
面向云计算应用的用电负荷数据差分隐私保护方法
2022-07-20 01:44沈志恒孙飞飞李知艺
电力自动化设备 2022年7期
于 群,沈志恒,孙飞飞,李知艺
(1. 浙江大学电气工程学院,浙江杭州 310027;2. 国网浙江省电力公司经济技术研究院,浙江杭州 310016)
0 引言
在新型电力系统的建设过程中,海量物联网设备的广泛部署产生了大量有价值的数据信息,基于机器学习的大数据分析方法在电网规划运行中的应用越来越普遍,在能源预测、稳定控制、故障诊断、市场运营等方面得到广泛应用[1]。与此同时,云计算作为新一代信息技术,将数据中心软硬件资源整合为虚拟计算资源。随着“东数西算”工程的全面启动,计算资源成为一种可灵活调用的基础公共资源[2]。在此背景下,用户或配电网运营商可以从云平台购买弹性计算资源,利用云计算服务低成本、高效率地完成各项大数据分析业务[3]。
机器学习即服务MLaaS(Machine Learning as a Service)是云计算的一种具体应用模式,能为数据持有者提供基于机器学习的数据处理、模型训练、预测服务和部署等自动化解决方案,吸引机器学习实践者在云平台部署应用程序,而无需建立自身的大规模基础设施和计算资源[4]。在典型的基于云平台的机器学习体系结构中,云平台提供机器学习模型及接口,终端用户将训练数据集上传至云平台,云平台将机器学习的运行结果返回给终端用户。
虽然MLaaS技术可以提升用户的效率和经济效益,但是会对用户数据隐私造成潜在的威胁。用户用电数据中暗含了大量的敏感用户信息,通过非侵入式电力负荷监测NILM(Non-Intrusive Load Monitoring)[5-6]等数据挖掘技术,可以推断用户用电设备的运行状态,进而获得用户的行为信息,包括普通用户的生活习惯、人口数量、经济状况以及高敏感度用户(如军工企业或重要科研单位)的装备产量、生产工艺、科研进展等。当用户将用电数据作为训练数据集上传云端时,一旦云平台被黑客攻破,将造成用户敏感信息的泄露。在人工智能时代,个人隐私保护愈发受到国内外的重视和关注。《中华人民共和国网络安全法》、欧盟《通用数据保护条例》等国内外法律法规的施行,对企业处理用户数据的行为提出了明确的要求。如何保护MLaaS 技术中的数据隐私,保证训练数据中的个人敏感信息不会被未授权人员直接或间接获取,成为制约云计算广泛应用的重要因素。
为了避免用户真实数据被攻击者获取,在用户上传训练数据集至云平台之前,可先对数据进行脱敏处理,抹去用户的敏感信息并确保数据的可用性。此类在上传数据之前即对数据进行保护的方法,能从源头上增强隐私保护的可靠性,进而大幅降低敏感信息的泄露风险。目前,基于差分隐私DP(Differential Privacy)[7]的本地化隐私保护方法在电力系统中应用较多,通常是对多用户的聚合用电数据和区域总体用电统计信息进行扰动[8]。然而,这些方法大多直接向原数据集中添加噪声,使数据的可用性不可避免地受到损失。为了实现数据隐私性和可用性之间的平衡,有学者提出了一种基于生成模型的隐私保护方法[9],用合成数据替代真实数据用于机器学习。生成对抗网络GAN(Generative Adversarial Network)[10-11]能够从少量训练数据中学习到真实的数据分布,生成难辨真伪的高质量合成样本,在电力系统中被广泛用于海量新能源场景生成[12]、缺失数据修复[13]、光伏功率短期预测[14]等研究领域。然而,多项研究证实了生成对抗网络易被攻击,攻击者可以从其生成的合成数据中推理重建训练样本[15],从而使合成数据失去隐私保护的作用。因此,如何在保证合成数据可用性的前提下保护真实数据的敏感信息,是亟待解决的问题。
