
一种空间关系增强的场景图生成方法
2022-12-03 10:18靳华中李文萱袁福祥
湖北工业大学学报 2022年4期
陶 琪,靳华中,李文萱,黎 林,袁福祥
(湖北工业大学计算机学院,湖北 武汉 430068)
场景图[1]是表示场景内容的一种数据结构,能描绘一张图像中的目标及目标间的关系,常以<主语,谓语,宾语>格式表示,例如
现有的场景图生成方法依赖于目标区域或目标区域的上下文信息。文献[11-15]的研究侧重于目标的视觉特征,对目标之间的空间信息利用不足。事实上,视觉场景是目标之间信息结构化和层次化的表示,具有较强的空间关系约束特征。相同目标的相对位置发生变化,其空间关系随之发生改变。例如,当“人”与“车”并排时,两者之间的关系可以使用“near”来表达;如果“人”在“车”上方时,“人”与“车”之间是“riding”关系。本文提出了融合空间信息的场景图生成方法,主要贡献包括:1)提出了一种空间关系增强的方法,增强目标间的空间关系。2)提出了利用目标间的关系统计筛选目标对的方法,排除数据集中不存在关系的目标对,提高关系检测效果。实验结果表明,本文方法在场景图生成的任务中比现有的方法有更好的召回率,生成的关系谓词更加准确。
1 相关工作
本文在Neural Motifs模型[14]的基础上,引入先验知识和目标的空间信息,提出一种空间关系增强的场景图生成方法。本节对Neural Motifs模型、先验知识的引用与空间信息表达上下文关系的相关工作进行介绍。
1.1 Nueural Motifs模型
Neural Motifs模型是一种利用循环神经网络融合全局信息和局部信息的方法。该模型将场景图生成分为候选目标框生成、目标检测和关系检测3个阶段。在候选目标框生成阶段,首先通过Faster RCNN[16]获取候选目标框,其次以候选目标框中心点在原图上的位置从左至右顺序输入到双向LSTM,最后将编码得到的目标上下文输入到目标检测阶段和关系检测阶段。在目标检测阶段,用一个单向LSTM解码目标上下文得到目标的类别标签并传递给关系检测阶段。在关系检测阶段,首先利用双向LSTM编码边上下文信息,接着将每一个边上下文信息处理为主语特征与宾语特征。最终该模型根据目标对不同的主语特征与宾语特征,得到关系表示。通过序列学习,Neural Motifs模型能学到简短及重复出现的规则化信息,但是将复杂的视觉信息抽象成线性序列造成了信息损失,例如在图像中,目标框“人”与“车”是上下位置,但是输入到网络时却是从左至右的顺序输入,导致目标间详细的重要的位置信息缺失。
1.2 先验知识的引入
引入先验知识是为了细化或加强目标间的关系,提升关系检测的效果。近年来,许多研究利用先验知识来辅助关系检测、视觉问答等任务。Bo D等[12]设计一个深度关系网络,利用空间位置和统计依赖性来解决关系识别中的歧义。Zellers R 等[14]对Visual Genome数据集上的关系谓词和目标对间的统计知识进行分析,发现统计知识为关系检测提供很强的正则化,将统计知识作为外部信息增强关系表示。Chen T等[17]引入目标对及其可能关系的关联图,明确地正则化关系检测的语义空间,从而解决关系检测的不均匀分布问题。Tang K等[18]对Visual Genomes数据集进行预处理,获得每两个目标间的合理的二进制先验知识,以此建立目标的动态树结构,树中节点的并行或层次关系更好地表达目标间的相关关系。上述这些研究引入统计知识,使关系检测取得更好的效果。与上述研究不同,本文引入目标对数值矩阵,用数值矩阵规范目标对间关系的数量,消除完全错误的关系三元组,提高场景图生成效果。
