
Customer Churn Prediction Model Based on User Behavior Sequences
2023-01-11 03:14ZHAICuiyan翟翠艳ZHANGManman张嫚嫚XIAXiaoling夏小玲MIAOYiwei缪艺玮CHENHao
ZHAI Cuiyan(翟翠艳), ZHANG Manman(张嫚嫚), XIA Xiaoling(夏小玲), MIAO Yiwei(缪艺玮), CHEN Hao(陈 豪)
College of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract: Customer churn prediction model refers to a certain algorithm model that can predict in advance whether the current subscriber will terminate the contract with the current operator in the future. Many scholars currently introduce different depth models for customer churn prediction research, but deep modeling research on the features of historical behavior sequences generated by users over time is lacked. In this paper, a customer churn prediction model based on user behavior sequences is proposed. In this method, a long-short term memory (LSTM) network is introduced to learn the overall interest preferences of user behavior sequences. And the multi-headed attention mechanism is used to learn the collaborative information between multiple behaviors of users from multiple perspectives and to carry out the capture of information about various features of users. Experimentally validated on a real telecom dataset, the method has better prediction performance and further enhances the capability of the customer churn prediction system.
Key words: multi-headed attention mechanism; long-short term memory (LSTM); customer churn prediction
Introduction
In recent years, with the major operators in marketing, technology promotion and development, the customer growth rate in e-market has become significantly slower[1]. At the same time, there is few differences in the way that each operator runs, and it will not have a significant advantage in the competition for new customers. Therefore, reducing the churn of on-net customers is an important means to protect the overall customer base of the operator. The current main method is to collect information about the features of churn customers, analyze and learn from the customers currently on the network through relevant algorithms and models, identify customers who will terminate their contracts with operators, and realize the prediction of churn customers. In the actual production environment, a large amount of human and material resources needs to be employed to remedy the identified churn customers, so the accuracy of model prediction becomes critical and has attracted the attention of academia and industry.
Early research focused on traditional machine learning to learn user behavior and basic feature information to achieve customer churn prediction. Verbekeetal.[2]and Kimetal.[3]both based on logistic regression models for customer churn prediction. Coussementetal.[4]introduced support vector machine (SVM) for customer churn prediction and also compared it with two algorithms based on interaction verification and grid search. Huangetal.[5]applied random forest algorithm to churn prediction of customers. De Caignyetal.[6]used decision tree algorithms and a logistic regression model algorithm to predict churn customers.
Later on, with the wide application of deep learning in telecommunication research, more and more studies started to introduce neural network models in customer churn prediction models, which achieved better results compared with traditional machine learning. Hungetal.[7]performed customer churn prediction by introducing back-propagation neural(BPN) networks, and the proposed method had outperformed machine learning models such as decision trees in terms of accuracy. Tsaietal.[8]combined two neural network techniques, namely the back-propagation artificial neural network (ANN) and self-organizing mapping (SOM), to perform customer churn prediction. Agrawaletal.[9]built a multilayer neural network for modeling learning by means of a nonlinear model. Huetal.[10]proposed a product-based recurrent neural network (RNN) to predict the churn of telecommunication customers. Pustokhinaetal.[11]used long-short term memory (LSTM) and stacked autoencode (SAE) models for customer churn prediction. Mitrovicetal.[12]and Almuqrenetal.[13]introduced social network analysis algorithms and social media mining models to churn analysis in telecommunications, respectively.
Current research in customer churn prediction has tried to introduce many deep models, but the current research is based on basic feature data for modeling analysis, without mining from the perspective of the overall user behavior sequences. To address the above issues, we propose a customer churn prediction model on user behavior sequences. For simplicity, we name the proposed multi-headed attention and long-short term memory network model as MALSTMN. We explore the interaction and correlation between multiple user behaviors, focus on the long- and short-term interest changes of each user, capture long- and short-term interests, and extract multi-angle feature information by introducing LSTM networks and multi-headed attention to user behavior sequences. All the learned feature representations and the user base information are combined by neural networks to obtain the final user representation and realize the customer churn prediction. The main contributions of this work are as follows.
(1) We delve into modeling user behavior sequences and propose a new model based on multi-headed attention mechanism and LSTM networks.
(2) For the aspect of temporal feature modeling, we introduce LSTM networks to predict temporal feature data and effectively solve the gradient disappearance and gradient explosion problems. For feature extraction, we introduce attention mechanism to learn collaborative information.
(3) We carry out the capture of information between different features of users and focus on different information perspectives through multiple self-attention mechanisms.
(4) We perform experiments on real datasets and the results show that our model achieves better results compared to the underlying neural network model.
1 Model Method
In this section, the MALSTMN model is presented in detail. The model consists of five main components. The input layer feeds user data into the model; the embedding layer converts sparse and high-dimensional user behavior data and user base information data into a low-dimensional dense matrix; the feature attention layer learns inter-feature dependencies and temporal relationships; the feature extraction layer is used for final feature extraction from multiple angles; the prediction layer is used for the final results. Figure 1 shows the complete model structure.
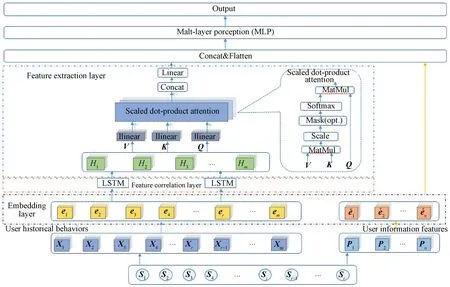
Fig. 1 General architecture of proposed model
1.1 Input layer
All user data inputs can be represented asS={S1,S2, …,Si, …,St}, wheretis the number of all users, andSi∈Stis the user data of theith user. Data of each user are composed of user historical behavior characteristic sequence data and user basic characteristic data. For user dataS, this can be specifically expressed asS=[X,P], whereXis the user historical behavior sequence data, andXi∈Xis the historical behavior sequence data of theith feature of the user;Pis the user base characteristic data, andPj∈Pis thejth user base characteristic information data of the user.
1.2 Embedding layer
Since both the user historical behavior characteristic sequence data and user basic characteristic data have very sparse and high-dimensional feature representations, we convert the high-dimensional sparse user history feature sequence data and user base information feature data into the corresponding low-dimensional dense matrix by the embedding layer. The specific implementation of the embedding layer is shown in the following equation:
ei=Embedding(Xi),
whereEmbeddingdenotes the operation of matrix multiplication between a row vector and its weights.
1.3 Feature correlation layer
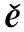
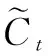
The input gate is used to control whether the current unit is affected by the input of the current user behavior information, the output gate is used to control whether the output information of the current unit affects the subsequent units, and the forgetting gate is used to control whether the previous user information state is forgotten, so as to dynamically adjust the user behavior data and achieve the mastery of the user’s overall interest preference.

