
基于深度强化学习的无人机通信抗干扰算法
2022-11-01 11:43张惠婷刘敏提丁元明
兵器装备工程学报 2022年10期
张惠婷,张 然,2,刘敏提,丁元明
(1.辽宁省通信网络与信息处理重点实验室, 辽宁 大连 116622; 2.大连大学信息工程学院, 辽宁 大连 116622; 3.西安电子科技大学雷达信号处理国家实验室, 西安 710071)
1 引言
无人机作战是未来战场上至关重要的一部分,但是在通信环境面临智能性干扰的情况下,要确保信息安全可靠的进行传输就成为一项挑战,因此无人机通信系统抗干扰研究至关重要。
为了有效对抗智能干扰,提高无人机系统通信质量,目前研究热点方向为无人机认知抗干扰。认知抗干扰目前主要通过智能决策算法对抗智能干扰,智能决策大致有两类:一类基于功率域抗干扰角度,智能体的发射功率可以根据干扰方发射功率进行调整来应对攻击。文献[4-6]在干扰功率不大的情况下,基于博弈理论,根据博弈双方的竞争关系,建立认知抗干扰网络模型,求出博弈均衡,获得用户最佳发射功率。另一类是基于频域抗干扰的角度,利用强化学习选择安全信道,规避干扰信道。文献[8]将信道选择问题建模为多臂赌博机模型(MAB),选择最小的臂对应的信道进行通信,但是不满足信道非独立的实际情况,文件[9]在MAB理论的基础上提出碰撞规避上届置信算法(UCB)的信道选择改进,在电台频谱接入问题中有效降低了碰撞概率和悔恨值,但是前期训练碰撞需要耗时。文献[10]基于协作Q学习(Q learning,QL)进行信道选择,虽然提高了数据传输安全容量,但算法收敛速度较慢。文献[11]利用深度Q网络(deep Q network,DQN)进行安全信道选择,累计奖励值高于QL算法,但是DQN由于Q值估计过高导致收敛速度减慢、估值失真。文献[12]在集中式训练环境下通过竞争性深度Q网络算法和优先经验回放技术以提高信道选择算法的效率,但信道数量较多时碰撞效率提升较大。在信道数量较大的情况下,文献[13-14]基于演员-评论员(actor-critic,AC)算法选择安全信道,但该算法的Actor与Critic网络实时更新数据,导致2个网络依赖性较强,算法稳定性较低。
针对智能性干扰攻击灵活性较差的问题,多域联合抗干扰方式被提出。文献[16]考虑功率域和频域,首先基于Stackelberg博弈从功率域判断受干扰情况,再分别利用频域进行MAB算法进行信道选择,文献[17]同样将受干扰分为是轻度、中度以及严重程度,中度干扰从功率域博弈论角度出发,轻度干扰从优化AC算法的频域角度进行信道选择避免干扰。但是以上算法从频域及功率域角度考虑,在干扰严重情况下,功率域抗干扰效果不佳,占用大量的频谱资源,并且用户传输时长固定,无法满足无人机高动态运行下对传输时间灵活性的要求。