本文针对云平台MLaaS中可能产生的敏感数据泄露问题,在差分隐私保护框架下提出了一种新的基于时序生成对抗网络的用电负荷数据脱敏方法,可以实现隐私性和可用性之间的平衡,确保即使攻击者窃取了训练数据也无法从中推断真实数据信息。首先,介绍了瑞利差分隐私RDP(Rényi Differential Privacy)的基本概念以及融合RDP 保护的生成对抗网络结构;然后,分三阶段介绍数据脱敏过程,理论推导所提方法如何实现对真实数据的差分隐私,并量化总隐私预算;最后,从定性和定量的角度进行算例分析,对隐私保护处理后数据的隐私性和可用性进行验证。
1 融合差分隐私保护的生成对抗网络结构
差分隐私[7]是一种备受关注的隐私保护技术,于2006年被Dwork首次提出。本文利用具有更严格隐私约束的RDP 跟踪训练过程中花费的隐私预算,进而评估并最小化隐私损失,从而保护训练数据的隐私性。
1.1 RDP的基本概念
差分隐私通过对查询或分析结果添加噪声信号,在保留数据集统计学特征的前提下去除个体特征以保护个体隐私,从而使该数据库的计算处理结果对于某个具体记录(如1 条负荷数据)的变化不敏感。差分隐私应用最广泛的定义为(ε,δ)-差分隐私,具体见附录A定义A1和定义A2。其中,(ε,δ)为差分隐私保护算法的隐私预算参数,表示隐私的置信水平。
将(ε,δ)-差分隐私定义应用于神经网络训练时存在如下问题:由于深度学习训练是不断迭代反向传播的过程,每次迭代时应用(ε,δ)-差分隐私机制都会使隐私预算线性增大,具体见附录A 引理A1。针对这一不足,有学者基于瑞利散度提出了RDP[16],具体见附录A定义A3和定义A4。
(α,ε)-RDP有以下2个重要的基本属性。
1)引理1(RDP组合定理[16]) 若给定一个随机算法A:X→Y1满足(α,ε1)-RDP,且算法B:Y1×X→Y2满足(α,ε2)-RDP,则(M1,M2)满足(α,ε1+ε2)-RDP,其中M1~A(X),M2~B(M1,X)。

上述2 个引理构成了本文所提隐私保护方法的理论基础:引理1 将总隐私成本分解为多个串行模块的隐私成本的组合,为所提模块的隐私预算量化提供了理论依据;引理2 可将RDP 结果转换为传统的(ε,δ)-差分隐私形式。
最常用的RDP 实现方法之一是文献[17]提出的差分隐私随机梯度下降法DPSGD(Differentially Private Stochastic Gradient Descent)。该方法通过向神经网络的反向传播梯度中加入满足高斯分布的噪声实现差分隐私,其主要步骤为:①裁剪单条数据的梯度范数以限制算法对单条数据的敏感度;②对批次数据的反向传播梯度中添加满足高斯分布的噪声;③执行梯度下降优化步骤以更新网络参数。DPSGD 基于Moments Accountant 组合定理,可在相同的隐私预算下达到更好的模型训练效果。
