
一种基于用户信息映射的跨领域推荐算法
2023-06-25 08:27苑树强史艳翠
天津科技大学学报 2023年3期
苑树强,史艳翠
(天津科技大学人工智能学院,天津300457)
随着网络技术的不断发展,人们的生活越来越丰富,越来越多的用户展现出丰富的兴趣,并在各个领域都有所涉猎.研究[1]表明不同平台的用户偏好和项目特征存在相似性和相关性,因此推荐系统开始利用用户在多个领域的交互信息提高推荐质量,即跨领域推荐[2].跨领域推荐是通过将一个领域的知识转移到另一个领域而缓解数据的稀疏性问题.尤其是当用户进入一个新的领域时,也就是冷启动问题,可以利用用户以前已有交互领域中的信息为其推荐.这两个问题也是推荐系统中长期存在的两个问题.
在跨领域推荐中,最关键的问题是如何建立两个领域之间的桥梁[3].Li等[4]提出一种密码本迁移学习算法,认为跨领域推荐不一定需要迁移具体的数据,而是将用户的评分模式从密集的源域迁移至稀疏的目标域,以此丰富目标域的评分矩阵.基于共享知识模型的跨领域推荐算法SKP[5],将用户属性信息加入推荐过程以解决正迁移不足的问题,引入其他可用的辅助信息增加可用数据量,缓解数据稀疏带来的影响.以上方法属于传统的跨领域推荐,没有对每个域自身的特点进行域适应,也没有进行特征映射.这可能会忽视不同域之间不同特征的影响,甚至会引入负迁移.
在不同的任务中,领域间的联系有所不同,因此对于不同的情况,例如用户、物品、文本属性、评分、标签、类别等都可能作为跨领域推荐的共享信息.Zhang等[6]通过捕获不同标记之间的语义关系,识别域间相似的用户和物品,通过用户和物品的域内和域间相关性约束矩阵分解;但域间用户和物品相似度的准确性对推荐结果的影响很大.Guo等[7]在源域和目标域各自利用用户配置文件生成用户标签矩阵,并利用矩阵分解找到与源域标签相似的目标域标签,将源域的用户配置文件转换为目标域的用户配置文件,使跨域推荐转为单域推荐;但稀疏的用户-标签矩阵导致标签相似性计算困难.
对于跨领域推荐,可迁移特征的质量也是影响推荐效果的重要因素.近年来,随着深度学习的发展,研究人员开始利用深度学习的方法改善跨域推荐的效果[8].Man等[9]提出一种利用多层感知器捕获跨域的非线性映射函数的框架,为学习各域实体的领域特征提供了很高的灵活性.Zhu等[10]认为不同用户的偏好不同,所以其映射函数也应该不同.通过用户特征嵌入反馈的元网络生成个性化的映射函数,以实现每个用户的个性化偏好传递.上述算法利用深度学习的方法映射用户特征,但训练依靠域间的重叠用户,而现实情况下域间重叠用户较少.Kang等[11]提出使用欧氏距离反映用户对物品的偏好,并使用半监督的方法训练映射函数,但度量空间中用户-物品偏好表示的准确性明显影响推荐结果的准确性.
大部分情况下,物品、标签等信息很难出现重叠;但随着网络的发展,信息越来越丰富,用户可能会同时在多个领域存在交互信息.所以,针对源域和目标域存在重叠用户的情况,本文提出一种基于用户信息映射的跨域推荐算法.虽然不同领域中标签没有重叠,但是不同领域中可能会存在含义相似的标签,即标签对用户和物品嵌入模型的影响应该是跨领域的.因此,首先通过用户和标签的交互信息得到用户和物品特征,并使用降维方法处理成低维特征,再将用户的源域特征映射到目标域.此外,用户映射之后应保持自己的偏好类别,所以通过聚类方法生成用户种群,并利用不同种群的偏好信息和重叠用户训练映射函数.综上所述,本文通过映射用户在源域中的信息,为用户推荐目标域的物品,本质上属于基于内容的推荐系统.
本文的主要工作如下:(1)提出一种新的用户、物品信息表示方式,利用直接标签和间接标签表示用户和物品,更好地体现用户偏好和物品特性;(2)改进降维方式,利用用户物品的交互信息降维,并考虑标签信息特征的重要性;(3)对于映射函数优化时标记样本过少的问题,利用种群信息标记非重叠用户,并优化映射函数.
1 算法描述
1.1 问题定义
跨领域推荐中存在一种情况:在一个系统中,存在一个信息丰富的领域A和一个信息较稀疏的领域B,当A中的用户进入B领域时,由于该用户在B领域中没有信息,因此会遇到冷启动问题,例如电商的图书领域和CD光盘领域,此时需要迁移A中的信息为用户改善推荐效果.在本文中,将信息丰富的领域称为源域S,信息稀疏的领域称为目标域T.源域和目标域的用户集合为US、UT,物品集合为VS、VT,标签集合为BS、BT,评分集合为RS、RT.m为用户数量,n为物品数量.图书领域和光盘领域在现实情况下一般不会存在重叠的物品和标签,但可能会存在一些重叠用户,使用UO=US∩UT表示重叠用户集合.
根据以上描述,给出问题的定义:假设存在两个领域,源域S和目标域T.US∩UT≠∅,VS∩VT=∅,BS∩BT=∅,目标是为源域中的非重叠用户推荐目标域物品.
1.2 用户和物品的向量化表示
要将源域的用户特征映射到目标域,首先要得到用户的向量化表示.大部分方法(如矩阵分解[12])的用户向量都依靠用户-物品的交互矩阵得到.但在目标域中用户-物品的交互矩阵一般较为稀疏,影响生成用户向量的准确性.并且,根据上述方法生成的用户向量得到的用户种群难以确认种群中用户偏好相似性,缺乏可解释性.标签作为用户自己理解和添加的信息,一定程度上反映了用户的兴趣,可以更好地反映用户的偏好信息.因此,本文主要依据用户和物品交互过的标签信息进行推荐.
由于用户和物品的向量化表示形式相同,下面用源域用户集合US为例,介绍源域用户向量生成的过程.对于US来说,每个用户的唯一标识是离散的,互相没有关系,可以使用one-hot编码表示[13],向量维度为US中用户的数量.对于标签而言,用户通常会交互多个标签,将其表示成multi-hot的形式.用户在打标签时是对某一物品标注,不仅是用户自己标注的标签可以作为标签信息,用户标注过的物品的其他标签也可以作为用户的信息表示.
如图1所示,对于用户1而言,除了标签1外,标签2、3也可以作为标签信息.将标签1称为用户1的直接标签,标签2、3称为用户1的间接标签.

