
一种并行出块的区块链共识算法
2022-06-29 06:47邵黑龙
阜阳师范大学学报(自然科学版) 2022年2期
邵黑龙,于 瓅
(安徽理工大学 计算机科学与工程学院,安徽 淮南232001)
引言
区块链技术是一种用密码学进行数据加密保护,P2P 网络通信,共识算法保证系统一致性的分布式账本技术。它起源于2008 年中本聪的《Bitcoin:A Peer-to-Peer Electronic Crash System》[1]一文,区块链技术作为比特币的底层支撑技术具有去中心化,不可篡改和可追溯等特性。区块链技术一经提出,就引起许多国家和企业的关注,其应用领域[2]也从最开始的加密货币领域发展到医疗,教育和物流等领域。
共识算法是区块链技术的核心,它保证了区块链系统的安全性和一致性[3]。工作量证明(Proof of work,PoW)是中本聪在比特币系统中使用的共识算法,PoW 共识算法需要节点不停地寻找随机数并计算hash 值,当hash 值满足系统的难度需求时,代表该节点成功“挖”到该区块地发布权,然后节点发布区块。由于PoW 共识算法需要不停的计算hash 值,因此巨大的能源浪费问题成了PoW 算法的弊端。为了解决这个问题,King 和Nadal[4]在PPCoin 一文中首次提出了股份权益证明(Proof of Stake,PoS)的概念,PPCoin 先通过一段时间的PoW 算法生成一定数量的代币,然后通过引入“币龄”机制进入PoS 阶段,该机制是节点拥有的币的数量越多,拥有币的时间越长,其被选为出块者的概率越大。PoS 算法虽然在一定程度上减缓了“挖矿”带来的能源消耗,但该算法同时会使区块链系统出现两极分化。由此,将传统的拜占庭容错共识算法用于区块链共识也成为了研究的热点。传统共识算法可追溯到1982 年Lamport 提出的“拜占庭将军问题”,Lamport 并在随后提出了Paxos 算法[5],但Paxos 算法只能容忍网络中存在一定数量的崩溃节点。1999 年,Castro 和Liskov[6]提出了第一个允许网络中存在一定数量恶意节点的共识算法—实用拜占庭容错协议(Practical Byzantine Fault Tolerance,PBFT),PBFT算法利用节点间三个阶段的通信,保证最少有大于三分之一总节点数目的正常节点能够达成共识。
许多学者都对PBFT 算法提出了改进,如引入信誉机制,积分机制等,这些改进提高了区块链系统的安全性,但在共识效率的提高方面效果并不明显。受到DAG 账本并行出块的思想,本文提出一种并行出块的多节点实用拜占庭容错(Multinode Practical Byzantine Fault Tolerance,MPBFT)共识算法。本文贡献如下:
1)设计多节点并行出块方式提高共识吞吐量,同时引入索引块机制,将多个事务块打包成一个区块确认,减少了事务块确认阶段的通信次数,且索引块机制解决了DAG 账本中全局顺序的问题。
2)优化了视图转换机制,MPBFT 算法的视图转换只会发生在提议阶段之后,因此,节点不需要共识新的事务块。
3)通过算法分析及实验评估了MPBFT 算法
1 相关研究
1.1 PBFT 算法简介
PBFT 共识算法是一种投票算法,在PBFT中,存在一个主节点和若干备份节点,所有节点中恶意节点的数目不超过总节点数目的三分之一。共识过程如图1 所示:

图1 PBFT 算法流程图
1)请求阶段:客户端向主节点发送请求消息<REQUEST,m,t,c>0,m是请求消息的内容。
