
无监督学习三元组用于视频行人重识别研究
2022-12-11 09:42蔡江琳韩华王春媛潘欣宇芮行江
智能计算机与应用 2022年11期
蔡江琳,韩华,王春媛,潘欣宇,芮行江
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引言
行人重识别的目的是在配备多台摄像机、且视野不交叉的环境中找到具有相同身份的目标行人。当目标行人穿过某台摄像机视野时,可以在另一台摄像机下找到相同身份的人。当前的行人重识别多是基于2 类:基于图像的行人重识别[1-7]和基于视频的行人重识别[8-12]。从传统的特征提取方法和度量学习方法、到利用卷积神经网络训练模型,基于图像的行人重识别模型已经取得了很高的识别准确度。但在实际的监控视频中,由于行人的许多不确定因素,例如光照、遮挡、姿态变化等,导致监控跟踪失败,基于图像的二维特征很难解决这些问题。而不同于图像重识别的是,基于视频的行人重识别的研究对象是行人轨迹,包含了行人更多的时空信息,连续的帧图像之间有着密切联系。当前基于视频的行人重识别技术已取得有效的成果。例如,Times Shift Dynamic Warping(TSDTW)[13]模型通过对每个行人的时空动态信息进行编码来生成一种潜在的特征表示,解决不准确和不完整序列的选择和数据匹配问题。又如一种顶推度量学习模型[9],是通过优化最小类内的变化来提高top rank 中行人重识别的准确度。再如,采用一种视频排序函数[14]方法,在排序的同时可以从含噪或者不完整的视频序列中选择可靠的时空特征。上述的视频重识别技术多是采用有监督的学习方法,但是在实际的场景中,往往不具有可测量性和实际性。为此,基于半监督[1,12]和无监督[13-19]的学习方法开始得到更多的关注。
当前由于无监督学习存在的一些固有性质,导致无监督模型的性能比有监督模型差。而事实上,这些基于视频研究的无监督模型不能有效地利用深度卷积神经网络[20](deep Convolutional Neural Networks)强大的特征学习能力,获取具有表达性的特征和具有判别力的匹配模型。主要是因为无标签数据集中并不具备有效的监督信息供模型训练。在基于深度神经网络的行人重识别中,常用三元组损失函数作为度量模型损失的方法。而对于无监督学习则需要模型自主挖掘三元组用于损失计算。本文中,基于无监督学习挖掘三元组方案的主要内容有:
(1)单相机内的时空一致性,每条行人轨迹中的图像都属于同一个ID,目的是利用构成轨迹的图像更新轨迹特征。
