
基于YOLACT++的槟榔检测算法研究
2022-12-03 10:18舒心怡
湖北工业大学学报 2022年4期
舒 军,王 祥,舒心怡
(1 湖北工业大学电气与电子工程学院,湖北 武汉 430068;2 湖北工业大学太阳能高效利用及储能运行控制湖北省重点实验室,湖北 武汉 430068;3 武外英中国际学校,湖北 武汉 430000)
槟榔是海南的重要经济作物,产量占全国97%以上,曾列入抗击新冠肺炎中药配方,具有较高药用价值[1]。槟榔检测作为槟榔加工的重要步骤。目前,主要采用最大类间方差法(OSTU)[2]、最大极值稳定区域(MSER)[3]等传统图像处理方法将图片中的槟榔与背景分割开,再根据槟榔图像最小外接矩形的长宽对槟榔进行分级。在槟榔图像采集过程中,由于机械振动造成槟榔花蒂掉落、槟榔堆叠,和打光原因造成的阴影生成。使得传统的图像处理方法无法准确识别单个槟榔实例,给槟榔分级造成严重干扰。因此,实现高可靠性的槟榔实例分割是目前亟需解决的问题。
实例分割具备目标检测和语义分割的特点,既需要检测出同一种类的不同实例对象,又需要做到像素层面分类。当前,实例分割算法逐渐被应用于农业生产中,并具有较高的应用价值,姜红花等[4]将 Mask R-CNN运用于玉米叶与杂草的检测,杂草检测率达91%。陈佳等[5]采用YOLACT算法将白羽鸡背部的分割面积与体质质量进行关联,实现白羽鸡体质质量评估,平均准确率97.49%。刘文波等[6]在SOLOV2网络中引入可变形卷积,实现对番茄叶片病害的检测,掩模分割精度达42.3%。YOLACT++[7]作为YOLACT改进算法[8],相较于Mask R-CNN[9]具有速度优势,较SOLOV2算法[10]在槟榔堆叠时具有边缘分割优势。选用YOLACT++作为槟榔实例分割模型,仍然存在掩模预测错误与检测框回归不准确造成的部分槟榔掩模残缺的问题。
针对槟榔自动化加工中槟榔检测的需求,需要实例分割速度达到18帧/s以上,同时要确保检测与分割准确性。在YOLACT++主干网络中引入改进的Res2Net[11]模块增强网络语义信息提取能力,改善掩模预测错误问题。对于边界框不精确问题,本文采用CIoU[12]边界框回归损失函数,改善了边界框预测精度。实验结果表明,改进算法改善了槟榔实例分割效果,进而提高了槟榔的分级准确率。
1 槟榔检测流程
槟榔检测主要由图像采集、图像处理和槟榔分拣三部分完成,其检测系统模型见图1a,使用工业相机采集传送带上的槟榔图片,使用工业光源增加槟榔与传送带对比度,突出槟榔特征。服务器用训练好的槟榔检测模型对采集来的槟榔图片进行实例分割与等级判断,结果发送到人机交互界面,同时控制气泵,将不同等级的槟榔果吹入不同的收集桶中。
槟榔分级流程见图1b,工业相机完成槟榔图片的采集,每张图片正常采集三颗槟榔,用实例分割网络识别出带花蒂槟榔与无花蒂槟榔的类别、掩膜和预测框位置,若槟榔预测框相交,可判断为槟榔堆叠,进行回流处理。对于无花蒂的槟榔,计算其掩模的小外接矩形的长和宽。对于带花蒂的槟榔,将其掩膜的最小外接矩形长度减去30 mm,视为去花蒂处理,宽度保持不变。最后,依据最小外接矩形的长宽将槟榔分为A、B、C、D四个等级,槟榔分级指标见表1。每颗槟榔均采集三个不同位置的图片,三次等级检测中选其中至少两次相同的等级作为最终分级。对三次等级检测均不同的情况进行回流处理。