图1 标签关系表示Fig.1 Representation of label relation
同理,对于物品1而言,标签1、2、3为直接标签,标签4为间接标签.用户和物品的标签信息由直接标签和间接标签组成.
以用户为例,标签信息表示为b,包括直接标签和间接标签两部分.直接标签表示成multi-hot向量形式,用符号b表示,间接标签为交互过的物品的直接标签的向量集合,使用符号b'表示.b'=+...+,表示该用户交互的第z个物品直接标签表示.
其中α为超参数,表示间接标签在用户表示中的影响力.以用户1为例,=[1 0 0 0],b'=[0 1 1 0],最终的标签信息为b=[1αα0].用户信息的整体表示如图2所示.

图2 用户信息的整体表示Fig.2 Overall representation of user information
同理,物品向量也由one-hot编码和标签信息表示,标签包括物品本身的标签以及与该标签交互的用户的其他标签.
本文源域和目标域中用户、物品表示向量的集合分别使用uS、vS、uT、vT表示.
1.3 特征向量降维
在现实情况下,如在亚马逊数据集中,用户数量和物品数量都非常庞大,所以1.2节的用户向量和物品向量都是一个非常稀疏的高维向量,难以直接使用.因此,本文提出一种降维方式,将高维向量降维.采用深度学习嵌入方法,借鉴双塔模型的思想[14],通过深度神经网络(deep neural networks,DNN)处理稀疏向量.但如果直接将该向量输入DNN中,会导致网络参数过多.为了解决这个问题,将输入向量分成两个部分,如图3所示.下面以源域中的用户i和物品j为例,将上一节得到的用户向量或物品向量和作为输入(∈uS,∈vS),并将one-hot编码部分和标签编码部分分别处理输入隐藏层中:
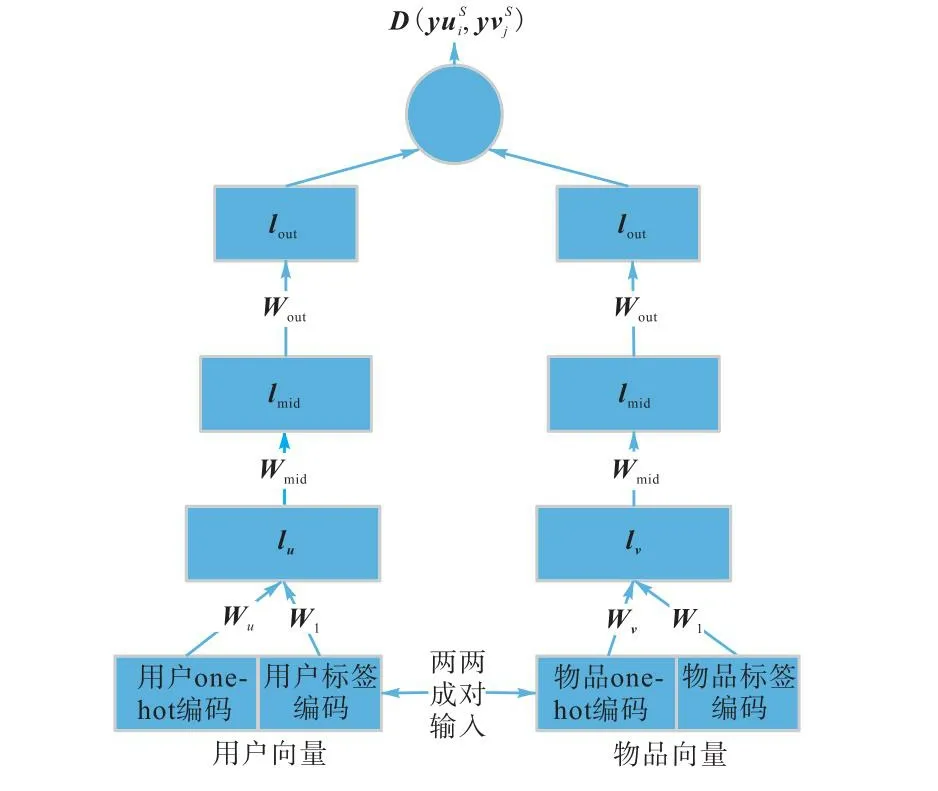
图3 深度学习降维方法Fig.3 Deep learning dimension reduction method
间的欧氏距离,表示用户和物品的交互信息,使用户与交互过的物品的距离更近.损失函数为
式中:W1为二元指示矩阵,表示用户物品是否有交互,◦表示公式中只考虑交互过的用户和物品的信息,因为未交互过的用户和物品距离不应该更近.将源域和目标域中用户、物品表示向量集合uS、vS、uT、vT分别降维得到对应的降维向量集合yuS、yvS、yuT、yvT.
1.4 种群映射函数
1.3节中得到了用户和物品的低维向量表示,将源域和目标域的用户yuS通过k均值聚类(k-means)算法分别生成k个用户种群,其中用户之间的距离使用欧氏距离表示.
本模型生成映射函数将源域的用户向量映射到目标域中.该函数反映了源域和目标域之间的关系.将重叠用户在源域的向量映射到目标域中,并使它和目标域中交互的物品距离更近.通过重叠用户在目标域中的交互信息优化映射函数
