起着很重要的作用。原始模型如图1所示利用Conv stage 4层输出经过反池化和前一层输出融合方式,逐层进行融合,最后得到输出,然而这样使得融合的特征信息不够完整。

图1 原始特征融合方式
本文将原先EAST网络结构特征合并层的融合方式改成RefineNet网络结构。RefineNet网络使用较多residual connection,与ResNet残差网络形成long-range连接,梯度能够传递到整个网络中,网络结构如图2所示。ResNet50残差网络提取出的2-5层4种分辨率特征图,经过3×3卷积和线性修正单元输出后,再经过3×3卷积和上采样,将特征恢复至最大尺寸,然后进行加权输出,最后在通过池化、卷积和加权操作输出传递给后续处理。
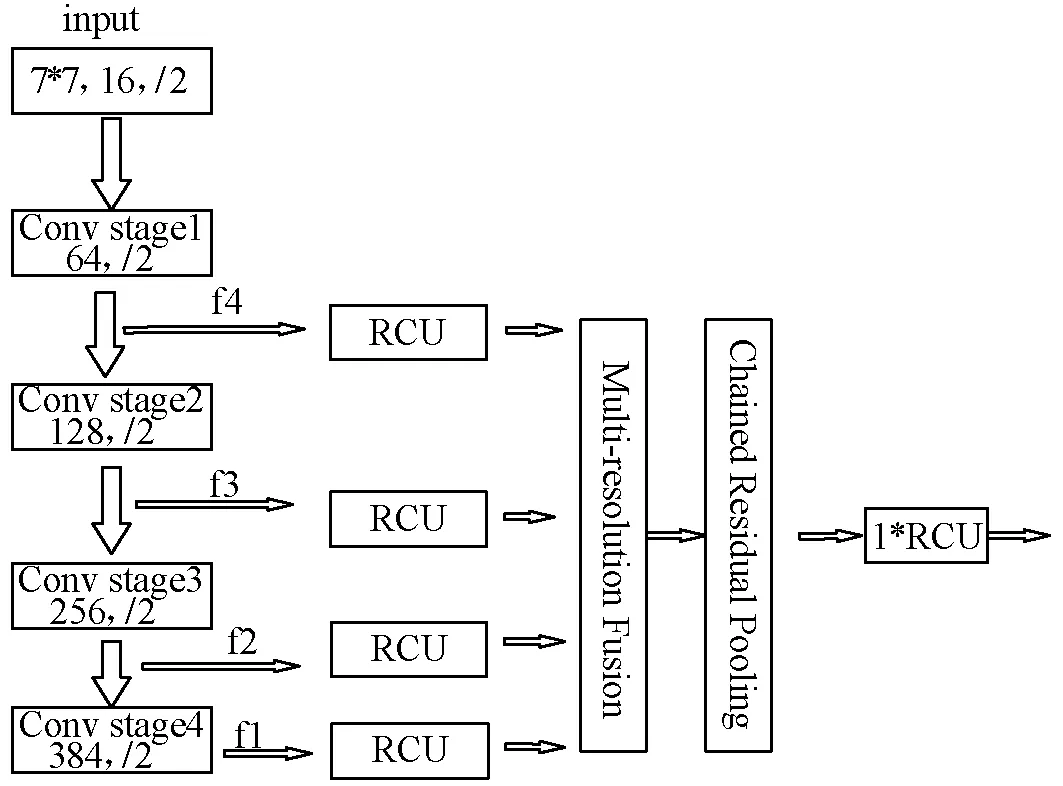
图2 RefineNet网络结构
2 网络结构
整体网络结构如图3所示,网络输入图像大小为512×512。首先经过ResNet50残差网络,提取四个级别的特征图f1、f2、f3和f4,大小分别为输入图像的1/32、1/16、1/8和1/4;之后每个输入路径都经过RCU,在RCU中,分为两路,一路经过2个3×3卷积,一路不进行任何操作,两路进行加权输出;随后所有路径输出都通过MRF(Multi-Residual Fusion)融合为高分辨率特征图,该模块将3×3卷积应用于输入自适应,生成具有相同尺寸的特征图,所有特征图经过上采样将特征恢复至最大尺寸后进行加权输出。从MRF输出的特征图通过CRP(Chained Residual Pooling)模块,该模块由3个池块组成,每个池块由一个最大池化层和一个卷积层组成,一个池块将前一个池块的输出作为输入,通过合并残差连接,将所有池块的输出特征图与输入特征图融合在一起。输出后再经过RCU,目的是在多路径融合特征图上采用非线性运算。最后,通过3个3×3卷积,使其维度变为32。此外,每个最大值池化核大小为5×5,每个卷积核大小为3×3,卷积之后使用修正线性单元ReLU(Rectified Linear Units)作为激活函数。

