
基于人工智能算法的地浸采区产量预测
2023-08-04 02:50廖文胜杜志明王亚安王立民
铀矿冶 2023年3期
贾 皓,廖文胜,杜志明,王亚安,王立民
(1.核工业北京化工冶金研究院,北京 101149;2.中核矿业科技集团有限公司,北京 101149)
随着地浸采铀工艺的日趋成熟,地浸勘探领域智能化逐渐完善,通过与大数据、人工智能算法的深度融合,大幅提高了勘探工作效率与质量[1];地浸与水冶过程也基本实现了实时监控与数据集成调度,但对于在生产过程中采集的数据仍然存在只收集不处理,或仅对数据直观判断的情况[2]。对于海量数据,未进行深层挖掘与分析建模,不仅无法根据已有的生产参数安排未来生产计划,也无法精准把握矿区的生产趋势[3-4]。
在铀矿采区开发的中后期,随着金属浸采率不断增加,其浸出液铀浓度与水量通常呈下降趋势,通过洗井、注液过滤、增强抽注循环等方式虽能够在短期内增加金属产量[5];但囿于资源总量,整体上金属产量仍呈降低趋势,导致开采成本显著增加。实际生产中的井场,在集控室与水冶车间对抽注液量、压力、金属浓度等参数的实时监控与采集,不仅能够对生产异常即时诊断,更有利于形成广泛全面的生产数据库。根据长周期下的生产参数建立数据模型,从而准确预测金属产量,可为采区未来生产制度的调整与矿区的整体经济性评价提供参考。
1 预测算法研究现状
1.1 智能算法应用领域
目前,铀矿采区金属日产量预测主要通过平均铀浓度与日抽液量乘积求取,误差较大。基于人工智能算法的采区产量预测在铀矿领域研究较少,而在石油天然气、煤炭、稀土等领域应用较为成熟。薛永超[6]等使用深度森林算法对油井产量做出预测,获得92%左右的预测精度,该方法在传统的随机森林算法上做出了极大改进,但在精度上仍然存在优化空间。蔡光琪[7]等基于原煤剥离量等自变量提出了改进的切比雪夫神经网络,该方式较传统BP神经网络运算资源小且精度更高;但未考虑储量因素,具有一定局限性。马承杰[8]考虑到传统数值模拟方式的缺陷,从储层物性出发,使用长短期记忆神经网络与循环神经网络建立LSTM数据模型,该模型性能优越,能够更好地捕捉时序关系差异;但在长期预测上精度仍有局限性,需进一步优化输入参数。
1.2 地浸产量预测适用算法分析
当前人工智能算法主要用于解决分类和回归问题;而本研究中的地浸产量预测问题,属于数据拟合回归范畴,因此诸如SVM、决策树、KNN等众多分类算法并不适用,应当从回归预测算法中选取合适算法进行。常见的回归算法有人工神经网络(ANN)、卷积神经网络、BP神经网络、逻辑回归、多元线性回归等。