引理3(Moments Accountant 组合定理[17]) 设DPSGD 的随机选择概率为Q,训练次数为T,Mi为标准差为σ的高斯机制,那么对于存在常数c1和c2使得∀ε<c1Q2T、∀δ>0的情况,若高斯机制Mi的标准差σ满足式(1),则(M1,M2,…,MT)满足(ε,δ)-差分隐私。
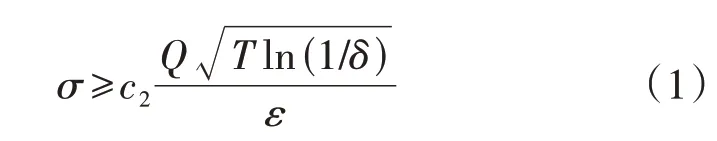
1.2 RDP保护下的时序生成对抗网络结构
基于数据合成的用户用电负荷数据脱敏的研究主要存在以下2个挑战。
1)数据隐私保护:大多数已有的负荷数据合成方法都没有在保护数据隐私的前提下训练模型,不具备数据脱敏能力。
2)时间特征保留:用户用电与温湿度、光照等随时间动态变化的因素有关,同时也与用户收入、家庭住址、节假日等静态影响因素有关。已有的生成对抗网络方法还不能很好地保留用电负荷数据特有的时间相关性和静态特征。
鉴于此,本文提出了RDP 保护下的时序生成对抗网络模型,如图1 所示。具体而言,RDP 保护下的时序生成对抗网络由编码器、解码器、生成器和判别器组成:①对于生成对抗网络的生成器和判别器,采用能够有效捕捉时间步之间关系的循环神经网络RNN(Recurrent Neural Network),挖掘用电负荷数据的动态时间特性;②将自编码器(autoencoder)与生成对抗网络相结合,利用自编码器对用电负荷数据的静态特征进行挖掘;③引入RDP 机制,保护真实数据的敏感信息。
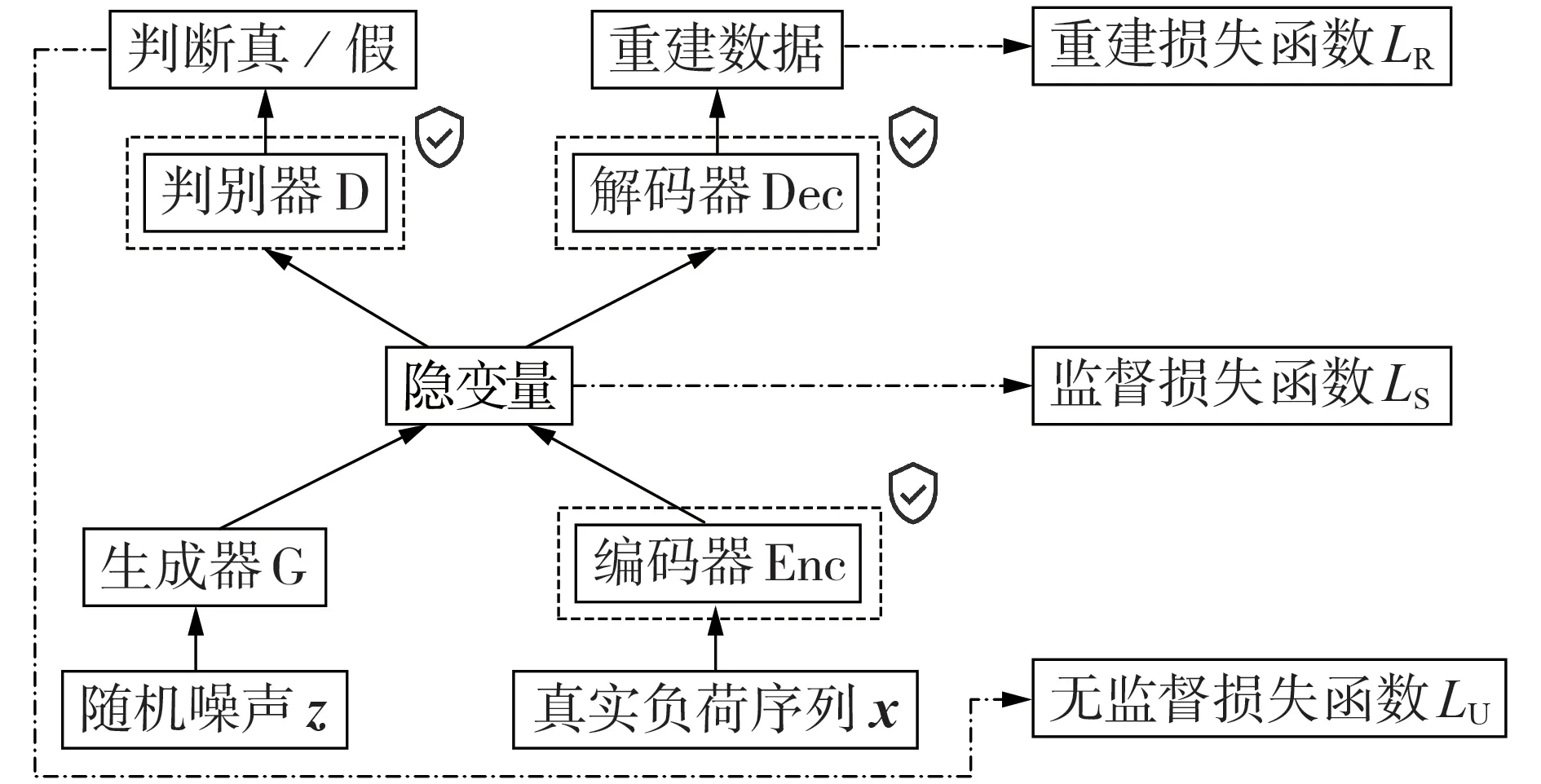
图1 RDP保护下的时序生成对抗网络模型Fig.1 Time-series GAN model with RDP protection
自编码模块(编码器、解码器)提供负荷数据与隐变量空间(latent space)的可逆映射,从而降低对抗性学习空间的高维性,允许对抗模块(生成器、判别器)通过低维特征表示学习负荷数据的潜在影响因素。这利用了这样一个事实:复杂系统的时间特性往往也是由更少和更低维的因素驱动的。同时,引入自编码架构,有助于挖掘用户用电负荷的静态特征。
将自编码架构与对抗网络相结合,实质上是在原始生成对抗网络的无监督范式中引入训练数据特征信息进行监督训练,与原始对抗网络结构相比,利用了训练数据中更多的信息。自编码模块提供负荷数据影响因素编码的隐变量空间,对抗模块在该空间内运行,真实负荷数据与合成负荷数据的潜在影响因素通过监督损失函数进行同步,使生成器同时学习负荷数据的动态时间特性和静态特征。
上述模块设计主要关注合成负荷数据的可用性。为了实现可用性与隐私性之间的平衡,且由于编码器、解码器和判别器在训练过程中与真实用电数据有直接接触,故基于DPSGD 对这3 个模块添加差分隐私保护机制,实现模块参数对输入数据的差分隐私保护。生成器则是通过与编码器、解码器和判别器之间的交互进行学习训练,根据差分隐私的后处理免疫性[18],生成器参数及其合成数据也获得同样的差分隐私保护属性。将满足差分隐私保护的合成负荷数据替代真实负荷数据用于云计算,即使合成负荷数据被攻击者非法窃取,攻击者也无法通过合成数据分辨真实数据的敏感信息,从而实现对真实数据的脱敏。
定理1 对于任意2 个相邻数据集X和X′,设从负荷数据集X到生成器参数Φ的映射A:X→Φ满足(ε,δ)-差分隐私,给定生成器参数Φ到生成器输出Y的随机映射f:Φ→Y,则f◦A:X→Y满足(ε,δ)-差分隐私性质,其中“◦”为复合函数运算符。具体证明过程见附录B。