图1 槟榔检测系统

表1 槟榔分级指标 mm
2 YOLACT++网络结构
YOLACT++整体结构见图2a,包含主干(Backbone)、预测头(Prediction Header)、原型分支(Protonet)、快速非极大值抑制(Fast NMS)、裁剪模块(Crop)和阈值分割(Threshold)六个部分组成。基于ResNet101构造的主干网络对输入的图像进行特征提取,生成C1~C5五个特征图。将C3,C4,C5三个特征图作为特征金字塔的中间输入层,经过多个尺度的特征融合生成P3~P7五个特征图,再通过两个并行的分支任务。第一个分支将P3特征图通过图2(b)所示的原型分支产生k个原型掩模。第二个分支在预测头中以特征图的每个像素点为锚点,生成长宽比为[1,1/2,2,1/3、3]的锚框,用于检测是否存在实例。再分别进行原型掩模的系数预测(mask Coefficients)、锚框分类(Class)与边界框回归(Bounding Box Regression)。Fast NMS对经过边界框回归后的锚框进行筛选,获取最终的实例预测框。将原型掩模与掩模系数进行线性组合,生成的图像经过预测框区域裁剪和阈值分割,进而获得最终的实例掩模。
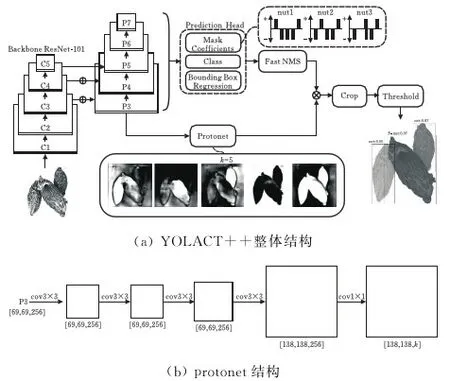
