
融合法律文本结构信息的刑事案件判决预测
2023-02-14 10:32郑伟昊窦志成文继荣
计算机工程与应用 2023年3期
张 晗,郑伟昊,窦志成,文继荣
1.中国人民大学 信息学院,北京 100872
2.大数据管理与分析方法研究北京市重点实验室,北京 100872
3.中国人民大学 高瓴人工智能学院,北京 100872
4.数据工程与知识工程教育部重点实验室,北京 100872
近年来,以机器学习和深度学习为代表的人工智能技术发展迅速,研究人员以及工业界将人工智能技术应用到各种不同的领域和实际场景,例如医疗领域的肿瘤影像诊断、金融领域的股票预测和城市规划领域的城市计算等。人工智能技术促进了各种研究和工业领域的智能化的发展。人工智能在各个领域交叉融合发展的趋势促使利用人工智能等技术构建法律智能以解决法律任务得到学界的逐渐认同。深度学习和自然语言处理等人工智能技术在信息检索、文本分类等研究领域取得了显著成果,一些研究工作进而将这些技术应用到法律领域,法律任务智能化引起了学界甚至工业界的广泛关注。司法领域全国法律裁判文书网提供了大量真实且格式规范的司法案例和数据,进一步促进了法律任务智能化的研究和应用。
目前法律任务智能化已经应用于各种场景中,例如司法案件检索、法律法条的检索、案情法律依据推荐、司法问答、自动定罪、自动量刑、裁判文书自动生成等[1]。法律领域的诸多任务主要是基于文本进行分析和研究,并且需要进行语义层面的分析,主要涉及自然语言处理(NLP)技术,例如自动定罪涉及文本分类、文本语义分析等技术。当前深度学习为代表的NLP技术在诸多需要语义分析的任务中取得显著成果,例如阅读理解、问答等,也促进了法律任务智能化的研究。
法律任务智能化不仅可以提升司法人员办案的效率,例如卷宗检索和类案推荐等技术可以帮助司法人员快速找到相关案件和法律法条从而提升司法人员工作效率;它也可以一定程度上提升司法公正性,例如基于深度学习定罪等技术通常是基于大量历史案件的信息学习定罪的特征以预测罪名,一定程度上可以降低司法人员出现人为错误的可能性。
法律任务智能化中一个重要任务是法律判决预测。在法律领域中,通常包含定罪和量刑两个主要的任务。定罪是司法机关为惩罚犯罪、保障人权,依据法律规定,根据证据认定行为事实并进而认定犯罪嫌疑人和被告人的行为罪与非罪、此罪与彼罪、重罪与轻罪及罪数的活动[2-3],例如盗窃罪与故意杀人罪的确定。量刑是指司法机关在定罪的基础上,考虑刑事责任的轻重,依据法律规定对犯罪人是否判处刑罚或者适用某种非刑罚处理方式,判处何种刑罚和刑期以及是否执行某种刑罚的审判活动[2,4]。例如,犯罪嫌疑人的年龄是量刑时的参考情节之一,同一种罪行且其他犯罪方式一致时,未成年人的刑罚会比成年人轻,低于14岁的未成年人会更轻。
计算机领域中法律判决预测任务通常包括法条推荐、定罪预测和刑期预测。该任务是在给定一个案件的案情描述时,自动预测犯罪嫌疑人涉及的相关法条和罪名以及判处的刑期。相关法条是与犯罪嫌疑人的案情事实相关的刑法等法律条文,罪名是法律条文中明确规定的罪名,刑期预测通常是对犯罪人的主刑的裁量。主刑也称为基本刑,是我国法律对犯罪人主要的处罚方式,一般包括管制、拘役、有期徒刑、无期徒刑和死刑。例如,图1中林某滥用职权案中,给定经司法机关侦查确认的案情描述,模型应自动推荐的相关法条为刑法第三百九十七条,此外模型应自动预测出犯罪嫌疑人林某的罪名为滥用职权罪,林某的刑期为有期徒刑2年(24个月)。

图1 司法领域的判决示例Fig.1 Example of judgement of criminal case in judicial field