矿区内抽注液井数量多,现场针对单井能够获取的参数较为单一(仅有流量、金属浓度),数据维度过低,不利于高精度数值模型的建立。因此,笔者从数据集成角度考虑,以整个采区金属日产量为研究对象,增加注液压力、注氧压力、浸采率等输入参数,从资源总量与浸采工艺数据入手,建立金属产量预测模型。
本研究中可用的数据既有相关生产参数,也有相对应的每日金属量数据,可以采用有监督学习的算法。多元线性回归建模速度快、算力需求小、模型可解释性强,常被用于煤炭价格、地下水水位、煤矿井下瓦斯体积分数等具体指标数据的预测[9-11],与本研究中的数据类型较为契合。人工神经网络属于黑箱模型,可以充分逼近各类非线性关系,还具有并行分布处理与自适应未知参数的特点,该方法在页岩油藏产量与地下水涌水量等地质参数预测方面都有成功运用的先例[12-13]。因此本研究拟采用多元线性回归和人工神经网络算法建立模型。
2 生产参数概况
以北方某矿床C10采区进行分析,该采区铀金属储量为55.3 t,截至2022年2月浸采率约48%。该采区共包含21口抽液井与47口注液井(目前关停抽液井4口),矿体平均厚度为4.3 m(厚度0~13.5 m),平均铀品位为0.016%(品位0.01%~0.054%),平均平米铀量为1.33 kg/m2。该采区自2017年10月开始投入生产,其金属日产量在2018年中旬达到高峰(约35 kg/d),随后下降至约10 kg/d。从井场集控室采集了对金属日产量存在相关性的变量(表1)。
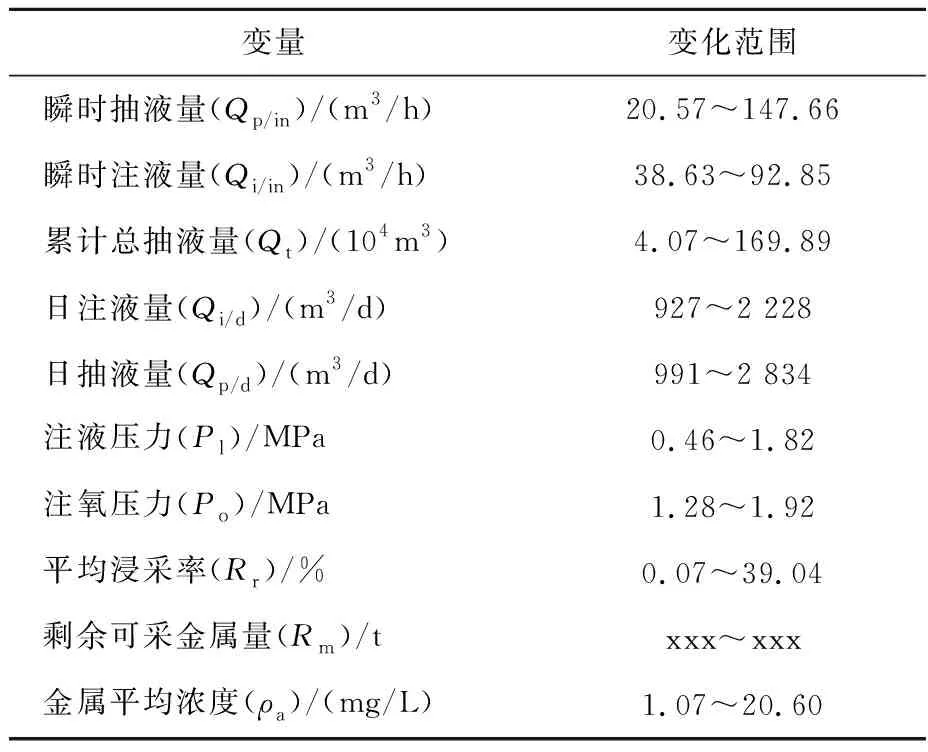
表1 采区生产参数汇总Table 1 Summary of production parameters in mining area
该采区信息化程度较高,可获取抽液、注液与储量等众多参数。针对单日金属量的预测,需要使用每日采集一次或单日采集多次取平均值的参数。因此,舍弃取样频率较低的参数,如浸出液pH、离子浓度与电位等,以抽注液参数与金属浓度为主要研究变量。
金属平均浓度为该采区各抽孔每日采样浓度的加权平均值,考虑到每日采样时刻的差异与单日内浓度波动,本研究通过表1中的10个变量建立金属日产量预测模型,通过多元线性回归与人工神经网络方式实现产量预测。
3 铀产量预测模型构建
3.1 基于多元线性回归方法的预测模型
3.1.1 多元线性回归基本原理