基于以上抗干扰不同角度的分析,本文中将频域和时域结合,提出一种基于动态深度双Q学习(dynamic-deep double Q learning,D-DDQN)的无人机时频域联合认知抗干扰(time-frequency domain joint cognitive anti-jamming,TFDJ-AJ)算法。该方法首先利用能量检测法得到当前回合的干扰判别信息,然后优化DDQN的贪婪策略,将实际传输奖励反馈给贪婪因子,进行动态DDQN决策,最后把信道选择和传输持续时间决策问题转换为序贯决策问题,通过智能决策进行最佳传输,实现时频域联合抗干扰,有效提高无人机系统通信安全容量。
2 无人机通信模型
2.1 系统模型
无人机通信抗干扰模型如图1所示。考虑由一个无人机、一个接收机和一个干扰机组成的通信系统。无人机向接收机发送数据,干扰机释放干扰信号,进行无人机通信破坏。系统模型中共有(>1)个信道,定义={1,2,…,}为信道集,在通信过程中,用户传输持续时间是可变的。

图1 通信抗干扰模型示意图Fig.1 Communication model
2.2 干扰及检测模型
无人机通信系统的干扰端用表示,干扰端通过不定期调整干扰方式来干扰和破坏用户通信网络。代表干扰频率范围,代表无人机传输频率范围。为了简化分析,设置=,并用代表用户传输带宽,则可以计算出无人机信道集的数量,如式(1)所示。
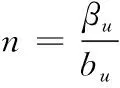
(1)
基于能量检测法建立一个干扰检测模型,如式(2)所示。每个信道对应频率设置一个带通滤波器,对不同频率信号进行滤波,得到检测模型H,计算每个频率上的信号功率。
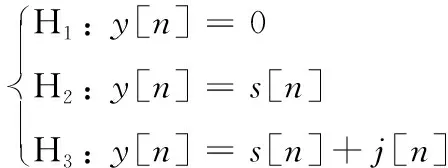
(2)
其中:[]表示当前信号;[]表示通信信号;[]表示干扰信号。
通过宽带频谱感知中的能量检测法来检测干扰信息,()代表每个频率信号能量,代表门限值,判别干扰信号能量,如式(3)所示。若()高于则认为当前存在干扰,属于H,否则属于H或H,然后将每个频率是否存在干扰信号的判别信息输入至D-DDQN智能决策模型。

(3)
2.3 信道模型
检测到信道中的干扰后,就可以在信道内避开干扰进行通信。在通信过程中,接收端根据能量检测感知干扰信道信息对安全信道和传输持续时间进行决策,然后将上一步完成的决策信息以确认字符(acknowledge character,ACK)的形式送回发射端,表示确认接收到正确决策成功通信。最后,无人机发射端根据新的传输策略在下一个时隙进行通信。
