
含缺失标签的大规模多标签分类算法
2022-09-06 11:08刘依璐曹付元
计算机工程与应用 2022年17期
刘依璐,曹付元,2
1.山西大学 计算机与信息技术学院,太原 030006
2.山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006
随着数据量的爆炸式增长,大规模多标签分类算法比传统的多标签分类算法更符合实际的分类要求。大规模多标签分类的目标是训练一个分类器,该分类器可以从大规模的标签集合中挑选出与实例最相关的标签子集。目前已被广泛用于图像及视频标注[1-2]、文本分类[3-4]、基因功能预测[5]、临床医学[6]等实际任务中。
对于大部分现有的大规模多标签分类算法[7-10],都要求训练数据中所有的标签信息是完整的。然而在实际应用中,用户提供的标记可能是不完整的。一方面是因为标签数量多,逐个标注的过程费时费力,因此大部分人工标注者会选择只标注相对重要的标签,而丢弃不太重要的标签。另一方面原因是标注者的知识范围有限。例如,在维基百科的在线收藏中给文章标记类别时,人工标注者通常只标注他们知道的类别标签。这就导致了多标签数据集中标签的缺失情况。在这种情况下,直接在含有缺失标签的数据集上训练传统的分类器会给分类效果带来较大的误差。
因此,许多用于解决含缺失标签的大规模多标签分类算法被提出。例如,Tan 等人[11]提出的归纳式解决方法Smile,该方法借助标签在整个原始数据集中的共现概率来获取标签之间的相关性,而后利用它来恢复原始数据集中丢失的信息,然后构建一个线性的分类器,通过一致性和平滑性这两个基本的假设来优化最终的目标函数。为了便于处理大规模数据,该算法还引入了共轭梯度加速算法及基于树的最近邻查找方法进行模型优化。王晶晶等人[12]提出MCWD+传统多标签分类器的方法进行缺失标签的恢复及模型训练,该算法主要通过迭代地更新每个训练实例的权重并且引入一个标签相关性矩阵来恢复训练数据中的缺失标签信息,最后采用传统分类器进行模型训练。由于该算法采用传统分类器进行训练,因此在处理大规模数据时效率并不高。Akbarnejad等人提出的ESMC算法[13]是一种基于嵌入的方法,为充分考虑标签之间的相关性,采用了非线性嵌入标签向量的方法,并通过学习特征空间与潜在空间之间的映射进行建模。此外,还借助了伪实例参数化稀疏高斯过程的思想,大大减少了模型的训练时间,使其能够处理大规模数据。LSML算法[14]提出一种学习标签特定特征的新方法,用于带有缺失标签的多标签分类。通过学习高阶标签相关性,从原始标签矩阵中增加一个新的补充标签矩阵。然后,学习每个类标签的标签特定数据表示,并在此基础上结合学习到的高阶标签相关性来构建多标签分类器。MLLCRS-ML 算法[15]提出一种能够处理含缺失标签的分类器,该分类器考虑了特定于标签的特征,同时利用成对的标签相关性来恢复丢失的标签,并使用加速近端梯度法来有效地解决潜在的优化问题。
上述方法可以归类为全局多标签分类方法,因为它们都假设标签之间的关系可以在整个实例集上进行建模,然而在实际任务中,标签之间的相关性只能适用于一部分实例子集,并且很少有相关性是全局适用的。例如,在给杂志中的图片标注标签时,“apple”与“fruit”之间的高相关性就不能同时被美食类杂志和科技类杂志共享,而只能被美食类杂志使用。
与全局标签相关性不同,局部标签相关性是由部分样本计算得出的,利用这种相关性进行训练更加符合实际任务需要。例如:在美食类的杂志中,使用“apple”与“fruit”之间的高相关性;在科技类的杂志中不使用“apple”与“fruit”之间的高相关性,而使用“apple”与“phone”之间的高相关性。为此,本文提出一种基于局部标签相关性的多标签分类方法LMC(local label correlations-based multi-label classification algorithm),通过使用局部的标签相关性进行缺失标签信息的恢复及低秩分类器的训练。具体来说,该算法首先对特征空间进行聚类分析,将训练集中的所有示例划分到不同的簇中,然后在标签空间中使用共现次数来估计局部标签相关性。最后,利用得到的标签相关性进行缺失标签的恢复,并将该过程与低秩模型的训练过程整合至一个统一的框架中,以提升大规模数据上的模型训练速度。
1 含缺失标签的大规模多标签分类算法
本章讲述提出的LMC算法。第一部分介绍多标签分类算法的问题定义。第二部分详细介绍LMC算法主要处理过程:获取局部标签相关性、缺失标签的恢复及模型训练。第三部分介绍算法的优化。第四部分介绍算法的测试过程。
1.1 问题定义
在传统的多标签分类任务中,X=Rd代表含有d维特征向量的输入空间,Y={1,-1}q代表含有q个可能标签的输出空间,训练集D={(xi,yi)|1 ≤i≤n} ,其中n表示训练样本的个数,xi=(xi1,xi2,…,xid)∈X 表示第i个实例的d维特征向量,yi=(yi1,yi2,…,yiq)∈Y 表示第i个实例相应的q维标签向量,yi中的取值yij=1 时表示第j个标签属于第i个实例,否则表示为yij=-1。多标签分类任务的目标是从已知的训练集D中学习一个分类模型h:X→2Y来准确地预测新实例的标签集合。
让X=(x1;x2;…;xn)∈Rn×d为实例的特征矩阵,Y=(y1;y2;…;yn)∈{1,-1}n×q为实例的标签矩阵,对于传统的多标签分类来说矩阵Y中的数据没有缺失,然而在含有缺失标签的矩阵Y中只有部分相关标签是已知的,只能得到一个不完整的标签矩阵C=(c1;c2;…;cn)∈{1,0,-1}n×q,其中ci=(ci1,ci2,…,ciq),当cij=1 时表示第j个标签属于第i个实例,cij=-1 时表示第j个标签不属于第i个实例,cij=0 则表示第j个标签缺失。此外,本文中采用的标签矩阵C是高维的,即C中的q值较大。
1.2 LMC算法
在含有缺失数据的大规模多标签分类问题中,主要面临两个问题:一方面是较大的数据量[16-20],另一方面是训练数据中存在缺失的标签信息[21-24]。在这种情况下,采用传统的多标签分类器不仅会降低分类器的分类准确度,还会产生较大的时间和存储代价。为了解决上述两个问题,本文提出一种基于局部标签相关性的LMC算法,该算法首先对训练样本的特征域进行聚类分析,将原始数据集分成k个数据簇,使得同一个数据簇中的样本具有相似的标签相关性;然后在每个数据簇中挖掘标签之间的局部相关性,并利用得到的相关性进行缺失标签信息的恢复;最后为每个数据簇训练一个低秩的分类器,并将标签的分类任务与缺失标签的恢复任务进行集成,采用迭代优化的方式得到最终的分类器。在预测阶段,给出一个新样本,利用与样本距离最近的数据簇对应的局部模型进行标签预测。图1 简明扼要地说明了LMC 算法的框架,在下面的章节中将对该算法进行详细阐述。

