
基于姿势引导与属性分解的人物图像生成
2023-01-09 14:29张战成
计算机工程 2022年11期
殷 歆,张战成
(苏州科技大学 电子与信息工程学院,江苏 苏州 215009)
0 概述
人物图像生成在图像编辑、图像重建、动画制作、短视频虚拟特效等领域[1]得到广泛应用。姿势迁移的目标是以目标姿势引导模型生成出具有相同姿势的真实人物图像,其为人物图像生成领域一个具有挑战性的任务,尤其是不同视角下人物不同姿势图像在外观上存在较大差异时,要求生成器能够捕获图像分布所具有的较大变化。
早期的人物图像生成方法直接对整个源人物图像进行编码,然后解码生成图像,这种整体编码在面对具有复杂多样衣服的多种人物图像时,难以针对详细的纹理对整个人物进行正确编码,细节失真较为严重。属性分解的生成对抗网络(Attribute-Decomposed Generative Adversarial Network,ADGAN)[2]提出一种将源人物图像分解为多个部件并分别编码再重组构建完整样式码的编码方式DCE(Decomposed Component Encoding),其只针对人物一个组成部分的特征进行编码,使编码难度降低,同时也加快了模型的收敛速度,所生成图像的细节更为逼真,但是,这种单纯的先分解人物组件编码再拼接的编码方式相对于整体编码方式遗漏了人体各部分之间的关联性,当源人物的姿势和衣服纹理过于复杂时,该编码方式容易出现纹理和颜色编码混乱,进而导致所生成的人物丢失源人物的纹理特征。
针对上述问题,本文提出一种姿势引导分解组件编码器P-DCE(Pose Guided Decomposed Component Encoding),为每一个分解的源人物组件增加源人物完整的人体姿势关键点信息,确保在任何复杂人物图像的编码中都不会丢失人物各个部件之间的关联性。同时,在网络中加入循环一致性约束,用来约束生成图像与源图像之间的纹理编码和人物姿势的一致性,从而保证生成图像与源人物图像的整体外观相一致。
1 相关工作
生成对抗网络(Generative Adversarial Network,GAN)[3]在图像生成领域发挥了重要作用,但是其难以控制生成器的输出,生成内容极其依赖训练数据集的分布。为了使GAN 的输出变得可控,文献[4]提出条件生成对抗网络(Conditional Generative Adversarial Network,CGAN),在生成器输入端增加一个标签输入,在鉴别器的输入端也加入相同标签,从而控制生成器输出与标签相关的内容,CGAN 的出现推动了图像风格迁移的发展。文献[5]结合CGAN 的思想同时在网络中加入多鉴别器用于生成人物衣服的搭配图像,文献[6]在CGAN 的基础上加入UNet 结构[7],提出一种新的鉴别器Patch GAN,称为pix2pix,其实现了图像到图像的翻译和图像的风格迁移,扩展了CGAN 的应用范围。随后,文献[8]提高了pix2pix 的图像生成质量,生成的图像达到了高分辨率的水平,但是pix2pix 系列方法依赖于训练标签间一一对应的关系,导致数据集的获取比较困难。为了解决上述问题,使图像风格迁移更易训练,文献[9]提出一种无监督的图像风格迁移方法CycleGAN,该方法引入循环一致性约束,使用2 个包含未标注图像的图像域训练生成图像。文献[10]使用CycleGAN 的循环约束结构设计用于雨天图像中雨水去除的DerainCycleGAN 算法。文献[11]提出一种结合变分自动编码器(VAE)和生成对抗网络的联合生成模型,以生成高质量的不可见特征,有效解决了训练数据集获取困难或不可用的问题。文献[12-13]基于pix2pixHD 对生成人物视频进行研究,但是pix2pix 的特性使得生成人物图像不具多样性。
