
Active Kriging-Based Adaptive Importance Sampling for Reliability and Sensitivity Analyses of Stator Blade Regulator
2023-01-21 08:04HongZhangLukaiSongandGuangchenBai
Hong Zhang,Lukai Song,2,★and Guangchen Bai
1School of Energy and Power Engineering,Beihang University,Beijing,100191,China
2Research Institute of Aero-Engine,Beihang University,Beijing,100191,China
ABSTRACT The reliability and sensitivity analyses of stator blade regulator usually involve complex characteristics like highnonlinearity,multi-failure regions,and small failure probability,which brings in unacceptable computing efficiency and accuracy of the current analysis methods.In this case,by fitting the implicit limit state function(LSF)with active Kriging(AK)model and reducing candidate sample pool with adaptive importance sampling(AIS),a novel AK-AIS method is proposed.Herein,the AK model and Markov chain Monte Carlo(MCMC)are first established to identify the most probable failure region(s) (MPFRs),and the adaptive kernel density estimation (AKDE) importance sampling function is constructed to select the candidate samples.With the best samples sequentially attained in the reduced candidate samples and employed to update the Kriging-fitted LSF,the failure probability and sensitivity indices are acquired at a lower cost.The proposed method is verified by two multi-failure numerical examples,and then applied to the reliability and sensitivity analyses of a typical stator blade regulator.With methods comparison,the proposed AK-AIS is proven to hold the computing advantages on accuracy and efficiency in complex reliability and sensitivity analysis problems.
KEYWORDS Markov chain Monte Carlo;active Kriging;adaptive kernel density estimation;importance sampling
Nomenclature
AK Active Kriging
AIS Adaptive Importance Sampling
AKDE Adaptive Kernel Density Estimation
AK-IS AK combined with Importance Sampling
AK-MCS AK combined with MCS
AK-AIS Active Kriging-based Adaptive Importance Sampling
C.O.V.Coefficient of Variation
DS Directional Simulation
FORM First-Order Reliability Method
HCF High Cycle Fatigue
iPDF Instrumental PDF
IS Important Sampling
KAIS Kriging-based Adaptive Importance Sampling
LSF Limit State Function
M-H Metropolis Hastings
MCS Monte Carlo Simulation
MPP Most Probable Point
MCMC Markov chain Monte Carlo
MPFRs Most Probable Failure Region(s)
Meta-IS Meta-model-based Importance Sampling
PDF Probability Density Function
SORM Second-Order Reliability Method
1 Introduction
During the air compression process of aeroengine compressor,stator blade regulator plays a key role in increasing airflow and preventing surge phenomenon [1].As shown in Fig.1,by driving the multiple rocker arms in regulator,the blade inlet angle can be adjusted in place quickly.Nevertheless,due to the coupling effects of complex fluid-solid loads and repeated reaction forces from stator blade,high-frequency alternating stress and high cycle fatigue(HCF)failure are inevitably induced in these rocker arms.Engineering practice shows that the HCF failure occurred in multiple rocker arms has become the main failure mode and seriously affects the structural reliability of stator blade regulator[2–9].Moreover,on account of the multiple uncertainties of material variabilities,load variations and model randomness [10–17],large random behaviors physically emerge in these HCF lives [18–25].Therefore,it is required to develop reasonable probabilistic analysis methods to address these multiple uncertainties,quantify the stochastic behaviors,and ensure the structural reliability of stator blade regulator.

Figure 1:Schematic diagram of stator blade regulator
For probability analysis problems involving multiple random input variables,the key point is to calculate the following multivariate integral,i.e.,

wherexis the vector of random input variables;g(x)the limit state function,whereg(x)≤0 denotes the failure event;fX(x)the joint probability density function ofx;I[·] the failure domain indicator function,having the value 1 ifg(x)≤0 and the value 0 otherwise.
To obtain the failure probability by solving Eq.(1),the first-order reliability method (FORM)[26–28],second-order reliability method(SORM)[29,30],moment method[31,32],and Monte Carlo simulation (MCS) [33,34] have been developed and widely used.Unfortunately,for small failure probability (10-3~10-7) problems,a large number of sampling times and real limit state function(LSF) calls need to be generated [35–37],which limits the MCS availability due to the unacceptable sampling efficiency.To reduce the unaffordable computing tasks of the crude MCS method,surrogate model combined with MCS strategy has been emerged[38–47].As one impressive progress,the active learning Kriging(AK)combined with MCS(AK-MCS)is proposed,which can decrease the required LSF calls by only adding the failure samples in model updating process.Due to the advantages of fast modeling and accurate approximation,AK-MCS is widely used in reliability analysis [48–50].However,the estimation of small failure probability remains an issue for AK-MCS,since the method still regards the MCS sample pool as the sampling candidate regions.In this case,researchers have found a wise solution to avoid such disadvantages by integrating AK-MCS with variance reduction techniques [51–53].Wang et al.[54] incorporated multi-ring-based importance sampling into the Kriging.Tong et al.[55] introduced subset simulation importance sampling into the AK model.Zhang et al.[56] combined directional sampling with adaptive Kriging to overcome the limitations of the AK-MCS method.
In recent years,by shifting the sampling center from the origin to the most probable point(MPP),AK combined with importance sampling (AK-IS) can produce satisfactory results as long as the MPP can be well identified.Moreover,it has become hot solution paths in addressing small probability problems[57].Nonetheless,since only single MPP can be obtained,the traditional AK-IS method can only suitable to limit state functions with one single failure region,which significantly limits its application to multiple failure regions[58,59].In this case,to address the multiple MPPs or multiple most probable failure regions(MPFRs)in small failure probability problems,by combing AK model to obtain the samples in failure regions and kernel density estimation (KDE) to generate the importance samples,Markov chain Monte Carlo(MCMC)method based on improved Metropolis-Hastings (M-H) algorithm has been developed.Zhao et al.[60] used Markov chain Metropolis algorithm to efficiently generate samples in the failure region.Nassim et al.[61]used MCMC sampling method to explore all the failure regions.Cadini et al.[62] used MCMC and K-means clustering algorithm to identify the multiple-failure regions.Unfortunately,due to the fixed KDE function and great subjectivity in determining the initial state of MCMC [60,62],a large tail error of the kernel density function and unreasonable initial state problems can occur,inevitably decreasing the modeling accuracy.
Under such circumstances,by fitting the implicit LSF with AK model and reducing candidate sample pool with adaptive importance sampling(AIS),a novel AK-AIS method is proposed to address the high-nonlinearity,multiple failure regions,and small failure probability problems.In the proposed method,AK model is adopted to determine the initial state of Markov chain and identify the MPFRs,and the adaptive kernel density estimation(AKDE)function is constructed to generate the candidate importance samples in adaptive reduced sample pool.By sequentially importing samples to update the Kriging model,the reliability and sensitivity indices can be obtained through few real LSF calls.Compared with the current relevant methods [63–65],two computing advantages are accompanied with the AK-AIS method: (1) the AK model guided MCMC procedure can precisely determine the initial state of Markov chain and identify the MPFRs.(2) AKDE function needs fewer candidate samples and smaller candidate regions in model updating.These advantages are validated by two numerical examples and can be exploited in the reliability and sensitivity analyses of stator blade regulator.
The organization of this paper is summarized as follows: The AK-AIS method is expounded in Section 2.In Section 3,the effectiveness of the proposed method is examined by two numerical examples.In Section 4,reliability and sensitivity analyses of stator blade regulator are performed using the proposed method.Some conclusions are summarized in Section 5.
2 The Proposed AK-AIS Method
In this section,to reduce the calls of real LSF and improve the computing accuracy of complex reliability and sensitivity analysis problems,a novel AK-AIS method is presented,which includes the identification of the MPFRs,adaptive importance sampling and the corresponding procedures.The basic principle of the proposed AK-AIS method is illustrated in Fig.2.
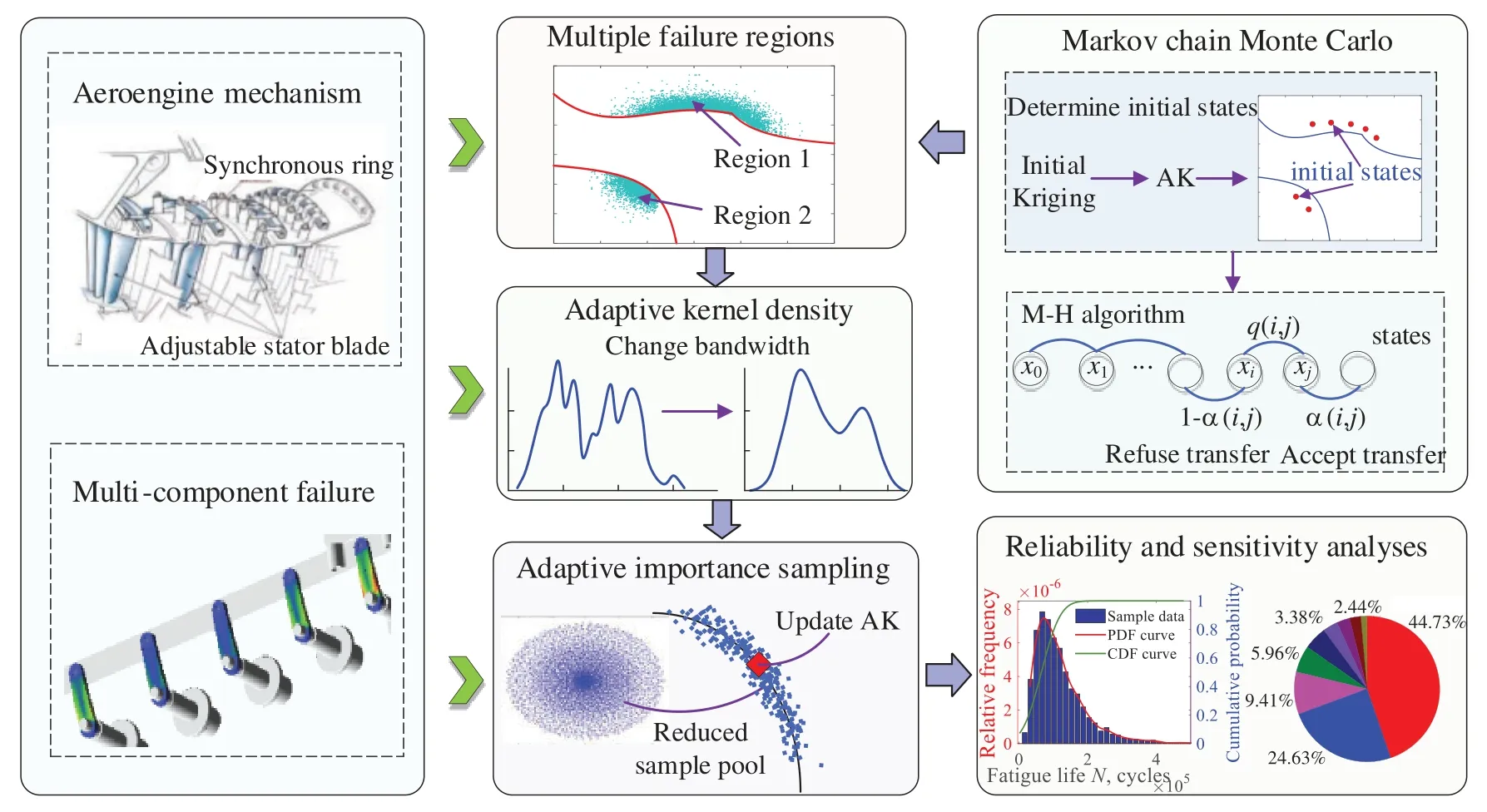
Figure 2:Basic principle of the proposed AK-AIS method
2.1 AK-Based MPFRs Identification
By determining the initial state of Markov chain with AK model and calibrate the boundaries by M-H algorithm,the accurate identification of the MPFRs is realized as follows.
2.1.1 MCMC Initial State Determination
To acquire the precise steady state distribution(i.e.,optimal importance sampling density function) in complex reliability and sensitivity problems,the AK model instead of subjective experience[66,67]is employed to determine the initial state of Markov chain.The basic thought is introduced as follows.
(1)Initial Kriging establishment
Considering Latin hypercube sampling(LHS)technique,the initial samplesx=[x1,x2,...,xs]and the corresponding responsesg0(x)are extracted.Based on the initial sample setD0={x,g0(x)}and Kriging tool[68,69],the initial Kriging can be built as