图1 算法框架Fig.1 Architecture of algorithm
1.2.1 获取局部标签相关性
不同的实例会产生不同的局部标签相关性。因此,本文提出的算法不再从整个数据集中挖掘标签关系,而是在相似的样本中寻找标签之间的相关性,舍弃掉不相似的样本,以减少其对标签关系获取准确度的影响。为了准确地获取标签之间的相关性,LMC 算法采用聚类的方式来挖掘数据之间的局部标签相关性信息。由于标签集合中有信息的缺失,直接对其进行聚类分析会影响相关性获取的准确度。鉴于标签中包含的信息来源于特征域,而且特征域中没有信息的缺失,因此LMC算法选择对特征域进行聚类分析。同时也可以在一定程度上避免因数据缺失产生的异常点及类别不均衡情况。
本文在实验过程中选择k-means 聚类算法来划分训练数据。对样例集合进行聚类后,训练数据被分为k个组{D1,D2,…,Dk},使得具有相似标签相关性的实例分到同一组中。然后在每个数据簇Di中挖掘局部的标签相关性。详细计算过程如下:
以标签l1与l2之间的相关性L(l1,l2)为例:
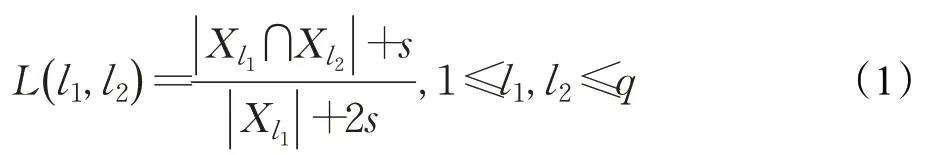
其中,Xl1表示被标签l1标注的实例集合,|Xl1|表示被标签l1标注的实例数目,Xl2、|Xl2|与Xl1、|Xl1|同理。|Xl1∩Xl2|表示同时被标签l1及l2标注的实例数目。s是引入的一个平滑参数,可以在一定程度上避免由于标签不平衡所产生的极端情况。例如,有100 篇文章,其中10 篇本应标注为足球和鞠蹴,而其他文章标记为足球。但此时由于文化差异,这10 篇文章中的鞠蹴标签全部丢失,即同时被标注为足球和蹴鞠的样本个数为0,则在不考虑s计算相关性时,足球和鞠蹴之间的相关性估计将为0,然而这两个标签是存在关联的。因此,通过设置s>0,就可以在一定程度上避免这种情况。
用L(· ,l2)=(L(l1,l2),L(l2,l2),…,L(lq,l2)) 表示所有标签与l2标签之间的相互关系。进一步地,将计算出的L(· ,l2)向量进行归一化处理,使得向量各元素之和为1,此时得到的所有相关性值在[0,1]区间内,因此,可以将归一化之后的L(· ,l2)中的值视为其余标签对某标签的贡献率。同样以标签l1与标签l2的相关性为例,具体的归一化过程如下:

最终,所有的标签相关性构成相关性矩阵L。
1.2.2 缺失标签的恢复
在获取了局部的标签相关性之后,就利用它对缺失标签进行恢复。恢复的基本原则有两点:
(1)在原始数据集中存在的标签在恢复的数据集中仍然存在,因为这部分信息是准确无误的,因此需要保留这部分信息。
(2)在进行不同样本标注时,具有强相关性的标签的取值相近,反之亦然。
因此,LMC中具体的标签恢复过程如下:
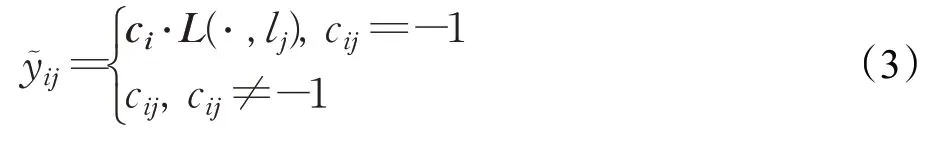
其中,是对第i个实例的第j个标签恢复后的值,ci表示含缺失标签数据集中第i个实例的标签向量,L(·,lj) 表示其余标签与第j个标签之间的相关性向量。采用式(3)可以很好地保证两点基本准则。
最后选择阈值0.5 来确定最终的值,如果的值大于0.5 时,在C中cij的值变为1;否则在C中cij的值变为-1。并将恢复好的标签矩阵记为Y~ ∈{-1,1}n×q,同时将其作为新的标签集。
1.2.3 模型训练
在处理在现有的解决方案中,许多算法都将分类任务与缺失标签的恢复任务分离开来,但是在处理大规模数据时会增加模型的训练时间。因此,LMC算法将这两个任务进行结合,在恢复数据的同时进行多标签分类。
在使用传统的线性分类器f(x;Z)=xZ(Z∈Rd×q)时,模型的训练误差通常表示为:

但直接在大规模数据集中使用传统线性分类器的训练时间会很长。基于以下观察:尽管多标签分类问题中的标签数量可能很大,但通常存在显著的标签相关性,这意味着输出空间是低秩的,LMC算法选择将建模所需的有效参数数量减少到远小于d×q,即通过对矩阵Z的低秩分解限制Z仅学习少量潜在因素来捕捉标签与特征之间的关系。这样不仅能有效控制过拟合,而且还能提高在大规模数据上的计算速度。具体做法如下:
在每个数据簇Di中,先利用标签之间的相关性进行缺失数据的恢复,后将恢复后的标签矩阵投入分类模型中进行训练,再将模型训练的结果作为新的输入重新进行标签恢复和训练。在分类模型中,采用低秩分解技术将矩阵Z分解为两个秩为r(r≪q) 的低秩矩阵W∈Rd×r和H∈Rq×r,使得Z=WHT。因此,模型的目标函数更新如下:
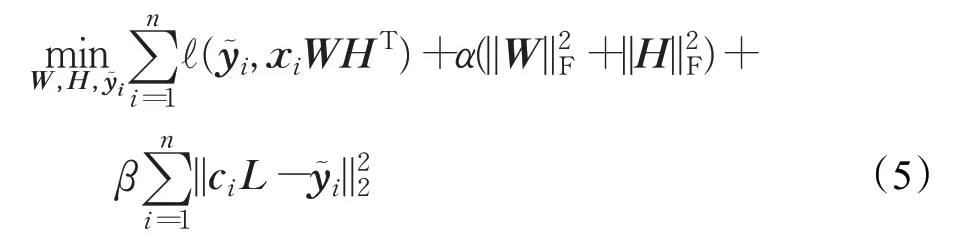
其中,表示第i个实例对应的恢复后的标签向量;α及β为调节因子,α用来进行低秩控制,防止模型的过拟合,β用来约束数据恢复的准确度。
在式(5)中,第一项用来计算模型的训练误差;第二项实现对参数的低秩控制;第三项为标签恢复的误差项,旨在使用标签之间的局部相关性进行缺失数据的恢复,若某标签缺失,且该标签与已存在标签之间的相关性越大,则该标签被恢复为1的概率就越大,反之亦然。
1.3 优化
针对式(5),LMC算法采用迭代最小化的方式进行优化。为了便于运算,首先将式(5)简化为矩阵形式。
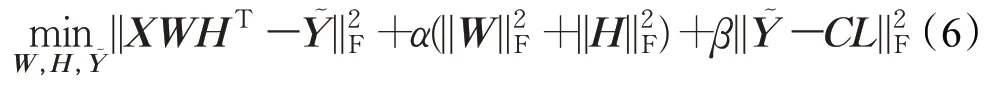
步骤1固定W、Y~ ,求H,则目标函数可以转化为:

接下来对上式进行求导,可得:

其中,I为单位矩阵。
步骤2固定H、,求W,则目标函数可以转化为:

与步骤1方法类似,令该式的导数为0,得到:

但是在计算W时,涉及大量的大规模矩阵相乘,计算速率会大大降低。因此,LMC 算法选择采用其他的方法进行优化。共轭梯度法是非常重要的一种优化算法,该方法所需存储量小,稳定性高,收敛速度快,是求解大型线性及非线性方程组最有用的方法之一。结合上述分析,LMC 算法采用共轭梯度算法对式(10)进一步进行优化。
首先需要对式(10)求解出一阶导数和二阶导数:
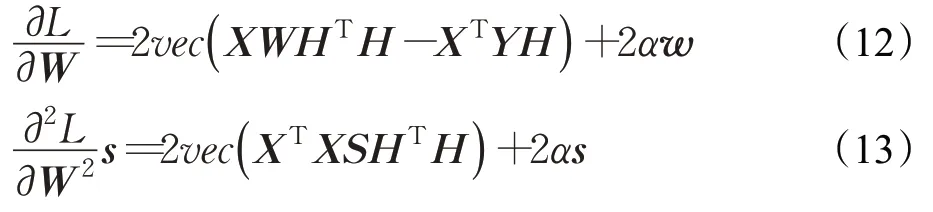
其中,w=vec(W),s=vec(S),vec(*)代表矩阵的向量化操作,S是一个d×q维的任意矩阵。
接下来就可以直接使用共轭梯度法进行问题的求解。具体的执行过程可参考相关文献[13]。
步骤3固定H、W,更新Y~ ,则目标函数可以转化为:

与步骤1方法类似,令该式的导数为0,得到:

然后,对中原本为1和-1的数据进行恢复,以保证原始数据集中的信息不发生丢失。
1.4 模型预测
在优化完成之后就可以得到最优的W和H,记为W*,H*。对于待预测的样本特征向量xtest,首先计算距离其最近的聚类簇,然后利用该聚类簇的局部分类器进行预测,公式如下:

上述利用局部标记相关性的LMC算法的详细步骤如算法1所示。
算法1LMC算法
输入:训练集D=[X,C],测试样本xtest,聚类个数k,平衡因子α、β,最大迭代次数max_iter。
输出:测试样本的预测标签向量ytest。
1.对训练样本的特征域进行k-means 聚类分析,得到k个小聚类簇{D1,D2,…,Dk}
2.fori=1 tokdo
3.将聚类簇Di作为训练样本
4.初始化Y~ =C,随机初始化矩阵W、H,max_iter=100
5.forj=1 tomax_iterdo
6.根据式(9)更新H
7.将式(12)、(13)作为共轭梯度算法的输入更新W
8.根据式(14)更新Y~
9.end for
10.end for
11.计算各聚类簇中心与xtest的距离
12.挑选距离最近的聚类簇对应的分类器,得到W*,H*
13.根据式(16)得到预测的标签向量ytest,并返回
2 实验
这部分主要评估LMC 算法的有效性。将LMC 算法在7 个多标签数据集进行实验,并和现有的5 种相关算法进行比较和分析,从而来验证LMC 算法的可行性和有效性。
2.1 实验设置
2.1.1 数据集
本文将LMC 算法在7 个来自不同领域的数据集上与其他算法进行对比实验。实验中用到的数据集的详细信息如表1所示。
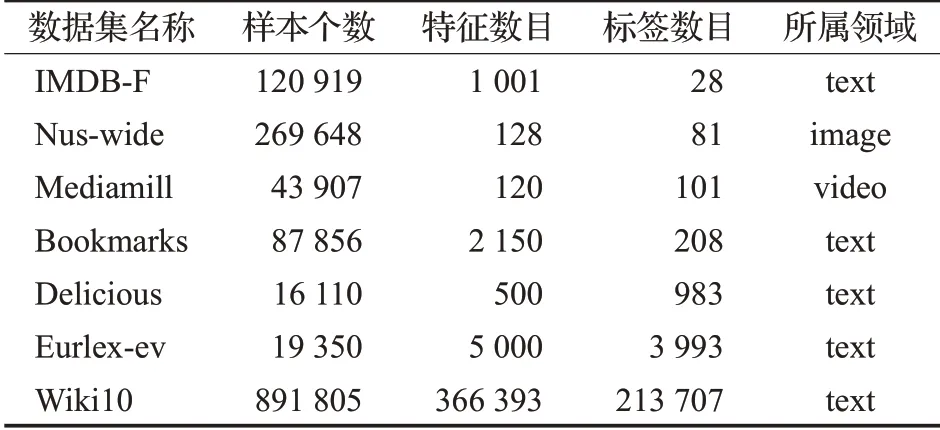
表1 数据集描述(按标签数目升序排列)Table 1 Description of data sets(sorted in ascending order of number of labels)
在实验过程中,对于每一个数据集,将其随机划分为训练集(占70%)和测试集(占30%),此过程反复进行5次,最后将这5次实验结果的均值作为最终的结果。
2.1.2 评价指标
现有评价多标签分类性能的指标主要分为基于实例的评价标准、基于标签的评价标准和基于排序的评价标准,详细描述可参考相关文献[25]。本文从中选择其中5 个常用的评价指标来对比各算法的性能,分别为P@1、P@3、P@5、average-AUC 和coverage。前三种标准是基于实例的评价标准,用来评估在测试集中预测值较高的几个标签的分类性能,coverage则用来评估整体的分类性能,average-AUC 属于基于排序的评价标准,从标签排序的角度来衡量分类性能。对于前4 种评价指标来说,指标的取值越大,则表明算法的性能越好;对最后一个评价指标而言,取值越小则算法的性能越好。
2.1.3 参数设置
本文将提出的LMC 算法与现有的5 种多标签分类算法进行比较,这些算法都可以用来解决含有缺失标签的大规模多标签分类问题。每个算法都根据原论文建议配置了相应的参数。
(1)Smile[11]:该算法利用标签之间的相关性进行缺失标签的估计,并建立线性的分类器进行模型的训练和对未知样本的标签预测。各个参数的具体设置详见文献[11]。
(2)MCWD+MLKNN[12]:该算法将标签恢复方法MCWD与传统多标签分类算法MLKNN进行结合用来进行缺失数据的恢复,且可以扩展至大规模数据集上。其中MLKNN算法中近邻个数的取值设置为10,平滑系数取值设置为1,其余各参数的具体设置详见文献[12]。
