
融合复杂先验与注意力机制的变分自动编码器
2023-01-09 14:28沈学利马玉营梁振兴
计算机工程 2022年11期
沈学利,马玉营,梁振兴
(辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105)
0 概述
随着互联网的快速发展,网络数据量呈指数级增长,用户面临信息过载问题[1]。由于面对海量信息用户很难快速获取感兴趣信息,信息生产者也很难将信息推荐给需要的用户,因此推荐系统应运而生。推荐系统是基于对用户和物品的分析,推荐给用户最有可能感兴趣的物品[2]。在推荐系统中协同过滤算法是使用较广泛的算法,其利用用户和项目的相似模式来提供个性化推荐[3]。但是协同过滤算法过多依赖用户对项目的显式反馈或隐式反馈,存在数据稀疏的问题。然而深度神经网络的应用在很大程度上缓解了数据稀疏问题,推荐系统的准确度也得到较大提升[4]。近些年,变分自动编码器(Variational Auto-Encoder,VAE)[5]受到研究人员的广泛关注,也产生了很多的变体模型。文献[6]将VAE 应用在协同过滤算法中,构建多项变分自动编码 器(Multinomial Variational Auto-Encoder,Multi-VAE)模型,使用多项似然函数替代高斯似然函数,同时在损失函数中加入正则化项以增强模型的解耦能力和提高模型的推荐效果。考虑模型限制条件,文献[7]设计基于条件的变分自动编码器(Conditioned Variational Auto-Encoder,C-VAE)模型,该模型将标签条件加入到VAE 中,同时对损失函数做出了改进,增加了模型的可解释性。文献[8]提出宏观和微观双层结构变分自动编码器(Macro-Micro Disentangled Variational Auto-Encoder,Macrid-VAE)模型,该模型使用多层神经网络获取高层次概念,再与用户行为进行结合,然后通过VAE 获取微观表现,提高了模型精确度,同样也增加了模型可解释性。
上述研究成果提高了模型的可解释性和精确度,但却忽略了VAE 模型本身的局限性。传统的VAE 模型除了会导致模型过度正则化外,还会造成只有少量隐向量被激活,该情况会随着网络深度的加深变得更加严重[7]。为此,本文提出融合复杂隐向量先验和注意力机制的变分自动编码器模型,简称为CCPAM-VAE。使用复杂隐向量先验分布替代标准正态分布,利用神经网络训练生成的伪输入作为假数据替代原数据,提高模型执行效率。通过添加辅助隐向量,增加隐向量的低维表现能力和解耦性。基于注意力机制强化具有较高权重值的重要信息,弱化具有较低权重值的不重要信息。
1 VAE 模型