wherefT(x)=[f1(x),f2(x),...,f m(x)] is the regression basis function;β=[β1,β2,...,βm] the regression coefficient;mthe dimension number of regression function;z(x)the local random deviation,which follows Gaussian distribution(0,σ2).
(2)Kriging model update with active learning function
Considering the large-scale randomly generated samples(i.e.,104samples)as candidate sampling pool,based on active learning function(i.e.,U[49],expected feasibility function(EFF)[70],reliabilitybased expected improvement function(REIF)[71],and REIF2[71]),the best next samplexk.can be identified and sequentially employed to update Kriging model.Regarding U function as an example,with the best next samplexk={U(x)},the corresponding LSFg(xk)is called and calculated.By adding the sample{xk,gk(x)}into thek-th sample setDk,thek-th updating Kriging modelgk(x)can be acquired as

(3)Screening the samples located in failure regions
Based on the updated Kriging model,the failure region samples withg(xi)<0(i=1,2,...,N)are screened out,and selected as the initial state of Markov chain.These screened samples are denoted as {x1,x2,...,xm} (m=1,2,...,l,l≥1).Due to the initial state obtained are determined by the failure samples,the obtained steady state distribution of MCMC would be more accurate than that of subjective experience methods.
Moreover,it should be noted that compared with the direct subjective given initial state of Markov chain,although the additional large candidate sampling pool (i.e.,104samples) is used to update Kriging model,only few LSF calls are required during the determination of the MCMC initial state.
2.1.2 Calibration of the Multiple Failure Boundaries
During the transition of the Markov chain from one state to another,by introducing an acceptance mechanism,M-H algorithm is adopted to accept the new transition state with a certain probability.With the combination of the state transition probability and acceptance probability,the failure samples can be generated quickly in Markov chain simulation.Considering the distributions of failure samples,the multiple failure boundaries can be accurately calibrated.The main steps are introduced as follows.
(1)Stationary distribution selection
Considering the obtained initial state of Markov chain{x1,x2,...,xm},to accurately acquire the desired samples in the failure region,and the limit stationary distribution is chosen as the optimal importance sampling density(ISD)hX(x)=IF(x)fX(x)/Pf.
(2)j-th state of Markov chain determination
Regarding the(j-1)-th statex(j-1),thej-th statex(j)can be generated by M-H algorithm.The ratiorof the conditional probability distribution of the candidate statex*to the previous statex(j-1)is defined as

According to the improved M-H criterion [72],x*is accepted as thej-th chain state,that isx*=x(j)ifr≥1,and vice versa.
(3)Failure boundaries calibration
Repeat Step(2)untilMMarkov chain states{x(1),x(2),...,x(M)}are acquired.Based on Steps(1)–(3),all Markov state samples{x(1),x(2),...,x(M)}residing in failure regions are obtained.Regarding the distribution of failure samples,the multiple failure boundaries can be effectively calibrated,and the MPFRs can be accurately identified,which is conducive to construct the efficient probability density sampling function to enhance the sign classification precision in complex reliability and sensitivity analyses.
2.2 Adaptive Importance Sampling
To address the large tail error problem caused by the fixed KDE function and low modeling efficiency problem caused by the large candidate sampling pool in IS method,an adaptive kernel density estimation(AKDE)function is constructed based on the identified MPFRs,and an adaptive reduced sampling pool varying with the fitted Kriging model is established.By combining the AKDE to generate important samples and the adaptive reduction sample pool to reduce candidate important samples,the adaptive importance sampling(AIS)method is proposed to guarantee a small tail error and few calls of real LSF.
2.2.1 Adaptive KDE Function Construction
Considering the generated samples in identified MFPRs,by combing Gaussian kernel function with high robustness and adaptive kernel window width parameter,a width-varying KDE function(i.e.,optimal important sampling density function) is built.This function can be regarded as the optimal important sampling density function,which can generate a set of important samples based on discrete random integer interpolation.Since the AKDE function fitted by the samples in identified MFPRs is closer to the optimal sampling density function,the sampling accuracy is promising to be elevated.
Based on the generated samples{x(1),x(2),...,x(M)}located in identified MFPRs,by modifying the window width parameterωand local bandwidth factorλj,the probability density function of those samples can be estimated by the following AKDE function,i.e.,

in which

whereMdis the number of different samples,Md≤M;αthe sensitivity factor,0 ≤α≤1;x(j)thej-th sample in failure region,j=1,2,...,M;Mthe number of sample points;nthe variable dimension;ωthe window width parameter;λthe local bandwidth factor;K(·)the KDE function,the frequentlyused gauss KDE function[64,72]is expressed as

whereCis the covariance matrix of the sample point set{x(1),x(2),...,x(M)},which mainly describes the data dispersion of each sample point in different directions and ranges.

whereis the mean value of these samples.
Assuming that a discrete random integersuobeying uniform distribution on interval[1,M].Ifu=j(j=1,2,...,M),the kernel density functionhj(·)of thej-th component is selected to generate samplexi(i=1,2,...,N).hj(·)can be represented as

wherex(j)(j=1,2,...,M)are the samples generated by Markov chain.The above sampling process is repeated untilNimportance samplesx1,x2,...,xNare obtained.
The window width parameter controls the smoothness of the AKDE function.By adaptively adjusting the kernel window width in the KDE process,the constructed AKDE function is promising to improve the smoothness degree and accelerate the convergence of the optimal sampling density function,then the desired important samples can be generated precisely.
2.2.2 Candidate Sampling Pool Reduction
Regarding the large candidate importance sampling pool will reduce the finding efficiency of the desired samples,by only selecting the importance samples close to the Kriging-fitted LSF as the candidate sample pool[73],the reduced important sampling pool is proposed.As illustrated in Fig.3,f G(G)is the joint probability density function of the performance predictionsG,the zone near the LSFG(x)=min(g1(x),g2(x))in the input(X)spaceΩLxSFand the output(G)spaceΩLGSFcan be defined as