(3)ESMC[13]:该算法使用随机方法非线性嵌入标签向量,以解决基于嵌入式的学习方法中尾标签预测不准确的问题。该方法在处理丢失标签及大规模数据集方面具有良好的表现。各个参数的具体设置详见文献[13]。
(4)LSML[14]:该算法提出一种学习标签特定特征的新方法,用于带有缺失标签的多标签分类。通过学习高阶标签相关性,从原始标签矩阵中增加一个新的补充标签矩阵。然后,学习每个类标签的标签特定数据表示,并在此基础上结合学习到的高阶标签相关性来构建多标签分类器。各个参数的具体设置详见文献[14]。
(5)MLLCRS-ML[15]:该算法提出一种能够处理含缺失标签的分类器,该分类器考虑了特定于标签的特征,同时利用成对的标签相关性来恢复丢失的标签,并使用加速近端梯度法来有效地解决潜在的优化问题。各个参数的具体设置详见文献[15]。
(6)LMC:对于本文提出的算法,k-means中聚类个数的取值在[50,150]内进行选择,平衡因子α的取值在[0.5,1.5]范围内进行选择,β取值在[0.5,1.0]之间,低秩参数r的取值在[30,300]内进行选择,迭代参数max_iter的取值设为50。
以上参数均采用五折交叉验证方法选择适用于各数据集的最优值。
2.2 参数影响
本节对LMC 算法中的五个重要参数:k-means 聚类中的类簇个数k,平衡因子α,平衡因子β,低秩约束参数r及最佳迭代次数max_iter展开研究。每次仅改变一个参数的取值,其余参数保持不变。
2.2.1 聚类个数k 的影响
在LMC 算法中,聚类个数k用来确定k-means 聚类的个数,进一步影响标签相关性的获取细致度。本文将k的取值从1 取到250,步长为50,并在LMC 算法上运行了10 次,然后取平均值作为最终结果。在各个数据集上随聚类个数变化时的Precision@1取值变化如图2所示。
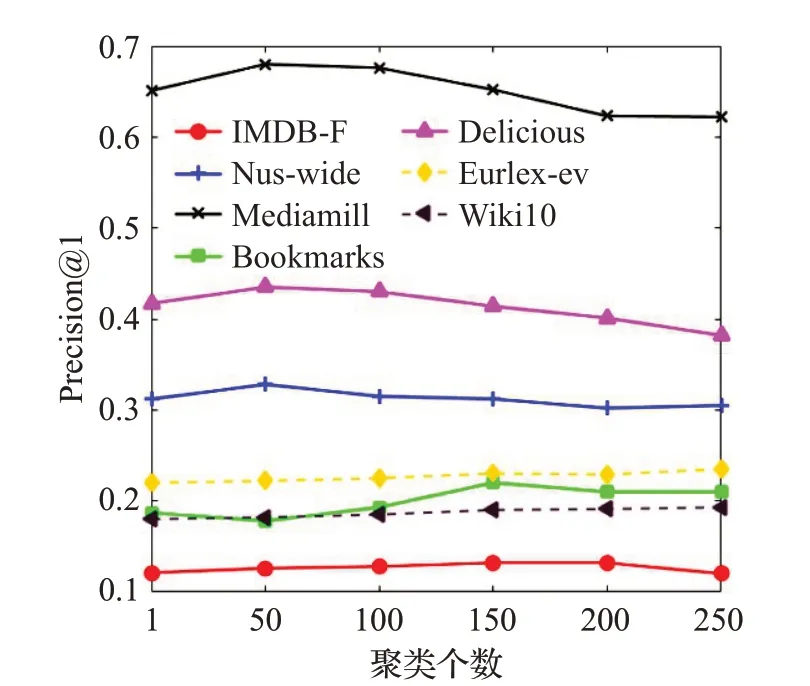
图2 聚类个数的影响Fig.2 Influence of number of clusters
从图2中可以看出当聚类簇个数为1时,Precision@1取值较低,说明此时算法的分类性能并不是最优,因为此时仅仅利用了全局的标签相关性。随着聚类个数的增加,算法的性能有所提升。但是当到达某个最优聚类个数之后算法的性能有所下降,这是因为当聚类个数过多时,每个聚类簇中的样本个数过少,无法准确捕捉标签之间的相关性。而且当聚类个数较多时,LMC 算法训练的分类器个数也较多,训练时间也会明显增加。鉴于图2显示的结果,本文建议聚类个数的设置为50/100/150。在下列实验中,LMC算法在各数据集中的聚类个数取值均以该图为指导进行设置。
2.2.2 平衡因子α 的影响
平衡因子α用来控制模型的低秩性,以避免模型出现过拟合及降低模型的复杂度。本文设置α的取值从0至2.0,步长为0.5,并将10 次实验结果的平均值作为最终结果。图3展示了LMC算法在各个数据集上随平衡因子α变化时的Precision@1取值。
从图3 中可以看出当α取值为0 时,Precision@1 取值较低,因为此时并没有对分类器施加低秩约束,而且模型的复杂度非常高。当α取值增加时,算法的性能有所提升,这是因为模型的复杂度得以降低,过拟合的可能性也得到了减少,最终使得模型的处理效率得到了提升。鉴于图3结果,本文建议α参数取值大于0.5。