针对人物图像生成问题,已经有许多基于生成对抗网络合成任意姿势的人体图像生成算法被提出。文献[14]提出一种双阶段的生成器结构以合成人物图像,其中,第一阶段对具有目标姿势的人物进行粗略合成,随后在第二阶段对其进行细化,在生成过程中较好地分离了人物的姿势和外观。文献[15]提出一种全新的生成器架构,通过自适应实例规范化AdaIN[16]控制生成器,合成比较逼真的人脸图像,AdaIN 可实现任意风格迁移,其中也包括人物姿势和纹理的迁移,被广泛应用于许多人物图像生成任务中。文献[17]将级联式姿势注意模块加入到生成器中,以逐步引导可变性传递过程,利用双向策略在无监督的情况下合成人物图像,但是该方法只将源人物的姿势传递给目标人物,忽略了人物的外观、衣服纹理、背景等信息,对于复杂纹理的生成效果不佳。文献[2]提出的ADGAN 在PATN 级联式模型的基础上进行优化,采用级联式姿势注意力模块完成姿势引导,同时使用AdaIN 模块将人物组件属性(如头部、上衣、裤子等)编码注入到姿势编码中,可以生成纹理一致和姿势一致的人物图像,但是ADGAN缺少对姿态控制的引导条件,导致人物姿态失真。为了更精确地进行人体纹理解耦,文献[18]提出联合人物图像的全局和局部逐区域编码和标准化的方式来预测不可见区域的服装的合理风格,使生成图像的人物纹理更加精确。
2 姿势引导和属性分解的生成对抗网络
本文在ADGAN[2]的基础上增加姿势引导纹理生成模块,并设计一种新的融合模块,加入循环一致性约束,在人体分解纹理编码部分对每一个分解后的模块(如头部、上衣、裤子、肢体等)都在通道维上拼接人体姿势信息,每个通道代表一个人体部位的关键点。
本文所提姿势引导和属性分解的生成对抗网络的生成器结构是由姿势路径和纹理路径这2 条路径所组成的双流结构,如图1 所示。生成器需要3 个输入,即需要生成的目标人物姿势Pt∈R18×H×W、源(条件)人物图像Is∈R3×H×W、源人物姿势Ps∈R18×H×W,输出为生成的图像Ig∈R3×H×W,即源人物Is在目标姿势Pt下的图像。纹理编码器的输出通过若干个级联模块与解码器连接,纹理路径输出的样式码被注入到级联模块中与姿势编码相结合,通过解码器重构出目标人物图像Ig。对于生成图像Ig,添加了姿势回归和纹理回归模块。
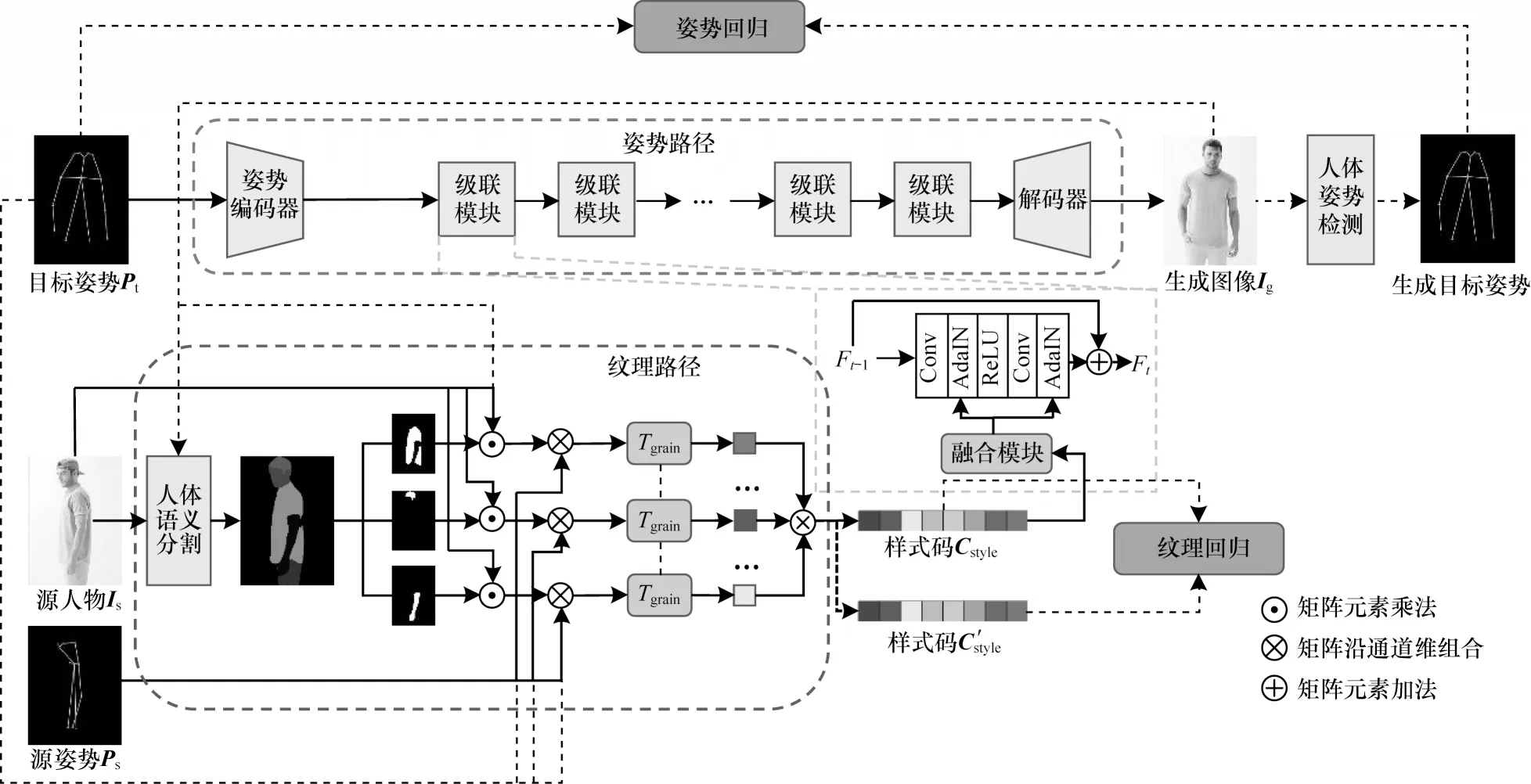
图1 双流生成器结构Fig.1 Double stream generator structure
2.1 纹理路径