in which

wheregindicates the real performance function;ˆgithe estimated value of thei-th performance function,i=1,2;τthe 2-elements vector whose all elements are equal to the threshold value,which can be given according to the actual situation;Fthe unit column vector;r=[R(x,x1),R(x,x2),...,R(x,xn)]Tthe correlation vector between an predicted pointxand training sample points (x1,x2,...,xn);Rthe correlation matrix.Based on the definition of zone ΩLxSFand ΩLGSFin Eqs.(10) and (11),the whole candidate important samples pool generated by the AKDE is divided into two parts(inner zone and outer zone).By taking the importance samples inner the zone as candidate samples,the Kriging model is further updated to achieve the accuracy sign prediction of IS samples.The proposed reduction strategy of candidate sample pool has the potential to improve modeling efficiency and accuracy with few calls of real performance function.
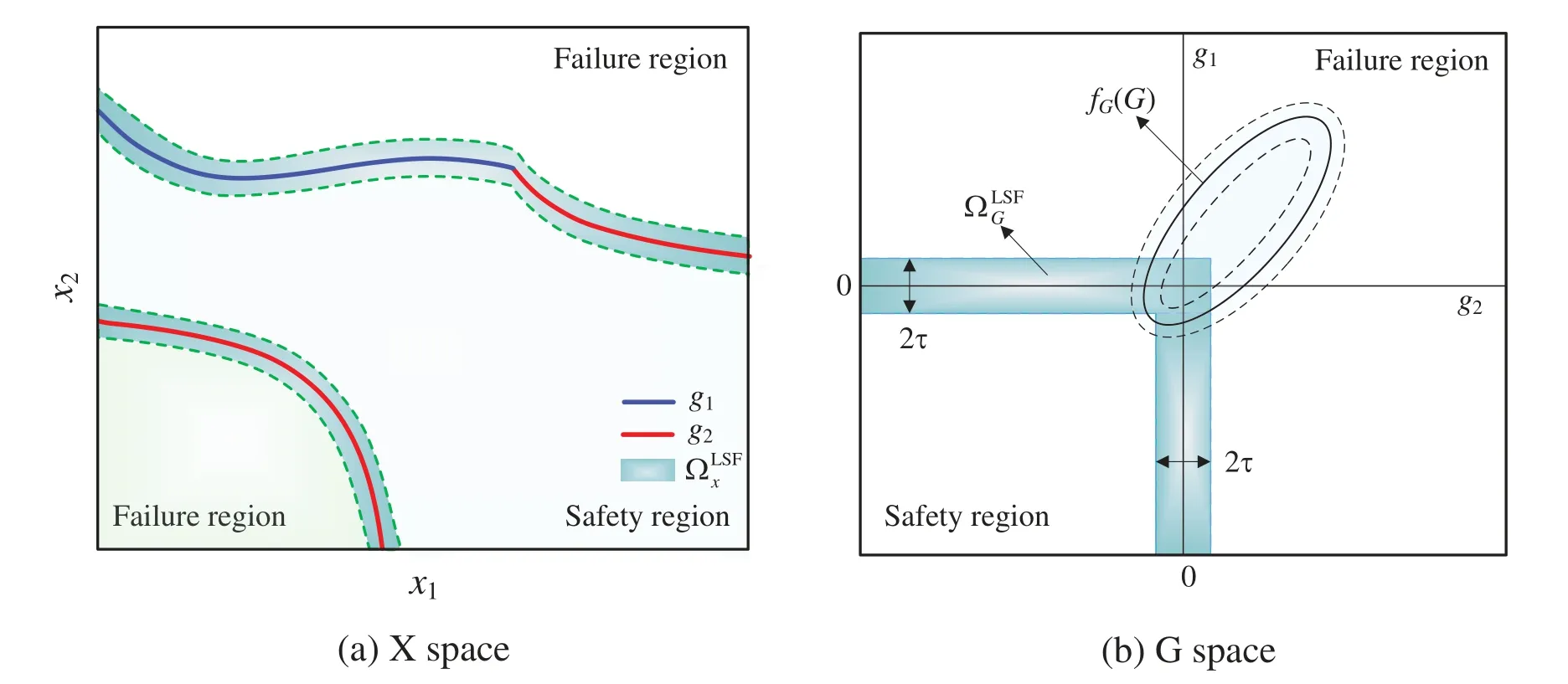
Figure 3:Reduction principle of the candidate sampling pool
With the reduced candidate sampling pool,the number of candidate samples is significantly reduced.Moreover,the reduced candidate sampling pool moves adaptively as the Kriging-fitted LSF updated ceaselessly,which ensures that the desired samples can be precisely found.In addition,since the Kriging update process is based on AK model described in Section 2.1.1,the best fitted LSF can be approached with fewer calls of the real LSF,which can significantly increase the modeling accuracy and efficiency.Once the best fitted LSF is acquired,the unbiased estimationcan be expressed as

wherexidenotes thei-th sample points,Nthe number of candidate samples;f X(x)the joint probability density function ofx;hX(x) the importance sampling probability density function;IF(·) the failure domain indicator function,having the value 1 ifg(x)≤0 and the value 0 otherwise.
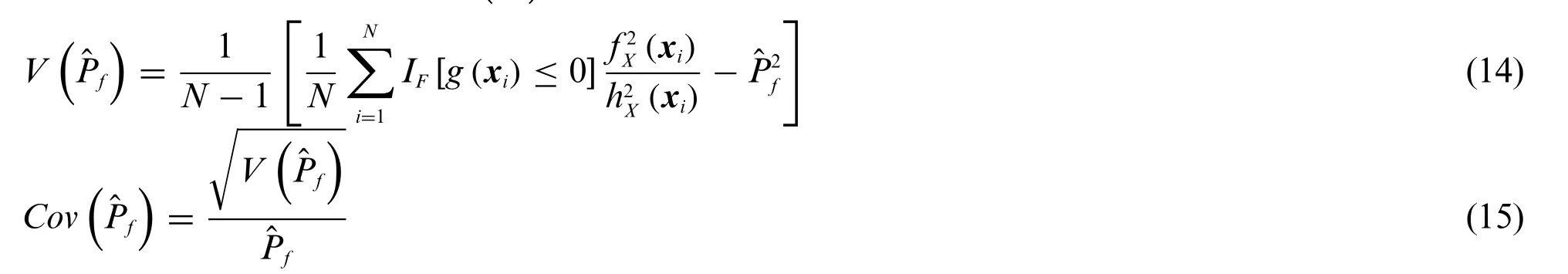
With the samples of input random parameters gained by massive samplings,the local sensitivity index of the failure probabilityPfwith respect to the distribution parameterθxi,i.e.,meanμxiand standard deviationσxiin the normal distribution)of each input variablexiis estimated as

wherexjis the important sampling points,j=1,2,...,N;is thek-th distribution parameter ofxi;the partial derivative of thek-th distribution parameter ofxi.
To assess the effect ofxion the failure probability in its entire distribution ranges,a global sensitivity index is established[74,75]as

wherePf|xiindicates the conditional failure probability,which can be rewritten as the condition expectation of the indicator function

Therefore,the sensitivity index is transformed into a variance-based index of the indicator function,i.e.,

Based on the total variance law
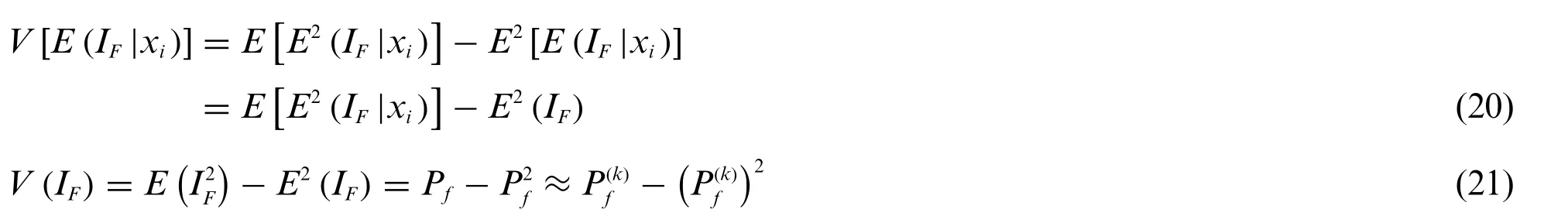
whereV(·) is the variance value function;V(IF) represents the variance ofIF;E(·) the mean value function,E[E2(IF|xi)]is expressed as
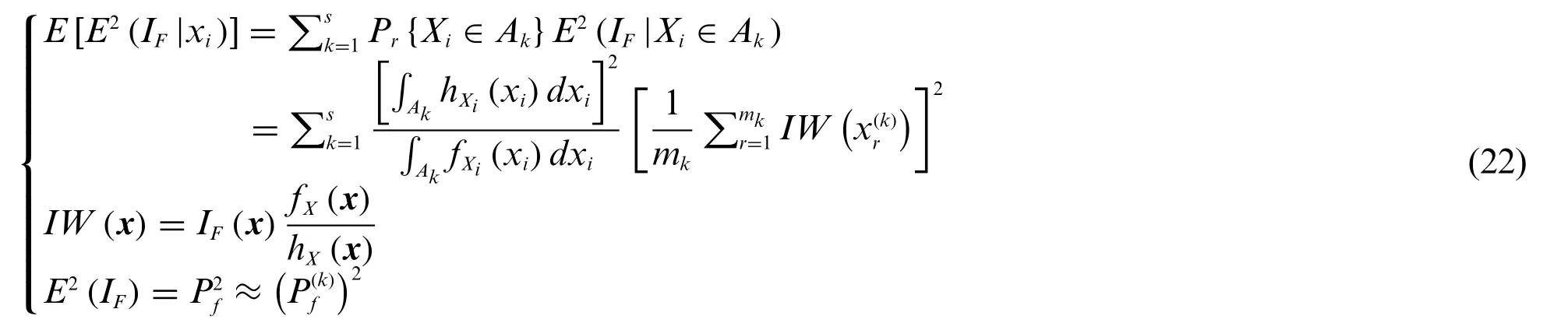
The normalized version of the main effect index and total effect index are given as
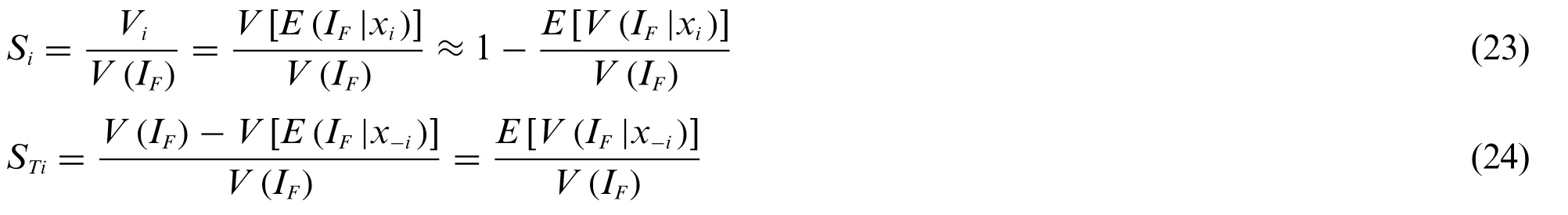
whereSiandSTiare the main effect index and total effect index of the single input variablesxi,respectively.
2.3 AK-AIS Procedure
The flowchart of the proposed algorithm is depicted in Fig.4.The basic procedure is summarized as follows:

Figure 4:The flowchart of the proposed AK-AIS method
Step 1:Transform input variables into standard normal space.
Step 2:Construct the initial Kriging model.Considering the initial samples set by LHS technique and Kriging toolbox,the initial Kriging model is constructed.
Step 3:Determine the initial state of Markov chain.The Kriging model is updated by active learning function and the initial states of Markov chain are obtained by AK model.
Step 4:Generate failure samples populating all the MPFRs.Based on the initial state of Markov chain,more samples located in the failure region are acquired through M-H algorithm,and all the MPFRs are identified.In this step,none of samples is evaluated with the real performance function.
Step 5:Perform AKDE and generate candidate important samples.A quasi-optimal iPDF for IS is constructed by AKDE,and then a large number of important samples are generated obeying the quasi-optimal iPDFhX(x).
Step 6: Determine adaptive reduced sample pool.Taking the important samples in the reduced pool as candidate samples,the Kriging model is updated again until approaching the real LSF to ensure the prediction accuracy of important sample signs.If the update stop criterion is satisfied,the active learning process stops,and the algorithm goes to Step 7.Otherwise,continue to perform Step 6 to determine the reduced sample pool and update the Kriging model.Note that the AK model in this step is to obtain a high-precision surrogate model to realize the accurate prediction of important sample signs.The AK model in Step 3 is to obtain the initial state of Markov chain.The modeling purposes of the two steps are different.Since the Kriging model has been updated in Step 3,the AK model in this step can quickly approach the real LSF with fewer real LSF calls by combing with the adaptive sample pool reduction strategy.
Step 7:Estimate failure probability,C.O.V.and sensitivity.With the final Kriging model,the failure probability,C.O.V.and sensitivity can be estimated.If the estimated C.O.V.is larger than the requested criterion (i.e.,0.05 in this paper),the procedures will go back and re-execute Step 5.Note that no information about previous true evaluations is lost in Step 7,which prevents the waste of computing resources.
Step 8: End the algorithm and outputIf the C.O.V.meets the requirements,the algorithm is stopped,and the final results of failure probability and sensitivity are output.
Noticeably,by precisely identifying the most probable failure regions with AK model and efficiently re-updating the Kriging-fitted LSF by adaptive importance sampling,the proposed AK-AIS method holds the potential to improve the computational efficiency and accuracy for complex reliability and sensitivity analysis problems.
3 Numerical Examples
To demonstrate the accuracy and efficiency of the proposed method,two numerical examples are selected to compare the proposed method with the existing methods.All computations are performed on an Inter(R)Core(TM)Desktop Computer(3 GHz CPU and 16 GB RAM).
3.1 Numerical Example 1(Series with Three Branches)
The first example is taken from references [65,72].The performance function with three failure regions is defined as

wherex1andx2are two independent standard Gaussian random variables.
To identify the MPFRs using the proposed AK-AIS method,the real LSF functions are called 13 and 25 times to build and update the Kriging model,respectively;in the AIS process,the real LSF functions are further called 13 times to approximate the LSF curves.With 51 (i.e.,13 + 25+ 13) real LSF calls,the failure probability is achieved as 3.39×10-3and the sensitivity indices are listed in Table 1.The comparisons in Fig.5 illustrate that the MPFRs identification ability is consistent with that of the MCS method even with few real LSF calls.To investigate the effect of the active learning function on the efficacy of the AK-AIS model,several active learning functions are combined with AK-AIS model,whose sampling distributions and fitted LSF curves are depicted in Figs.6–7,respectively.The results show that:compared with AK-AIS+REIF,AK-AIS+REIF2 and AK-AIS+EFF methods,the AK-AIS+U method can approximate the real LSF with minimal real LSF calls.

Table 1:The PRS and GRS results for example 1
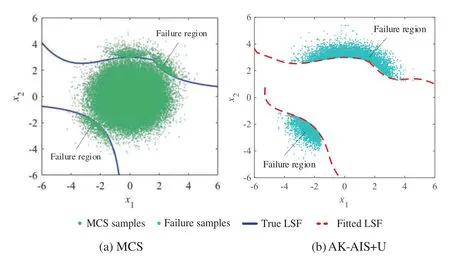
Figure 5:Comparison of MCS and the proposed method for example 1
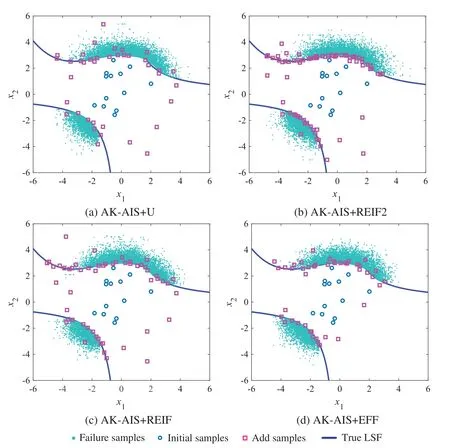
Figure 6:Comparison of active learning function for example 1
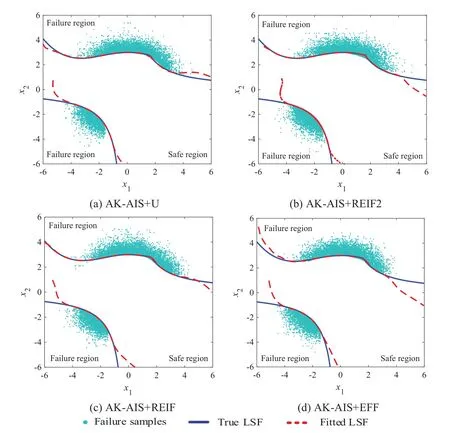
Figure 7:Comparison of fitted LSF for example 1
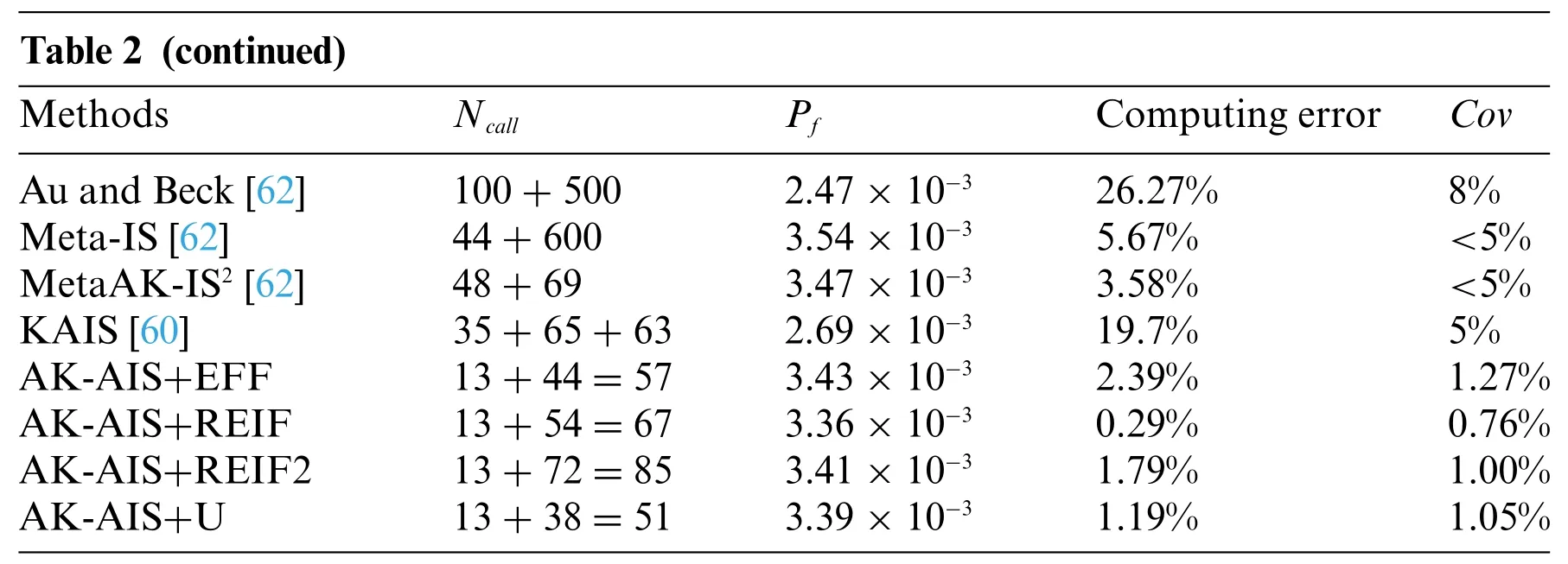
To validate the computational advantages of the proposed method,MCS,FORM,Subset,Meta-IS,MetaAK-IS2,and KAIS are also performed the example.From Table 2 and Fig.8,we observe that the AK-AIS(with U function)displays the highest accuracy and efficiency than FORM,Subset,Meta-IS,MetaAK-IS2and KAIS,and its failure probability (3.39×10-3) is closest to the reference value (3.35×10-3) of MCS.Moreover,as shown in Fig.8,compared to current methods,AK-AIS holds the minimum computing error of failure probability.Current small failure probability methods like MetaAK-IS2and KAIS acquire the failure probability are 3.47×10-3and 2.69×10-3by calling real LSF functions with 117 and 163 times,respectively,which consumes more time and lower accuracy than that of the proposed method.Therefore,the proposed AK-AIS method is validated to achieve high computing accuracy at a smaller price than other methods with subjectively given Markov chain initial state.

