
融合Logistic回归与Tabnet模型的P2P网贷违约预测方法
2022-09-08 09:40朱益冬陈玉明卢俊文曾念峰
厦门理工学院学报 2022年3期
朱益冬,陈玉明*,卢俊文,曾念峰
(1.厦门理工学院计算机与信息工程学院,福建 厦门 361024;2.易成功(厦门)信息科技有限公司,福建 厦门 361024)
随着个人借贷需求的不断增长,加上互联网和金融的优势互补[1],P2P平台[2-3]应运而生。2007年8月,中国第一个P2P网贷平台拍拍贷诞生[4],此后P2P行业[5]进入飞速发展阶段。但网贷平台的不规范经营给平台机构、融资者和投资者等带来一系列风险。特别是到2018年下半年,多家网络借贷平台集中爆雷,对行业声誉造成了较大负面影响。如何对借款人的信用进行评估[5-6],成为规范社会和金融稳定发展的关键问题。
众多学者应用机器学习的方法在信用评估领域作了许多深入研究。普雪飞[7]提出了一种P2P网贷信用风险量化评估模型,基于P2P平台Lending Club的真实借款数据,利用逻辑回归算法构建借款人信用评估方法。刘潇雅等[8]提出基于支持向量机集成的个人信用评估研究,该方法较单一SVM模型和传统集成方法效能明显提高。然而这些研究都是将国外数据集作为考察对象,并且采用的模型都是传统的机器学习,难以拟合复杂多变的指标,使得预测精确度不高。王冬一等[9]提出基于大数据技术的个人信用动态评价指标体系研究的方法,选择较新的算法进行实验,然而缺乏对多维度数据进行算法的优化整合和应用对比。王重仁等[10]提出融合深度神经网络的个人信用评估方法,采用基于注意力机制的长短期记忆(long short-term memory,LSTM)模型和卷积神经网络(convolutional neural networks,CNN)模型2个子模型。吴斌等[11]展开对P2P网贷个人信用风险评估模型研究,提出一种混合果绳神经网络的方法,有效提升了个人信用违约预测精确度。Song等[12]提出基于距离模型和自适应聚类的多视角集成学习,并用于P2P借贷中不平衡信用风险评估,然而无法在准确性和多样性上做到很好的权衡。Akanmu等[13]提出一种基于提升决策树模型的P2P借贷违约预测方法,在美国小企业管理局公开可用的贷款管理数据集上取得了非常好的拟合效果。Cai[14]基于随机森林的P2P网络借贷违约分析,利用SMOTE算法平衡借贷数据集,并应用随机森林和交叉验证对特征进行选择。马春文等[15]基于随机森林分类模型对P2P网贷借款标的信用风险因子进行研究。Liu等[16]提出一种粗糙集的方法进行信用评估,尽管粗糙集模型的分类精度不如决策树、逻辑回归和神经网络模型,但粗糙集模型更准确地预测信用不良的用户。尽管这些方法都取得了不错的识别率,但是由于结构复杂,缺乏可解释性,难以对具体指标展开分析。
