
基于Transformer模型的卫星单目位姿估计方法
2022-07-04 02:27王梓孙晓亮李璋程子龙于起峰
航空学报 2022年5期
王梓,孙晓亮,*,李璋,程子龙,于起峰
1.国防科技大学 空天科学学院,长沙 410073
2.中国航天员科研训练中心,北京 100094
非合作卫星目标位姿估计(三维旋转+三维平移)是实现交会对接、编队飞行、空间碎片清除等应用的关键技术之一。基于单目视觉的非合作目标位姿估计技术以其低功率、低质量、小体积等优势受到了国内外研究人员的广泛关注,并得到了充分研究。相比双目位姿估计方案,单目视觉具有视场大、可靠性高的优势。于2020年,欧航局高级概念小组与斯坦福大学交会对接实验室共同发起了KPEC (Kelvins Pose Estimation Challenge)比赛,并发布了航天器位姿估计数据集(Spacecraft PosE Estimation Dataset, SPEED),聚力推动空间非合作卫星目标位姿估计技术相关研究。
针对非合作目标单目位姿估计,传统方法依赖人工设计的特征,如SIFT (Scale Invariant Feature Transform)、SURF (Speeded Up Robust Features)等,依靠位姿先验通过特征点检测与匹配建立二维-三维对应关系,进而通过求解n点透视(Perspective-n-Points, PnP)问题得到相对位姿参数。然而,面对复杂光照环境、弱纹理或结构复杂的刚体目标,人工设计的特征在稳定性、鲁棒性等方面显出不足。此外,若不结合位姿先验,传统方法求解的可靠性较差。近年来,卷积神经网络(Convolutional Neural Network, CNN)技术得到了快速发展,凭借其强大的特征提取与表达能力在计算机视觉、图像处理等领域得到了广泛应用。已有基于CNN的目标单目位姿估计方法,依据位姿参数估计的方式,可以分为直接法和间接法。
直接法无需显式建立二维-三维对应关系,采用回归或分类的形式直接得到目标位姿参数。由于旋转和平移的物理量纲不同,通常采用分离的表示方法,即将物体的旋转和平移分开表示。在SPEED数据集上,Proença和Gao使用高斯混合模型与软标签技术实现了旋转量的预测。Sharma和D′amico提出了Spacecraft Pose Network (SPN),实现了2D目标检测,使用2D检测框内的图像估计相对姿态,然后利用2D检测框与相对姿态形成的约束条件,使用高斯牛顿方法求解平移量。
间接法使用点、线等特征表示刚体目标,该类方法首先预测二维到三维的对应性,然后通过PnP方法求解目标位姿参数。相关方法可进一步分为基于密集坐标表示和基于稀疏坐标的表示方法,前者一般预测二维图像上目标掩膜区域所有像素到三维模型上的对应关系,后者则首先定义一组稀疏的控制点,例如三维模型包围框角点、模型表面特征点等,进而预测这些点在二维图像上的坐标。Chen等使用热力图表示方法回归目标稀疏关键点,使用模拟退火算法筛选外点,并设计非线性优化方法求解PnP问题;Park等使用向量表示目标关键点序列,使用EPnP解算目标位姿参数;Huan等同样使用向量表示关键点,然后通过非线性优化求解位姿;EPEL_cvlab将图像均匀分割成若干网格,借助图像分割的方式预测卫星的8个三维包围框角点,使用EPnP求解位姿。
虽然基于CNN的方法在目标单目位姿估计中取得了优越的性能,但依然存在诸多不足。首先,CNN存在归纳偏置问题,导致训练得到模型泛化能力不足;其次,CNN在训练过程中缺少绝对位置信息,对绝对位置的描述不够直接;最后,CNN的长距离建模能力不足,缺少对关键点间的上下文建模。上述问题限制了已有相关方法的实际工程应用,尤其是当训练数据与测试数据有较大差异时,模型性能表现较差。例如缺少获得高质量6D标注的真实图像、仅能使用仿真渲染图像进行训练的场景,对模型的泛化迁移能力提出了更高要求。因此,本文在已有工作的基础上探索了新的神经网络结构,即基于注意力机制的Transformer模型,在航天器等刚体目标单目位姿估计中的应用。
注意力机制是一种新型深度学习模型,用于对整个输入序列的自身长距离建模,比CNN具有更好的泛化能力,该模型在自然语言处理领域取得了巨大成功。Vaswani等在注意力的基础上设计了一种用于机器翻译的端到端模型Transformer,在多个语言任务上取得了最佳性能。将Transformer思想应用于计算机视觉领域,设计面向不同视觉任务的端到端模型,近年来得到了研究人员的广泛关注。Carion等首先使用Transformer模型实现了端到端的二维目标检测器(DEtection TRansformer, DETR),达到了与Faster RCNN相近的性能水平;He等将Transformer应用在高光谱图像分类上,在分类精度和计算时间上均优于已有基于CNN的模型。Liu等针对车道线检测任务,重新参数化车道线的表示,借助Transformer模型实现了端到端的车道线参数回归,在车道线检测精度、计算耗时、迁移泛化等方面取了良好性能。
针对已有方法的模型泛化迁移能力不足、缺少上下文建模等问题,本文探索了Transformer模型在单目刚体位姿估计中的应用,创新地提出了一种基于端到端关键点回归的卫星单目位姿估计方法:首先设计一种基于关键点集合的刚体目标表示方法,并构建了相应的损失函数,其中每个关键点的表示由坐标项和分类项组成,其中坐标项描述了关键点的位置,分类项描述了关键点的序号;进一步,依据目标表示形式本文设计了预测关键点集合的端到端回归网络模型,并根据任务特点改进了用于特征提取的主干网络结构。不同于已有基于稀疏点集的目标表示方法中关键点与预测点之间一一对应的有序形式,本文方法输出预测点是无序的,预测点与事先定义关键点间的对应性由网络预测并通过概率模型得到,坐标预测头和类别预测头分别输出一组坐标项和分类项,其逐项的组合构成关键点集合的预测值,属于端到端集合预测,有利于关键点间的上下文建模,减少模型对数据的归纳偏置。最后,在公开数据集上的实验测试结果表明,本文方法实现了可靠、高效的卫星目标单目位姿估计,性能优于已有同类方法。本文贡献总结如下:
1) 探索了新的神经网络结构在航天器位姿估计中的应用,创新地将Transformer模型应用到刚体目标单目位姿估计中,获得了更优的迁移泛化能力。
2) 设计了一种基于关键点集合的刚体目标表示方法,并构建了相应的损失函数和位姿求解方法,使用网络预测建立输出的语义关键点与事先定义的三维关键点间的对应性,增强了模型对关键点间上下文建模的能力。
3) 设计了用于关键点回归任务的网络结构,针对关键点回归任务改进了用于特征提取主干网络结构。
1 刚体目标单目位姿估计及基于关键点集合的目标表示
本节首先对刚体目标单目位姿估计问题进行简要描述,然后对本文提出基于关键点集合的刚体目标表示方法及损失函数设计进行详细阐述。
1.1 刚体目标单目位姿估计问题
刚体目标单目位姿估计通过建立二维-三维对应关系,求解目标位姿参数。设刚体目标在相机坐标系下的位姿为∈,∈,第个关键点的三维坐标为[,,],其像点坐标的估计值[,]。由针孔成像模型可得约束