(2)从无标签数据集中挖掘三元组,设计一种自适应加权的条件、即三元组损失函数,动态调整正负样本对之间的距离,提高模型性能。
1 方法
1.1 单相机关联学习
单相机内关联学习的目的是为了学习具有判别力的单相机轨迹特征。基于单相机内的时空一致性如图1 所示。

图1 单相机内的时空一致性Fig.1 The spatio-temporal consistency with a single camera
研究中,将图1 中的行人轨迹定义为源轨迹,假设摄像机k下有Nk条小片段轨迹,则所有锚样本轨迹的特征集合为构成源轨迹中的任一帧图像特征表示为xk,p。而单相机内的时空一致性则意味着来自同一条轨迹的大多数图像都表示同一个行人,因此构成源轨迹中的任一帧图像与该轨迹间的特征距离会比该帧图像与其它轨迹间的特征距离小。
1.1.1 轨迹特征表示方法
由图1 可知,这里的行人轨迹是由连续的图像帧构成。每条轨迹包含了同一行人的多张连续图像,为此可以提取行人丰富的时空信息,使学习到的行人特征更加具有表达力。当前的许多轨迹特征处理方案多是利用卷积神经网络中的时间池化层,例如最大池化层[21](max-pooling)、或是平均池化层[10](mean-pooling),将小片段轨迹表示成一种序列级的特征。但是,这种方法在网络学习的过程中需要大量的计算成本,因为每个小批量学习迭代中都要用到前馈(feed-forward)轨迹中的所有图像,会造成时间浪费。为此,在模型训练过程中,将小片段轨迹表示成ak,i,并采用指数滑动平均的方法(EMA),通过构成该轨迹中的任意帧图像xk,p来更新轨迹特征。进而推得的数学公式可写为:
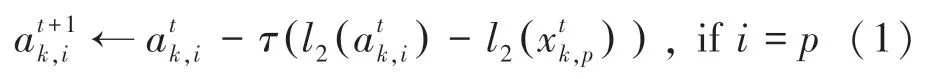
其中,i=p表示更新轨迹的图像是源轨迹中的任意帧图像;t表示小批量样本集训练迭代的次数;τ是向EMA 提供的衰减率参数,通常用来控制模型的更新速度相当于一个影子变量,其初值可表示为构成ak,i这条轨迹的所有图像帧的特征均值,最终目的是获取更新后轨迹特征值
由于轨迹特征ak,i和图像特征xk,p之间存在尺度和单位的差异,研究中采用l2对其进行归一化,例如,采用指数滑动平均的算法来更新轨迹,究其原因就在于对滑动窗口中的值求平均时,前面的值都是呈指数衰减的,导致原来的值对更新后的值产生的影响减少,而最近的值权重更大,从而使滑动均值只与最近的迭代有关系。当ak,i初始化为所有图像的特征均值并根据式(1)进行迭代更新时,单相机内的锚样本会伴随着模型学习的过程持续学习来表示每条轨迹。
1.1.2 关联排序