将接收端信噪比定义如式(4)所示。
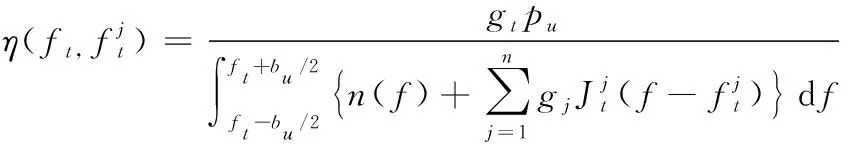
(4)
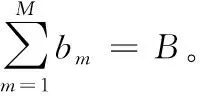
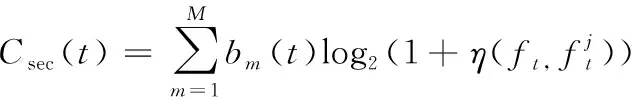
(5)
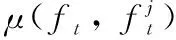
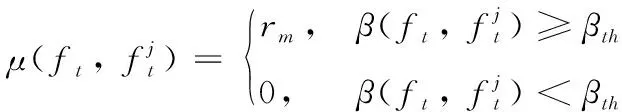
(6)
用户更换安全通道的开销为:
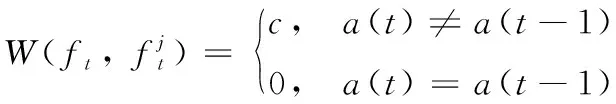
(7)
式中:表示信道切换系数;()表示用户在时刻采取的动作。无人机优化目标是最大化累计效用值来选择抗干扰策略如下式所示:
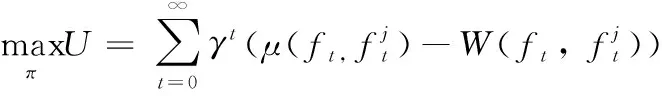
(8)
式中,代表折扣因子,且∈(0,1)。
假设传输信道=5,传输时间长度等级=4,状态和动作时频传输如图2所示。横轴代表频率,竖轴代表时隙。
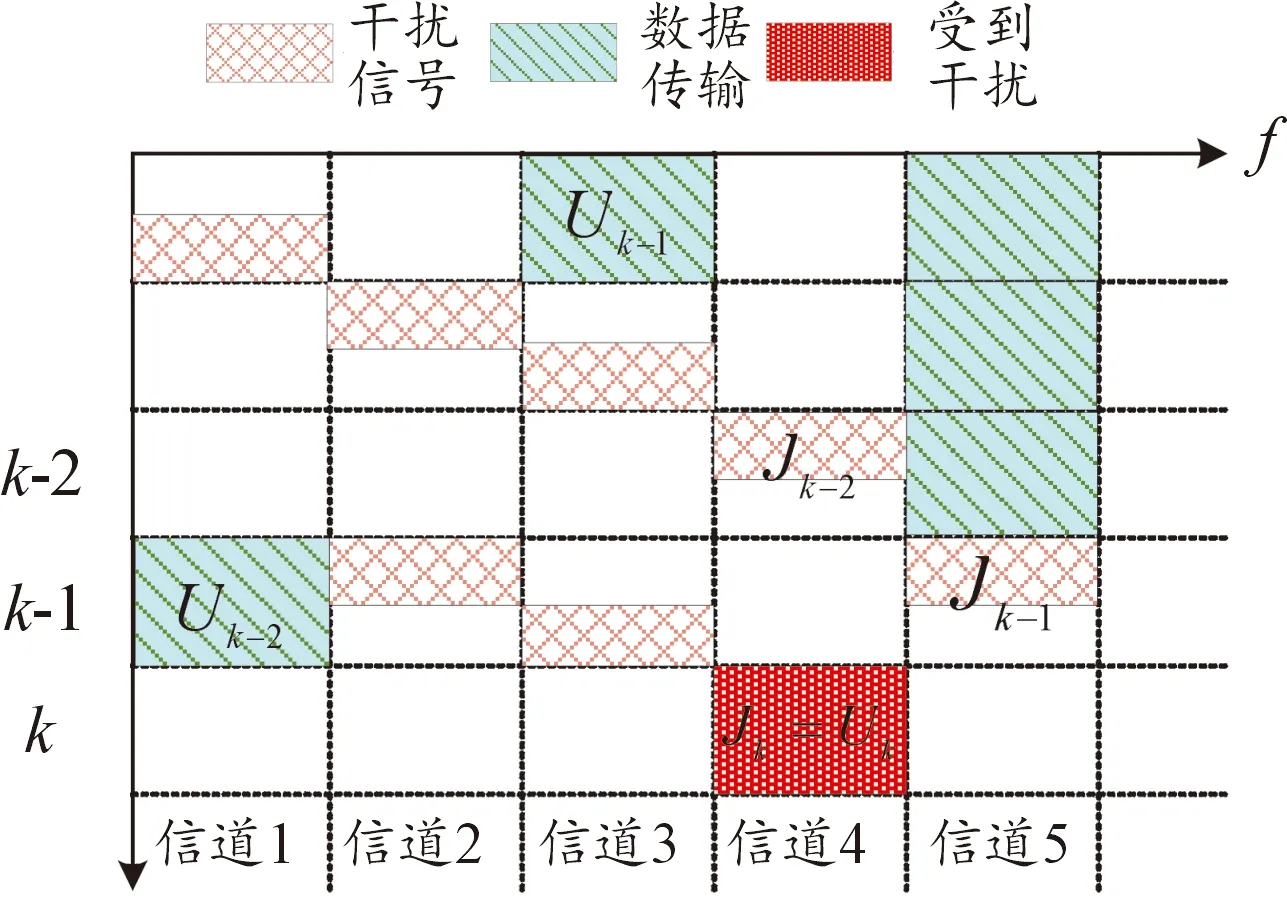
图2 干扰机与用户时频传输示意图Fig.2 Schematic diagram of time-frequency transmission between jammer and user
在第-1个时隙信道状态为[01100]。因为信道1足够安全,所以从-2个时隙进入-1个时隙时可从信道5跳转到信道1,可以持续传输较长时间,由于信道1在时隙依然没有干扰,那么传输可以在2个时隙都保持成功,此时奖励最大;如果-2跳转到-1时选择信道4,那么持续传输时间等级依然保持最大,但在传输之后若不立即进行信道跳转就会受到干扰,即使下个时隙进行信道跳转也会消耗转换信道的能量。
2.4 传输时隙模型
现有的通信传输时隙模型全部都是固定传输时长,但在无人机通信过程中,若传输时间过长则信号会被干扰,若传输时间太短则系统吞吐量性能较差。针对此问题,本文中建立用户数传输时长可改变的时隙模型。
用户有个传输持续时间可供选择且传输时间集为={,,…,}。每个时隙可以根据信道状态选择传输等级,传输时隙结构如图3所示。

图3 数据传输时隙结构示意图Fig.3 Schematic diagram of data transmission process
