
基于kmeans的12345问题热点分析
2023-05-29 09:24田俐
电子技术与软件工程 2023年7期
田俐
(湖北汽车工业学院 湖北省十堰市 442002)
服务型政府并不是一个新提出的概念,其社会管理功能大于政治统治性功能,该服务性受到了我国行政学界的青睐,有关理论也成为了多个学者的研究热点。同时政务服务也被越来越多的公民所关注, 即人们不断关注政府功能与作用[1]。
我国政府一直是服务性政府, 但要想充分地发挥政府的服务性质, 还需要以群众为依托,注重从群众角度,反馈社会各类问题。近年来,12345 热线已被广泛认可[2],它不仅可以解决公共的多种需要,还可以帮助政府更好地实现服务型政府的目标。该热线利用多种渠道,如12345、县长邮箱、手机短信、手机客户端、微博、微信,可以解决不同的需要,包含但不限于:有关行政、社区管理工作、公务的咨询,针对不属于紧急情况的求助,针对可疑的刑事犯罪活动,如侵害社会公民、企业法人或是任何机构的权益,以及有关部门的监督,以促使更多的企业实现可持续的发展。2021年1月6日,《国务院办公厅有关继续改善地方政务服务的指导意见》正式出台,旨在加强对地方政务服务的支持[3],以更好地解决公共的需求,促进经济社会的可持续发展。
面对群众通过12345 热线反馈的问题,如何准确地刻画城市问题是值得探索的。传统的方法成本高、时效性不强,难以快速反映整个城市的问题所在。面对群众反馈的各种数据,使用机器学习算法快速挖掘各类问题,准确提取出当前热点问题是值得探讨的事情。
本文采用文本向量化、聚类等知识内容,对北京大学开放研究数据平台上的“三亚市‘12345’市民服务热线记录数据”展开分析[4]。
1 相关技术
1.1 文本向量化
文本不能直接使用机器学习算法,需要将其转化为机器了解的数据语言。例如:常见的文本向量化方式词袋模型,它通过计算每个数据的频次来提取数据信息,并将其转换成一个较大维度的向量形式数据。但这种计算不考虑数据的语法和意思,而是通过计算频次来提取信息。另一种常见的方式是TF-IDF 算法,其计算方法为:TF-IDF=词频(TF)*逆文档频率(IDF),其中TF 代表文件中某个单词的出现的次数,而IDF 则取决于文件总数/每个单词所占文件的比例。当包含单词的文件数较少时,IDF 的数值会较大。通过TF-IDF 计算,可以将文本转换为向量形式,从而直接使用算法分析。然而,TF-IDF 计算依赖于一种假定,即某一文件中的重点单词在其他文件所占比例较小。此处使用TextRank进行处理后,降低信息维度,再使用词袋模型对其进行向量化处理。TextRank[5]算法是延用PageRank[6]算法的思想创建的基于图模型的关键词提取算法。TextRank 算法将文本转化为以词为节点,语义为边的词语网络图,较LDA 等算法而言,其无需引入外部语料进行训练,便可实现关键词的抽取。其主要计算各个词与其他词的关联,即边的权重,公式如下所示:
其中,ws(vi)表示句子i 的权重,wij表示两个句子的相似度。其流程为:首先对词进行分词处理,而后仅保留部分带有词性标签的词语,构建 N 个大小的窗口内,若滑动窗口,词v1 与词v2 在同一个窗口内,则它们与一条边相连。每个顶点的分数设置为1,顶点 Vi 的权重由连接到 Vi 的点In(Vi)、Out(Vj) 的权重来计算。从而根据其权重可以得到单词的排序。
该算法对每个文档单独执行,不需要一个文档语料库来进行关键字提取[7]。
1.2 PCA算法
主成分分析(PCA)作一种非监督的学习算法,具有节省时间、降低维度的优势,因此被应用于各种特征值提取的场合。pca 采用正交变换,把一个高维度的数据转换成一个低纬度的数据,同时最大限度地保留原有的信息,使得我们的分析更加快速。具体而言,我们经过计算协方差矩阵,得出它的特征值,并且建立它们的特征向量,具体的计算公式如下所示:
(λiE-A)x=0
其中λi 和x 分别表示矩阵A 的特征值和特征向量,将特征向量组合成一个新的矩阵,然后通过矩阵乘法的方式,就可以获得经过降维处理的数据。例如求得的特征向量矩阵为x',原数据为x,则降维后的数据为x'x。
1.3 聚类算法
KMeans 算法是一种典型的聚类算法,它是无监督学习算法,可以根据样本之间的相似度关系分为不同的簇。KMeans 算法是一种基于距离计算相似度的方法,其一般采用欧氏距离来表示样本之间的相似度关系。距离公式如下所示:
du,v=∑|ui-v|
ui表示数据成员,v 表示k 个簇的中心。若计算得到两个对象的距离越近,其相似度就越大,则可将其视作一类。Kmeans 算法的基本原理是:对于一群数据,确定k 个中心点,此处可使用肘部法确定,先假设分别将k 值设置为1、2、3 等等一系列值,计算样本点到各个质心的距离,而后根据距离绘制折线图,找出图中变化最大的点的k 值,即为此处选定的k 值。而后根据k个中心点的特征值和样本点的特征值,计算各个样本点到中心点之间的距离,选择距离最近的中心点,将其归为一类。计算完所有样本点,分至不同簇中,而后得到了k 个簇。对于这k 个簇而言,显然之前给定的质心不再是现在簇的中心点了,因而需要重新计算每个簇的质心,即该簇中各个样本点的平均值,更新质心点后,再次计算各个样本点到质心之间的距离,继续分簇,并再次更新质心。不断重复这一过程,直到质心不再改变,或各个聚类中的样本点保持不变或误差平方和局部最小,即得到kmeans 算法最终的分簇结果。
2 实验
2.1 数据预处理
数据预处理是进行后续数据分析、数据挖掘的基础步骤,需要将数据处理成不含异常值,重复值,空值等的形式,同时根据具体要求提取相应属性列或进行标准化。此处需要首先将文本文件转换成机器可以识别的数据形式,此处主要先进行中文分词、去停用词等操作[8],而后对上述处理后的数据取关键字,再进行向量化处理。
2.1.1 分词