纹理路径的全称为姿势引导的人物纹理属性分解编码器,源人物图像Is和源人物姿势Ps通过该模块被嵌入到隐空间中,编码为样式码Cstyle。如图1 所示,源人物图像Is输入到预训练的语义分割算法Look into Person[19]中提取人物的语义映射,并按照不同的人物属性(如头部、衣服、四肢等)转换为8 个通道的语义映射M∈R8×H×W,将每一个通道Mi∈RH×W(i∈[1,2,…,8])作为掩码,与源人物图像相乘得到当前人物属性的分解人物组件掩码。为了加强人体姿势关键点与人体分解组件之间的位置对应关系,将计算出的3 通道的分解人物图像与18 通道的源人物姿势Ps在通道维堆叠成21 通道的矩阵,输入到纹理编码器Tgrain中,计算出每个分支i对应的样式码,最终将所有的分解样式码堆叠起来组成完整的人物样式码Cstyle,如下:
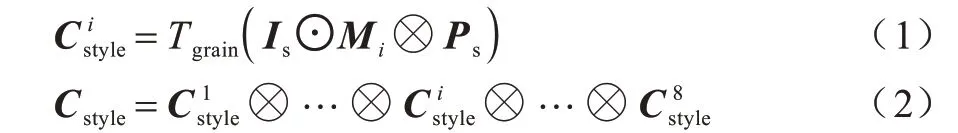
其中:⊙代表每个通道都逐元素相乘;⊗表示将2 个矩阵沿通道维堆叠;Tgrain为纹理编码器。
纹理编码器(Tgrain)是由一个固定权重编码器和一个可学习权重的编码器组合而成的全局编码器。固定权重编码器是在图片风格转换网络AdaIN 上使用COCO 数据集[20]预训练的VGG 网络[21],该编码器参数固定,由于预训练的VGG 网络在COCO 数据集中具有由各种纹理图像训练的权重,对复杂的纹理都具有强大的泛化能力,大幅提高了模型性能,但是,固定权重的编码器针对的是任意图像的风格转换,为使编码器可以更好地适应人物风格转换,在每一个VGG 层的位置叠加一个输出维度相同的可学习权重的卷积层,最终编码器输出的编码为由可学习权重编码器和固定权重编码器的输出所叠加的编码,经过平均池化层得到组件样式码,如图2所示。

图2 纹理编码器结构Fig.2 Texture encoder structure
2.2 姿势路径
姿势路径的目的是将纹理路径输出的样式码Cstyle表示的源人物纹理特征注入到目标姿势Pt的特征中,由一个融合模块将姿势特征与样式码特征连接。姿势路径由姿势编码器、解码器和t(t=8)个级联式模块组成,每个级联式模块由一个融合模块、卷积层和AdaIN 模块组成。
本文模型共采用8 个级联式模块,其中第一块没有前置块输入,其直接使用最初的目标人物姿势Pt通过姿势编码器编码后的输出作为输入,后续的每一个级联式模块的输出都由当前模块Ft的输出与前一个级联式模块Ft-1的输出相加所得,如图1 所示。
输入的参数通过融合模块(Fusion Module,FM)从样式码Cstyle中提取,不同于ADGAN 中的融合模块结构,本文模型中样式码Cstyle每一个组件的样式码都带有人体关键点信息,最终构成的样式码带有人体各部位的原始关联性,不需要使用全连接层进行线性重组,融合模块被设计成4 个下采样卷积层进一步提取样式码的特征,最后一层使用全连接层将特征转换为所需要的维度。在此基础上,将最后一个级联式模块Ft的输出输入到由8 个反卷积层组成的解码器中,得到最终的生成图像Ig。
2.3 鉴别器
本文模型使用单个鉴别器,用于确保生成图像Ig的外观与源人物相似,鉴别器的输入为生成图像Ig。鉴别器结构设计时参考PatchGAN[4]的全卷积设计,原始的GAN 鉴别器仅针对整幅图像输出一个评价值,PatchGAN 输出一个N×N大小的矩阵,矩阵中每一个元素对应图像中的一个小区域的评价值,这种鉴别器相比普通鉴别器对整个图像的关注更全面,得出的评价均值更准确,在一些图像风格迁移任务[4,6,14]中取得了更好的效果。
2.4 循环一致性约束
模型生成图像的隐空间信息应该与条件(源)图像的隐空间信息保持一致[22]。针对本文模型的2 条路径,网络中添加2 种隐空间回归、姿势回归和纹理回归。