在模型学习的过程中,逐渐更新摄像机k内的Nk轨迹特征。由式(1)获取所有锚样本轨迹集合为要搜索的目标行人图像为xk,p,为了找到和目标图像xk,p最近邻的轨迹特征,将目标图像与摄像机k内的所有轨迹进行关联,计算彼此间的相似程度,并进行排序,得到一个排序列表,再找到与目标图像距离最近的轨迹特征。
本节将使用标准的l2度量方法,对图像特征和轨迹特征进行标准化后将计算两者间的特征距离。计算目标图像与所有锚样本轨迹间的特征距离,这里需用到的数学公式可写为:

1.1.3 挖掘三元组和损失函数设计
在本节中,采用一种特殊的三元组损失函数来评估模型性能。在训练过程中起到一种类似顶推(top-push)的作用。单相机关联学习过程如图2 所示。图2中,使rank -1 的轨迹ak,t能够对应于目标图像所在的轨迹ak,p,即p=t。

图2 单相机关联学习过程Fig.2 The process of intra-camera association learning
传统的三元组损失函数是由FaceNet[23-24]提出,包括:锚样本xa、即要寻找的目标样本,与目标样本具有相同身份的正样本xp,与目标样本不具有相同身份的负样本xn,此处的数学公式具体如下:
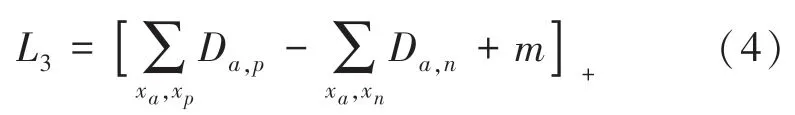
其中,[·]+=max (0,·) ;Da,p表示目标样本与正样本之间的特征距离;Da,n表示目标样本与负样本之间的特征距离;m是给定的阈值,可以使目标样本与正样本之间的最大距离远小于目标样本与负样本之间的最小距离。
为了在训练过程中学习更好的特征,充分挖掘各个样本对之间潜在的关联性、从而提取更加鲜明的行人特征,为此引入一种自适应加权的方法,将损失函数中的各个样本对距离加上相应的权重来训练模型,图3 给出的就是样本权重描述。则一般加权三元组的数学计算公式见如下:
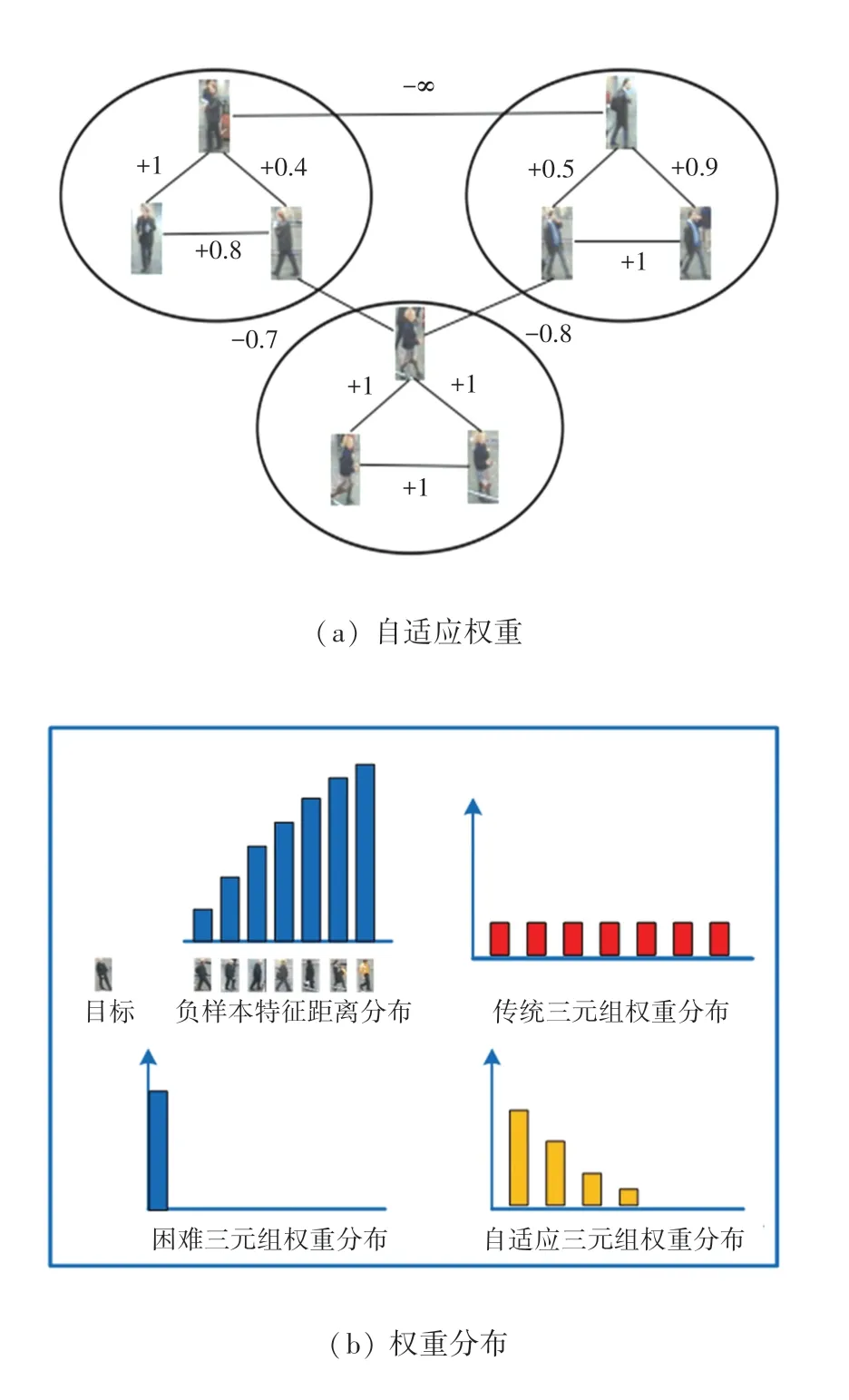
图3 样本权重Fig.3 Illustration of weights
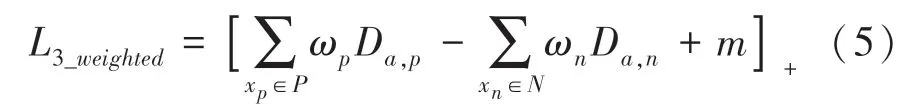
其中,xp∈P表示正样本集,xn∈N表示负样本集。
而由Hermans 等人提出的困难三元组损失[21],仅考虑正负样本时,对应的权重可以写成:
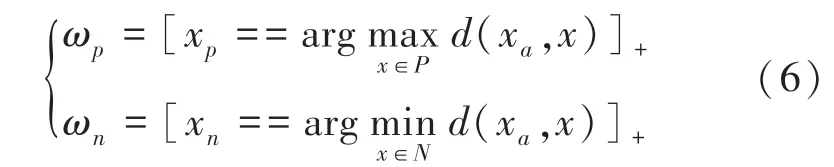
其中,最困难正样本是指视觉上看不是同一个人、但实际是相同身份的行人,则两者之间的特征距离会最大。最困难负样本是指视觉上看是同一个人、但实际上不是相同身份的行人,则两者之间的特征距离将会最小。这种方法可以有效避免在训练过程中由于简单样本的影响使训练陷入了较坏的局部最小值。而传统的权重统一的三元组损失在模型训练过程中对异常值较鲁棒,为此拟结合这2 种损失的优越性,来设计本节的三元组损失函数。