早期法律判决预测相关研究工作采用统计和概率的方法(Keown等人[5]、Nagel等人[6]、Segal等人[7]、Lauderdale等人[8]以及Ulmer等人[9])会损失案情描述信息和刑期预测情节等信息。基于人工构建特征的机器学习研究工作如林琬真等人[10]和高菲等人[11]提升了自动判决相关任务的准确率,但是存在损失案情描述语义信息等问题。针对早期工作的问题,一些研究者提出了一些基于深度学习的法律判决预测方法,如Luo等人[12]、Hu等人[13]、Zhong等人[14]、Xu等人[15]的工作。这些工作多是基于卷积神经网络(CNN)或者双向循环神经网络(LSTM)等神经网络模型对案情描述进行编码,利用注意力机制将法条信息融入案情表示,或考虑三个子任务之间的关系或法条之间的差异来提升法律判决预测任务的性能。虽然这些基于深度学习的研究工作在法律判决预测任务上取得了很好的效果,但是这些工作未考虑利用法律文本本身的多层层次化信息。
如图2所示,刑法法律文本包含多层结构。以刑法第三百九十七条为例,在法条大类的层次上该法条属于渎职罪,在罪名的层次上该法条包含两个罪名:滥用职权罪和玩忽职守罪,在刑期的层次上滥用职权罪和玩忽职守罪的刑罚标准都有三年以下有期徒刑或者拘役和三年以上七年以下有期徒刑等。
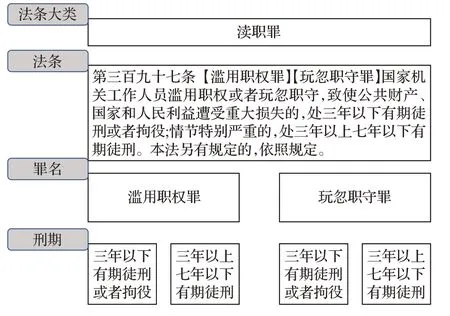
图2 法条的层次化信息示例Fig.2 Hierarchical information of law
针对该问题,本文引入了法律文本的多层层次化信息用于法律判决预测任务。具体来说,本文首先对法律文本的多层层次化信息进行预处理,生成法条、罪名和刑期三个层次,并利用协同注意力机制将三个层次的信息融入案情描述中,分别得到每个子任务融合不同层次的法律文本信息的案情描述表示,并按照子任务之间的顺序来预测司法判决结果。
本文主要的贡献如下:(1)考虑到法律文本具有多层结构信息,针对不同的子任务引入不同层次的法律文本信息并提出一种融合案情描述与法律文本多层结构信息的的神经网络模型;(2)在真实数据集上进行大量实验并与现有最好的深度神经网络模型进行比较和分析,实验结果表明本文提出的模型优于当前最好的法律判决预测模型,这证明了本文提出的模型的有效性。
1 相关工作
法律任务智能化目前相关的研究方向有许多,如智能法律问答、摘要生成、法律阅读理解以及法律判决预测等研究方向。传统人工的法律问答一般需要专业的律师针对提出的问题查询相关法律法规并结合专业知识进行分析和解释,通常费用较高且专业律师资源有限使得民众的需求无法满足,因而Fawei等人[16]提出了一个智能化的法律问答系统,利用问题中相关的案件信息和法律法规并结合法律推理进行分析和回答。Long等人[17]根据问题中的案件信息、法律法规及问题请求等信息通过阅读理解模型来实现法律问题的判定和回答。Xiao等人[18]提出利用CNN模型对中文的法律问题进行分类以帮助普通民众获取法律知识。
司法人员在现实的业务场景中需要对各类案件信息进行快速和认真的阅读并获取案件信息的关键内容形成文本摘要,面对司法人员的现实需求,法律领域的自动摘要生成也受到研究者的关注。Merchant等人[19]采用潜在语义分析的方法对长篇的法律文书进行关键信息的抽取以生成摘要,Kanapala等人[20]对摘要生成相关的研究进行总结和分析。
法律判决是司法中非常重要和严谨的工作,对于刑事案件更是如此。刑事案件的判决结果通常涉及犯罪嫌疑的重大的人身权利,现实的司法工作中通常都是司法机关根据法律依据经过多人多轮认真讨论的结果,判决结果都具有司法上可解释性且有理有据。因而法律任务智能化的司法可解释性的研究也得到研究者的关注,Jiang等人[21]研究自动定罪任务的可解释性问题,基于强化学习和文本分类模型抽取判决结果依据。Ye等人[22]提出序列生成模型从案情描述中生成法庭的判决依据。Liu等人[23]引用注意使用序列到序列的(Seq2Seq)模型来预测决策的原因。
法律任务智能化中一个研究者重点关注的任务是法律判决预测。法律判决预测通常是根据法律裁判文书及相关法律文本自动预测犯罪嫌疑人的涉及的法条、罪名、判处的刑期和罚金等判决结果。我国的法律案件通常可以划分为刑事案件、民事案件和行政案件。刑事案件主要依据刑法对犯罪嫌疑人进行判决,判决结果按照法律责任又可分为主刑和附加刑。当前法律判决预测任务研究的案件主要是刑事案件,主要对刑事案件中的主刑进行预测。例如Sulea等人[24-25]、林琬真等人[10]、Luo等人[12]、Hu等人[13]、Zhong等人[14]和Xu等人[15]都是基于刑事案件进行研究。