本文选择了三亚市二月份的15327 条数据作为研究对象,每个样本含有orderAll、order、工单编号、工单分类、工单来源、来电时间、来电类型、工单标题、工单内容、工单状态、是否延期、序号、处理时间、处理环节、处理单位、处理描述、extractAddress、lon84、lat84、cluster 等20 个特征值,即共有20 个特征列。此处仅使用oder、工单标题、工单内容、工单分类、extractAddress 等数据,例如表1 为其中一个样本值。

表1:数据集示例
从“工单标题”的数据来看,其中已经包含了市民反映的核心问题,与“工单内容”相比,其仅缺少反馈方式,因此,直接使用“工单标题”的数据,并进行相关的处理,将其转化为向量形式,具体步骤如下:
(1)删除“续”、数字、地址等部分内容,同时处理‘再次来电’等重复数据等问题。此处,续后面为工单编号,此处未找到与之对应的工单编号,直接删除。数字部分一般为某个小区所在位置,或是时间等,不是问题信息,同样地址也不是具体反映的中心部分,可进行适当删除。
(2)分词处理。此处使用jieba 工具进行分词。jieba是一种常用的分词方式,它通过利用 Trie 树的架构,将句子中的所有可能的单词排列形成一个有向无环图,而后通过动态规划来寻求最大概率路径,从而得到分词。jieba 拥有三种分词模式:精确模式;全模式;搜索引擎模式。jieba 是一种非常有效的分词工具,它容易获取,且精度高,无须事先搜集有关语料进行训练,极大地减少了时间成本。此处使用其精确模式,将“工单标题”划分成一个仅包含单词的字符串,为下一步关键词提取、向量化提供了基础词语。
(3)使用正则表达式,删除停用词等无意义词,提取问题描述数据。通过分词,我们能够更好地识别出句子的主题。然而,我们也会发现,许多例如表达语气的单词、标点符号或者连接词,而“关以及”、“问题”、“一栋”、“一巷”则完全等不具有任何分析的意义,我们必须先可以在此步中这些已使用才能更这样好地识别出重点。此处删除停用词使用的是中文停用表“cn_stopwords.txt”文件。
2.1.2 文本向量化
使用one-hot 独热码编码方式处理上述“工单分类”这项离散数据,将其转换成仅含有0 和1 的矩阵形式,对上述分词后的工单标题词组,使用词袋模型,进行向量化处理[9],转换成一个稀疏矩阵,具体操作为将处理后的不同关键字作为columns 值,当该单词在这个样本‘工单标题“中存在时,将其置为1,反之置为0。其公式可简写为下列形式:
对上述关键词向量化后,与工单分类矩阵数据拼接。此时若直接使用该数据,其维度太高,运行成本过大。此处使用PCA 主成分分析法进行降维处理,处理过程为计算矩阵的特征值和特征向量,组合特征向量得到特征矩阵,与原数据矩阵作乘法,即可得到降维之后的数据。本文将上述矩阵维度降至二维。这样处理使得原本的数据信息得以保留,同时降低了处理成本。
2.2 特征提取