姿势回归使生成图像Ig的姿势关键点Pg与目标姿势关键点Pt对齐,即Pg≈Pt,Pg由生成图像Ig通过预训练的人体姿势关键点网络(OpenPose)[23]计算得到。由于人体姿势关键点信息容易计算与表示,无需为此设计专门的姿势鉴别器,因此可使用式(3)直接计算Pg与Pt之间的L1 距离:

2.5 损失函数
模型的整体损失函数Lfull包含GAN 对抗损失Ladv、循环一致性损失Lp_cyc和Le_cyc、重建损失Lrec、感知L1 损失LpreL1,计算公式如下:

其中:λ1、λ2、λ3、λ4是损失函数对应的权重,实验中λ1、λ2取3,λ3、λ4取2。
对抗损失来自模型中的生成器G 和鉴别器D,目的是帮助生成器生成具有与源人物图像视觉外观相似的目标人物图像,如下:
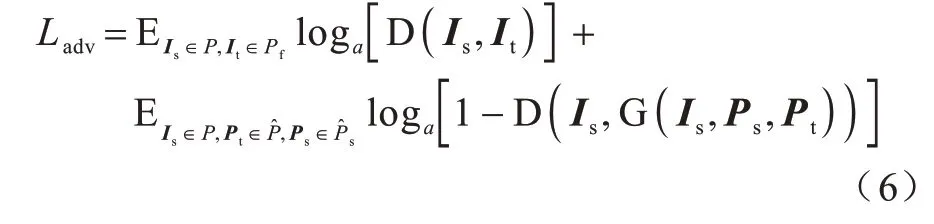
重建损失用于引导生成图像的外观与目标图像的外观相似,从而避免人物颜色和纹理的失真,可达到加快收敛和提高生成精度的效果,重建损失为生成图像与目标图像之间的L1 距离。
感知L1 损失用于减少生成人物姿势的扭曲和失真,且可以使生成图像看起来更自然,该损失在一些超分辨率重建[24]、风格转换[25]、姿势迁移[26]任务中具有有效性。
3 实验结果与分析
本文模型基于PyTorch 框架编写,GPU 卡为NVIDIA Tesla-V100。超参数的设置使用动量为0.5的Adam 优化器对模型进行800 个epoch 的训练,每一个epoch 进行17 000 次迭代,采用每隔80 个epoch将学习率下降20%的线性衰减学习率调整策略。
3.1 实验设计
3.1.1 数据集
本文实验在DeepFashion 数据集[27]上进行训练和测试,该数据集包含52 712 张分辨率为256×256像素的高清且具有多人物、多姿势和不同外观的人物图像,其中人物数量以及每个人物的姿势和外观丰富,使得该数据集被广泛应用于人体姿势迁移算法的训练和测试中。为了尽量简化输入图片的信息,在预处理阶段把每张图片切割为176×256 像素的分辨率,去除多余的背景,使用人体姿态估计算法OpenPose 获取每张图像的人体关键点数据。利用在数据集中随机抽取的方法配对相同人物在不同姿势下的101 967 个图像对用于训练,8 571 个图像对用于测试,经预处理后的部分图像如图3 所示。

图3 DeepFashion 数据集示例Fig.3 Example of DeepFashion dataset
3.1.2 评价指标
本文使用感知评分(IS)、结构相似性(SSIM)和峰值信噪比(PSNR)来评价生成模型的性能和模型生成图像的质量。
IS 是用来评价GAN 生成图像的质量和多样性的常用指标,其无需跟真实图像比较,只需生成多张图像即可计算。IS 在ImageNet 中被提出,计算时需使用预训练的Inception Net V3 生成图像信息,IS 值越大,说明GAN 网络生成图像的质量和多样性越好。SSIM 是一种用于衡量2 张图像相似度的常用指标,用于计算的2 张图像分别为真实图像和生成图像,该指标衡量2 个样本间的亮度、对比度和结构,计算时每次从图像上取一个分辨率为N×N的窗口单独计算,然后滑动窗口依次计算,最后取平均值作为全局SSIM 值,SSIM 值越高,说明生成图像与源图像差异越小。