图3 平衡因子α 的影响Fig.3 Influence of balance factor α
2.2.3 平衡因子β 的影响
平衡因子β用来约束缺失标签恢复的准确度。该参数选择与参数α同样的取值范围进行实验。给定平衡因子β不同的取值,LMC 算法在各数据集上Precision@1的变化如图4所示。
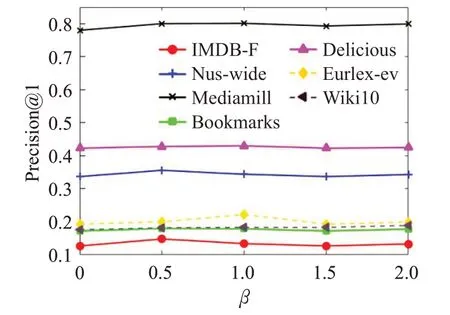
图4 平衡因子β 的影响Fig.4 Influence of balance factor β
从图4可以看出,当β取值为0时,算法并没有进行缺失标签恢复的情况下,而是直接使用含缺失的标签进行训练,因此算法的性能并没有达到最优。随着取值的增大,该算法会更加注重缺失标签的恢复,性能逐步提升。但是β取值过大时,算法会约束恢复后的标签过分接近含缺失标签取值,此时,算法的性能会逐步下降,设置退化为β取值为0的性能。因此,本文建议β参数的取值在[0.5,1.0]之内。
2.2.4 低秩参数r 的影响
参数r用来表示低秩矩阵的维度。该参数的取值范围从标签个数q的1/10 提升至标签个数的取值。同样将10次实验结果的平均值作为最终结果。
图5 展示了算法随着低秩的维度约束r变化时的性能变化情况,横坐标表示低秩约束的维度。在不同的数据集中,数据的冗余度及标签相关的程度不同,因此算法在该变量上的最优取值涉及范围较广。同样,r的取值不能过大也不能过小,过大会破坏标签的低秩约束,而且也会增加模型训练负担,过小则不能准确捕捉到标签之间的相关性。基于图5的实验分析,本文推荐r参数取值在标签个数较少的数据集上在总标签数的1/2~1/4 之间选择,在大规模数据集上则在总标签数的1/8~1/10之间选择。
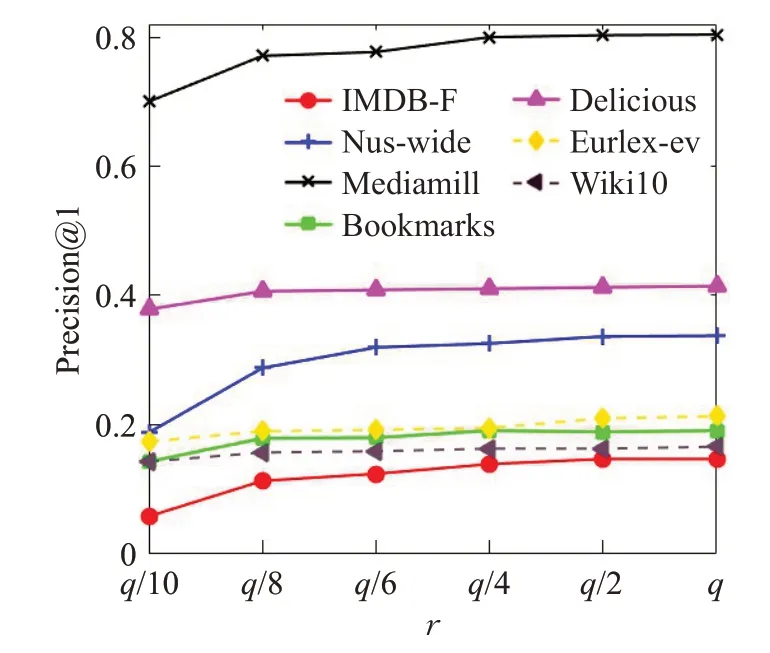
图5 低秩参数r 的影响Fig.5 Influence of low-rank parameter r
2.2.5 迭代次数max_iter 的影响
参数max_iter为模型的训练截止条件。该参数的取值范围从1 逐次增至150。图6 展示了算法增加迭代次数时目标函数的收敛情况,在其他数据集上的实验结果也是类似的。
从图6 可以看出,在迭代次数为50 之前,算法在以上四个数据集均达到收敛,具有较快的收敛速度。基于图6,推荐max_iter取值设为50。