Fig. 2 Structure of LSTM storage cell
1.4 Feature extraction layer
The output obtained from the feature attention layer isH. The feature extraction layer from multi-angle learns user behavior data among multiple features, and to realize the deep mining of user behavior data.
1.4.1Scaleddot-productattention
We employ self-attention mechanism to capture the dependencies between multiple user behaviors. In practice, we simultaneously calculate the attention function of a set of user behavior feature queries by transforming the user’s historical behavior sequence dataXthrough the feature embedding layer and the feature association layer, and then multiplying them by the weight matricesWQ,WK, andWV, respectively. We can obtain three matricesQ,K, andV[16].Qcan be understood as the query word;KandVare the information contents. Through Eq. (1), we can get the matching results.
(1)
1.4.2Multi-headedattention
The multi-headed attention mechanism, which enables the model to jointly pay attention to information in different representation subspaces at different locations, captures multi-perspective information among different behavioral features of users.
The specific implementation is to use key-value attention mechanism to identify the feature combinations and find the valuable forms of feature combinations. Taking as an example, we first define the correlation between featurewand featurebunder a specific attention headhas follows[16]:
(2)
(3)

(4)
In addition, the same user behavior profile may be combined with multiple other user behavior profiles in distributed interactions. We use multiple heads to create different subspaces by introducing multi-headed attention mechanism to distribute the learning of different feature interaction combinations. The output values of thedmodeldimension are generated by executing the attention function in parallel, and these data are concatenated and projected again[16]to obtain the final values.
MultiHead(Q,K,V)=Concat(head1,head2, …,headh)WO,
(5)
1.5 Prediction layer