PSNR 是使用最为广泛的图像画质评价指标,其提供了衡量图像失真或噪声水平的客观标准,PSNR 值越高,说明生成图像的失真程度越低。为了比较各方法之间的差异性,本文对所有生成图像的SSIM 和PSNR 指标进行成对t 检验(Paired ttest),该指标用于检验2 个样本平均数与其各自所代表的总体的差异是否显著,成对t 检验的p 值小于0.05,表示2 个样本差异显著,反之,则表示2 个样本差异不明显。IS 指标对多张图像进行度量,无法进行成对t 检验,实验仅报告全体测试样本上的度量。
3.2 损失曲线
对比本文模型和ADGAN 在训练时总损失Lfull的变化曲线,结果如图4 所示,从中可以看出,本文模型增加的姿势信息和循环一致性约束可以有效加快模型的收敛速度。

图4 损失曲线比较Fig.4 Comparison of loss curves
3.3 消融实验
为了测试网络中加入的2 个隐空间回归的有效性,设计2 组消融实验,分别使用基础网络加姿势回归以及基础网络加纹理回归,在DeepFashion 测试集中进行定性和定量测试,定性测试结果如图5 所示,定量测试结果如表1 所示,最优结果加粗表示。

图5 循环一致性约束对网络影响的定性结果Fig.5 Qualitative results of the impact of cycle consistency constraints on networks

表1 循环一致性约束对网络影响的定量结果Table 1 Quantitative results of the impact of cycle consistency constraints on networks
从图5 和表1 可以看出:当删除姿势回归之后,生成图像质量稍有下降,人物的一些细节有一定的失真,IS、PSNR、SSIM 指标略微下降,但是差异显著;当删除纹理回归之后,生成人物无法保持真实性,仅能看出姿势略有一致,人物纹理外观完全没有保持,IS、PSNR、SSIM 指标均有较为明显的下降,并且差异显著,造成该现象的原因可能是人物纹理隐空间比较复杂,在网络缺乏相应约束时,生成图像的人物纹理想要保持与条件人物纹理一致将变得非常困难。该实验结果表明,模型中加入纹理回归和姿势回归具有有效性。
3.4 与其他模型的比较
给定一些从测试集中选取的源人物图像和期望生成的目标姿势,本文模型可以生成符合目标姿势的自然且真实的结果,部分实验结果如图6 所示。

图6 部分实验结果示例Fig.6 Some examples of experimental results
为了评估本文模型在人体姿势迁移图像生成任务中的有效性,将其与ADGAN 和PATN 这2 个被广泛使用的人体姿势迁移模型进行对比实验,分为定性比较和定量比较。ADGAN 和PATN 均使用原文作者发布的在DeepFashion 数据集上训练出的预训练权重进行测试,测试集使用预先从数据集中划分出的8 571 个测试图像对,3 个模型的输入输出图像分辨率均设置为176×256 像素。