2)预准备阶段:在共识开始时,主节点将客户端发送的请求消息m计算并生成预准备消息<<PRE-PREPARE,v,n,d>σc,m>发送给备份节点,v为当前视图编号,n是主节点为消息m分配的唯一序列号,d是请求消息m的摘要。
3)准备阶段:备份节点接收主节点发送的预准备消息并验证其合法性,验证有效后生成准备消息<PREPARE,v,n,d,i>σc并广播,与此同时,所有备份节点收集来自不同节点的准备消息,当所有备份节点收集到2f+1 个相同的与预准备消息相匹配的准备消息后进入确认阶段。
4)确认阶段:节点进入确认阶段后生成确认消息<COMMIT,v,n,d,i>σi>并广播,当所有节点收集到2f+1 个相同的确认消息后则代表共识达成,进入答复阶段。
5)答复阶段:节点将生成的答复消息<REPLY,v,t,c,i,r>σi发送给客户端,若客户端接收到f+1个相同的答复结果,则请求执行完成。
1.2 PBFT 算法研究现状
基于PBFT 算法的改进研究主要分为两种,一种是改进PBFT 算法的投票过程,如2015 年Abraham 等人提出的Hot-stuff[7]算法,该算法提出将PBFT 中的准备阶段和确认阶段并行处理,并采用线性视图转换,在一定程度上提高了共识效率。2018 年,Golan-Gueta 等人[8]提出了可扩展拜占庭容错协议SBFT,该算法将主节点作为信息、签名的收集者,利用门限签名技术降低了通信复杂度,提高了共识效率。Peilun Li 等人[9]提出的Gosig 算法,采用VRF 函数选择多个节点作为出块节点,节点通过Gossip 网络对区块进行签名,主节点利用任意序列的聚合签名技术对签名收集并验证,并且采用流水线的共识方式,提高了共识效率。但在Gosig 中,每个节点每轮只能投票给一个区块,因此,Gosig 每轮也只能达成一个区块的共识。另一种是将PBFT 算法与其他算法相结合,如Luu 等人提出的ELASTICO[10]算法,该算法使用PoW 对节点进行分片,片内运行PBFT 共识算法。由Gilad 等人提出的Algorand[11]算法,使用PoS 算法选取委员会,委员会内部运行优化的拜占庭一致算法BA★,但为了防止腐化攻击,Algorand 算法需要在一轮共识后重新选择新的委员会。
国内的学者,如方维维[12],赖英旭[13],涂园超[14],方燚飚[15],段靓[16]等人都是将PBFT 算法与信誉积分相结合,选择信誉度高的节点作为主节点或共识节点,一定程度上减少了恶意节点的共识参与,但在共识效率上提升并不明显。
1.3 基于DAG 账本结构的共识算法研究
基于链式结构的共识算法,由于只能串行的在链的末端添加区块,因此共识效率低下。由Sompolinsky 等人提出的GHOST[17]算法是DAG账本的开端,但GHOST 算法本质上只是更改了主链选择协议,处于分叉链的区块仍然不被认可。2015 年,Lewenbegr 等人[18]提出的Inclusive协议真正实现了并行出块的区块链共识算法,但自私挖矿攻击使得该算法吞吐量并不能随着区块增加而线性提高。随后Li[19]等人提出的Conflux算法,Sompolinsky 和Zohar 等人[20]提出的PHANTOM 算法都是对DAG 算法的优化和改进。基于DAG 账本结构的共识算法虽然提高了共识效率,但是需要对全局区块进行排序,以便排除冲突区块,Conflux 和PHANTOM 都有对应的排序算法,但共识的区块经过全局排序后才能达成最终共识,大大增加了区块最终确认的时间。
2 MPBFT 算法
2.1 基于MPBFT 算法的账本结构