式中:W2为二元指示矩阵,表示重叠用户在目标域的交互信息;f()θ表示映射函数,θ为全局参数.
由于现实情况中一般只存在少量的重叠用户,利用重叠用户作为标记数据的有监督的训练方法难以很好地训练模型,所以本文利用用户种群关系标记非重叠用户.如图4所示,对于非重叠用户来说,映射后的位置应该靠近同类的重叠用户.
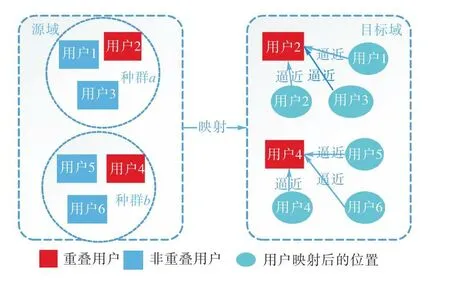
图4 非重叠用户映射Fig.4 Non-overlapping user mappings
因此,重叠用户映射后在目标域的距离逼近原本的位置,而非重叠用户则逼近同类重叠用户.基于以上思想,给出用户关系的损失函数为
其中:λ代表训练时种群信息的权重,da代表种群a内非重叠用户映射后与该类重叠用户的距离,k代表用户种群个数,da表示为
用户映射函数的完全损失函数可以表示为
为了获得映射函数,本文采用随机梯度下降法训练参数θ.通过训练集中用户向量反向传播训练映射函数参数,直到模型收敛.
1.5 跨领域推荐
当给一个源域用户推荐目标域物品时,这个用户在目标域没有任何交互信息,相当于冷启动用户.推荐与映射用户最接近的N个目标域物品,如用户i和物品j的距离D使用欧氏距离表示为
通过计算冷启动用户i和目标域物品的距离,将物品按欧氏距离由低到高排序,得出目标用户i的推荐列表,记为Ri={v1,v2,…,vn},最终选取前N个物品为目标用户i进行推荐.
1.6 总体程序
输入:源域和目标域的用户物品向量集合uS、vS、uT、vT.
输出:推荐物品序列.
(1)特征降维:利用用户物品的交互信息训练深度学习模型,将uS、vS和uT、vT中元素两两成对输入模型降维,得到降维后的向量表示yuS、yvS、yuT、yvT.
(2)源域用户聚类:将集合yuS通过k-means聚类算法生成k个用户种群.
(3)种群个性化映射:利用源域用户yuS中种群信息和重叠用户交互信息优化映射函数.
(4)生成推荐列表:将源域用户yuS映射到目标域,计算用户和目标域物品的欧氏距离,生成推荐列表.
2 实 验
实验环境:16GB内存,Windows10操作系统,RTX 2060显卡,Python3.6,机器学习框架TensorFlow 2.5.0.
2.1 数据集及其处理
实验部分使用的数据集是亚马逊数据集,该数据包含了42个不同的物品域,选取两个类别:图书和光盘.其中图书域用户数量为603668,光盘域用户数量为75258;重叠用户数量为16738.
将图书域视为源域,光盘域视为目标域.数据集中的reviewerID字段作为用户ID;asin字段作为物品ID;summary字段作为标签.对原始数据集中的数据进行清洗,删除交互少、孤立的数据.对于非重叠用户,在源域数据中去除了交互物品少于150的用户、交互用户少于150的物品和出现次数少于30的标签.在目标域中去除了交互数据少于30的用户和物品以及出现次数少于4的标签.对于重叠用户而言,去除了交互数据少于10的用户.数据集统计信息见表1.