Table 2:The failure probability analysis results for example 1 by different methods
Note:Assuming that the Pf MCS indicates the failure probability obtained by direct MCS and Pf denotes the failure probability retrieved by other methods,the computing error of each method is calculated by 1-[(|Pf MCS -Pf|)/Pf MCS]×100%.
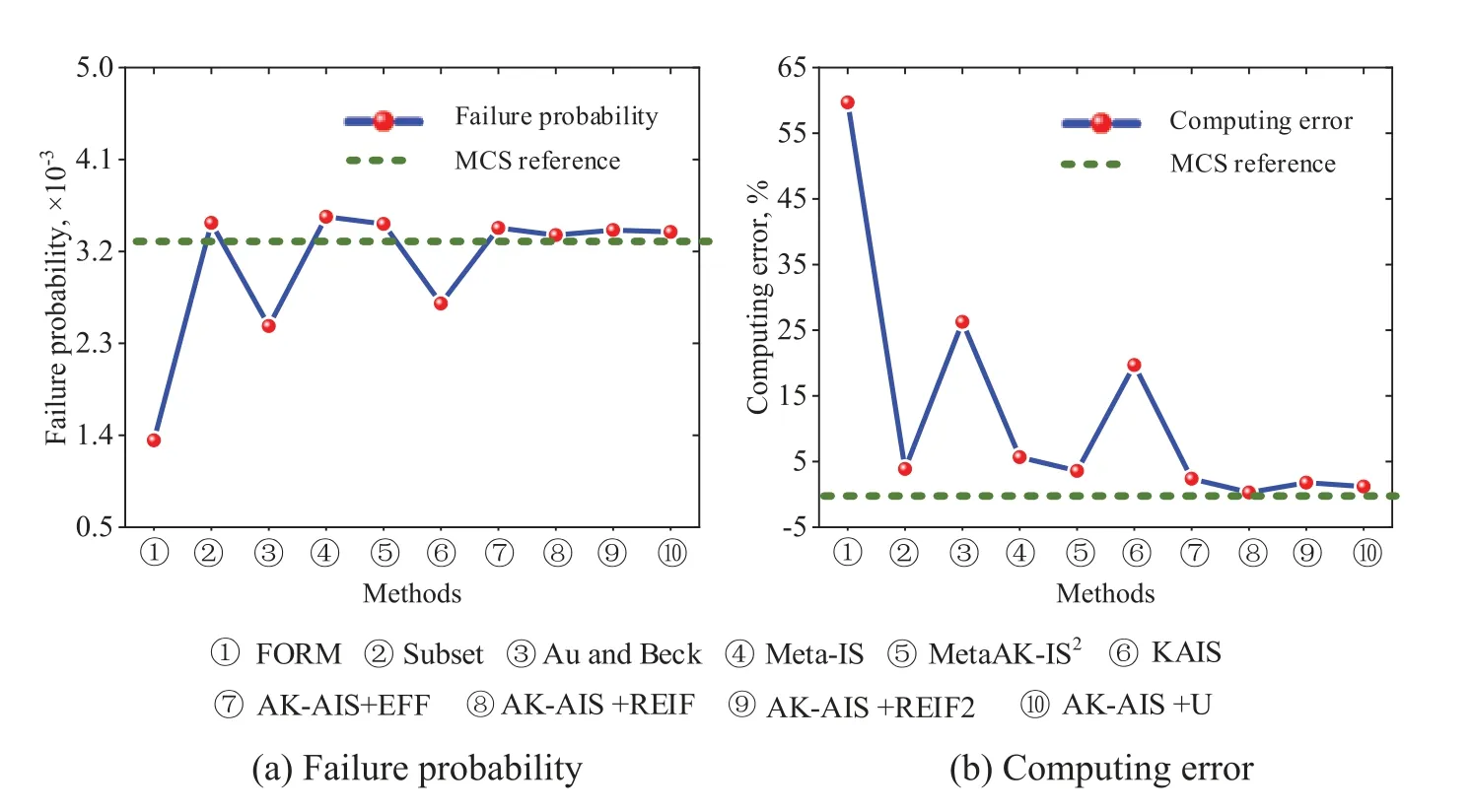
Figure 8:Comparison of the reliability results for example 1
3.2 Numerical Examples 2(Series with Four Branches)
The second example[76,77]is a LSF function with four failure regions,which is defined as
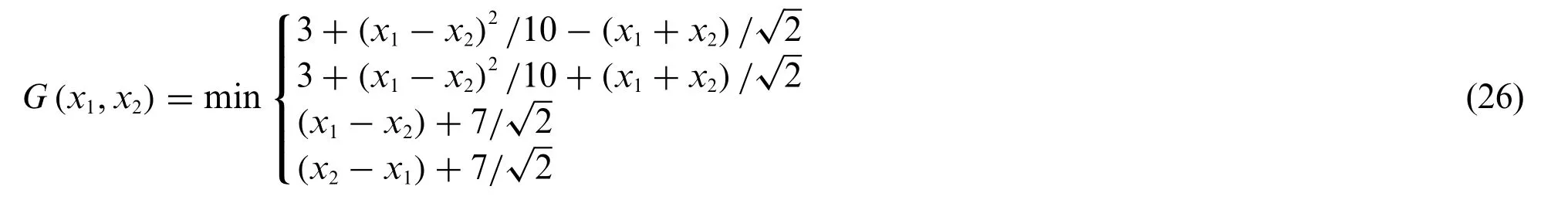
wherex1andx2are two independent standard Gaussian random variables.
Using the proposed method,the real LSF are called 10,19,and 23 times to build,update,and re-update the Kriging model,four failure regions are identified and the adaptive importance sampling is performed,respectively.With 52(i.e.,10+19+23)times of real LSF calls,the failure probability is achieved as 2.22×10-3and the sensitivity indices are acquired in Table 3.Compared with MCS method (Fig.9),the proposed method can well identify four MPFRs at a lower cost.In addition,various active learning functions are combined with AK-AIS,and their sampling distributions and fitted LSF curves are compared in Figs.10 and 11.Comparison results reveal that the AK-AIS combined with U function exhibits better LSF approximation effect than that of other combining types.