图2 YOLACT++模型结构
3 算法改进
3.1 主干网络改进
YOLACT++采用基于ResNet-101的主干网络(表2),其中Bottleneck[13]残差结构作为ResNet-101的基本模块(图3a),该结构在解决梯度消失同时增强网络的特征提取能力。为更进一步提取深层特征,充分利用单层内特征,本文采用改进的Res2Net模块替换主干网络中的Bottleneck模块,以获得更强的分层多尺度表示能力。Res2Net结构见图3b。Res2Net将经过1×1卷积特征图按通道均匀分为4个特征子图,每个特征子图含有相同的空间大小和通道数。除第一个特征子图,其余每个特征子图都对应一个3×3卷积。从第三个特征子图开始,将特征子图与前一个经过卷积的特征子图输出相加,作为该特征子图对应卷积的输入,然后将4个特征子图的输出结果进行合并,并经过1×1卷积输出。通过对特征子图的分割和拼接实现特征重用,扩大感受野,有利于全局和局部信息提取。最后通过卷积输出。改进的Res2Net增加了CBAM[14]注意力模块,对通道特征与空间特征进行加权,抑制无效特征,使得网络更关注于目标区域特征。
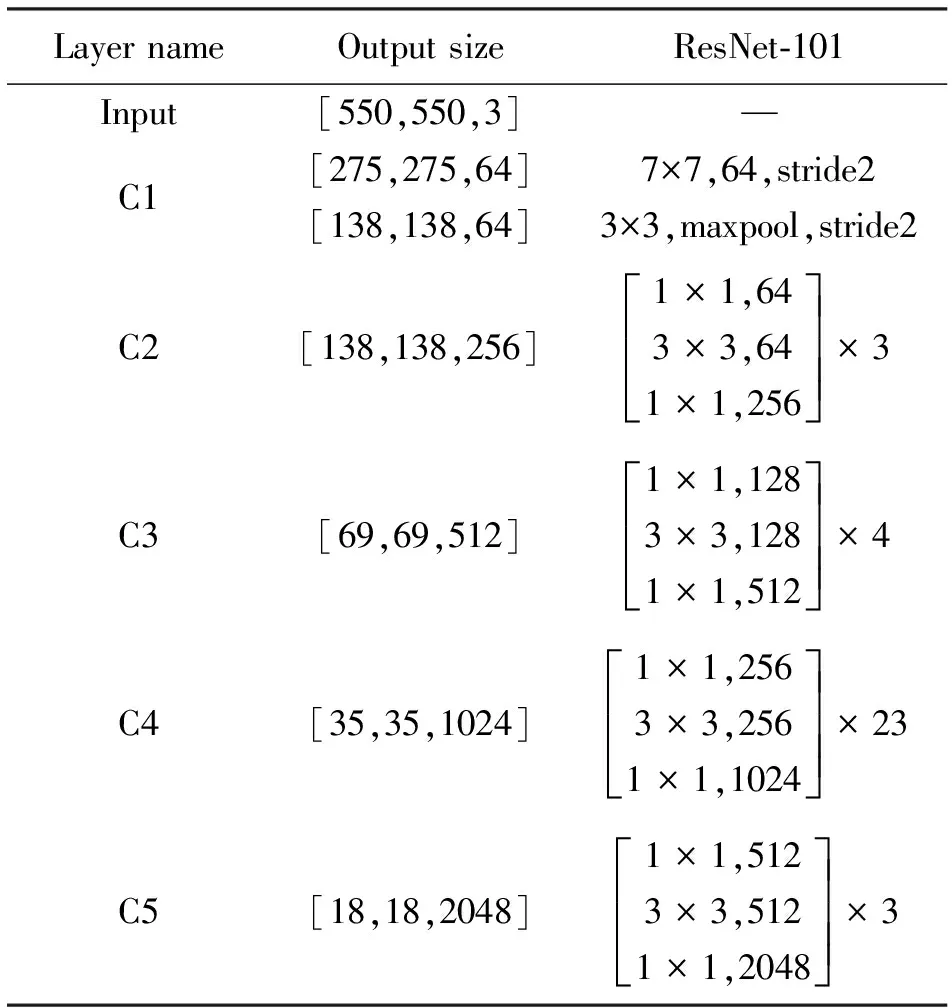
表2 ResNet-101主干网络