表1 数据集统计信息Tab.1 Data set statistics
2.2 实验设置
对于目标域,选取30%的重叠用户,删除其所有的交互信息,将其作为冷启动用户(测试用户)计算推荐准确性.在实验中,为了解决对所有物品排名的耗时问题,在用户没有交互过的物品(负样本)中随机抽取999个物品,并评估交互过的物品(正样本)的排名是否高于未交互物品(负样本).为了探究重叠用户数量对实验结果的影响,在模型训练时,对训练集中的重叠用户进行限制,分别选取重叠用户的10%、50%和100%对模型进行训练.为了消除实验结果的偶然性,每组实验分别进行10次并取平均值作为最终结果.
2.3 评价指标
使用精确率(precision)和平均精度(mean average precision,mAP)衡量和评价推荐结果.精确率是广泛用于推荐系统中的度量标准,精确率针对预测结果而言,表示预测为正的样本中有多少是真正的正样本.mAP是一种位置敏感的评价指标,反映每个用户的平均精确率的平均值;推荐列表中相关物品越靠前,mAP就越高.
其中:P表示精确率;R(u)表示推荐列表;T(u)表示用户实际交互的物品;Pav,i表示单个用户平均精确率,针对的是一个用户的排序结果;N1和N2分别表示j在命中列表和推荐列表中的排名;Pavm表示平均精度.
2.4 实验过程与结果分析
为了研究本算法的推荐效果,对模型中的几个参数分别单独测试它们对推荐效果的影响,包括聚类k值、降维的维度、间接标签的权重α、q和p的比值、种群信息权重λ,并与几组跨领域推荐的模型对比,分析模型的性能.
2.4.1 聚类k值
聚类k值对推荐结果的影响如图5所示,即用户聚类数目k值对冷启动用户top10推荐效果的影响.聚类k值表示源域用户和目标域用户的种群个数,代表着用户偏好的分类,聚类效果也影响着用户偏好映射的准确性.推荐结果在k值大于8时持续下降,在k值为6时取得最高值.分析原因可能是当k值过大或过小时,源域和目标域的分类难以做到很好的对应,导致映射效果降低,因此在后续实验中将k值设为6.

图5 聚类k值对推荐结果的影响Fig.5Effect of clustering k value on the recommendation result
2.4.2 降维维度
在实验过程中,选择合适的降维维度非常重要,降维维度对推荐结果的影响如图6所示.

图6 降维维度对推荐结果的影响Fig.6 Effect of dimension reduction length on recommendation results
为了研究降维维度对实验结果的影响,将降维维度逐渐增大,分别考虑降维到2、4、6、8时精确率和mAP的取值(图6).随着维度的提高,推荐结果准确性下降.在降维维度为2时,模型的性能表现最好.
2.4.3 间接标签权重
间接标签权重α代表着对间接标签信息在用户向量、物品向量中比重的大小,间接标签权重对推荐结果的影响如图7所示.