一些早期的工作通常是利用一些机器学习的方法对案件进行分类,例如Sulea等人[24-25]、林琬真等人[10]。后续深度学习模型在各个领域的应用,一些研究工作开始关注司法领域的判决任务。例如,Wang等人[26]提出了一种案情描述和法条的层次化文本匹配模型来预测犯罪嫌疑人的罪名。Chen等人[27]采用门控机制来提高刑期预测的性能。Luo等人[12]利用案情事实与法律条文之间的注意机制来帮助预测罪名。此外一些工作对样本较少的罪名进行了研究,如Hu等人[13]通过引入罪名的人工属性特征来提高少样本类别的定罪预测准确率。
随着大规模数据集出现以及任务标准化的定义出现[28],法律判决预测任务(LJP)被定义为由法条推荐、罪名预测和刑期预测三个子任务来组成。一些研究者提出了一些解决法律判决预测的新方法。Zhong等人[14]提出了一个拓扑图来利用不同LJP任务之间的关系来提升每个子任务的性能。Yang等人[29]在LJP任务中引入了多视角前向预测和后向验证来提升子任务的性能。Xu等人[15]通过将所有相关法条信息引入LJP任务中,构建法条之间的关系图来区分易混淆案件以提高LJP任务的性能。
2 问题定义
本章将详细介绍本文中所研究问题的定义以及相关符号和术语。
首先需要明确本文涉及的法律判决预测任务的范围。我国的司法案件主要分为刑事案件、民事案件和行政案件,本文选取刑事案件作为研究重点。刑事案件根据涉案人数和罪名数可分为单人单罪、单人多罪和多人多罪等,本文主要选取单人单罪的刑事案件作为研究重点。本文中法律判决预测任务涉及裁判文书中的案情描述,刑法中相关的法律文本,裁判文书中的判决口结果中的罪名和刑期。具体的说明如下:
法律文本:我国的司法判决都是根据现行法律文本的规定以及案件的事实描述来确定犯罪嫌疑人所触犯的法条、罪名和相应的刑期从而确定判决结果的。本文将数据集相关的刑法法条表示为L={a1,a2,…,aan},其中an为法律条文数。
裁判文书:本文中使用的数据集主要是来自于裁判文书。裁判文书主要由案情描述、法庭判决缘由和判决结果构成,案情描述是描述犯罪嫌疑人个人基本信息、犯罪行为、时间、地点和累犯次数等信息。由于案情描述包含的信息较多,文本的长度通常较长,因此本文将案情描述的文本表示为句子的序列Fact={s1,s2,…,sn},其中si是一个由单词组成的句子序列,n是案情所包含的句子总数。判决结果包含相关法条、罪名和刑期等,分别表示ya、yc、yp。
如图3所示,本文中的法律判决预测任务是基于多任务的框架,法律文本信息和案情描述经过预处理及词向量编码表示送入模型进行交互。最终法律文本和案情描述经过模型编码得到每个子任务的特征表示,从而用于预测每个子任务的标签。
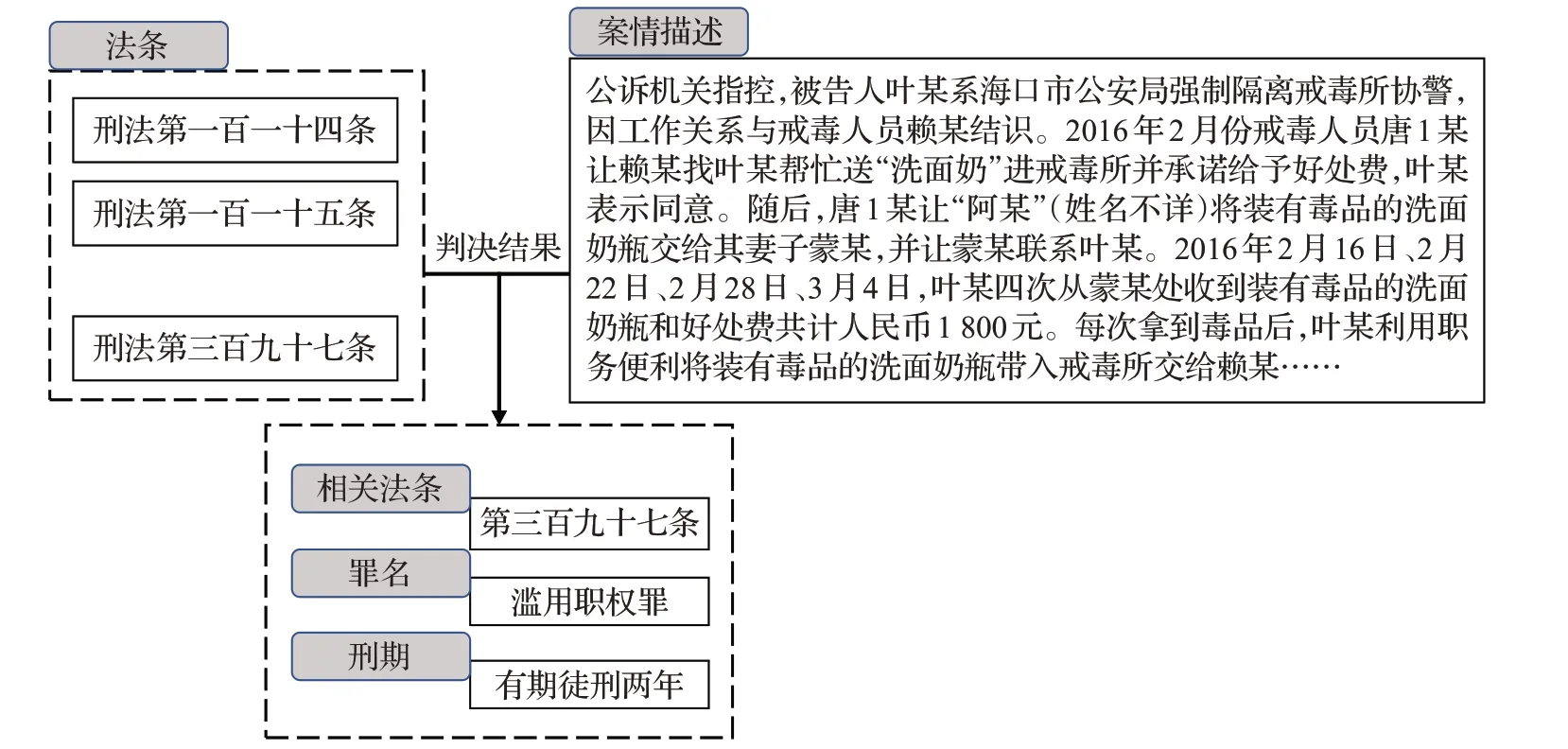
图3 法律判决预测任务定义Fig.3 Definition of legal judgment prediction task
推荐相关法条任务是根据案情描述Fact以及刑法的法律条文L来自动预测犯罪嫌疑人所触犯的法律条文ya。本文主要研究单人单罪的案件,即只有一个犯罪嫌疑人且只触犯一个法条的案件。因此推荐法条的子任务是一个单标签多分类任务。该任务可定义为Ta:fa(Fact,L)~ya。
定罪任务是根据案情描述Fact以及刑法的法律条文L来自动预测犯罪嫌疑人所触犯的法律条文中的罪行。与推荐相关法条的任务类似,本文主要研究单人单罪的案件,即只有一个犯罪嫌疑人且只触犯相应法条的一个罪名的案件。因此定罪的子任务也是一个单标签多分类任务。该任务可定义为Tc:fc(Fact,L)~yc。