1.3 空间信息表达上下文
随着场景图生成的研究,许多学者使用空间信息辅助场景图生成任务。例如,林欣等[19]通过对目标的相对位置和面积比例的编码与残差置乱上下文做最大全连接,以增强关系的空间上下文。Ren G 等[20]研究物体间的相对大小与相对位置,发现相对位置有助于决定关系类型,相对大小有助于判断某种关系的存在,以此他们建立目标间的交互上下文。Zheng Z 等[21]利用空间知识,根据对象的空间布局和对应的子图,模糊对象特征的部分上下文,以促进对象之间的关系识别。与之前的研究不同,本文引入空间信息目的是增强目标对的空间位置信息,改进关系谓词的细粒度分类,提高关系三元组准确性,实现场景图生成效果的提升。
综上所述,相比Neural Motifs模型,本文通过空间关系增强模块能一定程度上缓解因为序列学习而导致目标间空间规则损失的问题,使关系表示增添了目标间空间信息,使关系检测有更多的依据。通过统计知识的引入模块能辅助目标对的预测数量冗余问题,使关系检测更高效。
2 空间关系增强的场景图生成方法
为了生成更加准确的场景图,本文提出了一种空间关系增强的场景图生成方法。该方法主要由目标识别及关系向量生成、目标间的关系统计和空间关系增强三部分组成,整体框架如图1所示。

图1 场景图生成框架
场景图由目标及其关系组成。对于目标的检测,首先利用Faster RCNN模型[16]提取边界框和初始的目标标签概率的特征向量boi,其次在目标识别和关系向量生成阶段,利用boi和边界框信息生成目标上下文objecti,随后将其解码成目标类别分布objdisti,最后通过argmax获得目标类别Oi:
Oi=arg max(fc(objdisti))
其中,fc(·)表示全连接层。
对于关系的检测,首先利用边上下文edgei,将其解码成主语特征edgesubi和宾语特征edgeobji。然后根据目标对编号,将主语特征edgesubi与宾语特征edgeobjj按元素相乘得到关系向量Prodi,j;同样根据目标对编号,通过空间关系增强模块,获得空间向量Si,j。随后线性化处理关系向量Prodi,j与空间向量Si,j的乘积,得到关系类别分布reldisti,j;最后通过argmax获得reli,j:
reldisti,j=fc(Prodi,j⊙Si,j)
reli,j=arg max(fc(reldisti,j))
其中,⊙表示点乘运算,fc(·)表示全连接层。
2.1 目标识别及关系向量生成
目标识别及关系向量生成模块分为目标和关系两个阶段。目标阶段进行目标识别和目标上下文生成,关系阶段生成目标间的关系向量。
在目标阶段,首先使用Faster RCNN提取候选目标框进行目标预分类和边界框回归,其次结合Neural Motifs模型的目标上下文模块进行目标上下文的编码与解码。根据目标框的中心坐标从左至右排序,依次将目标特征fi输入到高速双向LSTM[22]中获得目标上下文信息objecti:
objecti=biLSTM(fi)
目标上下文objecti输入到LSTM[23]进行解码,得到目标类别分布objdisti:
objdisti=LSTM(objecti)
在关系阶段,首先根据目标上下文objecti与目标的语义词向量Wembi输入到高速双向LSTM[22]得到边上下文edgei:
edgei=biLSTM(concat(objecti,Wembi))
其中,biLSTM(·)表示高速双向LSTM。其次通过全连接层将提取的边上下文edgeI?分解成主语、宾语特征edgesubi,edgeobji:
edgesubi,edgeobji=fc(edgei)
其中,fc(·)表示全连接层。最后根据目标对编号i,j对应主语特征edgesubi与宾语特征edgeobjj进行点乘运算,从而得到目标间的关系向量Prodi,j:
Prodi,j=edgesubi⊙edgeobjj
2.2 目标间的关系统计
目标间的关系统计阶段的主要目的是排除不存在关系的目标对,减少召回率评价时的误判,提高场景图生成效果。该模块通过统计数据集中每两个对象同时出现的次数,建立数值矩阵M,并利用该矩阵判断目标之间是否存在关系,当目标间不存在关系时,不做进一步的关系检测;存在关系时,进行后续处理。
对象对数值矩阵M是根据目标数据集Visual Genome建立的一个151*151的两对象同时出现的矩阵,记M∈RC×C,其中C为151,151指的是数据集中最常见的150种对象类和一种包含其他所有非常见的对象类。具体方法是统计每张图片中每个关系三元组的主语和宾语,将其标签对应数字编号,并添加到数值矩阵M。关系数值矩阵Mr表示每张图片中n个目标可能存在的关系,记Mr∈Rn×n并置为零,并用数组A[n-1]存储n个目标标签的编号。
图2展示了引入目标间关系统计的具体步骤,第一步,根据目标框编号(从0到n-1)依次获取矩阵Mr的两个下标i、j,并且i≠j,下标i,j分别表示主语目标框与宾语目标框。第二步将M(A[i],A[j])对应数值矩阵M得到数值num。第三步,比较num与0的大小,当num大于0,则Mr[i,j]赋值为1,意思为目标i与j存在关系,然后输入下一组下标i、j;当num小于0,意思为目标i与j不存在关系,则输入下一组下标i、j。第四步判断i、j是否全部输入,当i、j没有全部输入,则返回第二步;当i、j全部输入,则表示所有可能目标对都经过数值矩阵M筛选,输出筛选后的关系矩阵Mr。

图2 目标间关系统计的引入
其中,下标i,j为主语目标框与宾语目标框的编号,M为对象对数值矩阵,Mr是建立的关系数值矩阵。
2.3 空间关系增强
本文提出一种空间关系增强的方法,该方法通过Hadamard积[24]将空间信息添加到关系检测中,目的是将目标间的空间信息融合到网络,提升网络的推理能力,进而提高关系检测性能。Hadamard积用元素相乘方法将多个相同尺寸的特征融合。本文将目标框之间的空间信息处理成4096维的数据,该尺寸与关系表示特征大小相同,然后通过Hadamard积将目标间的空间信息与关系表示特征融合,用于关系检测。该方法可以进行端到端的训练。
假定主语目标框s=(lxi,lyi,rxi,ryi)和宾语目标框o=(lxj,lyj,rxj,ryj),则主宾语目标间的空间信息包括相对大小Psi,j、相对位置Pwi,j及交并比Poi,j。其中坐标(lx,ly)表示目标框左上的顶点,坐标(rx,ry)表示目标框右下的顶点。
首先根据坐标信息,计算主语i与宾语j目标框的面积A(i)、A(j),并计算主语、宾语的相对大小Psi,j:
A(i)=(rxi-lxi)*(ryi-lyi)
A(j)=(rxj-lxj)*(ryj-lyj)