由于该模型是基于无监督的一种端到端的训练模式,因此没有预先标记的成对行人标签。为此要先找到对应的三元组,从而设计损失函数。此后的设计过程可做研究阐释如下。
由式(2)可以得到,摄像机k内所有锚样本轨迹与目标图像xk,p之间的特征距离为了确定对应的正负样本,利用式(3)找到rank -1 的轨迹ak,t,并且在理想状况下可认为ak,t对应xk,p所在的轨迹ak,p。那么如果p=t,则rank -1 轨迹ak,t就是轨迹ak,p,对应目标图像xk,p为正样本集;如果p≠t,则rank -1 轨迹ak,t不是轨迹ak,p,对应目标图像xk,p为负样本集。基于此,单相机内三元组损失可进一步剖析阐述如下。
(1)当p≠t时。损失函数为:

(2)当p=t时。三元组对应的正样本为ak,p,并且从小批量数据中随机采样M帧图像作为负样本,则损失函数为:

式(7)~式(8)是基于关联排序,由rank -1 判断三元组而设计的损失函数。为了挖掘轨迹中图像之间潜在的关联性,提取更鲜明的轨迹特征,根据目标图像与正负样本之间特征距离的大小来自适应加权训练模型,模型参数可由如下公式计算求得:
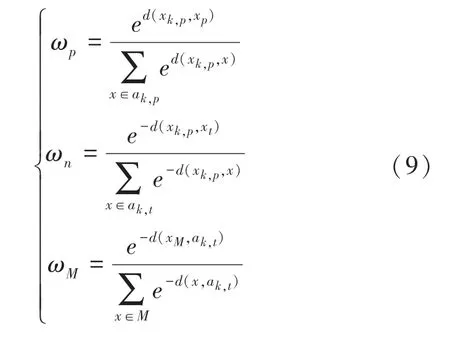
由式(9)可以看出,对于正样本,在计算ωp时,困难的样本与目标样本间的特征距离大,则分配的权重会大,模型训练时会更加注重困难样本学习;而简单的样本与目标样本间的特征距离小,分配的权重也会小。对于负样本,在计算ωn和ωM时,困难的样本与目标样本间的特征距离小,在设计时指数变成负号,从而保证分配给困难样本的权重更大。
此外在单相机内关联学习的过程中,每个小批量样本迭代时,都要对样本集中的图像进行采样计算LI_weighted,并持续更新锚样本轨迹集合,当数据集规模较大时,会造成计算资源和时间的浪费,这里采用了典型的随机梯度下降法来优化模型训练。
综上所述,这种设计的关联学习方案,在无标签数据集的前提下,可以采用一种端到端的深度学习方式。将单相机内的任意轨迹初始化为构成轨迹的帧特征的均值,以此减少计算成本,采用指数滑动平均的方法在批量迭代学习的过程中持续更新轨迹,保证轨迹特征与最近迭代的特征相关;对所有锚样本轨迹集合进行排序,确定rank -1 轨迹,并作为判断三元组的关键条件;在rank -1 轨迹的条件下,确定三元组,由此设计损失函数,并引入自适应权重挖掘样本间潜在的关联性,在批量学习中能够动态调整正负样本间的特征距离,可以加速模型的收敛速率,避免过拟合的风险,提高模型的鲁棒性。为此,这种方案能够有效学习单相机下具有判别力的轨迹特征,从而促进跨相机下轨迹关联的效率。