信用风险评估与预测涉及的指标众多,采用流行的Logistic回归(logistic regression,LR)模型,其参数简单,难以拟合复杂多变的信用指标。因此,针对借款人信用评估与预测问题,结合P2P平台的特点,本文提出基于Logistic回归[17]和Tabnet模型[18]的融合方法,对平台借款人违约概率进行预测。
1 LR与Tabnet模型
1.1 LR模型
LR是一种广义线性回归分析模型[19],在二分类和多分类应用广泛。LR的输出映射在0~1,而信用风险预测的概率值同样在0~1。
根据是否违约,信用评估划分为0和1两类,一般地,0表示未违约,1表示违约。按照广义线性回归模型的思想,最理想的方法是在线性组合后,通过一个单位阶跃函数将输出结果映射到0或者1。但是这种单位阶跃函数的导数性质不好,不利于权重优化,因此用其他可导函数形式来近似表示。sigmoid函数可以很好地近似单位阶跃函数,而且其导数性质非常好。sigmoid函数表达式为:
(1)
sigmoid函数的坐标如图1所示。
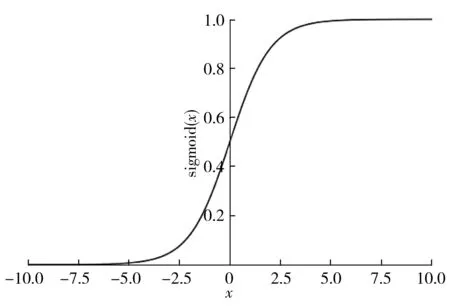
图1 sigmoid函数坐标图Fig.1 A sigmoid graph
sigmoid函数求导结果即是关于自身的一个函数。
(2)
因此,LR模型可表示为
(3)
其对数似然函数为
(4)
由于概率值的非线性,该对数似然函数的最优w值不能直接求解,于是采用梯度下降的方式求解,经过多次迭代即可得到最优参数w:
(5)
式(5)中:γ为学习率;J是损失函数。
1.2 Tabnet模型
金融领域存在不同的数据类型,其中使用最广泛的是表列数据,它给金融行业带来直接的商业价值。决策树模型非常适合处理表格类型的数据。Tabnet的主体思想是用神经网络来表示树模型,实验证明,Tabnet在处理表列数据的表现已经超过了GBDT[20]。
Tabnet使用序列化的注意力机制来选择在每个决策步骤中要推理的特征,从而学习得到最显著的特征,实现可解释性和更有效的学习。Tabnet神经网络结构如图2所示。

图2 Tabnet结构Fig.2 A Tabnet architecture
由图2可知Tabnet的具体流程:Tabnet给每个步骤传入相同维度特征f∈RB×D,其中,B是批大小,D是特征维度;接着进行Tabnet的编码处理,共有多个步骤的决策,每步决策的输入特征受前一步信息影响;然后输出处理好的特征表征结果和单步预测向量;最后将特征表征结果相加得到全局特征重要性,预测向量多步累加经过全连接层得到最终输出,完成预测。