Table 3:The PRS and GRS results for example 2
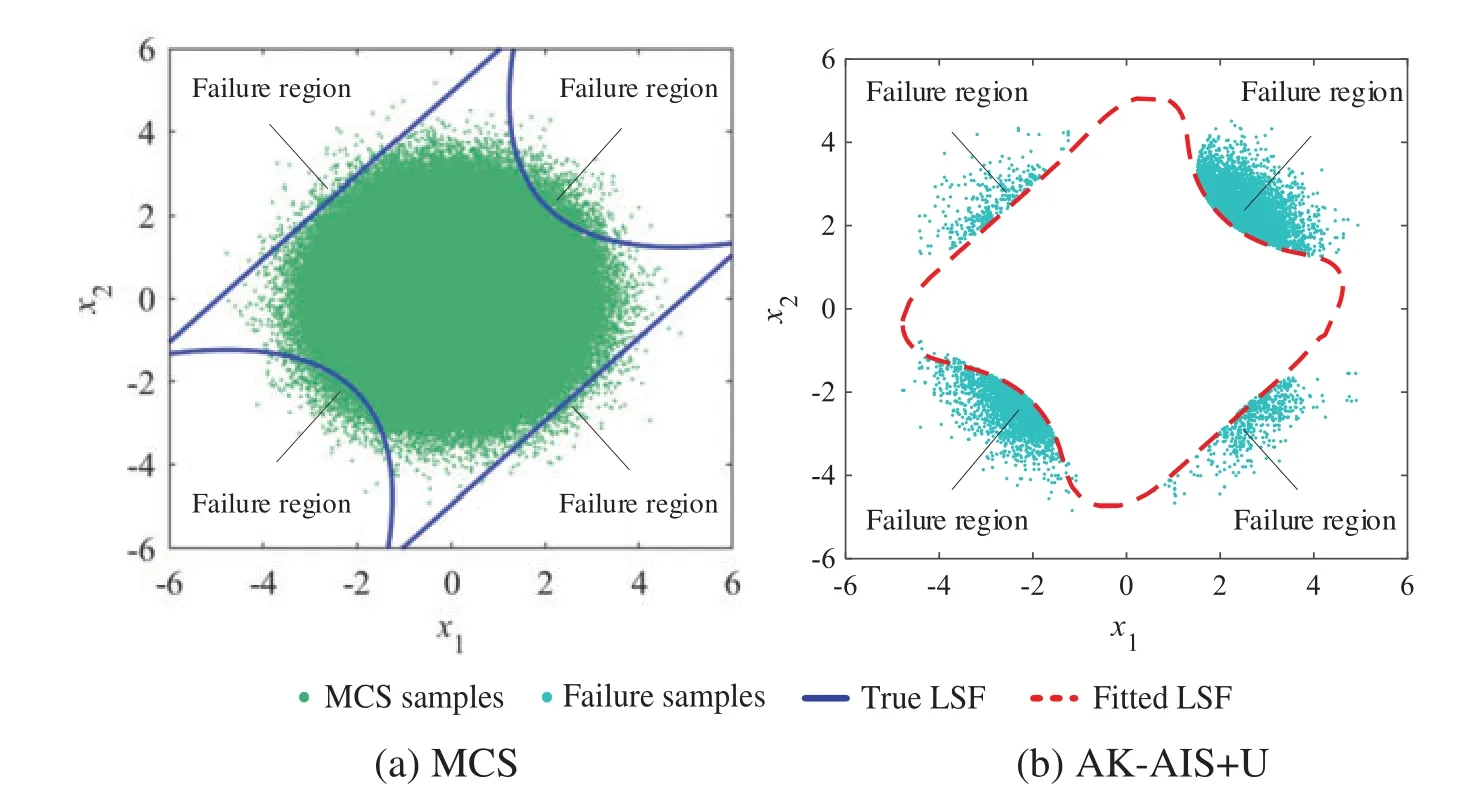
Figure 9:Comparison of MCS and the proposed method for example 2
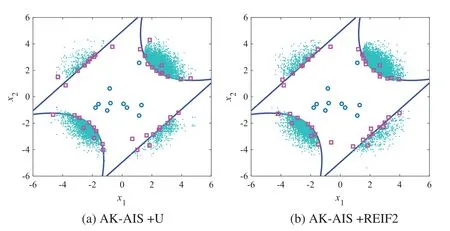
Figure 10:(Continued)
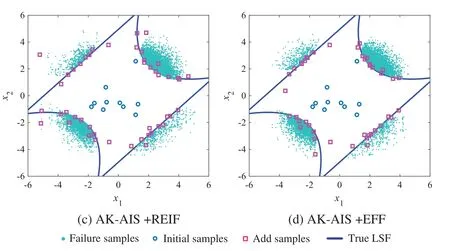
Figure 10:Comparison of activing learning process for example 2
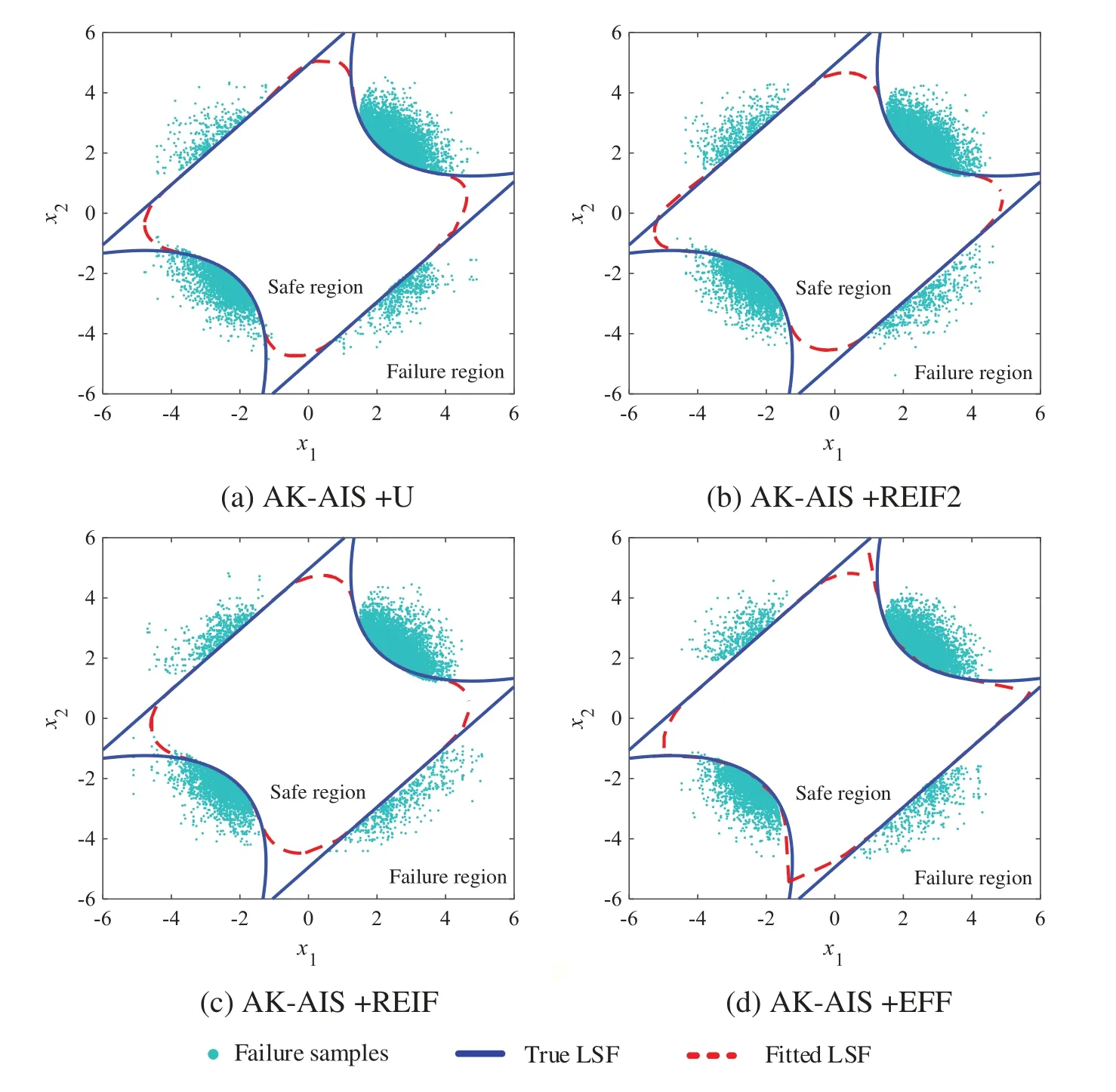
Figure 11:Comparison of LSF for example 2
To validate the computational advantages of the proposed method,Table 4 and Fig.12 compare the numerical results acquired from MCS,FORM,DS,Subset,SMART,MetaAK-IS2,and the proposed method.The AK-AIS (with U function) only needs 52Ncallto achieve the highest sign prediction and lowest coefficient of variation,which shows better computing efficacy than DS,Subset,SMART,and MetaAK-IS2.As revealed in Fig.12,although AK-AIS has the same failure probability with that of DS,Subset,and MetaAK-IS2;AK-AIS method has lower coefficient of variation and less calls to real performance function.Moreover,for MetaAK-IS2method with subjectively determining the initial state by engineering experience,it should call the real LSF 138 times to reach the equivalent accuracy as AK-AIS method.In summary,in four failure regions cases,the proposed method holds a strong competitive advantage on computing accuracy and efficiency.
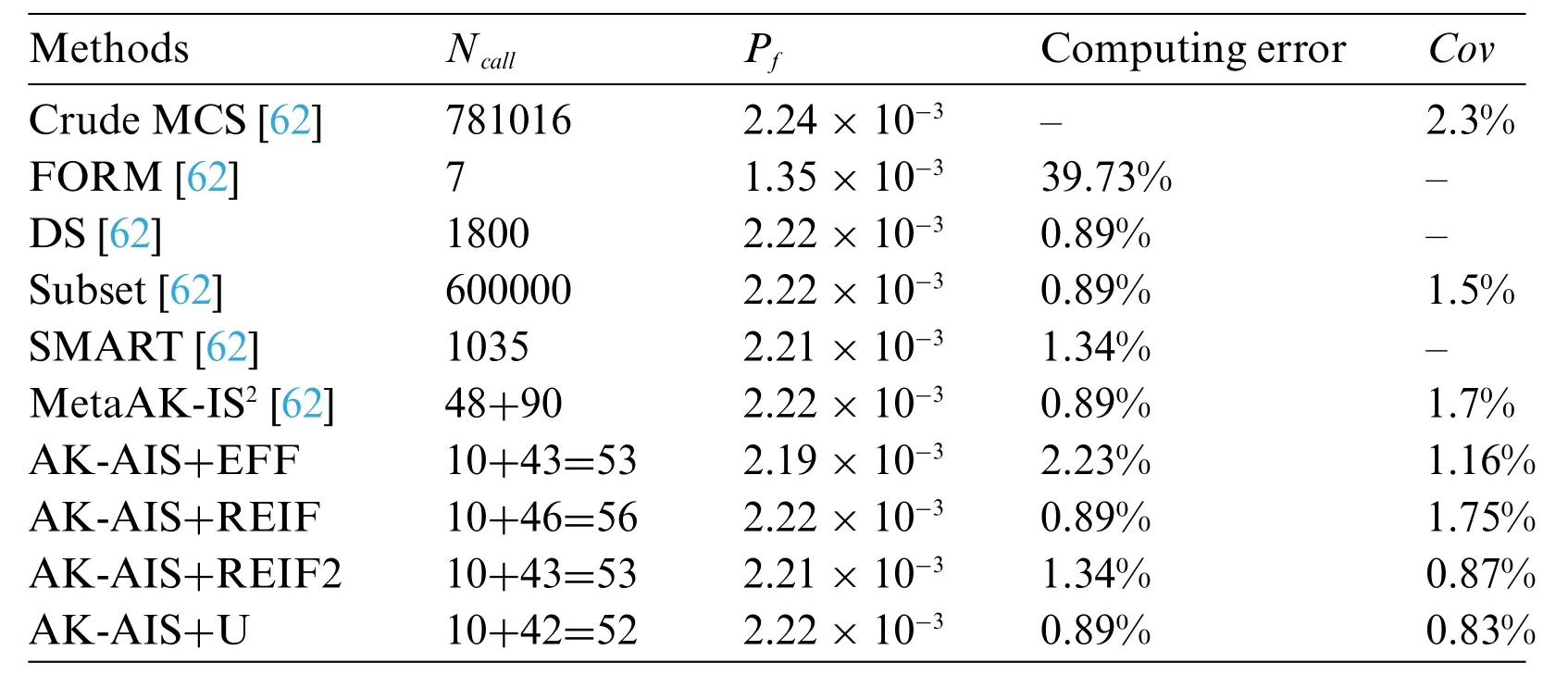
Table 4:The failure probability analysis results for example 2 by different methods
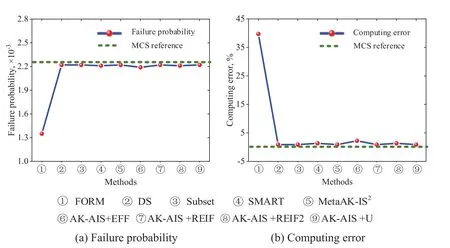
Figure 12:Comparison of the reliability results for example 2
4 Application:Reliability and Sensitivity Analyses of Stator Blade Regulator
Under the multiple uncertain parameters of flexible deformation,joint friction and multi-physics loads,the HCF life of stator blade regulator exhibits large dispersion,which seriously affects the fatigue reliability and security,and prone to HCF failure.A typical stator blade regulator with TC4 titanium alloy is illustrated in Fig.13.To precisely quantify the dispersion of HCF life and evaluate the security performance,fatigue reliability and sensitivity analyses for the above-mentioned stator blade regulator is performed using the proposed AK-AIS method.
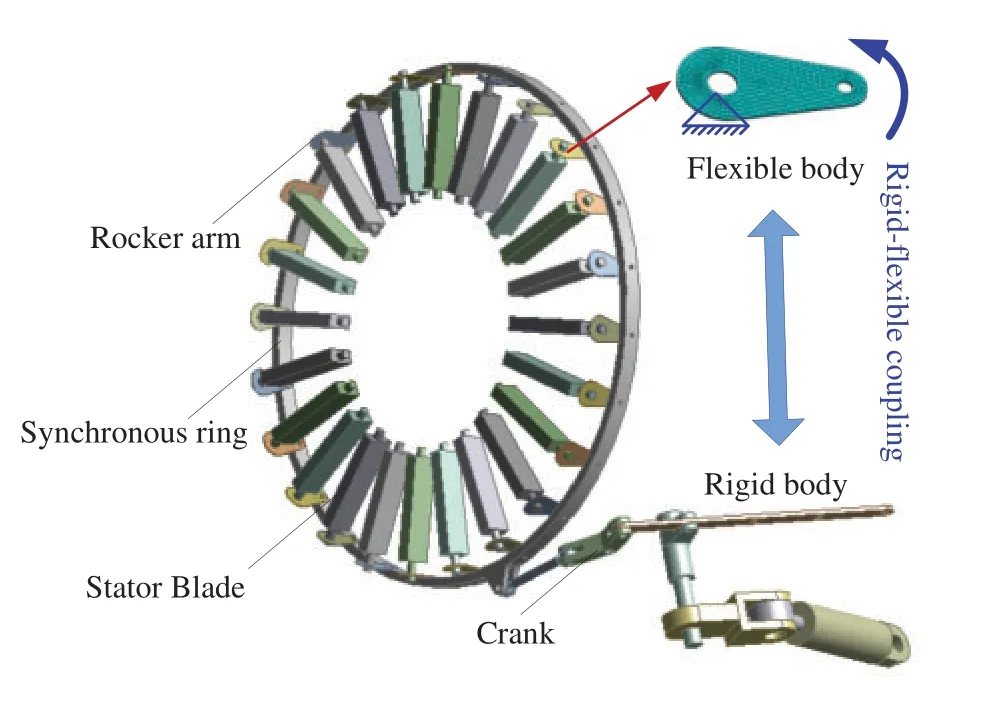
Figure 13:Rigid-flexible coupling schematic diagram of stator blade regulator
4.1 Material Preparations
According to the operating loads,material properties and model parameters pose important influence to the HCF life dispersion of stator blade regulator,the gas temperatureT,thermal conductivityλ,expansion coefficientα,aerodynamic torqueτ,elastic modulusE,material densityρ,Poisson’s ratiou,friction coefficientmu,material constantsγ,β,S0are chosen as the input random variables,their mean values and standard variances areμ=[150°C,8.02 W/(m°C),9.15×10-6°C,840 N·mm,110 GPa,4.44×10-9t/mm-3,0.34,0.2,12.23,-3.53,120]andstd=[3°C,0.148 W/(m°C),0.182×10-6°C,16.8 N·mm,2.2 GPa,0.088×10-9t/mm-3,0.0068,0.004,0.0014,0.0188,28.62][78,79],respectively.Assuming that all the selected physical random variables and model random variables obey mutually independent normal distribution.During the operation of stator blade regulator,two or more rocker arms may simultaneously undergo HCF failure.In this case,to simplify the computational complexity,HCF failure of two rocker arms are considered in this study,the series system with two failure units are given as