图6 迭代次数max_iter 的影响Fig.6 Influence of number of iterations max_iter
2.3 实验结果
本文仅展示缺失率为10%(缺失的标签个数占总标签个数的10%)时各对比算法在不同数据集上的实验结果,如表2~6 所示。其中最优的实验结果已用粗体标识出来,“—”表示因实验花费时间过长暂未取得实验结果,括号中的数字表示各算法在同一数据集上的结果排名。
从表2~6 中可以看出,在35 组(5 个评价指标×7 个数据集)对比实验结果中,LMC算法共有27次排名第一(含并列),7 次排名第二(含并列),排在第三的共有1次。这说明提出算法在缺失率为10%时分类的准确度上要优于其余五种算法,其他缺失率设置下的分类性能也类似。
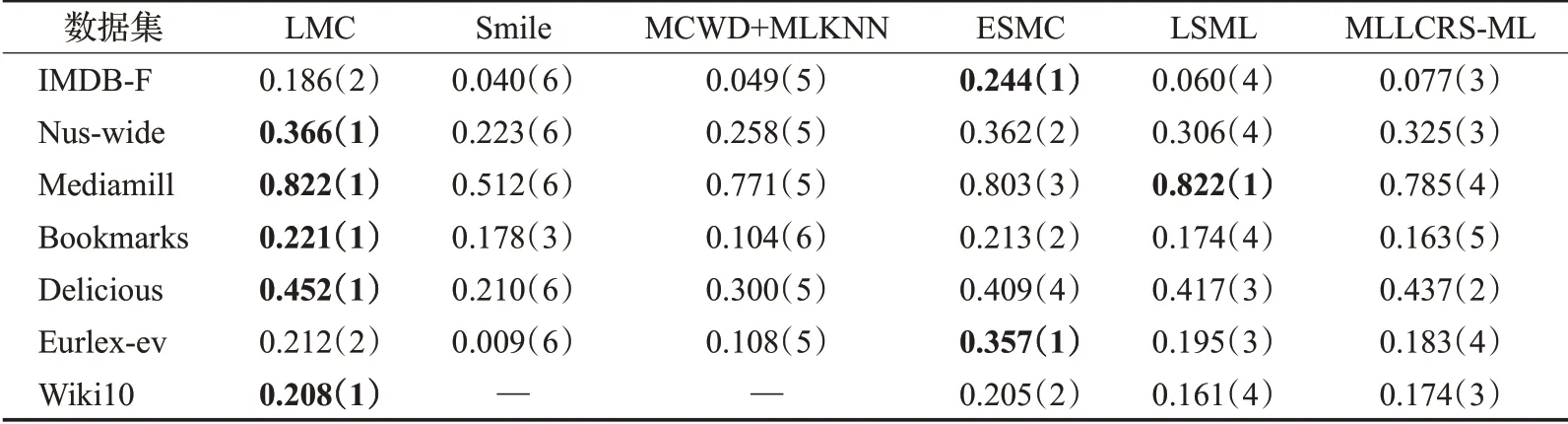
表2 在P@1下的实验结果“均值(排名)”(取值越大越好)Table 2 Experimental result on P@1“mean(ranking)”(the larger the value,the better)
2.4 分类结果分析
为了分析不同算法在不同数据集中的性能,使用Friedman 检验进行性能分析。在实验中,总共有6 种方法和7个数据集并分别将其记为k=6,N=7,Rj表示第j个算法在所有数据集上的平均排名,则Friedman统计值服从自由度为6-1=5 的χ2分布。表7 显示了在显著性水平α=0.05 上每个评估标准的FF取值。如表7 所示,所有的评估值都超过了临界值,因此这些方法的性能是不同的。

表3 在P@3下的实验结果“均值(排名)”(取值越大越好)Table 3 Experimental result on P@3“mean(ranking)”(the larger the value,the better)

表7 在每个评价标准下的Friedman统计值Table 7 Friedman statistics FF on each evaluation criteria