本文结合DAG 账本技术并行出块的思想,提出多节点并行出块的MPBFT 共识算法,在基于MPBFT 共识算法的区块链系统中,账本由事务块和索引块构成,每个区块都包含一个固定的序列化轮数,账本结构如图2 所示。

图2 基于MPBFT 算法的账本结构
在MPBFT 算法中,每轮共识分为两个阶段。第一个阶段中,每个节点都可以生成事务块,事务块的区块体中包含当前系统未处理的事务,区块头中包含当前轮数r、前一个索引块的hash值、时间戳、Merkle 根等字段。第二个阶段中主节点生成索引块,索引块的区块体包含当前轮所有待确认的事务块的hash 值,区块头中包含轮数r、前一索引块的hash 值、时间戳、Merkle 根等字段。由于每个索引块都包含前一个索引块的hash值和由当前轮事务块的hash 值构成的Merkle 根,更改任何一个事务块都会改变之后的所有区块。
2.2 MPBFT 算法的相关假设与符号定义
MPBFT 共识算法与PBFT 算法有着一样的安全假设,假设如下:
1)f<(n-1)/3(f为系统中恶意节点的数目,n为系统中总的节点数);
2)节点可以通过可信的公钥基础设施(Public Key Infrastructure,PKI)验证其他节点的身份;
MPBFT 算法中,节点和区块的定义及符号表示如表1 所示:
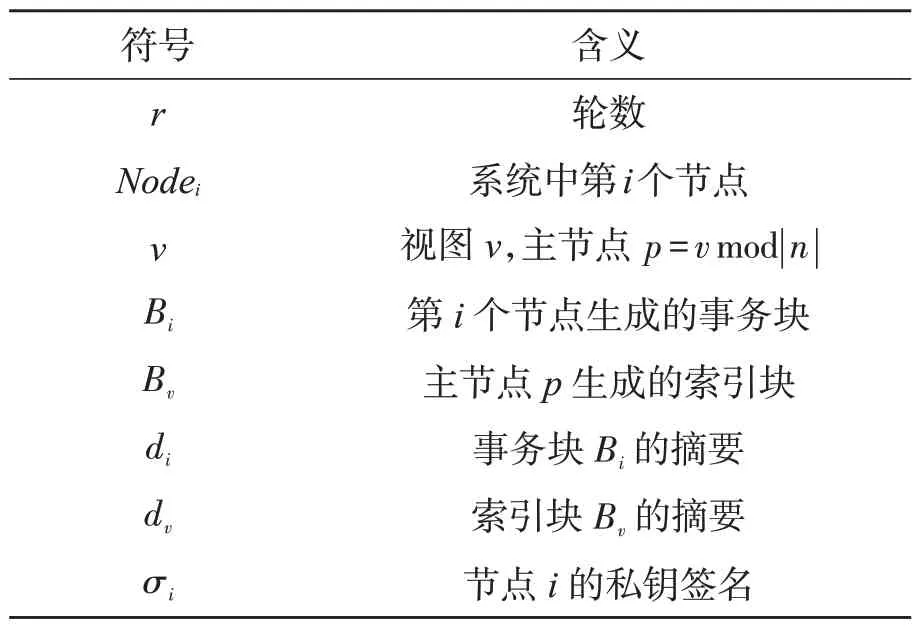
表1 MPBFT 算法中的相关符号及表示含义
2.3 MPBFT 共识算法及流程
MPBFT 共识过程分为两个阶段,第一个阶段是事务块的共识阶段,各节点通过收集其他节点的提议消息确认事务块Bi是否满足已提议状态,第二阶段是索引块Bv的共识阶段。MPBFT 算法的共识流程如图3 所示。
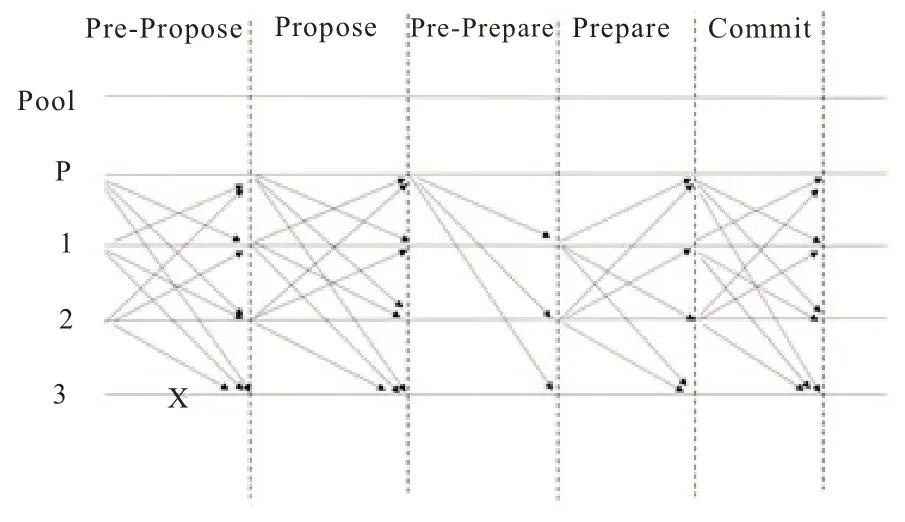
图3 MPBFT 算法流程图
1)预提议(Pre-Propose)阶段:所有节点打包当前系统中未处理的事务生成事务块,并计算生成预提议消息<<PRE-PROPSE,r,v,di,i>σi,Bi>,r是当前轮数,v为当前轮视图编号,i为当前提议节点的编号,Bi为当前节点提出的事务区块,di为该事务块的摘要,所有节点将预提议消息广播给其他节点。
2)提议(Propose)阶段:所有节点接收来自不同节点的预提议消息后,验证其合法性(包括区块所包含的事务,轮数r,区块的摘要di和节点的签名σi),验证预提议消息有效后,节点生成对应的提议消息<<PROPOSE,r,v,di,j>σi并广播。与此同时,所有节点收集来自不同节点的提议消息,如果收集到2f+1 个(包含自己)来自不同节点的具有相同r和di的提议消息,则将区块bi和对应的hash 值di标记为proposed。
3)预准备(Pre-Prepare)阶段:主节点将所有标记为proposed 的事务块的hash 值di打包生成Merkle 树,将Merkle 根包含在区块头中生成新的索引块Bv,并生成预准备消息<PREPREPARE,r,v,dv>σp,Bv>然后广播预准备消息给所有备份节点。
4)准备(Prepare)阶段:备份节点接收并验证主节点发来的预备准消息,验证内容包括索引块的区块体中所包含的事务块hash 值di是否被标记为proposed,轮数r,索引块的摘要dv和主节点的签名σv是否正确。节点验证索引块Bv合法后,生成并广播准备消息 <PRE PREPARE,r,v,dv,i>σi。与此同时,节点收集来自不同节点发来的准备消息,当节点收集到2f+1 个(包含自己生成的准备消息和主节点发送的预准备消息)相同的与预准备消息相匹配的准备消息后,将索引块Bv和索引块Bi包含的事务块标记为prepared,并进入确认阶段。