图3 网络结构对比
CBAM注意力模块结构见图4。由通道注意力模块和空间注意力模块构成。分别为特征图生成一维的通道注意力权重和二维的空间注意力权重,用于加强网络的特征提取能力。

图4 CBAM结构
在通道注意力模块中将输入的特征图U(大小H×W×C)经过全局最大池化和平均池化,获得两个1×1×C的特征图,其结果分别输入权值共享的两层感知器(MLP),将输出的特征相加经过激活函数,生成通道注意力权重Mc。最后将输入特征图与通道注意力权重相乘,生成通道注意力特征图F′。计算过程如下:
Zavg=AvgPool(U)
Zmax=MaxPool(U)
Mc=σ[fc2(δ(fc1(Zavg)))+fc2(δ(fc1(Zmax)))]
F′=Mc·U
式中:AvgPool表示全局平均池化,求取每个通道的像素平均值;MaxPool表示全局最大池化,保留每个通道的特征图的像素最大值;fc1全连接层,输入通道C,输出通道C/16;fc2全连接层,输入通道C/16,输出通道 C;δ表示ReLU函数;σ表示sigmoid函数。
在空间注意力模块中将通道注意力特征图F′作为输入先进行通道维度的平均池化和最大池化,获得两个H×W×1的特征图,再将两个特征图拼接后通过7×7的卷积层,结果经过sigmoid函数,得到二维单通道的空间注意力权重Ms,将空间注意力权重与通道注意力特征图相乘,生成同时具有空间与通道注意力的特征图F″。计算过程如下:
Zavg=AVGPool(U)
Zmax=MAXPool(U)
Ms=σ(fc3(Zavg,Zmax))
F″=Ms·F′
式中:AVGPool表示通道维度平均池化,对每个通道的特征图对应像素相加取平均值;MAXPool表示通道维度最大池化,保留各个通道特征图对应位置的最大像素值;fc3表示7×7的卷积,输出通道为1。
3.2 边界框回归损失函数改进
边界框回归损失函数用来衡量预测框与真实框的位置关系。YOLACT++采用Smooth L1损失函数作为边界框回归损失函数,分别对预测框的长、宽、中心点横坐标和纵坐标的偏置进行损失计算,具体计算过程如下:
式中:xa,ya,wa,ha表示anchor的中心点坐标、长和宽;x*,y*,w*,h*表示真实框的中心点坐标、长和宽;u表示网络预测的anchor偏置矩阵;v表示真实框与anchor的偏置矩阵。
由于Smooth L1作为边界框回归损失函数对四个偏置量分别计算损失值,算法无法准确描述预测框与真实框之间位置关系。采用CIoU损失函数将有助于解决上述问题。边界框回归损失示意图见图5,定义边界框损失函数:
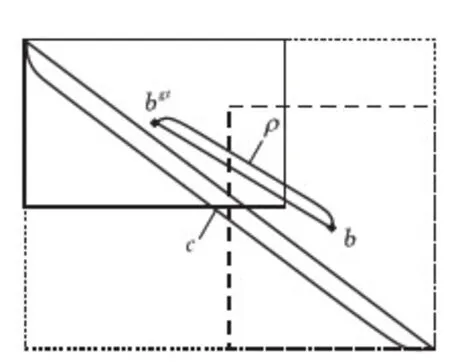
图5 边界框回归损失计算
式中:b,bgt分别表示预测框与真实框的几何中心;ρ表示两个中心点之间的欧式距离;c表示预测框和目标框最小外接矩形的对角线长度;α为用于平衡比例的参数;v用来衡量预测框和目标框之间的比例一致性。
网络先进行anchor偏置量预测,再将anchor经过平移缩放成为预测框b,完成边界框回归。利用预测框b与真实框bgt计算边界框回归损失函数,CIoU损失函数考虑到了预测框与真实框的交并比(IoU)、最小外接矩形、几何中心距离ρ和长宽比例。Smooth L1损失函数针对预测框的偏移量进行损失计算。只考虑几何中心距离与长宽比,缺乏对交并比和最小外接矩形的考量。
图6中实线框为真实框,虚线框为预测框。当偏移量u=(0,0,0,0),即预测框与anchor重合时,用两种边界框损失函数分别计算其对应损失值,可以发现采用Smooth L1损失函数计算的损失值均相同,但采用CIoU损失函数计算的损失值均不同,预测框与真实框交并比越大、外接矩形越小、几何中心距离越短、长宽比越接近,其损失值越小,预测框与真实框越接近,即边界框回归越准确。故可采用CIoU损失函数更加精确地衡量边界框回归性能。
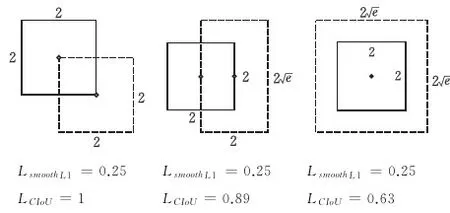
图6 不同预测框对应的损失函数
4 实验
4.1 槟榔图片采集与数据集建立
本研究以槟榔果作为研究对象。数据采集地点在益阳市口味王槟榔厂,图像采集设备选用德国acA1280-60gc Basler ace工业相机。对每颗槟榔采集如图7所示左、中、右三个位置对应不同角度的图片,共采集槟榔图片1500张,并对图片采用添加噪声、随机翻转、随机亮度、色彩通道转换这4种数据增强技术,将数据集扩充到6000张。用LabelMe 标注工具完成图像的标注工作,将图像的语义分为三类:背景(background)、带花蒂槟榔果(F-nut)、无花蒂槟榔果(nut)对应的标签分别为0、1、2。标记后的数据集包含原始图像和与之对应json标签文件,部分数据处理后的图片见图8。