(1)
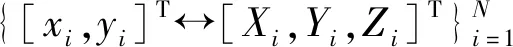
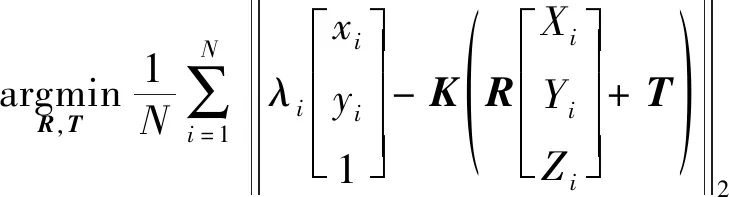
(2)
当存在3组及以上关键点时,式(2)可解,例如P3P、EPnP等求解方法。为提升算法对匹配外点的鲁棒性,本文使用随机采样一致性 (RANdom SAmple Consensus, RANSAC)方法实现鲁棒估计。
1.2 基于关键点集合的刚体目标表示方法
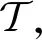
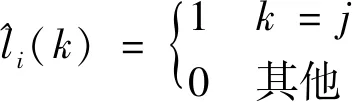
(3)
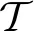
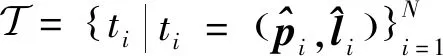
(4)

(5)
图1给出了使用本文描述方法表示一个包含11个关键点的刚体目标的具体形式,其中对于不属于集合中的点,其分类项的最后1项为1。由于本文描述方法具有无序性,图中的下标不能用于由元素到三维空间点的索引。
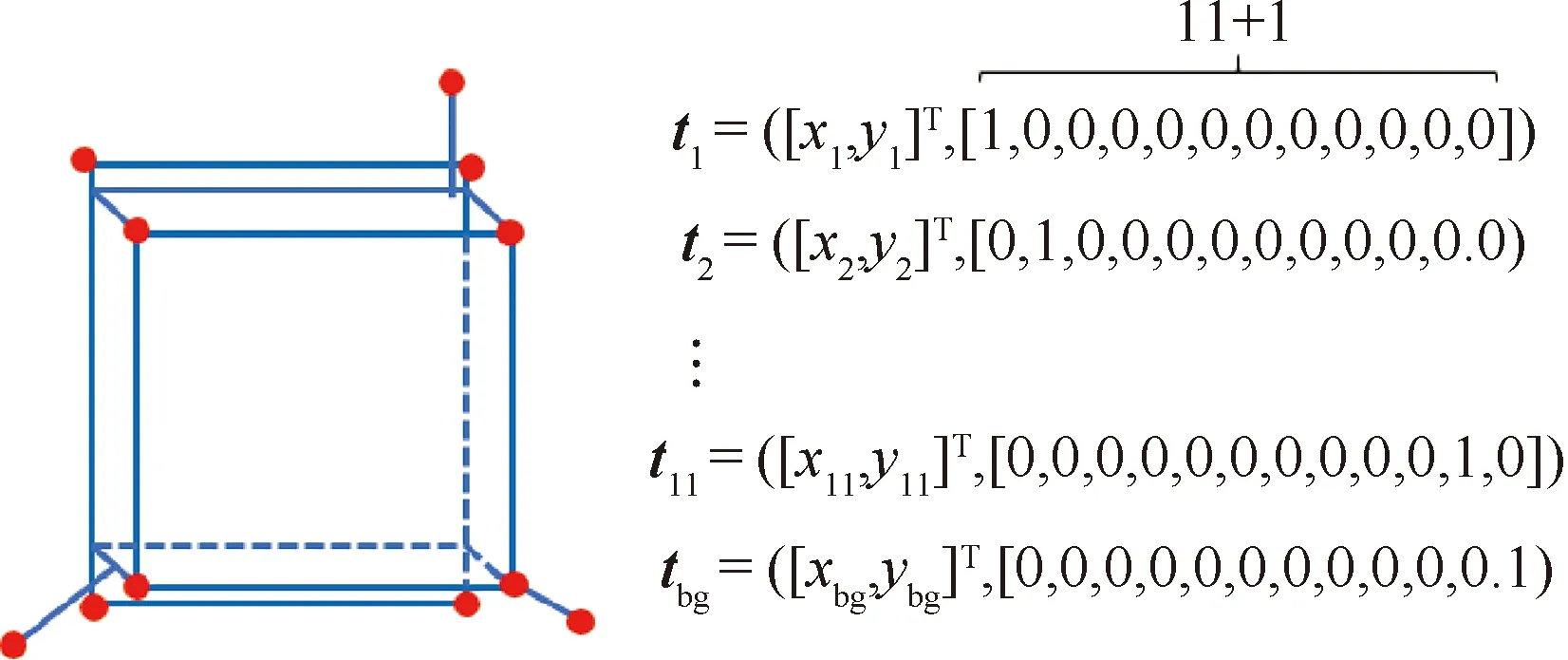
图1 基于本文方法描述包含11个关键点的刚体示意图Fig.1 Description of a rigid object with 11 key points using proposed representation method
1.3 损失函数定义
本文采用关键点集合的形式表示刚体目标,决定了模型的预测输出是元素数量固定的集合,每个元素由坐标值和类别预测概率组成
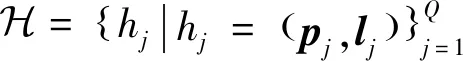
(6)
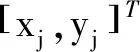
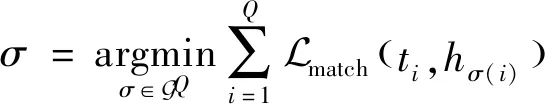
(7)
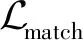
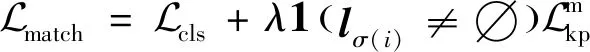
(8)
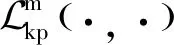
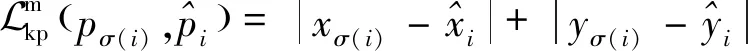
(9)
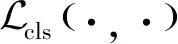
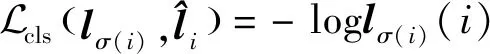
(10)
通过匈牙利算法求解式(7),得到点对应集合。
在得到单射函数后,网络的损失定义为
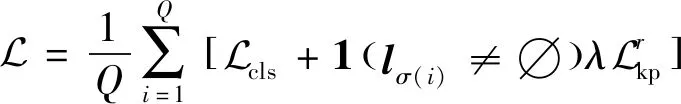
(11)
式中:坐标项的损失采用了smooth损失,