从结构上看,Tabnet从左到右由多个步骤的子模块组成,每个步骤关注不同层级的特征。单个步骤包含注意力机制变换器、特征变换器及一些辅助的运算。注意力机制变换器的作用是输出特征的掩码,用于衡量每个特征的重要程度,而特征变换器的作用是特征的提取,生成对样本属性更有效的表征。
注意力机制变换器输出一个掩码来进行特征选择,其掩码M[i]计算公式为
M[i]=sparsemax(P[i-1]·hi(a[i-1]))。
(6)
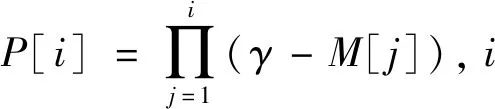
为了达到选择特征掩码的稀疏性,在损失函数上加了正则项Lsparse,其公式为
(7)
式(7)中:Nsteps是步骤数;B是批次的大小;D是特征维度。
特征变换器的作用是特征的提取,包括共享参数层和独立决策层,共享参数层以步骤参数共享,独立决策层参数只由该步骤训练得到。一般是两层参数共享,两层独立决策,构成都是批正则化加ReLU激活函数,融合残差连接。掩码与原始特征内积通过特征变换器后在分割层进行,其公式为
(8)
式(8)中:d[i]作为最终结果输出;a[i]作为下一步注意力机制变换器的输入。
最后是特征属性的输出,它刻画的是特征的全局重要性。模型先对一个步骤的输出向量求和,得到一个标量,这个标量反映了这个步骤对于最终结果的重要性,那么它乘以这个步骤的掩码矩阵就反映了这个步骤中每个特征的重要性,将所有步骤的结果加起来,就得到了特征的全局重要性。
总体上,Tabnet是一种类似于加性模型的神经网络,它采用的是顺序多步的框架,很好地将树模型的可解释性与深度神经网络的表征能力结合在了一起。
2 融合Logistic与Tabnet的网贷违约预测方法
LR是当前智能金融使用最广泛且比较成熟的信用评估方法,具有解释性强、简单易于理解、稳定性高等优势。然而,LR要求解释变量和事件发生的概率是线性关系,因此很可能会出现欠拟合及预测的精确度下降的情况。相反,神经网络预测精确度较高,但是缺乏解释性,不能很好确定各变量之间的关系,并且稳定性较差。
为了将LR与神经网络结合起来,既能展示LR的稳定性和解释性,又能运用神经网络提高精确度,达到最优的预测效果,本文提出了一种融合LR与Tabnet神经网络的算法。
该融合算法采用自顶向下的组合方式,将两个单一的模型连接。具体地,首先,将Tabnet预测出借款人的违约概率值作为一个新特征,同时Tabnet分析特征的重要性,剔除特征重要性为0的特征。其次,将二者结合作为LR模型的输入变量。Tabnet是神经网络模型,其分类效果较好。这样既能保留LR模型的可解释性和稳定性,又能得到Tabnet神经网络模型的高精确度。融合分类方法的过程如下:
1)获取数据集,得到数据集之后,分析数据集特点,对数据进行清洗和加工预处理。
2)采用IV和Pearson方法进行变量筛选,剔除大量冗余及分类相关性较低的特征。本实例经过这个步骤筛选出16个解释变量。
3)数据集划分为训练集与测试集,并构建Tabnet模型。根据网格搜索法寻找最优参数,设置好参数后,将训练数据输入Tabnet进行学习,Tabnet输出的原始预测结果作为新的特征。
4)将Tabnet模型作为进一步特征选择的工具,通过分裂增益特征选择,输出每个特征的重要性值,对前期筛选的16个变量进行特征选择,剔除特征重要性为0的特征,加上Tabnet预测所构造的新特征,得到新的数据集,最后将新的数据样本用于Logistic回归模型进行分类训练,得到最终的预测模型。
5)将测试集数据用于该融合模型预测,根据模型评价指标来分析模型的优劣。
图3为LR与Tabnet模型融合训练过程的示意图。

图3 LR与Tabnet融合模型步骤Fig.3 Model fusion steps of LR and Tabnet
3 实验分析
3.1 实验样本
利用爬虫技术获取人人贷借款人的资料信息,爬取的时间是2010—2019年。共获取满标数据共500 000余条,其中违约数据共4 000余条。随机选取违约样本2 000条。考虑人人贷最长的还款期限为36个月,也就是最晚2017年放贷的样本,要在2019年底才可以观察到借款人是否还清贷款,则违约样本时间范围在2010—2017年。因此,在2010—2017年采用随机采样的方式抽取样本,共获得样本容量为24 000余条的样本集,每个样本的特征维度是41。剔除了一些无用的解释变量,将一些变量进行组合,对离散型变量使用标签进行编码,对连续型变量采用信息价值法和Pearson分析法进行筛选,最后确定入模变量共16个,具体如表1所示。
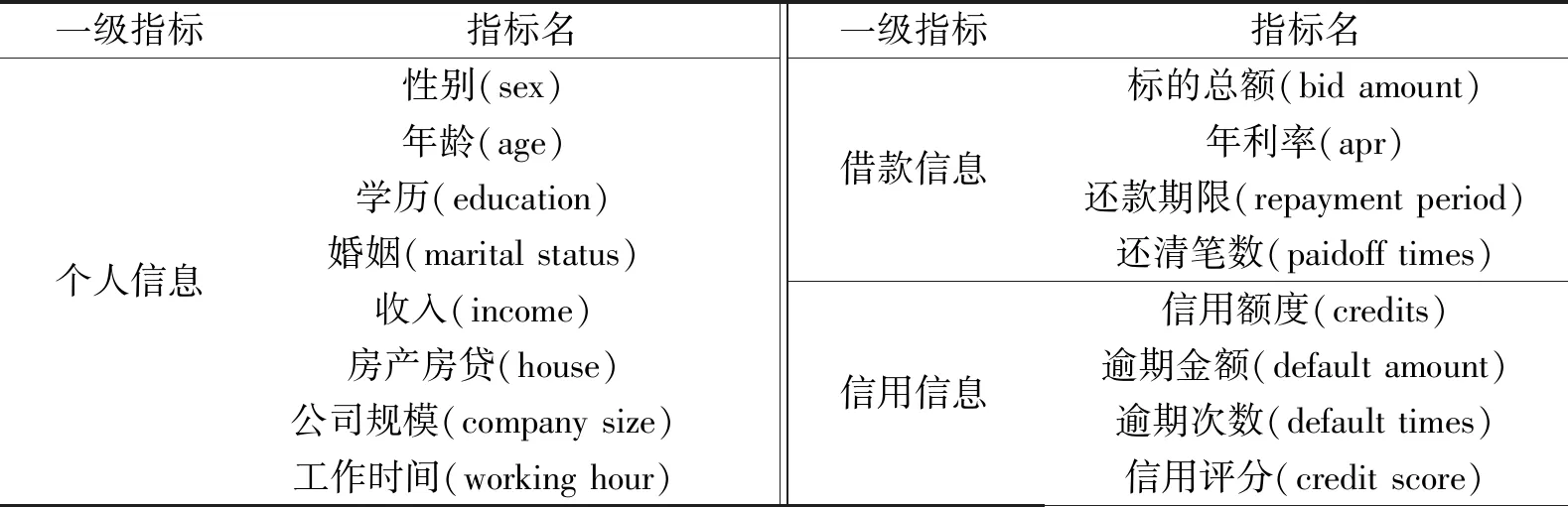
表1 入模变量Table 1 Variables into the model
将数据集按照3∶1划分成训练集和测试集。训练集共18 000条,用作模型的训练;测试集共6 000条,随机划分为3等分,用作模型的效果评估。样本数据划分情况如表2所示。
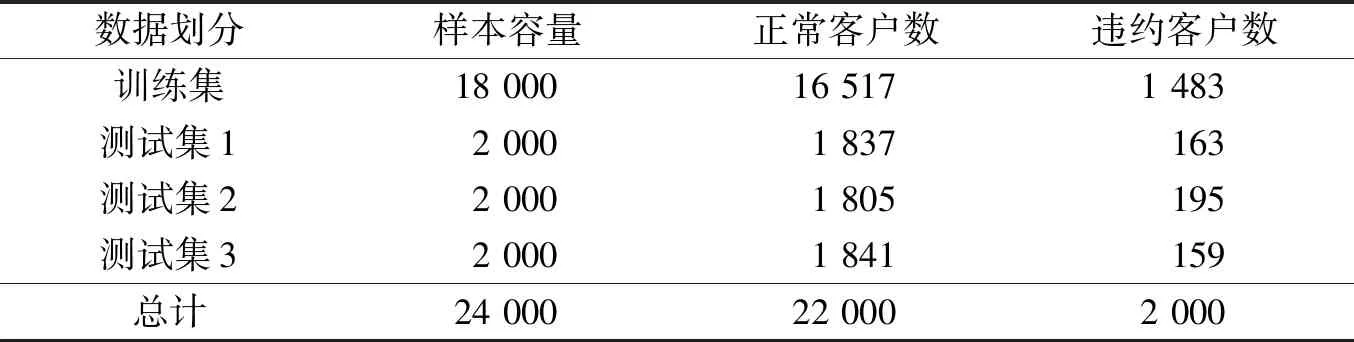
表2 样本集划分情况Table 2 A sample set splitting 单位:个