2 基于生成对抗网络的用电负荷数据脱敏过程
生成对抗网络往往因其难以训练备受诟病,尤其是在差分隐私保护下对指导生成器训练的其他模块引入了噪声干扰,使生成器的训练愈加困难。在整个网络联合训练之前,先对模块进行分块预训练,可以降低生成器的训练难度,加快模型的收敛速度,提高模型训练的稳定性,在相同的隐私预算下生成更高质量的合成数据。本节介绍所提模型的训练过程,理论推导所提模型如何实现对真实用电负荷数据的差分隐私,并量化总隐私预算。基于生成对抗网络的用电负荷数据脱敏过程如附录C 图C1 所示,主要分为自编码模块预训练、有监督生成器预训练、联合训练3个阶段。
2.1 自编码模块预训练
自编码器是一种神经网络架构,由编码器Enc:Rn→Rd和解码器Dec:Rd→Rn组成,其中n为真实日负荷序列长度,d为隐变量长度。将输入的真实负荷序列x∈Rn映射到隐变量空间L∈Rd进而重构数据x̂∈Rn。在理想的情况下,可以实现对原始输入真实负荷序列的完美重构,即x=x̂。对于连续输入的数据而言,自编码器可使用均方误差MSE(Mean Square Error)作为重建损失函数LR,如式(2)所示。
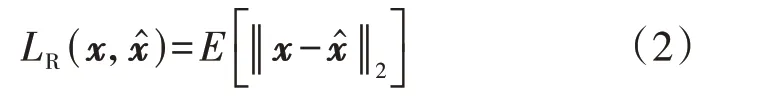
式中:E[·]为随机变量期望。编码器Enc 和解码器Dec 均采用循环神经网络,以捕获负荷序列时间步之间的时间相关性。在自编码模块的训练过程中,需要访问真实负荷数据以捕获负荷的潜在特征,这样的操作可能会触及用户隐私。因此,基于DPSGD对编码器和解码器采取裁剪梯度、添加噪声的措施,可以保证真实数据的差分隐私,具体算法见附录D算法D1。
2.2 有监督生成器预训练
经过自编码模块预训练后,自编码模块可以初步提供负荷数据的隐变量特征空间。然后,利用编码器输出的负荷隐变量对生成器进行监督训练,明确鼓励模型捕获负荷的动/静态时间特征。
以监督的方式训练生成器:编码器Enc 输入真实负荷序列x∈Rn,将其映射到隐变量空间L∈Rd;生成器G 输入随机噪声z∈Rn,同样将其映射到隐变量空间L′∈Rd。有监督训练的损失由这2 个分布之间的差异产生,使生成器学习到负荷潜在特征。应用最大似然作为监督训练的损失函数LS,如式(3)所示。
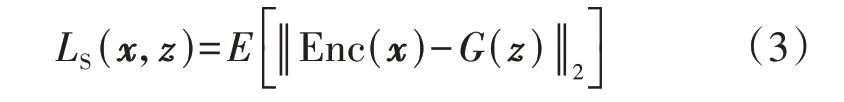
式中:Enc(·)为编码器函数;G(z)为生成器生成的隐变量。
生成器G 采用循环神经网络,以捕获负荷序列时间步之间的相关性。在该阶段的训练中,生成器需要编码器对真实负荷数据的访问进行监督训练,因此同样需要在编码器的训练过程中加入噪声。具体算法见附录D算法D2。
2.3 联合训练
对编码器、解码器、生成器、判别器这4 个模块进行联合训练。所提时序生成对抗网络模型结合了无监督范式的灵活性和监督训练具备的高效指导,通过监督目标和无监督对抗目标共同优化的负荷数据隐变量空间,使生成对抗网络在采样过程中遵循真实负荷训练数据的动/静态特征软约束。
生成对抗网络能够无监督学习训练数据的特征,拟合真实数据的分布,生成高质量的合成数据。生成对抗网络的学习过程是基于一个生成器G 和一个判别器D在如下零和极小极大(即对抗性)博弈中进行的:
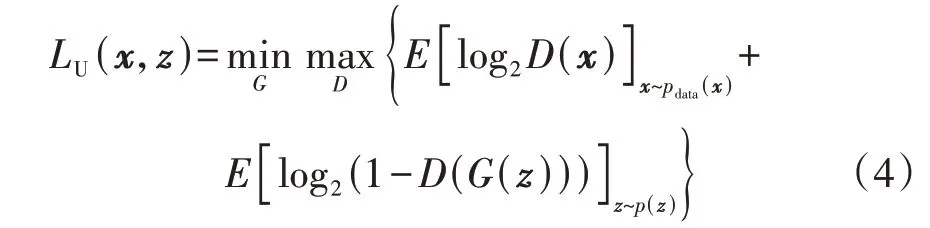
式中:LU为无监督损失函数;pdata(x)为真实负荷序列x的分布;p(z)为随机噪声z的先验分布;D(·)为输出区间为[0,1]的判别器函数,采用循环神经网络。生成对抗网络的训练过程就是生成器和判别器不断博弈的过程,最终使生成器生成的样本无限接近真实数据样本,模型收敛则训练结束,达到纳什平衡。
在联合训练中:首先,作为样本空间和隐变量空间之间的可逆映射,编码器和解码器应该能够实现负荷数据的准确重建,因此第1 个损失函数为重建损失函数LR,见式(2);然后,生成器和判别器之间存在无监督博弈,判别器致力于提高对真/假输入数据的判别精度,生成器希望能够生成使判别器误认为是真实数据的合成数据,因此第2 个损失函数为无监督损失函数LU,见式(4);最后,为了使生成器学习到自编码模块形成的负荷特征隐变量空间,对生成器和编码器之间施加式(3)所示监督损失函数LS,使生成器学习到真实数据的动/静态特征。在训练过程中,对编码器、解码器和判别器施加差分隐私随机梯度下降机制,使生成器在学习到用电负荷数据特征的同时,避免泄露真实信息。因此,自编码模块的损失函数Lae、生成器的损失函数Lg、判别器的损失函数Ld分别为:

式中:λ1、λ2为比例系数。联合训练的具体算法见附录D算法D3。
2.4 总隐私预算
如RDP 组合定理(引理1)所述,RDP 的可组合性允许对总隐私预算的计算执行累加过程。在定理1的基础上可以得到以下推论。
推论1 在联合训练阶段,设每一个训练步中自编码模块和判别器的隐私预算分别为ε1、ε2,则对于任意给定的α,该训练步的总隐私预算εstep=ε1+ε2。
推论2 在任一训练阶段(自编码模块预训练阶段、有监督生成器预训练阶段、联合训练阶段),设每一个训练步的隐私预算为εstep,该阶段共训练N次,则对于任意给定的α,该阶段的总隐私预算εtotal=Nεstep。
推论3 对于任意给定的α,设自编码模块预训练阶段、有监督生成器预训练阶段、联合训练阶段的总隐私预算分别为εae、εg、εgan,则整个训练过程的总隐私预算ε=εae+εg+εgan。
在2.1—2.3 节中,基于DPSGD 在每一个训练步实现对输入数据集的RDP。如RDP 组合定理(引理1)所述,对于任意给定的α,当多个顺序组合的RDP机制作用于同一个数据集X时,总隐私预算存在可累加性。值得注意的是,此处的多个顺序组合的差分隐私机制并不要求是相同的算法,而是强调对同一个数据集的多次访问。它允许多个不同的数据访问方式,共同消耗有限的隐私预算。因此,在联合训练阶段,单个训练步中先后出现2 次用电负荷数据访问(分别作为编码器和判别器的输入),此时单步总隐私预算为2 次数据访问所消耗的隐私预算之和(推论1);任意训练阶段的总隐私预算为各个训练步所消耗的隐私预算之和(推论2);整个训练过程的总隐私预算为3 个阶段所消耗的隐私预算之和(推论3)。
在根据所添加的高斯噪声分布计算总隐私预算ε时,采用数值积分方法[17]可以使计算结果更加准确。为了得到一个更严格的隐私上界,对多个α取值进行计算。取其中最小的ε及其对应的α作为最终的(α,ε)-RDP隐私保护水平。根据引理2,可将其转换为更普遍的(ε,δ)-差分隐私形式。
3 算例分析