(12)
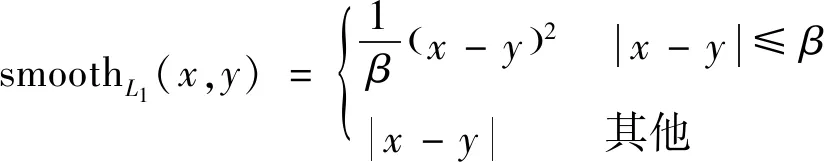
(13)
2 基于Transformer模型的端到端关键点回归网络
基于关键点集合的卫星目标表示方法,本节提出端到端关键点回归模型,设计一种适合关键点任务的主干网络,详细描述了模型结构。
2.1 整体结构
如图2所示,本文模型主要包含4个部分。第1个组件由在ImageNet上预训练的卷积神经网络和位置编码模块组成,分别用于提取特征和提供特征图的位置编码,称为主干网络。第2个组件是编码器,该组件将主干网络输出的二维语义特征图和位置编码图堆积并展平为一维,送入多层Transformer模型中,输出编码特征向量。第3个组件是解码器,该组件输入是查询向量、特征向量和位置编码向量,输出是解码特征向量。最后一个组件是前向传递网络,即线性层,由坐标项预测头和分类项预测头组成,两者分别从解码特征向量中得到坐标项和分类项的预测。
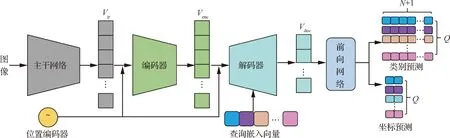
图2 基于Transformer模型的端到端关键点回归网络模型总体结构Fig.2 Overall architecture of transformer-based end-to-end key points regression network
2.2 主干网络结构
本文结合Transformer模型特点,以ResNet-50为基础,设计了一种适用于关键点回归的主干网络。一方面,特征图的尺寸越接近输出图像尺寸,位置信息保留越充分;另一方面,训练Transformer模型所需要的显存与特征图像素个数的平方成正比,如输入特征图过大,模型几乎是不可训练的。为平衡两者的需求,本文拟将主干网络输出的特征图尺寸降为输入图像的1/8。如图3所示,在ResNet-50的基础上,使用了Layer2和Layer3的输出。Layer2和Layer3输出的特征图尺寸分别是原图像的1/8和1/16。对于Layer2的输出,使用1×1卷积调整通道数量;对于Layer3的输出,依次经过上采样和3×3卷积得到1/8特征图。最后将Layer2和Layer3的特征图叠加,并通过1×1卷积调整通道数量输出1/8特征图。表1给出额外卷积层的通道数。
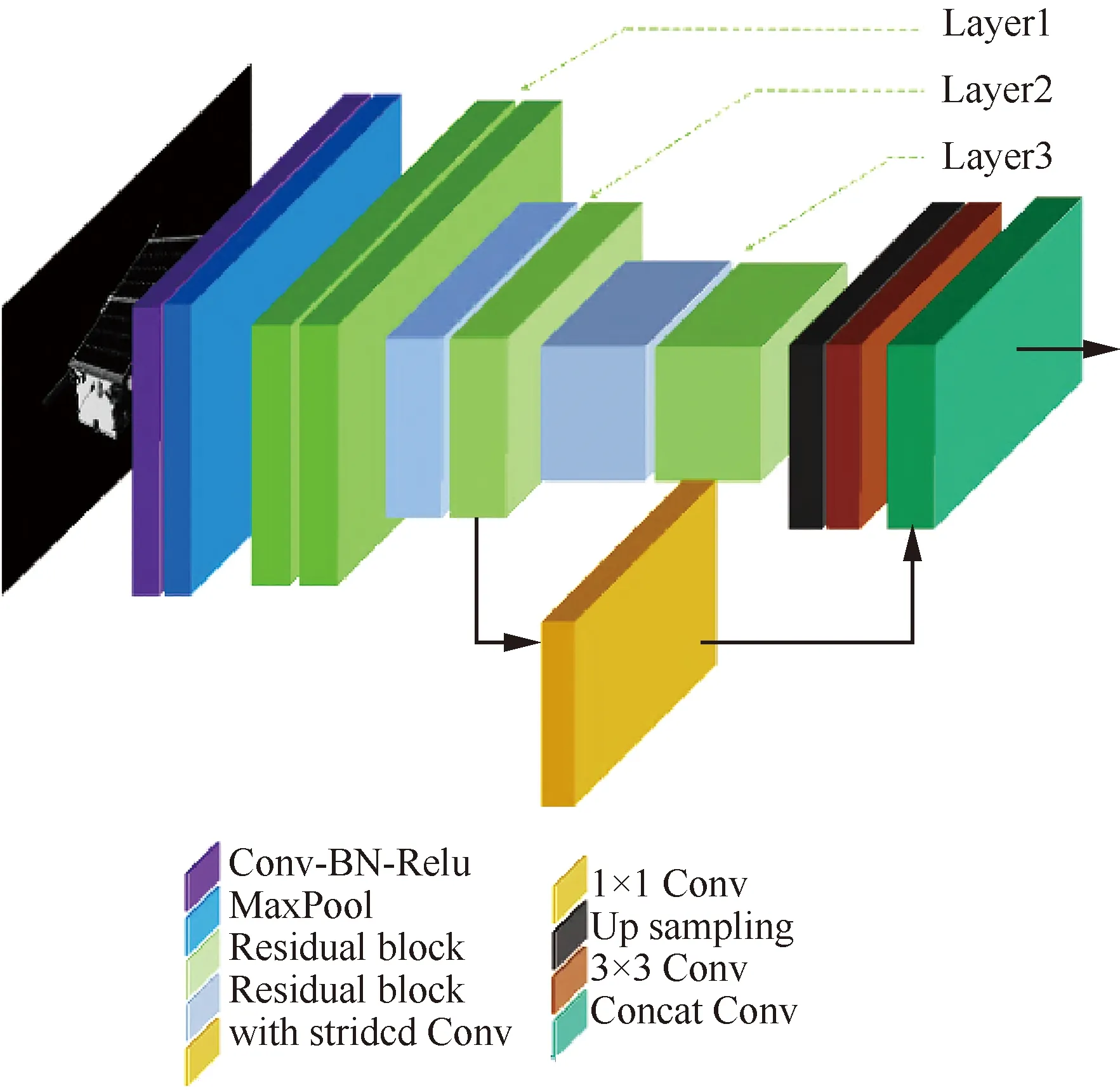
图3 主干网络结构示意图Fig.3 Structure of backbone