为了提高收敛速度、模型的稳定性和精确度,需要先对输入数据进行标准化处理,即将数据按照行、列或者其他属性值减去其均值再除以其标准差,所得到的数据都聚集在0附近。
3.2 模型性能评价
本文评估指标为准确率、精确率。根据真实数据标签和模型预测标签组合,将结果分为以下4类:
1)真正例(TP),该网贷样本是违约样本数据且经过模型预测后也是违约样本实例。
2)假正例(FP),该网贷样本是未违约样本数据且经过模型预测后却是违约样本实例。
3)真反例(TN),该网贷样本是未违约样本数据且经过模型预测后也是未违约样本实例。
4)假反例(FN),该网贷样本是违约样本数据且经过模型预测后为未违约样本实例。
3.3 基于融合模型的违约预测评估
本实验在操作系统为Window11、显卡为GTX1650、内存为32 GB的电脑上进行模型搭建调试和训练,数据分析依赖python的pandas库,逻辑回归模型基于scikit-learn实现,Tabnet基于开源框架pytorch实现。
首先对单个Logistic回归和Tabnet模型分别实验,然后对Tabnet-LR模型进行实验,最后以acc和pr作为评价指标,横向比较多个常用的机器学习算法。
3.3.1 LR模型实验
LR作为本实验的预测模型,满足本文研究预测风险的需要。将被解释变量借款状态1或0作为二分类变量,Y=0表示未违约,Y=1表示违约。前面确定了16个指标作为解释变量,使用scikit-learn 中的Logistic Regression建立本实验的Logistic回归模型,通过scikit-learn的网格搜索法得到最优超参数,具体超参数组合如表3所示。

表3 LR超参数值Table 3 LR hyper parameters
设定好超参数后,将训练数据集使用5折交叉验证的方法分成5等分进行实验,得到最优的Logistic回归分类模型。
3.3.2 Tabnet模型实验
Tabnet模型是基于pytorch的Tabnet网络,TabnetClassifier是Tabnet用于分类的函数库,该网络适用于二分类。使用scikit-learn的网格搜索最优参数,各超参数的值是:max_epochs为50,即最大迭代次数是50;patience为10,即模型迭代10次,loss不降低,则提前停止训练;batch_size设为1 024;virtual_batch_size设为128;num_workers设为0;weights设1;drop_last设为False;其他为默认超参数。设定好超参数后,将训练数据集使用5折交叉验证的方法分成5等分进行实验,训练Tabnet模型。结合Tabnet模型类似于树模型选择最优特征划分的原理,输出特征重要性,具体如图4所示。
