
基于多模态融合的文本生成图像
2022-12-11 09:42叶龙王正勇何小海
智能计算机与应用 2022年11期
叶龙,王正勇,何小海
(四川大学 电子信息学院,成都 610065)
0 引言
文本生成图像[1]属于自然语言处理和计算机视觉的融合任务,是图像生成技术的热点研究课题之一。文本生成图像指从给定的自然语言描述中生成真实的和文本一致的图像。文本生成图像可应用于图像描述生成[2-3]、视觉推理[4]、视觉问答[5]、医疗图像生成[6]等多个领域。
近年来,随着深度学习的快速发展,文本生成图像的主流方法采用生成对抗网络。早期,Mirza 等人[7]提出CGAN,Reed 等人[8]提出GAN-INT-CLS,但是使用这些方法生成的图像的质量和分辨率都较低。为了解决生成的图像分辨率的问题,Zhang 等人[9]提出了Stack-GAN,主要是将生成高分辨率的图像过程分成2 个阶段。低分辨率的图像是在第一阶段生成,第一阶段主要关注图像的整体结构;第二阶段生成高分辨率的图像,这个阶段主要关注图像的一些细节信息以及纠正第一阶段生成图像的一些错误。
多阶段图像生成的方法虽然解决了生成图像分辨率低的问题,但是生成的图像和输入文本依然存在语义匹配较低的问题。AttnGAN[10]引入注意力机制,通过注意力把生成图像和句子特征向量中最密切的部分联系起来。DM-GAN[11]通过引入动态记忆化机制来使得初始图像自适应地选择重要的文本信息,但是依然存在生成图像缺失、生成图像质量不高、低分辨率阶段生成图像与文本描述不相符的问题。
针对上述问题,本文提出了一种基于多模态融合的文本生成图像方法,在图像特征提取和文本描述提取时采用通道注意力来突出重要信息,同时将提取出的文本特征和图像特征用双线性池化[12]进行融合,从而得到文本信息和对应图像信息之间的映射关系。
1 相关工作
1.1 通道注意力机制
近年来,通道注意力在视觉处理[13]等任务得到广泛应用,其基本原理是通过对每个特征通道进行加权,来突出关键信息、抑制无效信息,从而达到提高特征表示能力的目的。Hu 等人提出了SENet[14],SENet使用全局损失函数来自适应地调整每个通道的权重,SENet 在图像分类方面效果显著。
1.2 多模态融合注意力机制
AttnGAN 中加入了注意力来提升文本生成图像的质量,但是,文本信息和图像信息之间的交互对于文本生成图像是至关重要的,特别是文本特征和图像特征之间的联系以及对齐。最近,双线性池化(MFB)在视觉问答方面表现出很好的效果,视觉问答需要做的是同时理解图像内容和文本内容,文本生成图像同样也需要理解图像内容和文本内容,因此,采用MFB 将文本信息和图像信息进行融合编码,这种多模态融合编码能够有效提升生成图像的质量。