代表干扰时长,代表无人机的传输时长,代表ACK传输的时间长度,表示进行能量检测的时间长度。在通信开始时隙中,用户根据获取的原始频谱信息随机选择传输信道和传输时长,接收端开始数据接收,接收完成后计算该操作的奖励值。在下一个时间,用户接收端进行能量检测,得到干扰信道信息。最后,用户根据该信息进行D-DDQN学习,确定下一个时隙要选择的传输信道和传输时长,并更新参数。在更新结束之后,接收端通过在时间内发送ACK信号将判决信息反馈给无人机发射端。
3 多域联合认知抗干扰算法
3.1 基于ε动态更新D-DDQN优化算法
3.1.1 强化学习框架
无人机抗干扰过程中,无法得知下一步状态具体有哪几步,状态转移概率未知,因此通常采用无监督学习的QL算法求解,但状态空间和动作空间较大时,搜索值的时间增加,收敛速度降低,很难对所有动作进行探索。DQN算法引入神经网络代替QL中的Q值表格,解决了状态、动作空间不足的问题。式(9)表示值函数优化目标:
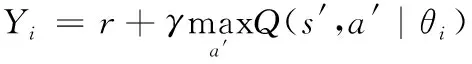
(9)
式(9)每次都要选择预测值最大的下一步动作,导致值估计过高。因此式(10)采用DDQN算法,更改DQN的网络参数设置,改善标签过估计。
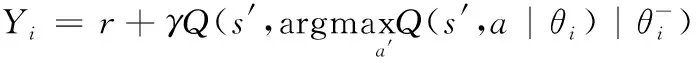
(10)
3.1.2 动态-greedy更新的D-DDQN算法
传统DDQN一般将-greedy策略作为策略进行训练更新,如式(11)所示。在该策略下,无人机随机选择动作的概率表示为,选择值最大所对应动作的概率表示为1-。
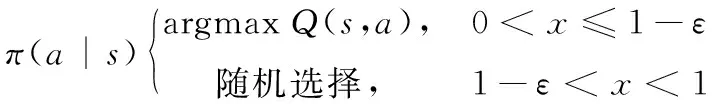
(11)
然而,取值固定就表示算法随机性在所有回合中都相等。但是在实际过程中,起始状态所需的随机性和收敛状态是不一样的,固定取值的情况下,算法只能收敛到局部最优,并且不能维持稳定的收敛状态。
算法基于DDQN提出动态策略,根据奖励值与迭代次数动态调整值,得到D-DDQN算法,如式(12)所示。动态调整过程为:选择最大值所对应的动作时,增加选择对应动作的概率值;选择其他动作时,减少选择对应动作的概率值。首先初始化为1,在算法的每次迭代后,都相应动态调整1次,直到减少到0。若前一回合受到干扰,那么≤0,减少值,降低策略的随机性,加快算法的收敛速度;若前一回合安全传输,那么≥0,则值不变,原有的随机性继续保持。改进后的策略更新过程如式(13)所示。其中表示在0~1内随机生成数。
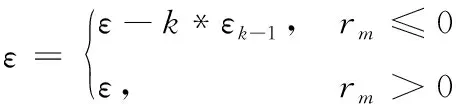
(12)

(13)
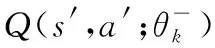
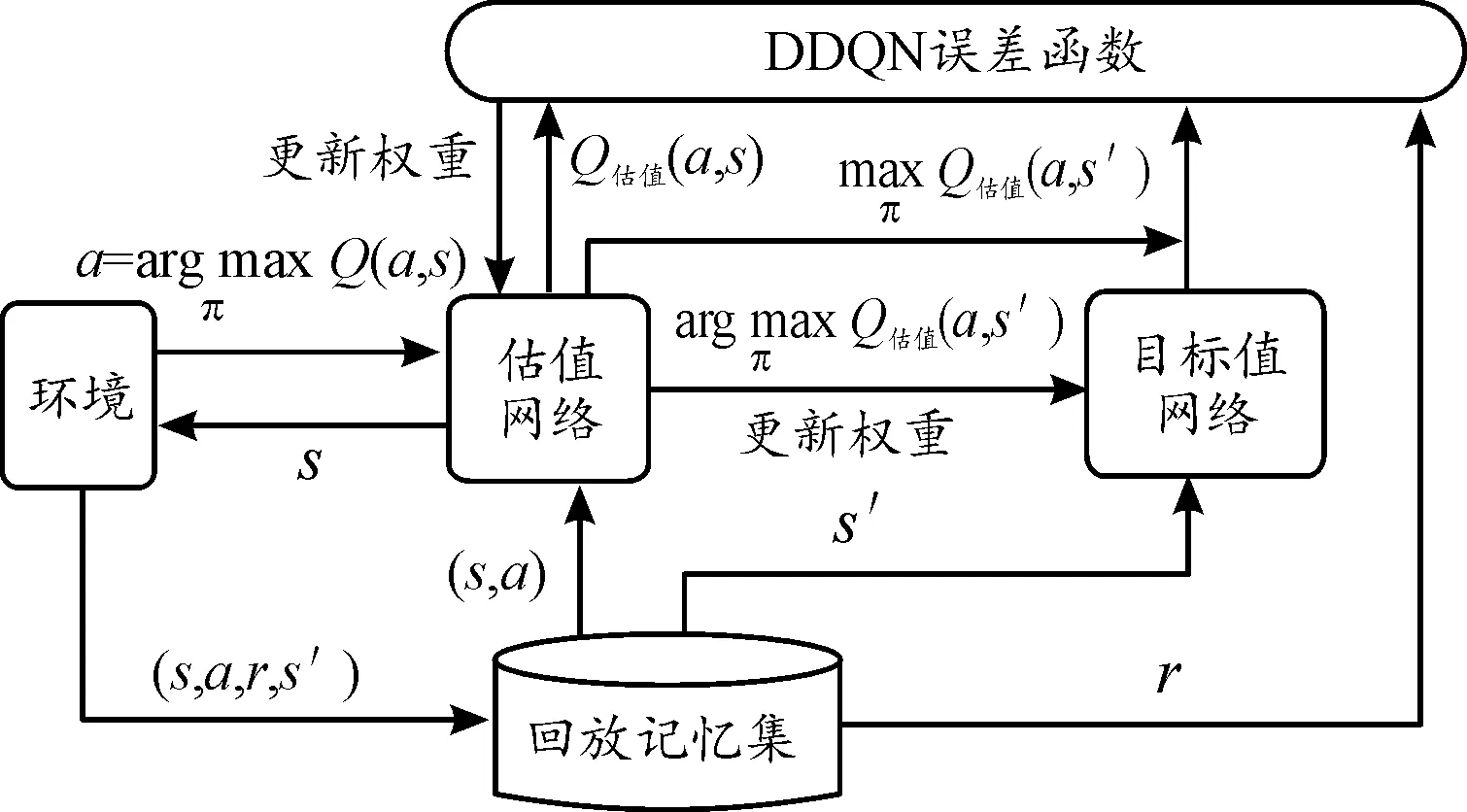