1.2 挖掘跨相机三元组锚样本和损失计算
由式(2)得到单相机内的轨迹排序列表详见图3。在模型迭代过程中,采用如下方式连接2 台摄像机k,l下的轨迹,作为跨相机关联学习的锚样本,即:
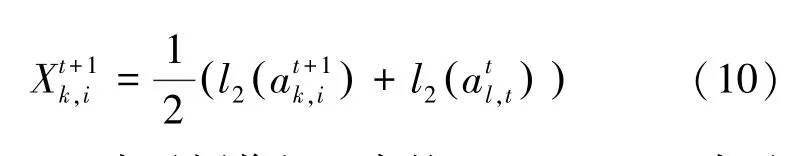
其中,ak,i表示摄像机k中的rank -1;al,t表示摄像机l中的rank -1;t表示样本集训练迭代的次数。

其中,DXp,p表示要查询的目标图像xk,p与跨相机关联的轨迹Xk,p之间的特征距离,而Xk,p即是由式(10)获得的与源轨迹ak,p关联的轨迹特征。ωn与ωM即是由式(9)获得。这种三元组损失函数将会有助于该深度模型推进跨相机下最匹配的轨迹合并成含有丰富信息的跨相机锚样本,并且此种关联的轨迹特征将有效对应于要寻找的目标图像特征。
1.3 联合优化关联损失
在模型训练中,还要知道模型识别的差异,通过联合单相机关联损失LI_weighted与跨相机关联损失LC_weighted作为模型训练的最终损失,数学计算公式为:
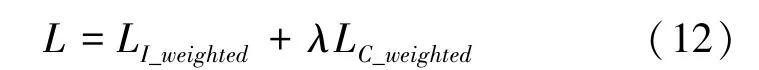
其中,λ是一个平衡参数。
在模型训练中,单相机内的轨迹特征学习见图2。随着模型的训练更新,要搜索的目标图像与源轨迹之间的关联程度更深,能够有效判别轨迹,从而增强跨相机下轨迹的关联程度,有效提高跨相机内的关联学习。因此,为了使模型对2 种关联学习的程度一致,这里将λ设置为1。
2 实验结果和分析
2.1 实验设置
本文采用标准视频数据集iLIDS-VID[23]、PRID2011[24]和MARS[10]来评估算法模型。文中的数据参数见表1。
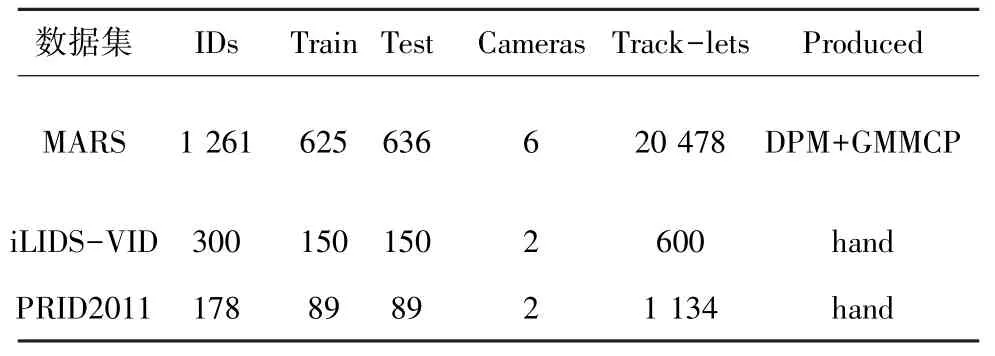
表1 数据集参数Tab.1 Parameters for the datasets
在MARS 数据集中共有20 478条行人轨迹,包括1 261个行人,每个行人至少穿过2 台摄像机视野。在6 台摄像机部署的监控环境下采集的行人轨迹更加贴近实际的监控场景,包含更多的未知变化。在iLIDS-VID 数据集中共有300 个行人,包含600条轨迹,在不同的摄像机下共有2 条轨迹,每条轨迹由23~192 张不等的连续图像构成,平均会有73 张图像。在PRID2011 数据集中共有178 个行人,包含1 134条轨迹,每条轨迹由5~675 帧图像构成。