表1 主干网络中额外卷积层的通道数Table 1 Number of channels of additional convolution modules in backbone
2.3 编码器与解码器结构
编码器与解码器的结构如图4所示,主要结构包括多头注意力模块、跳转连接与正则化模块和前向传递模块。多头注意力模块(Multi-Head Attention, MHA)是编、解码器的核心,其结构如图5所示。单头注意力模块即为缩放点积注意力,即

图4 编码器和解码器模块结构示意图Fig.4 Structure of encoder and decoder module
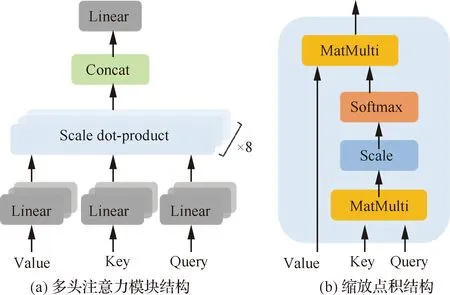
图5 多头注意力模块结构和缩放点积结构Fig.5 Structure of multi-head attention module and scale dot-product
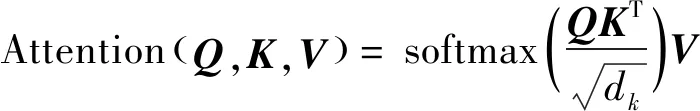
(14)
式中:、和分别表示查询向量、键向量和值向量;为输入数据的维度。多头注意力机制表述为
MHA(,,)=Concat(,,…,)
(15)

(16)
相比于缩放点积注意力,多头注意力机制将输入线性映射到个不同空间里计算特征相关性,提高了特征的表达能力。正则化模块(layer-Nnormalization, Norm)用于降低训练过程中的数据偏差,提高训练的稳定性。前向传递模块(Feed Forward Network, FFN)由2个线性变换单元和1个修正线性单元组成
FFN()=max(+,0)+
(17)
3 实验与分析
本节首先介绍用于分析的公开数据集和评价指标,然后在实验细节方面,介绍整体实验的流程和神经网络的参数以及关键点、目标检测真值的获取方法。最后的分析实验主要分为2部分,首先在训练数据集上分别完成组件分析实验,以确定最优的网络结构、组件层数等超参数;然后分别在训练数据集和测试数据集上完成了精度分析实验,与当前业界最优算法比较,分析本文方法优势。
3.1 数据集与评价指标
为验证本文方法性能,使用SPEED数据集进行实验,该数据集提供了Tango卫星图像,像素尺寸为1 920×1 200,仅训练集提供卫星的位姿真值。表2给出了训练集和测试集中真实与仿真图像的数量,训练集仅有5张真实图像。本文在训练集上完成组件分析实验和交叉验证实验,完成参数调优。通过将位姿估计结果上传至KPEC平台,在线测评得到2种测试集的评分结果。

表2 SPEED数据集中训练集和测试集图像数量Table 2 Number of images for training set and validation set in SPEED
SPEED数据集中的仿真图像分有无地球背景2种,真实图像均无背景。仿真图像中卫星目标的距离跨度较大,从3~40.5 m,卫星目标在图像中所占像素从1 k~500 k不等,为位姿估计带来较大挑战。真实图像中目标距离从2.8~4.7 m,真实图像与仿真图像有较大差异,如图6所示。

图6 SPEED训练集部分图像示例Fig.6 Example images of SPEED train set
对于6D位姿估计结果,旋转量的得分为旋转向量的夹角
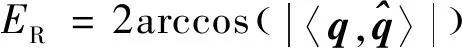
(18)
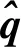
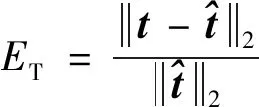
(19)
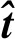
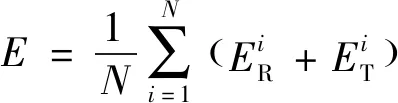
(20)