图4 智能决策框图Fig.4 Intelligent decision framework
定义误差函数(),如式(14)所示。采用梯度下降法对估值神经网络进行更新。

(14)
3.2 基于D-DDQN的TFDJ-AJ算法
本文中将时频域选择同D-DDQN算法结合,将算法所需基本元素定义如下:
1) 状态空间
所有通道的当前状态定义为,为1表示信道在当前时刻与干扰信号产生冲突,为0表示没有与干扰信号产生冲突,信道共有个,则状态集大小则为2。
2) 动作空间
将发射端在第个时隙的状态下完成的动作选择表示为=(,),其中是第个时隙的传输信道,是第个时隙的传输持续时间等级且满足={1,2,…,},因此,动作空间大小定义为×。
表示无人机选择信道的所有策略,根据当前状态和即时奖励进行动作选择。信道索引如下式所示:
={,,,…,},()∈
(15)
3) 状态转移概率
由于强化学习中相邻状态之间存在相关性,将用户在状态条件下,执行动作转移到新状态+1的转移概率定义为:
={(+1|,)},+1,∈×
(16)
4) 奖励函数
即时奖励函数=(,,)代表第个时隙的状态中执行动作的奖励,用式(8)来表示。
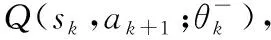
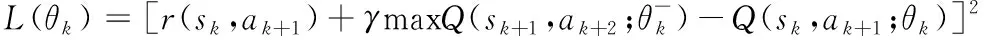
(17)
如式(18)和式(19)所示,通过梯度下降法更新,同时每经过轮就同步回合目标神经网络与估值神经网络,由于不用实时更新目标价值,因此可以减少选取目标价值的相关性。
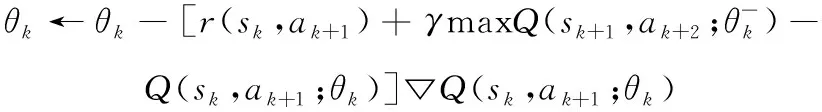
(18)
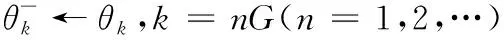
(19)
综上所述,提出的基于D-DDQN时频域联合的认知抗干扰算法(TFDJ-AJ)实现过程如下:
输入:干扰判别样式信息(),经验池
输出:最优策略估计,效用值函数
步骤1 建立估值神经网络和目标神经网络,经验池,设置总回合数;
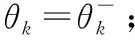
步骤3 随机选择通信频率和传输时长;
步骤4≤时,重复执行步骤5;
步骤5 获得信道状态集合;
步骤6 按照式(13)计算更新值;
步骤7 根据D-DDQN算法选择下一回合通信频率和通信时长+1;
步骤8 根据所得的奖励(,+1),决策下一回合的信道状态集合+1;
步骤9 将=(,+1,(,+1,),+1)存入经验池中;
步骤10 从中随机选取经验样本个,代入到式(19)更新;
步骤12>时,程序结束。
算法流程如图5所示。