图7 同一颗槟榔不同位置图像采集

图8 数据集处理
4.2 实验环境
槟榔实例分割实验硬件配置:操作系统Windows 10,CPU为 Intel Core i5-11400,GPU加速NVIDIA GTX1080ti 与CUDA10.0 cuDNN7.0,运行环境Python3.7,深度学习框架Pytorch1.2.0。
4.3 评价指标
选用AP(Average Precision)作为预测框和实例分割掩模的评价指标。AP通过计算精确度-召回率曲线(P-R)下方面积得到,由于IoU阈值的选取会影响精确度和召回率大小,选用AP75(IoU=0.75),mAP(IoU=0.50:0.05:0.95)作为评价指标,计算公式如下:
式中:TP表示模型识别为带花蒂槟榔或无花蒂槟榔且与真实标注类别匹配的样本数量;FP表示模型预测为带花蒂槟榔或无花蒂槟榔且与真实标注类别不匹配的样本数;FN表示预测为背景但真实标注为带花蒂槟榔或无花蒂槟榔的样本数量。
对网络模型运算速度及模型复杂度采用参数量(Parameter),以及浮点计算量(FLOPs)作为评价标准完成评价。对于一次卷积运算,其模型参数和浮点计算量公式如下:
Parameter=(K2Cin)Cout+Cout
FLOPs=[2(CinK2)Cout+Cout]HW
其中Cin,Cout分别为输入输出特征图通道数,K为卷积核的大小,H×W为输出特征图大小。考虑到激活函数(activation function)以及偏置(bias)等方面的不同,对FLOPs的计算方式不尽相同。为便于对比分析,本文采用Pytorch中的第三方库thop,对模型参数量、浮点计算量进行统一计算。
4.4 实验结果分析
实验数据集内共包含槟榔片样本6000张,其中用作训练集4800张,测试集1200张。训练epoch为800次,GPU每次处理4张图片,使用随机梯度下降(SGD)作为训练时的优化器,初始动量设置为0.9,学习率为0.001,权重衰减系数0.0001。
4.4.1参数量与计算量对比结果主干网络的改进将同一特征层的不同通道特征图进行多次多尺度的特征融合,使得高分辨率特征图与低分辨特征图信息相互补充,使得主干能充分提取图片的语义信息,同时造成部分主干网络模型尺寸与参数的增加,边界框回归损失函数改进也在一定程度上增加模型的计算量。网络改进前后网络参数量及总浮点运算量FLOPs量化结果见表3。可以看出网络参数、模型大小、浮点运算量相较于改进前提升9.8%,1.1%,6.6%
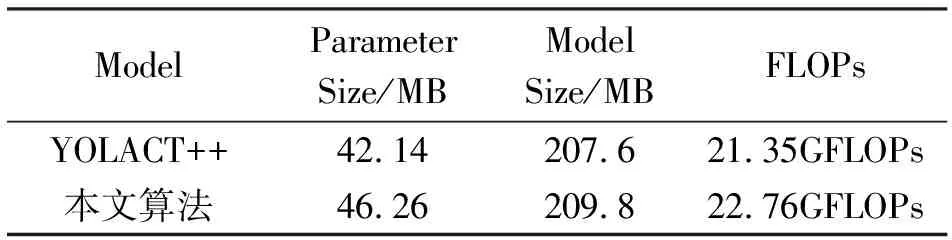
表3 网络改进前后参数量与计算量对比
4.4.2主干网络改进前后热点图对比针对主干网络的改进,采用Grad-CAM生成主干网络的热力图(heatmap)用来对主干网络的输出进行可视化分析,生成的主干网络改进前后的热力图见图9。颜色越亮表示主干网络对于该区域的关注力越强,原主干网络关注的区域包含槟榔的部分区域和背景区域,存在关注区域错误的问题。本文提出改进的主干特征提取网络,加深网络对于图像深层信息的提取能力,采用CBAM注意力机制,使得主干网络更关注于槟榔区域,并极大的抑制了背景阴影和掉落花蒂的干扰。

图9 主干网络热点图
4.4.3网络分割效果对比损失值用来衡量网络预测结果与标注之间的误差,损失值越小表示模型预测得越准,网络每一次迭代训练过程中生成损失值,并记录于训练日志中。网络改进前后的掩模损失函数相同,均采用预测掩模与标注掩模的二值交叉熵作为损失函数,故可通过掩模损失值作为衡量网络改进前后的掩模质量。掩模损失折线图见图10,损失值随着迭代次数的增多而下降,原网络进行800次迭代后loss值稳定在0.08左右。改进后网络损失值最终稳定在0.01左右,改进后的模型具有更加良好掩模预测性能。
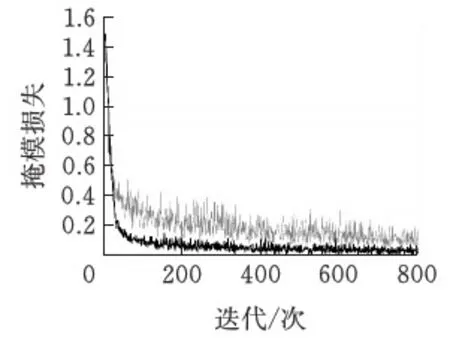
图10 掩模损失值曲线
从测试集中挑选3幅不同条件下的图片来测试槟榔实例分割模型改进前后的分割效果。图11可以看出对正常采集图像进行实例分割,掩模会受到预测框区域的限制,SmoothL1损失函数作为边界框回归的损失函数造成部分槟榔果预测框定位不准确,导致掩模的部分区域无法识别出来。图12和图13可以看到,原始的YOLACT++算法对传送带上的阴影与脏污和掉落的槟榔花蒂容易造成误分割。本文提出改进的主干特征提取网络,加深网络对于图像深层信息的提取能力,同时使得主干网络更关注于槟榔花蒂与槟榔籽,减少背景阴影与脏污干扰,算法使用CIoU作为边界框回归损失函数,使得边界框回归更加准确,一定程度上提升了掩模的分割质量。