3.2 实验细节
3.2.1 整体实验流程与参数设置
图7展示了本文通过关键点回归进行刚体位姿估计的流程。首先,输入图像经过目标检测器得到目标的二维包围框,然后对输入图像进行裁减、缩放得到尺度相同的图像作为关键点回归网络的输入;经过关键点回归网络输出关键点的像素坐标,最后经过RANSAC+PnP得到目标的位姿。
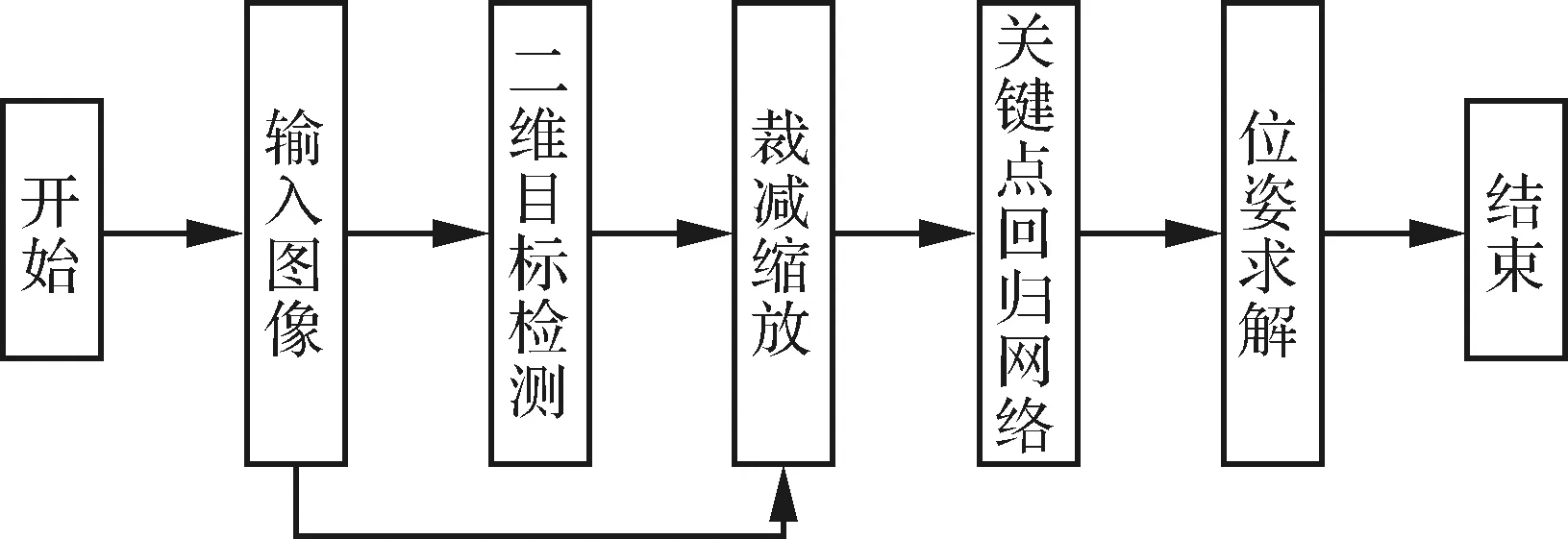
图7 基于关键点的刚体位姿估计流程图Fig.7 Flow chart of keypoints-based pose estimation of rigid object
在2D目标检测中,本文使用了mmdetection中的Faster RCNN,训练数据为12 000张仿真训练图像,图像尺寸短边为800,长边不超过1 333,批大小为6,epoch总数为3。使用随机梯度下降法(Stochastic Gradient Descent, SGD)进行优化,初始学习率为0.01,第1个epoch之后降为0.001,动量为0.9,权重衰减系数为0.000 5。数据增强包括随机旋转、随机亮度和对比度调整、RGB值漂移、JPEG压缩质量、高斯噪声、ISO噪声、模糊等。
在关键点回归实验中,本文将12 000张仿真训练数据集随机分为6等分,进行6-fold交叉验证,以更好地分析并选择模型中的超参数。批大小为20,epoch总数为150。使用SGD进行优化,初始学习率为0.000 1,在第100个epoch之后降为0.000 01,动量为0.9,权重衰减系数为0.000 5。数据增强方法与2D目标检测基本一致。考虑到Transformer模块占用的显存受输入特征图的尺寸影响较大,本文将裁减之后的图像缩放为224×224。
在位姿求解的过程中,求解方法为EPnP,RANSAC算法中重投影误差阈值为20个像素,最大迭代次数为20。
3.2.2 关键点与检测框真值获取
SPEED训练集仅标注了目标卫星的位置和姿态,没有给出目标卫星的三维模型。如图8所示,本文以文献[23]的方法为基础,从训练集中选择若干图像,手工选择11个关键点,使用多视图三角的方法求解关键点的三维坐标,以重投影误差3为标准剔除粗大误差。根据关键点三维坐标,重投影得到相对应的像素坐标,作为关键点回归的真值,以关键点包围框作为2D目标检测的真值。
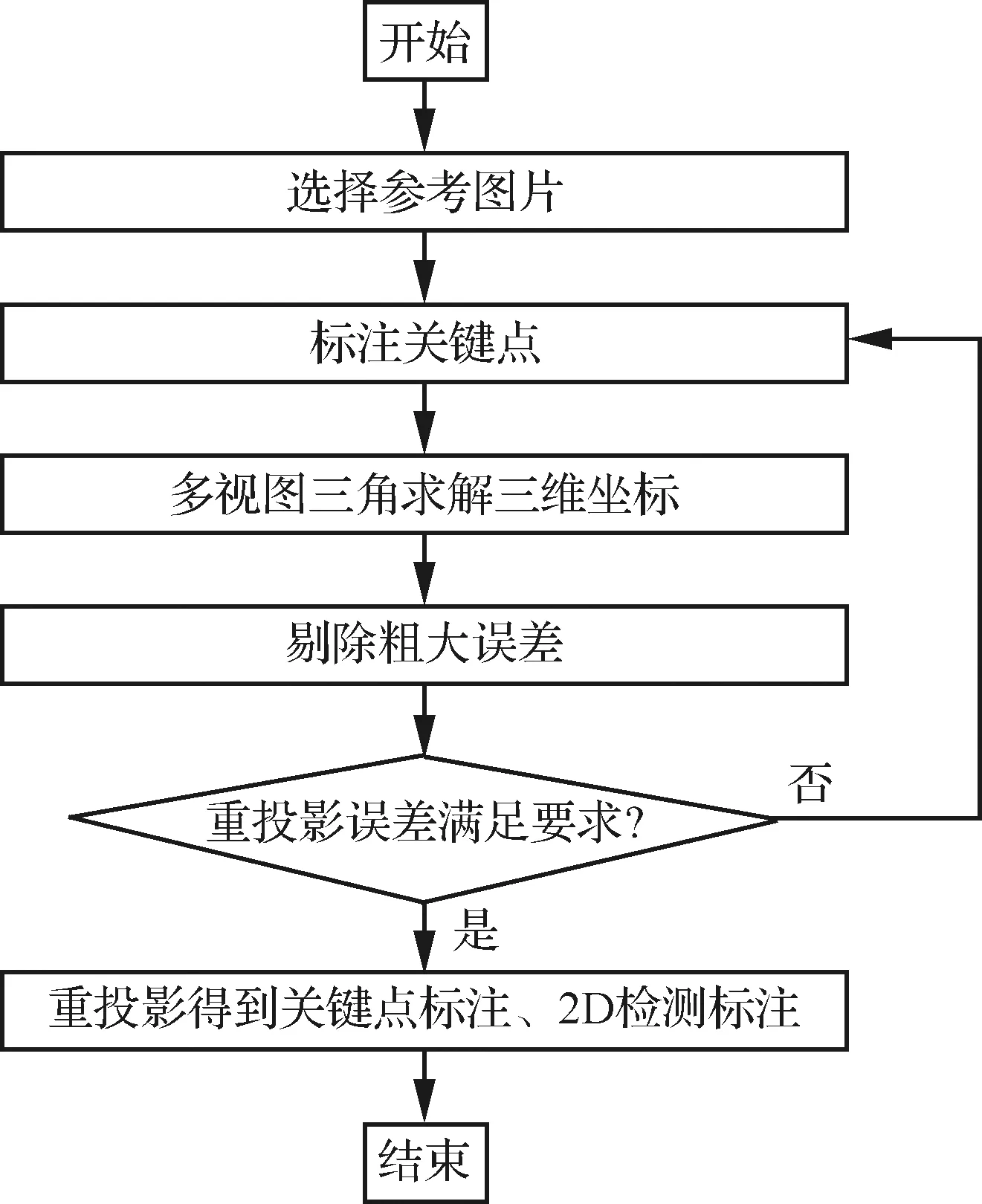
图8 由位姿标注得到关键点和2D目标检测标注流程图Fig.8 Flow chart of acquiring keypoints and 2D bounding boxes from pose annotations
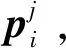
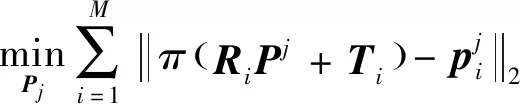
(21)
得到,其中:(·)表示透视模型,即
([,,])=[,,1]
(22)
在得到关键点三维坐标之后,由于训练集中每幅图像位姿真值已知,可以通过针孔成像模型式(1)得到每个关键点在每幅图像中的像素坐标,从而得到关键点真值。
3.3 组件分析实验
本节将仿真训练数据集进行6等分,以前5组作为训练集,最后1组作为测试集,分析主干网路结构、编/解码器层数、查询向量个数、图像缩放尺寸对位姿估计精度的影响。本节分析实验默认参数为:批大小为15,查询向量个数为40,图像缩放尺寸为224,epoch总数为150。由于模型训练所占用的显存受待考察超参数的影响,相应的编、解码器层数越少,查询向量个数越少,图像缩放尺寸越小,则占用显存越少,可增加批大小以获得更好性能,因此最佳性能需要在本节实验的基础上调参获得。
3.3.1 主干网络
针对关键点回归任务的特点,2.2节中设计了特征图分辨率为输入图像1/8的主干网络,本节将简要分析主干网络的作用。为方便描述,将本文设计主干网络称为ResNet50s8,将原ResNet-50的第3个残差模块输入的网络称为ResNet50s16,后者特征图分辨率为输入图像为1/16。为公平比较,实验中将ResNet50s8和ResNet50s16的输入尺寸分别设为224和448,使其特征图分辨率相等。批大小设置为1,重复计算100次,统计主干网络的平均计算耗时。两者得分与计算耗时比较如表3所示。可见,在特征图分辨率相同的情况下,本文设计的ResNet50s8在得分上有明显优势。在计算耗时上,本文在ResNet50s16的基础上添加了上采样层与2个卷积层,所增加的计算时间约为0.7 ms,几乎可以忽略不计。