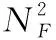
((+(-1)+))
(20)
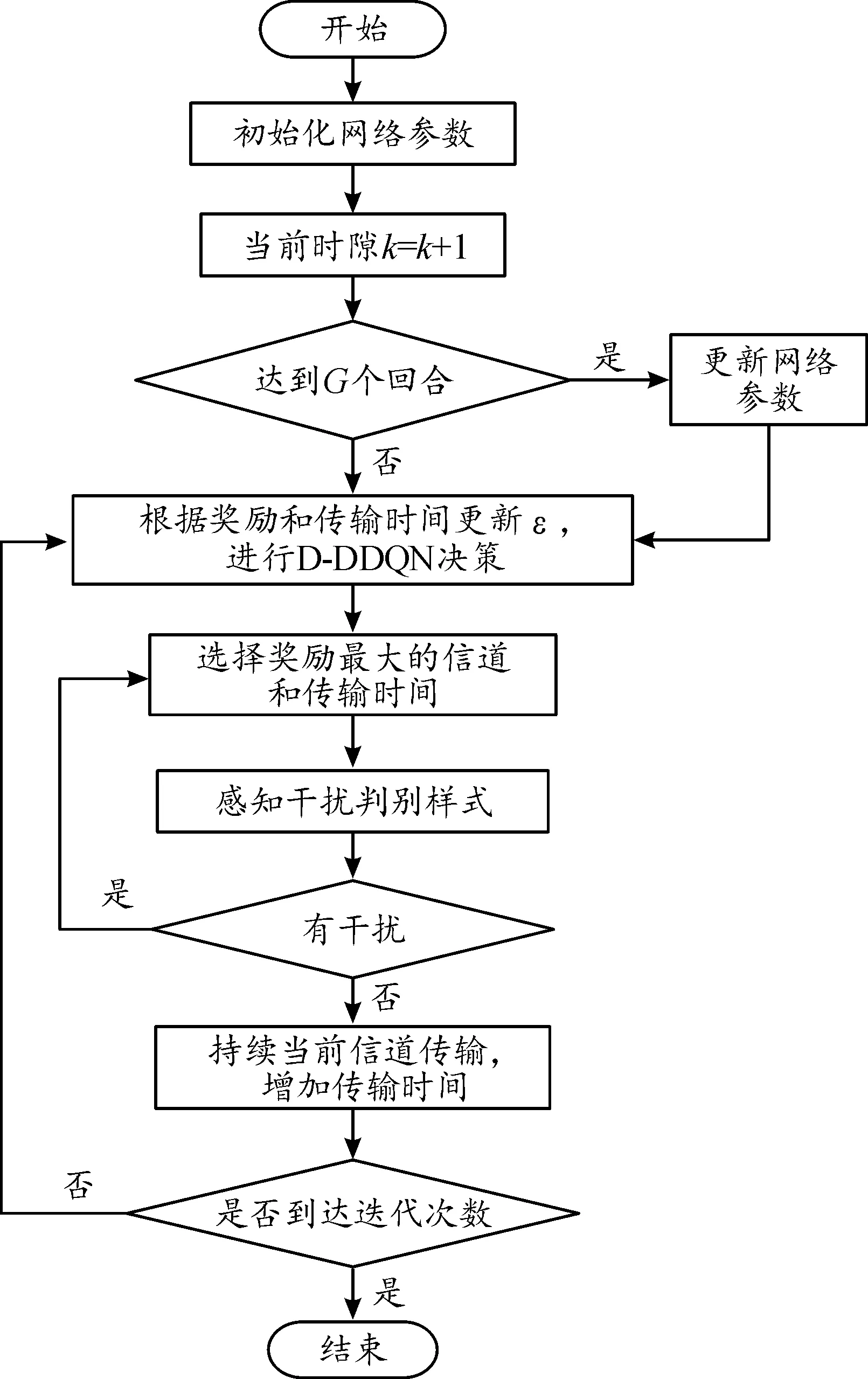
图5 基于D-DDQN的TFDJ-AJ算法流程框图Fig.5 Flow chart of TFDJ-AJ algorithm based on D-DDQN
4 实验仿真与分析
为验证所提算法有效性,对系统获得效用值、通信安全容量、决策成功率、状态均方误差指标进行仿真,其中,系统获得效用值以及通信安全容量分别由式(8)和式(5)计算所得。仿真环境采用Pytorch 1.2.0深度学习框架与Matlab 2018a仿真平台。模型参数设置如表1所示。
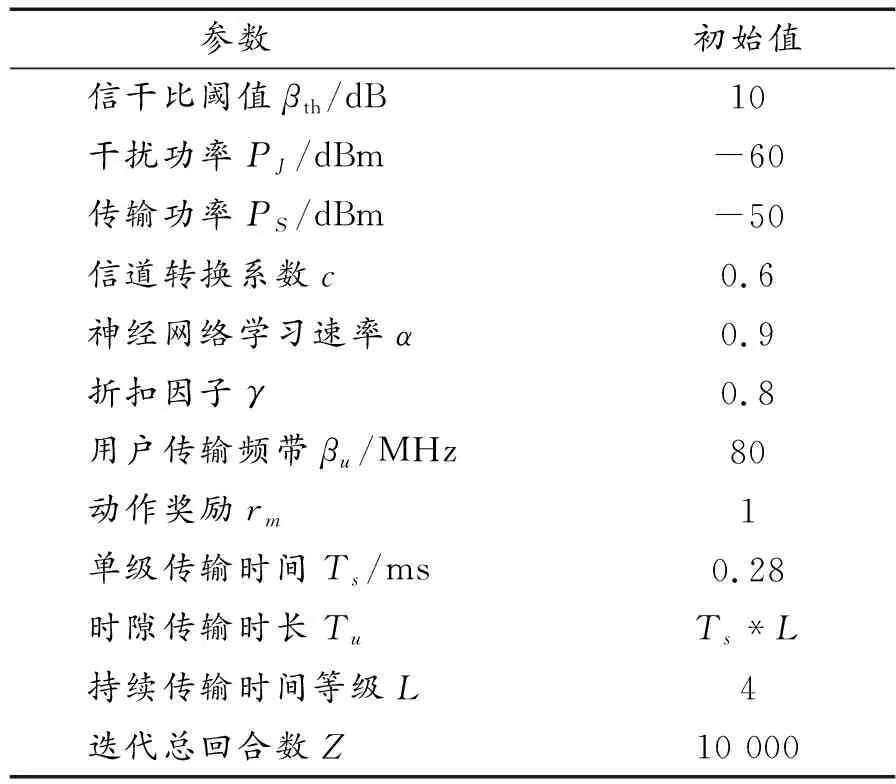
表1 模型参数Table 1 Model parameter settings
经验池容量大小=10 000,小批量经验样本=32。设定传输带宽为5 MHz,则信道个数=16。设定干扰模式有4种,一是扫频干扰,每个传输时隙扫频带宽为500 kHz;二是梳状谱干扰,每个传输时隙选择8个干扰谱,每个干扰谱带宽为1 MHz;三是左右扫频干扰,每个频带上的干扰带宽为250 kHz;四是智能型干扰,为以上3种干扰每隔20个传输时隙随机切换一种。
图6表示不同传输时间下智能决策获得的效用值。由图6可知,效用值根据不同的时间设定变化较大,因为持续传输时间较长会增加系统受干扰的可能,持续传输时间较短会加剧传输能量的消耗,实际应用中干扰机随机变化干扰策略,很难确定一个最佳持续传输时间。同样在D-DDQN算法架构下,持续传输时间的不同,算法到达效用值限值的收敛速度是大致相同的,但TFDJ-AJ算法由于自适应的选择持续传输时长,避免了频繁切换信道造成的能量损失,效用值表现最佳。
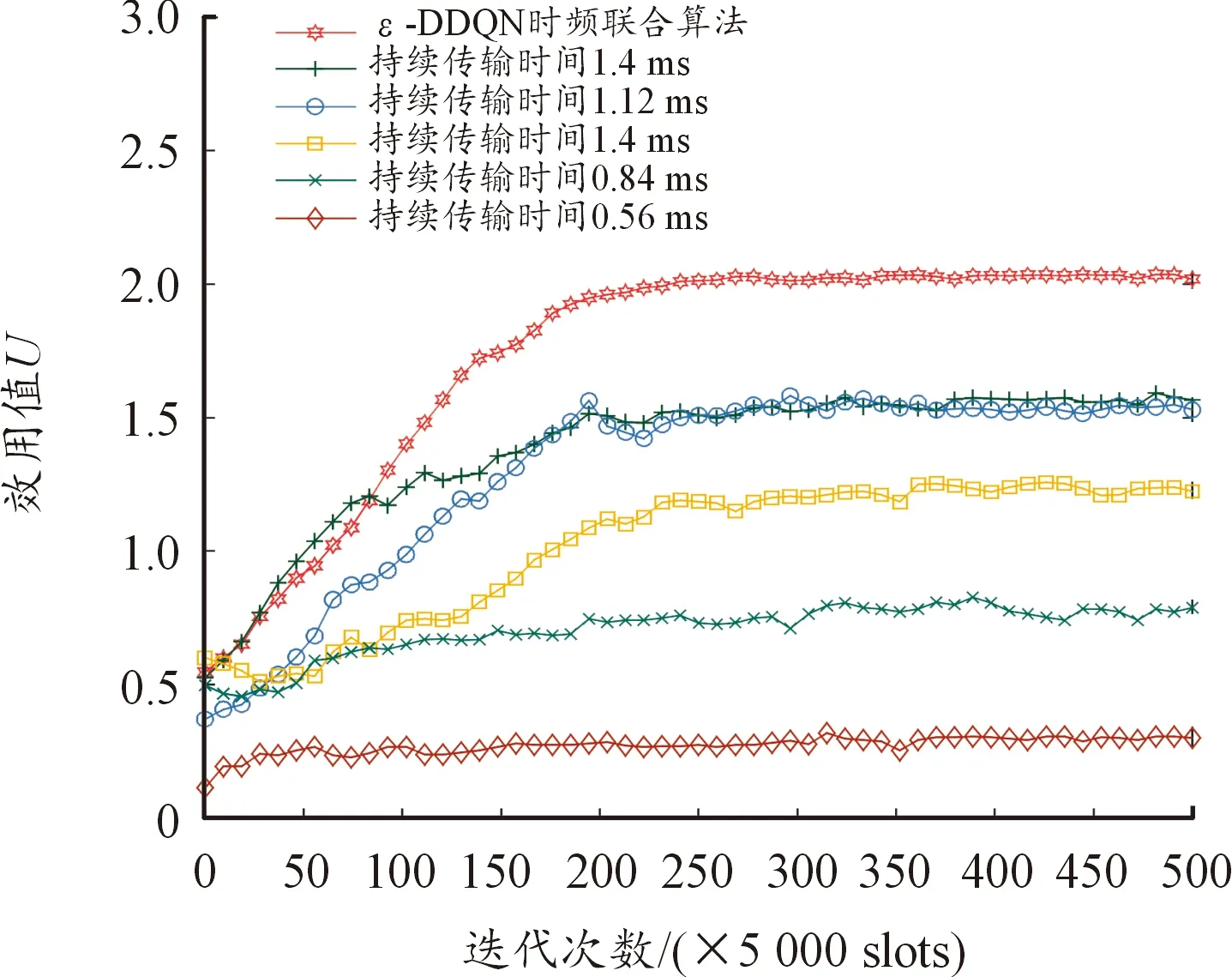
图6 不同时间传输策略下效用值曲线Fig.6 Comparison of effective values under different time transmission strategies
图7表示在时频联合基础下4种决策算法的通信安全容量。由图7可知,提出的TFDJ-AJ算法要优于DQN-AJ与AC-AJ以及QL-AJ算法。TFDJ-AJ算法采用DDQN的架构,目标值神经网络和估计值神经网络分别更新,与DQN-AJ算法和未使用网络的QL-AJ算法相比,其算法收敛速度有明显的提升,通信安全容量提高;同AC-AJ算法相比,虽然AC-AJ算法可以同时实现值函数的估计和动作的选择,但是对于Actor和Critic网络之间的依赖性太强,收敛速度尽管有所提升,但网络稳定性较差。TFDJ-AJ算法利用动态策略将原本的贪婪策略进行改进,增强了全局寻优的能力,得到的数据可靠性更高,通信安全容量较AC-AJ算法提高了15%左右。

