
基于改进密度峰值聚类算法的轨迹行为分析
2022-09-06 11:09刘漫丹
计算机工程与应用 2022年17期
吕 奕,刘漫丹
华东理工大学 化工过程先进控制和优化技术教育部重点实验室,上海 200030
教育管理信息化是信息化社会的重要组成部分。随着校园信息化程度的不断提高,利用校园网通过无线网络的方式进行校园电子化信息管理成为主流,由此积累了大量的校园无线网络数据。如何有效地分析和利用这些海量数据,从而让其更好地服务于校园和教育,近年来成为一个热点问题。根据用户登录无线网的位置及时间,并按照时间顺序将位置依次连接起来,可以得到用户轨迹信息。根据轨迹信息之间的相似性对群体特征进行深入探索和分析,可以有效推进校园网的更新迭代以及指导学生的网络使用行为。
轨迹数据聚类[1]是轨迹分析的重要方面,其是将具有不同时间和空间相似度特征的时空对象划分为多个类或簇,使同一类内的对象相似性程度高,而不同类之间数据的相似性程度低。针对轨迹行为分析已有不少研究成果。吴笛等人[2]对南海旋涡轨迹进行时空聚类分析,在空间聚类的基础上提出轨迹线段时间距离的度量方法和阈值确定原则,验证了基于密度的轨迹时空聚类方法的有效性。穆桃等人[3]通过分析多层网络流量,利用多种机器学习方法,预测出用户的地理位置类型和兴趣爱好,并将两者相结合提高用户分类的准确性。李旭等人[4]通过构造用户兴趣度矩阵的方式改进用户间相似度的计算方法,提出了基于兴趣矩阵的相似度聚类算法。
对校园无线网络轨迹行为特征进行聚类分析,一方面,可以根据不同集合中学生的轨迹特点将高校学生分为不同簇,分析判断不同簇学生的特点,为高校教育教学方案提供依据,为学生管理系统提供决策支持[5]。另一方面,将离群点检测算法与聚类算法相结合,可以因此判断出学生中的离群学生并进行针对性处理。由于校园轨迹具有较强的规律性[6],通过检测学生的异常轨迹,可分析学生是否按时上课或者是否在教学期间内离校等问题,针对频繁发生轨迹异常的学生进行有效的管理,密切关注使用者动态,防止意外事件发生[7]。
本文采用基于共享最近邻的快速搜索密度峰值聚类算法(shared-nearest-neighbor-based clustering by fast search and find of density peaks,SNN-DPC)[8]对校园无线网络轨迹进行聚类分析,在传统的局部密度的核密度计算方式的基础上,改进局部密度度量,使得算法适用于多比例、各密度以及数据集之间交叉缠绕等高维度的复杂数据集,更有利于对校园无线网络数据进行聚类分析。聚类算法对离群点信息较为敏感,若将离群点算法与聚类算法相结合,可以有效减小离群点对整体聚类的影响。因此,本文将离群点检测算法与SNN-DPC 聚类算法相结合,得到两种改进后的SNN-DPC算法,两种改进算法均克服了原有聚类算法对离群点敏感问题的不足。将算法应用于实际校园无线网络信息处理中,可以定位浏览信息异常学生,为高校信息化建设提供了信息支持。
1 SNN-DPC算法介绍
SNN-DPC 算法是在基于密度峰值的快速搜索聚类算法(clustering by fast search and find of density peaks,CFSFDP)[9]的基础上,考虑了每个点的邻居的影响,引入了一种间接距离和密度的测量方法,利用共享邻居的概念来描述点的局部密度和它们之间的距离[9]。
定义1(共享最近邻数SNN)对于数据集X中的任意两个点xi和xj,点xi的K个最近邻集合(Γ(xi))与点xj的K个最近邻集合(Γ(xj))的交集定义为共享最近邻数SNN(xi,xj)。通常来说,两个点共享的邻居数目越多,则这两个点越相似。共享最近邻数用式(1)表示:
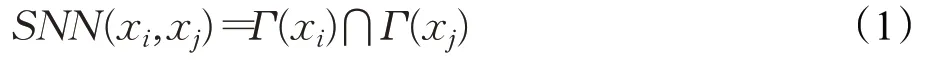
定义2(SNN相似度Sim(xi,xj))点xi和xj之间的相似性程度称为SNN相似度。对于数据集X中的点xi和xj,相似度可以定义为式(2):
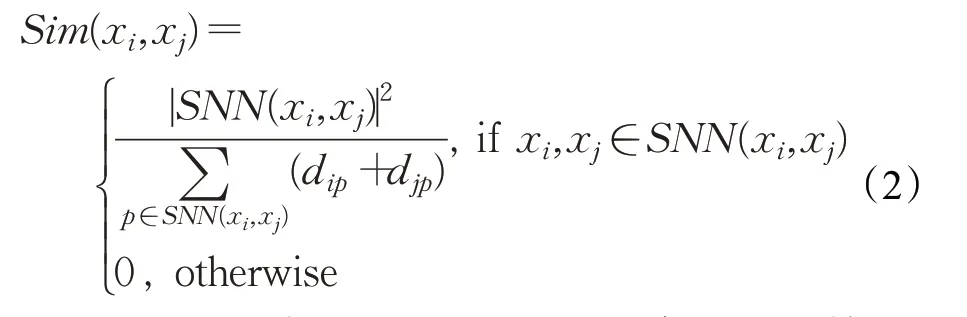
其中,SNN(xi,xj)表示点xi和xj的共享最近邻数,d表示数据点间距离,通常为欧氏距离,点p为点xi和点xj共享的邻居点,也就是说,仅当点xi和点xj出现在彼此的K邻居集合中时,才计算SNN相似度。否则,点xi和点xj之间的SNN相似度为0。在定义任意两个点的SNN 相似度之后,使用该相似度来计算点xi的局部密度ρi。
定义3(局部密度ρi)与点xi相似度最高的K个点的SNN相似度(Sim(xi,xj))之和,用式(3)表示:

其中,L(xi)=(xi,…,xK)表示与点xi相似度最高的K个点的集合。
局部密度ρ不仅利用距离信息,而且还通过共享最近邻数SNN 获得有关聚类结构的信息,充分揭示了点与点之间的内在关系。
定义4(最近距离δi)计算点xi与其高于自身密度的点的最近距离δi(简称xi的最近距离)需要找到局部密度大于点xi的点xj,然后将数据点xi和xj之间的欧氏距离乘以这两点分别与它们的最近邻距离之和,取最小值。具体定义如式(4)所示:
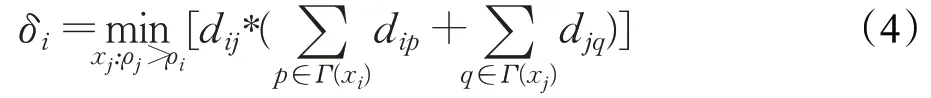
可以看出,最近距离δ不仅考虑了距离因素,同时考虑了每个点的邻居信息,从而补偿了低密度簇中的点,并提高了δ值的可行性,适应不同密度数据集。
密度最大点的δ值需要特殊定义,因为其是数据集X剩下所有点中δ最大的,如式(5)所示:

定义5(决策值γ)局部密度与最近距离之积。点xi的决策值γi用式(6)表示:

决策值γ的作用在于确定聚类中心点,通常来说,γ值越大,相应的ρ和δ越大,对应的数据点越有可能成为聚类中心。根据决策值确定聚类中心点之后,SNN-DPC 算法对未分配的点分为两类考虑,确定的从属点与可能的从属点。
定义6(确定的从属点与可能的从属点)满足不等式(7)所示的条件,就是确定的从属点,否则就是可能的从属点。假设点xi已经被安排到一个簇中,xj还没有被安置,如果点xj满足不等式(7),那么xj不可避免地属于xi所在的簇。换句话说,xi和xj各自的K邻域中至少一半是共享的,两点才有可能成为同一个簇的点。

除了定义上的差异外,确定的从属点和可能的从属点之间的另一个区别是,在非极端情况下,每个点都可能同时从属于多个聚类,却不可避免地只能从属于一个簇。
2 基于共享邻居的改进聚类方法
SNN-DPC算法在计算样本点间相似度时采用的是欧式距离代表数据点之间的相似程度,距离越大,表示相似性程度越低,因此不能利用相似度矩阵直接进行计算。本文首先通过转换函数,将相似度矩阵转变为距离矩阵,再使用SNN-DPC算法,可以提高聚类算法对各种相似度矩阵的适应度。聚类可以对相关性较强的样本进行划分,而离群点检测可以对相关性非常弱的样本点进行分类,聚类与离群点分析可以形成一种互补关系。SNN-DPC 算法中没有对离群点进行分析,在处理确定的从属点与可能的从属点时力求每一个点都可以安排到一个确定的簇,因此不可避免地会受到离群点对聚类结果的影响。本文通过将离群点检测算法与SNN-DPC算法相结合,先对数据集中的离群点做“高亮”处理,对剩下的点进行聚类,可以提高聚类的准确性与快速性,达到较好的聚类效果。另外,检测出的离群点也可做单独分析。
2.1 相似度矩阵转变为距离矩阵
本文采用的原始数据集为某校园无线网络中记录的用户真实轨迹数据。数据集中将包含的校园全区域范围内的各地点分别用数字进行编号。用户某天的时空轨迹序列如表1所示,其中l表示用户所在区域编号,t表示用户在该地的网络登录时间,m为用户总量,W1,W2,…,Wm分别表示各用户轨迹序列中的登录记录总数。

表1 用户时空轨迹数据集Table 1 User spatial-temporal trajectory dataset
基于无线网络中时空轨迹的数据特点,在分别计算不同用户之间轨迹的时间相似性和空间相似性后,引入连续因子优化空间相似性度量,结合轨迹的时间维度与空间维度求得用户之间的轨迹相似度信息[10]。
相似度信息包括时间相似性与空间相似性。
对于整体轨迹序列而言,两轨迹中时间距离小的轨迹点越多,说明相遇次数越多,轨迹整体的时间相似性越高。采用最短时间距离(shortest time distance,STD)[11]模型计算时间相似性。
假设存在两个用户ui和uj,其时空轨迹序列分别为Ri={ri,1,ri,2,…,ri,x,…,ri,Wi}和Rj={rj,1,rj,2,…,rj,y,…,rj,Wj}。并假设存在两个轨迹点ri,x(li,x,ti,x)和rj,y(lj,y,tj,y),其时间距离记为Dis(ri,x,rj,y),如式(8)所示:
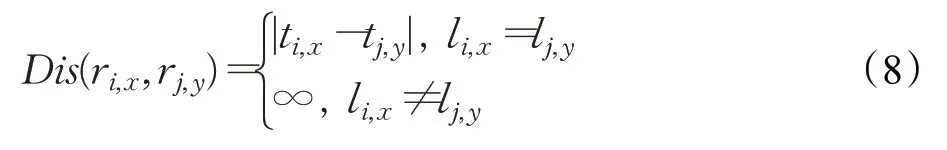
最短时间距离定义为轨迹Rj中所有轨迹点中与轨迹点ri,x时间距离最小的值,表示如式(9):
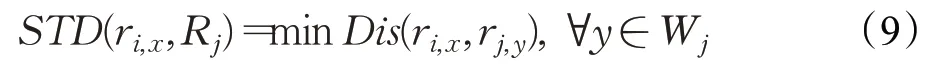
轨迹Ri对于轨迹Rj的时间相似性可以近似为轨迹Ri中所有轨迹点与Rj中对应STD 匹配轨迹点的时间相似性总和,记为Cor(Ri,Rj),表示为式(10):

由于STD模型的计算结果不具有对称性,两轨迹之间的时间相似性表示为式(11):

