
基于Bert-BiLSTM 的商品评论情感分析研究
2022-12-11 09:43徐鹏罗梓汛黄昕凯
智能计算机与应用 2022年11期
徐鹏,罗梓汛,黄昕凯
(广东东软学院,广东 佛山 528225)
0 引言
在互联网迅速发展、大数据来临,以及中国电商行业竞争加剧的背景环境下,用户于电商平台上购买商品的行为规模呈指数级上升,评论数据也随之增多。通常情况下,商品的评论数据中,蕴含着用户观点态度、情感倾向以及个人的见解。因此挖掘出用户的评论数据中的深层意向至关重要。在此前提下,商品评价分析应运而生。
商品评价分析是指通过对用户评论的处理,分析用户对商品的关注程度和情感态度,为商户选品和用户购买提供一定的决策辅助[1]。在本文Bert与BiLSTM 的商品评论情感分析研究中,商品评论情感分析占据主要地位,重点旨在发现用户是否有购买该商品的意愿并起到推荐作用,引导更多用户进行购买及评论。传统的关键词提取算法和预训练模型不能很好地联系上下文的语境和词向量稀疏等问题,不能精准有效地标出关键词。针对此问题,本文采用Bert 模型对评论数据进行词向量处理,避免分词造成的歧义,同时BiLSTM 能结合上下文的语境,使得模型更为精确,实现评论文本情感分析。
1 模型构建与研究
1.1 循环神经网络
循环神经网络(Recurrent Neural Network,RNN)能够挖掘出特征中语义信息,使深度学习模型在处理语言数据时运用更加广泛。循环神经网络在原有的神经网络基础上,增加了对隐藏层的循环结构,使隐藏层既可不受输入影响,还能接收上一时刻隐含层的影响[2]。循环神经网络设计展开如图1 所示。
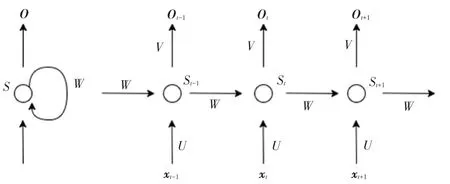
图1 RNN 结构图Fig.1 RNN structure
1.2 LSTM
相比于RNN,LSTM 引入了输入门i、遗忘门f、输出门o以及内部记忆单元c,通过门控状态来控制传输状态,记住需要记忆的信息,忘记不重要的信息;而不是和RNN 一样,只能够做记忆上的叠加。LSTM 能有效解决传统RNN 在处理时间序列长期依赖中的梯度消失和梯度爆炸的问题,且对很多需要“长期记忆的”任务来说,效果显著,误差较小[3]。LSTM 单元结构如图2 所示。

图2 LSTM 单元结构Fig.2 LSTM unit structure
由图2 可知,ft称为遗忘门,表示Ct-1需要用作于计算Ct的特征;“⊗”表示LSTM 中最重要的门机制;Wf是遗忘门的权重;bf是遗忘门的偏置。此处需用到的数学公式可写为:
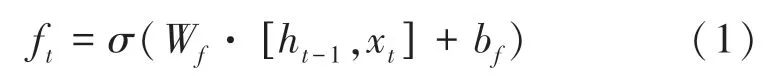
对于输入门i来说,可用于控制输入x和当前计算的状态更新到记忆单元的程度大小。相应的数学表示形式为:

it能够控制的部分特征,用来更新Ct,与ft相同,可由如下公式进行计算:

对输出层来说,其设计原理的数学表达式为:
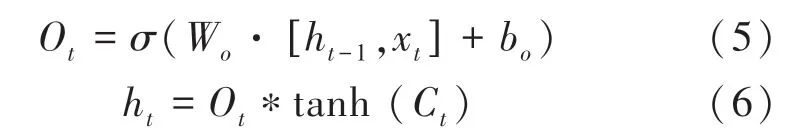
上述所有表达式中,σ通常是指Sigmoid函数,主要起到门控作用,其输出为0~1,当输出接近0 或1时,才能符合物理意义上的开或关。
1.3 BiLSTM
BiLSTM 是对LSTM 的改进方案。该方案有效解决了LSTM 无法学习反向特征的问题,因此本文采用双向BiLSTM 模型用于情感分类,一个用于保存上一词语的前后文,另一个用于存储下一词语的前后文[4]。BiLSTM 结构如图3 所示。