1.3 文本生成图像方法
文本生成图像主流的方法是使用堆叠式网络来生成高质量的图像。Zhang等人[9]提出了StackGAN,采用了2 个堆叠的生成器,第一阶段关注图像的背景、轮廓等基本信息,生成低分辨率的64∗64 像素的图片,第二阶段弥补之前缺失的细节和纹理等高级特征,生成256∗256 高分辨率的图像。Xu 等人[10]提出了AttnGAN 模型,该模型在生成网络中引入了自注意力机制,AttnGAN 实现了单词与图片中的某个子区域的对应,自动选择字级条件以生成图像不同子区域。2019年,Qiao 等人[15]提出了MirrorGAN 来实现图像到文本,文本到图像的双重映射。Zhu 等人[11]提出的DMGAN 通过引入动态记忆化机制来使得初始图像自适应地选择重要的文本信息。然而现有的对文本编码的方式,没有考虑到文本信息与对应图像之间的映射关系,导致第一阶段生成的图像和输入文本的不匹配,也会导致后面两级图像的优化受到影响。因此,本文基于DM-GAN 网络进行改进,在图像特征提取和文本描述提取时采用通道注意力来突出重要信息,在预训练文本编码器时引入了双线性池化,将文本特征和图像特征进行联合编码后,输出一个新的融合后的特征向量,新的特征向量学习到图像和文本之间的关系,因此可以生成更加真实的图像。
2 基于多模态融合的生成对抗网络
MLT-GAN 模型框架如图1 所示。由图1 可知,本文设计的MLT-GAN 由预训练编码器、生成对抗网络和动态存储三个模块构成。多模态融合注意力机制用于预训练编码器,是将文本特征输入到多模态融合编码器中,多模态融合编码器将输出特征向量fc和单词特征矩阵W。随机噪声和多模态融合注意力向量相结合,输入到生成对抗网络中,三级生成器逐级生成高分辨率的图像。单词特征矩阵W主要是用来在动态存储模块中和初级图像特征进行融合来生成下一级的图像特征。上述过程的数学方法公式分别如下:
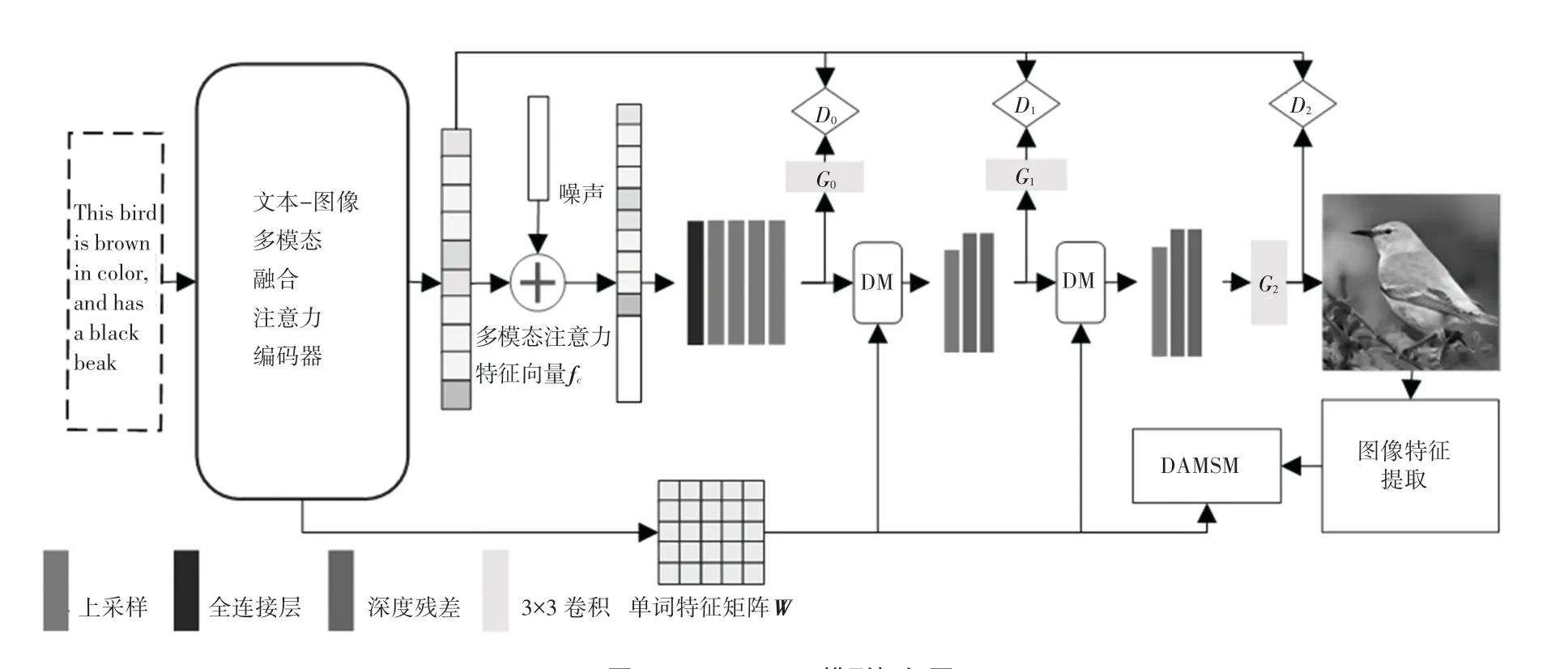
图1 MLT-GAN 模型框架图Fig.1 MLT-GAN model framework diagram
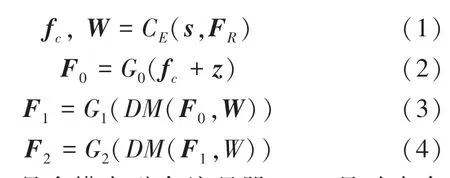
其中,CE是多模态融合编码器;DM是动态存储模块;原始图像特征是FR;G0,G1,G2表示三级生成器;s是从文本描述中提取的全局句子向量;F0,F1,F2是G0,G1,G2生成的图像特征;z是随机高斯噪声。
2.1 多模态融合注意力编码