空间相似性信息利用最长公共子序列(longest common subsequences,LCSS)[12]算法,寻找两个给定序列的公共子序列中最长的子序列。
轨迹Ri和轨迹Rj的空间相似性由LCSS序列的长度分别占两条轨迹长度比例的平均值与连续因子共同决定:
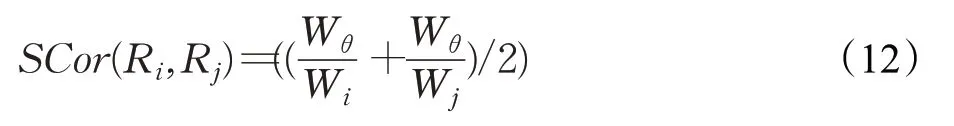
其中,Wθ表示LCSS序列的长度。
用户相似性可以通过轨迹段的时空相似性得到,用式(13)表示:
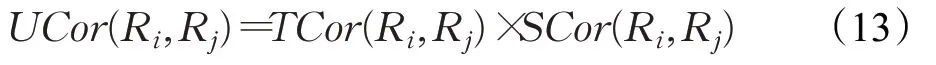
相似度矩阵用S表示,如式(14)所示:

其中,sij表示用户i和用户j之间的相似度,即式(13)中的UCor(Ri,Rj),0 ≤sij≤1。矩阵的对角线元素为1。
由于相似度矩阵与距离矩阵负相关,即相似度矩阵中的值越大,距离矩阵中的值应该越小。因此,采用如式(16)所示的转换函数将相似度矩阵转换为距离矩阵。
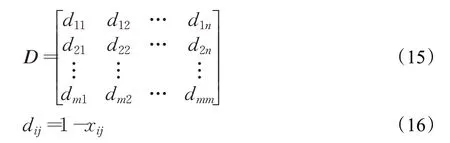
其中,i=1,2,…,m,j=1,2,…,m,dij表示用户i和j之间的距离,D表示距离矩阵。
2.2 基于离群点检测的SNN-DPC聚类算法
为了减少离群点对算法的影响,首先需要确定数据集中的离群点并且移除它们。许多真实世界的数据集展示了一个非常复杂的结构,在实际应用中,通常会按照实际情况选择对应的离群点数据挖掘算法。本文针对SNN-DPC 算法提出两种离群点检测算法,一种算法是基于局部密度离群点检测的SNN-DPC 算法,简称RSNN-DPC 算法,该算法是利用SNN-DPC 算法本身计算的局部密度值,设定阈值范围,寻找离群点。另一种算法是基于LOF 离群点检测的SNN-DPC 算法,简称LSNN-DPC 算法,其是将LOF 算法与SNN-DPC 算法相结合,减少实验输入参数并去除离群点的影响,成为新的去除离群点的聚类算法。
2.2.1 基于局部密度离群点检测的改进算法(RSNN-DPC)
在SNN-DPC 聚类算法中,有两个重要指标可以表征样本点的密度情况,即局部密度ρ和最近距离δ,通过第1 章对SNN-DPC 算法的分析,最近距离是根据局部密度进行定义的,因此可以通过局部密度来表征样本点的密度情况。如果一个对象的局部密度相对于其相邻对象的密度要低得多,那么这个对象很有可能就是一个离群值。
在SNN-DPC算法中,局部密度ρ具有以下特性[13]:
(1)当邻居数K较小时,点xi与其邻居xj之间的共享邻居数较小,同时点xj与点xi之间的距离也较近,此时,K反映了点xi较小邻域内的局部密度。相反,当K较大时,点xj与点xi之间的距离较远,它反映了xi的较大邻域内的局部密度。低密度簇中的点之间的距离较大,因此K的变化将对低密度簇产生更大的影响。
(2)当|SNN(xi,xj)|恒定时,如果点xi和点xj到它们的每个共享邻居的距离都很小,则ρi较大。换句话说,如果点xi和点xj之间的距离很小,并且每个共享的相邻点到xi和xj的距离也很小,那么点xi的密度就很大。因此,空间中距离数据点xi越近的点对ρi的贡献越大。
通过对局部密度的分析可知,局部密度ρ不仅利用距离信息,而且还通过共享最近邻数SNN 获得有关聚类结构的信息,充分揭示了点与点之间的内在关系。在这种情况下,如果局部密度值为0,说明数据集X中与之相关的所有点SNN相似度为0,可能原因有以下两点:
(1)该点独立于其他各点,与数据集中剩余点没有共享邻居点,即SNN为0。
(2)点xi和xj到它们所有共享邻居的距离接近于无穷
因此,可以将局部密度ρi作为离群点的一个判断条件,通过判断局部密度是否为0 选择离群点并删除,再进行接下来的聚类。算法的具体步骤用算法1 和算法2表示,其中算法1表示的是RSNN-DPC算法的整体过程,算法2表示的是在确定聚类中心后分配确定的从属点与可能的从属点的具体算法步骤。
算法1基于局部密度离群点检测的改进算法(RSNN-DPC)
输入:相似度矩阵X,邻居数目K,聚类数NC。
输出:聚类结果Φ={C1,C2,…,CNC} ,离群点集合Ψ={ψ1,ψ2,…}。
步骤1对相似度矩阵X进行预处理,根据转换式(16),计算距离矩阵D。
步骤2根据式(2)计算相似性矩阵Sim(xi,xj)。
步骤3根据式(3)计算局部密度ρ。
步骤4筛选出局部密度ρi=0 的数据点作为离群点,输出离群点集合Ψ={ψ1,ψ2,…},并将数据集中的离群点删除,对剩余样本聚类。
步骤5根据式(4)、(5)计算最近距离δ。
步骤6根据式(6)计算所有点的决策值并按降序排列,得到排序后的γ′。
步骤7根据聚类个数NC,选择γ′最大的前NC个点确定为聚类中心,由此产生聚类中心数据集Center={c1,c2,…,cNC}。
步骤8根据算法2,分配确定的从属点和可能的从属点,并将从属点归类到对应的集合中,得到聚类结果Φ。
算法2分配确定的从属点和可能的从属点
输入:聚类中心数据集Center={c1,c2,…,cNC}, 邻居数目K,距离矩阵D。
输出:最终聚类结果Φ={C1,C2,…,CNC}。
步骤1初始化队列Q,将聚类中心Center中所有点置入队列Q。
步骤2将队列Q中第一个点xa从队列中取出,根据距离矩阵D查找点xa的K个最近邻,定义最近邻集合为Ka。
步骤3依次选择最近邻集合中的未分配点x′∈Ka x′∈Ka,如果x′满足条件(7),则将数据点x′归类到xa所在的簇中,并将x′添加至队列Q尾部,作为已知分配情况的样本点;否则x′为可能的从属点,暂时无法分配簇集,继续选择最近邻集合Ka中的下一个点判断分配情况,Ka中所有样本点判断完毕后转步骤2,进行队列Q中下一个确定的从属点的分配。
步骤4当Q=∅时,代表所有确定的从属点已经分配完毕,数据集中剩余点为可能的从属点,接下来对可能的从属点进行分配。
步骤5找到未分配的可能的从属点并重新编号。定义一个矩阵M,行表示未分配点的编号,列表示簇序号。
步骤6计算每一个未分配的点的邻居中属于各个簇的邻居数,并将其写入分配矩阵M的对应簇的列元素中。
步骤7寻找中M每一行元素的最大值Mimax,用最大值所在的簇表示该行未分配点i的簇。分配完成后更新矩阵M,直到所有点均被分配。
步骤8输出最终聚类结果Φ={C1,C2,…,CNC}。
2.2.2 基于LOF离群点检测的改进聚类算法(LSNN-DPC)
2.2.1小节采用局部密度来表示样本点的密度情况,可以根据样本点局部密度的差异检测出密度明显异常的点,但是由于局部密度受到邻居数的影响较大,当邻居数取值不合理时,可能检测不出离群点。在众多的离群点检测方法中,LOF(local outlier factor)方法[14]是一种典型的基于密度的离群点检测方法,此方法能有效识别局部离群点和全局离群点,因此在离群点检测问题中广泛应用。其主要定义如下:
定义7(ε-邻域Nε(i)和数据点xi的k-距离Nk(i))ε-邻域定义为与数据点的距离小于ε的数据点集合。数据点的k-距离定义为与数据点的距离小于k_dist(i)的数据点集合。ε-邻域用于确定数据点的密度特征比较范围,即每个数据点的密度特征与其ε-邻域内的数据点比较。同样,k_dist(i)表示数据点xi与距其第k近的数据点的距离,具体定义如式(18)所示:

其中,k为自然数。
定义8(数据点xi的核心距离cd(xi))当xi的ε-邻域内数据点数目大于MinPts时,xi的核心距离定义为xi的MinPts-距离,否则定义为0,具体如式(19)所示:

其中,MinPts为给定自然数。
定义9(数据点xi关于xj的可达距离rd(xi,xj))当xi的ε-邻域内数据点数目大于MinPts时,xi关于xj的可达距离定义为xi的核心距离与两点之间真实距离的最大值,否则不作定义。也就是说,数据点xi关于xj的可达距离至少是xi的核心距离,或者是两点之间的欧式距离。具体定义如式(20)所示:
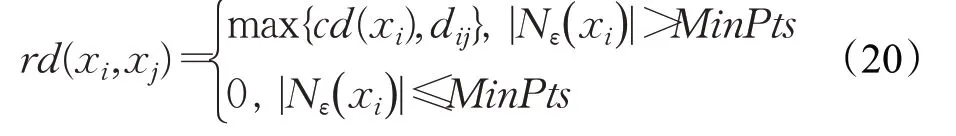
定义10(数据点xi的局部可达密度lrd(xi))局部可达密度定义为数据点xi的MinPts-邻域内数据点个数和xi与其邻域内其余数据点可达距离之和的比值,表征了数据点xi的局部密度。局部可达密度值越大,局部区域点的分布就越密集。定义如式(21)所示:

定义11(数据点xi的离群因子LOF(xi))数据点xi的离群因子定义为xi的MinPts-邻域内数据点与xi点局部可达密度的平均比值。数据点的离群因子值越高,说明xi点与其邻域内数据点密度特征差异越显著,其成为离群点的可能性也就越大。

xi的离群因子LOF(xi)表示的是一种密度对比,表示数据点与整体的一种密度差异。若LOF 值远远大于1,表示该点的密度与数据的整体密度差异较大,则认为该点为离群点。假如LOF值接近于1,表示该点与整体的差异较小,因此可认为该点为正常点。
为直观表示说明,随机生成一个100×2 的数据集,指定第99 个和第100 个数据为离群数据。图1 用二维坐标图的形式说明了原始数据的分布情况,可以看出,大部分数据分布在一个1×1的正方形区域内,而第99个点和第100 个点远离样本集合,明显为离群点。图2 展示了通过LOF算法计算的100个样本点的离群度。