图3 BiLSTM 结构图Fig.3 BiLSTM structure
1.4 Bert
Bert 是一个预训练的语言模型,重点强调了不再采用传统的单向语言模型、或者把2 个单向语言模型通过浅层拼接的方法来进行预训练,而是通过使用遮挡语言模型(MLM)生成深度的双向语言表征[5]。
Bert 的提出为自然处理领域带来明显提升。前期的模型是单向训练、并将2 个单向训练相结合,而Bert 则为了将句子转化为词向量而使用了多层Transformer[6],对语境的分析相比单向模型来说会更加透彻[2]。Bert-base 的Encoder 是由12 层结构相同的Transformer Encoder 结构堆叠而成。虽然结构上是相同的,但相互间的权重并不共享[7]。Bert Ttransformer Encoder 结构如图4 所示。Bert 的模型架构上采用了Transformer 的encoder 部分,输入由字嵌入(token embedding)、段嵌入(segment embedding)和位置嵌入(position embedding)三部分相加构成,每个输入的起始token 会固定设置为′CLS′,用于下游的分类任务,2个不同的sentence 间会加入′SEP′作为分隔,输入的尾部同样会加入一个′SEP′[8]。嵌入层架构如图5 所示。

图4 Bert Transformer Encoder 结构Fig.4 Bert Transformer Encoder structure

图5 Bert 嵌入层架构Fig.5 Bert embedded layer structure
研究中,由MLM 和下一句预测(NSP)来进行Bert 的模型训练。MLM 对输入中的部分词语进行随机选取替换,致力于通过训练能够正确预测出原始输入的替换词,进而联合双向上下文达到双向编码的效果[9]。NSP 能够预测2 个句子是否连在一起,用于挖掘句子关系。在预处理时会以50%的概率从其他文档中随机选取首个text的下一个text,在预训练中预测其后的text是否为前一个text的真实下文,即可整理得到句子的逻辑关系[10]。
注意力机制如图6 所示。运算结构为一层Decoder 与一层Encoder 对应。在Encoder中,输入经过Embedding后,需进行位置嵌入(Positional encoding),再经过Multi-Head Attention,最后是全连接层[11]。

图6 Attention 运算Fig.6 Attention operation
1.5 Bert-BiLSTM 模型构建
本文采用Bert 的嵌入层将词序列抽取输出embedding 序列、再转换成词向量形式,同时将Bert输出的词向量经过BiLSTM 进一步再做特征提取,将其传送到输出层。输出层由全连接层和softmax层构成,在全连接层调整特征向量的维数,并使用softmax分类器对评论文本进行分类,实现情感分析。模型设计架构如图7 所示。

图7 Bert-BiLSTM 模型架构Fig.7 Bert-BiLSTM model structure
在BiLSTM 的输出层引入Multi-Head Attention注意力机制,词向量在BiLSTM 层产生的输出向量hi进入Multi-Head Attention层输出,提高文本情感信息的利用反馈。计算公式见如下:

2 实验与分析
2.1 实验数据准备
实验使用的商品评论数据集为Julian McAuley,UCSD 整理的Amazon product data-Clothing,Shoes and Jewelry 数据集,总共278 677 条数据,数据未带情感标注,实验抽取10 000 条评论作为实验数据,并对文本内容以自然语言处理(SNOWNLP)来做分类辅助的人工标注,标注结果可分为positive、neutral、negative,选取数据集70%作为训练集,20%作为测试集,10%的商品评论作为校验集。实验部分数据示例见表1。

表1 实验数据示例Tab.1 Examples of experimental data
为确保数据有效性,需对文本数据进行预处理。文本预处理的过程为:去除多余无用符号,对文本单词进行纠错处理,通过自定义停用词表将文本数据中的无意义单词进行剔除,使用正则表达式把文本中特殊符号删除,再使用Sentence BERT 提取到句子主干,索引长度实现标准化,从而避免了句子过长无法训练问题。评论数据预处理结果示意见表2。