基于浙江省某地区的真实用电负荷数据集进行算例验证与分析。该数据集包括2019 年7 月1日至8 月31 日共885 条日负荷数据,采样频率为15 min/次。在配置NVIDIA Quadro RTX 4000 的工作站中采用图形处理器(GPU)计算模式,编程环境为Python 3.6/PyTorch[19]。
本文所提用电负荷数据脱敏方法只在本地(终端)部署和运行,算法本身不存在被攻击的途径,因此只对合成用电负荷数据的质量进行分析评价。考虑到负荷数据大多是无标签的,提出以下3 个评价指标对合成用电负荷数据的质量进行分析:①隐私性,从合成数据中无法推断真实数据信息;②真实性,合成数据应当与真实数据具有相同的分布;③可用性,当应用于同一目的(如预测、分类等)时,合成数据应当与真实数据具有相同的效果。三者之间的关系为:合成负荷数据的隐私性要求从合成数据中无法推断出使单条真实负荷数据的敏感信息,且不希望改变负荷数据集的整体分布特性(真实性)和负荷数据自身的特性(可用性)。
3.1 合成负荷数据的隐私性验证
合成负荷数据的隐私性要求即使攻击者获得了合成数据,也无法从中获得真实数据信息。采取基于相似度的指标来衡量攻击者从合成数据中识别得到个人真实数据信息的可能性。
对合成负荷数据集随机采样885 条数据,计算每条合成数据与原始数据中最接近的记录之间的欧氏距离do,如式(8)所示。
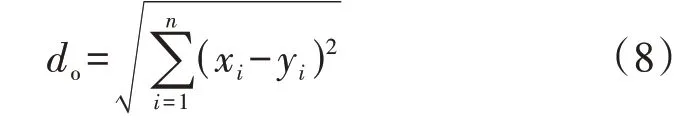
式中:xi、yi分别为任意1 条真实负荷数据和合成负荷数据中采样点i的量测值。当do小于某一相似度阈值时,可以认为合成数据与真实数据相匹配;当do=0时,表明合成数据与某条真实数据相吻合,即泄露了真实信息。将可以被合成数据匹配到的真实数据占全部真实数据的比例定义为匹配率。
不同相似度阈值下合成数据与真实数据的匹配率如图2 所示。以真实负荷数据间的最小欧氏距离作为参考,由于各条负荷数据与其他负荷数据间的最小欧氏距离的平均值为0.5,故在小于0.5 的范围内,取0.30、0.35、0.40 作为相似度阈值。由图2 可知:当相似度阈值为0.40 时,随着ε增大,匹配率随之增大,最终稳定在22%左右,即大约有22%的真实数据与合成数据之间的最小欧氏距离小于0.40,有一定的可能被合成数据泄露部分信息;当相似度阈值为0.35 时,仅有极少量的真实数据可以与合成数据相匹配;而当相似度阈值为0.30时,没有真实数据可以与合成数据相匹配,即在任意的总隐私预算下,合成数据与真实数据之间的最小欧氏距离均没有小于0.30 的情况,说明本文所提方法合成的负荷数据具有较好的隐私性。
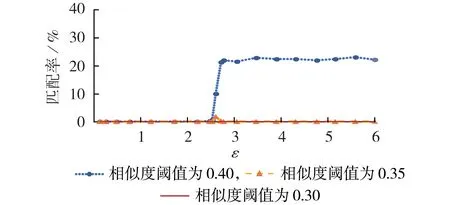
图2 不同相似度阈值下的匹配率Fig.2 Matching rate under different similarity thresholds
3.2 合成负荷数据的真实性验证
本节从定性和定量2 个角度比较合成负荷数据与真实负荷数据的分布。
1)分布可视化。对合成数据集随机采样885 条数据,利用t 分布随机邻接嵌入(t-SNE)[20]算法和主成分分析(PCA)[21]算法对合成样本与原始样本在二维空间中的分布进行可视化,从而对合成负荷数据的真实性进行定性评估。