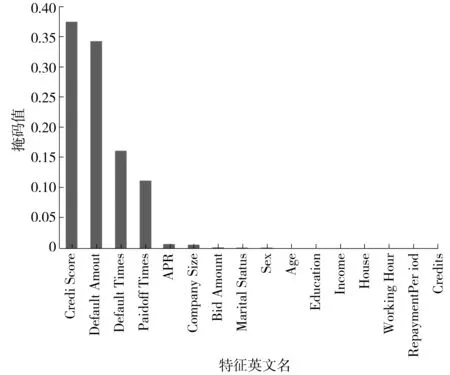
图4 特征重要性Fig.4 Importances of features
3.3.3 LR-Tabnet融合模型实验
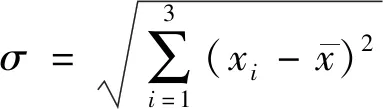

表4 LR回归、Tabnet模型和LR-Tabnet模型评价结果Table 4 Evaluation results of LR regression,Tabnet model and Tablet-LR model
由表4可见,测试集1和测试集3中组合模型的预测准确率均高于其他单个模型,组合模型的预测精确率在所有测试集上均优于其他模型的。组合模型的精确度和准确度明显优于LR模型,说明组合模型极大改善了LR模型的预测能力。在准确率和精确率上,组合模型的标准差均低于其他模型的,说明组合模型有很好的稳定性。
3.4 分类性能比较
经典的机器学习的分类算法有KNN、SVM、朴素贝叶斯和决策树。本文采用acc(准确度)和pr(精确度)来评价预测算法的能力。每个模型均采用网格搜索法设定最优的超参数。实验均采用5折交叉验证的方式选取最优模型。各分类器的评估结果如表5所示。
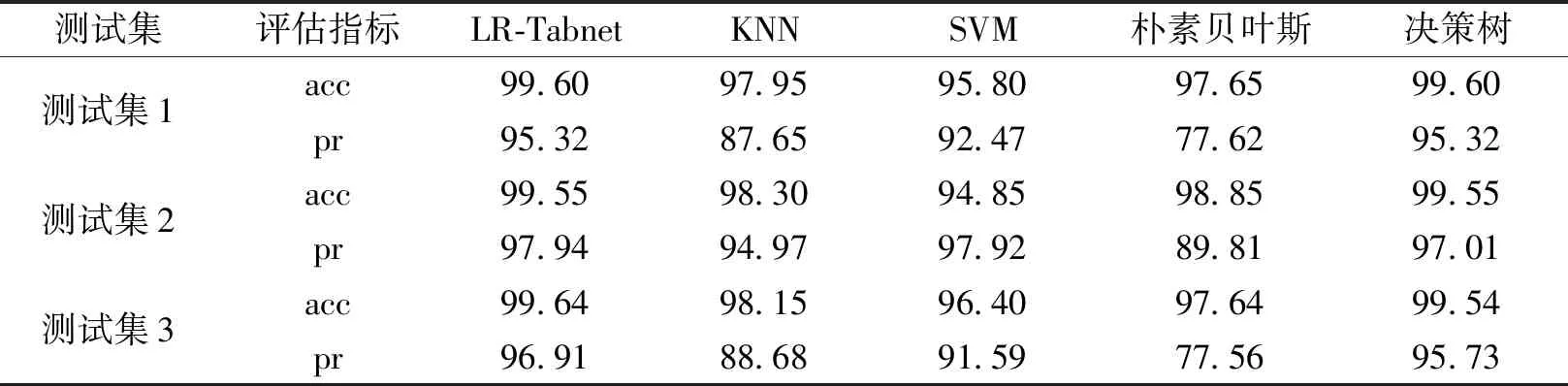
表5 各算法的分类性能比较Table 5 Classification performance of algorithms compared 单位:%
由表5可见,LR-Tabnet模型在3个测试集上要优于其他算法,其次是决策树分类。特别是在测试集1和测试集3上,LR-Tabnet模型的精确率比朴素贝叶斯分类器的提升了近17%,说明该融合算法是有效的。
3.5 融合模型的可解释性
在实际场景中,不仅要满足模型的效果,通常还会分析特征对模型结果的影响,这对解决现实问题至关重要。使用python的statsmodels包查看LR中的重要参数。R-squread是自变量与因变量直接关联强度的检验参数,得到参数R-squared为0.95,接近于1,可知变量之间的关联性很强,模型的拟合优度好。
coef是每个变量的估计系数,P值表示变量在逻辑回归中起到的作用。一般认为,P值小于0.05的自变量是显著的,统计表明,该变量会影响被解释变量为1的概率(即借款人违约的概率)。[0.025,0.975]是回归系数的置信区间的下限、上限,某个回归系数的置信区间以 95%的置信度包含该回归系数。