变分自动编码器由KINGMA 等[9]于2013 年 提出,是一个深度生成模型,结合了变分贝叶斯方法和神经网络,将求和问题转化为优化问题,大大增加了模型适用范围,广泛应用于自然语言处理、计算机视觉、推荐系统等领域[10-12]。变分自动编码器的整体框架由编码器和解码器组成,因为编码器和解码器具有很大的灵活性,所以可以选择不同的神经网络作为组成部分。用户-物品的评分矩阵(见图1)作为输入数据输入模型,解码器最终输出得到重构后的数据,通过最小化与输入数据的误差来优化模型参数。同时,重构后的数据包含了之前评分矩阵的未评分数据[13-15]。VAE 模型分为变分推理过程和生成过程,对于每个用户u的生成部分过程表示如下:
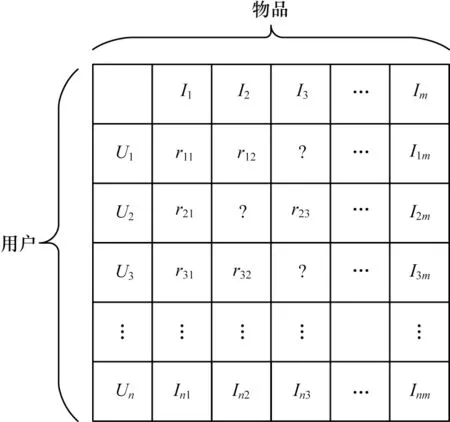
图1 用户-物品评分矩阵Fig.1 User-item rating matrix
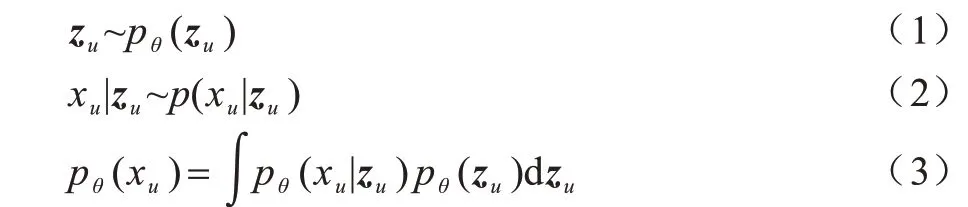
其中:zu表示用户u的隐向量;pθ(zu)~N(0,I)表示隐向量zu的先验分布服从标准正态分布。
2 CCPAM-VAE 模型
2.1 模型结构
本文设计的CCPAM-VAE 模型整体采用编码器-解码器结构,如图2 所示。在编码器阶段,输入数据经过密集块(Dense Block,DB)生成辅助隐向量z1,将z1与上一层DB 块的输出联合,作为下一个DB块的输入,生成隐向量z2。在解码器阶段,将辅助隐向量z1和隐向量z2经过注意力机制模块的输出联合,输入到DB 块,得到的结果输入到Softmax 函数中获得重构数据。在模型的编码器和解码器阶段,使用跳跃连接,加快模型优化速度,缓解深层网络的退化现象。
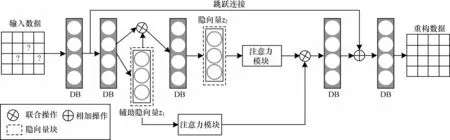
图2 CCPAM-VAE 模型结构Fig.2 CCPAM-VAE model structure
DB 模块结构如图3 所示。首先对输入数据x进行Dropout[16]操作,可以暂时屏蔽部分神经元,由于每次训练所屏蔽的神经元不一定相同,因此在一定程度上增加了模型的泛化能力;然后经过一个带有Tanh 激活函数的全连接层进行特征提取;最后使用批量标准化(Batch Normalization,BN)进行归一化处理,加快模型收敛速度。DB 模块的表达式如式(4)所示:
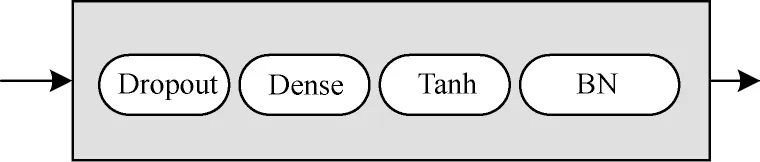
图3 DB 模块结构Fig.3 DB module structure
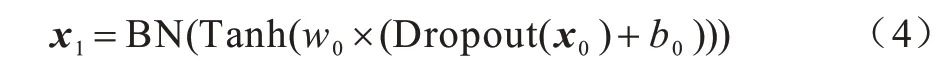
其中:w0是全连接层的权重值;b0是偏置;x0是模块输入;x1是模块输出。
2.2 伪输入
2.2.1 伪输入计算
通过最大化下界lgpθ(xu) 来优化参数θ、φ,lgpθ(xu)的下界如下:

式(5)也被称为证据下界(Evidence Lower Bound,ELBO),其中,qφ(zu|xu)表示后验分布,KL(*)表示Kullback-Leibler 散度,用来衡量两个概率分布之间的差距。
对KL 散度部分进行分解可得到:
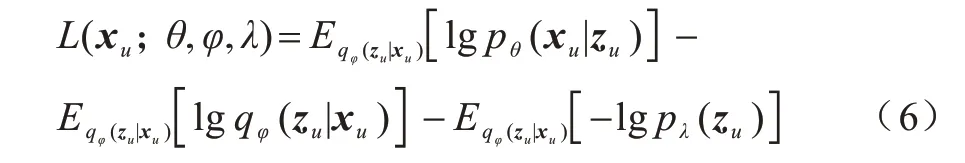
其中,θ、φ、λ分别代表不同的分布参数。
式(6)右边的第一部分是重构误差,第二部分是变分后验分布的熵,第三部分是变分后验和先验的交叉熵。使用拉格朗日乘子对第三部分求最大值,如式(7)所示:

后验分布如式(8)所示:
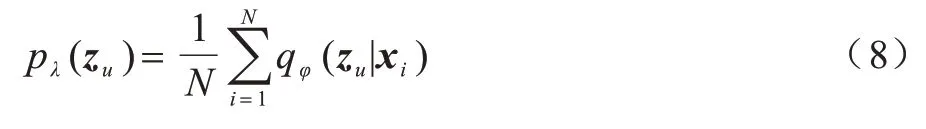
其中:N是数据集的大小。
由于求解先验分布需要使用整个数据集,这样做不仅浪费计算资源,还会导致模型过拟合,因此使用可学习数据替代原数据,可以很好地解决该问题,如式(9)所示:

2.2.2 伪输入模块
如图4 所示,在伪输入模块中,首先将输入数据输入a个DB1块中,所得的结果再输入到DB1块,输出μ1和σ1(如式(10)所示),然后使用隐向量模块中的重参数化技术,如图5 所示,其中σ2表示方差,μ表示均值,o表示重采样,将数据采样问题转化为标准正态分布采样问题,最后由式(10)得到z1。

图4 伪输入模块结构Fig.4 Pseudo input module structure
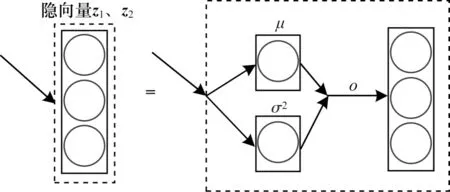
图5 隐向量模块Fig.5 Hidden vector module

接着将z1与式(10)上一层的输出联合,输入到DB2块中得到μ2和σ2。使用重参数化技术得到z2。该过程不仅能够使得采样过程独立,而且可以通过反向传播更新参数。
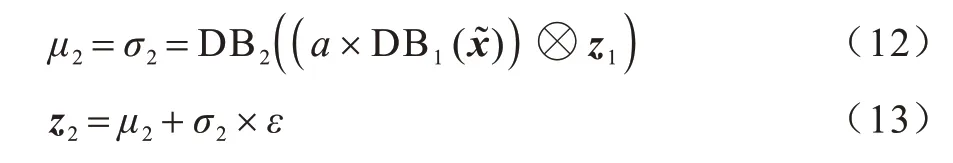
2.3 辅助隐向量
在训练过程中,传统的变分自动编码器模型经常出现隐向量非激活情况,这种情况会随着网络深度的加深变得更加严重。为解决该问题,在模型中添加辅助隐向量,双隐向量结构如图6 所示,包含x作为输入数据的变分过程和x作为生成数据的生成过程。

图6 双隐向量结构Fig.6 Double implicit vector structure
变分过程如式(14)所示:

生成过程如式(15)所示:

最终得到带有辅助隐向量的损失函数,如式(16)所示:
2.4 隐向量注意力机制
随着近些年深度学习的快速发展,注意力机制已成为计算机视觉、自然语言处理、语音识别等领域的重要技术[17-19]。Transformer[20]等神经网络模型与注意力机制相结合后,性能得到大幅提升。
隐向量作为用户-物品评分数据的高维表示,对于重构数据起着至关重要的作用。因为隐向量非激活问题也同样影响着重构数据的质量,所以本文通过融合注意力机制,对隐向量中含有重要信息的节点赋予更大的权重值,增强重要信息在重构数据中的作用;对于不重要的信息赋予更小的权重值,弱化其在重构数据中的影响,同时也减少了噪声。
在注意力模块中,首先将隐向量输入函数Z生成注意力得分,然后经过Softmax 函数,对注意力得分进行0-1 范围映射,将其转化为和为1 的概率值,最后将概率值与隐向量做乘积,如式(17)~式(19)所示,注意力模块结构如图7 所示。函数Z的选择很多,本文仅使用带有激活函数的全连接层作为函数Z。
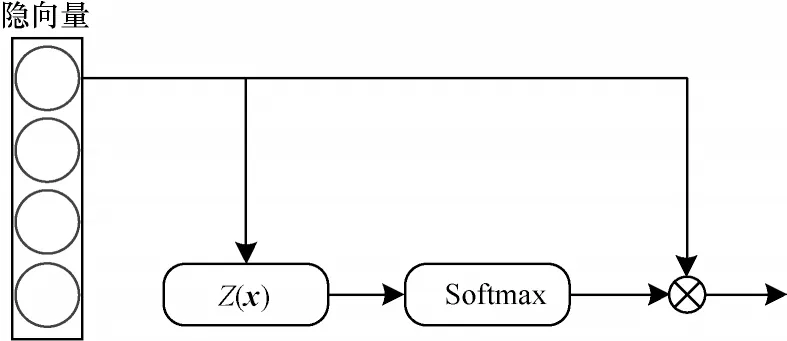
图7 注意力模块Fig.7 Attention module