本文中,将MARS 数据集中的625 个行人的轨迹用来训练,其余的636 个行人的轨迹用来测试模型。将iLIDS-VID 中的行人平均划分作为训练集和测试集。对于PRID2011,采用传统的分割方案,将178 个行人平均划分用来训练和测试,每条轨迹至少包含27 帧图像。
本文中采用累积匹配特性CMC值来评估基于iLIDS-VID 和PRID2011 算法的性能,学习过程中将行人标签随机划分,重复10次,确保统计结果稳定。采用CMC和平均精度均值map来评估基于MARS算法的性能。
仿真实验是基于Linux 系统,搭建GPU 版的Tensorflow[25]框架,使用Python 编写完成的。利用基于ImageNet[26]预训练的参数初始化该深度模型。为了保证采样的小批量集中都包含所有摄像机下的行人,将batch_size设置为128。对于较大规模的数据集MARS,设置迭代次数为2×105,并采用随机梯度下降(Stochastic Gradient Descent,SGD)的方法训练模型。将初始化学习率设置为0.01,当模型迭代剩下5×104时,学习率下降为0.001。自适应加权训练模型,为了避免被零除,在实验中,将权重衰减速率设为e-6。对于较小规模数据集iLIDS-VID 和PRID2011,将学习率初始为0.045,设置迭代次数为4×104,采用RMSProp 优化器[27]优化模型时,设置指数衰减为每2个epoches为0.94。此外,则根据经验将2 种关联损失的阈值m设为0.2。在测试阶段,研究获取的轨迹特征是遵循l2标准化。对跨相机下轨迹间的l2距离进行计算,作为相似度测量的标准,用于视频行人重识别中。
2.2 结果和分析
基于ImageNet 预训练参数来初始化本文模型,采用典型的MobileNet[28]网络作为本文模型的骨干网络。对此过程可给出探讨论述如下。
(1)本文设计的自适应加权损失与其它损失对比。为证明本文优化的自适应加权三元组损失函数能够有效提高模型的准确度,基于标准数据集PRID2011、iLIDS-VID 和MARS(这里的各数据集皆为rank -1 轨迹),与使用权重一致的传统三元组损失函数和困难样本权重的三元组损失函数做对比,说明本文采用自适应加权的方法更适用于行人重识别研究。比较结果见表2,CMC曲线如图4 所示。
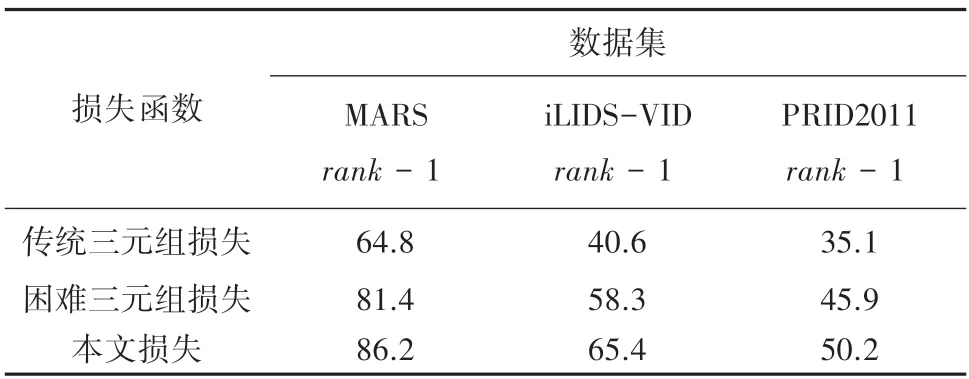
表2 不同关联损失之间的比较Tab.2 Comparisons between different association loss