多元回归分析是指通过对多个自变量与1个因变量的相关分析,建立预测模型进行预测的方法。当自变量与因变量之间存在线性关系时称为多元线性回归分析,公式为
f(x)=ω1x1+ω2x2+…+ωnxn+b。
(1)
式(1)形式简单,易于建模且可解释性强。ω和b通过均方误差最小化来确定,该方式又称“最小二乘法”,即找到1条直线,使样本到直线上的欧氏距离之和最小,均方误差计算公式为
(2)
3.1.2 多元线性回归模型搭建
以10个生产参数为自变量,金属日产量为因变量进行模型搭建。首先对所有自变量计算方差膨胀系数(variance inflation factor,VIF),VIF是回归系数估计量的方差与假设自变量无线性相关时方差的比值,表示多元线性回归模型中的共线性程度。其计算方法见式(3),R2表示判定系数,是衡量模型拟合度的参量。
VIF=1/(1-R2)。
(3)
VIF值越接近于1,多重共线性越轻;反之越重。通常,对于VIF>10的自变量选择放弃;但考虑到本模型流量参数选取较多(存在一定的多重共线性),因此对VIF适当放宽,对于VIF>30的自变量选择舍弃。各自变量的VIF值见表2,平均浸采率与瞬时注液量参数的VIF>30,选择舍弃。
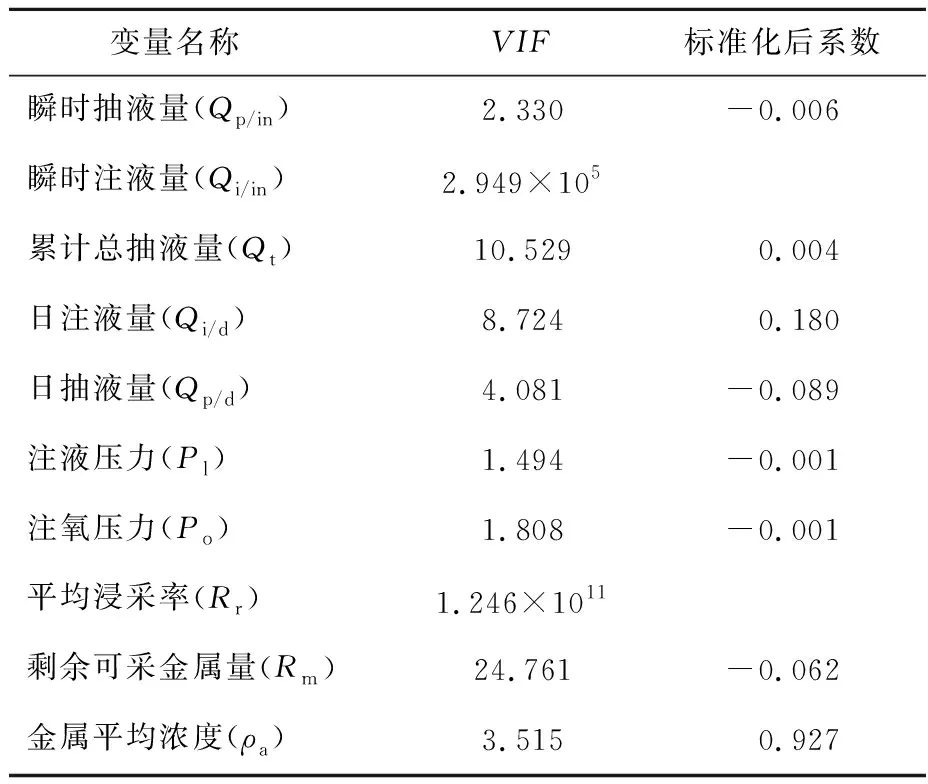
表2 各生产参数VIF与标准化系数计算结果Table 2 Calculation results of VIF and standardization coefficient of each production parameter

表3 使用贝叶斯优化后的超参数取值Table 3 The value of super parameters after Bayesian optimization

f(x)=-0.005×Qp/in+8.147×10-8×Qt
+0.007×Qi/in-0.4×P1-0.56×P0+0.003×
Qp/d+1.942×ρa-6.18×10-5×Rm-14.341。
(4)
由于各变量数值在数量级上差异较大,故式中变量系数不能反映各自变量对于金属日产量的影响程度,需要对自变量系数进行标准化处理,得到标准化后的系数(表2)。可以看出,金属平均浓度起决定性作用,与常规计算方法相对应;日抽液量与日注液量的影响程度较大,表明流场循环情况对于金属日产量也具有重要影响。