本文设计了一种多模态融合编码器来将图像信息和文本信息进行联合编码和对齐。
多模态融合编码器框架如图2 所示。由图2 可看到,多模态融合编码器由4 部分组成,包括文本特征提取、图像特征提取、通道注意力编码和多模态融合注意力编码。对此拟展开研究分述如下。
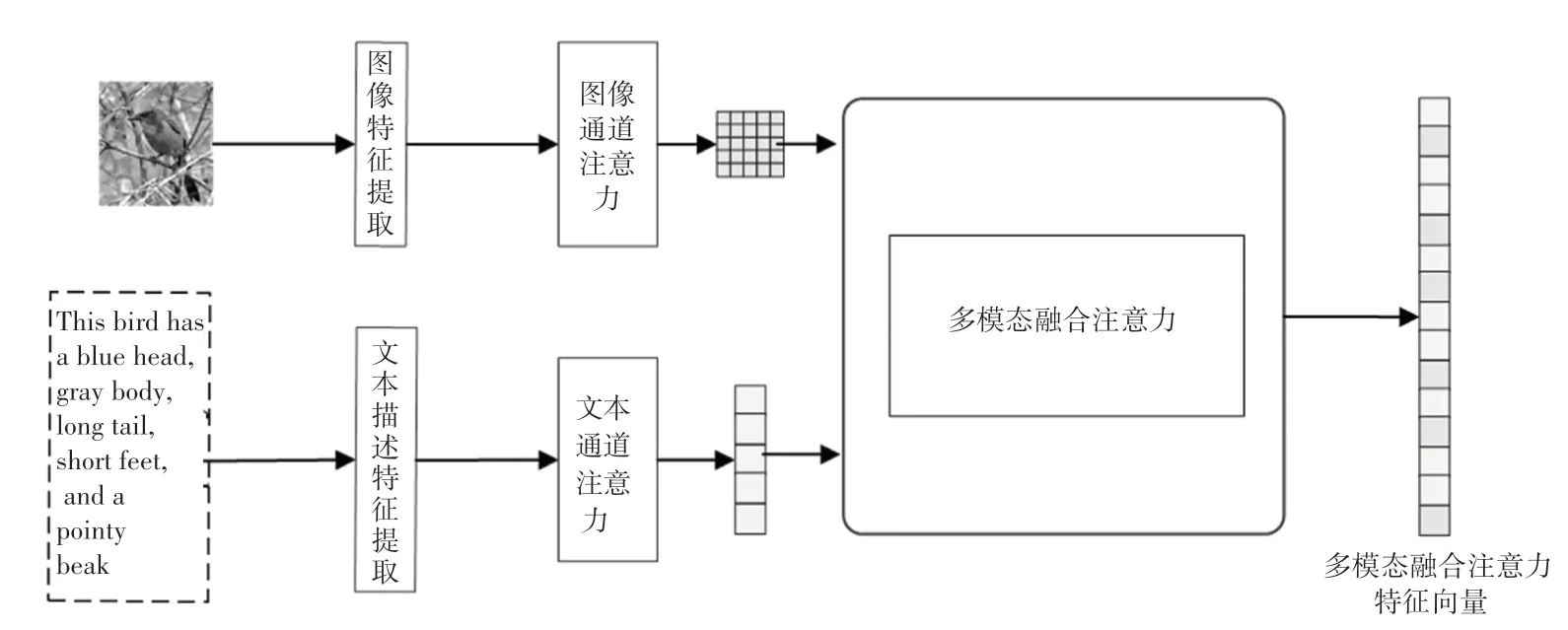
图2 多模态融合编码器框架图Fig.2 Multimodal fusion encoder framework diagram
(1)文本特征提取。提取文本特征用的是双向长短时网络[12](LSTM),双向长短时网络是将文本描述进行编码,输出一个单词特征矩阵Wd∗t和全局句子特征向量s。推得的数学公式为:

其中,t表示单词的个数;d表示词向量的维度;Ttext表示原文本描述;TE表示双向LSTM 网络。
(2)图像特征提取。图像特征提取采用InceptionV3 模型[13]。此处需用到的公式为:

(3)通道注意力编码。为了突出图像特征和文本描述特征中的重要信息,引入通道注意力,将特征提取后的图像特征图和文本特征向量输入到通道注意力中,采用通道注意力对图像特征图和文本特征向量进行加权,使得生成的图像多样性更加丰富。图像通道注意力和文本通道注意力如图3、图4 所示。

图3 图像通道注意力模块Fig.3 Image channel attention module
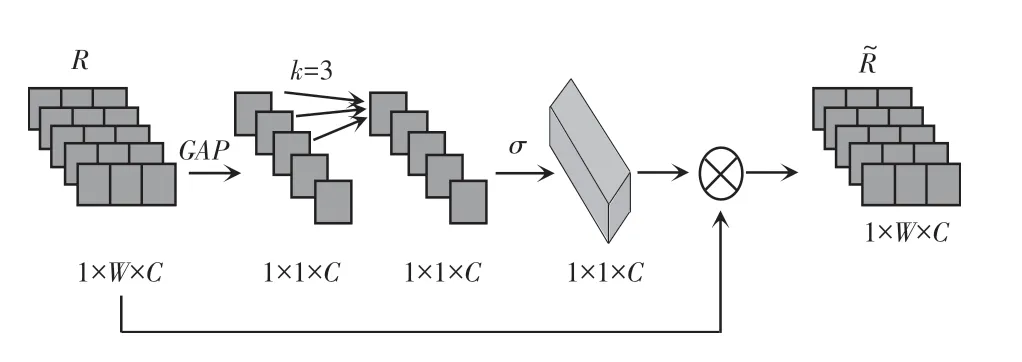
图4 文本通道注意力模块Fig.4 Text channel attention module
在通道注意力模块中,权重w的计算如下:
其中,y=GGAP(R),是通过对输入的特征图经过平均池化后得到;σ是Sigmoid函数;Q是权重矩阵。
假定接受的特征图R∈RW×H×C,W、H、C分别表示特征图的宽度、高度和通道维度。全局平均池化的计算公式如下:
权重矩阵Q的尺寸是k × C,针对每一个通道yi,对应的权重wi,仅需考虑相邻的k个通道的相应加权(本文设置的是3),如下式所示:


(4)多模态融合注意力编码。多模态融合注意力编码主要是将文本特征和图像特征的内部联系搭建起来,实现两者的联合编码。经过通道注意力的图像特征和全局句子特征s′通过多模态融合注意力编码后,融合成一个新的特征fc,本文采用的多模态融合注意力编码方法是双线性池化(Bilinear Pooling)。数学函数形式见如下:
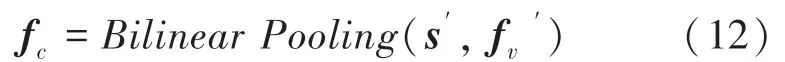