图1 100个随机数据分布二维示意图Fig.1 Two-dimensional schematic diagram of 100 random data distribution
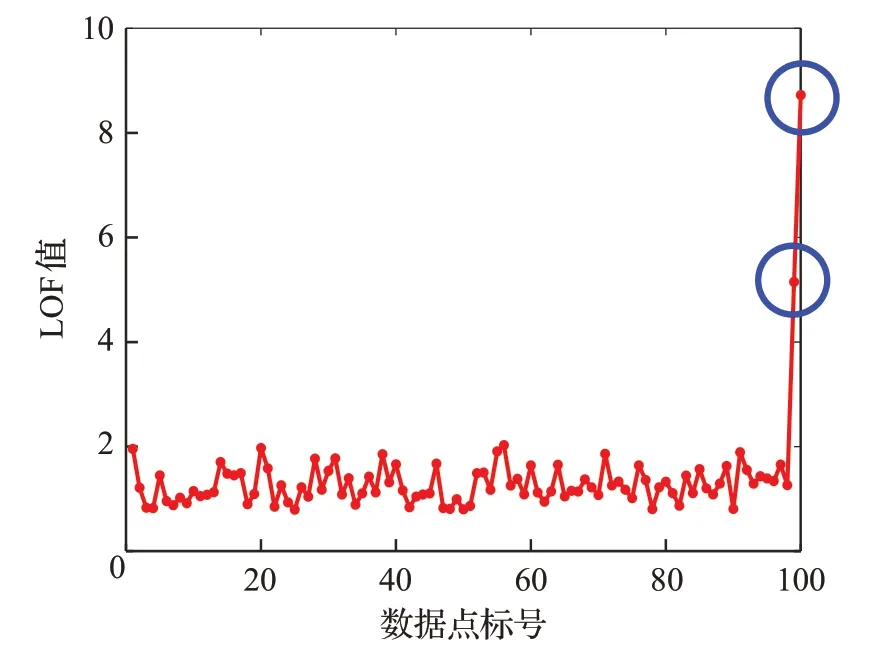
图2 各数据样本点LOF值比较Fig.2 Comparison of LOF value of each sample point
大部分LOF值在1附近波动,表示大部分点密度与整体密度差异不大,而99 和100 个点的LOF 值远大于1,接近5和8,表示这两点的密度与整体密度差异较大,因此可以认为这两点为离群点,这与之前的假设也是契合的。
在现实场景中,数据分布往往是非均匀的。LOF算法可以很好地解决基于距离和统计离群检测方法无法检测局部离群点的问题[15],但其算法本身也存在一些不足:
对于分布较密的数据集,如果选择的MinPts值较小,可能会出现部分对象的MinPts-距离为空值,导致其MinPts-邻域内的所有点到该点的距离都为0,在计算可达距离时会出现分母为0,导致LOF值无穷大的现象,会导致局部异常因子运算异常。
LOF 算法的性能受参数MinPts影响较大,对于参数值的确定,需要一定的邻域知识,这使得算法的难度加大。而且人工干预和经验值的参与也会直接影响到算法在离群检测中的性能。
基于LOF算法的两个不足,本文提出利用SNN-DPC中定义的邻居数K代替MinPts-邻域中MinPts值的改进方法。由于SNN-DPC 中定义的邻居数是与某点xi距离最近的K个点的个数,MinPts-邻域中的MinPts表示的含义与邻居数K相近,因此用邻居数K来替换邻域值MinPts是合理的。将LOF 算法与SNN-DPC 算法相结合,此时只需要设置一个邻居数K即可,有效减少了参数的输入个数,降低了获取参数的困难性。同时,由于定义的邻居数不可能为0,也可以杜绝算法在运行时出现分母为0的运算错误。
LSNN-DPC的具体算法步骤用算法3表示,其中包含的算法2在2.2.1节已作说明。
算法3基于LOF离群点检测的改进算法(LSNN-DPC)
输入:相似度矩阵X,邻居数目K,聚类数NC。
输出:聚类结果Φ={C1,C2,…,CNC} ,离群点集合Ψ={ψ1,ψ2,…}。
步骤1对相似度矩阵进行预处理,根据转换公式(16),计算距离矩阵D。
步骤2根据离群因子计算式(22),计算各样本点的LOF 值,找到超出阈值范围的点,输出离群点集合Ψ={ψ1,ψ2,…},并将数据集中的离群点删除,对剩余样本点进行聚类。
步骤3根据式(2)计算相似性矩阵Sim(xi,xj)。
步骤4根据式(3)计算局部密度ρ。
步骤5根据式(4)、(5)计算最近距离δ。
步骤6根据式(6)计算所有点的决策值并按降序排列,得到排序后的γ′。
步骤7根据聚类个数NC,选择γ′最大的前NC个点确定为聚类中心,由此产生聚类中心数据集Center={c1,c2,…,cNC}。
步骤8根据算法2,分配确定的从属点和可能的从属点,并将从属点归类到对应的集合中,得到聚类结果Φ。
3 实验分析
为了验证算法的有效性及可行性,本文选择真实校园无线网络中记录下的数据集产生的相似度矩阵转化后距离矩阵的Stu_500 和Stu_2000 进行验证与评估。由分析可知,距离矩阵是通过最短时间距离子序列轨迹相似性度量模型得到的相似度矩阵通过转换函数得到的。两个数据集均由山东某高校2019 年9 月1 日至2019 年9 月30 日共一个月的学生轨迹记录以及学生相关信息组成。表2 说明了两个数据集包含学生种类的大致情况。