刑期预测任务是Fact以及刑法的法律条文L来自动预测犯罪嫌疑人的刑期。刑法中的刑罚包含管制、拘役、有期徒刑、无期徒刑、死刑。本文中主要涉及有期徒刑、无期徒刑、死刑。其中有期徒刑在刑法中区间通常是一年、二年、三年、五年、七年、十年、十五年。本文按照数据集中刑罚的统一处理,分为“死刑或无期”“十年以上”“七到十年”“五到七年”“三到五年”“二到三年”“一到二年”“九到十二个月”“六到九个月”“零到六个月”“无刑期”。因此刑期预测任务同样被定义是一个多分类任务,该任务可定义为Tp:fp(Fact,L)~yp。
3 模型
本章将具体介绍本文提出的融合法律文本多层层次化信息的LJP模型。
3.1 模型整体框架
如图4所示,模型主要由案情描述编码模块、法律文本多层层次化(Article、Charge、Prison)编码模块、案情描述和法律文本层次化信息的交互模块、三个子任务特征交互模块,以及模型预测模块组成。下文将具体介绍每个模块的功能。
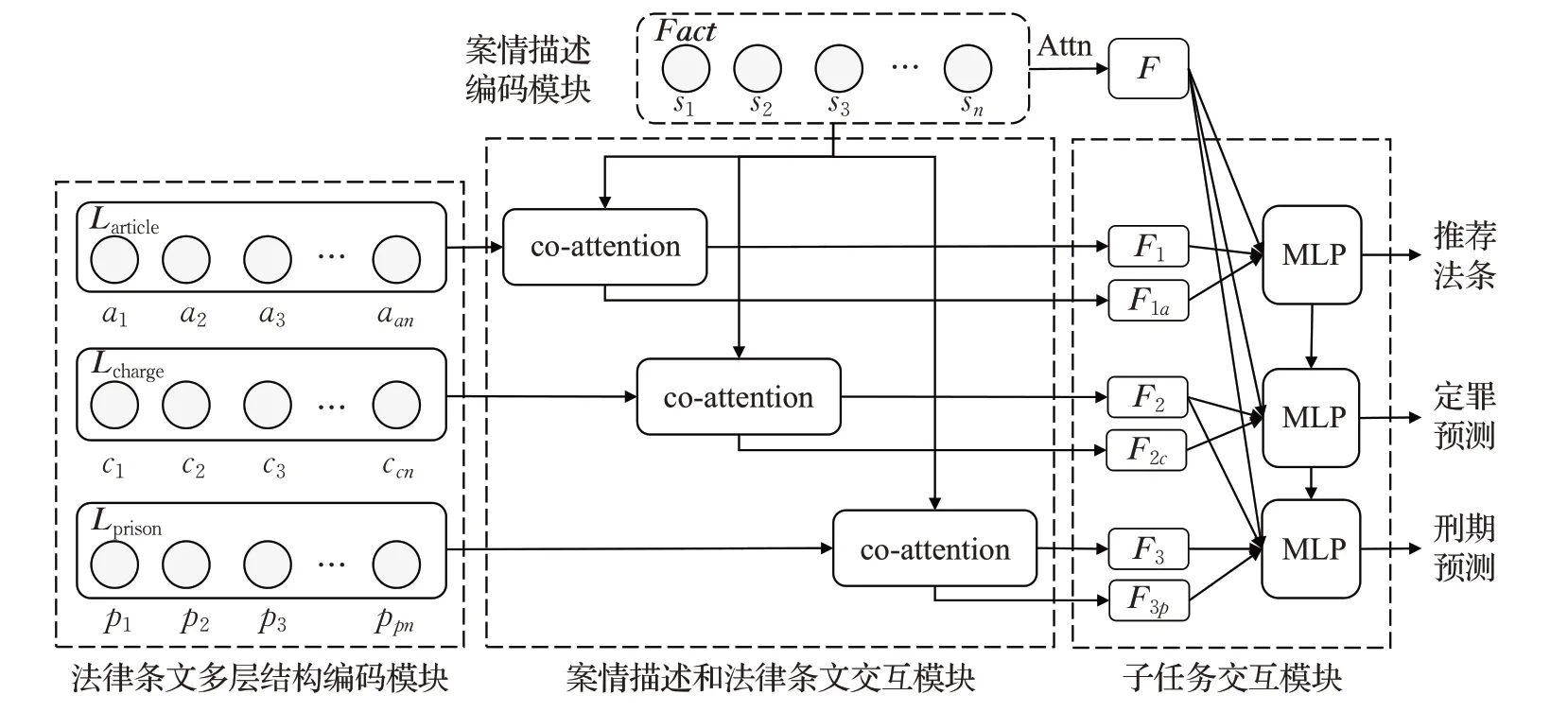
图4 模型整体框架图Fig.4 Overall framework of model
案情描述编码模块。从图3可以看出由于案情描述的文本通常较长且涉及犯罪嫌疑人的个人信息以及犯罪嫌疑人所犯事实的起因经过等信息,其中决定犯罪嫌疑人所犯罪行的信息相对较为分散,因此本文采用句向量表示案情描述的文本。案情描述模块将输入案件的案情描述分为n个句子,每个句子经过词向量编码后表示为si,因此整个案件的案情描述可以表示为n个句子的向量序列Fact={s1,s2,…,sn}。之后案情描述的句向量表示Fact送入案情描述和法律文本层次化信息的交互模块。案情描述再经过注意力机制(Attn)处理得到输出向量F作为子任务的特征。模块的具体实现细节将在3.2中介绍。
法律文本多层层次化编码模块。由于法律条文是具有多层结构信息的,为了将法律条文的多层结构信息用于法律判决预测的三个子任务,本文将法律文本划分为三个层级:法条、罪名、刑期(情节轻重程度等量刑情节)。与案情描述编码模块类似,将预处理的法律文本信息采用句向量的编码模式处理,然后依次得到法律文本中涉及刑期、罪名和法条向量表示Larticle、Lcharge、Lprison作为模块的输出。该模块的输出送入到案情描述和法律文本多层层次化信息的交互模块。具体的实现细节在3.3节中介绍。
案情描述和法律文本多层层次化信息的交互模块。该模块将法律文本多层层次化编码模块得到的法条表示Larticle、Lcharge、Lprison和案情的表示Fact通过协同注意力机制得到三个融合法条信息的表示F1、F2、F3以及法律文本融合案情的表示F1a、F2c、F3p。这些特征作模型预测模块的输入,具体实现细节在3.4节中介绍。
三个子任务特征交互模块。推荐法条子任务将案情描述模块的输出F,案情描述和法律文本的交互得到的融合法条信息的案情表示向量F1、法条对案情信息的注意力权重向量F1a作为该任务的输入。最后将这些特征级连为Farticle并采用多层感知机(MLP)来预测相关法条。
定罪子任务将案情描述F,融合罪名信息的案情表示向量F2、罪名对案情的注意力权重向量F2c以及推荐法条子任务的特征Farticle作为总的特征,并将这些特征级连后通过MLP层来预测罪名。
刑期预测子任务将案情描述F,案情融合罪名信息的表示向量F3、案情对罪名的注意力权重向量F2c以及罪名预测子任务的特征Fcharge作为总的特征,并将这些特征级连后通过MLP层来预测刑期。具体实现细节在3.5节中介绍。
3.2 案情描述编码模块
在司法领域中案情描述文本通常较长,本文将案情描述文本划分为多个句子,首先通过CNN模型得到句子的表示从而得到整个案情描述的表示。具体来说,如图5所示本文首先将案情描述文本预处理为n个句子,每个句子最多包含sl个词,每个句子中的词使用词向量wi进行表示。然后本文将每个句子送入4个不同的CNN子模块,这4个CNN采用不同的卷积窗口用于获取不同粒度的特征。每个CNN子模块经过卷积层和池化层得到的特征向量拼接作为最终一个句子的向量表示si。案情描述的表示由每个句子的向量表示构成,即Fact={s1,s2,…,sn}。