定性比较结果如图7 所示,可以看出,在相同源人物下进行较为复杂的姿势迁移时,本文模型生成图像的效果在视觉上优于PATN,略优于ADGAN,在人体纹理(如衣服、发型等)方面本文模型更准确。定量比较结果如表2 所示,表中展示3 种指标在3 个模型上的表现,以及本文模型与其他2 个模型的SSIM 和PSNR指标t-test的p 值,从中可以看出,本文模型具有最高的IS 值,说明生成图像服饰多样性较好,在SSIM 值上与ADGAN 相当,从成对t 检验指标上可以看出差异不显著,在PSNR 指标上本文模型最高,并且与其他模型相比差异显著,说明本文模型生成的图像效果失真度最小,能够保证生成图像的质量。

图7 3 种模型的生成图像比较Fig.7 Comparison of images generated by three models
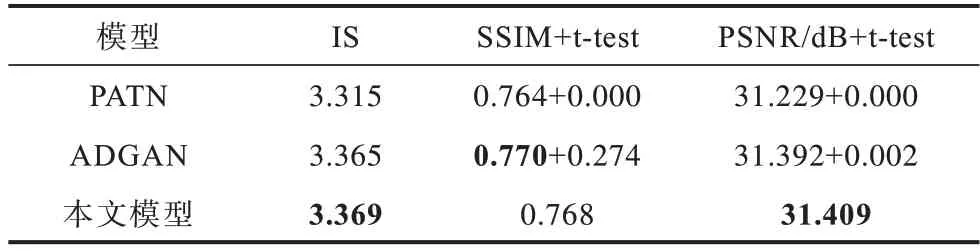
表2 3 种模型的性能比较结果Table 2 Performance comparison results of three models
PATN 模型由于没有在网络中加入人体语义分割信息,仅对人体姿势信息使用级联式结构进行编码,在训练过程中损失了过多人体纹理信息,导致生成的人物图像纹理失真比较严重,仅能较好地保证生成图像人物姿势的一致性。本文模型和ADGAN模型都加入了人体语义分割信息,并且采用分解组件编码结构,在编码时加强了人物纹理信息,最终生成图像的质量都优于PATN。本文模型在分解组件编码的基础上又增加了源人物姿势信息,在编码后的特征中保留了人物纹理与源人物姿势之间的对应关系,进一步提高了对人物纹理的编码能力。此外,本文模型还添加了循环一致性约束,使生成人物图像的纹理、姿势信息与源人物图像的纹理、姿势信息更容易保持一致,对于具有复杂纹理的人物图像依然可以保证纹理稳定性以及准确性。
4 结束语
本文提出一种姿势引导分解组件编码的姿势迁移人物图像生成对抗网络。在生成人物分解样式编码时引入人体姿势关键点的条件信息,将AdaIN 输入处全连接结构的融合模块替换为多层卷积结构,进一步提取人物姿势分解组件的特征,从而加强模型中人物姿势和纹理的关联度。此外,对生成图像和纹理编码加入循环一致性约束,提高网络生成图像中人物纹理的精度和姿势的一致性。DeepFashion数据集上的实验结果表明,条件分解组件编码较直接分解编码具有更快的收敛速度,在IS、SSIM、PSNR 指标上本文模型较对比模型有明显优势,人物生成图像质量有一定提升。
本文在训练生成对抗网络时提供更多的条件信息并增加更多的约束条件,使得网络的生成图像效果得到增强,但是,本文模型依然存在一些局限性,在生成具有复杂姿势的人物时会有失真,这是由于DeepFashion 数据集中人物姿势较为单一,具有复杂姿势的人物训练数据偏少,在模型中缺乏对生成人物姿势的有效约束条件。下一步将扩充训练集中的复杂姿势人物图像,在模型中增加针对生成人物姿势的有效约束,从而解决上述问题。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
文苑(2020年5期)2020-06-16
小学生学习指导(低年级)(2020年3期)2020-06-02
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
中国生殖健康(2019年10期)2019-01-07
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