表2 数据集情况描述Table 2 Description of dataset
表3说明了本次实验的硬软件环境及开发工具。

表3 实验环境Table 3 Experimental environment
为量化评价算法的检测结果,需要使用评价指标表示聚类效果的优劣程度。校园无线网络数据集是无标签的,因此不能依靠外部指标,只能通过内部指标来判断聚类形成的簇间距离和簇内距离大小。一般来说,聚类的目标是使得簇间距离增大而簇内距离减小,通过对簇内距离和簇间距离不同角度的组合判断,提出以下几种评价指标。评价指标根据趋势分为两类:一类指标数值越大,聚类效果越好,称为正相关指标;另一类指标数值越小,聚类程度越高,称为负相关指标。正相关指标包括邓恩指数(Dunn validity index)[16]、轮廓系数(Silhouette index,Sil)[17];负相关指标包括紧密性程度(compactness,CP)[18]、戴维森堡丁指数(Davies-Bouldin index,DBI)[19]。各个指标都能够从一个方面对聚类结果进行一定的评估,但是也都存在一定的局限性,因此,应将各种内部指标结合起来综合评估,而不应该因为一个评价指标没有得到较好的评价结果而否定聚类效果[20]。
3.1 数据集预处理
学生相似度矩阵中存在数据缺失或者不完整的部分,会影响数据的正确性继而不利于聚类,为了清除数据缺失等问题的影响,同时提高数据挖掘的质量,需要对数据进行预处理操作。
缺失的数据一般指的是没有采集到的数据或者是无限小的无效数据,对学生轨迹相似度的缺失处理分为两种情况。对相似度矩阵中全零行或者全零列判断为学生轨迹数据整体信息缺失,对于这部分数据记录其学生编号,采用整体赋值的办法处理。而对相似度矩阵中某一行或一列有部分数据缺失,即此人与其他大部分人有相似度,仅与小部分人相似度为0,对这部分数据的处理与缺失值处理相同,当相似度矩阵转化为距离矩阵时赋一个比较大的数据,表示此人与这部分人相似度极低。
3.2 算法参数的选择与分析
SNN-DPC算法中提出采用决策图的方式确定聚类数。决策图是将γ值降序排列后,以数据点个数为横坐标,以排序后的γ′值为纵坐标。γ′值越大表示该点的局部密度ρ和最近距离δ越大,即越有可能成为聚类中心点。实验中的决策图,即Stu_500 数据集与Stu_2000数据集得到的排序后的γ′值如图3和图4所示。
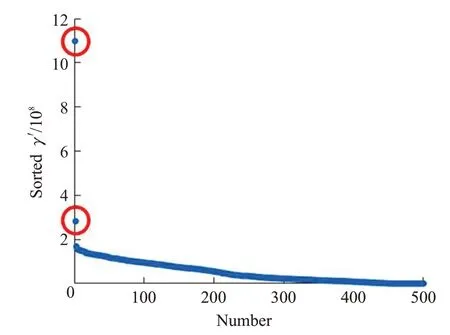
图3 Stu_500决策图Fig.3 Decision diagram of Stu_500
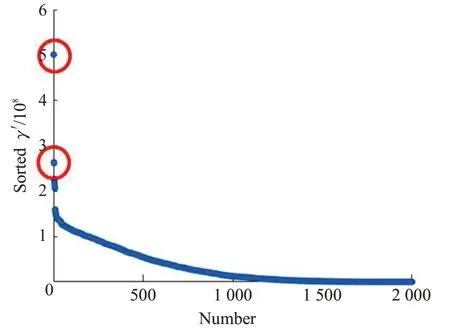
图4 Stu_2000决策图Fig.4 Decision diagram of Stu_2000
可以看到在决策图中,γ′值比较大且远大于剩余点的γ′值的点均有两个,已用红色圆圈在图中标明。
因此以聚类数为2(NC=2)为例说明使用RSNNDPC与LSNN-DPC算法聚类后内部指标的差异。
明确聚类簇数后,本实验可调整的参数仅包含邻居数K。选择合适的邻居数范围能够有效减少寻找最优邻居数的时间,因此先对各个内部指标随邻居数变化情况进行预实验,即令邻居数K从小到大变化,观察各指标变化情况。对于邻居数范围选择的下限,考虑到若邻居数目过少,某些数据集中点密度过于稀疏,不具备相似性,而且对于某些数据集,可能因为K过小导致错误,因此下限确定为5。
图5 和图6 分别表示Stu_500 和Stu_2000 数据集Sil、DBI 两个指标的变化情况,图(a)均为Stu_500 数据集,其K值从5到200变化,图(b)对应Stu_2000数据集各指标随邻居数增加的变化情况,其K值从5到500变化。以Stu_500 数据集为例分析,Sil 指标越大,表示聚类效果越好。由图5(a)可知,当邻居数较少时,Sil指标的震动幅度较大,并且出现了多个峰值点,随后,当邻居数K >50 时,Sil数值较平缓,意味着选择邻居数范围为[5,50]就足以找到最优邻居数。