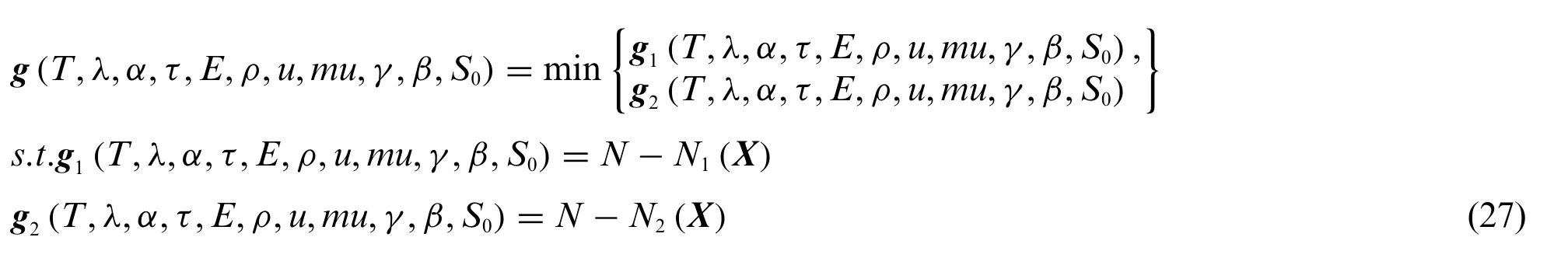
whereX={T,λ,α,τ,E,ρ,u,mu,γ,β,S0};Ndenotes the allowable life;N1(X),N2(X)the fatigue life of two components,which can be obtained by rigid-flexible coupling model of stator blade regulator(i.e.,the real LSF)[2,5].
4.2 AK-AIS Modeling
According to Latin hypercube sampling (LHS) technique and the distributed traits of input variables,65 groups of input variables are extracted,and the corresponding real outputs(fatigue lifeN1andN2) are acquired by calling rigid-flexible coupling model.Based on the 65 groups of input variables and output responses,the initial Kriging model is established.Subsequently,with 48 and 371 times calls the complex rigid-flexible coupling model,the Kriging model is gradually updated,and re-updated to the real LSF.With the obtained Kriging-fitted LSF curves,the nephograms of the relationship between output responses and partial variables are drawn in Fig.14.It can be found that all the nephograms appear high-nonlinearity between responses and partial parameters,which reveals that the reliability and sensitivity analysis of stator blade regulator is a highly nonlinear problem.
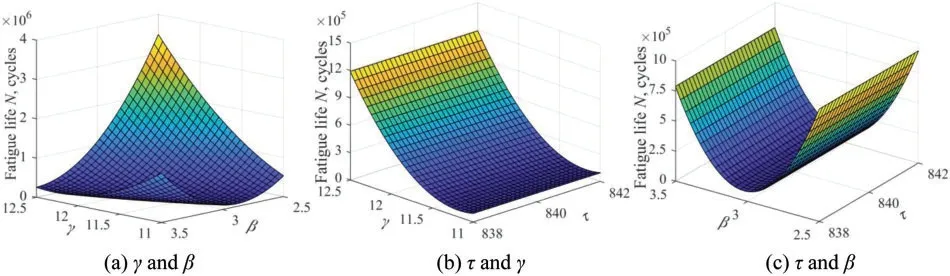
Figure 14:Relationship nephograms of output response with partial variables
4.3 Reliability and Sensitivity Analyses
Based on the LHS technique,10,000 samples are generated and imported into the Kriging-fitted LSF curves instead of the complex rigid-flexible coupling model.Then,the marginal probability distributions of mean stressσmand fatigue lifeNfcan be acquired,as shown in Figs.15 and 16,respectively.The relationships between HCF life and partial uncertainties are quantified utterly in Fig.17.With the obtained Kriging-fitted LSF curves,the sensitivities and effect probability of input variables on fatigue failure are revealed.According to Fig.18 and Table 5,we find that the material constantsγ,β,aerodynamic torqueτand gas temperatureTare the dominant factors affecting the HCF failure of stator blade regulator.
4.4 Methods Comparison
To verify the advantages of the proposed AK-AIS method,we compare the failure probability analysis results with MCS,FORM and AK-MCS.As shown in Table 6,the failure probability obtained by AK-AIS is closer to the MCS reference value than that of FORM and AK-MCS.More importantly,the proposed method only calls 484 times of the real LSF.On the contrary,MCS and AK-MCS methods require 10,000 and 498 calls of the real LSF,respectively.Consequently,the proposed AKAIS method can achieve higher failure probability by fewer calls to the real LSF,which provides a way to address the complex reliability and sensitivity analyses problems with high-nonlinearity,multiple failure regions,and small failure probability.