表3 2种主干网络得分与耗时比较Table 3 Comparison of two backbones in terms of score and time-consumption
3.3.2 编、解码器层数
为方便描述将编、解码器层数为的模型称为,图9展示了不同模型得分随训练进行的变化。首先以最终得分来看,随着编、解码器层数的增加,模型得分先增加后减少。其次,随着训练进行,复杂度最高的和最低的的得分下降最慢,且收敛之后的最终得分也低于其他模型。其解释为:一方面,编、解码器层数过少,会导致对卷积网络提取的特征解释不足;另一方面,随着编、解码器层数的增加,不同特征之间相互包含程度越大,对关键点定位不利。在该试验的设置下,当编、解码器层数为5时达到最佳得分。当减少层数时,可以使用更大的批次进行训练。因此,该超参数的最佳选择范围为3~5。
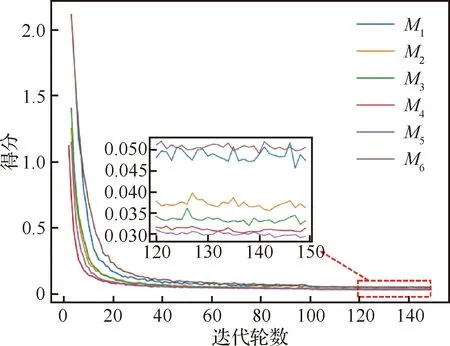
图9 不同编、解码器层数的模型在训练过程中的得分Fig.9 Scores of models with different encoder/decoder layers during training
3.3.3 图像输入尺寸
2.2节中提到,提高特征图分辨率有利于关键点回归任务,因此,增加输入图像的尺寸应该也可以提高位姿估计精度。如表4所示,随着图像输入尺寸的体征,模型得分呈现明显的减小的趋势,再次验证了本文观点。当输入尺寸达到272时,模型得分略微上升,其原因可能有2点:① 实验中噪声所致;② 输入尺寸应与RANSAC+PnP的参数相适配。但是输入图像越大,占用显存急剧增加,对该值的选择应在224~256。

表4 不同图像输入尺寸的模型得分Table 4 Scores of models with different input sizes
3.3.4 查询向量个数
不同查询向量个数的模型得分如表5所示,可见,随着查询向量数量的增加,位姿求解精度呈现微弱的提高趋势。该现象可以解释为模型的复杂性提高,增强了模型对数据的拟合。增加查询向量个数会提高训练所需显存,因此该值的选择不应超过40。