图5 Sil指标随邻居数增加的变化Fig.5 Change of Sil index as number of neighbors increases
DBI指标值越小,表示聚类效果越好。观察图6(b)可以发现,当邻居数接近为10时,DBI达到一个最小值,可见此时对应的K邻居数为DBI 指标最优时的邻居数,随着邻居数的增加,DBI的值越来越大,后期稳定在一个比较高的数值,根据趋势分析,不能再出现最小值点,因此,选择邻居数范围为[5,60]足以找到使得DBI达到最优时的邻居数。
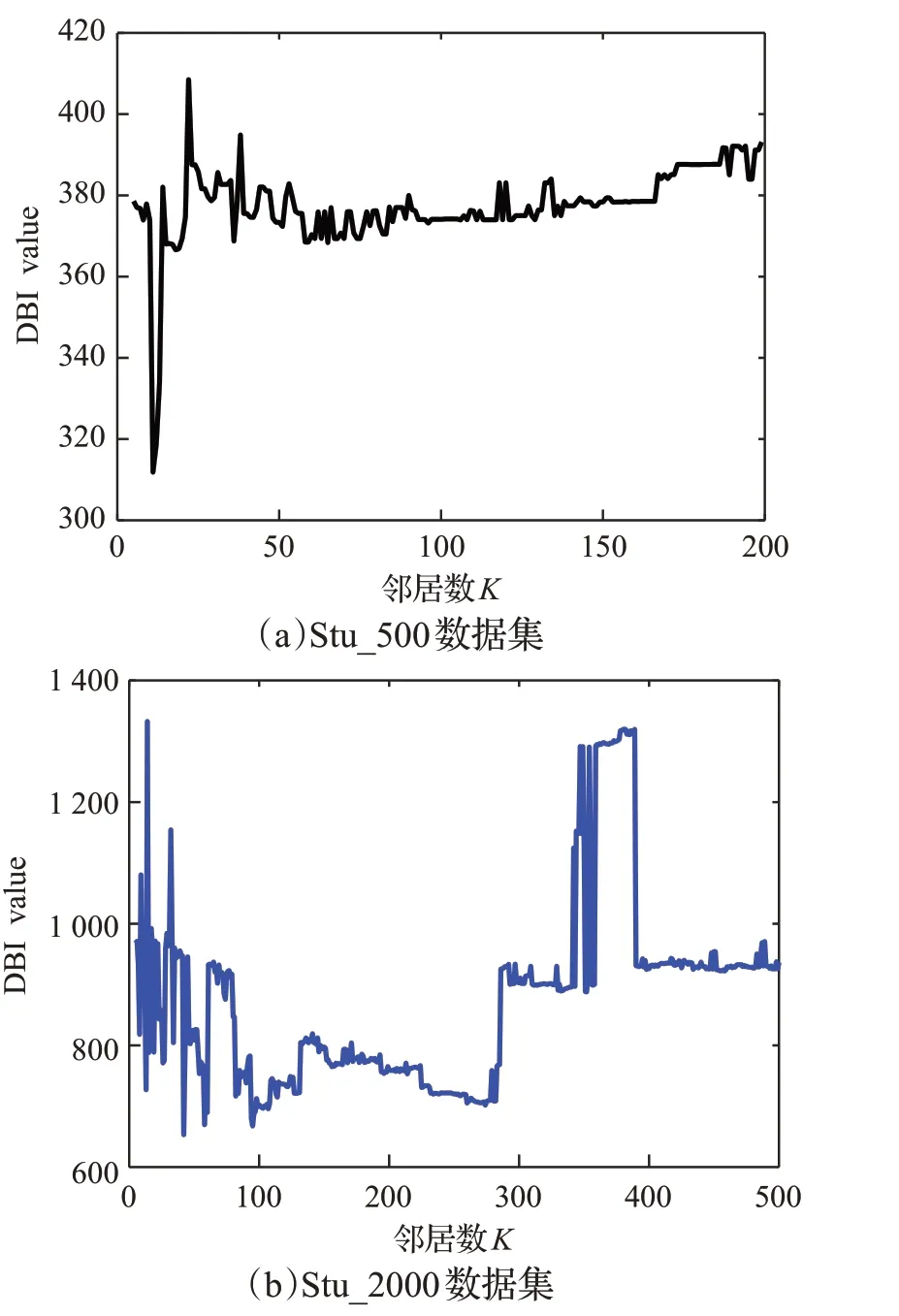
图6 DBI指标随邻居数增加的变化Fig.6 Change of DBI value as number of neighbors increases
综合上述分析,对Stu_500 矩阵,邻居数K的取值范围确定为[5,60]即可,后续实验操作也将基于这个实验范围进行内部指标分析。运用同样的方法,对Stu_2000 矩阵进行邻居数K的取值判定,发现取值范围为[5,300]可以满足选择最优指标的最低要求。
根据2.2.2 节对LOF 算法的分析,若离群因子值接近于1,表示样本点与整体的差异较小,因此可认为其为正常点,否则视为离群点。本文设置阈值为2,若计算出LOF≥2,则认为该样本点为离群点。
若分开使用LOF 算法和SNN-DPC 算法,需要设定LOF算法的MinPts距离,为保证实验的统一性,采用距离样本点第10 远的样本点(即MinPts=10)距离作为LOF算法的MinPts距离。
3.3 离群点检测数量的对比实验
本文采用两种离群点检测算法与SNNDPC 算法相结合,去除离群点的影响,增加聚类结果的可信度。离群点检测在聚类之前进行,因此不需要指定明确的聚类簇数,两种离群点检测算法的变量仅为邻居数K。本节探讨随着邻居数K的增加,RSNN-DPC 和LSNN-DPC两种算法在检测离群点个数方面的变化情况。
图7(a)表示Stu_500矩阵,邻居数K从5到60变化时,离群点数量变化情况。可以发现,随着邻居数的增加,LSNN-DPC算法得到的离群点个数,除了K <6 时离群点数量较大,剩余情况检测出的离群点数量基本保持平稳,可以说明该算法的稳定性较高,不会随着邻居数的增大而产生太大变化。而通过RSNN-DPC寻找到的离群点数目受到邻居数的影响较大,当邻居数较小时,离群点数量很大,随着邻居数目的增加,离群点的个数呈现出单调递减的趋势,但是在K >35 时,随着邻居数的增大得到离群点的数量稳定。

图7 离群点数量变化Fig.7 Change in number of outliers
图7(b)表示Stu_2000矩阵,当邻居数K从5到300变化时,两种算法得到的离群点数量变化情况。可以发现,随着邻居数K的增加,LSNN-DPC算法得到的离群点数目基本保持稳定,而通过RSNN-DPC 算法得到的离群点数量呈递减趋势,两者最终判断的离群点数量接近一致。
通过两个数据集的对比发现,随着数据点总量的增加,LSNN-DPC检测出的离群点数量更为统一。RSNNDPC前期离群点数量变化较大,后期离群点数量保持稳定。两者最终判断的离群点个数趋于相同。
3.4 聚类内部指标的对比实验
通过比较聚类内部指标的具体数值,可以推断出各个算法聚类的优劣。本文用Stu_500 和Stu_2000 两个校园无线网络轨迹距离矩阵进行实验,在计算各指标时,将每个离群点单独设置为一类,聚类中心为离群点本身。例如假设LSNN-DPC算法得到h个离群点,那么在计算各指标时,计算的是h+NC个聚类中心与其对应点之间的关系,这样可以保证各个算法计算得到的指标值考虑到所有样本点,而不是完全不考虑离群点后指标的变化。
表4至表6分别表示使用Stu_500矩阵,令K从5到60变化,每一种算法当CP指标、DBI指标、Dunn指标分别最优时,对应的邻居数K及其对应的CP指标、DBI指标、Dunn 指标、Sil 指标值。SNN-DPC 行表示原SNNDPC 算法未去除离群点的影响时聚类得到的各指标,LSNN-DPC行代表LSNN-DPC算法得到的各指标情况,RSNN-DPC行表示RSNN-DPC算法得到的各指标对应情况,LOF+SNN-DPC 行代表通过单独使用LOF 算法(K=10),去掉离群点后再使用SNN-DPC 聚类算法得到的各指标数值。

表4 CP指标最优时对应其余各指标值(Stu_500)Table 4 Other index values corresponding to optimal CP index(Stu_500)