U=MLP(D).
(6)
2 Experiments
In this section, we describe the actual telecom customer dataset, and the relevant settings of the parameters in the experiments, the comparison experiments with the time-series prediction base model, the ablation experiments, and the evaluation methods.
2.1 Datasets
In order to evaluate the validity of the MALSTMN model proposed in this paper, we used real telecom data of customers from July, 2019 to July, 2021. This dataset contains customer historical behavior data of temporal type and customer basic information data of non-temporal type (after desensitization). Customer historical behavior sequence data are the stitching of monthly behavior data generated by customers from July, 2019 to July, 2021 in the order of time size. The total current dataset is 1.05 million. Among them, customer behavior data mainly include: monthly_rent, arpu(average revenue per user), dou(dataflow of usage: average data flow per one month per one user), all_voice(user monthly voice allowance), sms_count(number of user sms per month), and call_voice(user monthly call voice volume). Customers base information data mainly include age, sex, and basic information on the network.
2.2 Experimental setup
The hyperparameters set for the experiments are lr: 0.001, batch_size: 200, hidden_units: 128, where lr is the learning rate, batch_size is the batch size, and hidden_units is the hidden layer unit size. We use Adam as the model optimizer in the experiments.
2.3 Evaluation metrics
To evaluate the effectiveness of the proposed MALSTMN model, the specific performance metrics to measure the model are the area under the receiver operating characteristic curve AUC, accuracy, precision, and F1_score. F1_score is a statistical indicator used to measure the accuracy of dichotomy models. It combines both the precision and recall of the classification model. The F1-score can be viewed as a harmonic average of the model precision and recall, with a maximum of 1 and a minimum of 0.
2.4 Comparison methods
We compare the model on the dataset with the following models.
(1) BaseModel[16]. It only uses the most basic self-attentive mechanism to model the user historical behavior characteristic sequence data for learning.
(2) Recurrent neural network(RNN)[17]. It is the most primitive RNN, which is essentially a fully connected network. Just to consider the past information, the output depends not only on the current input but also on the previous information. That is, the output is determined by the previous information (that is the state) and the input at this time.
(3) LSTM[14]. To solve problems such as gradient disappearance and explosion, and to get better prediction and classification of sequence data, RNN is gradually transformed into LSTM.
(4) Gate recurrent unit(GRU)[18]. GRU is also very popular because the training speed of LSTM is slow. GRU can be much faster with a slight modification on it, and the accuracy remains basically the same.
From the experimental results in Table 1, our proposed model is the best result among all methods. It can be seen that the proposed MALSTMN model achieves the best overall performance, and the effects such as AUC and accuracy ACC improve about 7.0% compared to those of the base attention model, and also about 0.2% compared to those of LSTM. Our model digs deeper into the customer behavior feature data than other models. On the basis of the RNN focused on temporal order, combined with the multi-headed attention mechanism to capture the impact of the overall behavior from multiple perspectives separately, the most suitable results are obtained.
In addition, it can be found that in terms of user behavior sequence modeling, RNN has better results.

Table 1 Experimental results of different models on real telecom user datasets
Also to further validate and gain insight into the proposed model, we performed an ablation study and compared the following variants of MALSTMN.
(1) MALSTMN-M. The effectiveness of the multi-headed attention mechanism module is demonstrated by removing the multi-headed attention mechanism and modeling the user behavior sequence using LSTM and self-attentive mechanism.
(2) MALSTMN-L. The effectiveness of the LSTM module is demonstrated by removing the LSTM module and modeling the user behavior sequence using only the multi-headed attention mechanism.
(3) MARNNN. The LSTM superiority is demonstrated by replacing the LSTM module with an RNN module to model the user behavior sequence.
(4) MAGRUN. The LSTM superiority is demonstrated by replacing the LSTM module with the GRU module to model the user behavior sequence.
The specific ablation experimental results are shown in Table 2. By removing the multi-headed attention module and LSTM module by MALSTMN-M and MALSTMN-L, respectively, the effect decreases compared to the complete MALSTMN model, which proves the effectiveness of the multi-headed attention module and LSTM module. By comparing the actual effect of MARNNN, MAGRUN, and MALSTMN, the experiments prove the effectiveness of LSTM in comparison to other RNNs.

Table 2 Comparative study of ablation performance of MALSTMN modules
3 Conclusions
In this paper, we propose a user off-grid prediction model based on user behavior sequences. We fully model and analyze the behavioral data generated by the user over a long period of time, and do not just replace the overall features of the user with the behavioral feature data at a certain time, taking into account the long-term data of the user and mining more information about the user compared to traditional prediction models. Specifically, we learn the modeling of interest evolution of user behavior sequence data through the LSTM networks in the temporal prediction model to master users’ long short-term interest preferences as a whole, and then capture information from multiple perspectives across multiple user features through the multi-headed attention mechanism to find the similarity among users and user feature data. An extensive experimental analysis confirms the superiority of our proposed model MALSTMN over traditional timing prediction methods. In future work, we plan to fully model user base information, mine more user base information, and explore more similarities between user behaviors and between users so that the model can learn more useful information and improve the accuracy of the user off-grid prediction system.
 Journal of Donghua University(English Edition)2022年6期
Journal of Donghua University(English Edition)2022年6期
- Journal of Donghua University(English Edition)的其它文章
- Conductive Polyacrylonitrile Fiber Prepared by Copper Plating with L-Ascorbic Acid as Reducing Agent
- Fabrication and Characterization of Yarn-Based Temperature Sensor for Respiratory Monitoring
- Anti-wrinkle Finishing of Cotton Fabrics with Pyromellitic Acid Enhanced by Polyol Extenders
- Preparation and Characterization of Sepiolite Microfibers with High Aspect Ratio
- Solution Blowing of Palygorskite-Based Nanofibers for Methylene Blue Adsorption
- Active Absorption of Perforated Plate Based on Airflow