其中:w是全连接层权重;Z是注意力评分;a是经过0-1 范围映射的评分值;oout是该模块的输出。
3 实验与评估
3.1 实验数据
采用4 个公开的数据集Movielens-1M(ML-1M)、Movielens-Latest-Small(ML-LS)、Movielens-20M(ML-20M)、Netflix 测试模型性能,数据集包含用户对物品的评分,评分范围为[1,5]。数据集介绍具体如下:
1)ML-1M 数据集是Movielens 数据集之一,包括6×103个用户、4×103部电影和1×108个电影评分。
2)ML-LS 数据集来源于Movielens 电影网站,能够进行自动采集更新,包含6×102个用户、9×103部电影和1×105个电影评分。
3)ML-20M 数据集来源于Movielens 电影网站2015 年4 月提供的数据,包括1.38×105个用户、2.7×104部电影和2×107个电影评分。
4)Netflix 数据集来源于电影租赁网站Netflix 2005 年公布的数据,包含4.8×105个用户、1.7×104部电影和1×108个电影评分。
数据集详细信息如表1 所示。

表1 数据集详细信息Table 1 Dataset details
3.2 数据处理
为测试模型在强泛化下的性能,对数据集进行如下处理[20]:
1)将数据集划分为训练集(80%)、验证集(10%)、测试集(10%)3 个部分,使用训练集的用户历史点击记录训练模型。首先从验证集和测试集的用户中获取一部分历史点击记录了解模型性能表现,然后通过查看模型对其他未显示的历史点击记录的排名来计算性能指标。
2)对数据集进行预处理。首先将用户-项目评分表转化为值为0 或1 的二值化矩阵,将其作为隐式反馈表,具体方式是将评分大于3.5 的值设为1,评分小于或者等于3.5 的值设为0;然后移除评分次数少于5 的用户。
3.3 实验环境设置
CCPAM-VAE 模型算法由Python 语言实现。实验硬件设备为Intel®CoreTMi7-8700 @3.2 GHz 处 理器,GeForce RTX 2080Ti 11 GB 显卡,32 GB 运行内存。为了使模型达到较好的效果,使用网格搜索法进行超参数搜索。超参数搜索范围如表2 所示。使用Adam 优化器[21]训练模型,使用ReLU 作为层与层之间的激活函数。采用Xavier 随机初始化[22]对模型参数进行初始化,保证了每层输出的方差不受该层输入个数影响,且每层梯度的方差也不受该层输出个数影响。
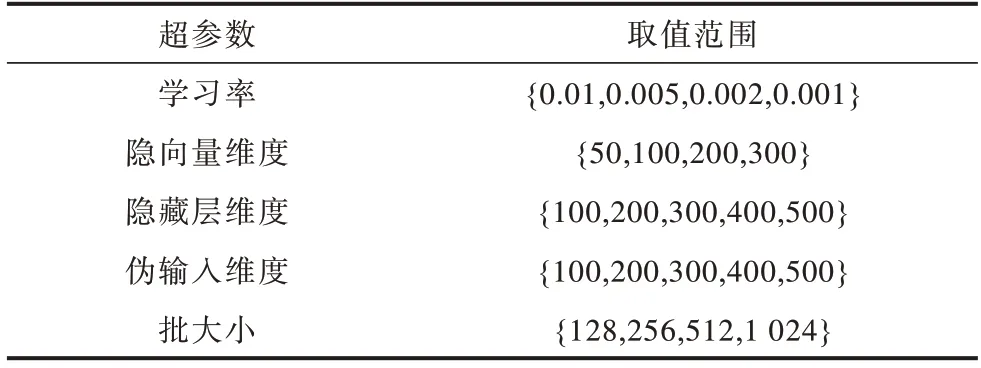