双线性池化具体细节如图5 所示。由图5 可看到,双线性池化可以分解为2 个阶段,首先,不同模态的特征被扩展到高维空间,然后进行元素相乘,接着经过总和池化获取向量的全局特征,再通过归一化层来将高维特征进行压缩输出。
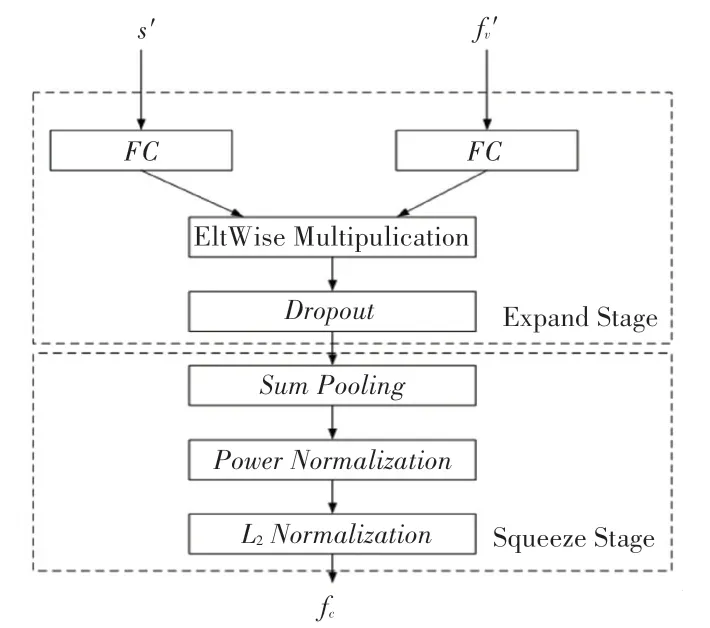
图5 双线性池化Fig.5 Bilinear pooling
2.2 经典三级生成对抗网络
由图1 可知,MLT-GAN 模型采用了和StackGAN、StackGAN++、AttnGAN、DM-GAN 相类似的三级对抗生成网络,分别为G0/D0,G1/D1,G2/D2。G0由一个大小为3∗3 的卷积层、3 个上采样层和一个全连接层组成,第一阶段生成64×64 分辨率的图像;第二阶段G1和G2在G0的基础上进行优化,分别生成128∗128 分辨率的图像和256∗256 分辨率的图像,两者的结构一致,由2 个深度残差网络层、1 个上采样层和1 个大小为3∗3 的卷积网络层组成。
2.3 动态存储记忆模块
动态存储模块存在于生成器G0与G1,生成器G1与生成器G2之间,该模块的作用是在初始图像的生成上,基于动态内存将图像质量进行进一步的细化。动态存储模块框图如图6 所示。图6中,动态存储记忆模块由4 部分组成,分别为:内存写入、键寻址、值读取、响应。研究对此将给出探讨论述如下。
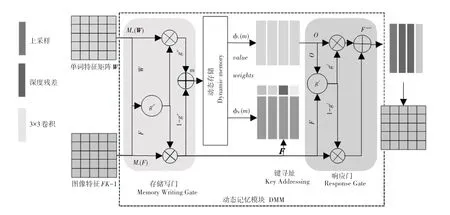
图6 动态存储模块框图Fig.6 Dynamic storage block diagram
(1)模块的输入是:
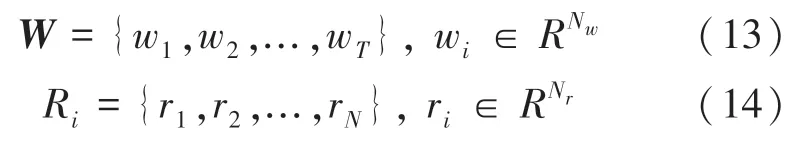
其中,W表示单词特征矩阵;Ri表示图像特征;R0表示初始图像特征;R1表示第二级图像特征;R2表示第三级图像特征;T表示单词个数;Nw表示单词特征维数;N表示图像像素个数;Nr表示图像像素特征矩阵的维度。
(2)内存写入门。主要通过内存写门来实现,通过选择相关单词来细化初始化图像,对此可表示为:
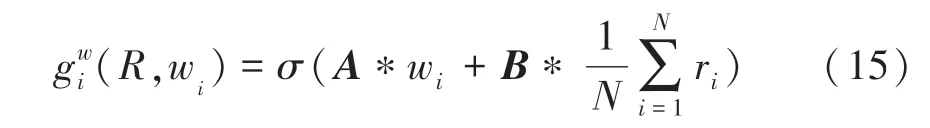
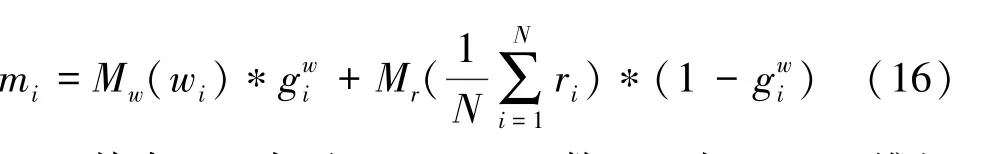
其中,σ表示sigmoid函数;A为1∗Nw维矩阵;B为1∗Nr维矩阵;Mw(·)和Mr(·)表示1∗1的卷积操作,Mw(·)和Mr(·)是以Nm维度把文字特征和图像特征嵌入到同一个特征空间中。
(3)键寻址过程。在这一步中,使用密钥存储器检索相关的存储器,计算每个内存槽的权重,作为内存槽mi与图像特征rj的相似概率,可由如下公式来求值:
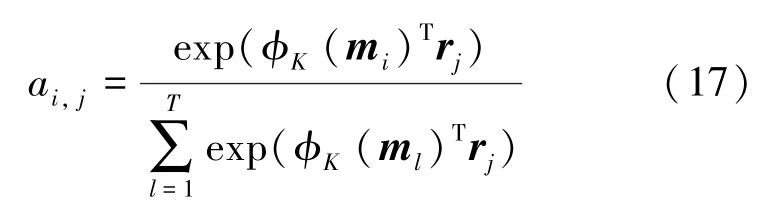
其中,ai,j表示第i个内存和第j个图像特征的相似度,φK()是1∗1 的卷积网络,目的是将内存特征映射到Nr维度。
(4)值读取过程。输出记忆表示定义为根据相似概率的记忆加权求和,数学定义公式具体如下:
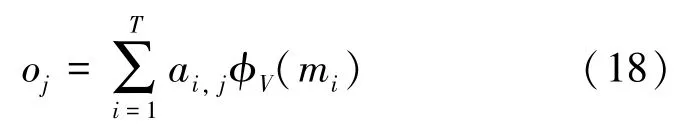
其中,φV()为值内存访问进程,将内存特性映射到Nr维数,φV()实现1∗1 的卷积操作。
(5)响应门。是用来完成响应步骤的,响应门是通过利用门控机制来及时控制信息以及图像信息的更新。可由如下公式进行描述:

2.4 损失函数
MLT-GAN 的损失函数由2 部分组成,分别为生成器损失函数和判别器损失函数。文中对此可做阐释解析如下。
(1)生成器损失函数L。由3 部分组成:分别为条件损失函数LCA、生成损失函数和深度多模态相似模型损失函数(DAMSM)LDAMSM。即可由下式来计算:

其中,λ1和λ2分别为条件损失LCA和深度多模态相似模型损失函数LDAMSM的权重。
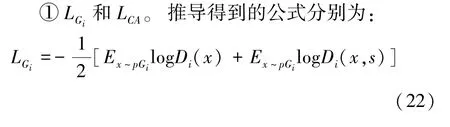
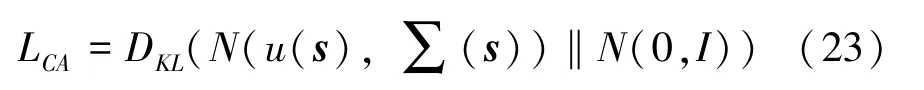
其中,u(s)是句子特征的均值,∑(s)是句子对角协方差矩阵。u(s)和∑(s)由全连接层计算,式(22)中,第一项是无条件损失,目的是使得生成的图像尽可能真实,第二项是条件损失,目的是使得图像与输入的句子相符合。条件损失LCA用来防止过拟合。
②LDAMSM。DAMSM 损失函数用来衡量图像和文本描述的匹配程度,DAMSM 损失函数使生成的图像更好地适应文本描述。
(2)判别器损失函数。由条件损失LCD和非条件损失LD组成,具体公式如下:

其中,
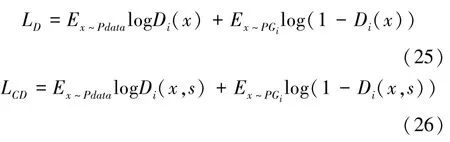
其中,无条件损失LD是用来区分生成的图像和真实图像,条件损失LCD是用来判断输入的句子和图像是否符合。
3 实验
3.1 实验数据集
本文在Coco[16]和CUB[17]两个数据集上分别进行了训练和测试。其中,CUB 数据集是专门针对鸟类图像的数据集,CUB 数据集收录了200 种鸟类,数据集包括鸟类图片和对应的文本描述。Coco 数据集包含了复杂场景、丰富的类别,共有80 个类别,数据集的具体情况见表1。

表1 数据集Tab.1 The experimental dataset
3.2 实验过程
本文在公开数据集Coco 和CUB 数据集上训练和测试了MLT-GAN。