表4 在P@5下的实验结果“均值(排名)”(取值越大越好)Table 4 Experimental result on P@5“mean(ranking)”(the larger the value,the better)
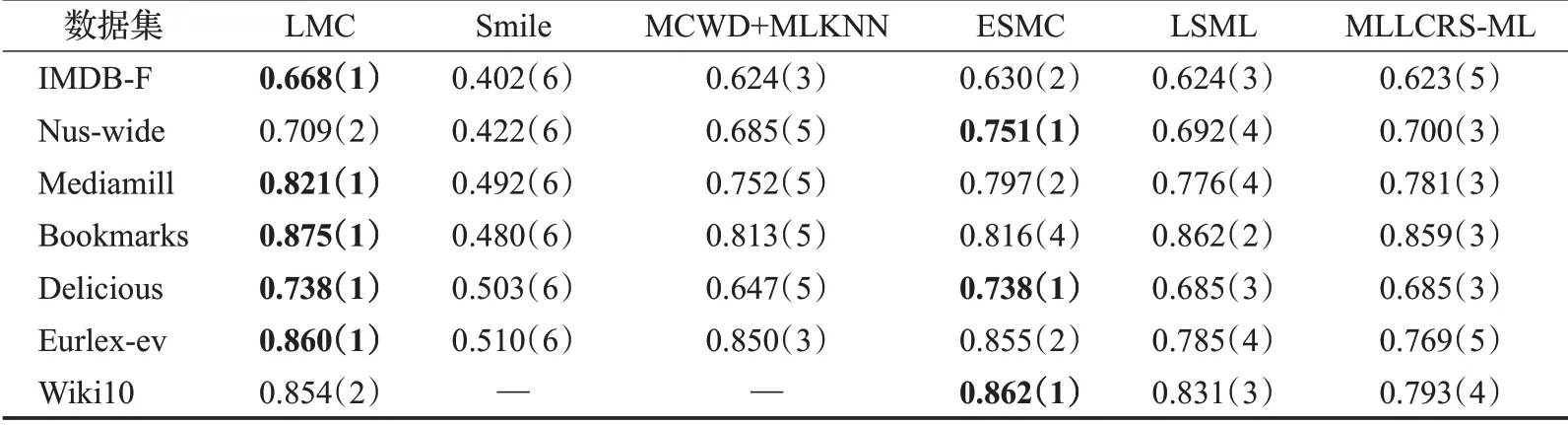
表5 在average-AUC下的实验结果“均值(排名)”(取值越大越好)Table 5 Experimental result on average-AUC“mean(ranking)”(the larger the value,the better)
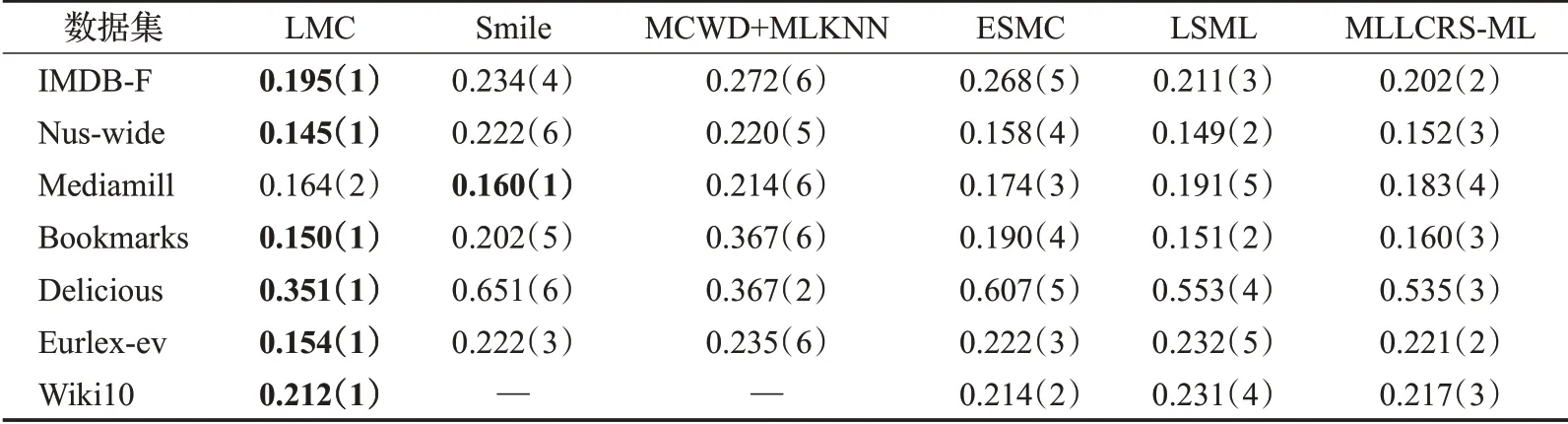
表6 在coverage下的实验结果“均值(排名)”(取值越小越好)Table 6 Experimental result on coverage“mean(ranking)”(the smaller the value,the better)
之后,使用Nemenyi 检验进一步分析所有比较方法之间的相对性能,它可以显示提出的LMC 算法是否能比比较算法实现更好的性能。临界值域(CD)由计算。通过查表,可以得到qα=2.850。然后,可以计算出CD=2.850。如果LMC的平均排名与另一种方法在所有数据集上至少有一个CD 差异,则这种方法的性能明显不同于LMC。图7总结了每个评估标准的CD图。在图7中,可以看到LMC的水平段在所有评估标准中与除ESMC 之外的其他算法没有重叠,因此这意味着LMC 与其他算法之间存在显著差异。ESMC与LMC差别不大的原因是两个算法都是用标签之间的相关性进行缺失标签恢复,并且都存在对长尾标签的处理。此外,通过图7 可以得出结论,LMC 在所有评估指标上都优于其他算法。

图7 在每个评价标准上的CD图Fig.7 CD diagrams on each evaluation metric
2.5 算法时间复杂度
LMC算法主要包括聚类和迭代两个部分。k-means聚类的时间复杂度为O(n),在迭代中,主要时间成本是计算变量W,时间复杂度为O(r(nq+nr+rq))。因此,总的时间复杂度为O(nrq+nr2+qr2+n) 。为了分析LMC算法的训练速度优势,表8总结了所提出方法和比较方法的时间成本,一般来说,n≫d>q>r。为了便于比较,此处取每个算法复杂度的最高项进行对比,由于MCWD+MLKNN算法涉及n3,因此该算法的时间复杂度最高。Smile涉及n2,LSML中涉及d3,MLLCRS-ML中q2dn值大于ESMC 中的nq3,ESMC 中的r为三次方,而在LMC 中为二次方。因此,所提出的LMC 方法的复杂性优于其他方法。

表8 各算法的时间开销Table 8 Time costs of different methods
通过上述大量实验的比较分析,充分体现了LMC算法在恢复缺失数据和大规模多标签数据分类方面的优势。
3 结束语
本文提出了一种基于局部标签相关性的多标签分类算法,用于解决在大规模数据集上含有缺失标签的分类问题。该方法首先通过在特征空间上应用聚类分析,将原始数据集分解为多个数据簇,后利用隐藏在数据簇内部的局部标签相关性来进行缺失标签的恢复及局部模型的训练。本文在7 个来自不同领域的基准数据集上进行了大量实验,结果表明本文提出算法在处理大规模数据及缺失数据上具有一定的优越性。对于未来的工作,将寻求一种更合适的方法将具有相似标签相关性的多标签实例进行聚类。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
计算机系统应用(2021年2期)2021-02-23
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
电子技术与软件工程(2019年18期)2019-11-18
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
电子技术与软件工程(2017年14期)2017-09-08
航天返回与遥感(2014年5期)2014-07-31
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