表5 不同查询向量个数的模型得分Table 5 Scores of models with different query numbers
3.4 精度分析实验
本节进行实验分析位姿估计精度,并与业界最优方法进行比较。由于SPEED数据集没有提供测试数据集的位姿真值,本节首先在训练数据集上完成交叉验证实验,给出较为详细的实验数据分析;然后将测试集位姿估计结果上传至比赛平台得到评分,通过与同类型方法比较分析本文方法的优劣。
3.4.1 仿真训练数据集实验
将训练数据集6等分,选择其中5组进行训练,剩余1组进行测试,6组实验的详细结果如表6所示。选择SPN和文献[14]进行对比,其中SPN将视角采样离散化,将旋转量预测描述为分类问题和偏移量回归问题,并结合2D检测结果求解平移量。文献[14]采用的方法与本文方法类似,选择11个关键点,在目标检测部分使用更强的检测器,在关键点回归部分采用更复杂的主干网络,图像输入尺寸与本文相同,使用维度为1×1×22的向量表示所有关键点序列。表6说明,相对于同类型基于关键点的方法,本文方法在旋转量和平移量上有较高提升,验证了本文方法的优势。
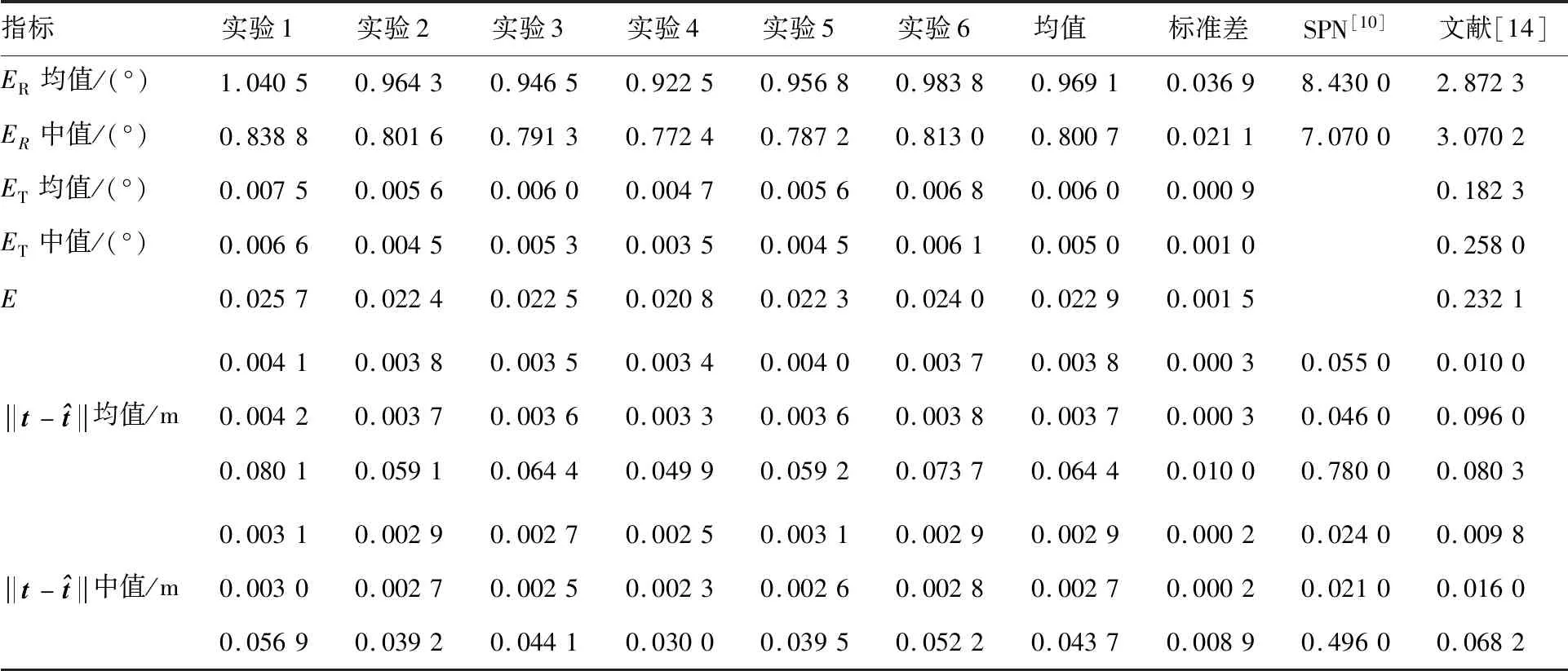
表6 训练数据集上的实验结果Table 6 Experimental results on training dataset
图10可视化了一组交叉实验训练过程中,模型在分割测试数据集上的归一化重投影误差为
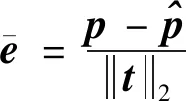
(23)
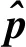

图10 一组交叉验证实验中不同迭代轮次的归一化重投影误差散点图Fig.10 Scatter plots of normalized reprojection errors for different iteration epochs in a cross validation experiment

图11 部分测试图像上的预测结果Fig.11 Prediction results of some images from test set
3.4.2 测试数据集实验
在使用单个模型进行预测的基础上,本文将在仿真训练数据上分割的6个训练集上得到的模型进行集成,以得到更优效果。集成方法为将模型预测结果先以3为标准剔除,然后求平均。在部分真实、仿真测试图像上的目标检测与关键点重投影结果如图12和图13所示。

图12 在仿真测试数据集上的部分图像二维目标检测与关键点重投影Fig.12 Results of 2D object detection and key points re-projection of part of synthetic test images
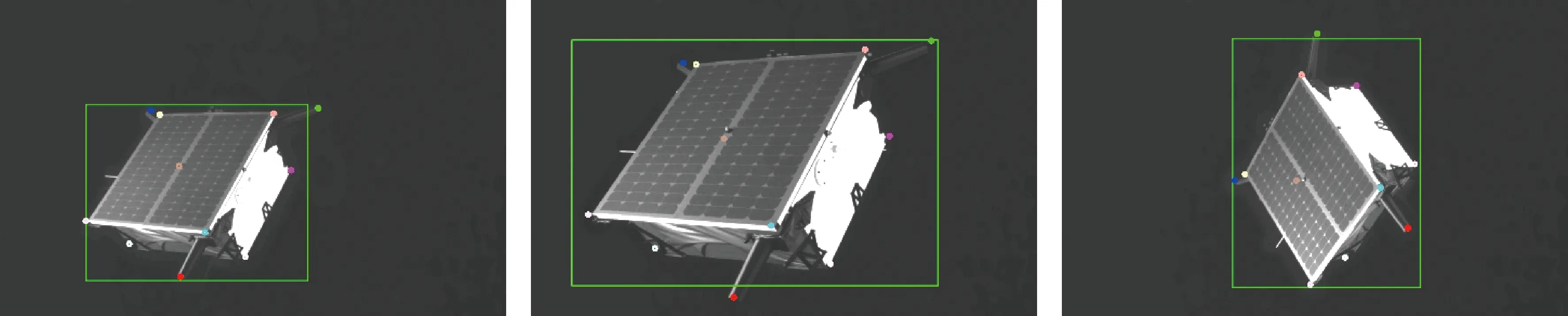
图13 在真实测试数据集上的部分图像二维目标检测与关键点重投影Fig.13 Results of 2D object detection and key points re-projection of part of real test images
KPEC比赛中有48支队伍提交了有效结果,表7选择前5名的模型及基准模型与本文方法作比较,本文方法在仿真与真实测试集上均得到第3名的成绩。除本文方法外,其他方法均使用训练集中的5张真实图像参加训练,提高在真实测试集上的表现。结合表6中的实验结果分析,在仿真测试集上的单模型实验结果略高于表3中的6次实验均值,但仍然在3标准以内,说明模型在仿真测试集上具有良好的泛化表现;在真实测试集上的得分高于表6中6次实验的均值,其原因为仿真与真实测试图像在光照与信噪比等方面有较大差异,导致模型泛化较差。