图3 整体网络结构
这样设计网络的优点是网络结构中使用多个identity mapping 连接,梯度可以传递到整个网络中。在网络深层,其输入为融合后的特征,经过卷积缩减特征维度,然后使用全局平均池化,这样能够减少网络参数,最后使用softmax分类器输出分类结果。
3 损失函数
3.1 文本框置信度
在大多数文本检测算法中,训练图像都是通过平衡采样处理以应对文本的不平衡分布,虽然会改善网络性能,但会引入更多的参数来进行调整,所以本文采用类平衡交叉熵作为文本框置信度的损失函数,其计算式表示为:
(1)

(2)
3.2 几何图形
自然场景图像中文本的大小变化较大,直接使用L1或L2损失进行回归将引导损失偏向于更大的文本区域,需要为文本区域生成精确的文本框预测,文本框包括文本旋转角度和文本位置信息两部分,因此,本文在文本位置部分采用IOU(Intersection Over Union)损失函数,其计算式表示为:
(3)

文本旋转角度损失计算式表示为:
(4)

Lg=LAABB+μθLθ
(5)
式中:Lg代表整体几何图损失;μθ取值为10。
3.3 损失函数融合
得到文本框置信度和几何图形的损失后,需要将二者融合为一个新的损失以便神经网络训练并更新参数,该函数表达式为:
L=Ls+λgLg
(6)
式中:L代表总的损失。由于损失函数不同,实际实验中得到的损失值有很大差别,因此,λg作为超参数用于平衡两个损失,在实验中,λg取值为1。
4 实验与结果分析
4.1 实验环境
实验设备为配置TITAN XPascal的Ubuntu16.04系统,12 GB内存。深度学习框架为Tensorflow。采用公共数据集ICDAR 2015和MSRA-TD500,ICDAR 2015包含1 000幅训练图像和500幅测试图像,MSRA-TD500包含300幅训练图像和200幅测试图像,拍摄这些图像时,由于没有考虑位置,所以场景中的文本是任意方向的。检测数据集的难点在于文字的旋转性。
4.2 评价指标
采用准确率(Precision)、召回率(Recall)和F1-score作为算法性能的评价指标,定义如下:
(7)
(8)
(9)
式中:TP是指正样本被预测为正;FP是指负样本被预测为正;FN是指正样本被预测为负;P是指准确率,R是指召回率。
4.3 训练过程
数据预处理:在训练样本较少的情况下,数据扩增的方法有利于提升网络性能,将训练集的原始图像剪裁、翻转以扩增训练样本。
参数设置:为了更好地训练网络收敛,本文使用Adam优化器,具体训练参数配置如表1所示,训练网络总耗时约144 h。
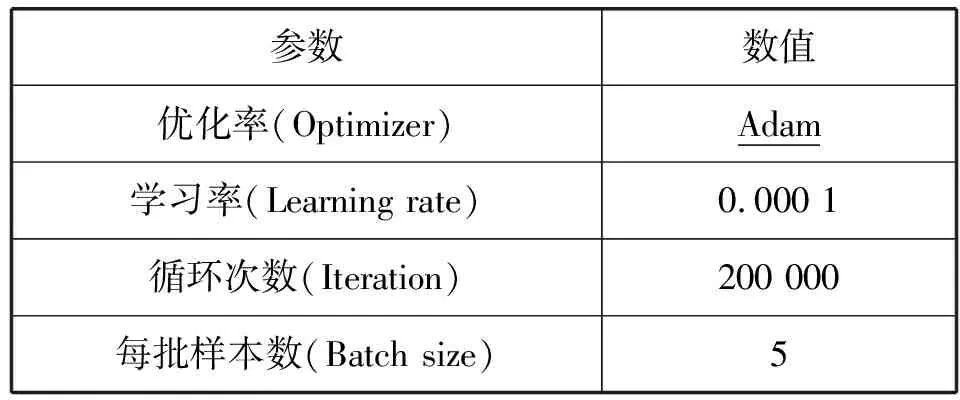
表1 训练网络的参数配置
4.4 结果分析
为了验证本算法的性能,选取现有几种优秀的文本检测算法与本文算法进行实验对比。CTPN算法是Tian等[3]提出的,它采用了数学上“微分”的思想,将文本检测任务进行拆分,转化为多个小尺度文本框的检测,并结合CNN与RNN,形成一个端到端的训练模型,不仅提升了文本定位的效果,还提升了精准度。SegLink[2]算法是2017年发表的文本检测算法,该算法能够检测任意角度的文本,融入了CTPN小尺度候选框的思路又加入了SSD算法的思路。主要思想是将文本进行分解,得到两个局部可检测的元素,即segment和link,segment是对字符或单词的方框,覆盖文本的一部分,link用来连接方框,最后检测是通过连接片段产生,并且该算法还可以检测非拉丁文。经实验,该算法使定位的准确率和训练效率得到了很大的提高。TexeBoxes++算法是Liao等[16]在2018年提出的文本定位算法,该算法是在SSD的基础上进行改进的,能够检测任意方向的文本。其核心是通过四边形或倾斜的矩形来表示文本区域。Pixel-Link算法是Deng等[17]在2018年提出的文本定位算法,该算法放弃了边框回归的思想,采用实例分割的方法,将同一个实例中的像素连接在一起,之后进行分割,然后从分割结果中得到文本边界框,这大大提升了文本定位的效果。
在TITAN X显卡上进行训练和测试,上述几种算法在ICDAR2015数据集上的结果如表2所示,本文算法召回率为81.61,准确率为85.51,F1-score为83.51。