当总隐私预算ε=5时,PCA 算法和t-SNE 算法的降维可视化结果如图3所示,当总隐私预算ε分别为1 和无穷大(即不设隐私保护机制)时的可视化结果对比如附录E 图E1 所示。由图可以看出,随着总隐私预算的增大,合成负荷数据分布逐渐趋近真实负荷数据分布,在较小的总隐私预算(ε=5)下合成数据已经具有与真实数据相似的分布,且在不设置隐私保护机制(ε为无穷大)时合成负荷数据分布与真实负荷数据分布基本吻合,表明所提方法有效地捕捉了负荷特征和时间相关性。
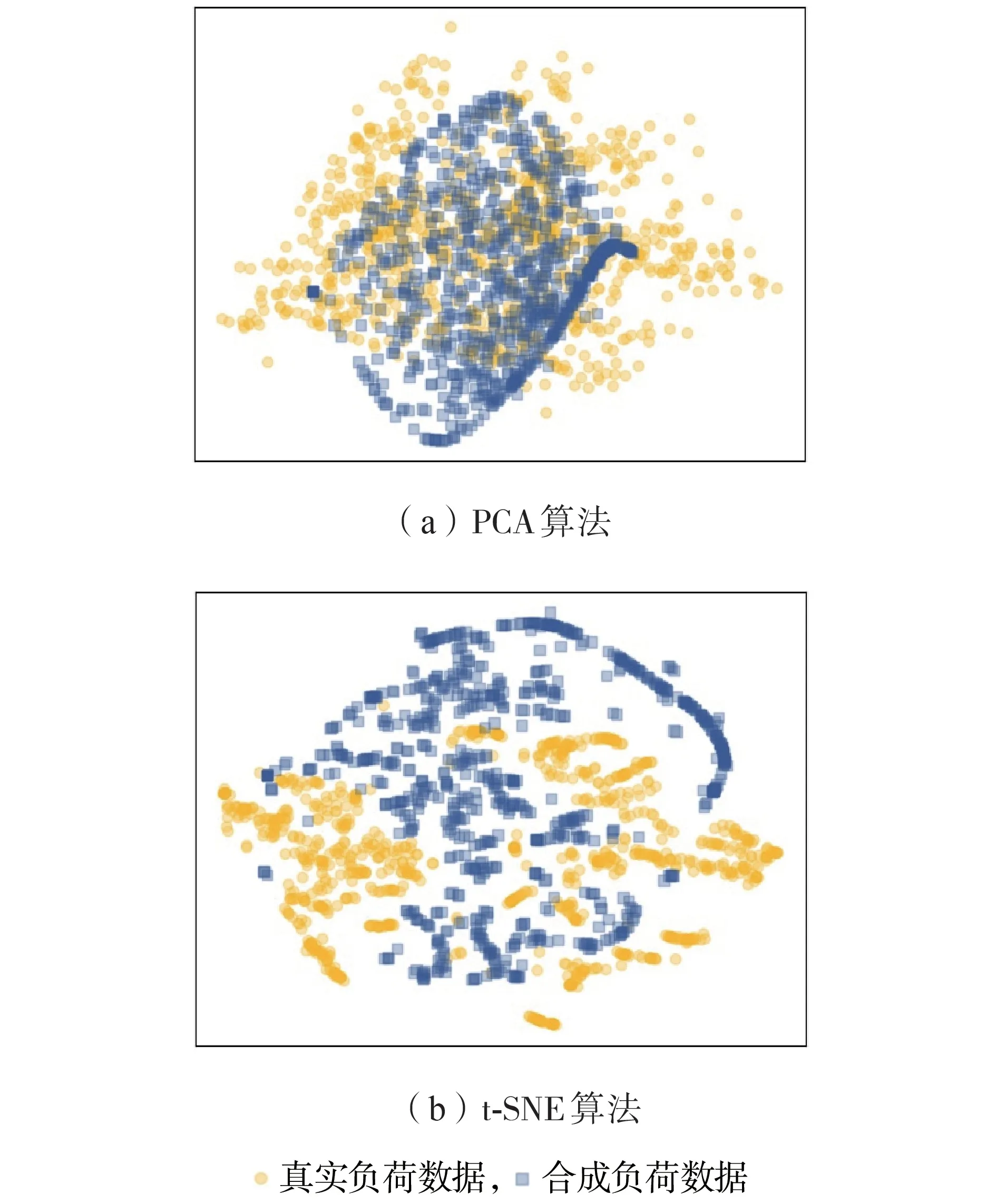
图3 ε=5时PCA算法和t-SNE算法的降维可视化结果Fig.3 Visualized results of dimension reduction for PCA algorithm and t-SNE algorithm when ε=5
2)最大均值差异MMD(Maximum Mean Discrepancy)。最大均值差异是一种用于度量不同域数据集之间分布差异的指标,可以用来表示模型捕获真实数据分布的程度,其定义如下:

最大均值差异与总隐私预算之间的关系曲线见图4。由图可知,在差分隐私保护下,当隐私预算较小时,随着ε增大,合成数据与真实数据之间的分布差异逐渐减小;当隐私预算增大到一定的阈值后,二者之间的最大均值差异逐渐收敛到一个较小的定值,并逐渐趋近于无隐私保护时的数值。图4 验证了所提方法对真实负荷分布的捕获能力,合成负荷数据的分布与真实数据分布之间差别较小,从定量角度验证了合成负荷数据的真实性。

图4 最大均值差异与总隐私预算之间的关系曲线Fig.4 Relationship curves between MMD and ε
3.3 合成负荷数据的可用性验证
设定如下MLaaS 应用场景:用户将合成负荷数据作为训练集上传至云平台,利用云平台提供的预测模型进行负荷预测。设云平台采用目前在时间序列预测领域得到最广泛应用的长短期记忆LSTM(Long-Short Term Memory)神经网络[22]作为负荷预测模型。合成负荷数据的可用性意味着合成数据应当与真实数据具有相同的预测效果。
引入3 组不同的训练集、测试集进行实验:①实验1,基于真实数据集训练预测模型,基于真实测试集测试模型的性能;②实验2,对合成训练集进行训练,对真实测试集进行测试;③实验3,对合成训练集进行训练,对合成测试集进行测试。其中,训练集和测试集在真实数据集和合成数据集中都是不相交的。一方面,如果基于合成负荷数据训练预测模型,应用于真实数据时有较高的预测性能(实验2),则合成负荷数据很好地捕捉了真实负荷数据的时序特征。同时,这也意味着利用经过隐私保护处理的数据代替用户敏感数据用于模型训练是可行的。另一方面,如果基于合成数据对负荷预测模型进行训练和测试(实验3)时的性能与基于真实数据进行训练和测试(实验1)时的性能相似,则允许研究人员将大量的实验部署在基于合成数据进行算法调试,只需要对真实敏感数据进行少量的测试,从而降低隐私保护成本。