(21)
式中,||为信道系统状态的个数。
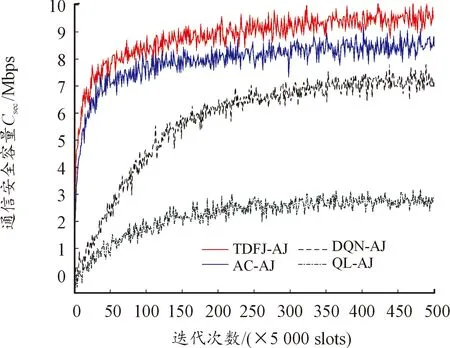
图7 不同算法的通信安全容量曲线Fig.7 Comparison of communication security capacity of different algorithms
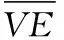
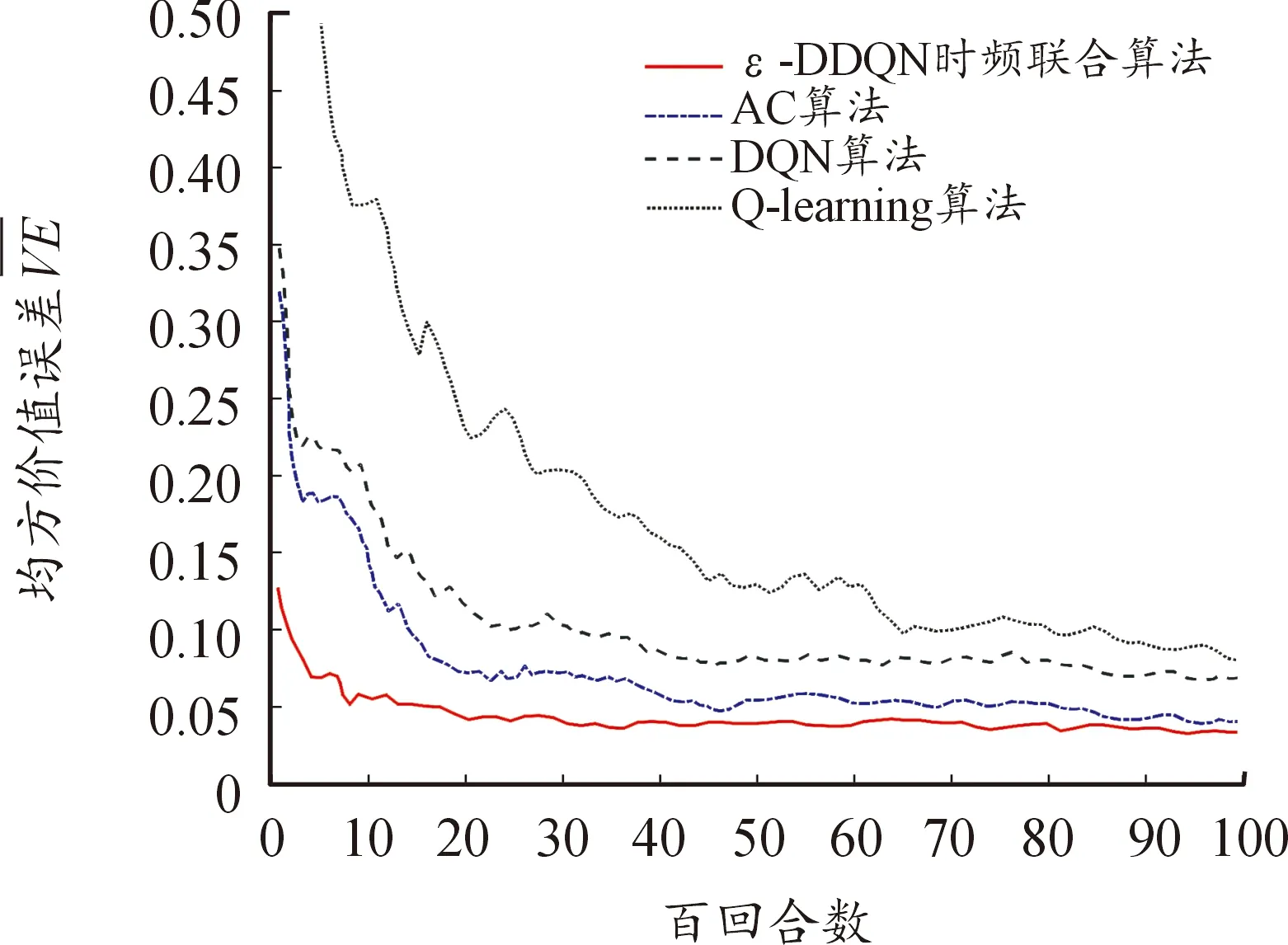
图8 状态价值均方误差曲线Fig.8 State value mean square error curve
为了验证所提算法抗干扰后的通信传输性能,定义决策成功率,如式(22)所示。
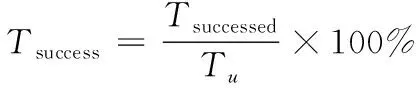
(22)
式中,为成功传输的总时长。
图9表示4种决策算法下的决策成功率。由图9可知,在前2 000回合左右,D-DDQN算法同AC算法相比,平均决策成功率相差不大,这是因为AC-AJ算法不需要经验池回放数据,更快决定抗干扰策略,但是由于状态不稳定,所以波动较大,决策成功率相对较低。而基于D-DDQN的TFDJ-AJ算法在2 500回合之后逐渐收敛至95%以上,这说明D-DDQN算法能够一定程度避免局部最优,达到较好的抗干扰性能。
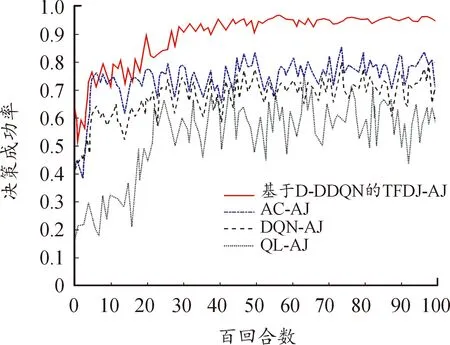
图9 基于不同智能决策算法的决策成功率曲线Fig.9 Comparison of decision success rate based on different intelligent decision algorithms
图10表示基于不同贪婪策略更新的决策算法在前 10 000回合下决策成功率。由图10可知,在不同的贪婪因子设定的情况下,在前2 000回合左右,基于D-DDQN的TFDJ-AJ算法低于利用固定值进行策略更新的决策成功率,这是因为算法动态调整值,前期具有较强的随机性,成功率相对较低,但是收敛速度加快。在固定值的决策下,随着值逐渐增大,收敛后的平均决策成功率逐渐降低,而在3 000回合之后,利用动态策略改进的D-DDQN算法性能提升至95%以上,这再次证明了D-DDQN策略较好的性能。
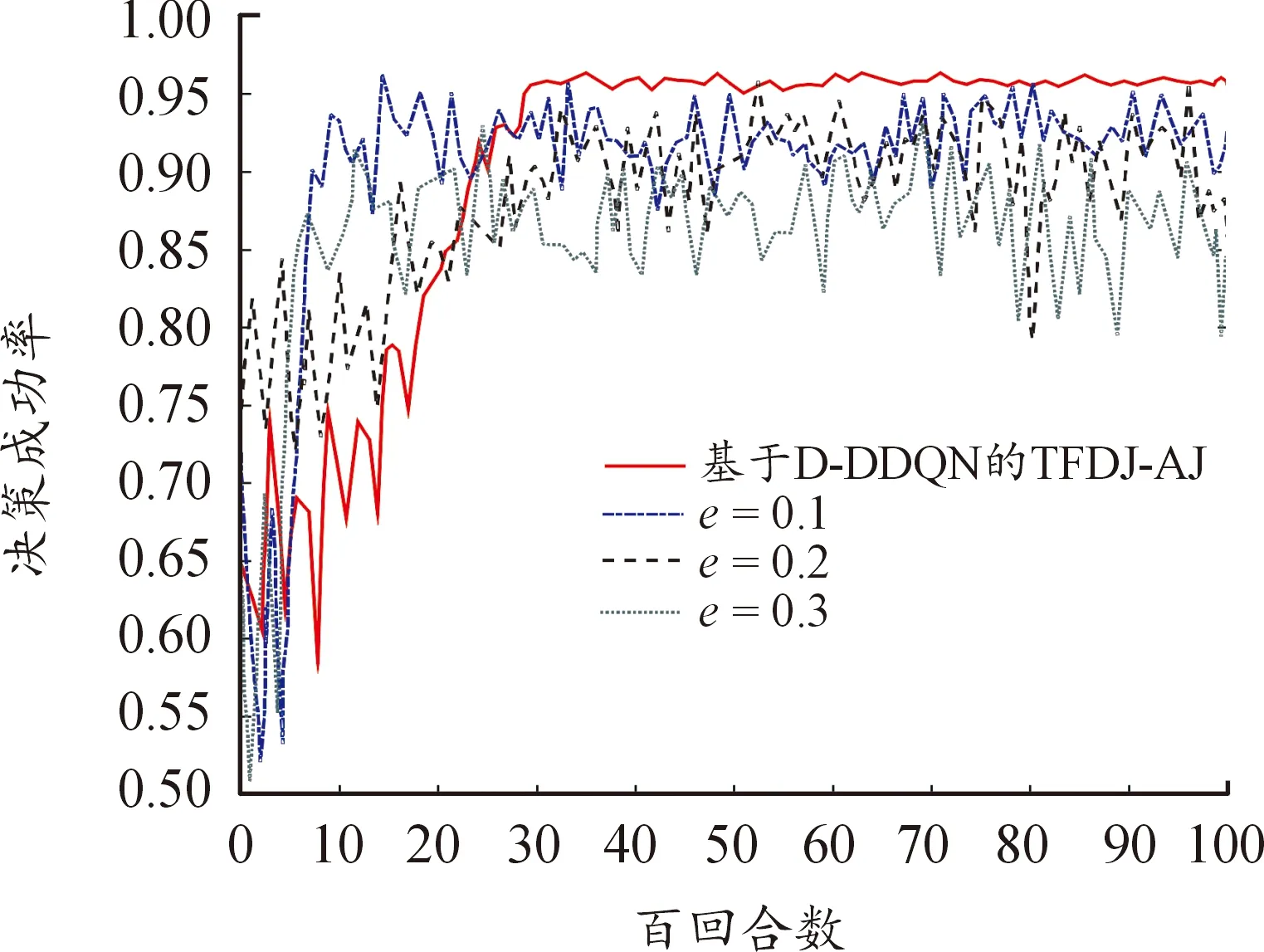