表2 不同算法在ICDAR 2015数据集上的表现(%)
通过表2能够看出,本文算法的准确率和召回率均远高于CTPN算法,与Seglink算法对比,召回率高5%,准确率高12%,和TextBoxes++算法进行比较,本文算法在召回率上提升了4%,和Pixel-Link算法相比,在准确率上高将近3%,与EAST算法相比,准确率和召回率均有所提高,并且在实验过程中,所用的训练时间也少于EAST算法,说明本文算法检测任意文本更准确。此外,通过比较能够看出,F1-score是上述算法中最优的,表明本文的算法综合性能最好。
在MSRA-TD500数据集上的结果如表3所示。
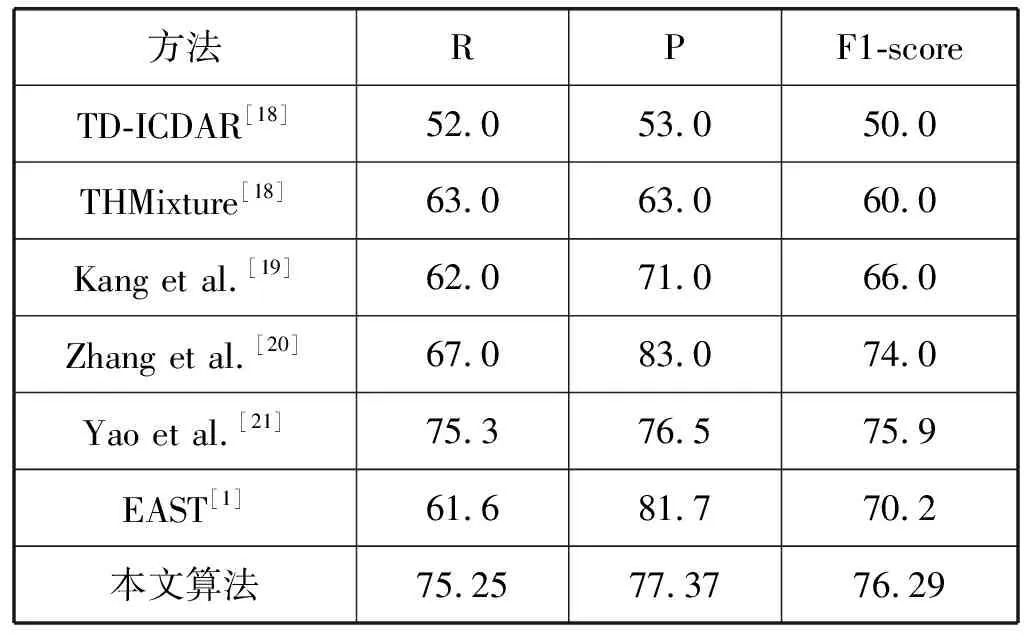
表3 不同算法在MSRA-TD500数据集上的表现(%)
通过表3能够看出,所改进方法的三个值均取得了优异的效果,表明了该方法在处理不同长度的文本行方面的卓越能力。具体来说,本文算法的F1-score略高于文献[21],与文献[20]方法相比,本文算法在F1-score上提高2.29%,在召回率上提高8.25%。
为了将实验结果直观表现出来,将真实标签值与预测值标注在图像上,如图4所示,第一组为ICDAR 2015中图像,后一组为MSRA-TD500中图像,(a)为经典EAST算法预测结果,(b)为本文算法预测结果,从图中能够看出,本文算法检测长文本效果优于经典EAST算法。

(a) EAST预测

(b) 本文算法预测图4 效果图
5 结 语
针对特征融合过程中特征信息的丢失,本文提出利用RefineNet网络改进EAST算法用于文本检测,并优化损失函数,使算法在处理样本不平衡问题上更加合理。该网络在ICDAR 2015数据集取得较好的准确率和召回率,实验表明完善特征信息有效地帮助深度卷积网络提升文本定位效果。
本文还未将注意力机制,数据增强纳入网络,也未采用多尺度训练,此外,本文方法仅对水平文字检测效果好,对于弯曲文本有待深入研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
阅读与作文(英语初中版)(2019年8期)2019-08-27
初中生世界·九年级(2018年12期)2018-12-22
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
读者(2015年9期)2015-05-04