图7 间接标签权重对推荐结果的影响Fig.7 Effect of indirect label weight on recommendation results
由图7可以看出,随着间接标签权重的提高,推荐精确率和mAP逐渐升高,达到最高点后开始下降.这主要是因为只考虑直接标签难以反映用户的全部偏好,适量加入间接标签可以提高用户偏好的描述准确性,而间接标签为其他用户打的标签,有可能带有与本用户不同的偏好信息,过高的权重可能会放大间接标签中的无关因素.
2.4.4 降维中q和p的比值
q和p的比值反映降维过程中标签信息权重.q和p的比值对推荐结果的影响如图8所示.

图8 q和p的比值对推荐结果的影响Fig.8Effect of the ratio of q and p on the recommendation results
由图8可以看出,标签信息权重为4.5时效果最好,主要是因为标签信息代表用户的偏好和物品的类别,适当提高标签信息的权重有利于得到更好的推荐结果,而过高的标签信息权重可能会忽略用户项目的标识信息.
2.4.5 种群信息权重
种群信息权重λ代表在训练映射函数时,非重叠用户信息的影响力大小.种群信息权重对推荐结果的影响如图9所示.

图9 种群信息权重对推荐结果的影响Fig.9Effect of population information weight on recommendation results
由于重叠用户数量较少,适当提高非重叠用户信息的权重,可以改善推荐效果.由图9可知,在λ为0.75时效果最好;但非重叠用户在目标域不存在用户交互信息,所以过高的权重可能会影响映射的准确性.
2.4.6 消融实验
为研究间接标签和种群信息的有效性,在选取重叠用户100%时,分别在缺失间接标签和种群信息的条件下进行消融实验,结果见表2.

表2 消融实验结果Tab.2 Ablation experimental results
P@10、P@20分别代表精确率在top10和top20上的表现,M@10、M@20分别代表mAP在top10和top20上的表现.由表2可以看出,加入间接标签信息明显提高了模型的推荐精确率,因为用户与物品的直接交互较少,直接标签不能很好地代表用户和物品的信息.而加入种群信息标记非重叠用户,使映射函数的训练不仅仅依靠重叠用户,提高了映射的准确性,进而得到更好的推荐效果.
2.4.7 基线设置
为了评估算法性能,选取以下几组不同的方法和本文提出的模型对比,以验证本文模型的有效性.
EMCDR[9]:一个用于处理跨域推荐的嵌入和映射框架,通过潜在空间中的映射函数将源域和目标域中的用户和物品投影到两个不同的潜在空间中.
SSCDR[11]:一种基于半监督方法的冷启动用户CDR框架,利用非重叠用户的数据学习映射函数.
PTUPCDR[10]:一个CDR用户偏好个性化传输框架,学习一个由用户特征嵌入组成的元网络生成个性化的桥接函数,以实现用户偏好的个性化传递.
表3列出了各模型在top10和top20上的详细数据.EMCDR使用重叠用户训练映射函数,受重叠用户数量影响较大;本文模型利用种群信息解决非重叠用户在目标域中信息较少的问题,对重叠用户数据的依赖性降低.对于同样利用非重叠用户数据和利用用户交互信息训练模型的SSCDR和PTUPCDR,本文模型也表现出更好的推荐结果.

表3 不同模型的评价指标对比Tab.3 Comparison of evaluation indexes of different models
实验表明,本文模型可以更好地应对真实情况下重叠用户过少的问题,可以有效地为具有跨域信息的冷启动用户推荐物品.
3 结 语
本文通过将源域中的用户偏好映射到目标域,提高用户在目标域中的推荐效果,适用于为其他领域存在交互信息的冷启动用户进行推荐,如向电商平台中已购买过某领域(如图书)物品的用户推荐目标域(如衣服)的物品.利用标签信息获得更准确的用户偏好,经过深度学习降维处理后将其映射到目标域,并通过种群信息利用非重叠用户训练映射函数,提高映射准确性.通过大量的实验,探究各个参数对实验结果的影响,验证了本文模型对重叠用户数量的依赖更低,相较于基准实验,有更好的推荐准确性.
猜你喜欢
今日农业(2022年15期)2022-09-20
车主之友(2022年4期)2022-08-27
计算机技术与发展(2020年11期)2020-12-04
海峡姐妹(2019年12期)2020-01-14
红土地(2018年7期)2018-09-26
电子与信息学报(2015年12期)2015-08-17
计算物理(2014年1期)2014-03-11
燕山大学学报(2014年1期)2014-03-11
当代畜禽养殖业(2014年10期)2014-02-27
中学生物学(2008年6期)2008-08-29