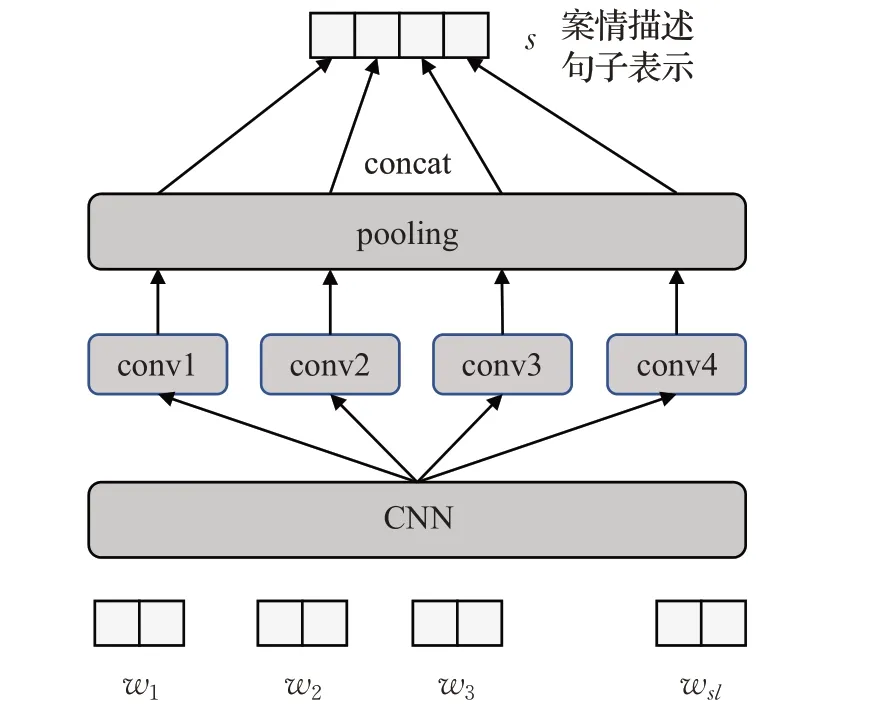
图5 案情描述中句子的编码表示Fig.5 Representation of sentence in case description
3.3 法律文本信息的层次化预处理
法律文本的多层结构如图6所示,刑法中同一个法条大类通常包含多个不同的法条,一个法条通常包含一个或者多个罪名的相应描述,同一个罪名通常对不同程度的量刑情节规定了相应的刑期。本文认为这种层次化的信息对于法律判决预测任务是有用的。如图6所示,刑法第三百九十七条的法条大类是渎职罪,该法条对滥用职权罪和玩忽职守罪作出了明确的规定,其中滥用职权罪又按照情节的严重程度规定了不同刑期的刑罚。
由于刑法涉及的法条相对不多,本文对每个法条按照法条-罪名-刑期的三层结构人工划分为三个层次。本文将法条大类信息作为法条层的法律要素,法条规定的罪名描述文本作为罪名层的法律要素,刑期及量刑情节等文本信息作为刑期层的法律要素。
与案情描述的处理类似,本文采用3.2节的句向量编码模块依次对法条、罪名和刑期层构建法律文本向量表示。具体来说,本文首先将一个刑期层的所有法律要素(如情节严重、三年以下等文本信息)经句向量编码表示为hi,然后通过注意力机制融合刑期的中不同的法律要素表示构成该刑期的总的向量表示。罪名层同刑期层的处理方式类似,此外本文将刑期层的表示作为罪名层的法律要素,法条层的处理同理,如图6。统一的处理公式如下:
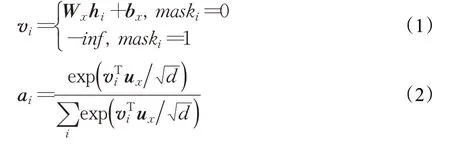
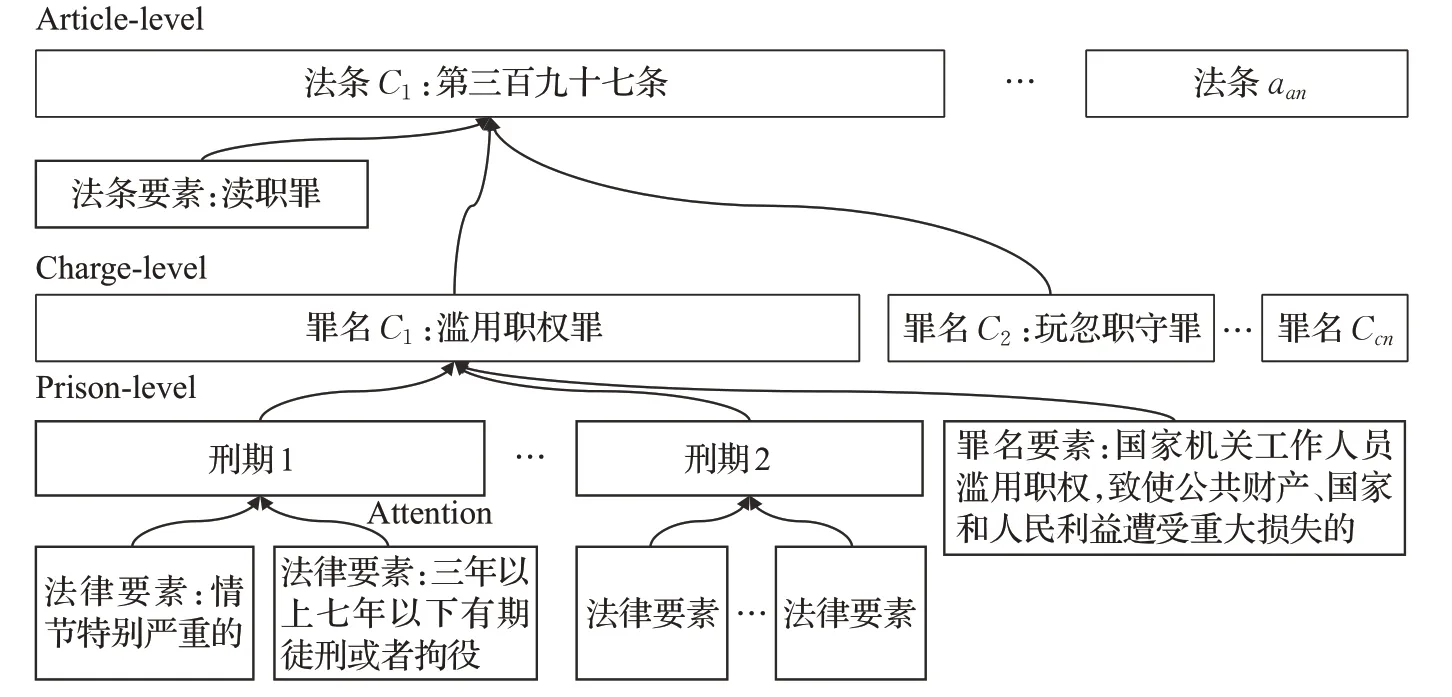
图6 法律文本层次化的表示Fig.6 Hierarchical representation of legal text

其中Wx、bx、ux为参数矩阵,hi为输入的法律要素通过CNN得到的句向量表示,maski表示相应的法律要素是否参与计算,d为输入序列的词向量维度,sf为对所有法律要素hi的注意力总的向量表示,对应一个刑期的表示或者一个罪名的向量表示。
3.4 法律文本层次化信息和案情描述的语义交互
本文通过协同注意力机制将法律文本的层次化信息与案情描述进行细粒度的交互。本节首先介绍协同注意力机制的原理。如图7所示,输入向量A=(a1,a2,…,ai,…,am),B=(b1,b2,…,bj,…,bn),其 中A∈Rm×d,B∈Rn×d,ai和bj的维度是相同的。为了计算A中每个向量ai和B中每个向量对bj的匹配得分,将向量B和AT点乘得到一个二维矩阵M。在此基础上分别通过按行和按列做Softmax得到bj对每个ai的注意权重矩阵ri和ai对每个bj的注意力权重矩阵cj。然后对ri注意力矩阵作row-wise平均得到最终的avg权重,再将avg权重与矩阵C相乘得到B矩阵的注意力向量。具体公式如下:
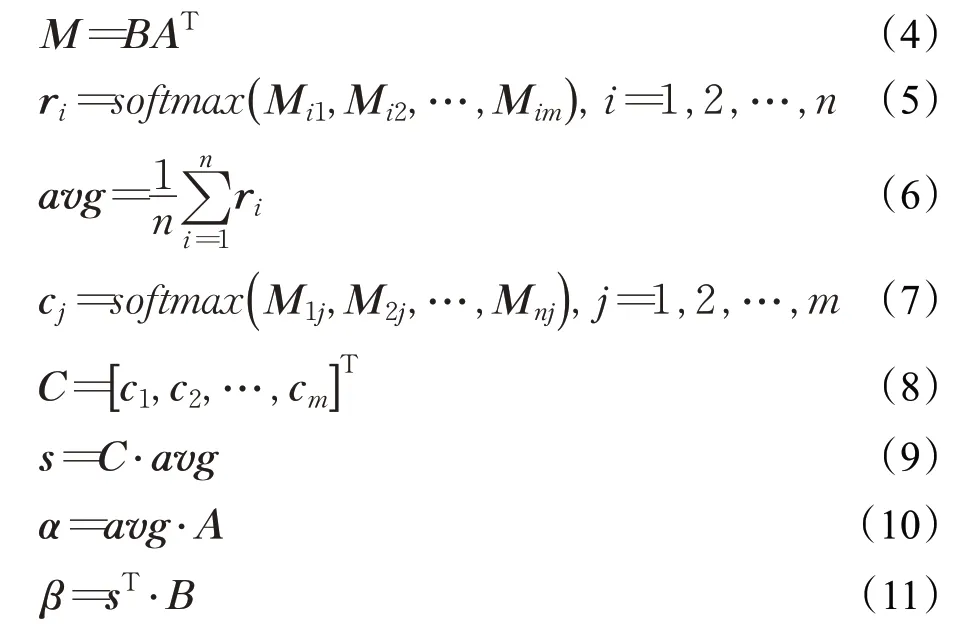

图7 协同注意力机制原理图Fig.7 Co-attention mechanism
本文通过构建不同层次的法律文本信息与案情描述的交互,得到三个子任务相应的融合法律文本信息的案情描述表示F1、F2、F3。此外本文也分别得到法条、罪名和刑期对案情的注意力权重向量F1a、F2c、F3p作为三个子任务特征的一部分。
3.5 法律判决预测子任务
法律判决预测的三个子任务推荐法条、定罪和刑期预测在司法中有依次的顺序关系,即确定相关法条才能确定相应的罪名,确定相应的罪名才能按照法律文本规定确定相应的刑期。因此本文将推荐法条作为定罪和刑期预测的上游任务,定罪任务作为刑期预测的上游任务。本文将上游任务的特征向量送入下游任务中从而实现子任务的顺序关系,如图4所示。
首先本文对案情描述进行句向量表示从而得到案情描述的整体表示F,作为所有子任务案情描述表示的基础特征。
推荐法条子任务。本文通过协同注意力机制得到的融合法条信息的案情描述表示F1以及法条对案情的注意力权重向量F1a。本文将Fa=concat[F;F1;F1a]作为该任务的总的特征并采用MLP来预测相关法条,公式如下:
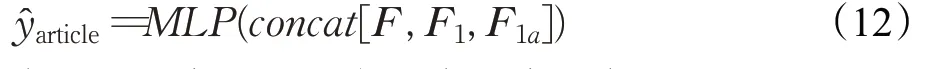
定罪子任务。与推荐法条任务类似,本文通过协同注意力机制得到的融合罪名信息的案情描述表示F2、罪名对案情描述的注意力权重向量F2c。本文将Fc=concat[F,F1,F2,F2c,Fam]作为该任务的总的特征,并采用MLP来预测罪名ŷcharge。Fam是推荐法条任务中Fa过全连接层后的特征。公式如下:

刑期预测子任务。与定罪子任务类似,本文将上游子任务得到的融合刑期信息的案情描述表示F3作为该刑期预测任务的刑期相关的特征,并将Fp=concat[F,F1,F2,F3,Fcm]作为该任务的总的特征,并采用MLP来预测刑期。Fcm是定罪任务中Fc通过全连阶层后的特征。公式如下:
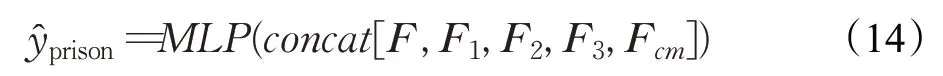
3.6 损失函数
本文中法律判决预测的三个子任务推荐法条、定罪和刑期预测都建模为多分类任务,因此本文采用交叉熵损失函数作为每个子任务的损失函数。具体公式如下:

最终法律判决预测任务总的损失函数如下:
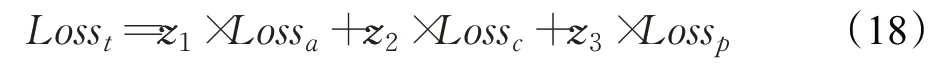
其中z1、z2、z3分别是三个子任务损失函数的权重。
4 实验和分析
将详细介绍本文的实验设置、基线模型,然后在真实的数据集上进行了大量实验并对实验结果进行比较分析,从而验证本文提出的融合法律文本多层层次化信息的法律判决预测模型的有效性。
4.1 数据集和预处理
本文中实验使用的数据集是中国人工智能与法律挑战(CAIL2018[28])的公开数据集。该数据集分为CAIL-smal(l练习阶段数据集)和CAIL-big(第一阶段数据集),如表1所示。数据集中每个案例包含事实描述、适用的相关法条、罪名和刑期等信息。为了与基线模型对比,本文过滤了具有多个相关法条和多个罪名的案例,即多人多罪的案件,只保留单一法条和单一罪行的案例。此外,参照Zhong等人[14],本文只保留了不少于100个案例样本的相关法条和罪名的类别,并过滤掉相关法条和罪名不一致的案例,并将刑期限划分为不重叠的时间间隔。

表1 数据集的统计信息。Table 1 Statistics of datasets
词的向量表示在自然语言处理的任务起着十分重要的作用,常用的词向量表示有词袋模型和词的分布式向量表示模型。词袋模型是对每个词进行独热编码,向量的维度是整个词典的词个数。词袋模型具有向量维度高和缺乏语义关系描述的问题,因而本文采用词的分布式向量表示。分布式向量表示的如法律领域中,与盗窃有关的词有“偷盗”“盗取”“偷窃”等,在分布式表示中这些词向量之间的距离更近,有效地表示词语义之间的相似性。本文基于深度学习的模型采用分布式词向量表示,选取经典的Word2vec词向量模型进行训练以得到词向量表示。Word2vec一般有两种算法用于训练词向量,分别为连续词袋模型(CBOW)算法和跳字模型(Skip-gram)算法,本文采用Skip-gram算法用于训练词向量,其中词向量的维度设置为200。数据预处理是基于文本的深度学习方法中的一个重要模块。本文对数据集中案例的案情描述及法条信息的预处理主要包括分词和去停词。本文THULAC[30]工具对法律文本和案情描述等文本进行分词并去除句子中标点符号、“的”等停词,使深度学习模型关注语义信息较高的重要词汇,过滤次数较少的词条,以及案件对案情描述无有用信息的“足以认定”之后的文本。
4.2 评价指标
本文中法律判决预测的三个子任务(推荐法条、定罪和刑期预测)都建模为多分类任务,因此本文采用多分类任务常用的评价指标准确率(accuracy)、宏精确率(macro-precision)、宏召回率(macro-recall)和宏F1值(macro-F1)对三个子任务结果进行评价。评价指标的计算公式如下:

其中TPi、FPi、FNi、Pi、Ri、F1i分别为第i个类别所对应的真阳性样本数、假阳性样本数、假阴性样本数、精确率、召回率和F1值。