表2 超参数取值范围Table 2 Super-parameter value ranges
3.4 基线模型
Multi-DAE[5]将DAE 应用于协同过滤算法,并使用多项式逻辑似然函数替代经典高斯似然函数,实验结果证明其取得了不错的效果。
Multi-VAE[5]将VAE 应用于协同过滤算法,并使用β-VAE[4]损失函数,其中超参数β作为重建损失和KL 损失之间的权衡参数添加到损失函数中。
Macrid-VAE[7]在Multi-VAE 的基础上,将神经网络拟合生成的类别向量矩阵与输入相乘,对输入数据高维度和低维度解耦,增强了模型的可解释性。
CDAE[7]将用户潜在因素作为额外输入,添加到标准去噪自动编码器模型中。与标准去噪自动编码器模型一样,使用Dropout 方式对输入数据添加噪声。
NCF[23]构建用于协同过滤的神经网络特征学习框架,并将用户和物品潜在特征输入到该框架中。
3.5 评估指标
在测试集上,CCPAM-VAE 模型使用NDCG@K和Recall@K两个评估指标为每个用户预测项目排名,并将其与真实项目排名进行比较。
DCG@K为折损累计增益,是一种对排序结果的评价指标,用户u的DCG@K如式(20)所示,其中,I[·]是指示函数,r(i)是排名为i的物品,Tu是用户u点击过的物品集合。NDCG@K是DCG@K经过归一化后的值,取值范围为[0,1]。
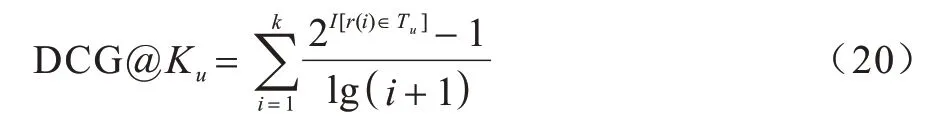
Recall@K为召回率,是一种衡量推荐效果的指标,用户u的Recall@K如式(21)所示,其中分母是K和用户点击的物品数的最小值。
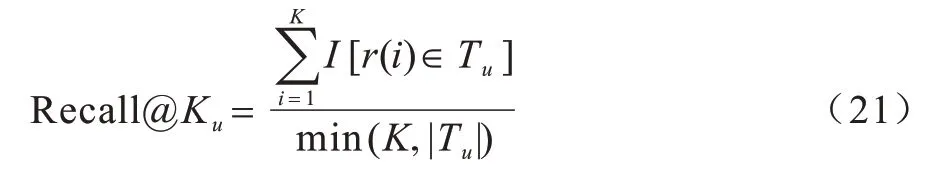
3.6 实验结果分析
3.6.1 模型性能对比
表3 从Recall@20、Recall@50、NDCG@100 3 个指标对CCPAM-VAE 模型进行评估,在数据集ML-1M 上,指标平均提升了10.79%、5.12%、8.74%;在数据集ML-LS 上,指标平均提升了26.20%、22.26%、17.42%;在数据集ML-20M 上,指标平均提升了7.47%、6.97%、6.97%;在数据集Netflix 上,指标平均提升了7.34%、8.86%、8.82%。上述结果表明,相较于基线模型,本文模型不仅在大数据集ML-1M、ML-20M、Netflix 上有较好的表现,在小数据集ML-LS 上也有不错的效果。这表明复杂先验能够帮助模型学习更加复杂的数据关系,减少模型出现过拟合的情况。同时,基线模型Macrid-VAE 在这4 个数据集上的表现要优于其他基线模型,这表明高维度解耦能够显著提升性能。