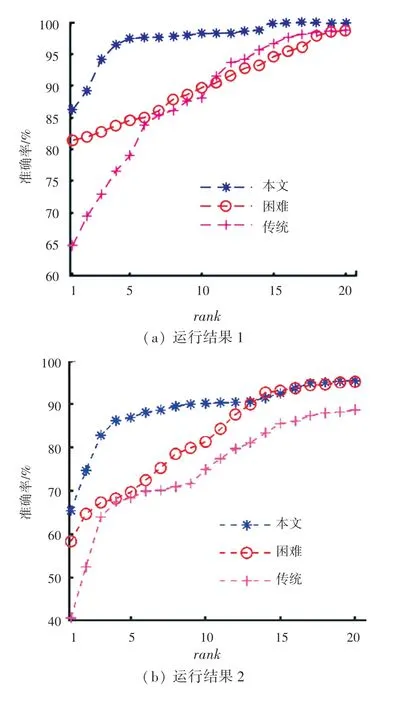
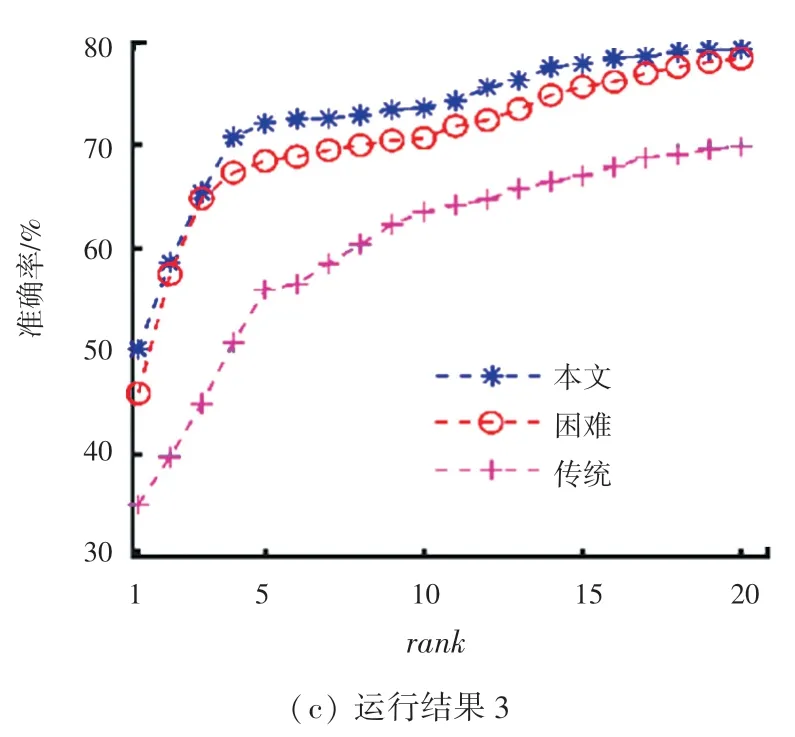
图4 基于不同数据集的3 种损失性能比较Fig.4 Comparison of three loss performance based on different datasets
实验证明,本文引入自适应权重,动态训练模型,提高模型的准确度更有效。由表2 可以看出,本文模型基于3 种标准数据集训练结果均比使用传统和困难三元组损失高。在MARS 这种多摄像头捕捉、更贴近于现实监控场景中,本文rank -1 相较于其它2 种损失分别高出4.3%和15.1%。在数据集iLIDS-VID 和PRID2011上,本文rank -1 比另外2种损失分别高出7.1%和24.8%以及4.3%和15.1%。再结合基于不同数据集的3 种损失性能比较的CMC曲线图如图5 所示,图5 中的蓝色曲线是本文模型性能。从图5 中可以直观看出,基于本文设计的损失函数的模型性能明显优于另外2 种损失,在不使用任何行人的先验信息条件下,本文的rank -1 基本可以达到50%以上。
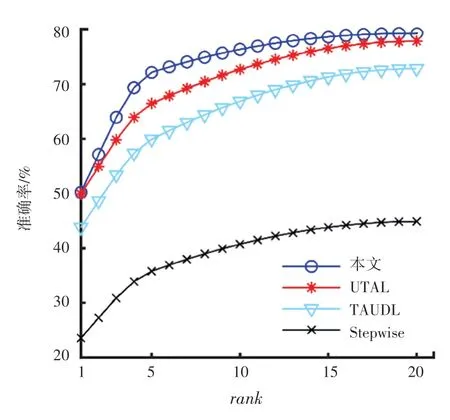
图5 基于MARS的CMC 曲线图Fig.5 CMC curve on MARS
(2)本文算法与其它较先进算法对比。本文中先基于较大数据集MARS 进行实验,分别与2020年较先进的算法UTAL[29]、以及其它较先进的算法Stepwise[18]等做比较,比较结果见表3。
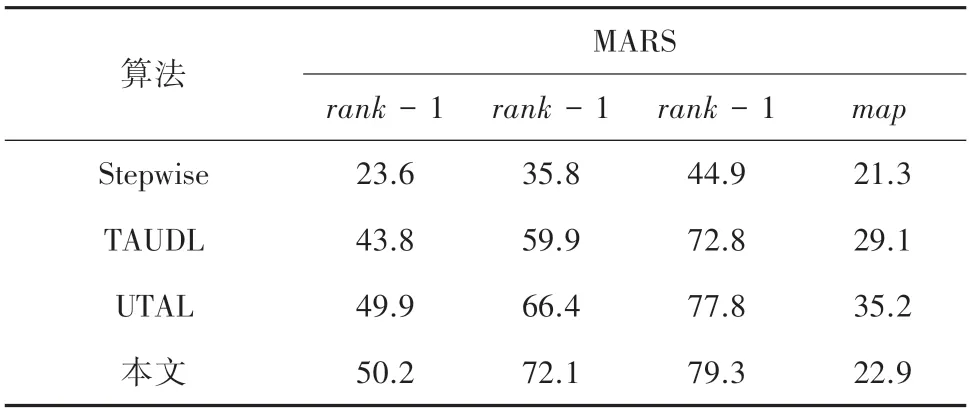
表3 在MARS 上的结果比较Tab.3 Comparison results on MARS %
实验证明,在选用了较大的数据集、且更加接近真实的监控场景中,本文模型识别的准确率明显优于其它模型。本文算法的rank -1 为50.2%,要比先进的UTAL 算法rank-1 高出0.3%。这就说明本文模型在没有任何先验行人信息的前提下,更加适用于行人重识别任务。
此外本文在标准的较小数据集PRID2011 和iLIDS-VID 上做了对比实验。实验结果见表4。CMC 曲线如图6 所示。

表4 在PRID2011 和iLIDS-VID 上的结果比较Tab.4 Comparison results on PRID2011 and iLIDS-VID %
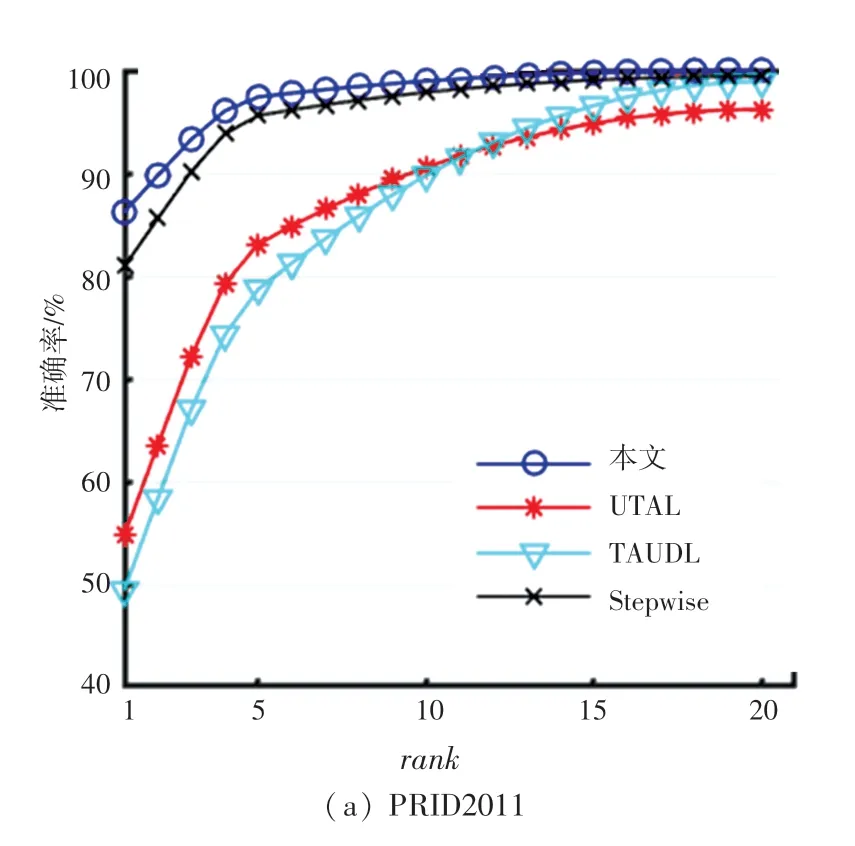