其次利用主语与宾语目标框的坐标,计算主语与宾语目标框的中心坐标(Xi,Yi)、(Xj,Yj)。再用欧氏距离计算主语、宾语的相对位置Pwi,j:
根据主语与宾语目标框的交集与并集,计算他们之间的比值,得到主语、宾语的交并比Poi,j:
其中,A(i,j)为主语、宾语目标框的并集,A(i)、A(j)是主语与宾语目标框的面积。
最后将空间信息Psi,j、Pwi,j、Poi,j归一化,使用sigmoid为激活函数的卷积层将其转换为4096维的空间向量Si,j,并将其与关系向量Prodi,j按位相乘得到最终的关系谓词表示Prodsi,j:
Si,j=conv(Psi,j,Pwi,j,Poi,j)
Si,j=sigmoid(Si,j)
Prodsi,j=Prodi,j⊙?Si,j
其中conv(·)表示卷积层,Prodi,j是主语、宾语的乘积特征,用4096维的向量表示,⊙ 表示点乘运算。
3 实验结果与分析
3.1 数据集
本文选取的是Visual Genome数据集,该数据集包含108077张图片,平均每张图片标注38个对象和22个关系。在实验中,类似于之前的研究,使用最常见的150个对象类别和50类关系谓词,并将整个数据集的70%、30%划分为训练集和测试集,从训练集中选取5000张图像作为验证集。
3.2 评价指标
类似于之前的研究[13],本文通过以下三种任务来评估提出的模型:
谓词分类(predicate classification,PredCls):给定图像,目标框(对象)和对象类别的真值标注,预测给定对象之间的关系标签。场景图分类(scene graph classification,SGCls):给定图像和目标框,预测目标框(对象)的类别标签,并预测每个对象对的关系标签。场景图生成(scene graph generation,SGGen):给定图像,预测图像中出现的对象,并预测对象之间的关系标签。
实验评价指标采用Recall@K,缩写为R@K:即主谓宾关系三元组 <主语,关系谓词,宾语> 的置信度得分前 k 个的召回率。三元组的置信度得分Score一般采用:
Score=score(sub)*score(obj)*score(pred)
约束条件指的是对于每对目标对,只获取一个关系。也有研究[27]省略了这个约束,获得多个关系,从而得到更高的评价指标值。
3.3 实验相关设置
本文使用带有VGG16[25]的Faster RCNN作为底层目标检测器。输入图像的大小设置为592 × 592,并且使用类似于YOLO-9000[26]锚框的尺度和长宽比。使用SGD算法在目标数据集Visual Genome上训练场景图分类与关系谓词分类模型,设置batch size为2,momentum为0.9,weight decay为0.999,学习率初始化为0.001,并在验证集的mAP趋于平稳时除以5。在训练场景图生成模型,设置batch size为2,momentum为0.9,weight decay为0.999,学习率初始化为0.0001,并在验证集的mAP趋于平稳时除以10。
3.4 结果分析
实验分别在约束和无约束条件下将本文方法与现有方法进行比较,包括视觉关系检测VRD[11]、关联嵌入AE[27]、迭代消息传递IMP[13]、改进版本的IMP+[14]、直接利用统计概率的方法FREQ[14]和堆叠主题网络SMN[14],实验结果见表1、表2。