采用平均绝对误差MAE(Mean Absolute Error)计算预测误差,作为合成负荷数据可用性的定量评估。3 组实验的负荷预测平均绝对误差(标幺值)如图5和表1所示。由结果可知,当将基于合成负荷数据训练的预测模型应用于真实数据(实验2)时,其预测误差随着ε的增大而减小,当ε超过一定的阈值时,其预测误差近似等于基于真实负荷数据训练的预测模型(实验1)的结果,甚至有偏小情况出现。这说明本文所提方法很好地学习到了负荷数据的时序特征,即使没有学习到真实负荷数据中较为敏感的部分信息,也可以将预测误差控制在较小的范围内。相较于基于真实数据训练和测试负荷预测模型(实验1)的性能,基于合成数据训练和测试负荷预测模型(实验3)时,当ε较小时,预测误差也较小,表明此时的合成数据质量较低,时序特性较差;随着ε增大,预测误差逐渐趋近于实验1 的预测误差,表明此时基于合成数据进行预测已经具有与真实数据相似的性能。上述3 组实验结果通过定量的方式验证了合成负荷数据的可用性。
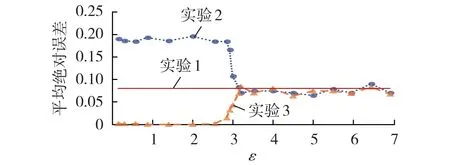
图5 负荷预测平均绝对误差与总隐私预算的关系曲线Fig.5 Relationship curves between MAE of load prediction and ε
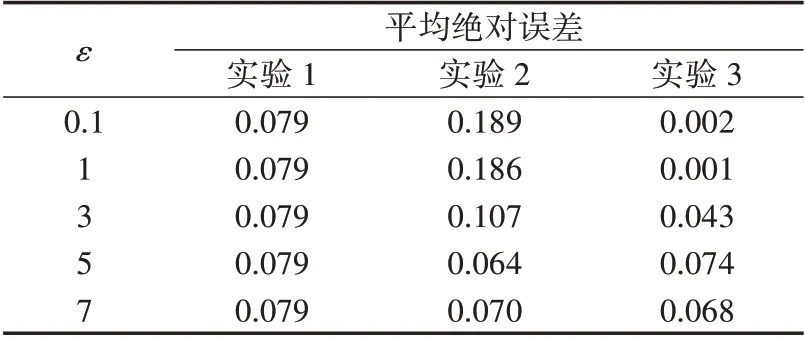
表1 负荷预测平均绝对误差Table 1 MAE of load prediction
综合3 组实验的结果可知,负荷数据的隐私性与其真实性、可用性之间存在负相关关系,增大隐私保护力度势必会导致捕获到的负荷特征信息减少。因此在实际应用中,需要结合具体的需求选取合适的隐私预算:若实际应用场景中对算法精度、数据可用性要求较高,则可选择较大的隐私保护预算;若实际应用场景对数据隐私要求较高而可以允许牺牲一部分算法精度和数据可用性,则应选择较小的隐私预算。
4 结论
本文针对云平台MLaaS中可能产生的敏感数据泄露问题,通过构建融合差分隐私机制、自编码器、生成对抗网络的用电负荷数据生成模型,以采用满足差分隐私的合成数据替代真实数据实现数据脱敏。通过算例进行实验分析,可得如下结论:
1)所提基于时序生成对抗网络的用电负荷数据生成模型,实现了对用户用电隐私数据的差分隐私保护及隐私预算的量化;
2)在一定的隐私预算下,本文所提方法能够生成分布与真实负荷数据分布相近、可用性与真实负荷数据相似的合成负荷数据,在有效保护用户用电隐私的同时,保证了合成数据的可用性。
训练数据隐私泄露已成为阻碍云计算进一步发展的重要原因之一。如何在保证合成数据可用性的前提下尽可能减少真实数据的隐私保护开销,是需要进一步解决的问题。随着新型电力系统的发展,电网运营商对云端计算资源的需求将进一步加大,解决云计算模式下的隐私保护问题刻不容缓,本文所提方法和思路具有较好的应用前景。
附录见本刊网络版(http://www.epae.cn)。
猜你喜欢
数学杂志(2022年5期)2022-12-02
网络安全与数据管理(2022年1期)2022-08-29
湘潭大学自然科学学报(2022年2期)2022-07-28
仪器仪表用户(2022年6期)2022-06-06
新世纪智能(数学备考)(2021年5期)2021-07-28
海洋信息技术与应用(2021年1期)2021-06-11
科学技术创新(2021年5期)2021-03-17
中国科技纵横(2020年24期)2020-11-28
——编码器
演艺科技(2020年7期)2020-08-13
探测与控制学报(2015年4期)2015-12-15