从多元线性回归模型效果(图1)来看,在前期单日产量增长阶段,模型预测值与真实产量拟合良好;但在生产后期,预测值整体偏大且具有不稳定性。这是由于各自变量权重不变导致其某一部分适应性下降。单日金属产量预测值平均误差约为1.56%;自2017年11月至2020年12月的总产量预测误差为246.8 kg,相对误差为1.24%,整体预测效果可靠。

图1 多元线性回归模型训练效果Fig. 1 Training effect of multiple linear regression model
3.2 铀产量的人工神经网络预测模型
3.2.1 人工神经网络基本原理
近年来,有关神经网络在各学科领域的运用方兴未艾[14-16]。神经网络是由具有适应性的简单单元组成的广泛并行连接网络,能够模拟生物神经系统对外界情况做出交互反应,图2为单个神经元示意图。

ω—权值;b—偏置;σ—激活函数。图2 单个神经元计算原理Fig. 2 Calculation principle of single neuron
根据激活函数选取的不同,人工神经网络既可以解决分类问题,也可用来进行回归拟合,其模型结构见图3。原始数据输入之前通常进行标准化处理以消除数据尺度间的差异,标准化计算公式为

图3 人工神经网络结构示意图Fig. 3 Structure diagram of artificial neural network
(5)
多个隐藏层的设置能够识别出训练数据的突出特征;激活函数能够给输出层中经过线性计算的系统添加非线性特征。其中ReLU函数能够使神经网络模型更快速地收敛,避免过饱和现象,有效抵抗梯度消失问题,ReLU函数的公式为
f(x)=max(0,x)。
(6)
在人工神经网络建立中,通常需要调节模型参数,性能最优的参数组合就是所求目标。贝叶斯优化算法基于现有的参数预测结果来建立替代函数(概率模型)[17],通过替代函数得到目标函数最优解,可用来调节模型超参数。
3.2.2 人工神经网络模型搭建
搭建的人工神经网络产量预测模型,输入数据包含该采区2017年11月至2020年12月的生产数据,共1 065组。由于该模型不包含时间序列相关变量,部分日期无生产数据不影响模型精度。考虑到验证模型的泛化迁移能力,2021年1月至2022年2月的生产数据不纳入模型训练与测试。
以表1中的10个自变量为数据输入层,在输入之前通过标准化处理以消除不同参数间的差异。考虑到样本的均匀覆盖,在近3年的1 065组生产数据中,按照7∶3的比例随机选取训练集与测试集。使用训练集搭建模型,使用测试集对模型进行初步检验。