图10 基于不同ε策略的决策成功率曲线Fig.10 Based on different ε comparison of decision success rate of strategies
为了验证算法的泛化性,评估算法在更复杂场景下的性能,仿真改变表1中的通信场景,设定无人机信号传输带宽为60 MHz,信道个数=60。无人机传输功率为-10 dBm,干扰机功率为-5 dBm。
图11表示在更加复杂的通信场景下4种决策算法的决策成功率。输入神经元数量根据信道变化大大增加,网络重新训练所需要的时间增加,因此决策算法在第3 000回合左右达到收敛状态,基于D-DDQN的TFDJ-AJ算法在 3 500回合之后逐渐收敛至92%以上。综合2个通信场景的决策成功率收敛性能对比,发现通信场景越复杂,本文中所提算法相较于AC-AJ算法优势越明显。因为复杂信道模型下,只要将D-DDQN网络的神经元参数进行调整,就能够解决当前的决策问题,虽然计算复杂度增加,但是算法仍然收敛较为快速准确,说明该模型运用到单个无人机通信一般场景依然有效。
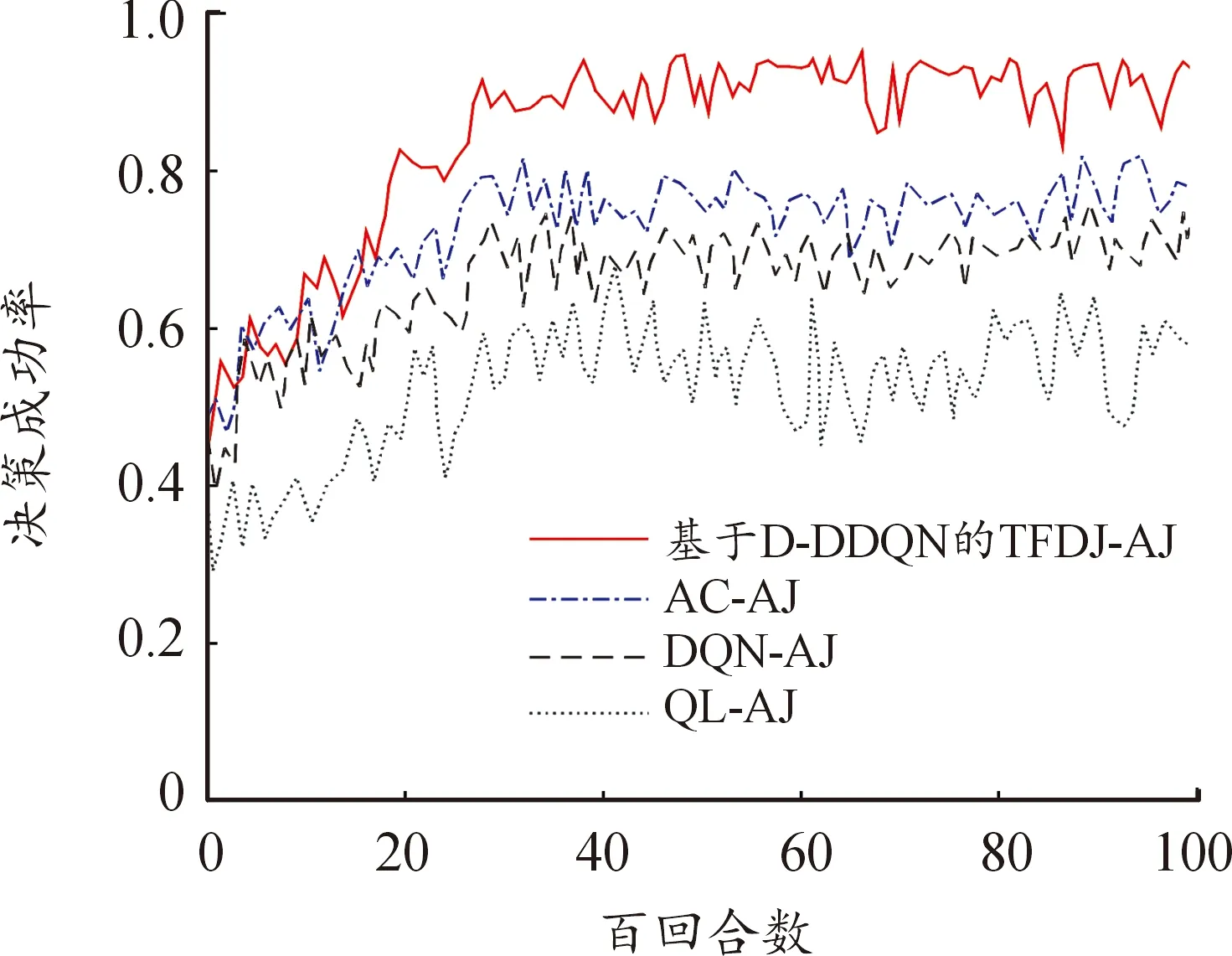
图11 改变通信场景后决策成功率曲线Fig.11 Comparison of decision success rate after changing the communication scenario
5 结论
1) 针对军用无人机面临高动态干扰时需要同时满足灵活控制时间传输长短和处理大规模状态空间的问题,提出时频域联合认知抗干扰算法。以D-DDQN算法为基础架构,根据奖励动态更新贪婪策略,提高了算法的收敛性,解决值过估计问题。
2) 在此基础上,将信道选择和传输持续时间联合调度,以通信效用值为优化目标,通过切换信道防止恶意干扰,选择最佳传输时间最大化系统利用率。
3) 通过仿真证明所提算法整体抗干扰性能较好,在抗干扰的同时避免了频繁切换信道造成的能量损失,较好地满足实际需求。
猜你喜欢
软件导刊(2019年7期)2019-10-11
振动工程学报(2019年2期)2019-05-13
科学与技术(2018年23期)2018-06-17
软件导刊(2018年1期)2018-02-01
无线互联科技(2017年17期)2017-09-15
中国新通信(2017年12期)2017-07-16
物联网技术(2016年11期)2017-01-12
科学与财富(2016年18期)2016-12-22
中国新通信(2016年4期)2016-03-24
CHIP新电脑(2016年3期)2016-03-10