图11 正常采集

图12 花蒂掉落及槟榔堆叠

图13 背景阴影及槟榔堆叠
4.4.4不同改进点对比为了验证不同改进点的有效性,做了四组对比实验,结果见表4。

表4 不同改进点对比实验结果
通过对比实验1与实验2可以发现,主干网络的改进对于预测框与掩模的mAP均分别提升1.73%,1.93%。对比实验1与实验3,边界框回归中CIoU的引入明显提高了预测框的平均精度,相较于改进前上升2.94%。对比实验1与实验4,可以发现主干网络与边界框整体改进相较于原算法在预测框mAP与掩模mAP上分别提升5.41%与5.20%,但检测速度有所损失,降低了4.7帧/s。
4.4.5样本预测结果用训练好的网络模型进行分级测试,将A、B、C、D四个等级的槟榔各两百颗送入传送带进行实例分割与槟榔分级测试,改进前后实验测试结果见表5。

表5 改进前/后识别结果
通过对比可以发现YOLACT++网络的实例掩模由于受到预测框精度限制,导致无法实现完整的掩模分割,造成部分槟榔等级被误分为低等级。由于打光造成的阴影被误分割为槟榔区域,造成槟榔被误分为高等级。而本文算法很好的改善了上述问题,使得槟榔的平均准确率提升2.12%,达到98.87%。
4.4.6不同算法对比为进一步验证本文算法的实例分割效果,利用槟榔数据集分别对Mask R-CNN、SOLOv2、YOLACT++与本文算法进行训练,用训练好的模型验证槟榔的检测与分割效果。Mask R-CNN作为R-CNN最具代表性的双阶段实例分割算法,SOLOv2作为单阶段实时实例分割代表,训练结果对比见表6。从表6可以看出Mask R-CNN检测速率不佳,SOLOv2检测精度稍逊于本文算法,本文算法相较于Mask R-CNN、SOLOv2在掩模mAP上分别高出4.09%,2.37%。本文算法相较于Mask R-CNN在预测框mAP上分别高出4.90%。

表6 不同算法分割数据对比
5 结论
提出了一种基于YOLACT++的槟榔检测模型,对采集的槟榔图像进行标注并采用数据增强方法扩增数据集。在主干网络中引入改进的Res2Net模块,加深了主干特征提取能力。并改进了边界框回归损失函数,进而改善了掩模分割效果。测试实验结果表明,训练出的模型在处理花蒂掉落、槟榔堆叠和复杂背景等情况下的槟榔图片均有较好的检测效果,训练后的模型掩模分割效果优于Mask R-CNN、SOLOv2网络,槟榔实例分割速度达到22.4帧/s,槟榔分级准确率提升了2.12%,满足工业现场需求。对模型部分参数稍作修改仍可应用于其他工业生产线产品检测,具有较高的应用价值。由于网络的改进造成部分速度损失,后续工作将在保证网络分割质量的前提下优化网络结构,提升分割速度。
猜你喜欢
广东教育·高中(2022年1期)2022-03-16
西北园艺(果树)(2021年2期)2021-11-30
世界热带农业信息(2018年5期)2018-11-09
世界热带农业信息(2018年1期)2018-06-22
世界热带农业信息(2018年6期)2018-03-05
读书文摘(2017年10期)2017-10-16
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中学理科·综合版(2008年3期)2008-03-07