4.3 基线模型和实验设置
为了验证本文提出的融合法律文本多层层次化信息的法律判决预测模型的有效性,本文对比了目前在法律判决预测任务上效果最好的模型。基线模型设置如下所示。
CNN[31]:基于CNN的模型,具有多个过滤窗口宽度用于文本分类,在法律判决预测任务中采用多任务的训练方式来训练模型。
HARNN[32]:该模型是一种基于RNN的神经网络,具有分层注意机制,用于文档分类。与CNN模型类似,HARNN也中采用多任务的训练方式来训练模型。
FLA[12]:该模型使用注意机制捕获案情的事实描述与数据集所涉及的法条之间权重信息用于定罪预测。
Few-Shot[13]:该模型提出一种区分混淆罪名的深度学习方法,首先根据法律知识人工构建10个用于区分罪名的属性特征,并用注意力机制通过案情描述预测这10个属性特征从而增强模型的表示能力。
TOPJUDGE[14]:该方法利用法律判决预测LJP的拓扑结构并基于多任务学习框架,将子任务之间的依赖关系转化为有向无环图来提升三个子任务的性能。
MPBFN-WCA[29]:该方法也是基于法律判决预测的多任务学习框架,采用多角度前向预测和后向验证来提升三个子任务的性能。
LADAN[15]:该方法通过构建法条之间的图蒸馏模型来获取区分相近法条的特征从而提升法律判决预测的性能,这是目前最好的模型。
HLJP:本文中提出的融合法条多层层次化信息的法律判决预测模型,本文模型的具体参数设置如下:本文中预训练的词向量维度为200,案情描述的句子最长含有100个词,每个案情描述最多有16个句子。模型训练的批处理样本数为128,模型中CNN的卷积的窗口长度为2到5,CNN模型的特征长度为256。本文训练模型使用AdamW优化器,学习率设置为1E-3,权重衰减设置为1E-3。
4.4 实验结果和实验分析
为了比较本文提出的融合法律多层层次化信息的模型HJLP和基线模型,本文在CAIL-small和CAIL-big进行了大量的实验,实验结果如表2和表3所示。在实验设计时,由于FLA、CNN、HARNN和Few-Shot等模型原有的论文不是在法律判决预测任务实现的,因此本文在原有模型基础上增加了相应的子任务分别表示为:FLA+MTL(MTL表示三个法律判决子任务)、CNN+MTL、HARNN+MTL和Few-Shot+MTL。
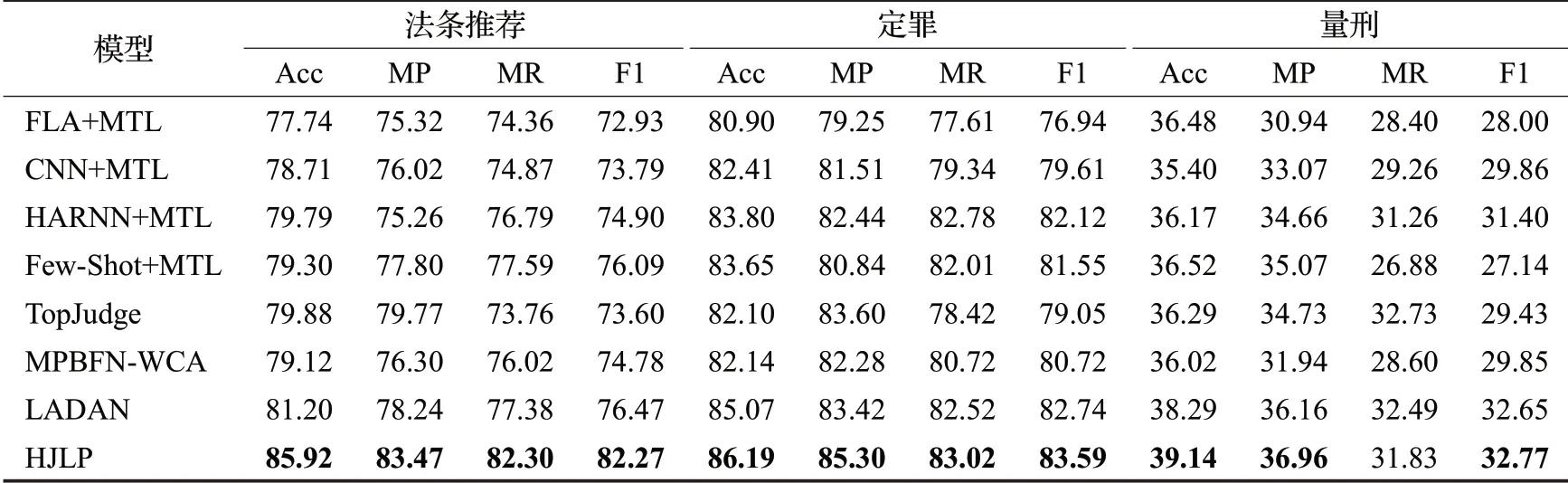
表2 模型在CAIL-small数据集上的法律判决预测任务结果Table 2 Results of model on CAIL-small dataset 单位:%
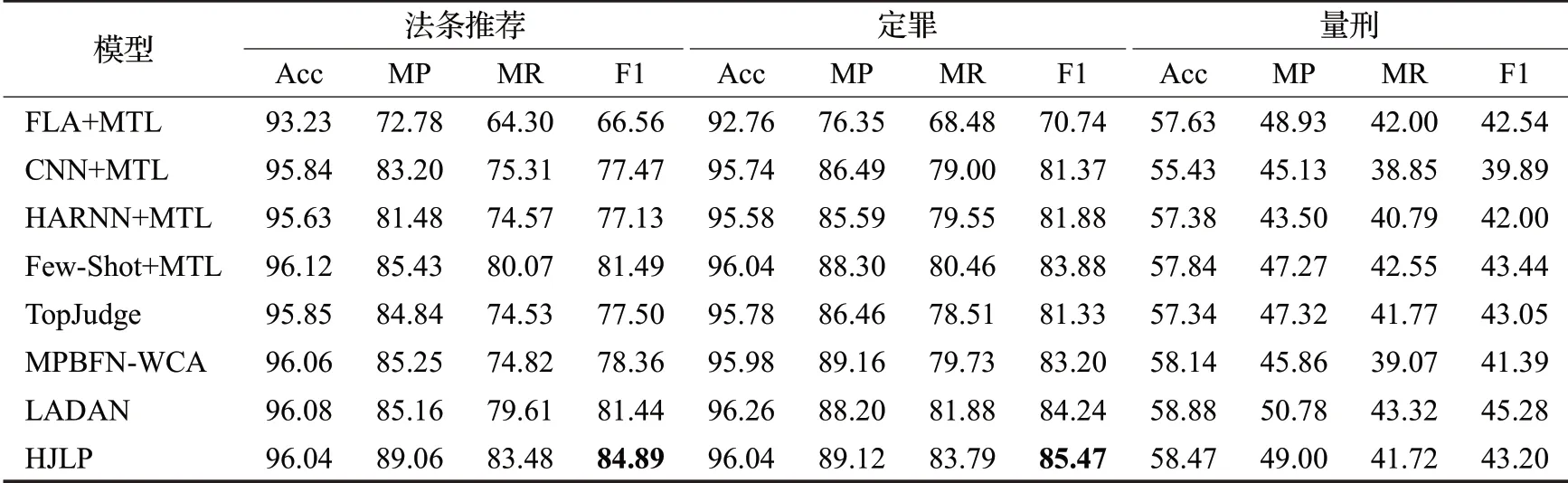
表3 模型在CAIL-big数据集上的法律判决预测任务结果Table 3 Results of model on CAIL-big dataset 单位:%
从实验结果可以看出:
(1)本文提出的模型HLJP在CAIL-small和CAILbig数据集上整体都是优于当前最好的LJP模型LADAN。其中在CAIL-small数据集上的推荐相关法条任务上本文的模型HLJP比最好的模型LADAN在评价指标Acc上提升了5.81%,在评价指标F1上提升了7.58%,在罪名预测任务上的F1上提升了1.03%,在刑期预测任务上的评价指标上也有提升。在CAIL-big数据集上的推荐相关法条任务上本文的模型HLJP比最好的模型LADAN在评价指标F1上提升了4.24%,定罪任务在F1上提升了1.46%。表格中加粗的实验结果表示与最佳基线模型LADAN相比有显著性改善(p<0.05)。总体来说实验结果验证了本文提出的模型HLJP的有效性和鲁棒性。