Table 5:The PRS and GRS results for stator blade regulator

Table 6:The failure probability analysis results by different methods
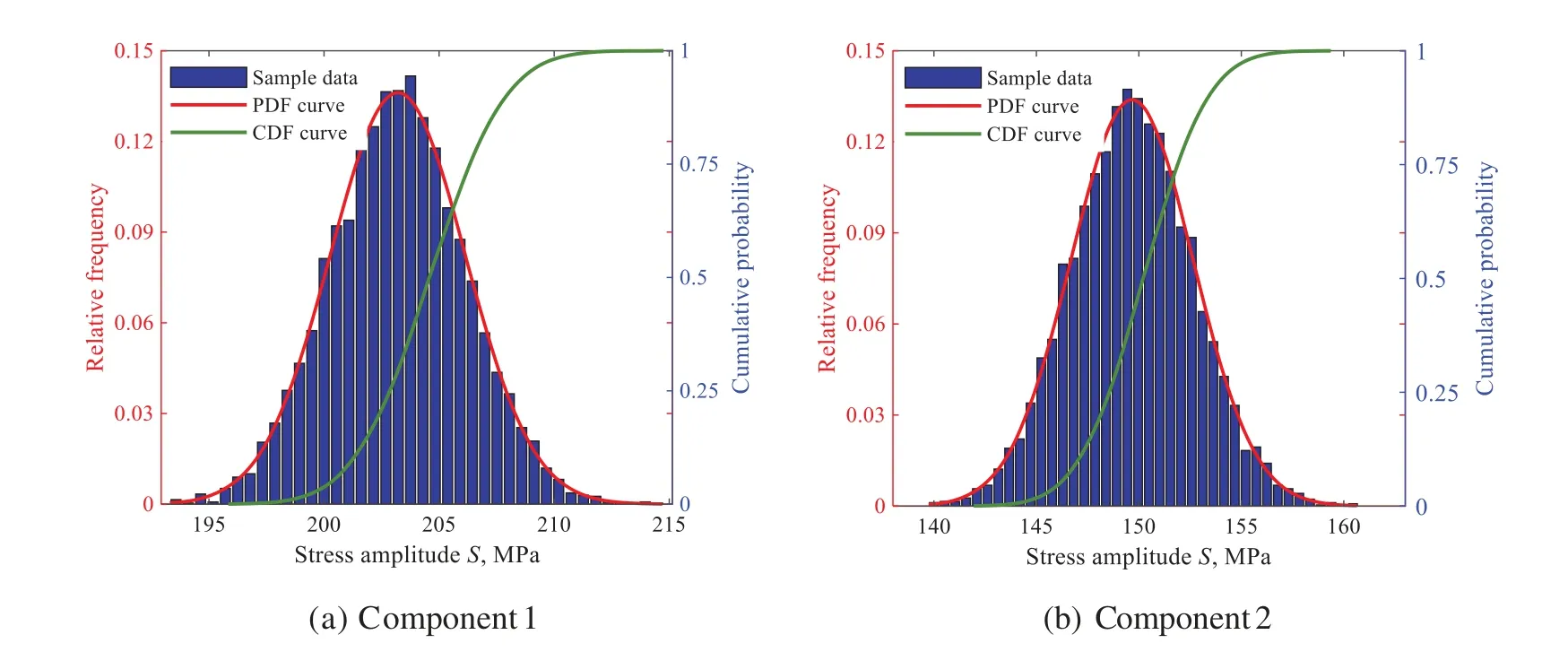
Figure 15:Stress probability distribution of multiple components
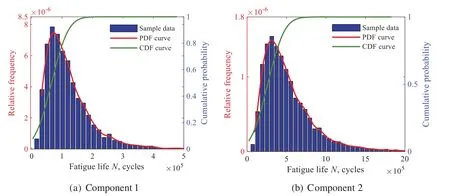
Figure 16:HCF life probability distribution of multiple components
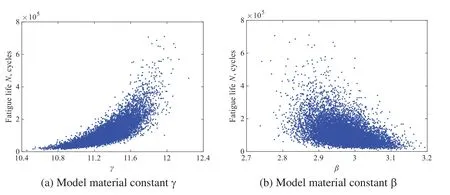
Figure 17:Scatter correlation sketches of HCF life

Figure 18:Sensitivity analysis results of stator blade regulator HCF failure
5 Conclusions
To address the high-nonlinearity,multi-failure regions,and small failure probability problems in reliability and sensitivity analyses of stator blade regulator,by combining the advantages of active Kriging (AK),Markov chain Monte Carlo (MCMC),adaptive kernel density estimation (AKDE)and importance sampling(IS),a novel active Kriging-based adaptive importance sampling(AK-AIS)method is developed.The proposed method is validated by two numerical examples with multiple failure regions and then is applied to a typical reliability and sensitivity analysis of aero-engine stator blade regulator.Some conclusions are summarized as follows:
(1) Numerical examples verify that the proposed AK-AIS method holds high accuracy and efficiency in MPFRs identification and the Markov chain initial state determination.
(2)Application case indicates that the proposed method can efficiently and accurately accomplish the reliability and sensitivity analysis of stator blade regulator.Moreover,it has been found that the material constantγ,β,aerodynamic torqueτand gas temperatureTposes the most impact on the failure probability of stator blade regulator.
(3) The proposed method is suitable for the complex reliability and sensitivity analyses with high-nonlinearity,multiple failure regions,and small failure probability,which provides theoretical guidance for determining the initial state of Markov chain in complex engineering.
Although the study provides a feasible and efficient approach for the reliability and sensitivity analyses of stator blade regulators,limitations do exist.Most deviations from expected solution can be attributed to incomplete factors considered in this study.According to the present study and the questions raised,the following problems require to be addressed for further application of the proposed approach in future.
(1)To improve the computing quality of complex mechanism reliability analysis,more additional factors (design tolerance,performance degradation,vibration mechanics,and so forth) should be analyzed and investigated.
(2)To further improve the computational efficiency of reliability analysis with high-dimensional,small failure probability problem,a more effective method to determine the initial state of Markov chain needs to be further studied.
(3) An advanced kernel function should be adopted in high precision kernel sampling density function,such as Gaussian linear mixture kernel function,ANOVA Kernel,and Sigmoid Kernel.
Funding Statement:This work was supported by the National Natural Science Foundation of China under Grant Nos.52105136,51975028,China Postdoctoral Science Foundation under Grant [No.2021M690290],the National Science and Technology Major Project under Grant No.J2019-IV-0002-0069.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2023年3期
Computer Modeling In Engineering&Sciences2023年3期
- Computer Modeling In Engineering&Sciences的其它文章
- A Consistent Time Level Implementation Preserving Second-Order Time Accuracy via a Framework of Unified Time Integrators in the Discrete Element Approach
- A Thorough Investigation on Image Forgery Detection
- Application of Automated Guided Vehicles in Smart Automated Warehouse Systems:A Survey
- Intelligent Identification over Power Big Data:Opportunities,Solutions,and Challenges
- Broad Learning System for Tackling Emerging Challenges in Face Recognition
- Overview of 3D Human Pose Estimation