表2 评论数据预处理示意表Tab.2 Comment data preprocessing schematic
2.2 实验参数
本文模型Bert-BiLSTM 参数设置如下。输入层采用预训练模型BERT-Base-uncased,该模型采用12 层Transformer,隐层维度为768,Multi-Head-Attention 的参数为12,模型总参数大小为110 MB。特征提取层主要由BiLSTM 构成。
模型训练方面,设置批次大小为64,最大序列长度为512,隐藏层个数为13,epoch为4,batch size设定为256,优化器选用LAMB,防止过拟合的dropout率为0.5。
2.3 实验评价指标
本文的研究内容是预测商品评论数据是否为消极或积极,是自然语言处理中常见的分类任务。若预测结果为积极,标记为1,否则标记为0。预测结果的混淆矩阵见表3。

表3 混淆矩阵Tab.3 Confusion matrix
表3中,TP表示预测结果为积极,实际评论也为积极;FP表示预测结果为积极,而实际为消极;FN表示预测结果为消极,而实际为积极;TN表示预测结果为消极,实际也为消极。接下来,对于研究中选用的评价指标,拟展开探讨分述如下。
(1)召回率。表示模型实际为1 的样本,预测仍为1 的样本概率,其计算公式为:

(2)精准率。是指在所有预测为1 的样本中,实际有多少个样本为1,其计算公式为:

(3)F1值。是对召回率和精准率的综合评价指标,是对其进行加权平均的结果,其计算公式为:

2.4 实验结果分析
本文从准确率(Precision score)、召回率(Recall score)、F1(F1-score)三个方面作为评价指标。其中,Precision是判别模型对负样本的区分能力;Recall是模型对正样本的识别能力;F1是将Precision与Recall相结合的综合值,这2 个评价指标的结合可以更加全面地反映分类性能。特别地,利用F1值来评估分类器性能时,分类器的性能越好,F1值越接近于1,因此本文选其作为衡量实验效果的主要评价指标。
在对比实验上,本文选取了Bert、BiLSTM、W2V-SVM 模型进行训练与结果比较。具体描述如下。
(1)Bert:使用预处理模型 BERT -base -uncased,参数与本文Bert 预设参数保持一致,利用预训练文本特征后输入Bert 情感分类。
(2)BiLSTM:定义参数大小与2 层双向LSTM的模型结构一样,并使用全连接层,再经过SoftMax分类器输出情感分类结果。
(3)W2V-SVM:使用SNOWNLP 进行分词,并做数据转化,接着将Word2Vec 模型词表初始化,再将各个词向量用平均的方式生成整句对应的向量。用矩阵进行建模与转化,拟合SVM 模型,并使用本文准备的文本评论数据进行训练。
对比模型的实验结果见表4。由表4 的整体结果分析可知,Bert-BILST 模型精度与Bert、BiLSTM和W2V-SVM精度相比分别提高了3.32%、9.1%和4.35%。Bert-BiLSTM 的双向神经网络相对于传统文本分类模型在语境上有较大提升,进行情感分析可以获得更好的结果。表5 为示例分析结果展示。

表4 对比试验模型比较Tab.4 Comparative test model comparison %
3 结束语
本文对基于Bert 和BiLSTM 的情感分析进行了研究。实验结果表明,Bert 将句子转化为词向量,输入到BiLSTM 模型中,由于BiLSTM 能兼顾上下文的语境,提高句意的情感丰富度,有效提升了文本分类的准确度,得到较为优化的分类器。经过对比实验后,所得结果均要优于传统的机器学习模型SVM 以及W2V-SVM、Bert、BiLSTM 等深度学习模型。只是本文研究仍有一定不足,如某些评论数据存在歧义,过分积极化实则隐藏为消极,在后续研究中需要对此类数据进行特殊处理,并且加大评论数据集,进而提升模型整体效果,增强泛化能力。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国生殖健康(2020年5期)2021-01-18
艺术评论(2020年3期)2020-02-06
小太阳画报(2019年10期)2019-11-04
制造技术与机床(2019年10期)2019-10-26
中华诗词(2018年9期)2019-01-19
电子制作(2018年18期)2018-11-14
中国生殖健康(2018年5期)2018-11-06