表7 各种模型在测试数据集上的得分Table 7 Scores of various models on test data sets
重点分析与本文方法类似的UniAdelaide和SLAB Baseline,两者均使用关键点表示刚体目标。UniAdelaide使用11个关键点表示卫星目标,用热力图表示关键点真值,使用了HRNet输出了高分辨率热力图,其尺寸为768×768,使用非极大值抑制(Non-Maximum Suppression, NMS)从热力图中提取关键点,并使用多个模型进行集成取得更好效果;SLAB Baseline采用类似于UniAdelaide类似的方法,以1×1×22的向量表示11个关键点。本文方法在仿真与真实测试集上的得分均优于SLAB Baseline,但在仿真测试集上低于UniAdelaide。可能原因是特征图分辨率因素,UniAdelaide使用的特征图为768×768,而本文方法使用的特征图仅28×28,约为前者的1/27。使用分辨率较高的特征图不仅会降低模型推理速度,也给后处理操作带来较高计算量,严重影响模型实时性。此外,在真实测试数据集上,本文方法取得优于UniAdelaide的表现,说明本文方法在不同数据域间具有更好的泛化优势。
3.5 模型计算耗时
本节针对算法实时性进行考察。测试平台硬件为:NVIDIA RTX2080Ti显卡,Intel i7-7700k CPU和16 GB RAM,软件平台为Python、Pytorch。模型参数为:编、解码器层数为3,查询向量个数为30,图像缩放尺寸为224,主干网络为ResNet50s8,批大小为1。模型推理各个部分耗时如表8所示,可见本文方法基本达到5帧/s。本文算法在目标检测之后需要将原图像进行裁剪缩放,依次经过图像预处理和关键点回归模型得到预测结果,其中,最为耗时的部分为关键点回归部分。未来工作可以考虑优化主干网络,减少编、解码器中的计算量以提高模型实时性。
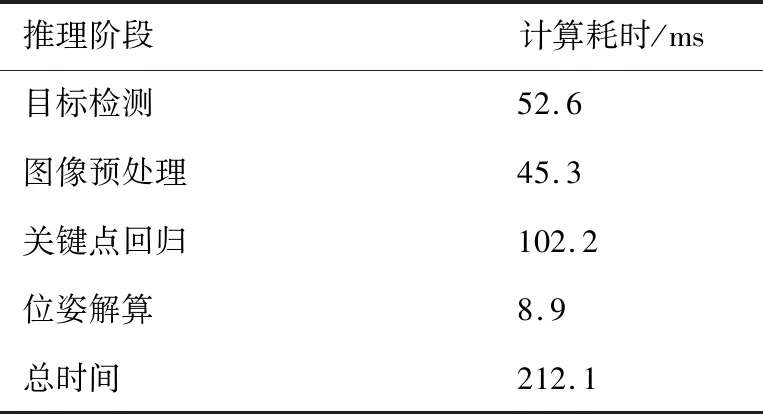
表8 模型推理过程中各部分耗时Table 8 Time consumption of every stage during model inference
3.6 特征可视化
如图14所示,为更好地理解模型的工作原理,将最后一个解码器中的交叉注意力权重,即查询向量与来自编码器的的相似性,进行可视化。其中图14(a)为模型的预测结果,模型正确地预测了11个关键点的位置;图14(b)~图14(l) 依次为第0~10个关键点对应的查询向量与可视化结果;图14(m)为图14(a)中颜色对应的关键点标签序号。可见,交叉注意力权重较大的地方,对应着关键点在图像中位置。交叉注意力权重更加类似于关键点热力图表示中的热力图,但构建热力图真值需要额外超参数,且从热力图中推理关键点位置需NMS或加权等操作。与之相比,本文的端到端关键点回归模型无需额外参数,模型更加简洁直接。

图14 模型特征可视化Fig.14 Feature visualization
4 结 论
围绕卫星目标单目位姿估计问题,针对已有基于卷积神经网络方法存在归纳偏置、绝对距离描述不直接、长距离建模能力不足等问题,本文创新地将Transformer模型应用到刚体目标位姿估计任务中。首先,提出一种基于关键点集合的表示方法,集合中的每个元素由坐标项与分类项组成;其次,构建了基于该表示形式的损失函数;借鉴自然语言处理中的Transformer模型,设计了一种端到端的关键点回归网络模型,增强关键点间的上下文建模。本文在公开发布的SPEED数据集上对所提方法进行测试,实验结果表明本文方法达到了与当前最优性能相当的性能表现,在迁移泛化性能方面优于已有同类型方法。特征可视化实验表明解码器的交叉注意力权重具有关键点热力图表示的特点,说明本文端到端关键点回归模型具有隐式的热力图学习能力。
在进一步的工作中,可以考察具有线性计算和空间复杂度的注意力机制模型,同时也可以将本文关于刚体目标的表示形式扩展到多个目标和刚体目标的六自由度位姿跟踪。
猜你喜欢
电子乐园·下旬刊(2022年5期)2022-05-13
现代信息科技(2019年18期)2019-09-10
初中生世界·九年级(2018年12期)2018-12-22
广东教育·高中(2017年10期)2017-11-07
中学课程辅导·教学研究(2017年18期)2017-09-13
科技创新与应用(2017年26期)2017-09-12
中国信息技术教育(2016年13期)2016-09-10
电脑爱好者(2015年24期)2015-09-10
新高考·高一物理(2015年5期)2015-08-18
读者(2015年9期)2015-05-04