在融合模型中,Tabnet预测出借款人的违约概率值作为一个新特征,同时Tabnet分析特征重要性,剔除特征重要性为0,最后输入Logistic回归模型中训练的7个变量,观察这7个变量P值、std err、coef值等,结果如表6所示。
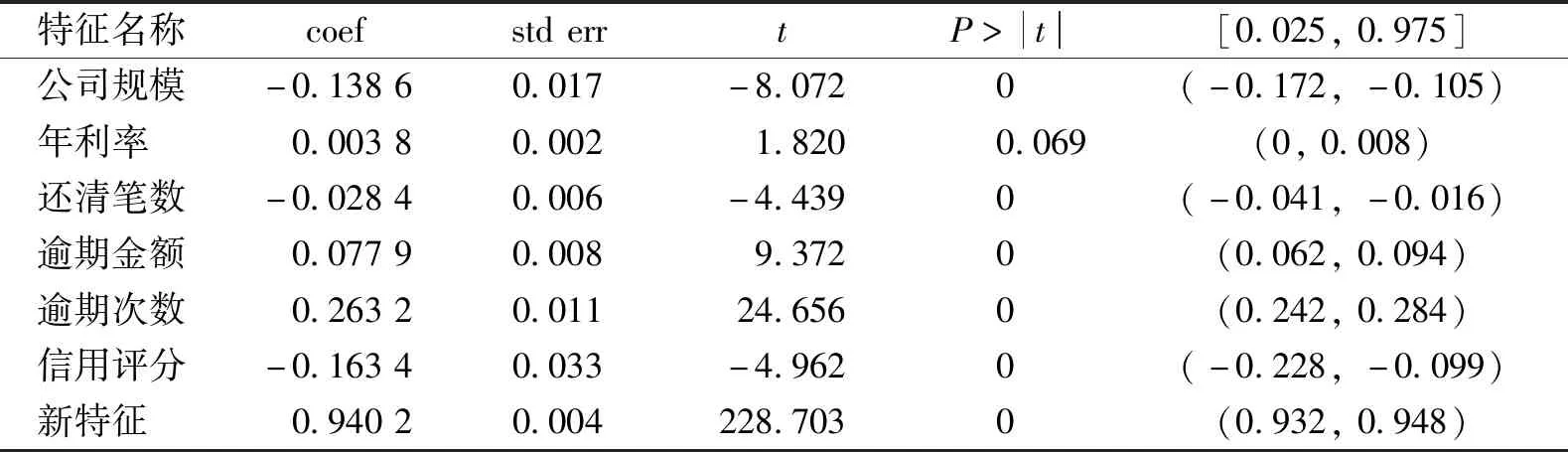
表6 变量特征权重表Table 6 Weights of variable features
由此得到各变量与最终借款状态的关系:公司规模系数为负,说明公司规模与借款人违约呈负相关,即公司规模越大,违约概率越低;年利率和违约概率呈正相关,表明随着年利率的增加,借款人负担不起这么高的年利率,从而导致逾期;借款人还清的笔数越多,说明借款人的还款意愿越高,因此逾期的概率越低;逾期金额和逾期次数均与违约呈正相关,说明逾期的金额和逾期次数增加,借款人就会更难以还上借款;信用评分反映的是借款人的综合信用,评分越高的借款人发生违约的概率越低。
4 结论
本文提出一种融合Logistic回归与Tabnet模型的P2P网贷违约预测方法,在对采集到的人人贷数据进行预处理后,将处理得到的数据运用到LR-Tabnet模型中。针对传统的单个机器学习识别分类问题存在的局限性,本文结合神经网络在处理大量样本和高维度的人人贷数据仍具有很好学习能力的优势,通过模型组合的方式,对比单个模型的识别准确率和精确率,识别率得到了较大提升。同时,不仅保留了LR的可解释性和稳定性,还提高了LR的识别率。融合模型在3个测试集上的平均识别准确率和精确率分别是99.60%、96.72%,相比于其他2个单个模型,平均识别准确率和精确率分别提升了0.88%、4.5%和0.02%、1.25%。
本文选取的人人贷平台虽在P2P平台中排名靠前,但也不能代表整个网贷平台,每个网贷平台的借款人维度有所不同,需要针对具体问题具体分析。再加上没有考虑外部经济因素和环境因素比如2020年初的新冠病毒侵袭的影响,本研究还存在一定的局限性,今后将采用更灵活的特征筛选和模型构建的方式作进一步的研究。
猜你喜欢
法制博览(2019年29期)2019-12-13
电子制作(2019年19期)2019-11-23
中国外汇(2019年10期)2019-08-27
上海财经大学学报(2019年3期)2019-06-04
电子制作(2019年24期)2019-02-23
瞭望东方周刊(2018年4期)2018-02-01
商周刊(2017年17期)2017-09-08
商周刊(2017年17期)2017-09-08
新民周刊(2016年49期)2016-12-26
重型机械(2016年1期)2016-03-01