实验共由3 步组成,第一步预训练多模态融合编码器,第二步训练整个模型,第三步测试整体模型的性能效果。对此内容可做重点论述如下。
(1)预测训练多模态融合编码器。通过不同的任务预训练多模态融合编码器,来得到每个任务中文本信息与图像信息之间的关系,可以得到对应此任务的文本与对应的图像的融合编码,运行的结果是保存训练好的编码器模型。
(2)训练整个模型。在整个模型训练过程中,首先加载已经过训练并保存了的编码器模型,接着单独训练MLT-GAN 模型的剩余部分。
(3)测试整个模型的性能效果。分别在Coco数据集和CUB 数据集上进行测试,本文的MLTGAN 均生成了30 000张逼真图像,通过计算相应的IS分数和FID分数,来衡量本文提出的MLT-GAN模型的性能好坏。
3.3 评价指标
本文采用FID[18](Frechet Inception Distance)和IS[19](Inception Score)分数来衡量MLT-GAN 的性能。对此,文中将进行研究表述见如下。
(1)IS。IS值越高,表示生成图片的多样性和品质就越好,IS的公式如下:
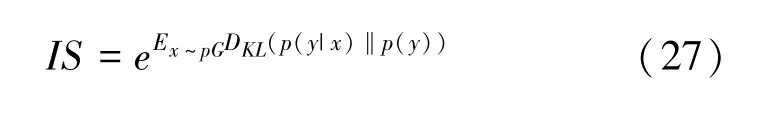
其中,p(y |x)是预训练图像编码器预测的对应标签y的条件概率,p(y)则是预训练图像编码器预测的对应标签y的边缘概率。
(2)FID得分。是指真实图像与虚假图像之间在特征方面的距离,当真实图像与虚假图像特征越近时,FID值就越小。其计算方法为:

3.4 实验结果
3.4.1 定量评价
本文从定量评价和定性评价两个方面来评估MLT-GAN 模型的性能。本文使用在Coco 数据集和CUB 数据集的测试集中生成的30 000 张图像来计算FID分数和IS分数,并与一些主流的对抗生成网络进行了对比,实验结果见表2、表3。

表2 不同模型在CUB 数据集上的FID和IS 分数Tab.2 FID and IS scores of different models on the CUB dataset
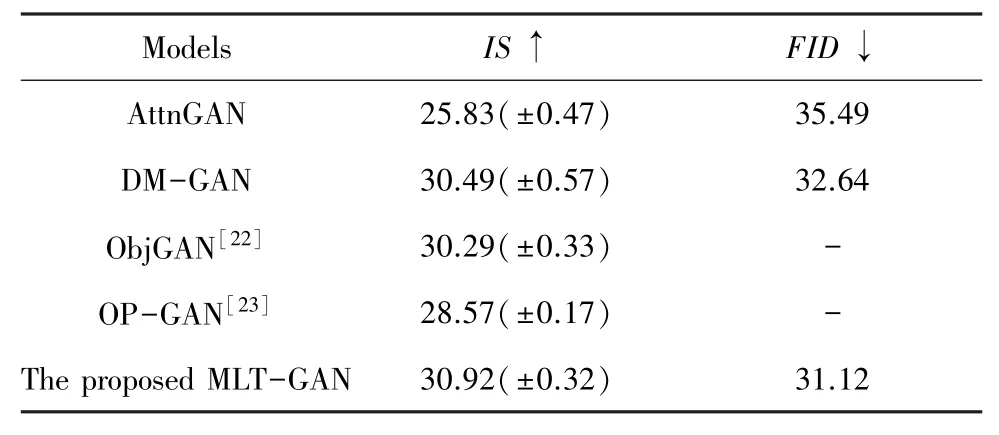
表3 不同模型在Coco 数据集上的FID和IS 分数Tab.3 FID and IS scores of different models on the Coco dataset
表2 列出了MLT-GAN 与部分主流的对抗生成网络在CUB 数据集上的FID和IS分数。与本文的基础网络DM-GAN 模型相比,本文设计的MLTGAN 网络的IS分数从4.75 提高到4.83,可知提升了2.11%,DM-GAN 模型的FID分数为16.09,而本文提出的MLT-GAN 模型的分数为15.26,显然有所下降,说明本文提出的MLT-GAN 模型生成的鸟类图像在图像质量和清晰度上有了明显的改善。