表6 Dunn指标最优时对应其余各指标值(Stu_500)Table 6 Other index values corresponding to optimal Dunn index(Stu_500)
通过对表格的分析可知,最优指标集中出现在LSNN-DPC 和RSNN-DPC 中,说明文中所提出的两种基于离群点检测的SNN-DPC聚类算法在提高聚类效果上有一定的优势。其中LSNN-DPC 的CP 指标表现最优,说明使用LSNN-DPC得到的类簇,类内距离近,簇内聚合度最高。LOF+SNN-DPC 算法虽然能在一定程度上减少离群点对聚类效果的影响,但是由于参数K固定,并且参数的取值困难,导致参数取值不合适或者离群点判断存在偏差,使聚类结果劣于LSNN-DPC 和RSNN-DPC。
表7 至表9 表示的是Stu_2000 矩阵聚为两类时,当K从5 到300 变化时,每一种算法得到的聚类结果中,CP、DBI、Dunn指标最优的邻居数对应的其余各指标数值。表格各行的含义与Stu_500数据集定义相同。
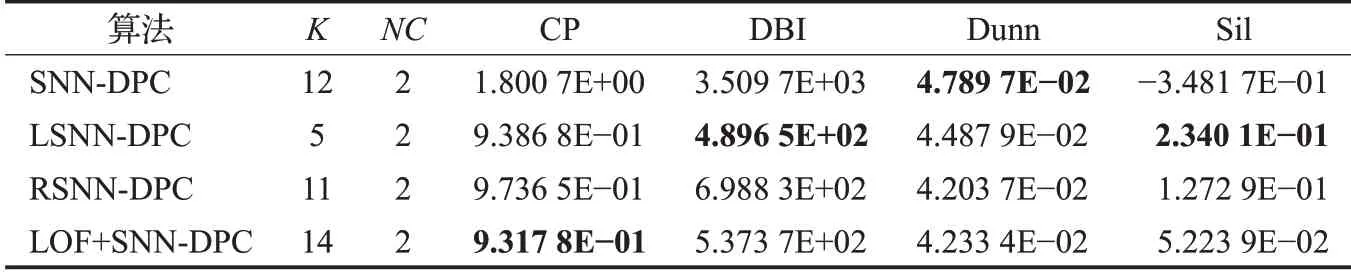
表7 CP指标最优时对应其余各指标值(Stu_2000)Table 7 Other index values corresponding to optimal CP index(Stu_2000)

表9 Dunn指标最优时对应其余各指标值(Stu_2000)Table 9 Other index values corresponding to optimal Dunn index(Stu_2000)
通过对表格的分析可以发现,针对CP 指标来说,LOF+SNN-DPC 算法是最优的,说明针对Stu_2000,令MinPts=10 能够单独使用LOF算法找到对聚类影响最大的离群点。尽管LSNN-DPC 和RSNN-DPC 在CP 指标上的表现差强人意,但是样本点规模的扩大没有明显影响到改进后算法的聚类效果,LSNN-DPC 算法和RSNN-DPC 的大部分指标均优于SNN-DPC 和LOF+SNN-DPC。也就是说,两种改进算法对数据集中数据量增加的鲁棒性较高,进一步验证了基于离群点检测的改进SNN-DPC算法在无线网络轨迹相似度数据集上的可行性。

表5 DBI指标最优时对应其余各指标值(Stu_500)Table 5 Other index values corresponding to optimal DBI value(Stu_500)

表8 DBI指标最优时对应其余各指标值(Stu_2000)Table 8 Other index values corresponding to optimal DBI value(Stu_2000)
另外,以Stu_500矩阵为例,通过上面数据的分析,当NC=2 ,邻居数K=37 时,比较LSNN-DPC 算法、RSNN-DPC 算法与未去除离群点的SNN-DPC 算法,对比结果如表10所示,其中聚类中心点8,279表示聚类中心点为编号为8和编号为279的两个点。

表10 聚类结果对比Table 10 Comparison of clustering results
可以看到,LSNN-DPC 和RSNN-DPC 两种算法不会影响聚类中心点的选取,只会去除边缘的离群点,避免离群点对整体聚类效果的影响,优化聚类效果。因此,基于离群点检测的SNN-DPC 算法可以应用于此类基于校园无线网络轨迹数据的聚类研究中。
4 结束语
现有聚类算法大多数是利用欧氏距离、马氏等距离来定义相似度,也就是说,大部分聚类算法直接利用距离矩阵对数据集进行处理,而无法直接处理相似度矩阵。针对此问题,本文在校园无线网络时空轨迹用户相似性度量研究的基础上,研究了聚类算法应用于相似性矩阵上的可能性,将相似度矩阵转化为距离矩阵,再通过基于密度的聚类算法进行聚类分析。其次,由于大部分聚类算法未考虑到离群点对聚类结果的影响,本文提出了两种基于离群点检测的SNN-DPC 聚类算法,其中LSNN-DPC检测出的离群点数目较为稳定,RSNN-DPC算法检测出的离群点数目前期变化较大,后期趋于稳定。两种改进算法一方面可以减少输入实验参数,另一方面在剔除离群点的影响后进行聚类,可以提高聚类的聚合程度。通过实验验证,LSNN-DPC 和RSNN-DPC两种改进聚类算法各项指标整体优于SNN-DPC算法和LOF+SNN-DPC 算法。将改进后的算法应用到实际校园无线网络轨迹行为特征的挖掘中,可以聚类校园中大部分用户的轨迹数据,通过分析大部分用户的行为特征,有利于分析学生之间的关联性,可以为校园建设方案提供可靠依据。另外,对于算法得到的离群点,也可以找到相应的用户对其进行处理,及时发现学生的异常,有针对性地对不同属性的学生进行管理。
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
铁道通信信号(2019年6期)2019-10-08
小型微型计算机系统(2018年8期)2018-09-07
现代装饰(2018年5期)2018-05-26
环球市场信息导报(2017年36期)2017-12-24
雷达学报(2017年6期)2017-03-26
阅读(中年级)(2016年4期)2016-11-19