该模型结构除了输入层与输出层外,还包含2个隐藏层,通过贝叶斯优化算法调节得到最优模型参数。该模型第1个隐藏层包含95个隐藏神经元,第2个隐藏层包含97个隐藏神经元,最大迭代次数196次,初始学习率为0.005。基于以上参数即可得到人工神经网络产量预测模型。
从基于1 065组训练测试数据的模型效果(图4)看出,实际金属日产量与人工神经网络模型的预测值变化趋势基本相同;在前期到达产量峰值前,实际金属日产量跳动较大,而人工神经网络模型预测值变化较平缓。这可能是由于生产前期金属浓度增长较快,地下流场不稳定且变化较快,反应速率持续增加;也可能是因每日的金属浓度记录时间不同造成的。对于产量下降阶段,人工神经网络模型的预测值较为精准,单日金属产量平均误差仅有0.88%;比多元线性回归模型更为精确。从整体来看,人工神经网络模型对这3年总产量的预测误差为81.4 kg,相对误差为0.41%;这也表明该模型预测精准,效果良好。
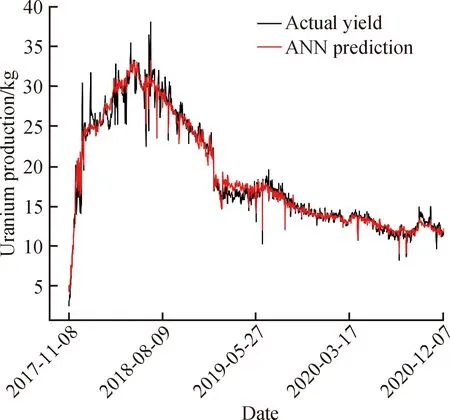
图4 人工神经网络模型训练效果Fig. 4 Training effect of artificial neural network model
4 实例运用与分析
基于以上2个预测模型,使用该矿床C10采区的2021年1月至2022年2月的数据进行泛化能力检验。
4.1 多元线性回归模型检验
多元线性回归模型针对验证数据集的预测与误差分布见图5。可以看出,在这段时间前期,金属日产量在10~12 kg/d波动;在生产中后期,金属日产量缓慢下降。多元线性回归模型的预测趋势与预期相符;但数据波动较为严重,预测值变化趋势为降低-增加-降低,预测结果均衡性较差,但相对误差大多在±5%之内。从期间金属总产量来看,整体预测较为可靠,相对误差为-1.68%。
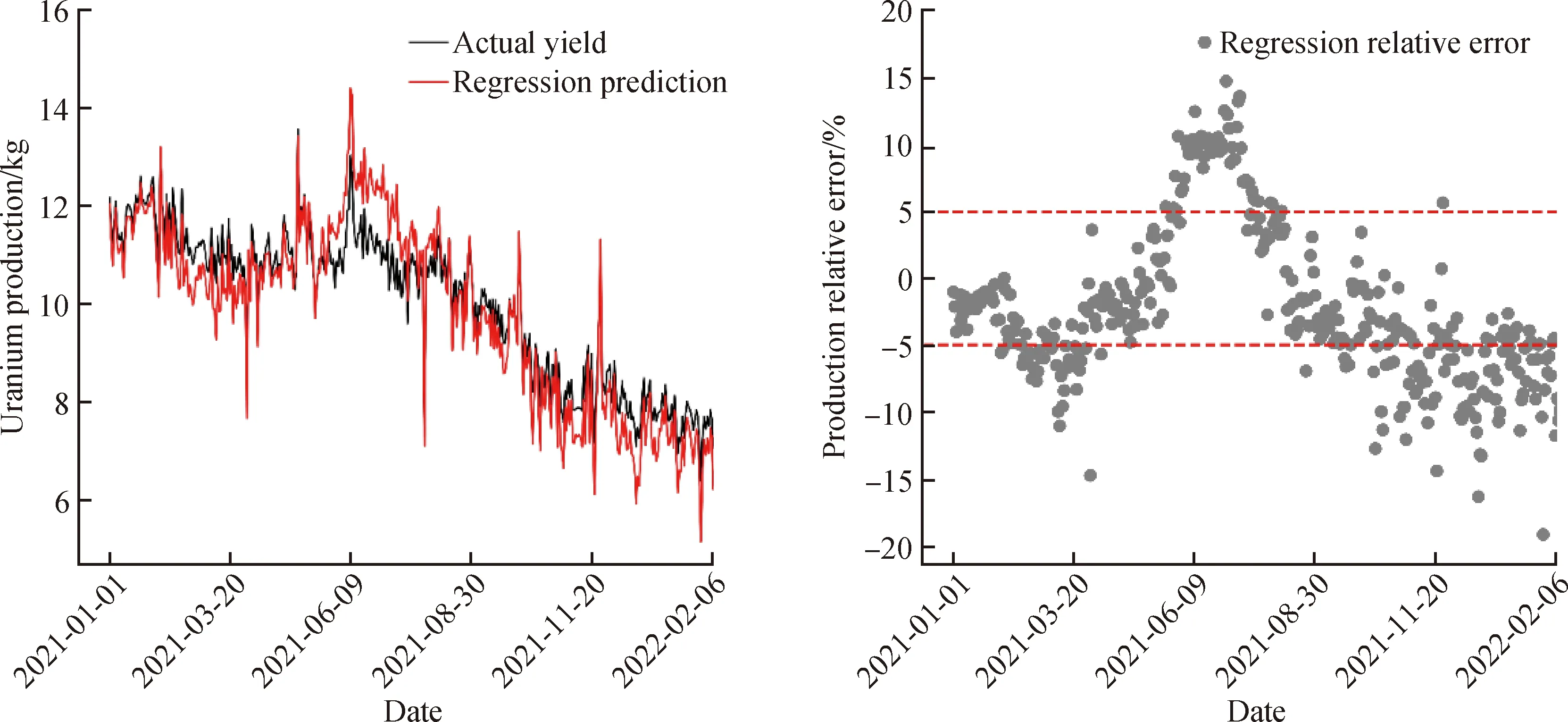
图5 多元线性回归预测检验与误差分布Fig. 5 Prediction test and error distribution of multiple linear regression
4.2 人工神经网络模型检验
人工神经网络的预测结果与误差分布见图6。可以看出,该模型整体趋势拟合效果良好,对跳动较大的产量数据拟合效果一般;绝大多数预测值均分布在±5%以内,且无明显变化趋势。该模型泛化能力较多元线性回归模型有了很大提高,从预测期间金属总量来看,相对误差仅为-0.63%,说明该模型不仅能够准确预测金属日产量,也能精准确定某段时间的金属总产量。