5)确认(Commit)阶段:节点进入确认阶段后计算生成确认消息<COMMIT,r,v,dv,i>σi并广播,同时节点收集其他节点发送的确认消息,当节点收集到2f+1 个(包含自己)来自不同节点的具有相同r和dv确认消息后,将索引块Bv和索引块所包含的事务块Bi标记为committed,并将区块Bv和Bi加入到本地区块链上。
2.4 视图转换
与PBFT 算法不同的是,MPBFT 算法的视图转换只会发生在提议(Propose)阶段之后。在共识开始后,每个节点会运行一个计时器,当计时器在时间内没有接收到来自主节点的预准备消息(包含合法的索引块)时,节点启动视图转换,并广播视图更改消息 <VIEW-CHANGE,r,v+1,dv-1,i>σi,dv-1为前一个索引块的hash 值。MPBFT 的视图更改消息比PBFT 要简化的多,由于r和dv-1可以保证系统的状态一致性,因此,节点在发送view-change 消息时不用像PBFT 算法那样,在视图更改消息中添加2f+1 个检查点消息和2f+1 个前一阶段的准备消息。
当新的主节点p(v+1 视图下)收集到2f+1个(包含自己)相同的view-change 消息后,多播新视图消息<<NEW-VIEW,r,v+1,V,dv+1>σ,Bv+1>(V为2f+1 个有效的view-change 消息组合),需要注意的是,由于MPBFT 视图转换只会发生在提议(Propose)阶段之后,在此阶段所有正常节点都至少拥有2f+1个标记为proposed 的事务块,因此新的主节点不需要在广播新的预准备(Pre-Prepare)消息,直接将新的索引块Bv+1和dv+1其摘要添加到new-view 消息中。其余节点接收到newview 消息后直接计算并生成准备消息,并继续按照2.3 所述流程进行下一步共识。
3 算法分析
3.1 安全性分析
定理1在提议阶段,共识过程中若proposed(di,r,v)为真,则proposed(d′i,r,v)一定为假,准备阶段,确认阶段同理。
证明若proposed(di,r,v)为真。则至少2f+1个节点在发送了具有相同di,r,v的提议消息,若proposed(d′i,r,v)为真,则至少2f+1 个节点发送了具有相同(d′i,r,v)的提议消息。则:
2f+1+2f+1-(3f+1)=f+1
即至少有f+1节点在此阶段即发送了相同的(di,r,v)提议消息,又发送了相同的(d′i,r,v)提议消息,这种行为是恶意的,但系统中最多存在f个恶意节点,因此互相矛盾,故共识过程中若proposed(di,r,v)为真,则proposed(d′i,r,v)一定为假。
3.2 效率分析
BFT 类共识算法的共识效率主要与节点间的通信次数有关,MPBFT 算法中索引块的机制将PBFT 算法中多轮的确认阶段缩减为一轮确认,因此减少了通信次数。下面对PBFT 算法和MPBFT 算法在个共识节点中存在f个拜占庭节点的情况进行通信分析。
在共识中存在最多f个恶意节点时,此时当主节点为恶意节点时,节点会发生视图转换,因此PBFT 算法一轮共识1 个区块所需的通信次数至少为:

其中,p为一轮共识发生视图转换的概率,p=。
MPBFT 算法一轮最少共识2f+1 个事务区块,PBFT 算法共识2f+1 个区块需要2f+1 轮共识,因此PBFT 共识2f+1 个区块所需的通信次数为:
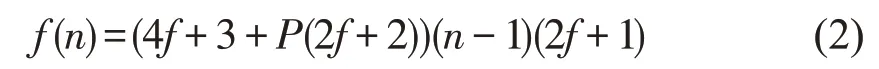
在共识中存在最多f个恶意节点时,MPBFT算法一轮所需的最少通信次数为:

取节点总数分别为4,7,10,13,16(即f分别为1,2,3,4,5)得PBFT 算法与MPBFT 算法共识2f+1 个区块的通信次数对比图,通信次数如图4所示:

图4 共识2f+1个区块时PBFT与MPBFT通信次数
由图4 分析可得,MPBFT 算法与PBFT 算法共识相同数量的区块时,MPBFT 算法所需的通信次数少于PBFT 算法,且随着区块数量的增加,通信次数的差值也逐渐增加。
4 实验结果及评估
本文基于go 语言实现了PBFT 和MPBFT 算法,实验环境配置在一台Intel(R) Core(TM) i5-6300HQ CPU@2.30GHz、8G 内存、操作系统为windows10 64 位的计算机上,由于MPBFT 算法提高了一轮共识的通信复杂度,只适用于少量节点共识,又受限于设备限制,因此在本地开启4 个端口模拟4 个节点进行共识,每个事务区块包含1000 条事务,实验过程中通过输出时间戳记录共识时延,共识吞吐量等数据。
4.1 共识时延
共识时延指客户端向节点发送请求到收到f+1个相同答复消息的时间,用Δt表示。

在本地开启4 个共识节点,1 个客户端节点,记录客户端发送请求的时间戳与收到f+1个相同答复消息的时间戳。为不失一般性,实验30 次取平均共识时延,PBFT 和MPBFT 的共识时延如表2 所示:

表2 PBFT 和MPBFT 共识时延对比
从表2 中可以看出,在4 个节点参与共识的情况下,MPBFT 算法一轮共识的共识时延比PBFT 算法的共识时延多0.7 s,但实验中MPBFT算法一轮共识3 个区块,PBFT 算法一轮仅共识1个区块,PBFT 算法共识3 个区块则需要6.42 s,远远高于MPBFT 算法。
4.2 事务吞吐量
事务吞吐量是衡量共识算法性能的重要指标,在区块链系统中指的是每秒达成共识的事务数量,用TPS 表示
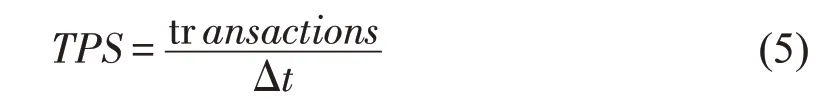
实验中,4 个节点作为共识节点,每个节点打包1000 条事务为一个区块,实验共识30 次,其吞吐量对比如图5 所示:

图5 PBFT 和MPBFT 吞吐量对比
从图5 中可以看出,由于MPBFT 算法并行出块,其吞吐量远高于PBFT 算法,吞吐量维持在1000-1200 之间,PBFT 算法的吞吐量仅维持为400-600 之间。
通过共识时延和吞吐量对比,可以得出MPBFT 共识算法在性能和效率上优于PBFT 共识算法。
5 结束语
目前的BFT 类共识算法是一种串行共识算法,共识效率较低。本文结合DAG 账本并行出块的思想,提出多节点提议事务块,主节点生成索引块的MPBFT 算法。索引块的共识机制不仅减少了事务块在确认阶段的通信复杂度,而且维护了账本的全局顺序。但改进的MPBFT 算法只支持少量节点的共识,在后续的工作中,将考虑结合聚合签名等算法进一步减少节点间的通信复杂度。
猜你喜欢
节能与环保(2022年7期)2022-11-09
数学小灵通·3-4年级(2021年12期)2021-08-26
当代党员(2019年19期)2019-11-13
散文诗世界(2019年10期)2019-09-10
学生天地·小学中高年级(2018年10期)2018-12-13
电脑知识与技术(2017年27期)2017-11-20
计算技术与自动化(2017年3期)2017-10-26
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
试题与研究·中考数学(2016年4期)2017-03-28