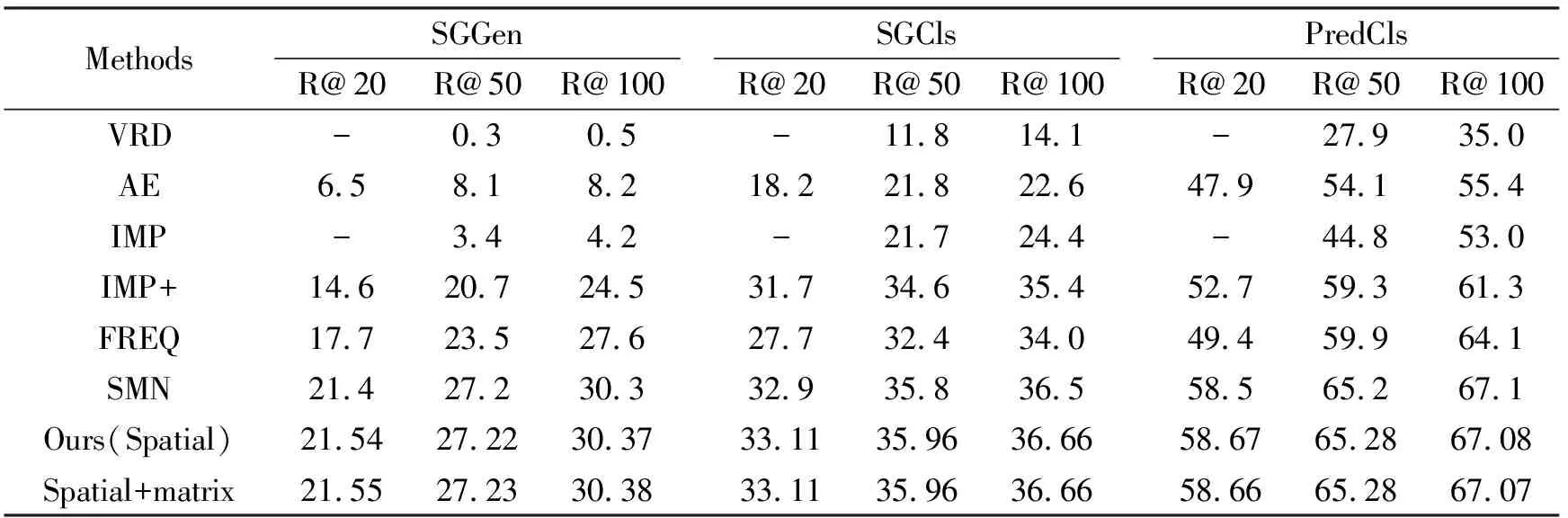
表1 约束条件下,本文方法与现有方法实验结果

表2 无约束条件下,本文方法与现有方法实验结果
从表1可以看出,约束条件下本文方法相比Neural Motifs模型,在场景图生成、场景图分类和关系谓词检测三类任务中R@20提升都超过了0.1%;尤其是在场景图分类中每一项指标都超过了0.1%,另外两类任务的指标也都有小幅提升。从表2可以看出,在无约束条件下场景图分类任务中两项指标均高于0.3%,另外两类任务的指标也有提高。综上所述,在约束和无约束条件下,空间关系增强方法在各项指标中效果均有明显提升;在约束条件下,目标间的关系统计方法在各项指标中略有提升。
图3是利用场景图分类模型做的部分结果可视化,其中矩形框表示与数据集给定真值相同的目标,带有向边的平行四边形表示与数据集给定真值相同的关系谓词;椭圆形框表示与数据集给定真值不同的目标,带有向边的菱形表示与数据集给定真值不同的关系谓词。Row 1为带目标框的图片,Row 2为Neural Motifs模型场景图分类Row 3为本文模型场景图分类。
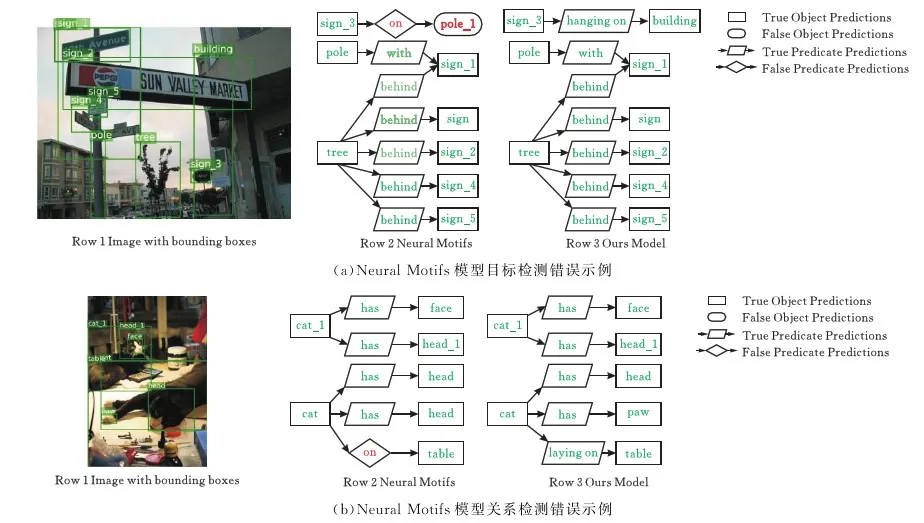
图3 部分可视化结果
从图3a可以看出,Neural Motifs模型将场景中的building预测成场景中出现过的pole。从图3a、图3b可以看出Neural Motifs模型对于关系的预测往往都是on这类简单且比较模糊的关系谓词,而本文模型可以预测hanging on,laying on这类描述更准确的关系谓词。结果表明,本文模型比Neural Motifs模型更加优异,特别是对一(b)Neural Motifs模型关系检测错误示例些模糊的关系谓词做了更进一步的精准预测,目标分类也更准确。
图4是目标预测与真值不同所导致的错误预判。图4a中复杂场景容易影响目标检测的效果;图4b的简单场景中,由于目标框重叠比较多,导致目标检测效果较差。图5是关系谓词预测与真值不同所导致的错误预判。

图4 错误目标检测示例

图5 错误关系预测示例
4 结束语
本文提出了一种空间关系增强的场景图生成方法,研究了场景图中空间信息利用的问题。该方法以Hadamard积为基础,将目标间的空间信息融合到关系表示中,从而增强关系表示。该方法主要思想是将目标间的空间信息转换为空间向量,其维度与关系向量相同,再利用Hadamard积将空间向量与关系向量融合。此外,本文统计数据集中每两类目标的关系矩阵,剔除不存在关系的目标对,减少关系谓词的错误检测。实验结果表明,本文方法提取的关系描述更准确,语义更丰富,能更具体的表达场景信息。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
疯狂英语·初中天地(2021年4期)2021-06-09
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
初中生学习指导·中考版(2020年8期)2020-09-10
西夏研究(2020年2期)2020-06-01
现代哲学(2019年4期)2019-12-14
疯狂英语·初中版(2019年12期)2019-01-02
报刊荟萃(上)(2017年3期)2017-06-26
艺术与设计·理论(2016年11期)2017-01-13
现代经济信息(2009年8期)2009-02-03