(2)从具体子任务的角度来说,本文提出的模型HLJP在CAIL-small和CAIL-big数据集上F1的提升都要高于定罪任务和刑期预测任务。例如在CAIL-small上评价指标F1提升了7.58%,在罪名预测任务上评价指标F1提升了1.03%,刑期预测提升了不到0.5%。在CAIL-big数据集上罪名预测任务有提升而刑期预测甚至出现了性能的下降。相比较而言法律文本多层层次化信息的对推荐相关法条任务效果更明显,而对定罪和刑期预测任务而言效果不是很好。可能的原因是本文在法条多层层次化信息模块设计时定罪和刑期预测层的特征相对更少,另外一个可能原因是刑期预测任务中刑期的法律要素对每个罪行的描述比较相似但是不同罪行的刑期却不同。
(3)从数据集的角度来说,本文提出的模型HLJP在CAIL-small数据集上评价指标的提升要比在CAIL-big数据集上提升要高。例如,相关法条推荐任务HLJP在CAIL-small数据集上评价指标F1提升了7.58%,而在CAIL-big数据集上评价指标F1仅提升了4.24%,在刑期预测任务和定罪任务也有类似的特点。主要原因可能是CAIL-small数据集相对于CAIL-big数据集而言类别的数目更少并且法条和罪名的通常是一对一的关系,本文增加了法条层信息以后更容易区分不同的类别。CAIL-small中类别分布相对CAIL-big更均衡,例如推荐法条第二百三十四条的案件在CAIL-small有860与100多个案件的少样本类别比例在8∶1,而在CAIL-big中该案例有18万个左右,少样本类别的案件数目依然在100~200个,这可能也其中一个原因。
4.5 消融实验
为了进一步验证本文提出的模型HLJP考虑法律文本多层层次化信息的效果,与Xu等人[15]实验一致,本文在CAIL-small数据集上作了消融实验。如表4所示,“-无层次化信息”表示本文在HJLP模型的基础上去除层次化的法律文本信息表示只保留法条的表示;HLJP表示本文提出的模型。从实验结果可以看出本文提出的模型在去除法律文本层次化的信息之后,在法条推荐、罪名预测和刑期预测三个子任务上的Acc和F1评价指标上都有显著下降,说明本文提出的考虑法律文本层次化信息是十分有效的。
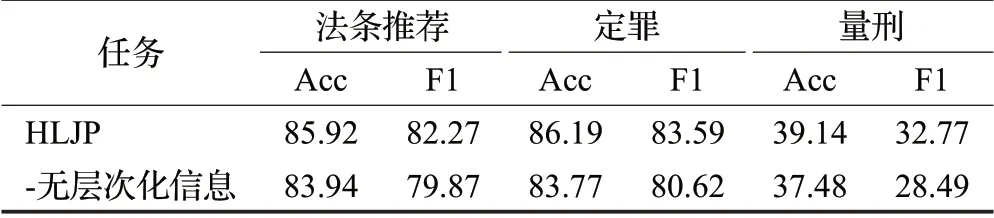
表4 消融实验Table 4 Ablation experiment 单位:%
5 结束语
本文选取智能司法领域中十分重要的法律判决预测任务作为研究重点。现有基于深度学习的法律判决预测方法通常未考虑法律文本中的多层层次化信息,针对该问题本文引入法律文本的多层层次化信息用于法律判决预测任务。具体来说,本文首先对法律文本的多层层次化信息预处理,利用协同注意力机制得到每个子任务的融合不同层次的法条信息的案情描述的表示从而提升三个子任务的性能。本文在真实的公开数据集上进行了实验,结果显示本文提出的融合法律文本多层结构信息的方法在法律判决预测任务上优于当前最好的模型。
本文的研究也存在一定不足之处,如本文只选取了单人单罪作为研究重点。我国法律中有多种类型的案件,本文只针对刑事案件做研究,未对民事和行政各类等案件做对比实验。此外本文也未将研究重点放在少样本类别的。未来,本文考虑从以下几个方面继续研究人工智能在法律判决预测领域的应用:(1)司法领域存在类别不均衡的问题,现有方法在类别不均衡的数据集上性能依然有限;(2)现有的法律判决预测任务多是基于单人单罪进行研究,很少有研究多人多罪的;(3)法律判决预测具有很强的因果关系,在司法领域构建可解释性的模型是十分必要的。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南方周末(2020-01-30)2020-01-30
青少年科技博览(中学版)(2019年12期)2019-04-10
职工法律天地·下半月(2017年10期)2017-09-23
进出口经理人(2017年8期)2017-09-13
法制与社会(2016年32期)2016-12-01
商(2016年20期)2016-07-04
铁道通信信号(2016年1期)2016-06-01
中国舰船研究(2015年2期)2015-02-10
航天返回与遥感(2014年5期)2014-07-31