表3 CCPAM-VAE 模型与基线模型的性能对比Table 3 Performance comparison among CCPAM-VAE model and baseline models
3.6.2 不同隐藏层维度和K值对模型性能的影响
图8 给出了当隐藏层维度d取100、200、300、400、500 而其他参数不变的情况下,CCPAM-VAE 模型在4 个数据集上的NDCG@100 值。从图8 可以看出,隐藏层维度的增加不一定能带来模型性能的提升,过高维度或者过低维度会导致模型过拟合或者欠拟合的现象,使模型表现不佳。对于数据集MLLS,在隐藏层维度d=200 时,模型性能达到最佳。对于数据集ML-1M、ML-20M、Netflix,隐藏层维度d=300 时,模型性能达到最佳。这说明对于不同规模的数据集,模型达到最佳性能所需的隐藏层维度不一定是相同的。
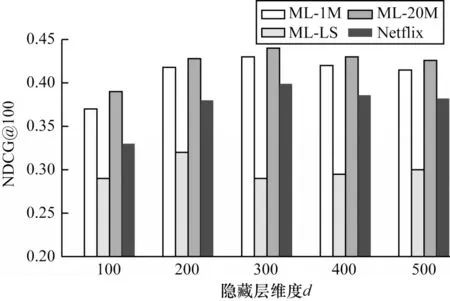
图8 隐藏层维度对NDCG@100 的影响Fig.8 Impact of hidden layer dimensions on NDCG@100
图9给出了当K取5、10、15、20时,CCPAM-VAE 模型和基线模型在4 个数据集上的NDCG@K值。在数据 集ML-20M、Netflix、ML-1M 上,当K取5 时,NDCG@K的值几乎最大,这表明在数据量比较大的情况下,CCPAM-VAE 模型和基线模型不仅适合对物品进行Top-K推荐,而且适合应用于推荐数量有限的场景。在数据量较小的数据集ML-LS 中,随着K值的增大,NDCG@K的值也不断增大,这表明在数据量比较小的情况下,CCPAM-VAE 模型和基线模型不适合进行Top-K推荐。由此可见,CCPAM-VAE 模型在4 个数据集上的表现均优于基线模型。

图9 CCPAM-VAE 模型与基线模型在4 个数据集上的NDCG@K 对比Fig.9 NDCG@K comparison among CCPAM-VAE model and baseline models on four datasets
3.6.3 消融实验分析
在数据集ML-1M、ML-LS、ML-20M 和Netflix上对CCPAM-VAE 模型的复杂先验和注意力模块进行有效性验证,结果如表4 所示。其中,#-表示不使用复杂先验和注意力模块,#a 表示使用复杂先验,#b 表示添加注意力模块,#ab 表示使用复杂先验和注意力模块。从表4 可以看出,独立使用复杂先验和添加注意力模块均能提升模型精确度,将两者同时加入CCPAM-VAE 模型,可使模型精确度达到最佳。
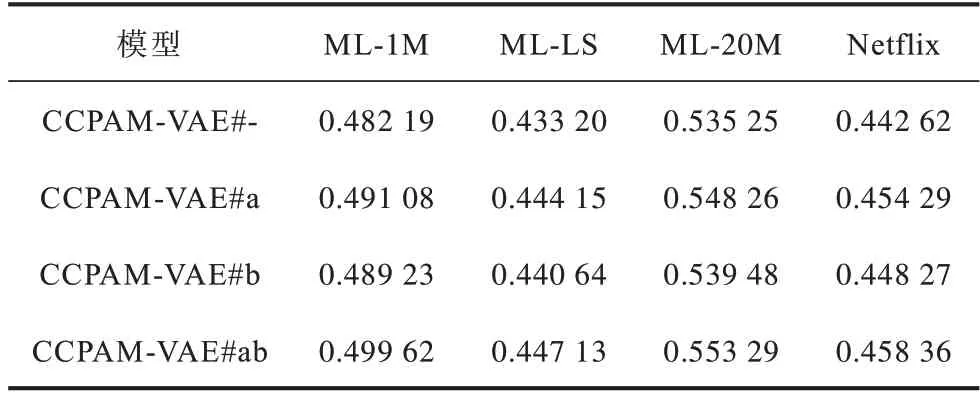
表4 CCPAM-VAE 模型消融实验的Recall@50 对比Table 4 Recall@50 comparison of ablation experiment of CCPAM-VAE model
4 结束语
本文提出融合复杂隐向量先验与注意力机制的变分自动编码器模型,使用复杂隐向量先验分布使模型获得更多的潜在表征,通过添加辅助隐向量增加隐向量的低维表现能力和解耦性。在公开的数据集Movielens-1M、Movielens-Latest-Small、Movielens-20M 和Netflix 上,基 于Recall@20、Recall@50 和NDCG@100 指标进行性能评估,验证了该模型相较于基线模型能够有效提高推荐精确度。但由于本文仅将评分矩阵作为模型输入,在后续研究中还将在变分自动编码器中融入知识图谱、图神经网络[24-25]等更复杂的数据形式和数据关系,进一步研究其对推荐效果的影响。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
网络安全与数据管理(2022年1期)2022-08-29
中国卫生统计(2022年2期)2022-05-28
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
矿山测量(2020年2期)2020-05-17
岁月(2016年5期)2016-08-13
中国市场(2016年45期)2016-05-17
探测与控制学报(2015年4期)2015-12-15