图6 人工神经网络模型预测检验与误差分布Fig. 6 Prediction test and error distribution of artificial neural network model
4.3 预测效果对比
3种方式预测效果对比见表4。可以看出,多元线性回归模型和人工神经网络模型的预测效果较简单金属日产量计算方法有了较大提高。通常使用金属浓度与当日抽液量相乘求解金属日产量,虽然计算误差大多分布在±5%内;但由于计算值普遍偏小,因此预测值并不均衡,在日产量与总产量的预测上表现一般。多元线性回归模型的性能介于计算值与人工神经网络模型之间,其预测误差较小;但存在一定比例的离群值(相对误差大于10%)。人工神经网络模型表现优异,其金属日产量与总产量误差均小于1%;虽然预测趋势较实际日产量更为平缓;但拟合效果最好,76.2%的预测值相对误差均在±5%以内,且离群值较少,说明该模型预测精准且泛化能力良好。

表4 3种预测方法的预测效果对比Table 4 Comparison of prediction effects of three prediction methods
5 结论
针对地浸铀矿采区金属日产量预测问题,搭建了多元线性回归模型和人工神经网络模型,2种模型较传统的金属日产量计算方法均有了较大提升。
1)通过对生产参数的分析,将变量精简后建立的多元线性回归模型能够对C10采区的金属产量做出较为精确的预测,预测结果准确可靠,具有一定的泛化能力。从多元线性回归预测模型公式可以直观看出各生产参数与金属日产量的相关性与影响权重,可为生产制度的调整与增产提供指导。
2)人工神经网络模型较多元线性模型在精度上进一步提高,对于近13个月采区预测的日产量平均误差仅为-0.36%,总产量预测误差为-0.63%,相对误差分布集中于±10%以内,模型预测效果优异。
猜你喜欢
中国应急管理科学(2022年2期)2022-05-23
中国锰业(2021年3期)2021-03-31
空间科学学报(2020年4期)2020-04-22
电子制作(2019年10期)2019-06-17
中国煤炭(2016年9期)2016-06-15
天然气与石油(2015年1期)2015-02-28
金属矿山(2014年7期)2014-03-20
建筑材料学报(2014年4期)2014-03-11
凿岩机械气动工具(2014年2期)2014-03-01
无损检测(2010年8期)2010-12-04