在上述二维数据的基础上,本文继续使用KMeans算法对其进行聚类分析[10]。此处选用kmeans 算法主要是由于在此之前数据集中并没有一个明确的label 标志着各个工单问题分别属于哪个核心问题,不知道目标变量是什么,主要目的是将相似的样本自动归到一个类别中,因而此处使用非监督学习算法,而KMeans 算法显然是非监督学习算法中用于聚类的典型代表,因而此处使用KMeans 算法计算各个数据相似度并进行聚类处理。面对预处理后的数据首先需要确定k 值,使用肘部法,画出肘部图,发现当k=3 时,畸变程度变化最明显。为了避免过拟合或达不到分类的目的,我们选择k 的值为3,并从图像中随机选择3 个聚类的质心及中心点,然后计算上述各个样本点与质心之间的距离或相似度,并按照相似度大小将其划分到相似度较小的类中,同时更新3 个质心的值,重复这个步骤,直到达到质心不再发生改变。聚类结果如图1 所示。
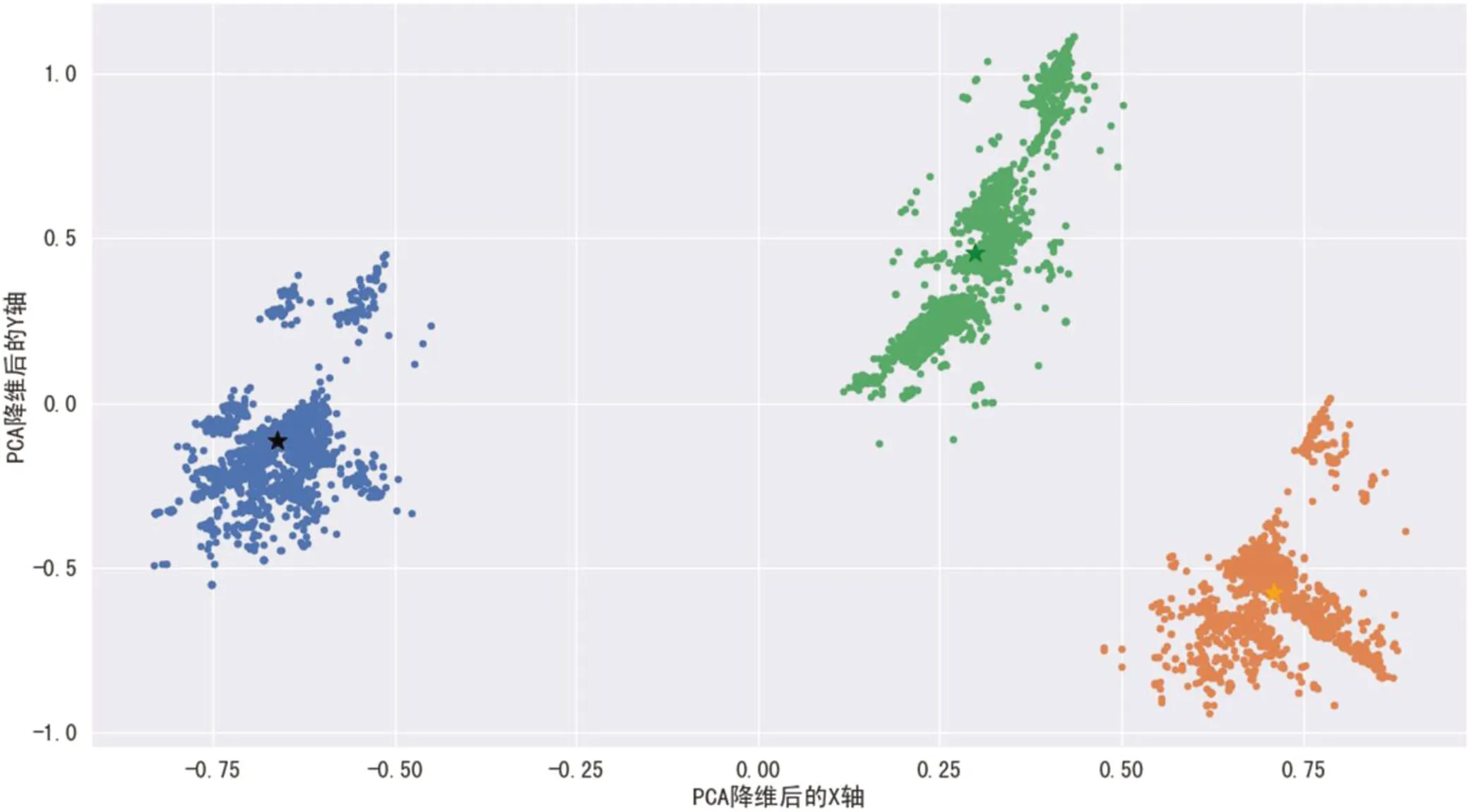
图1:kmeans 算法分簇图
从以上图像可以看出,根据kmeans 算法,就“工单标题”、“工单分类”而言可以将问题大体分为三个簇,此处分别用绿色点、蓝色点、橙色点表示,每个簇的质心使用相同颜色的星型图案显示在图中。此处分簇效果比较好,簇间距离较大,簇内距离较小,分类比较明显。
将上述每个簇的“工单标题”拼接成一个数据,对该数据使用TestRank 算法,计算出每一类的关键词。最终得到集中突出的问题为噪音和违停的问题。观察原始数据有771 条数据涉及到“噪音”问题,450 条数据涉及到违停问题。
3 结论
本文通过对北京大学开放研究数据平台“三亚市‘12345’市民服务热线记录数据”2019年2月数据处理并展开分析,得到海南省三亚市群众于二月份反映的主要问题可以划分为三类,反映了噪声和违停等问题。从这些数据可以看出在2019年2月,三亚市民对这一类问题比较困扰,市政府等相关单位应着手于此,从集中反应的问题出发,逐步解决群众反馈的问题。通过有效利用和深入挖掘这一类政务数据,我们不仅能够更好地了解当前的社会状况,还能够有效地帮助我们构筑起一个具有高效率、高质量的服务型政府,从而极大地改善和优化我们的社会环境,实现城市的高效运转。
但显然,使用本文中提到的算法内容对大规模数据进行分析速度较慢,而且单单使用这几列数据,以及以上算法对此进行分析,其分析效果还是是不够的,需要进一步处理数据,给定相应场景的分词,停用词,进行数据分词以及提取数据关键词,同时提升算法,才能得到一个更好的效果。在未来,我将从更多的维度进行展开分析,而不单单局限于上述提到的这几个部分,进一步改进数据预处理部分,以及分类计算方法,从而使得分析结果能够更加清楚地反映市民生活过程中的集中问题。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
电子测试(2022年7期)2022-04-22
北京航空航天大学学报(2021年4期)2021-11-24
高技术通讯(2021年6期)2021-07-28
校园英语·月末(2021年13期)2021-03-15
中国核电(2017年1期)2017-05-17
中国科技信息(2015年23期)2015-11-07
航天器工程(2014年5期)2014-03-11
外语学刊(2011年3期)2011-01-22
物理与工程(2010年1期)2010-03-25