表3 列出了MLT-GAN 与部分主流的对抗生成网络在CUB 数据集上的FID和IS分数。与本文的基础网络DM-GAN 模型相比,本文设计的MLTGAN 网络的IS分数从30.49 提高到30.92,DMGAN 模型的FID分数为32.64,而本文提出的MLTGAN 模型的分数为31.12,已出现明显的下降,说明本文提出的MLT-GAN 模型生成的鸟类图像在图像质量和多样性上有了一定的改善。
通过上述实验的定量的分析可得,本文提出的MLT-GAN 模型所生成的图像质量和清晰度比其他方法生成的图像质量和图像清晰度有了一定的提升,生成图像的内容也更加接近真实的图像,证明了本文提出的MLT-GAN 模型在文本生成图像任务中具有良好的效果。
为了进一步检验本文所述的通道注意力机制和多模态融合注意力机制在提高模型性能方面的作用,本文将基础网络DM-GAN 上加入通道注意力模块,将其命名为TDM-GAN,将基础网络DM-GAN上加入多模态融合注意力模块,将其命名为MDMGAN,将本文提出的MLT-GAN 同其进行对比,实验结果见表4、表5。
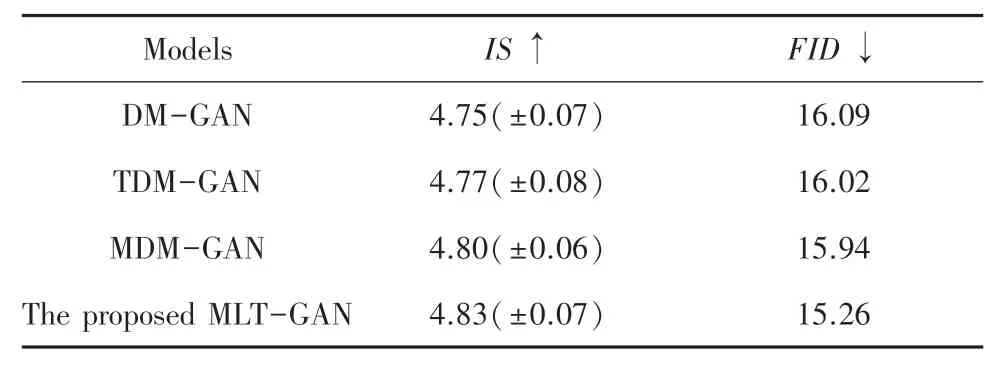
表4 不同模型在CUB 数据集上的消融实验Tab.4 Ablation experiments of different models on CUB datasets
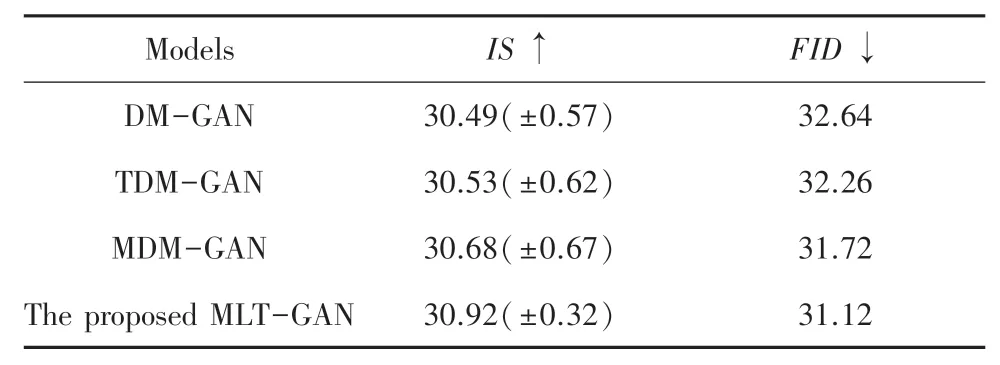
表5 不同模型在Coco 数据集上的消融实验Tab.5 Ablation experiments of different models on Coco datasets
根据表4、表5 给出的实验结果可以得到,本文提出的MLT-GAN 比去除了通道注意力和多模态融合注意力模块的网络效果更好。
3.4.2 定性评价
为了更加直观评价MLT-GAN 的性能,本文以示例的形式将MLT -GAN 模型生成的图像和AttnGAN 网络模型、DM-GAN 网络模型生成的图像进行对比,对比结果如图7、图8 所示。
图7 是CUB 数据集上3 种模型生成的部分图像。从图7 中可以看出,AttnGAN 和DM-GAN 生成的图像实物和背景的边界不清晰,存在模糊区域,忽略了鸟类图像的一些细节特征,图像的分辨率不高,而本文提出的MLT-GAN 生成的鸟类图像背景与实物背景分明,生成的图像分辨率高且具有更多的细节特征。