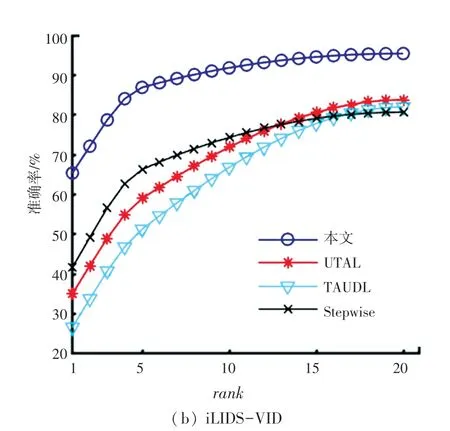
图6 基于PRID2011 和iLIDS-VID的CMC 曲线图Fig.6 CMC curve based on PRID2011 and iLIDS-VID
实验证明,在较小的数据集上,本文算法识别准确率更高,rank -1 分别为86.2%,65.4%,相较先进的Stepwise[16]算法分别高出了5.3%和23.7%。在图6 中蓝色曲线代表本文的算法,可以直观看出比其它较先进的算法高出较多,模型性能更好,在无监督学习条件下,基于PRID2011 训练的模型准确率达到85%以上。基于iLIDS-VID 数据集训练的模型性能,从图6 中也可以看出明显高于其它算法性能,rank -1 比黑色曲线高出23.7%。
在结合不同损失函数性能对比和与当前较先进算法的比较中可以发现,本文算法较优越主要可归因为基于rank -1 挖掘的三元组较困难。具体地,当rank -1 轨迹不是源轨迹时,表明该轨迹是与目标样本距离最近的负样本、即困难样本;当rank -1轨迹是源轨迹时,本文随机采样的M张图像作为负样本,再通过图像间的特征距离来分配权重,对困难样本着重学习。而在特征学习的过程中,基于困难三元组学习可以得到更加有效的特征。综上所述,本文模型在不使用任何先验身份信息的前提下,更加适用于行人重识别任务。
3 结束语
本文提出无监督学习三元组用于视频行人重识别研究。在基于单相机内轨迹的时空一致性学习轨迹特征过程中,利用关联排序的方法从无标签的数据集中挖掘目标图像的三元组用于计算损失,并引入自适应加权的方法来动态调整正负样本间的距离,提高模型的鲁棒性,学习单相机下具有判别力的行人特征。同时基于rank -1 合并2 台不同摄像机下的关联轨迹,作为跨相机损失计算的三元组锚样本。最终联合2 种关联损失优化,提高无监督模型的准确度。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
山西大学学报(自然科学版)(2021年1期)2021-04-21
意林(2021年5期)2021-04-18
五邑大学学报(自然科学版)(2019年3期)2019-09-06
当代陕西(2019年15期)2019-09-02
扬子江(2019年1期)2019-03-08
计算机技术与发展(2018年12期)2018-12-20
学苑创造·A版(2018年11期)2018-02-01
小天使·一年级语数英综合(2017年6期)2017-06-07
读者(2017年5期)2017-02-15