图7 AttnGAN、DM-GAN、MLT-GAN 在CUB 数据集上生成的图像Fig.7 Generated images of the AttnGAN model、DM-GAN model and MLT-GAN model on the CUB dataset
图8 是3 种模型在Coco 数据集上生成的部分图像。从图8 中可以看出,AttnGAN 模型生成的图像轮廓不完整,图片中具体的场景很难识别,DMGAN 模型生成的图像质量相较于AttnGAN 有了一定的提升,但是生成的图像内容残缺,捕捉到的细节特征不够明显,图片的质量有待提高。而本文提出的MLT-GAN 模型生成的图像存在较少失真,图像内容结构完整,轮廓清晰,文本描述中的细节和纹理的重点得以突出,图像质量得到显著提高。

图8 AttnGAN、DM-GAN、MLT-GAN 在Coco 数据集上生成的图像Fig.8 Generated images of the AttnGAN model、DM-GAN model and MLT-GAN model on the Coco dataset
4 结束语
本文提出了一种基于多模态融合的文本生成图像方法(MLT-GAN),通过在预训练编码阶段引入通道注意力和多模态融合注意力来对文本信息和图像信息进行融合编码,从而捕捉到文本特征和视觉特征之间的内在联系,提升了图像的质量。实验结果表明,在Coco 数据集和CUB 数据集上,相较于DM-GAN 模型,本文提出的MLT-GAN 模型的FID分数降低了4.66%和5.16%,IS指标提高了1.41%和1.68%。本文提出的MLT-GAN 在CUB 数据集和Coco 数据集,相较于基础网络DM-GAN 和单独添加了通道注意力的TDM-GAN 以及单独添加了多模态融合注意力的MDM-GAN 都有一定的提高,因此,本文提出的MLT-GAN 在文本生成图像任务中具有良好的效果,生成图片的质量得到显著提高。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小雪花·成长指南(2022年1期)2022-04-09
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
制造技术与机床(2017年7期)2018-01-19
传媒评论(2017年3期)2017-06-13
西安工程大学学报(2016年6期)2017-01-15
第二课堂(课外活动版)(2016年2期)2016-10-21
探测与控制学报(2015年4期)2015-12-15
